
Сказ про то как Apache Arrow к уткам по паркету ходил.
В этой статье сошлись 3 технологии обработки/хранения данных и каждая по своему примечательна, но обо всем по порядку.
Статья печаталась под
Статья печаталась под Arrows (Icicle) , Apache (Incredible Bongo Band) и Duck Funk ибо под что же еще печатать статью на такую тему…
Утверждение 1. Паркет это хорошо (особенно в сравнении с ламинатом)

Когда-то в стародавние времена записи хранили строками - древние египтяне не дали бы соврать.
И подход "один атомарный объект = кортеж из разнородных типов данных" был всем понятен и приятен.
Даже в аналоговых записных книжках на целлюлозе наши родители писали контакты примерно так:
Иванов { String, page indexed by first letter} Иван {String} Иванович {String}, 84959367832 {Big integer}.
Конечно вряд ли они уточняли тип данных под каждый элемент кортежа, но тем не менее видно что одна строка имеет разные типы данных.
Хотя тут возразят что телефон
Хотя тут возразят что телефон - это то же текст ибо "скобочки, дефисы и плюсы", но можно расширить пример на дату рождения с типом date и снова получить разнородные типы в одной строке.
И в файлы запись шла так же - строками (тот же CSV/TXT).
Отсюда 2 печальных следствия:
когда у вас в исходных данных таблица на 100500 столбцов из которых вам надо всего 3 - вам будет грустно, потому что придется честно прочитать (==залить в оперативку) все 100500 столбцов чтобы в итоге оставить свои 3.
сжимать файл с разнородным типом данных придется чем-то универсальным типа RAR/7zip/Gzip а всё универсальное всегда работало хуже специализированного. И да, перед чтением этого архива придется понести накладные расходы на распаковку универсальным (==медленным) архиватором обратно тех самых 100500 столбцов чтобы взять оттуда те самые 3 нужных.
И тут родилась гениальная идея - сменить на 90 градусов подход (в прямом смысле этого слова), т.е. хранить данные не строками а колонками. Причём физически хранить, и хранить с метаданными - описание данных, включая заголовки колонок и типы колонок. Таким способом победили сразу 2 проблемы: и первую (физически выдергиваем только только нужные колонки) и вторую (на лету распаковываем то что лучше всего упаковал алгоритм, заточенный именно под тип данных каждой колонки).
Один из ярких представителей этого вида - формат паркет.
К перечисленным плюсам - это еще и кросс-языковый пакет: его могут читать не только R (в отличие от RDS) но и Python, Java, да и вообще это популярный формат хранения данных во всяких там "Хадупистых Биг дэйта стеках" (наряду с Avro, JSON)
Сравним размеры и скорость записи/чтения CSV vs. parquet
Для этого возьмём самый большой датасет из пакета "nycflights13"
library(nycflights13) data(package='nycflights13') library(arrow) str(flights)

# создаем временную директорию нашего эксперимента parquets.dir <- paste0(tempdir(),'\\flight_parquets') print(parquets.dir) dir.create(path = parquets.dir) # Тестируем размеры и скорость записи/чтения одного CSV файла file.name <- paste(parquets.dir,'flights_1.csv',sep = '\\') system.time( write.csv2(flights,file = file.name) ) # 8.58 sec хотя data.table::fwrite мог бы быстрее paste(file.size(x = file.name)/1024^2," Mb") # 34.96 Mb system.time(read.csv2(file.name)) # 1.52 sec file.remove(file.name) # Тестируем размеры и скорость записи/чтения одного parquet файла file.name <- paste(parquets.dir,'flights_1.parquet',sep = '\\') system.time( arrow::write_parquet(flights,sink = file.name) ) # 0.34 sec file.name <- paste(parquets.dir,'flights_1.parquet',sep = '\\') system.time( arrow::write_parquet(flights,sink = file.name) ) # 0.34 sec paste(file.size(x = file.name)/1024^2," Mb") # 5.43 Mb (в 7 раз) system.time(arrow::read_parquet(file.name)) # 0.05 sec
Как видим - разница существенная как по скорости записи, чтения так и по размеру файла.
Утверждение 2. Arrow - прекрасен, а pandas - не очень.

В какой-то момент всякие бизнесы накопили у себя "Дату" в весьма приличных объемах и захотелось бизнесам ее поанализировать. А так как этой "Даты" было у каждого примерно много (по субъективно-бизнесовым ощущениям ), то зародилась в недрах бизнесов профессия "аналитик" с маниакальными склонностями все подряд фильтровать да джоинить, а затем по группам суммировать, усреднять, обогащать вычисляемыми колонками, и (не к ночи сказано) строить оконные функции по всему этому безобразию.
В ту эпоху жил да был один умный паренёк, и звали его Вес Маккини.
И очень он любил Python, но страдал в те времена от убогости Python при анализе табличных данных. Не знаю сколько он мучился но в итоге начал пилить своего буратину и выпилил самый популярный пакет работы с табличными данными во всей экосистеме Python - Pandas.
Буратина оказался настолько пригожим что в сообществе Python это вмиг произвело "вау-эффект", причем настолько глобальный, что сложно теперь найти jupiter-ноутбучек без стартового заклинания адептов Python:
import pandas as pd
Конечно у Pandas были и недостатки, но по тем временам его достоинства перекрывали примерно всё!
Но шли годы, объем данных для анализа рос экспоненциально (как число джунов с курсов "дата сайенс за 4 недели на python и у вас 300k/sec"), жёсткие диски сменялись на быстрые твердотельные SSD накопители, число ядер у пользователей под капотом размножалось методом почкования, становилось трендом многопоточность вычислений и вот на фоне всего этого выяснилось что проявившиеся недостатки Pandas - это вовсе не детские болячки, а обострения хронических болезней старого пенсионера.
Даже если оставить за скобками нечитаемый марсианский синтаксис Pandas (люди избалованные R'вскими пакетами tidyverse поймут о чём речь) - Pandas страдает от питоновского GIL (Python Global Interpreter Lock).
Как будто мало ему бедолаге этого, Pandas еще и "награжден" своим личным бутылочным горлышком при работе с гетерогенным типами данных - BlockManager. Говоря простым языком - если вы хотите работать с датафреймом в 1 гигабайт, то будьте готовы выделить под Pandas в 5-10 раз больше свободной оперативной памяти чем сам исходный датасет (т.е. минимум 5 незанятых гигабайт под 1)
спойлер
Люди избалованные R'вским пакетом data.table, читая это - снисходительно улыбаются.
Помимо затыков с производительностью Pandas припас для неопытных новобранцев в когорту Python острые грабельки - недетеременированное и неявное поведение в процессе манипуляции с переменными. Проще говоря, если вы расслабились и забыли (или не знали) и явно не прописали определённые (кажущиеся излишними) синтаксические команды в Pandas, то самое неприятное в том что скорее всего в большинстве случаев всё будет прекрасно работать. До определённого неявного момента, и когда стрельнёт - то будет оочень больно. Желающие подробностей могут пройти по ссылке (18+).
Сам Вес Маккини все это прекрасно понимал, и написал статью Apache Arrow and the "10 Things I Hate About pandas . Там он хорошо описал почему в 21м веке уже не стоит для анализа данных использовать голый Pandas, почему Dask - не панацея и как он пришёл к проекту Arrow.

Подробно рассказывать в этой статье чем Arrow хорош не буду, и без меня статей написано про него достаточно, скажу лишь что помимо отличной производительности у него есть коннекторы как к Python так и к R, причем в R он написан на прекрасном dplyr, то есть получаете производительность в подарок при том что остаетесь в читаемом удобном синатксисе не требующем изучения +1 языка.
Проведем замеры по скорости фильтрации того же набора данных используя arrow, но теперь мы увеличим число parquet-файлов в 10 раз (3 млн.360 тыс. записей суммарно).
library(dplyr) # закатаем в паркет 10 копий flights for(i in 1:10){ file.name <- paste0('flights_',i,'.parquet') print(file.name) arrow::write_parquet(flights,sink = paste(parquets.dir,file.name,sep = '\\')) } # открываем arrow датасет на всю папку хранения паркетов ds <- open_dataset(sources = parquets.dir) ds
Фильтрация у нас по вхождению в список 'EWR','JFK' , номер месяца в интервале февраль-ноябрь и перевозчик не входит в коды 'OO','HA','YV'.
system.time( ds %>% filter(origin %in% c('EWR','JFK'), between(month,left = 2,right = 11), !(carrier %in% c('OO','HA','YV'))) %>% collect()) # 0.65 sec
Здесь остановимся и подумаем: итак arrow понадобилось на датасете в 3,3 миллиона записей перебрать каждый из 10 файлов, отфильтровать вхождение числового признака в интервал + вхождение категориального признака в список + не вхождение другого категориального признака в список. И все это чуть более чем за половину секунды...
Из последнего реального кейса: на работе мне пришлось из 150 csv файлов суммарным весом более 10 гб (естественно я их перегнал в паркеты) делать фильтрации определённых продуктов и магазинов и всё это произошло настолько быстро, что я еще перепроверял результаты потому что в первый раз не поверил что такое возможно.
На момент написания статьи сейчас вышел пакет версии 6.0.1 в котором помимо фильтрации теперь можно делать JOIN's, группировки и агрегации силами самого arrow (раньше после collect отфильтрованный массив возвращался и группировался силами R'вского dplyr)
Посчитаем время фильтрации с агрегацией по времени полета и задержек с группировкой по перевозчику, аэропорту вылета, году и месяцу.
system.time( ds %>% filter(origin %in% c('EWR','JFK'), between(month,left = 2,right = 11), !(carrier %in% c('OO','HA','YV'))) %>% group_by(carrier,origin,year, month) %>% summarise(min_arr_delay=min(arr_delay,na.rm = T), mean_arr_time=mean(arr_time,na.rm = T), mean_dep_delay=mean(dep_delay,na.rm = T)) %>% collect() ) # 0.36 sec
Обратите внимание что доп.операция группировки с суммированием после фильтрации оказалась даже быстрее чем просто фильтрация.
Догадка
Я запускал несколько раз вручную и просто фильтрацию и фильтрацию с группировкой и каждый раз с группировкой было быстрее чем без нее. Знающие люди подскажут в комментариях , у меня единственная гипотеза ускорения в то что без группировки надо возвращать из Arrow в R больший датасет чем с группировкой (видимо существенные накладные расходы) при том что сама операция группировки на стороне arrow по длительности незначительна.
Здесь остановимся и еще раз подумаем: итак arrow понадобилось на датасете в 3,3 миллиона записей перебрать каждый из 10 файлов и к той самой фильтрации применить различные агрегации с группировкой по перевозчику, аэропорту вылета, году и месяцу. И все это чуть более чем за треть секунды...
Наберемся немного наглости и скажем что нам и этого мало, хотим быстрее.
А при чём тут вообще утки?

Идея "колоночности" в файлах дала такой бустинг в сфере аналитики данных что очень скоро появился целый класс баз данных: аналитические колоночные СУБД.
В этой прекрасной когорте сейчас много всяких, из самых известных: Apache Druid, Greenplum, Vertica и ClickHouse от Яндекса.
Но есть и менее раскрученные проекты но от этого не менее крутые, вот о них и поговорим.
Задайте себе вопрос: какая база - самая распространенная в мире? Многие знают ответ - sql lite.
Ей можно даже внутри R (и скорее всего в Python тоже) сессии пользоватся in-memory, если вдруг соскучились по SQL или надо объекты из памяти в базу сохранить. Единственный минус - в ней классическое строчное хранение записей.
А что вы бы сказали если бы была возможность работать так же внутри сессии с большими объемами данных но бэкендом бы к R/Python выступал колоночный аналог sql lite?
Знакомьтесь, DuckDB !

Полностью описывать ее не буду (по ссылке выше сделали это лучше меня) но помимо своей колоночности она может смотреть на набор parquet-файлов как на единую колоночную гипертаблицу со всей гибкостью SQL языка.
То есть в нашем случае DuckDB может выступать колоночным SQL-движком над этими файлами!
Перепишем наши условия фильтрации и агрегирования на SQL и замерим скорость
# Начинаем утиные истории library(duckdb) # "DuckDB can also read a series of Parquet files and treat them as if they were a single table. # Note that this only works if the Parquet files have the same schema. # You can specify which Parquet files you want to read using the glob syntax." library(DBI) drv <- duckdb(":memory:", read_only = FALSE) con <- dbConnect(drv) sql <- paste0("SELECT carrier,origin,year, month,", " min(arr_delay) as min_arr_delay,", " avg(arr_time) as mean_arr_time,", " avg(dep_delay) as mean_dep_delay", " FROM parquet_scan('",parquets.dir,"\\*.parquet')", " where origin in ('EWR','JFK') and carrier not in ('OO','HA','YV')", " and month between 2 and 11", " group by carrier,origin,year, month") system.time( df2 <- dbGetQuery(conn = con,sql)) #0.06 sec
0.06 sec - это не ошибка, я перепроверял.
Чтобы удостовериться сделаем микробенчмарк на 30 замеров
library(microbenchmark) mb <- microbenchmark(arrow = ds %>% filter(origin %in% c('EWR','JFK'), between(month,left = 2,right = 11), !(carrier %in% c('OO','HA','YV'))) %>% group_by(carrier,origin,year, month) %>% summarise(min_arr_delay=min(arr_delay,na.rm = T), mean_arr_time=mean(arr_time,na.rm = T), mean_dep_delay=mean(dep_delay,na.rm = T)) %>% collect(), duckdb=dbGetQuery(conn = con,sql), times = 30L) dbDisconnect(con, shutdown=TRUE) library(ggplot2) ggplot2::autoplot(mb)+theme_minimal()
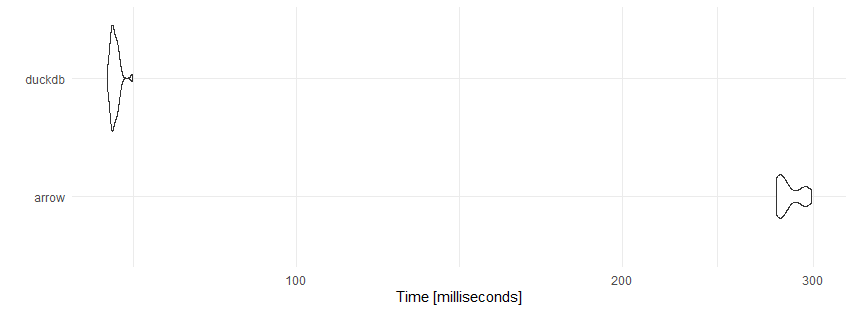
print(mb)

Как говорится - комментарии излишни.
Оба эти проекта (arrow & DuckDB) дружат, и активно развиваются последнее время.
Есть даже конвертер для переключения движка туда и обратно прямо внутри dplyr - пайплайнов, то есть мы можем явно указывать - какая часть пайпланов выполняется arrow а какая DuckDB
DuckDB quacks Arrow: A zero-copy data integration between Apache Arrow and DuckDB

Ниже - пример:
ds %>% select(-time_hour) %>% # duckDB не понимает tz=America/New_York поэтому отбросим заранее (может кто запостит в issues??) filter(origin %in% c('EWR','JFK'), between(month,left = 2,right = 11), !(carrier %in% c('OO','HA','YV'))) %>% to_duckdb() %>% # Переключаем на утиный движок - далее DuckDB group_by(carrier,origin,year, month) %>% summarise(min_arr_delay=min(arr_delay,na.rm = T), mean_arr_time=mean(arr_time,na.rm = T), mean_dep_delay=mean(dep_delay,na.rm = T)) %>% collect()
Надеюсь что статья окажется полезной, хотя уверен что мажоритарный класс питонистов будет продолжать колоться но пользоваться pandas.
Для них (и не только для них) ниже от H2O интересный бенчмарк производительности R'вского data.table, pandas, arrow, DuckDB и прочих на 0,5 гб, 5 гб и 50 гб.

