
Завтра финал Чемпионата мира по футболу. Самое время для рассказа о футбольных прогнозах.
Если ты интересуешься футболом и умеешь работать с данными, кажется, неизбежно в твоей жизни настанет момент, когда тебе захочется предсказывать результаты любимой команды, а лучше вообще все.
Такой день наступил и в моей жизни. И пусть я больше интересуюсь спортивным "Что? Где? Когда?", футбол - это классно. И это классно и с точки зрения прогнозов - и много данных, и много интересующихся, кому можно показать результаты. Давайте попробуем!
И раз за дело взялись зануды, будет много теорий, ещё больше таблиц и графиков.
Готовы? Вперёд!
Постановка задачи
Построить такую модель, которая на основании данных прошлых игр способна предсказывать результаты (победа-ничья-поражение) футбольных матчей. Ещё неплохо, если можно будет при получении новых данных (в футбол играют каждую неделю) оперативно обновлять прогноз. Чем предсказания точнее, тем лучше.
Как считать, какая модель хорошая, а какая - плохая?
Мы “скармливаем” модели большую часть исторических данных, но часть “оставляем себе”. Для модели - это будущее, которое нужно предсказать. Для нас - такое же прошлое. Появляется очень конкретный инструмент для сравнения: какая модель себя лучше покажет, та и молодец.
Далее в этом тексте мы говорим модели, что на дворе 1 октября 2022 года и просим предсказать результаты всего октября. Чемпионат мира мы не трогаем, а так, получается, самый свежий месяц клубного футбола.
Оценивать будем по трём метрикам.
Первая, очевидная, метрика - это точность прогноза (accuracy). Допустим, мы сделали прогноз на 100 матчей, в 80 наш прогноз сбылся, в 20 - нет. Это значит, что точность прогноза 80% (и это была бы очень крутая точность).
К сожалению, эта метрика не всегда показывает настоящую картину. Например, в игре Реала и Ман сити в этом году можно всегда “предсказывать" победу. Точность будет достаточно высокая (под 90%). Но никакой информации о том, когда и на ком гранды потеряют очки мы таким прогнозом не получим.
Этот недостаток устраняет продвинутая метрика под названием f1, на неё мы будет усиленно ориентироваться. Как она работает и почему, расскажу чуть ниже на примере.
Строгая формула под спойлером

где


А ещё хочется добавить деньги. Ни для кого не секрет, в футболе ставки на исход матчей популярны, так что умельцев (или "умельцев") предсказывать результаты игр достаточно. Неплохо иметь параметр, который позволит как и с ними сравнить. Мы будем использовать метрику ROI (Return Of Investment). Допустим, я поставил по рублю на 100 матчей. В 80 матчей я угадал со средним коэффициентом 1.8, а в 20 - не угадал. Тогда мой доход - это
80 (успешных прогнозов) * 1 (рубль) * 1.8 (коэффициент) + 20 (неуспешных прогнозов) * 1 (рубль) * 0 (я же не угадал) = 144 рубля,
а
ROI = (144 (рубля, доход) - 100 (рублей первоначальных вложений) ) / 100 (рублей первоначальных вложений) = 44%.
Это значит, что а) я “в плюсе”, т.е. заработал больше, чем вложил, б) заработал на 44% больше, чем вложил.
Далее по тексту будем брать ставки известой букмекерской конторы William Hill.
Что дальше?
Я буду последовательно усложнять модель и на каждом этапе смотреть, как она себя показывает по этим трём метрикам.
По идее, с каждым новым этапом должно становиться всё лучше и лучше, но, как вы увидите, в жизни не всё так гладко.
Где брать данные?
Футбол хорош ещё тем, что базовую информацию об истории футбольных матчей можно достать многими способами. Да хоть википедию парсить. Для меня важный фактор - иметь под рукой и историю, и свежие результаты плюс-минус оперативно.
Поэтому я остановился на вот этих людях. Всякие продвинутые вещи типа xG они не дают, но результаты матчей, статистику по игрокам дают и даже бесплатно. Денег хотят только за то, чтобы выдавать информацию быстрее, чем по умолчанию. Котики, нечего сказать.
Что будет в нашем распоржяении?
Данные о примерно 43 тысячах футбольных игр из топ-5 европейских лиг (Англия, Испания, Италия, Германия, Франция) высшего и первого дивизионов, а также еврокубки (Лига Чемпионов, Лига Европы и Лига Конфедераций) с 2012 года по сентябрь 2022.
С помощью этого добра попробуем предсказать результаты 1264 футбольных матчей октября.
Данные по ставкам за текущий сезон 2022/2023 брал вот с этого сайта.
Поехали!
Модель №0. Его Величество случай
Да-да, начинаем с генератора случайных чисел: просто в каждом матче случайно выдаём результат, победа, ничья или поражение. Считаем метрики и смотрим.
Здравый смысл подсказывает, что ничего хорошего из этого не выйдет. Кто-то может зло пошутить, что это будет совпадать со средним результатом “диванных экспертов”. Но я бы на другом заострил внимание. Этот прогноз - простой. Это всегда плюс. И этому прогнозу не требуются вообще никаких данных. Это значит, что любой прогноз на данных должен быть лучше, иначе все сложности просто не имеют смысла. Получается, это не просто нормальный прогноз, а лакмусовая бумажка, которая отделяет какую-то мысль от полностью бесполезного шума.
Итак, что же мы видим?

Точность 25%, т.е. угадали мы исход только четверти игр. Чуть-чуть не повезло. Метрика f1 на уровне 13% (пока просто запомним). Ну и по деньгам мы в большом минусе. Логично, букмекерам надо как-то зарабатывать.
В зависимости от лиги точность генератора случайных варьируется в диапазоне 21%-28%, а ROI можно увидеть в интервале от -37% до -43%. Если вы на своих ставках проигрываете больше - остановитесь.
Модель №1. Хозяева начинают и выигрывают
Ну что, пришло время включить наши данные. Кстати, как вообще они выглядят? Ну такая какая-то таблица

Их можно для начала немного покрутить. Наверное, у вас тоже давно мучают какие-то вопросы?
Например, какой самый популярный счёт?

1-1! Кто бы мог подумать? А вы на 0-0 ставили, небось, а он только на четвёртом месте.
Какая топ-лига самая забивная?

Бундеслига, почти 1.7 забитых за матч! И забивают и пропускают больше. Возможно, АПЛ - самая зрелищная потому, что там разрыв между забитыми и пропущенными небольшой?
Насколько важен фактор своего поля?

То есть 44% всех игр заканчиваются победой хозяев. С учётом того, что почти везде дома и на выезде играется одинаковое количество матчей, фактор своего поля - это что-то серьёзное. А давайт с него и начнём?
Нам надо бахнуть какую-то очень простую модель. Как насчёт модели "всегда предсказываем победу хозяев"? А почему бы и нет.
Посмотрели на данные, обобщили. Всё, теперь просто. Узнаем, кто играет "дома" - ему и победу вручаем.
Что из этого выйдет? Давайте посмотрим на обе модели рядом:

А это рабочая история! Результат лучше случайного на целых 12%! По деньгам, конечно, в минусе. Обращу внимание, что продвинутая метрика выросла не так сильно. Очевидно, этот прогноз немного "хитрый". И дальше его особо никуда не улучшишь.
Ну что, для начала неплохо. Двигаемся дальше.
Модель №2. ЭЛО-рейтинг команд
Рейтинг ЭЛО - достаточно популярная система расчёта рейтинга спортивных результатов. Её любят в шахматах, но и в футболе она активно применяется.
Суть её простая. Если ты играешь лучше, чем ожидалось, твой рейтинг растёт, если хуже - падает. И чем более неожиданный результат, тем масштабнее изменение твоего рейтинга. Например, если Реал проиграет Барселоне, то потеряет максимум 1-2 пункта. А вот если проиграет Мурсии, то расстанется с доброй двадцаткой баллов. Для того, что его рассчитать, нужны только результаты матчей. Отлично!
В такой модели важнее всего разность рейтингов. Чем она у команд больше, тем выше вероятность, что одна победит другую.
Но этот рейтинг и сам по себе интересен.
Вот топ-10 команд на данный момент (декабрь 2022):

У меня возражения вызывает только нахождение в топе ПСЖ. И даже понятно, почему так происходит: команда достаточно сильно выступает в своём чемпионате. И "Барсы" не хватает, но тут система рейтинга не при чём. Давайте посмотрим, что там у Барселоны и сравним её движение с набравшей хороший ход в этом сезоне "Наполи"
 и Наполи (кирпичный) в зависимости от числа игр")
Разошлись буквально в начале текущего сезона.
Кстати, рейтинг, который я расчитал, не совсем “чистый”. В идеальном мире все команды должны начать играть в начале времён с одинаковым рейтингом. А там дальше, кто проиграет, кто выиграет, время всё расставит по местам. В реальной жизни у этого много минусов. Самый главный из которых в том, что рейтинг будет отражать реальную картину мира далеко не сразу.
Поэтому начальный рейтинг зависит от лиги, в которой начинает команда. Английская команда начинает с одного рейтинга, а французская - с рейтинга пониже. И команды низших дивизионов (Сегунда, Чемпионшип и т.п.) тоже получают “штраф” на старте. Чем лучше результаты страны в еврокубках, тем выше начальный рейтинг каждой команды. Команды низших лиг слабее старших ровно на 200 пунктов - примерно столько теряет за сезон аутсайдер высших лиг.
Вот так выглядит динамика рейтинга испанских команд в первом сезоне расчёта рейтинга:
 и первой (Сегунда) дивизионов испанского футбола")
Сначала между дивизионами пропасть. Но потом лучшие Сегунды и худшие Примеры начинают стремительно сближаться и к концу сезона они вполне органично меняются местами.
Выглядит логично.
Давайте теперь посмотрим, как этот рейтинг предсказывает будущее. Снова посмотрим на все модели вместе.

Стало лучше! Выросла и точность и "продвинутая метрика". Это значит, что у этой модели есть какое-то подобие прогнозной силы. И даже по деньгам вышли "в плюс". Безусловно, это не значит, что на этом можно зарабатывать какие-то деньги. Это просто инструмент сравнения с футбольными аналитиками.
Интересно, что лучше всего точность на низших дивизионах, а в высших по деньгам в минусе. Скорее всего это объясняется большей разницей в классе.
Вот такая диаграммка должна помочь понять, как работает прогноз.

Тут хорошо видно, что сложнее всего по текущей модели верно предсказывать ничьи. Надо подумать, что с этим делать.
Модель №3. Рейтинг ЭЛО как компонент более сложной модели
На самом деле, рейтинг ЭЛО - это тупиковый вариант.
По очень простой причине: его никак не получится органично улучшить. Добавить фактор своего поля, погоды или настроения капитана команды. Любые попытки это сделать на уровне формулы ЭЛО приводят к тому, что она разваливается.
Как же быть?
Ну вообще существует очень много алгоритмов, которые пытаются искать закономерности в данных. И умеют работать с разными параметрами.
Попробуем настроить известную модель под названием случайный лес (Random Forest). Она может принять десятки тысяч параметров, но мы ей дадим только прогноз на основе формулы ЭЛО (по сути, предыдущую модель). В идеальном мире, она должна выдать ровно такой же результат. Но на практике будет хорошо, если станет хотя бы не хуже.
Что же мы видим?

Точность выросла, по финансам тоже получше вышло. Но продвинутый показатель стал хуже. Кажется, мы снова начинаем хитрить? Увы, алгоритмы машинного обучения часто этим страдают. Ничего страшного, стало не так уж плохо. Зато у нас появилось пространство для улучшений.
Модель №4. Алгоритм, ЭЛО и простые параметры
Давайте попробуем добавить, кроме самого прогноза ЭЛО то, что просто получить и может быть важно с точки зрения результата.
После некоторого числа экспериментов я остановился на таких вещах:
общее число побед,
общее число поражений,
фактор своего поля (дома или на выезде играем),
в высшем дивизионе играет или нет
Что же выдал алгоритм в этот раз?

Стало, конечно, лучше. Но не такого мы ждали. Правда это "чуть-чуть" пришло равномерно по всем разрезам.
Ещё алгоритмы машинного обучения хороши тем, что они говорят, какой параметр модели какое влияние на итоговый результат оказал. На первом месте с большим отрывом идёт рейтинг.
Модель №5. Подбираем хорошие параметры алгоритма
В двух предыдущих моделях я взял хорошие данные, выбрал логичные признаки, взял нормальный алгоритм, но использовал “какие-то” параметры этого алгоритма. А Random forest вообще гибкая штука. Можно попытаться “выжать” из модели чуть больше, если попотеть.
Обычно это даёт 1-2% улучшений, но здорово грузит систему. Как будет в этот раз?

Совсем чуть-чуть потеряли по точности, зато f1 сейчас лучший, чем когда-либо был у нас. Просто замечательно.
Интересно, прогноз каких игр изменился?

Судя по всему, встреча противоположных тенденций и поведение на границе понятности.
Модель №6. Личные встречи
Попробуем обогатить данные какими-то нашими представлениями о спорте или футболе, которые помогут повысить точность прогноза.
Нанчём с гипотезы “неудобного противника”. Это когда есть какой-то гранд, который выигрывает всех, но есть у него один враг, с которым ему всегда традиционно сложно.
На языке чисел эта гипотеза звучит так: статистика личных встреч команд может дать больше информации, чем простой рейтинг.
Вот так выглядят таблицы личных встреч в топ-лигах:




Чем зеленее, тем более приятный результат для команд, названия, которых расположены на вертикальной оси.
Тут мы видим, что, например, самым неудобным соперником для мадридскогго Реала является… Барселона. Кто бы мог подумать? Но это мы и из рейтинга увидим. А вот то, что у Реала нулевая история личных встреч с командой Кадис (19-е место в текущем чемпионате) - это как раз оно, андалузцы - неудобный соперник Галактикос. Пока.
ПСЖ не имеет конкурентов в своей лиге, но лучше всего статистика у Осера, всего лишь -1.
Ну что, давайте добавим этот параметр в модель и посмотрим, что выйдет?
Добавили, покрутили параметры модели. Итог - честно заработанное улучшение в 2% на экспертизе. Так оно, чаще всего и работает. А вы любите как в кино, чтобы фейерверки и крутые открытия?
А Манчестер Сити имеет просто неприличную статистику личных встреч с Ливерпулем. Кажется, Клопп что-то знает.
Наполи идёт хорошо, но с фаворитами играть будет сложно: отрицательня история как с Юве, так и с Интером. А Торино по каким-то причинам неудобный соперник для Аталанты.
Ну что, давайте добавим этот параметр в модель и посмотрим, что выйдет? Сначала посмотрим пару матчей:
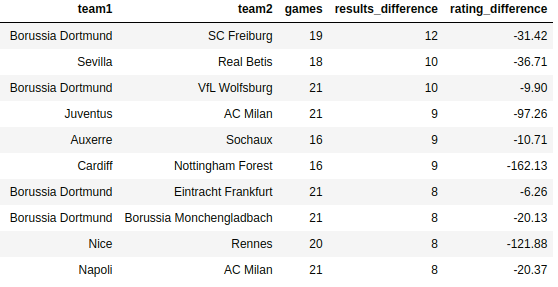
Андалузское дерби - что-то печальное. Бетис сильнее с другими противниками, зато Севилья в 18 последних играх имеет результат +10 с принципиальным соперником. Ничего себе!
Ювентус растерял рейтинга, это понятно, но с Миланом долго ещё будет иметь комофртный плюс.
Кардиф - Форест - рекорд по разнице. Рейтинг уверенно ставит на англичан, а история личных встреч - на валлийцев.
А теперь всей выборке:

Точность стала хуже, зато бьём рекорды по продвинутой метрике. Это обнадёживает. Кстати, эта модель считает, что личные встречи даже важнее, чем рейтинг. Ну что же.
Самое главное, что "проблему ничьих" так и не решили
Модель №7. Статистика матча
Кроме самих результатов, можно попробовать использовать более подробную статистику, которую представляют почти во всех современных лигах: число ударов в створ, доля владения мячом, число фолов, офсайдов и т.д.
Идея хорошая. Чем больше данных - тем больше сигнала из них можно извлечь. В теории. К сожалению, эта же теория говорит, что если просто запихнуть в модель много-много чисел, они скорее дадут шум и модель переобучится - при формально росте показателей потеряет свою предсказательную способность.
Так что прежде чем грузить модель, посмотрим на данные. Как в топ лигах распределены значения ключевых показателей статистики?



И, самое главное, как они связаны между собой и числом забитых и пропущенных мячей?

Никак.
Зависимость называется "крайне редко голов больше, чем ударов по воротам". Всё.
Увы, все эти параметры - достаточно слабый сигнал.
Но есть более серьёзная проблема. В отличие от истории личных встреч или рейтинга, нам неизвестно ДО игры, сколько раз Бензема залезет в офсайд, а сколько - пробьёт в створ ворот.
Тем не менее попробуем обогатить модель этими данным. Вдруг полпроцента выжмем? Модели будем показывать среднее значение показателей за последние 8 матчей (достаточно, чтобы встреча с нетипичной командой не исказило статистику, но и сезон ждать изменения в стиле игры тоже не нужно).
Что же получилось?

Стало хуже. Модель начала искать закономрености там, где их нет, переобучилась и на неизвестных себе данныхз дала худшие прогнозы. Так бывает. Отбрасываем, двигаемся дальше.
Модель №9. Персональные показатели
Кроме командной статистики есть ещё и индивидуальная. Её много, разной, вполне себе можно достать. Но надо как-то понять, как свести её в формат, который будет не так шуметь.
И тут можно использовать футбольных экспертов. Они выставляют игрокам оценки после игры на основе ТТД игроков. Кажется, именно эта оценка - отличное обобщение, которое нам ценнее, чем показатели сами по себе.
Снова посмотрим, как выглядит распредление оценок и как оно связано с результатом игры?

Вот такие оценки ставят. Чем выше столбик, тем чаще оценка встречается. Можно обобщить, что те игроки, которым матч "зашёл" получают что-то около 6,5, а тем, кто "не зашёл" - около 4,6.
И, похоже, результат команды влияет на оценки специалистов. Или наоборот? Хорошие оценки приводят к хорошим результатам?

Короче, норм тема, надо пробовать. Логика та же - подаём модели среднее значение за 8 последних игр.
Что же выйдет?

Это лучше статистики матча. Но всё равно хуже, чем без новой информации. Грустно. Ничьи, правда, чуть лучше описывает. Не очень понятно почему. Держим в уме, но двигаемся дальше.
Модель №10. Ожидаемое поведение по статистике
Давайте пробовать бить по слабой точки прогноза: модели очень сложно разобраться с ничьей.
Попробуем такую гипотезу.
Представим себе, что матч закончился 0-0. Но одна команда много держала мяч, создавала моменты, била по воротам. Другая - пыталась отбиться. Результат - счёт на табло, вопросов нет. Но скажите мне: какова вероятность, что эти команды наберут очки в следующем матче? Кажется, что та команда, которая много и хорошо играла, но "недодавила" в этом матче, вполне может додавить в следующем.
Можно было бы просто добавить xG в модель. Но нормальные данные по этой характеристике получить на данный момент сложно. Поэтому мы сконструируем свой примитивный показатель: к счёту на табло будет добавлять ещё один мяч одной из команд. Та, которая чаще бьёт в створ, чаще просто бьёт или чаще владеет мячом. Если все эти показатели равны, шут с вами, не добавляем ничего. На полученных результатах строим ещё один рейтинг. И вот его передаём модели в качестве прогноза. Какого, а?
Получили новые данные - посмотрим на них.
 и \"видоизменённого\" (кирпичная линия) рейтинга для команды Рома")
И аналогичная картина для мадридского Реала.
 и \"видоизменённого\" (кирпичная линия) рейтинга для команды Реал (Мадрид)")
Ну что, смотрим что выйдет на данных?

Итог: новая модель практически не испортила лучшую.
Да, ожидался немного не такой вариант.
А насколько это вообще всё плохо?
Сложно сказать.
Вот есть такой лидерборд. Там люди, конечно, азартные. Есть, например, человек, у которого точность 39% и ROI +9%). Но, в целом, ROI 20% выглядит вполне достойным топ-20.
А вот как раз экспертный рейтинг за октябрь-2022. Судя по числам, тут люди что-то понимают. Но всё равно для топ-20 достаточно просто быть в плюсе. А лучшая модель вполне уверенно борется за топ-5.
Модель № N+1
На этом стоит пока остановится. Хотя обидно не получить 50% точности, кажется, что это вполне возможно.
Есть ощущение, что все рассматриваемые модели смотрят на одни и те же вещи, просто под разными углами. Поэтому и результат близкий. Для того, чтобы увеличить точность, требуются гипотезы, с помощью которых можно лучше проникнуть в суть того, что происходит на поле.
Пока что в шорт-листе следующие гипотезы.
Индивидуальный рейтинг игроков и корректировки на состав. Если суперзвезда не вышла на поле, прогноз команды понижается. Тут должен быть какой-то фактор сыгранности. И не иметь возможность делать прогноз до тех пор, пока составы не станут доступы - неприятное ограничение.
Сброс рейтинга при изменении стиля игры. Новые игроки, новый тренер, команда просто начала играть по-другому. По-хорошему, это уже другая команда, рейтинг прошлой инкарнации использовать нехорошо. Но как определять этот момент? И насколько сильно, простите, обнулять?
Определение стиля игры команды. И определения того, как команды разных стилей играют между собой. Условно, команда со ставкой на владением мячом, хорошо вскрывает "автобус", но проигрывает команде, специализирующейся на контратаках.
Использовать другие алгоритмы машинного обучения. В том числе менее требовательные к числу параметров, чтобы можно было попробовать найти какие-то закономерности на большом количестве параметров.
Весь код доступен. Буду рад новым гипотезам и предложениям.
Больше упоротой аналитики, смелых моделей и разных визуализаций на разные темы в моём блоге. Всегда рад обратной связи, новым гипотезам и предложениям о том, чего б ещё покрутить.

