
В начале 2020 года я только начинал разрабатывать HTML-игры, и коллега посоветовал выложить что-нибудь на Яндекс Играх — эта площадка недавно открылась. Первым делом нужно было подключиться к SDK Яндекса. Я разрабатываю игры на Construct. Он поддерживает JavaScript, так что я написал небольшой фрагмент кода, который позволял получать игроков и показывать рекламу, и подключиться к SDK. Потом добавил добавил поддержку Яндекс Метрики, просмотр видео за вознаграждение, и постепенно собралась маленькая библиотечка. Тогда я еще не предполагал, что за полтора года эта идея вырастет в целый сервис-посредник для интеграции с разными игровыми площадками. Под катом расскажу, как так получилось, и что под капотом у этой разработки.
class YandexSDK { constructor () { this.ready = new Promise(resolve => this.init = resolve); } setSDK (ysdk) { this.ysdk = ysdk; } showFullscreen () { this.ready.then(() => this.ysdk.adv.showFullscreenAdv({callbacks:{}})); } } const Yandex = new YandexSDK(); (function(d) { var t = d.getElementsByTagName('script')[0]; var s = d.createElement('script'); s.src = 'https://yandex.ru/games/sdk/v2'; s.async = true; t.parentNode.insertBefore(s, t); s.onload = initSDK; })(document); function initSDK () { YaGames.init({ adv: { onAdvClose: wasShown => console.info('adv closed! was shown: ', wasShown) }, screen: { fullscreen: true, orientation: { value: 'portrait', lock: true } } }).then(ysdk => { Yandex.setSDK(ysdk); Yandex.init(); }); }
Тот самый первый скрипт для работы с Яндекс SDK
Сперва я просто делился библиотекой с друзьями и знакомыми, разрабатывающими в Construct — давал им готовый скрипт, который подключал игру к Яндекс Играм. Но в Construct с JS работать не очень удобно, и я решил переписать все в формате плагина, — чтобы можно было добавлять нужные функции с помощью визуального программирования.

Собрал прототип за три дня и выложил в открытый доступ, чтобы им могли пользоваться все желающие. Он до сих пор висит в списке плагинов Яндекса. Возможно, им кто-то еще пользуется, хотя обновлений давно не было.
Функций плагина хватало для простых проектов, но потом я увлекся разработкой игры-филворда и решил, что в ней просто необходим рейтинг игроков. В Яндекс Играх тогда не было собсвенных лидербордов, так что я написал сервер на NodeJS, подключил MongoDB как базу данных, и стал складывать туда рекорды игроков. Опять же, все это завернул в плагин для Construct и благополучно о нем забыл, потому что переключился на другой проект.

Следующей игрой была несложная карточная стратегия. В Яндекс Играх она вряд ли хорошо бы зашла — не та аудитория, так что я направился в VK. Делать такой же плагин как для Яндекс совсем не хотелось. Тогда и появилась мысль, что нужен универсальный плагин, который будет править всеми проверять, на какой площадке игра, и подключать местный SDK. Это должен был быть посредник, который выступает универсальной оберткой под разные SDK популярных площадок.
Как работает SDK
Construct довольно удобный, но это все таки нишевое решение, его используют далеко не все, так что я вынес логику плагина в отдельный скрипт. Теперь основную работу выполнял Javascript SDK, а плагин дергал за ручки. Проще говоря: если в плагине вызвали «показать рекламу», то он вызывает мой SDK, а SDK обращается к игровой площадке и запрашивает показ рекламы. Такое решение можно масштабировать на все движки, которые поддерживают экспорт в HTML, везде можно подключить JS SDK и все это завести.
Как SDK определяет площадку
На словах все звучит просто, но создание собственного SDK оказалось связано с кучей тонкостей. Например, не хотелось тащить бандлы всех площадок в один SDK.
Во-первых, такое решение будет много весить, а во-вторых, площадки просят затачивать игры под свою платформу и, например, Яндекс Игры не допустят до релиза проект, в коде которого есть строки, которые обращаются к VK и наоборот.
Из-за этого HTML-разработчикам, которые хотят публиковаться в разных местах, приходится поддерживать сразу несколько версий одной и той же игры. В идеале, скрипт должен снимать эту боль, определять, к какой площадке его подключают, и самостоятельно подгружать нужный бандл.
Я выбрал путь косвенного автоопределения площадки через URL адрес фрейма, в который вшита игра. Каждая площадка передает условно какой-то ID в параметрах ссылки, и по ним можно определить, например, Яндекс это или VK.

Для Яндекс Игр индикатором служит хост — games.s3.yandex.net. Дополнительно из него можно забрать ID площадки — 148868.
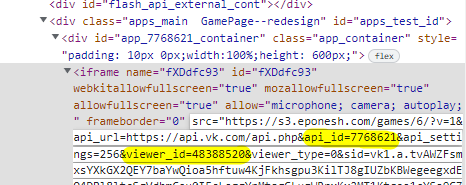
Для VK игру нужно размещать на своем хостинге, так что метод определения по хосту не подходит. Зато VK прокидывает в URL фрейма свои параметры: api_id, viewer_id и auth_key — для игр и vk_user_id, sign, vk_app_id для приложений. Их наличия хватает, чтобы удостовериться, что перед нами площадка VK. Этот метод косвенный, даже костыльный, но он работает.
Единственная площадка, где определение по URL фрейма оказывается бесполезным — это Smart Market. Фрейм здесь чистый, URL пустой, никакие параметры дополнительно не передает — не за что уцепиться. В этом случае я определяю площадку через явное прокидывание get-параметра _platform - ?_platform=SMARTMARKET
Как SDK загружает конфигурацию и подключается к площадке
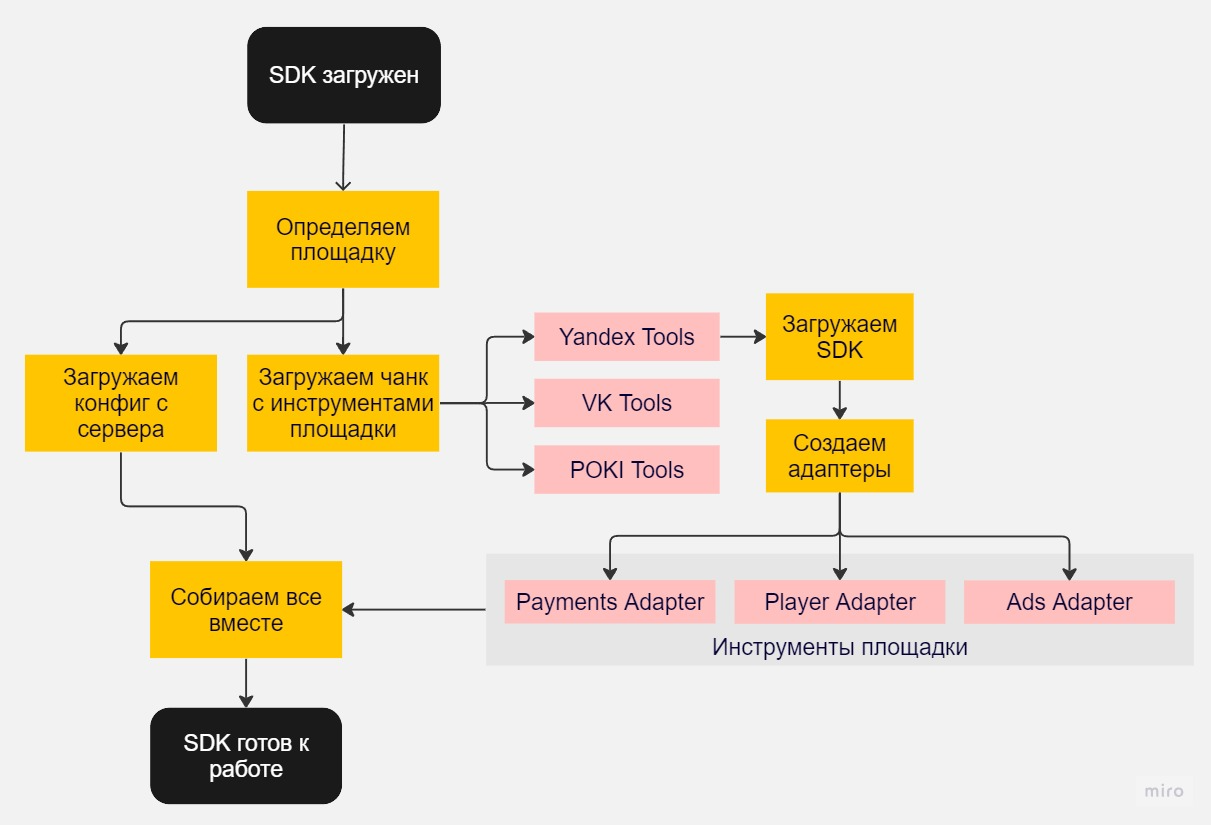
После того как сервис определил площадку, для нее нужно загрузить определенную конфигурацию. В нее входят настройки баннеров (частота показа и автообновления, ID и размеры блоков), информация об игре, ID счетчиков метрик, поля игрока, серверное время и много другой полезной информации.
За ней SDK обращается к серверу и параллельно начинает загружать инструменты для работы с SDK площадки и саму библиотеку площадки — например Яндекс SDK или VK Bridge.
Я решил разбить инструменты для работы с площадками на отдельные чанки через Webpack — каждый чанк — отдельная площадка. Это решило проблему веса при масштабировании, потому что у под площадку грузится только нужный чанк.
const toolsBundles: Record<PlatformType, PlatformChunk> = { [PlatformType.YANDEX]: () => import(/* webpackChunkName: 'platforms/platform.yandex' */ './tools/getYandexTools'), [PlatformType.VK]: () => import(/* webpackChunkName: 'platforms/platform.vk' */ './tools/getVKTools'), [PlatformType.OK]: () => import(/* webpackChunkName: 'platforms/platform.ok' */ './tools/getOKTools'), // ... };
Пример списка чанков
У всех площадок разная логика, код, названия методов и результаты, так что я держу в бандле обертку, которая вернет в основной SDK то, что мне нужно. Вот пример инициализации инструментов для работы с площадкой:
export default async function getYandexTools(tools: PlatformBootupTools) { const sdk = new YandexSDK(tools.gp, {}); // Инициализируем SDK const [, , projectConfig] = await Promise.all([ // Начинаем загружать SDK sdk.init(), // Настраиваем дополнительные локальные хранилища tools.setupStorage([new YandexStorage(sdk), new YandexPlayerStorage(sdk)]), // Получаем конфиг с сервера с учетом языка игрока tools.fetchConfig(sdk.lang), ]); // Создаем адаптеры под SDK const adsAdapter = new YandexAdsAdapter(sdk, projectConfig.platformConfig); const appAdapter = new YandexAppAdapter(sdk); const playerAdapter = new YandexPlayerAdapter(sdk); const platformAdapter = new YandexPlatformAdapter(sdk); const socialsAdapter = new YandexSocialsAdapter(sdk); const paymentsAdapter = new YandexPaymentsAdapter(sdk); return { adsAdapter, appAdapter, playerAdapter, platformAdapter, socialsAdapter, paymentsAdapter, projectConfig, }; }
Затем я получаю нужные адаптеры от площадки и скармливаю их в модули моего SDK.
const platformTools = await getToolsByPlatform({ platformType, tools }); const { adsAdapter, playerAdapter, platformAdapter, socialsAdapter, paymentsAdapter, projectConfig, appAdapter, } = platformTools; const platform = new Platform(platformAdapter); const ads = new Ads(adsAdapter, projectConfig.asdConfig); const app = new App(appAdapter, projectConfig.project); const socials = new Socials(socialsAdapter); const player = new Player(playerAdapter, projectConfig.playerFields); const payments = new Payments(paymentsAdapter); const variables = new GameVariables(projectConfig.gameVariables); const achievements = new Achievements(projectConfig.achievements);
Работая с единым интерфейсом, я, например, указываю, что нужно показать рекламу, а обертка знает, как это вызвать, например, в Яндекс SDK или в VK Bridge. В результате не важно, к какой площадке подключена игра, потому что результат придет одинаковый.
export default abstract class AbstractAdsAdapter { isStickyAvailable: boolean; isFullscreenAvailable: boolean; isRewardedAvailable: boolean; isPreloaderAvailable: boolean; async showPreloader(banner: Banner): Promise<boolean> { return Promise.resolve(true); } async showFullscreen(banner: Banner): Promise<boolean> { return Promise.resolve(true); } async showRewardedVideo(banner: Banner): Promise<boolean> { return Promise.resolve(true); } async showSticky(banner: Banner): Promise<boolean> { return Promise.resolve(true); } async refreshSticky(banner: Banner): Promise<boolean> { return Promise.resolve(true); } async closeSticky() {} }
Пример интерфейса для рекламного адаптера, который должна удовлетворить имплементация конкретного рекламного адаптера площадки
Чего еще не хватало в первой версии сервиса

На бэкенде нужно было сделать какую-то авторизацию. Я решил не париться, и воспользовался готовым решением от Google. Иначе пришлось бы хранить у себя логины и пароли, возиться с восстановлением данных, бороться с социальной инженерией и так далее. А так эти моменты за меня решает Google-авторизация. Некоторые разработчики шутят, что пора делать авторизацию через Яндекс, но я еще надеюсь, что Google в России не забанят.

Мой сервис сохранял данные игроков на сервере — по сути, в любом необходимом формате. Можно было добавлять список полей, типизировать и таким образом настраивать его под нужды конкретной игры.

Например, можно построить лидерборд по уровню игрока и по опыту — нужно просто изменить соответствующие параметры. Кстати, впоследствии гибкость построения лидербордов сыграла злую шутку, потому что когда у тебя не 100 тысяч игроков, а 100 миллионов, сортировать их становится сложновато.
С этим минимальным набором фич я пришел к знакомым разработчикам HTML-игр и предложил протестировать сервис. Аналоги тогда работали только с иностранными площадками, например, GameArter, а у меня поддерживались Яндекс Игры, VK и Одноклассники, так что идею подхватили с энтузиазмом. Уже через неделю у меня был длиннющий бэклог с разными хотелками от бета-тестеров, так что я стал развивать архитектуру и прикручивать новые фичи.
Что под капотом

В начале у меня был довольно простой набор сервисов. Прежде всего это API на Node.js, база данных MongoDB, Nginx и админка на Nuxt 2 / TypeScript, SDK только TypeScript. Плюс игровой оверлей на Preact.
Deploy
Все эти сервисы завернуты в Docker контейнеры и оркестрируются через Docker Compose.
Я сразу настроил CI/CD через GitlabCI. Как только пушу сервис в мастер, собирается билд с контейнером и затем выливается на продакшен сервер. По сути, это стандартный CI/CD pipeline. Я решил вкрутить его с самого начала, чтобы не приходилось выливать что-то вручную.
Поначалу это была просто сборка билда сервиса и раскатка на сервер. Есть много статей про настройку CI/CD в gitlab, например, GitLab CI: Учимся деплоить — в ней собраны основные возможности GitlabCI.
Пример моего конфига .gitlab-ci.ym для деплоя на прод:
variables: IMAGE: gamepush/api:latest deploy: image: docker:19 services: - docker:19-dind stage: deploy only: - master before_script: - docker login -u $CI_DOCKERHUB_LOGIN -p $CI_DOCKERHUB_PASSWORD - docker build --pull --cache-from $IMAGE -t $IMAGE . - docker push $IMAGE - apk add --update openssh - eval $(ssh-agent -s) - echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - > /dev/null - mkdir -p ~/.ssh - chmod 700 ~/.ssh - ssh-keyscan $CI_DEPLOY_PROD_HOST >> ~/.ssh/known_hosts - chmod 644 ~/.ssh/known_hosts script: - ssh root@$CI_DEPLOY_PROD_HOST "cd /var/www/gamepush-deploy/; \ sudo docker pull $IMAGE; \ sudo docker-compose up -d --no-deps --build api; \ docker image prune -a -f;"
Порядок следующий:
Логинимся в докер, собираем билд и пушим образ;
Устанавливаем модуль openssh прямо в раннере, чтобы подключиться к нашей удаленной машине;
Добавляем приватный ключ с которым пойдем на сервер. Добавляем сервер в доверенные хосты;
Подключаемся к серверу, пулим образ, через docker-compose пересоздаем контейнер с новым билдом и чистим старые билды через docker image prune, чтобы сэкономить место.
SDK
Поскольку SDK — это обычная JS-библиотека, ее нужно где-то положить, чтобы потом к ней можно было обращаться. Сначала я просто поместил ее в папку на сервере, чтобы поддержать работоспособность старых версий при релизе новой, я хранил там все сборки SDK.
Конечно, можно было сделать версионирование SDK, но я отказался от этой идеи, чтобы в любой момент можно было пофиксить баги или добавить полезный функционал без пересборки билда с обновлением версии SDK.
С этим связана проблема. Если я выложил новую версию SDK, а у игрока, например в VK, закешировалась и загрузилась старая версия основного модуля, то он может загрузить новый чанк с инструментами, которые не совместимы с новым SDK. Эта проблема решается Webpack из коробки. Он генерирует хэши при сборке, и при загрузке старой версии SDK, тянется старая версия VK-адаптера. Так можно хранить все версии сразу.
Количество сборок SDK со всеми чанками росло, какие билды уже не актуальны, а какие еще могли быть в кеше, — неизвестно. Не хотелось периодически подчищать старые сборки, более того, не хотелось вообще об этом беспокоиться... Так что я перезалил это все на S3. Теперь новые билды выливаются сразу туда, и я не переживаю о переполнении и каком-либо контроле. Правда, чтение с S3 происходит не быстро, поэтому я спрятал S3 за Nginx и кэширую основной SDK и чанки, а затем и вовсе закрыл все CDN от Cloudflare.
Пример конфига для получения файлов SDK из S3 хранилища:
server { server_name s3.gamepush.com; add_header 'Access-Control-Allow-Origin' '*' always; add_header 'Access-Control-Allow-Methods' 'GET, OPTIONS' always; proxy_ssl_name gp.s3provider.com; proxy_ssl_server_name on; proxy_http_version 1.1; proxy_set_header Host gp.s3provider.com; proxy_intercept_errors on; proxy_cache off; proxy_read_timeout 300s; proxy_connect_timeout 75s; # gzip из коробки в Cloudflare gzip off; location /files/ { proxy_pass https://gp.s3provider.com/files/; } }
И затем получение SDKпроксируется на свой S3 домен с дополнительным кешированием в Nginx на минуту.
server { server_name gamepush.com; location ^~ /sdk/ { set $args ''; # gzip из коробки в Cloudflare gzip off; proxy_ignore_headers Expires Cache-Control; proxy_cache sdk; proxy_cache_valid 200 302 1m; proxy_ssl_server_name on; proxy_pass https://s3.gamepush.com/files/gs/sdk/; } }
S3 хост закрыт CDN от Cloudflare и обмазан его кешами. Это нужно из-за того, что S3 сервер долго извлекает файлы из хранилища, и бонусом CDN дополнительно сжимает их в gzip и brotli.
Дополнительное проксирование решает проблему очистки кэша Cloudflare. Если не куплен Enterprise план, скинуть кэш можно только явно передавая список источников на которых нужно очистить кэш, например iframe в Яндексе. Домены все разные, и лучше если источник будет один, в моем случае — корневой домен.
Сам корневой домен не закрыт CDN. На нем API и файлы SDK, которые весят не много и раздаются напрямую. Возможно в будущем имеет смысл раздавать SDK напрямую из S3, закрытого CDN. Но в случае выкатки SDK с критическим багом, откатить такое не получится, пока не протухнут кеши CDN и браузеров.
API
Сам сервис API сделан с использованием GraphQL — это язык запросов для API поверх HTTP. Идея GraphQL в том, что один сервис собирает в себе все остальные сервисы и возвращает только те данные, которые нужны клиенту. Например, тебе нужен список достижений игрока и список покупок, но за это отвечают разные сервисы. GraphQL-сервис сам опрашивает эти сервисы и отдает то, что запросил пользователь. Из самой схемы можно генерировать типизированный серверный и клиентский код. Я использую gqlgen для генерации из схемы на Go (API теперь на Go, но об этом в следующий раз) и graphql-codegen для генерации типов и клиента на фронте.
Все запросы в БД за проектом, достижениями, покупками или описанием структуры игрока кешируются на некоторое время, и это позволяет отвечать довольно быстро, особенно в пиковые нагрузки. Кэши сбрасываются при обновлении сущности, и следующий запрос пойдет в БД и обновит кэш.

Собирать эти данные помогает prometheus client, образец которого взят здесь (для Go).
Для NodeJS в проекте использовался Apollo Server. Плагин для сбора метрик — @bmatei/apollo-prometheus-exporter. Из-за использования GraphQL-схемы было достаточно просто переехать на Go, так как схема строго типизирует и входящие, и исходящие данные, а также отвечает за валидацию данных согласно схеме. Значит все что мне нужно переписать, — это запись и чтение в БД. Все остальное, даже список резолверов, генерируется фреймворком.
База данных
MongoDB, как многие говорят, — идеальный выбор для стартапа. Когда еще нет устоявшейся схемы и постоянно все переписывается, отсутствие типизации спасает. Сейчас, конечно, и в MongoDB можно задать жесткую схему. Но мой выбор пал на нее в том числе и из-за гибкости.
Вот несколько преимуществ и недостатков, которые я отметил за время работы с MongoDB:
+ Очень хорошо заточена под индексы. В том числе под индексирование сложных объектов и массивов. В моем проекте нет сложных индексов, но часто используются составные, например по номеру проекта и тегу достижения. Также все чаще нужны TTL-индексы, скажем на отслеживание игроков онлайн или хранение сессий в течение месяца, с автоочисткой.
Моя самая любимая фича с индексами, которая очень спасает — Index Intersection. Она позволяет на основе двух даже составных индексов использовать поиск по индексу, когда запрос затрагивает эти два индекса. Это выручает при построении рейтинга игроков.
Даже когда в базе более 100 млн записей, поиск по индексам все равно ничего не стоит. Главное только, чтобы серверу хватало памяти на хранение индексов. По-умолчанию база забирает себе половину ОЗУ сервера, а остальную рекомендует оставить под кеширование системой файлов БД.
- Индексы получаются очень объемными. Так, на хранение ObjectID индекса, который тебе не нужен, но обязателен для БД, уходит 2.2GB для коллекции в 100 млн. записей. В среднем хранение остальных составных индексов для этой коллекции занимает ~3.6GB.
+ Синтаксис запросов. За все свои годы я так и не привык к работе с SQL, поэтому работа с JSON для меня, как фронтендера более привычная и удобная.
- Пока не поработаешь с агрегациями. Но желательно проектировать так, чтобы они не понадобились. В этом как раз помогает GraphQL и подход дата-лоадеров. У меня агрегации используются в основном только в расчете статистики.
+ Репликация и шардирование из коробки, настраивается и синхронизируется автоматически, достаточно только указать список реплик. Они сами синканутся и распределят роли.
- Но есть нюансы. Есть много возникающих проблем с настройкой реплик, но они обычно инфраструктурные, например факт того, что БД находится в контейнере и даже не знает своего хоста.
Также не хватает обычного автоинкрементящегося числового ID, так что приходится подкостыливать.
Панель управления
Она достаточно простая. Из фреймворков был выбран Vue, тогда еще Vue2. В помощь ему Nuxt. Препроцессоры: SASS и Pug. Из библиотек компонентов остановился на Vuetify из-за его большого функционала, который помимо компонентов предоставляет еще и сетки, хелперы для стилей, темизацию. В общем css почти не пишу.
Оверлей
Оверлей — окна поверх игры, например, со списком достижений или лидеров. Нет ничего нуднее, чем делать скролл на движках игр. Такое решение позволяет переиспользовать во всех играх основные удерживающие игрока фишки.
Для него был выбран Preact, так как он достаточно легковесный, всего 7kb. Для сравнения, Vue 40-50kb, React около 500kb. Основным критерием выбора был именно вес, но еще мне хотелось пощупать реакт и tsx. Тем более все равно пет-проект.
Preact полностью может заменить React, что было очень нужно при работе с VK и их рекламными компонентами, которые работают только в реакт-экосистеме. Можно настроить сборку совместимую с Preact в два флажка в tsconfig:
{ "compilerOptions": { "jsx": "react-jsx", "jsxImportSource": "preact", } }
Как работает сервис
Опишу, как происходит самое распространенный запрос к GamePush — сохранение игрока.
Прежде всего нам нужно как-то понять, с кем мы имеем дело, особенно если игрок не авторизован. Можно использовать какой-нибудь local storage, либо IndexedDB. Туда мы можем поместить ID / токен игрока, чтобы потом, при обращении на сервер, его идентифицировать.
Перед синхронизацией с сервером первым делом нужно получить у игровой площадки информацию об игроке — ID, ник и аватар. В это же время можно параллельно пойти и загрузить локальное сохранение игрока. Оно пригодится для перестраховки, если на сервере что-то вдруг случилось, или нам нужно сохранить прогресс именно с этого браузера.
Дальше SDK обращается на сервер, авторизовывается на нем и сохраняет игрока в базу. А потом от сервера возвращается ответ, и новый стейт записывается локально вместе с секретным кодом, чтобы можно было авторизовать игрока.
Как обеспечить локальное сохранение игрока? Самое простое решение — записать в local storage. Но есть iOS, которая упорно не хочет туда ничего сохранять. На этой платформе внутри iframe local storage работает как session storage, данные хранятся пока не закроешь браузер, а потом данные удаляются.
Чтобы это победить, я сохранял стейт везде, где только можно, — в localstorage, в IndexedDB, и если позволяла площадка, — на ней. Я пробовал записывать данные в куки, но со временем политика безопасности браузеров, особенно Safari — начала блокировать third-party куки. В конце концов Яндекс сделал обертку над localstorage — через общение с помощью post message между iFrame и верхнеуровневым доменом, и я начал дополнительно сохранять все через него. Из остальных площадок только GamePix пришли к такому же решению. В итоге для Яндекса данные сохраняются параллельно в 4 хранилища: LocalStorage, IndexedDB, обертку Яндекса над LocalStorage и, если игрок авторизован, в данные игрока на площадке.
Была еще одна интересная проблема, связанная с тем, что если пользователь заходит в браузер в режиме инкогнито, его нужно предупредить, что он потеряет прогресс, когда закроет вкладку. В какой то момент я реализовал через GamePush создание секретного кода сохранения и показывал игроку этот код, когда нужно было сохраниться. Как в играх на старых приставках, его можно было записать, ввести потом и продолжить с того же уровня игры.
Вот только разработчики браузеров специально делают так, чтобы со стороны сайта не было заметно, что браузер работает в режиме инкогнито. Раньше можно было, например, проверить существует ли local storage, можно ли записать в IndexedDB. Долгое время я определял режим инкогнито через установку Third-Party Cookies в стороннем iframe, но сейчас это эти лазейки прикрыли.
Новые фичи
Разобравшись с хранением данных игроков, авторизацией и вызовом разных функций платформы через универсальный SDK, я начал прикручивать дополнительные модули.
Например, в VK или Одноклассниках можно отправить пост на свою страничку и пригласить людей в игру, а на площадке Яндекс этого нет. Если выводишь игру сразу на несколько площадок, это очень неудобно. Чтобы как то уравнять их в возможностях, я начал писать адаптеры, которые показывают окно с нужной функцией поверх обычного интерфейса игры, подобно тому, как это происходит с лидербордами. То есть, если площадка не поддерживает какие-то действия, их нарисует мой сервис.
Кстати, с окнами связан еще один важный момент. Как оверлей может влиять на стили сайта и движки на которых разработчики пишут игры, так и стили игры могут влиять на оверлей. Что-то пойдет не так, и вся верстка поплывет. Поэтому я проставляю специальный префикс gp-overlay ко всем своим классам. Отказываясь от базовых имен классов, которые может как-то использовать движок игры, я изолирую свой код.
Рост нагрузки и польза проекта
В итоге я сделал интеграции со всеми основными игровыми площадками. Заработал сарафан, сервис набирал популярность, но проект еще воспринимался, как хобби. Первое время дохода от моих игр с лихвой хватало, чтобы покрывать расходы на сервер. О монетизации я не задумывался, но нагрузка росла.
Моя первая виртуалка работала на одном ядре и гигабайте оперативной памяти. Ее мне хватило надолго, потому что вся база данных составляла всего 25 мегабайт, а игроков было около ста тысяч. Поначалу у меня было всего 40 запросов в минуту, и долгое время Grafana была настроена именно на RPM.

В начале мая я открыл доступ к GamePush для всех желающих и тут понеслась. Сначала RPM превратились в RPS — нагрузка выросла до 3-4 запросов в секунду. Это было по-прежнему немного, но в июне я увидел цифру в 1 миллион игровых аккаунтов. Grafana показывала уже 9-10 RPS. Тогда я перешел на двухядерный сервер.
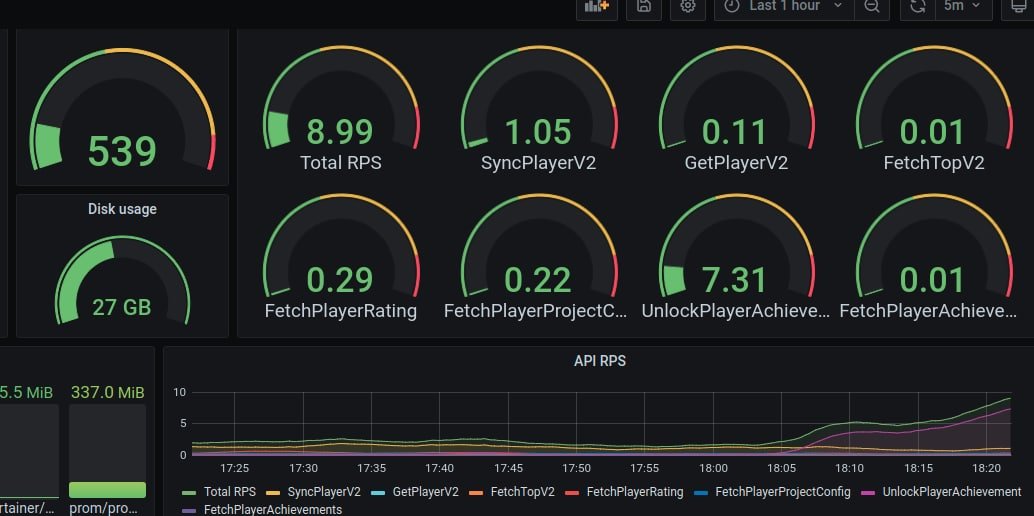
Месяц за месяцем счетчик неуклонно шел к 20-30 RPS. Сервер начал скрипеть и окончательно сдался в районе 60 запросов в секунду. На 1 RPS уходило примерно 2% ЦПУ, и двух ядер уже не хватало.

Естественным ответом на рост нагрузки стало вертикальное масштабирование. Сначала я выделил 4 ядра, потом 6, далее — 8. Чтобы как-то контролировать процесс роста и поддерживать сервер, я ввел монетизацию по запросам к серверу для новых пользователей. Оплата за запросы к серверу показалась мне более справедливой — сколько запросов сгенерировал, за столько и заплатит. Такой подход дает контроль нагрузки для меня и осознанное потребление для клиента. И все равно я уперся в потолок.

У моего хостера это это высокочастотный сервер на 5 ГГц, 8 ядер, 16 ГБ ОЗУ. Масштабироваться больше некуда, только если горизонтально (в случае базы данных это слишком сложный путь) или переезжать.

Не хочется этого делать, так что пока я придумываю всякие оптимизации, но об этом в следующий раз. Сейчас хочется сказать, что нет никаких гарантий, что из проекта получится бизнес, но я определенно не жалею, что заварил эту кашу. Я тут по сути и девопсер, и бэкендер, и фронтендер — прокачался во всем и получил кучу ачивок. Пет-проджекты действительно сильно развивают скиллы, но, предупреждаю: есть риск, что они сожрут все ваше время и заменят основную работу — тогда точно будет не до скуки — в хорошем смысле этих слов.
Надеюсь, вам было интересно. Пока что мы не глубоко заглянули под капот моего сервиса[ссылка удалена модератором]. Про какие аспекты его работы рассказать в следующий раз?

