Сube (до недавнего времени cube.js) относительно молодой проект (первый релиз март 2019) - реализация концепции OLAP-куб. Несмотря на отличную документацию, в интернете пока что мало информации на русском языке. Если вы выбираете систему аналитики, приверженец open-source или просто хотите узнать об альтернативах Power BI и Tableau, то это статья для вас. Обзор платформы и применение на реальном примере.
Кратко об OLAP-кубах
OLAP (Оперативный анализ данных) — технология хранения и обработки многомерных данных, позволяющая получать сложные аналитические отчёты в реальном времени.
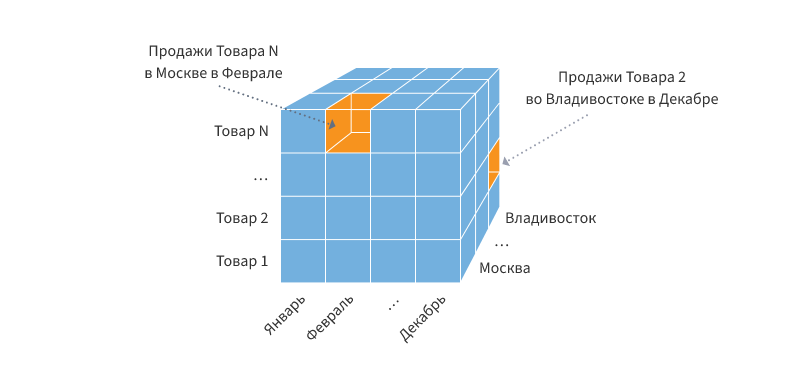
В основе технологии лежит представление данных в виде многомерных кубов.
Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса - измерения (dimensions).
На пересечении осей, в ячейках внутри куба находятся данные, количественно характеризующие процесс - меры (measures).
В качестве одного из измерений используется время (time dimension).
На рисунке представлен пример 3-мерного куба, содержащего измерения «Товар», «Месяц» и «Город».
Автором идеи OLAP является Эдгар Кодд, который сформулировал 12 правил, определивших эту технологию:
Многомерный концептуальный взгляд на данные (Multidimensional conceptual view)
Прозрачность для пользователя (Transparency)
Доступность разнородных источников данных (Accessibility)
Постоянство характеристик производительности при увеличении числа измерений (Consistent reporting performance)
Клиент-серверная архитектура (Client server architecture)
Общность измерений по структуре и возможностям обработки (Generic Dimensionality)
Обработка разреженных матриц (Dynamic sparse matrix handling)
Наличие многопользовательской среды (Multi-user support)
Операции с любым числом измерениями (Unrestricted cross-dimensional operations)
Интуитивное манипулирование данными (Intuitive data manipulation)
Гибкое формирование отчётности (Flexible reporting)
Неограниченное число измерений и уровней агрегирования данных (Unlimited Dimensions and aggregation levels)
Представление данных в виде куба обеспечивает возможность реализации концептуально простых операций для поддержки процесса анализа — срез и фрагментацию, детализацию, свертывание и вращение:
Срез (slice) — извлечение из куба подмножества ячеек, связанных с каким-либо значением одного из его измерений. Например, срез по значению «Февраль» измерения «Месяц» (см. рис. выше) позволяет получить данные по продажам всех товаров во всех городах. Фактически, срез можно рассматривать как одномерный куб, который можно представить в виде обычной плоской таблицы. Использование срезов позволяет выполнить декомпозицию задачи анализа сложных многомерных структур на несколько более простых одномерных задач.
Фрагментация (dice) — извлечение из куба некоторого подкуба, содержащего только те значения измерений, которые нужны для анализа. Например, фрагмент куба может содержать данные только за определенный интервал дат или о продажах по заданным городам.
Детализация (Drill Down/Up) — позволяет аналитику изменять уровень представления данных в кубе от более общего к более детальному (down) или наоборот (up).
Свертывание (RollUp) — агрегирование данных по одному или нескольким измерениям. Производится в том случае, если нужны сводные, а не полные данные.
Вращение (pivot) — позволяет менять пространственную ориентацию осей измерений куба, выбирая наиболее удобное для аналитика представление.
Платформа Cube
Cube - headless (отделенная от отображения) платформа бизнес аналитики. Она помогает получать данные из разных источников данных, организовать в твердые определения и доставлять в любое приложение. С помощью неё можно построить собственный интерфейс для отображения графиков на любой библиотеке (например rechart.js для React). Или получать данные с помощью REST, GraphQL и SQL API.
Поддерживаемые источники данных:
Postgres
MySQL
SQLite
MongoDb
ClickHouse
Google BigQuery
... и другие (также поддерживает написание собственных драйверов)
Почему Сube
Не буду копировать преимущества из документации, опишу собственный опыт.
Задача: выбрать систему аналитики для самописной ERP системы.
Варианты: Power BI или другие подобные решения, написанием запросов на чистом SQL и Cube.
Преимущества
Бесплатно
Стоимость пользователя в Power BI 10$
Быстро
Так как Power BI работает не напрямую с источником данных, а создает “набор данных” для кеширования и оптимизации запросов это работает дольше даже на небольших наборах данных. Cube выполняет запросы напрямую в SQL, в связке с кешированием и преагрегацией это дает высокую скорость
Простая интеграция
Интеграция в уже существующий фронтенд Power BI оказалась тяжелой задачей из-за отдельных окон (iframe) для каждого отчёта и отдельного контроля доступа. Наличие REST API и GraphQL API значительно облегчают эту задачу.
Кривая обучения
Для использования достаточно иметь базовые знания по SQL и базам данным
Проблемы
Работа с несколькими источниками данных
Есть трудности с объединением, например данных из MongoDb и MySQL, для этого требуется написать сложные преагрегации.
Пока что нет поддержки REST API
Например у внешней CRM системы нет прямого доступа к базе данных. Поэтому для анализа потребуется выгрузка в один из поддерживаемых источников данных.
Поддержка
Несмотря на организацию SQL кода, при изменении структуры данных аналитика сломается. Для этого нужен поставленный процесс разработки или умный CI, чтобы изменения в структуре данных не заливались в прод, пока не поправится схема в Cube. Также не хватает инструментов проверки корректности запросов на тестовых данных, чтобы интегрировать это в CI.
Архитектура
CUBE выступает как слой доступа к данным, переводит запросы в SQL, управляет кешированием, очередью и подключением к базе данных.
Файлы схемы данных. Обычные JS файлы, на основании которых генерируется SQL
Сервер на NodeJS. Генерирует и выполняет SQL запросы по схеме, отвечает за кеширование и контроль доступа.
Клиентская библиотека. Выполнение запросов и преобразование данных для отрисовки

Практическая задача
У нас есть данные о звонках, которые совершают сотрудники. Схема данных выглядит следующим образом

CallInfo (Информация о звонке)
type - income, outcome
status - 'success', 'missed', 'busy', 'not_available', 'not_allowed'
incomePhone в формате +799999999
Требуется построить минимальный анализ, сразу напишем SQL запросы
Получить количество пропущенных звонков по сотрудникам
SELECT CONCAT(e.name, e.second_name, e.patronymic) as initials, count(*) FROM calls c LEFT JOIN phone_number pn ON pn.phone = c.income_phone LEFT JOIN employee e ON e.id = pn.employee_id WHERE status = ‘missed’ AND start_date ≥= ‘2022-01-01’ AND start_date ≤= ‘2022-02-01’ GROUP BY initials
Среднюю длительность разговора по сотрудникам
SELECT CONCAT(e.name, e.second_name, e.patronymic) as initials, avg(duration) FROM calls c LEFT JOIN phone_number pn ON pn.phone = c.income_phone LEFT JOIN employee e ON e.id = pn.employee_id WHERE start_date ≥= ‘2022-01-01’ AND start_date ≤= ‘2022-01-01’ GROUP BY initals
Песочница
В Cube есть песочница, с возможностью создания схемы на основании таблиц БД, конструировании и выполнение запросов, визуализацией и генерацией шаблонов фронтенд приложений.
Для тех, кто хочет самостоятельно изучить возможности и посмотреть как это выглядит на практике, я создал репозиторий с данными, схемой и интср.
Схема
Каждый куб определяется в отдельном файле. Отдельный куб отражает определенный набор данных, в SQL это можно достичь с помощью представлений. Внутри каждого куба объявляются измерения (dimensions) и меры (measures)
Определим Куб Информации о звонках
cube(`CallInfo`, { // основной SQL запрос sql: `SELECT * FROM calls`, //меры measures: { count: { type: `count`, }, countMissed: { type: `count`, filters: [ { sql: `status = 'missed'` } ] }, avgDuration: { type: `avg`, sql: `duration` } }, // измерения dimensions: { type: { sql: `call_type`, type: `string` }, incomePhone: { sql: `income_phone`, type: `string` }, outcomePhone: { sql: `outcome_phone`, type: `string` }, status: { sql: `status`, type: `string` }, duration: { sql: `duration`, type: `number` }, startDate: { sql: `start_date`, type: `time` } } })
Воспользуемся песочницей, чтобы сконструировать запрос
Measures - доступные меры
Dimensions - доступные измерения
Segment - доступные сегменты (статические фильтры)
Time - доступные временные измерения. Добавление фильтрации по временному периоду
Filters - доступные фильтры. Добавление фильтрации для данных
Возможность выбрать тип графика
Line - Линейная
Area - с областями
Bar - Столбчатая
Pie - Круговая
Table - таблица (с ним мы и будем работать)
Number - число
Остальные возможности в этом туториале нам не потребуются.

Соединения (joins)
Так как мы анализируем звонки в разрезе сотрудников, нам понадобятся ещё два куба “Сотрудники” и “Номера”
Почему мы не сделали один куб, где запрашивались бы сразу все необходимые данные?
Да, можно было бы написать один куб и ограничится на этом, все зависит от задач.
Мотивация в разделении на отдельные кубы состоит в том, что можно анализировать как отдельные простые сущности, так и строить сложный анализ, где участвуют множество измерений из разных процессов.
В рамках нашей задачи это может выглядеть так
Звонки
Динамика количества входящих звонков по месяцам
Среднее количество пропущенных звонков по месяцам
Сотрудники
Динамика среднего количества уволенных сотрудников по месяцам (при наличии даты найма и статуса в компании в таблице сотрудников)
Номера
Количество телефонных номеров в организации
Комлпексные с измерениями и мерами из нескольких сущностей
Динамика коэффициента соотношения пропущенных звонков к входящим в разрезе сотрудника
Количество звонков на неизвестные номера (запись есть в CallInfo, но нет номера привязанного к сотруднику)
Для того, чтобы соблюдать принцип DRY (Dont Repeat Yourself) мы выносим кусочки SQL кода в отдельные логические единицы (кубы) привязанные к процессу или сущности - это может быть одна таблица, несколько таблиц с JOIN либо сложный UNION.
Типы соединений в CUBE соответствуют типам отношений в SQL
hasMany - один ко многим
belongsTo - много к одному
hasOne - один к одному
Для нашей задачи нам требуется соединение CallInfo → PhoneNumber → Employees
Cube автоматически находит связь между кубами с помощью алгоритма Дейкстры, поэтому не нам не требуется определять связи в каждом кубе.
Определим Куб Сотрудников
cube(`Employee`, { sql: `SELECT * FROM employee`, joins: { PhoneNumber: { // указываем условие соединения, это подставится после ключевого слова ON sql: `${CUBE}.id = ${PhoneNumber}.employee_id`, // 1 сотрудник может иметь несколько номеров relationship: `hasMany` } }, dimensions: { name: { sql: `name`, type: `string` }, secondName: { sql: `second_name`, type: `string` }, patronymic: { sql: `patronymic`, type: `string` }, position: { sql: `position`, type: `string` }, initials: { sql: ` CONCAT(${CUBE.secondName}, ' ', LEFT(${CUBE.name}, 1), '.', LEFT(${CUBE.patronymic},1) )`, // соединяем Фамилию и первые буквы имени и отчества // CUBE - ссылка на текущий куб (таблицу) type: `string` } } })

Определим Куб Номеров
cube(`PhoneNumber`, { sql: `SELECT * FROM phone_number`, joins: { // т.к номер телефона является связующим между звонком и сотрудником, определяем связи с другими кубами CallInfo: { sql: `${CUBE}.phone = ${CallInfo}.income_phone`, relationship: `hasMany` } }, dimensions: { phone: { sql: `phone`, type: `string` } } })
Теперь мы можем выполнить запросы из задачи

Сгенерированный SQL
SELECT CONCAT( `employee`.second_name, ' ', LEFT(`employee`.name, 1), '.', LEFT(`employee`.patronymic, 1) ) `employee__initials`, count( CASE WHEN (status = 'missed') THEN `call_info`.id END ) `call_info__count_missed` FROM employee AS `employee` LEFT JOIN phone_number AS `phone_number` ON `employee`.id = `phone_number`.employee_id LEFT JOIN call_info AS `call_info` ON `phone_number`.phone = `call_info`.income_phone WHERE ( `call_info`.start_date >= TIMESTAMP(convert_tz(?, '+00:00', @ @session.time_zone)) AND `call_info`.start_date <= TIMESTAMP(convert_tz(?, '+00:00', @ @session.time_zone)) ) GROUP BY 1 ORDER BY 2 DESC LIMIT 10000

Сгенерированный SQL
SELECT CONCAT( `employee`.second_name, ' ', LEFT(`employee`.name, 1), '.', LEFT(`employee`.patronymic, 1) ) `employee__initials`, avg(`call_info`.duration) `call_info__avg_duration` FROM employee AS `employee` LEFT JOIN phone_number AS `phone_number` ON `employee`.id = `phone_number`.employee_id LEFT JOIN call_info AS `call_info` ON `phone_number`.phone = `call_info`.income_phone WHERE ( `call_info`.start_date >= TIMESTAMP(convert_tz(?, '+00:00', @ @session.time_zone)) AND `call_info`.start_date <= TIMESTAMP(convert_tz(?, '+00:00', @ @session.time_zone)) ) GROUP BY 1 ORDER BY 2 DESC LIMIT 10000
Итог: как применять в продакшне
Мы определили схему и можем получать данные не только на фронтенде, но и в любом другом сервисе.
Пример запроса к REST API
{ "measures": ["CallInfo.avgDuration"], "dimensions": ["Employees.initials"], "filters": [{ "member": "Employees.id", "operator": "equals", "values": ["1"] }], "timeDimensions": [{ "dimension": "CallInfo.startDate", "dateRange": ['2022-01-01', '2022-01-02'] }], }
Пример ответа
{ ... запрос "data":[ { "CallInfo.avgDuration": 5, "Employees.initials": "Иванов" }, { "CallInfo.avgDuration": 4, "Employees.initials": "Петрова" } ] ... метаданные }
Из личного опыта
На момент написания статьи в ERP системе в схеме данных более 150 таблиц и более 100 кубов для анализа. Написан редактор рабочих столов. Данные используются в разных частях приложения.
Примеры комплексного анализа
Зависимость успешности продажи от количества дней обработки заявки
Процент участия сотрудника в прибыли
Сумма прибыли на вложенный рубль рекламы

Источники
http://www.olap.ru/basic/alpero2i.asp
https://wiki.loginom.ru/articles/
https://cube.dev/docs/introduction/

