

Привет! Меня зовут Максим Бабенко, я руковожу отделом технологий распределённых вычислений в Яндексе. Сегодня мы выложили в опенсорс платформу YTsaurus — одну из основных инфраструктурных BigData-систем, разработанных в Яндексе.
YTsaurus — результат почти десятилетнего труда, которым нам хочется поделиться с миром. В этой статье мы расскажем историю возникновения YT, ответим на вопрос, зачем нужен YTsaurus, опишем ключевые возможности системы и обозначим область её применения.
В Github-репозитории находится серверный код YTsaurus, инфраструктура развёртывания с использованием k8s, а также веб-интерфейс системы и клиентский SDK для распространённых языков программирования — C++, Java, Go и Python. Всё это — под лицензией Apache 2.0, что позволяет всем желающим загрузить его на свои серверы, а также дорабатывать его под свои нужды.
Как YT стал основной big-data системой Яндекса

История берёт своё начало в 2006 году, когда Яндекс стал уже достаточно большим. Вопрос, где хранить и как обрабатывать имеющиеся в компании данные, уже не был таким уж простым. В то время речь шла про логи множества сервисов, а их обработка предполагала разнообразную аналитику, которая позволяла бы решать широкий спектр задач от улучшения моделей машинного обучения до анализа поведения пользователей при функциональных или интерфейсных изменениях в сервисах.
В воздухе уже витала идея масштабируемого эластичного хранилища данных, поверх которого можно было бы выполнять параллельные вычисления, не задумываясь о физическом расположении данных и отказоустойчивости физических составляющих кластера.
В 2004 году вышла статья MapReduce: Simplified Data Processing on Large Clusters, которую написали Джеффри Дин и Санджай Гемават из Google. Она во многом предопределила развитие отрасли распределённых вычислений на десятилетие вперёд. Неудивительно, что подобная реализация парадигмы MapReduce появилась и в Яндексе. Она называлась YAMR — Yet Another MapReduce.
YAMR создали с нуля в кратчайшие сроки и она, безусловно, оказала колоссальное влияние на развитие внутренней инфраструктуры компании. Но со временем пришло понимание, что многие из первоначально заложенных в неё дизайн-решений не позволяли системе эффективно развиваться. Например, мастер-сервер YAMR был единой точкой отказа и не масштабировался.

Со стороны может показаться, что решение развивать собственную инфраструктуру — это типичное проявление NIH-синдрома, а вариант использования готового коробочного решения в виде Apache Hadoop даже не рассматривался. Но это неправда. В сентябре 2015 года группа инженеров Яндекса даже отправилась в Калифорнию, чтобы на месте познакомиться с теми, кто использовал стек Hadoop в продакшене. На встречах задавались вопросы про ограничения, особенности эксплуатации и то, как Hadoop предположительно будет развиваться.
Но тут стало понятно, что стек Hadoop значительно отстаёт даже по сравнению с YAMR, который уже поддерживал erasure-кодирование и умел в ipv6-связность. Эти аспекты, естественно, были далеко не единственными: более подробно мы разбирали аргументы за и против использования Hadoop в одной из предыдущих статей.
По итогам анализа мы отказались от идеи взять Hadoop. Одновременно между вариантами эволюционно развивать YAMR и революционно написать новую систему был сделан выбор в пользу второго решения. Тем более, определённые предпосылки для этого уже были: ещё в 2010 году небольшая группа энтузиастов, в которой мне посчастливилось оказаться, начала работать над проектом с кодовым названием YT. При должной доработке у него были все шансы заменить YAMR.
Важно понимать, что заменить YAMR одномоментно не было никакой возможности: в пике своего развития эта система управляла кластерами, суммарно насчитывающими тысячи узлов, а поверх YAMR API было написано большое количество прикладного кода. Поэтому процесс доработки YT и миграции на него с YAMR растянулся на многие годы. Детали этой истории интересны сами по себе и, вероятно, заслуживают отдельного рассказа.
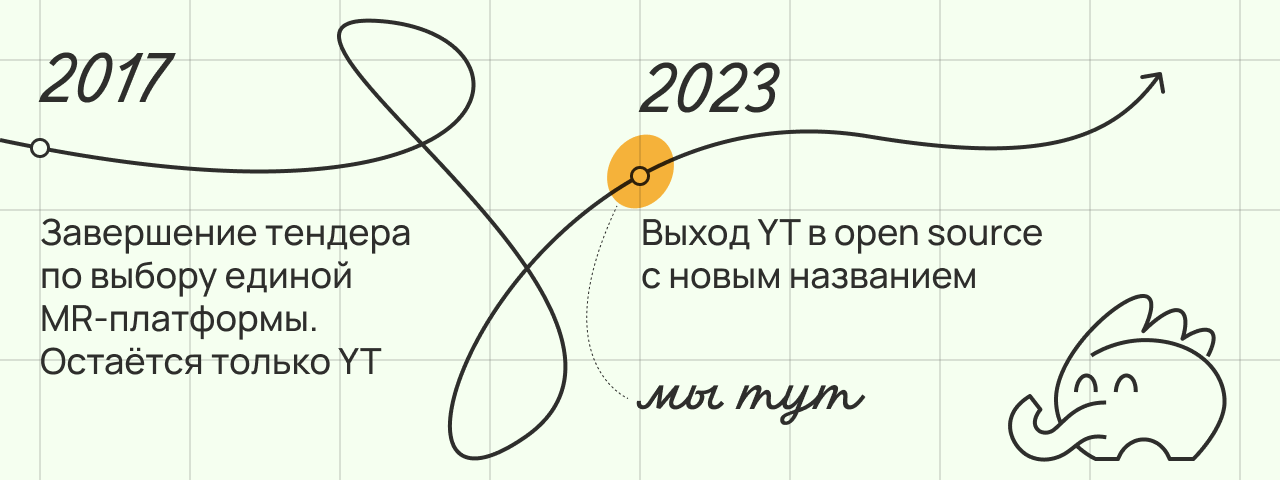
С 2017 в Яндексе осталась единственная MapReduce-система, развитие которой, как в терминах масштаба, так и возможностей, продолжается по сей день. Сегодня в компании есть несколько кластеров YT, которые варьируются по размеру от единиц до десятков тысяч серверов. Самые большие инсталляции хранят в сумме эксабайты данных, используют милллионы ядер CPU и тысячи карточек GPU для вычислений в режиме 24/7.

Откуда взялся «Уайтизавр»
Когда мы выпустили первую статью про систему YT, в комментариях появился вопрос пользователя @Iora:
Кстати, вопрос к автору: YT не будет Open Source?
Отвечаем на него спустя почти 7 лет: YT не будет, а вот YTsaurus — да!
Система, которую мы изначально разрабатывали, называлась YT. Эту же аббревиатуру можно увидеть во многих частях кодовой базы. В Яндексе ходят слухи, что аббревиатура YT задумывалась как сокращение от Yandex Table — возможно, по аналогии с известной системой Big Table компании Google, но надёжных свидетельств, подтверждающих подобное, обнаружить не удалось.
При выходе в опенсорс оказалось сложно сохранить название в первоначальном виде. И дело здесь даже не в том, что это двухбуквенное сочетание с большой долей вероятности ассоциируется с одной из популярных платформ видеохостинга: в названиях продуктов у коротких имен мало шансов оказаться свободными.
Так или иначе, мы сошлись на названии YTsaurus. В нём присутствует знакомый и близкий нам префикс YT. Кроме того, наша команда всегда относилась к проекту как в живому существу, и теперь мы точно знаем, какова его порода.
В кодовой базе и в наших текстах мы будем часто сокращать YTsaurus до YT. Мы сами ещё привыкаем к полному имени :)
Возможности системы
Мы проектировали систему так, чтобы она была гибкой и расширяемой, и на текущий момент её возможности не исчерпываются MapReduce в классическом понимании этой технологии. В этом разделе я опишу основные технические возможности, доступные в opensource версии YTsaurus от низкоуровневого стораджа до высокоуровневых compute-примитивов.
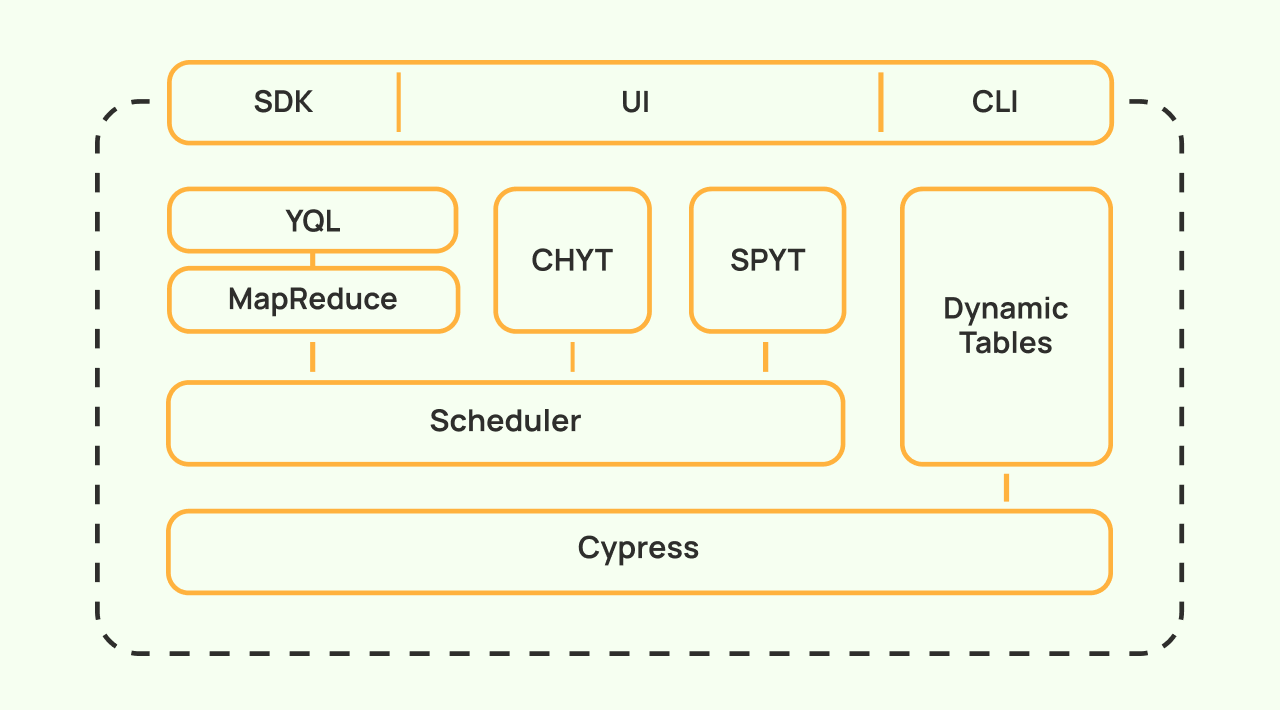
Cypress — надёжное и эффективное хранение данных
В основе любой BigData-системы находится хранилище разнообразных логов, статистики, индексов и прочих структурированных или неструктурированных данных. YTsaurus построен поверх Cypress (или Кипариса) — отказоустойчивого древовидного стораджа, возможности которого тезисно можно описать следующим образом:
древовидный namespace, узлами которого являются директории, таблицы (структурированные или полуструктурированные данные) и файлы (неструктурированные данные);
прозрачное шардирование больших табличных данных на чанки, которое позволяет работать с таблицей, как единой сущностью, не думая о деталях её хранения;
поддержка колоночного и строчного механизмов хранения табличных данных;
поддержка сжатого хранения с использованием различных кодеков кодирования — например, lz4 и zstd с варьируемым уровнем сжатия;
поддержка erasure-кодирования с использованием разнообразных стратегий подсчёта контрольных сумм, обладающих разными параметрами избыточности и допустимых видов потерь;
выразительная схематизация данных с поддержкой иерархических типов и признаков сортированности данных;
фоновые репликация и починка erasure-данных, не требующие никаких ручных действий;
транзакционная семантика с поддержкой вложенных транзакций и блокировок уровней snapshot/shared/exclusive;
транзакции, которые могут затрагивать много объектов Кипариса и длиться неограниченно долго;
гибкая система аккаунтинга места.
Основа Кипариса — реплицированный и горизонтально-масштабируемый мастер-сервер, который хранит метаинформацию об устройстве дерева Кипариса, а также о составе и местоположении реплик чанков всех таблиц на кластере. Мастер-серверы представляют собой Replicated State Machine, реализованную поверх технологии Hydra — in-house версии алгоритма консенсуса, схожей с Raft.
Кипарис реализует отказоустойчивый эластичный data layer, который используется практически во всех слоях системы, о которых пойдёт речь дальше.
MapReduce-вычисления и планировщик общего назначения
Несмотря на то что технологию MapReduce уже давно нельзя назвать чем-то новым и необычным, её реализация в нашей системе определённо заслуживает внимания. Мы до сих пор используем её для вычислений, обрабатывающих петабайты данных и требующих большой throughput.
MapReduce в YTsaurus обладает следующими отличительными чертами:
богатая модель базовых операций: классический MapReduce (с разными стратегиями shuffle и поддержкой многофазного партиционирования), Map, Erase, Sort, и разнообразные расширения модели с учётом сортированности входных данных;
горизонтальная масштабируемость вычислительных операций: операции дробятся на джобы, которые работают на отдельных серверах;
поддержка до сотен тысяч джобов в одной операции;
гибкая модель иерархических вычислительных пулов с мгновенными и интегральными гарантиями, а также fair-share распределением недоутилизированных ресурсов между потребителями без гарантий;
векторная модель ресурсов, позволяющая заказывать различные вычислительные ресурсы (CPU, RAM, GPU) в разных пропорциях;
запуск джобов на вычислительных узлах в контейнерах, изолированных друг от друга по CPU, RAM, файловой системе и process namespace с использованием механизма контейнеризации Porto;
масштабирующийся планировщик, способный обслуживать кластеры с миллионом одновременно исполняемых задач;
сохранение практически всего прогресса вычислений при обновлениях или выходе отдельных узлов планировщика из строя
Отдельно отметим возможность запускать не только MapReduce-джобы, но и свой сервис внутри YT-операции с помощью «ванильных» (Vanilla) операций. Мы используем эту возможность для ряда других компонентов нашей платформы, о чём расскажу дальше.
Динамические таблицы k-v storage
Парадигма MapReduce практически непригодна для построения интерактивных пайплайнов вычисления с субсекундным временем отклика. Дело не только в самом способе обработки данных — хранилище здесь играет не менее важную роль.
Статические таблицы YT, также как набор файлов в HDFS, вполне могут быть входами и выходами MapReduce-вычислений, но они не способны использоваться в интерактивном сценарии из-за привязки к медленному персистентному носителю. Для интерактивных сценариев в индустрии чаще всего используются хранилища key-value. Они способны масштабироваться горизонтально и при этом обеспечивать низкую латентность доступа на чтение и запись.
К счастью, ещё в 2014 году в рамках YT мы начали работу над динамическими таблицами. Отчасти они построены по модели Apache HBase. Они масштабируются горизонтально и используют нашу распределённую файловую систему в качестве нижележащего хранилища. Но в отличие от Apache HBase динамические таблицы органично вписаны в общую экосистему: они представляют собой узлы Кипариса и их можно использовать во многих сценариях, где ожидаются статические таблицы.
Приведу пример: в YT можно сформировать динамическую таблицу в качестве результата MapReduce-операции и использовать её для быстрого поиска и вставки по ключу. В то же время можно построить фоновый MapReduce-процесс, который будет обрабатывать слепок данных в динамической таблице, чтобы вычислять по ней какую-либо статистику.
Ключевые особенности динамических таблиц:
хранение данных в модели MVCC, позволяющее читать значения по ключу и таймстемпу;
масштабируемость: динамическая таблица делится на таблеты (шарды по диапазонам ключей), которые обслуживаются отдельными серверами;
транзакционность: динамические таблицы — это OLTP-хранилища, позволяющие модифицировать в одной транзакции множество строк из разных таблетов различных таблиц;
отказоустойчивость: выход отдельного узла, обслуживающего таблет, приводит к тому, что этот таблет переезжает на другой узел без потери данных;
изоляция: узлы, обслуживающие таблеты, группируются в бандлы, живущие на отдельных серверах, за счет чего обеспечивается изоляция нагрузки;
проверка конфликтов на уровне отдельных ключей или даже отдельных значений;
возможность ответа из RAM для горячих данных;
встроенный SQL-like язык для сканирующих аналитических запросов.
Помимо динамических таблиц с интерфейсом k-v storage, в системе есть поддержка динамических таблиц, реализующих абстракцию очереди сообщений — а именно топика и потока. Эти очереди также можно считать таблицами, потому что они состоят из строк и обладают собственной схемой. В одной транзакции можно одновременно изменять строки в k-v динамической таблице, а также в очереди. Это позволяет строить потоковую обработку данных поверх динамических таблиц YT с семантикой exactly-once.
YQL
Первым высокоуровневым примитивом поверх YT выступил YQL — язык запросов, основанный на SQL-синтаксисе. YQL занимает по отношению к YT примерно такое же положение, как Hive по отношению к Hadoop. Это технология позволяет пользователям писать простые запросы, вместо того, чтобы выражать эту логику кодом на одном из языков программирования, который будет запускать одну или несколько MapReduce операций. Вот пример такого запроса:
SELECT
region,
AVG(age) AS avg_age_in_region,
COUNT(DISTINCT ip) AS ips_count
FROM //home/production/users
GROUP BY region
ORDER BY avg_age_in_region;Без подобного компонента наша экосистема была бы неполной, ведь очень многие задачи из области BigData можно лаконично сформулировать в виде SQL-запроса. YQL — один из самых популярных инструментов как у аналитиков, производящих ad-hoc-расчёты поверх больших данных в YT, так и для регулярных продакшн-расчётов.
К преимуществам YQL можно отнести:
мощный графовый движок исполнения, который строит MapReduce-пайплайны из сотен узлов и может адаптивно перестраиваться по ходу вычисления;
возможность построения сложного пайплайна обработки данных на SQL с сохранением подзапросов в переменные в виде цепочек зависимых запросов и транзакций;
стабильное параллельное исполнение запросов произвольной сложности;
эффективная реализация джойнов, подзапросов и оконных функций без ограничений на их топологию и вложенность;
богатая библиотека встроенных функций;
поддержка пользовательских функций на C++, Python и JavaScript;
автоматическое исполнение небольших частей запросов на заранее подготовленных вычислительных инстансах в обход MapReduce-операций для уменьшения latency.
CHYT
Думаю, почти все читатели этой статьи слышали о ClickHouse. В 2016 году эта СУБД стала первопроходцем среди технологий Яндекса в open source и оказалась настолько успешной, что в 2021 году отделилась в самостоятельную компанию ClickHouse inc.
На сегодняшний день ClickHouse — одна из популярнейших аналитических баз данных с невероятно эффективным колоночным движком исполнения и множеством интеграций с BI-системами. К приятным особенностям ClickHouse можно отнести хорошее разделение storage- и compute-частей в исходном коде, что позволило нам в 2018 году построить CHYT — интеграцию вычислительного движка ClickHouse с YTsaurus в качестве стораджа.
В нашей экосистеме CHYT отвечает:
за быстрые аналитические запросы поверх статических таблиц в YT с субсекундным latency;
переиспользование уже имеющихся данных в кластере YTsaurus без необходимости копировать их в отдельный кластер ClickHouse;
возможность интеграции через родные ODBC- и JDBC-драйверы ClickHouse, например, со сторонними системами визуализации.
Отмечу, что интеграция произведена на довольно низком уровне. Это позволяет нам выжимать максимум возможностей как из YTsaurus, так из ClickHouse. В данной интеграции реализованы:
поддержка чтения как статических, так и динамических таблиц;
частичная поддержка транзакционной модели YTsaurus;
поддержка распределённых вставок;
CPU-efficient-преобразование колоночных данных из внутреннего формата YTsaurus в in-memory представление ClickHouse;
агрессивное кэширование данных, позволяющее в ряде случаев читать данные для исполнения запросов исключительно из памяти инстансов.
Отмечу, что серверный код ClickHouse запускается в вышеупомянутых ванильных операциях, используя те же вычислительные ресурсы, что и MapReduce-вычисления. В этом смысле кластер YTsaurus выступает compute-облаком по отношению к запущенным в нём кластерам CHYT. Это позволяет разным пользователям запустить на одном кластере YT несколько кластеров CHYT, которые будут абсолютно изолированы друг от друга, и решить тем самым задачу разделения ресурсов в облачном стиле.
SPYT
В 2019 году вышел в свет продукт SPYT, интегрирующий Apache Spark в качестве compute-движка поверх данных в YT. Как и в случае CHYT, в качестве вычислительных ресурсов под кластер Spark используются ванильные операции YTsaurus. Apache Spark изначально спроектирован таким образом, чтобы к нему можно было достаточно просто подключить стороннее хранилище в качестве источника данных.
SPYT также уверенно занял нишу в экосистеме YTsaurus. Это один из основных способов написания ETL-процессов благодаря богатым возможностям интеграции со сторонними системами. Под капотом у Spark используется гибкий оптимизатор распределённых вычислений, который по максимуму использует in-memory-хранение для промежуточных данных, и в состоянии реализовывать пайплайны вычислений с разнообразными джойнами.
Различные SDK
Часто SDK к системе на конкретном языке генерируется автоматически или написано кем-то из сообщества пользователей и давно не поддерживается. В нашем случае все API на популярных языках (С++, Python, Java, Go) мы разрабатываем сами, поэтому в них учтены и продуманы все тонкости взаимодействия с системой.
Наши клиенты, написанные на разных языках, умеют ретраить запросы, в том числе они могут записать или прочитать большой объём данных несмотря на возможные сетевые сбои и другие ошибки. При их создании мы учитывали особенности языков и использовали их для того, чтобы сделать взаимодействие с системой максимально удобным и простым.
Веб-интерфейс
Удобный веб-интерфейс — это обязательная черта для системы, которой ежедневно пользуются тысячи пользователей, включая нашу команду. Более того, мы сознательно не стали строить отдельные веб-интерфейсы для пользователей и администраторов. Это избавило нас от частой ситуации, когда администраторский веб-интерфейс создаётся на коленке силами энтузиастов: пользовательская сторона ведь важнее, а перед администраторами можно не стесняться :)
Что можно делать через веб-интерфейс YTsaurus:
перемещаться по Кипарису и просматривать данные;
производить операции с таблицами, папками и файлами;
запускать и просматривать MapReduce-вычисления;
запускать и просматривать историю SQL-запросов во всех вычислительных движках — в YQL, CHYT, SQL динамических таблиц;
администрировать систему: следить за состоянием компонентов кластера, заводить, удалять и банить пользователей, управлять правами доступа и квотами, просматривать версии компонентов кластера и многое другое.
Техническая сторона YTsaurus
Подавляющая часть серверного кода написана на языке C++ — мы любим этот язык за богатую функциональность и возможность писать эффективный код. Надеемся, что после выхода YTsaurus в opensource мы сможем поделиться большим количеством наработок, которые могут быть полезны как отдельные C++-примитивы.
Серверный код собирается с помощью компилятора clang и системы сборки cmake.
Отдельные части системы написаны на Go, Python и Java. Также есть API для разработки приложений, работающих с YTsaurus, на упомянутых выше четырёх языках программирования.
Кодовая база автоматизировано синхронизируется с внутренним репозиторием. Таким образом, снаружи постоянно доступна свежая версия YTsaurus.
YTsaurus работает под x86-64 linux.
Развёртывание и администрирование
Внутри Яндекса у YTsaurus более 20 инсталляций. Все они очень разные по размеру и конфигурации: от 5 до 20K+ хостов в одном кластере. Также YTsaurus интегрирован с рядом внутренних систем Яндекса: аутентификацией, выдачей и аудитом доступов, мониторингами, управлением железом и оркестрацией контейнеров. Все эти системы позволяют нам управлять кластерами с минимальными усилиями.
Для удобства пользователей мы решили вложиться в разработку своего оператора второго уровня для автоматического развёртывания кластера YTsaurus в Kubernetes с поддержкой стандартной механики обновления на новую версию с даунтаймом. Оператор позволяет за несколько минут развернуть свой кластер YTsaurus на локальной машине в minikube, публичном облаке или собственной on-premise инсталляции Kubernetes.
Конфигурацией кластера можно управлять на лету с помощью изменения системных узлов в дереве метаданных (Кипарис). С помощью базовых команд работы с Кипарисом list, get, set и remove можно создать аккаунт, завести пользователя или вычислительный пул, выдать доступ к каталогу или декоммисовать ноды кластера.
Ещё хочется отметить возможность динамической конфигурации отдельных компонент: изменяя специальные атрибуты, можно регулировать, например, размеры кэшей, период хартбитов или настройки логирования на нодах.
YTsaurus — это вычислительная платформа и она подразумевает запуск произвольного пользовательского кода. Для исполнения и изоляции недоверенного кода YTsaurus использует разработанную в Яндексе систему контейнеризации Porto. Рекомендую установить её в качестве kubernetes CRI. Это откроет весь спектр возможностей YTsaurus по изоляции джобов и использованию кастомного окружения в различных операциях.
И конечно же, эксплуатация большой распределённой системы невозможна без инструментов observability — логирования, количественного мониторинга и трейсинга. YTsaurus пишет структурированные логи для аудита и мониторинга пользовательских действий, а также подробные отладочные логи, предназначенные для детальной диагностики проблем. Кроме того, система поддерживает экспорт метрик в формате Prometheus и поставку трейсов по протоколу Jaeger gRPC.
Что можно построить поверх YTsaurus
Раскроем несколько юзкейсов, как используется наша система в Яндексе.
Один из наиболее показательных и типовых сценариев использования YTsaurus — построение DWH. Например, заказы Такси, Еды, Лавки и Доставки поступают в динамические таблицы YTsaurus в сыром виде с минимальной задержкой. Объём данных измеряется сотнями ТБ ежемесячно.
Затем заказы обрабатываются разными инструментами: например, большинство аналитических витрин подготавливается при помощи YQL и SPYT. Общий объём данных превышает 6 ПБ. При помощи CHYT выполняется ad-hoc-аналитика и строятся разнообразные визуализации в Yandex DataLens. Похожие кейсы есть и у других сервисов Яндекса: Маркета, Музыки, Путешествий.
Есть и довольно специфические юзкейсы. Например, все три суперкомпьютера Яндекса управляются планировщиком YTsaurus. Множество узлов с разными типами GPU подключены к YT и распределены между разными деревьями пулов. Это позволяет пользователям явно указывать необходимую модель GPU и при этом использовать данные, которые лежат в YTsaurus.
Сейчас динамические таблицы YTsaurus хранят петабайты данных, а поверх них строится большое количество интерактивных сервисов. Один из крупнейших внутренних клиентов — команда Рекламы. На HighLoad++ 2022 коллеги рассказали о своём подходе к построению интерактивного stream-процессинга поверх YTsaurus.
Вместо заключения
YTsaurus — большой проект с богатой историей. Мы приглашаем всех желающих найти в нём что-то полезное для себя: например, технические решения, которые нам удалось воплотить в коде, или возможность развернуть инсталляцию YTsaurus и попробовать его в деле.
Будет здорово, если вы заинтересуетесь и захотите нам помочь в развитии системы. Приходите к нам с фидбеком в русскоязычный телеграм-чат или в его global-версию, а ещё лучше — с пул-реквестами.
