Многие программисты считают, что компиляторы — это волшебные «чёрные ящики», на вход в которые можно подать хаотичный код, а на выходе получить красивый оптимизированный двоичный файл. Доморощенные философы часто начинают рассуждать о том, какие фишки языка или флаги компилятора следует использовать, чтобы раскрыть всю мощь магии компилятора. Если вы когда-нибудь видели кодовую базу GCC, то и в самом деле могли поверить, что он выполняет какие-то волшебные оптимизации, пришедшие к нам из иных миров.
Тем не менее, если вы проанализируете результаты работы компиляторов, то узнаете, что они не очень-то хорошо справляются с оптимизацией вашего кода. Не потому, что пишущие их люди не знают, как генерировать эффективные команды, а просто потому, что компиляторы способны принимать решения только в очень малой части пространства задач. [В своём докладе Data Oriented Design (2014 год) Майк Эктон сообщил, что в проанализированном фрагменте кода компилятор теоретически может оптимизировать лишь 10% задачи, а 90% он оптимизировать не имеет никакой возможности. Если бы вам интересно было узнать больше о памяти, то стоит прочитать статью What every programmer should know about memory. Если вам любопытно, какое количество тактов тратят конкретные команды процессора, то изучите таблицы команд процессоров]
Чтобы понять, почему волшебные оптимизации компилятора не ускорят ваше ПО, нужно вернуться назад во времени, к той эпохе, когда по Земле ещё бродили динозавры, а процессоры были чрезвычайно медленными. На графике ниже показаны относительные производительности процессоров и памяти в разные годы (1980-2010 гг.). [Информация взята из статьи Pitfalls of object oriented programming Тони Альбрехта (2009 год), слайд 17. Также можно посмотреть его видео
(2017 год) на ту же тему.]
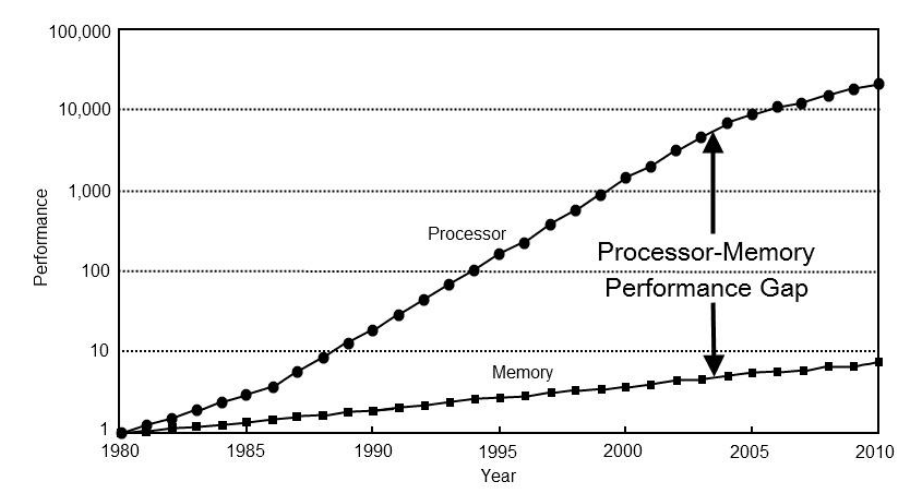
Проблема, демонстрируемая этим графиком, заключается в том, что производительность процессоров за эти годы значительно выросла (ось Y имеет логарифмический масштаб), а производительность памяти росла гораздо меньшими темпами:
Ну и что же? Мы тратим чуть больше тактов на загрузку из памяти, но компьютеры всё равно намного быстрее, чем раньше. Какая разница, сколько тактов мы тратим?
Ну, как ни грустно осознавать, но даже если у нас будут более качественные компиляторы и мощное «железо», скорость ПО значительно не повысится, потому что ПО такое медленное не из-за них. Главная современная проблема — использование процессоров не во всю их мощь.
В таблице ниже указаны параметры задержки самых распространённых операций. [Таблица взята из книги Systems Performance: Enterprise and the cloud (2nd Edition — 2020).] В столбце «Задержка в масштабе» указана задержка в значениях, которые проще понимать людям.
Посмотрев на столбец задержек в масштабе, мы быстро поймём, что доступ к памяти затратен, и что в случае подавляющего большинства приложений процессор просто бездельничает, ожидая ответа от памяти. [Узким местом не всегда является память. Если вы записываете или считываете много данных, то узким местом, скорее всего, будет жёсткий диск. Если вы рендерите большой объём данных на экране, то узким местом может стать GPU.]
На то есть две причины:
Перечисленные выше языки программирования придуманы более 20 лет назад, и принятые их разработчиками проектные решения, например, глобальная блокировка интерпретатора Python или философия Java «всё — это объекты», в современном мире неразумны. [Все мы знаем, какой бардак представляет собой C++. И да, успокойтесь, я знаю, что в списке нет вашего любимого нишевого языка, а C# всего 19 лет.] Оборудование подверглось огромным изменениям, у процессоров появились кэши и многоядерность, однако языки программирования по-прежнему основаны на идеях, которые уже не истинны.
Большинство современных языков программирования стремится упростить жизнь разработчика, избавив его от мучений с управлением памятью вручную. Хотя отсутствие необходимости думать о памяти делает разработчика продуктивнее, за эту продуктивность приходится платить высокую цену.
Выделение блоков памяти без контроля будет замедлять вашу программу, в основном из-за операций произвольного доступа к памяти (промахов кэша), каждая из которых будет стоить вам сотни тактов процессора. Тем не менее, большинство из перечисленных выше языков программирования всё равно будет вести себя так, как будто выделение произвольной памяти — это несерьёзная проблема, и вам не стоит из-за неё беспокоиться, ведь компьютеры очень быстры.
Да, компьютеры чрезвычайно быстры, но только если вы пишете ПО таким образом, что оно хорошо взаимодействует с «железом». На одном и том же оборудовании вы может работать и очень плавная 3D-игра и заметно лагающий MS Word. Очевидно, что проблема здесь не в оборудовании и что мы можем выжать из него гораздо больше, чем среднестатистическое приложение.
Ещё одна проблема современных языков программирования в том, что они недалеко ушли от программирования в стиле C. Не скажу, что есть что-то плохое в написании циклов
Отчасти языкам не хватает функциональности, которая бы позволила писать программы удобным человеку образом и при этом использовать оборудование так, чтобы обеспечивать наилучшую производительность. Хотя используемые нами сегодня типы абстракций удобны, они обычно демонстрируют плохую производительность на современном оборудовании.
Объяснение будет долгим, но давайте начнём с примера:
Вот пример того, как большинство программистов, включая и меня, писало бы код решения этой задачи. Он написан на типичном объектно-ориентированном энтерпрайзном уничтожителе кэша:
Представленное решение компактно и понятно. К сожалению, на современном оборудовании производительность его невысока.
Каждый раз, когда мы запрашиваем байт памяти, отсутствующий в одном из кэшей процессора, из основной памяти запрашивается вся строка кэша, даже если нам нужен только 1 байт. Так как получение данных из основной памяти — довольно затратная операция (см. выше таблицу задержек), нам бы хотелось, чтобы количество таких операций было минимальным. Этого можно достичь двумя способами:
В приведённом выше примере мы будем считать, что из памяти запрашиваются следующие данные (я предполагаю, что используются compressed oops; поправьте меня, если это не так):
Сколько раз нам нужно обратиться к основной памяти, чтобы подсчитать всех муравьёв-воинов (предполагая, что данные колонии муравьёв ещё не загружены в кэш)?
Если учесть, что в современных процессорах строка кэша имеет размер 64 байта, то мы можем получать не больше 2,6 экземпляра муравьёв на строку кэша. Так как этот пример написан на языке Java, в котором всё — это объекты, находящиеся где-то в куче, то мы знаем, что экземпляры муравьёв могут находиться в разных строках кэша. [Если распределить все экземпляры одновременно, один за другим, то есть вероятность, что они будут расположены один за другим и в куче, что ускорит итерации. В общем случае лучше всего заранее распределить все данные при запуске, чтобы экземпляры не разбросало по всей куче, однако если вы работаете с managed-языком, то сложно будет понять, что сделают сборщики мусора в фоновом режиме. Например, JVM-разработчики утверждают, что распределение мелких объектов и отмена распределения сразу после их использования обеспечивает бОльшую производительность, чем хранение пула заранее распределённых объектов. Причина этого в принципах работы сборщиков мусора, учитывающих поколения объектов.]
В наихудшем случае экземпляры муравьёв не распределяются один за другим и мы можем получать только по одному экземпляру на каждую строку кэша. Это значит, что для обработки всей колонии муравьёв нужно обратиться к основной памяти 100 раз, и что из каждой полученной строки кэша (64 байта) мы используем только 1 байт. Другими словами, мы отбрасываем 98% полученных данных. Это довольно неэффективный способ пересчёта муравьёв.
Можем ли мы переписать нашу программу так, чтобы запросы к памяти были более рациональными, и таким образом повысить производительность программы? Да, можем.
Мы используем максимально наивный Data Oriented Design. Вместо моделирования муравьёв по отдельности мы смоделируем целую колонию за раз:
Эти два примера алгоритмически эквивалентны (O(n)), но ориентированное на данные решение превосходит по производительности объектно-ориентированное. Почему?
Потому что ориентированный на данные пример получает меньше данных, и эти данные запрашиваются соседними блоками — мы получаем 64 флагов воинов за раз и не тратим ресурсы впустую. Так как мы получаем только нужные нам данные, нам достаточно обратиться к памяти всего два раза, а не по разу для каждого муравья (100 раз). Это намного более эффективный способ подсчёта муравьёв-воинов.
Я выполнил бенчмарки производительности при помощи тулкита Java Microbenchmark Harness (JMH), их результаты показаны в таблице ниже (измерения выполнялись на Intel i7-7700HQ с частотой 3,80 ГГц). Чтобы не загромождать таблицу, я не указал доверительные интервалы, но вы можете выполнить собственные бенчмарки, скачав и запустив код бенчмарка.
Сменив точку зрения на решение задачи, нам удалось добиться огромного ускорения. Стоит также учесть, что в нашем примере класс муравьёв довольно мал, поэтому данные с большой вероятностью останутся в одном из кэшей процессора и разница между двумя вариантами не так заметна (согласно таблице задержек, доступ к памяти из кэша в 30-100 раз быстрее).
Даже несмотря на то, что представленные выше примеры написаны в свободном стиле «всё является публичным», ориентированное на данные проектирование не запрещает использовать корпоративный подход со строгим контролем. Вы можете делать любые поля private и final, создавать геттеры и сеттеры, реализовывать интерфейсы, если вам так нравится.
Кто знает, может, вы даже поймёте, что все эти энтерпрайзные фишки необязательны? Но самое важное здесь в том, что надо перестать думать о муравьях по отдельности, а воспринимать их как группу. В конце концов, вы когда-нибудь видели муравья-одиночку?
Но постойте! Почему ООП настолько популярно, если имеет такую низкую производительность?
Проблемы: допустим, нам нужно найти, сколько в колонии красных муравьёв возрастом старше 1 года. В объектно-ориентированном подходе эта задача решается довольно просто:
При ориентированном на данные подходе всё становится чуть более сложным, ведь нам нужно быть аккуратными с тем, как происходит итерация по массивам (нужно использовать элемент, расположенный по тому же индексу):
А теперь представьте, что кому-то нужно отсортировать всех муравьёв в колонии на основании их имени, а затем что-то сделать с отсортированными данными (например, посчитать всех красных муравьёв из первых 10% отсортированных данных. У муравьёв могут быть странные правила, не судите их строго). При объектно-ориентированном решении мы можем просто использовать функцию сортировки из стандартной библиотеки. При ориентированном на данные способе придётся сортировать массив имён, но в то же самое время сортировать все остальные массивы на основании того, как перемещаются индексы массива имён (мы предполагаем, что нам важно, какие цвет, возраст и флаг воина связаны с именем муравья). [Также можно скопировать массив имён, отсортировать их и найти соответствующее имя в исходном неотсортированном массиве имён, чтобы получить индекс соответствующего элемента. Получив индекс элемента в массиве, можно делать с ним что угодно, но подобные операции поиска выполнять кропотливо. Кроме того, если массивы большие, то такое решение будет довольно медленным. Понимайте свои данные! Также выше не упомянута проблема вставки или удаления элементов в середине массива. При добавлении или удалении элемента из середины массива обычно требуется копировать весь изменённый массив в новое место в памяти. Копирование данных — медленный процесс, и если не быть внимательным при копировании данных, может закончиться память. Если порядок элементов в массивах не важен, можно также заменить удалённый элемент последним элементом массива и уменьшить внутренний счётчик, учитывающий количество активных элементов в группе. При переборе таких элементов в этой ситуации мы, по сути, будем перебирать только активную часть группы. Связанный список не является разумным решением этой задачи, потому что данные не расположены в соседних фрагментах, из-за чего перебор оказывается очень медленным (плохое использование кэша).]
Именно подобные задачи нужно решать при помощи особенностей языков программирования, потому что написание таких специализированных функций сортировки — очень монотонная работа. Что если язык программирования предоставит нам структуру, ведущую себя как массив структур, но внутренне ведущую себя как структура массивов? Мы смогли бы программировать в обычном объектно-ориентированном стиле, удобном для людей, и при этом обеспечивать высокую производительность благодаря оптимальному использованию оборудования.
Пока единственным языком программирования с поддержкой подобных безумных преобразований данных является JAI, но, к сожалению, он пока находится в состоянии закрытого бета-тестирования и недоступен широкой публике. Стоит поразмыслить, почему такая функциональность не встроена в наш «современные» языки программирования.
Если вы когда-нибудь работали в энтерпрайзе и засовывали нос в его кодовую базу, то, вероятнее всего, видели огромную кучу классов с множественными полями и интерфейсами. Большинство ПО по-прежнему пишут подобным образом, потому что из-за влияния прошлого в таком стиле программирования достаточно легко разобраться. Кроме того, те, кто работает с большими кодовыми базами естественным образом тяготеют к знакомому стилю, который видят каждый день. [См. также On navigating a large codebase]
Для смены концепций подхода к решению задач требуется больше усилий, чем для подражания: «Используй const, и компилятор всё оптимизирует!» Никто не знает, что сделает компилятор, и никто не проверяет, что он сделал.
Я написал эту статью потому, что многие программисты считают, что нужно быть гением или знать тайные компиляторные трюки, чтобы писать высокопроизводительный код. Чаще всего достаточно простых рассуждений о данных, движущихся в вашей системе. [Это не значит, что код всегда будет прост и лёгок для понимания — код эффективного умножения матриц довольно запутан.]. В сложной программе сделать это не всегда просто, но и этому тоже должен узнать каждый, если хочет потратить время на изучение подобных концепций.
Если вы хотите больше узнать об этой теме, то прочитайте книгу Data-Oriented Design и остальные ссылки, которые приведены в статье в квадратных скобках.
[БОНУС] Статья, описывающая проблемы объектно-ориентированного программирования:
Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP).
Тем не менее, если вы проанализируете результаты работы компиляторов, то узнаете, что они не очень-то хорошо справляются с оптимизацией вашего кода. Не потому, что пишущие их люди не знают, как генерировать эффективные команды, а просто потому, что компиляторы способны принимать решения только в очень малой части пространства задач. [В своём докладе Data Oriented Design (2014 год) Майк Эктон сообщил, что в проанализированном фрагменте кода компилятор теоретически может оптимизировать лишь 10% задачи, а 90% он оптимизировать не имеет никакой возможности. Если бы вам интересно было узнать больше о памяти, то стоит прочитать статью What every programmer should know about memory. Если вам любопытно, какое количество тактов тратят конкретные команды процессора, то изучите таблицы команд процессоров]
Чтобы понять, почему волшебные оптимизации компилятора не ускорят ваше ПО, нужно вернуться назад во времени, к той эпохе, когда по Земле ещё бродили динозавры, а процессоры были чрезвычайно медленными. На графике ниже показаны относительные производительности процессоров и памяти в разные годы (1980-2010 гг.). [Информация взята из статьи Pitfalls of object oriented programming Тони Альбрехта (2009 год), слайд 17. Также можно посмотреть его видео
(2017 год) на ту же тему.]
Проблема, демонстрируемая этим графиком, заключается в том, что производительность процессоров за эти годы значительно выросла (ось Y имеет логарифмический масштаб), а производительность памяти росла гораздо меньшими темпами:
- В 1980 году задержка ОЗУ составляла примерно 1 такт процессора
- В 2010 году задержка ОЗУ составляла примерно 400 тактов процессора
Ну и что же? Мы тратим чуть больше тактов на загрузку из памяти, но компьютеры всё равно намного быстрее, чем раньше. Какая разница, сколько тактов мы тратим?
Ну, как ни грустно осознавать, но даже если у нас будут более качественные компиляторы и мощное «железо», скорость ПО значительно не повысится, потому что ПО такое медленное не из-за них. Главная современная проблема — использование процессоров не во всю их мощь.
В таблице ниже указаны параметры задержки самых распространённых операций. [Таблица взята из книги Systems Performance: Enterprise and the cloud (2nd Edition — 2020).] В столбце «Задержка в масштабе» указана задержка в значениях, которые проще понимать людям.
| Событие | Задержка | Задержка в масштабе |
|---|---|---|
| 1 такт ЦП | 0,3 нс | 1 с |
| Доступ к кэшу L1 | 0,9 нс | 3 с |
| Доступ к кэшу L2 | 3 нс | 10 с |
| Доступ к кэшу L3 | 10 нс | 33 с |
| Доступ к основной памяти | 100 нс | 6 мин |
| Ввод-вывод SSD | 10-100 мкс | 9-90 ч |
| Ввод-вывод жёсткого диска | 1-10 мс | 1-12 месяцев |
Посмотрев на столбец задержек в масштабе, мы быстро поймём, что доступ к памяти затратен, и что в случае подавляющего большинства приложений процессор просто бездельничает, ожидая ответа от памяти. [Узким местом не всегда является память. Если вы записываете или считываете много данных, то узким местом, скорее всего, будет жёсткий диск. Если вы рендерите большой объём данных на экране, то узким местом может стать GPU.]
На то есть две причины:
- Языки программирования, которые мы используем и сегодня, создавались во времена, когда процессоры были медленными, а задержки памяти не были такими критичными.
- Best practices отрасли по-прежнему связаны с объектно-ориентированным программированием, которое показывает на современном оборудовании не очень высокую производительность.
Языки программирования
| Язык | Время создания |
|---|---|
| C | 1975 год |
| C++ | 1985 год |
| Python | 1989 год |
| Java | 1995 год |
| Javascript | 1995 год |
| Ruby | 1995 год |
| C# | 2002 год |
Перечисленные выше языки программирования придуманы более 20 лет назад, и принятые их разработчиками проектные решения, например, глобальная блокировка интерпретатора Python или философия Java «всё — это объекты», в современном мире неразумны. [Все мы знаем, какой бардак представляет собой C++. И да, успокойтесь, я знаю, что в списке нет вашего любимого нишевого языка, а C# всего 19 лет.] Оборудование подверглось огромным изменениям, у процессоров появились кэши и многоядерность, однако языки программирования по-прежнему основаны на идеях, которые уже не истинны.
Большинство современных языков программирования стремится упростить жизнь разработчика, избавив его от мучений с управлением памятью вручную. Хотя отсутствие необходимости думать о памяти делает разработчика продуктивнее, за эту продуктивность приходится платить высокую цену.
Выделение блоков памяти без контроля будет замедлять вашу программу, в основном из-за операций произвольного доступа к памяти (промахов кэша), каждая из которых будет стоить вам сотни тактов процессора. Тем не менее, большинство из перечисленных выше языков программирования всё равно будет вести себя так, как будто выделение произвольной памяти — это несерьёзная проблема, и вам не стоит из-за неё беспокоиться, ведь компьютеры очень быстры.
Да, компьютеры чрезвычайно быстры, но только если вы пишете ПО таким образом, что оно хорошо взаимодействует с «железом». На одном и том же оборудовании вы может работать и очень плавная 3D-игра и заметно лагающий MS Word. Очевидно, что проблема здесь не в оборудовании и что мы можем выжать из него гораздо больше, чем среднестатистическое приложение.
Совершенствовалось оборудование, но не языки
Ещё одна проблема современных языков программирования в том, что они недалеко ушли от программирования в стиле C. Не скажу, что есть что-то плохое в написании циклов
for, но становится всё сложнее и сложнее использовать весь потенциал процессоров и в то же время управлять сложностью современных программ.Отчасти языкам не хватает функциональности, которая бы позволила писать программы удобным человеку образом и при этом использовать оборудование так, чтобы обеспечивать наилучшую производительность. Хотя используемые нами сегодня типы абстракций удобны, они обычно демонстрируют плохую производительность на современном оборудовании.
Объяснение будет долгим, но давайте начнём с примера:
Представьте, что мы симулируем колонию муравьёв. Административный отдел колонии был уничтожен атакой муравьеда, поэтому он не знает, сколько муравьёв-воинов осталось живо в колонии.
Поможем нашему муравью-администратору посчитать муравьёв-воинов!
Вот пример того, как большинство программистов, включая и меня, писало бы код решения этой задачи. Он написан на типичном объектно-ориентированном энтерпрайзном уничтожителе кэша:
class Ant { public String name = "unknownAnt"; public String color = "red"; public boolean isWarrior = false; public int age = 0; } // shh, it's a tiny ant colony List<Ant> antColony = new ArrayList<>(100); // fill the colony with ants // count the warrior ants long numOfWarriors = 0; for (Ant ant : antColony) { if (ant.isWarrior) { numOfWarriors++; } }
Представленное решение компактно и понятно. К сожалению, на современном оборудовании производительность его невысока.
Каждый раз, когда мы запрашиваем байт памяти, отсутствующий в одном из кэшей процессора, из основной памяти запрашивается вся строка кэша, даже если нам нужен только 1 байт. Так как получение данных из основной памяти — довольно затратная операция (см. выше таблицу задержек), нам бы хотелось, чтобы количество таких операций было минимальным. Этого можно достичь двумя способами:
- Уменьшив объём данных, которые нужно получать для нашей задачи.
- Храня необходимые данные в соседних блоках, чтобы полностью использовать строки кэша.
В приведённом выше примере мы будем считать, что из памяти запрашиваются следующие данные (я предполагаю, что используются compressed oops; поправьте меня, если это не так):
+ 4 байта на ссылку имени
+ 4 байта на ссылку цвета
+ 1 байт на флаг воина
+ 3 байта заполнителя
+ 4 байта на integer возраста
+ 8 байт на заголовки класса
---------------------------------
24 байта на каждый экземпляр муравьяСколько раз нам нужно обратиться к основной памяти, чтобы подсчитать всех муравьёв-воинов (предполагая, что данные колонии муравьёв ещё не загружены в кэш)?
Если учесть, что в современных процессорах строка кэша имеет размер 64 байта, то мы можем получать не больше 2,6 экземпляра муравьёв на строку кэша. Так как этот пример написан на языке Java, в котором всё — это объекты, находящиеся где-то в куче, то мы знаем, что экземпляры муравьёв могут находиться в разных строках кэша. [Если распределить все экземпляры одновременно, один за другим, то есть вероятность, что они будут расположены один за другим и в куче, что ускорит итерации. В общем случае лучше всего заранее распределить все данные при запуске, чтобы экземпляры не разбросало по всей куче, однако если вы работаете с managed-языком, то сложно будет понять, что сделают сборщики мусора в фоновом режиме. Например, JVM-разработчики утверждают, что распределение мелких объектов и отмена распределения сразу после их использования обеспечивает бОльшую производительность, чем хранение пула заранее распределённых объектов. Причина этого в принципах работы сборщиков мусора, учитывающих поколения объектов.]
В наихудшем случае экземпляры муравьёв не распределяются один за другим и мы можем получать только по одному экземпляру на каждую строку кэша. Это значит, что для обработки всей колонии муравьёв нужно обратиться к основной памяти 100 раз, и что из каждой полученной строки кэша (64 байта) мы используем только 1 байт. Другими словами, мы отбрасываем 98% полученных данных. Это довольно неэффективный способ пересчёта муравьёв.
Ускоряем работу
Можем ли мы переписать нашу программу так, чтобы запросы к памяти были более рациональными, и таким образом повысить производительность программы? Да, можем.
Мы используем максимально наивный Data Oriented Design. Вместо моделирования муравьёв по отдельности мы смоделируем целую колонию за раз:
class AntColony { public int size = 0; public String[] names = new String[100]; public String[] colors = new String[100]; public int[] ages = new int[100]; public boolean[] warriors = new boolean[100]; // I am aware of the fact that this array could be removed // by splitting the colony in two (warriors, non warriors), // but that is not the point of this story. // // Yes, you can also sort it and enjoy in an additional // speedup due to branch predictions. } AntColony antColony_do = new AntColony(); // fill the colony with ants and update size counter // count the warrior ants long numOfWarriors = 0; for (int i = 0; i < antColony_do.size; i++) { boolean isWarrior = antColony_do.warriors[i]; if (isWarrior) { numOfWarriors++; } }
Эти два примера алгоритмически эквивалентны (O(n)), но ориентированное на данные решение превосходит по производительности объектно-ориентированное. Почему?
Потому что ориентированный на данные пример получает меньше данных, и эти данные запрашиваются соседними блоками — мы получаем 64 флагов воинов за раз и не тратим ресурсы впустую. Так как мы получаем только нужные нам данные, нам достаточно обратиться к памяти всего два раза, а не по разу для каждого муравья (100 раз). Это намного более эффективный способ подсчёта муравьёв-воинов.
Я выполнил бенчмарки производительности при помощи тулкита Java Microbenchmark Harness (JMH), их результаты показаны в таблице ниже (измерения выполнялись на Intel i7-7700HQ с частотой 3,80 ГГц). Чтобы не загромождать таблицу, я не указал доверительные интервалы, но вы можете выполнить собственные бенчмарки, скачав и запустив код бенчмарка.
| Задача (размер колонии) | ООП | DOD | Ускорение |
|---|---|---|---|
| countWarriors (100) | 10 874 045 операций/с | 19 314 177 операций/с | 78% |
| countWarriors (1000) | 1 147 493 операций/с | 1 842 812 операций/с | 61% |
| countWarriors (10000) | 102 630 операций/с | 185 486 операций/с | 81% |
Сменив точку зрения на решение задачи, нам удалось добиться огромного ускорения. Стоит также учесть, что в нашем примере класс муравьёв довольно мал, поэтому данные с большой вероятностью останутся в одном из кэшей процессора и разница между двумя вариантами не так заметна (согласно таблице задержек, доступ к памяти из кэша в 30-100 раз быстрее).
Даже несмотря на то, что представленные выше примеры написаны в свободном стиле «всё является публичным», ориентированное на данные проектирование не запрещает использовать корпоративный подход со строгим контролем. Вы можете делать любые поля private и final, создавать геттеры и сеттеры, реализовывать интерфейсы, если вам так нравится.
Кто знает, может, вы даже поймёте, что все эти энтерпрайзные фишки необязательны? Но самое важное здесь в том, что надо перестать думать о муравьях по отдельности, а воспринимать их как группу. В конце концов, вы когда-нибудь видели муравья-одиночку?
Где есть один, будет несколько.
Майк Эктон
Но постойте! Почему ООП настолько популярно, если имеет такую низкую производительность?
- Нагрузка часто зависит от ввода-вывода (по крайней мере, в бэкенде серверов), который примерно в 1000 раз медленнее доступа к памяти. Если вы записываете много данных на жёсткий диск, то улучшения, внесённые в структуру памяти, могут и почти не повлиять на показатели.
- Требования к производительности большинства корпоративного ПО чудовищно низки, и с ними справится любой старый код. Это ещё называют синдромом «клиент за это не заплатит».
- Идеи в нашей отрасли движутся медленно, и сектанты ПО отказываются меняться. Всего 20 лет назад задержки памяти не были особой проблемой, и best practices пока не догнали изменения в оборудовании.
- Большинство языков программирования поддерживает такой стиль программирования, а концепцию объектов легко понять.
- Ориентированный на данные способ программирования тоже обладает собственным множеством проблем.
Проблемы: допустим, нам нужно найти, сколько в колонии красных муравьёв возрастом старше 1 года. В объектно-ориентированном подходе эта задача решается довольно просто:
long numOfChosenAnts = 0; for (Ant ant : antColony) { if (ant.age > 1 && "red".equals(ant.color)) { numOfChosenAnts++; } }
При ориентированном на данные подходе всё становится чуть более сложным, ведь нам нужно быть аккуратными с тем, как происходит итерация по массивам (нужно использовать элемент, расположенный по тому же индексу):
long numOfChosenAnts = 0; for (int i = 0; i < antColony.size; i++) { int age = antColony.ages[i]; String color = antColony.colors[i]; if (age > 1 && "red".equals(color)) { numOfChosenAnts++; } }
А теперь представьте, что кому-то нужно отсортировать всех муравьёв в колонии на основании их имени, а затем что-то сделать с отсортированными данными (например, посчитать всех красных муравьёв из первых 10% отсортированных данных. У муравьёв могут быть странные правила, не судите их строго). При объектно-ориентированном решении мы можем просто использовать функцию сортировки из стандартной библиотеки. При ориентированном на данные способе придётся сортировать массив имён, но в то же самое время сортировать все остальные массивы на основании того, как перемещаются индексы массива имён (мы предполагаем, что нам важно, какие цвет, возраст и флаг воина связаны с именем муравья). [Также можно скопировать массив имён, отсортировать их и найти соответствующее имя в исходном неотсортированном массиве имён, чтобы получить индекс соответствующего элемента. Получив индекс элемента в массиве, можно делать с ним что угодно, но подобные операции поиска выполнять кропотливо. Кроме того, если массивы большие, то такое решение будет довольно медленным. Понимайте свои данные! Также выше не упомянута проблема вставки или удаления элементов в середине массива. При добавлении или удалении элемента из середины массива обычно требуется копировать весь изменённый массив в новое место в памяти. Копирование данных — медленный процесс, и если не быть внимательным при копировании данных, может закончиться память. Если порядок элементов в массивах не важен, можно также заменить удалённый элемент последним элементом массива и уменьшить внутренний счётчик, учитывающий количество активных элементов в группе. При переборе таких элементов в этой ситуации мы, по сути, будем перебирать только активную часть группы. Связанный список не является разумным решением этой задачи, потому что данные не расположены в соседних фрагментах, из-за чего перебор оказывается очень медленным (плохое использование кэша).]
Именно подобные задачи нужно решать при помощи особенностей языков программирования, потому что написание таких специализированных функций сортировки — очень монотонная работа. Что если язык программирования предоставит нам структуру, ведущую себя как массив структур, но внутренне ведущую себя как структура массивов? Мы смогли бы программировать в обычном объектно-ориентированном стиле, удобном для людей, и при этом обеспечивать высокую производительность благодаря оптимальному использованию оборудования.
Пока единственным языком программирования с поддержкой подобных безумных преобразований данных является JAI, но, к сожалению, он пока находится в состоянии закрытого бета-тестирования и недоступен широкой публике. Стоит поразмыслить, почему такая функциональность не встроена в наш «современные» языки программирования.
Best practices
Если вы когда-нибудь работали в энтерпрайзе и засовывали нос в его кодовую базу, то, вероятнее всего, видели огромную кучу классов с множественными полями и интерфейсами. Большинство ПО по-прежнему пишут подобным образом, потому что из-за влияния прошлого в таком стиле программирования достаточно легко разобраться. Кроме того, те, кто работает с большими кодовыми базами естественным образом тяготеют к знакомому стилю, который видят каждый день. [См. также On navigating a large codebase]
Для смены концепций подхода к решению задач требуется больше усилий, чем для подражания: «Используй const, и компилятор всё оптимизирует!» Никто не знает, что сделает компилятор, и никто не проверяет, что он сделал.
Компилятор — это инструмент, а не волшебная палочка!
Майк Эктон
Я написал эту статью потому, что многие программисты считают, что нужно быть гением или знать тайные компиляторные трюки, чтобы писать высокопроизводительный код. Чаще всего достаточно простых рассуждений о данных, движущихся в вашей системе. [Это не значит, что код всегда будет прост и лёгок для понимания — код эффективного умножения матриц довольно запутан.]. В сложной программе сделать это не всегда просто, но и этому тоже должен узнать каждый, если хочет потратить время на изучение подобных концепций.
Если вы хотите больше узнать об этой теме, то прочитайте книгу Data-Oriented Design и остальные ссылки, которые приведены в статье в квадратных скобках.
[БОНУС] Статья, описывающая проблемы объектно-ориентированного программирования:
Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP).

