Про управление проектами разработки в условиях микросервисной архитектуры
От автора
Статья была написана мной в 2020 году, после запуска в прод очередной платформы, построенной на микросервисной архитектуре с целью зафиксировать выученные уроки с точки зрения технического руководителя проекта. В проектах участвовало со стороны подрядчика более 300 человек технических специалистов - разработчиков, тестировщиков, аналитиков и др. Поэтому можно сказать, что проекты были достаточно крупными и значимыми.. Теперь уже многие компании - участники проекта либо свернули бизнес в РФ, либо поменяли бренд, а разработанные системы находятся в эксплуатации. Микросервисная архитектура давно не является новой архитектурной парадигмой. Но я думаю, что статья все еще актуальна, как и многие выученные уроки .
Введение
Достаточно много статей и хороших книжек можно найти про то, что такое микросервисная архитектура, какие преимущества она дает. Все больше компаний используют микросервисы, стартуют проекты по созданию решений с нуля или проекты по переводу монолитных решений на микросервисную архитектуру. Однако материалов, которые бы раскрывали важные особенности в управлении проектом разработки, построении процессов и в целом бы описывали микросервисную архитектуру с точки зрения руководителя по разработке, технического руководителя проекта, достаточно мало. Еще одна цель, которую преследует данная статья, это записать выученные уроки по результатам двух достаточно больших проектов по разработке решений с нуля на базе микросервисной архитектуры. Во-первых, чтобы сформулировать открытые вопросы и решения открытых вопросов. Во-вторых, чтобы не повторить сделанные ошибки в будущих проектах. Какие-то решения, или заключения, возможно, вам покажутся банальными, а другие спорными. Открытые вопросы не стоящими внимания. Такое случается, и это нормально, особенно в достаточно сложном, динамично развивающемся мире ИТ.
Надеюсь, что статья будет полезна руководителям проекта, delivery менеджерам, архитекторам, лидам разработки и тестирования.
Еще раз подчеркну, что статья не претендует на то, чтобы быть научным трудом или очередной статьей про архитектуру. Прошу воспринимать данный материал как заметки менеджера по результатам выполнения реальных проектов.
1. Инициализация проекта
В данном разделе описывается подход к выполнению самых ранних этапов проекта до начала разработки. Если вас интересуют более практические вопросы, то данный раздел можно пропустить.
Предлагаю сначала определить названия ролей компаний-участников этапа инициализации проекта. Под названиями ролей подразумеваются организации, а не физические лица.
Клиент – заказывает продукт или решение, платит деньги за выполненные работы.
Консультант – консалтинговая компания, помогает клиенту разработать концепцию решения, определить верхнеуровневые требования, сопровождает процесс выбора Разработчика (разработка RFP, критериев отбора и т.п.), выполняет аудит проекта по разработке продукта.
Разработчик – компания, которая отвечает за детальный анализ требований, архитектуру, разработку, тестирование, внедрение продукта или решения в продуктивную эксплуатацию.
Обычный подход к старту проекта по разработке продукта
На моей практике часто проекту по разработке решения предшествовали проекты по разработке стратегии и верхнеуровневой концепции решения, которые выполняли Консультанты из Big4 или выше.
Далее стартовала фаза выбора Разработчика, на которой Консультант помогал определиться клиенту с критериями выбора и обеспечивал поддержку процесса выбора Разработчика.
А после выбора подрядчика консультант обеспечивал аудит проекта.
После того, как Консультант сделал первые фазы инициализации проекта, сценарий был примерно одинаковый. При этом сценарий не зависел от того, какой консультант выполнял первые фазы.
А именно, на старте проекта закладывались вопросы и риски, которые невозможно было решить без серьезного пересмотра требований к решению и как результат последующего перезапуска проекта. Похоже, что сама схема подобного разделения ответственности между Консультантом, Разработчиком и Клиентом работает не очень хорошо. Возможно, на результат повлияли сразу несколько факторов, и сама схема лишь усугубляет и усложняет решение вопросов в проекте. Также стоит отметить, что автору приходилось участвовать в проектах только со стороны Разработчика. Поэтому ситуация, развитие событий будут описаны естественно в большей степени с точки зрения Разработчика программного обеспечения.
Дело вот в чем:
1. Одним из основных результатов выполнения обследования консалтинговой компанией является документ с перечнем требований к новому решению. Требования, которые получал Разработчик, оказывались как правило достаточно неточными, верхнеуровневыми, и не всегда технически реализуемыми. Однако клиент настаивал, чтобы требования легли в основу договора с Разработчиком.
Какие обычно последствия в результате непосредственного использования результатов работы Консультанта в качестве требований к решению:
Во-первых, консультант уже не несет прямой ответственности за качество требований перед клиентом. Консультант закрыл свой проект успешно и получил деньги от Клиента по договору. Даже если требования в итоге оказались не реализуемыми, неполными, неверными, Консультант и Клиент вместе вряд ли будут выставлять друг другу претензии. Хотя бы потому, что у клиента нет инструментов влияния на Консультанта – проект завершен. Но есть проект и договор с Разработчиком, большая часть ответственности за результат лежит на Разработчике, на которого у Клиента есть рычаги влияния.
Что можно улучшить?
С точки зрения Разработчика, очень важно планировать фазу определения требований (уточнения требований) в проекте Разработки, договариваться с клиентом, что требования на входе могут оказаться не совсем того качества, о котором говорят консультант и клиент. На самом раннем этапе внедрять процедуру управления изменениями, показывать клиенту риски, включая технологические риски, как следствие некачественных требований на входе в проект. Скорей всего разумный Клиент подтвердит, что Требования подлежат обязательной валидации архитекторами и аналитиками проекта по разработке. Также есть возможность роста Разработчика в область консалтинга, чтобы закрывать по сути все этапы большой программы.
Что можно сделать с точки зрения Клиента? Думаю, здесь уместно напомнить об общеизвестной управленческой практике, которая говорит о том, что нужно в первую очередь прислушиваться к мнению тех участников процесса, которые несут ответственность за конечный результат.
Также было бы круто, если система мотивации участников большой программы (Консультанта, Разработчика и Клиента) была построена, исходя из ответственности и степени влияния участника на конечный результат.
Возможно стоит уточнить, что из себя представляет обычно консалтинговый проект по определению требований? Это проект рассчитанный на несколько месяцев, в который вовлечено несколько консультантов и ключевые эксперты от клиента. Т.е. с точки зрения, человеко-часов такой проект в десятки раз меньше чем проект по разработке, внедрению, сопровождению решения. Поэтому, не стоит пренебрегать возможностью валидировать требования, детализировать, актуализировать совместно с тем, кто реально несет ответственность за гораздо более трудоемкий и технологически сложный проект.
С т.з. Консультанта, насколько я могу судить, что-то улучшить сложно. Т.к. при данной схеме Консультант свою прибыль получают легко. Хотелось бы подчеркнуть, что в консалтинговых компаниях работают действительно умные люди и профессионалы, насколько я могу судить исходя из опыта нескольких лет работы в консалтинге и по результатам совместной работы с консультантами в проектах. Думаю, что консультанты сами разберутся к чему приведет в итоге данная схема работы и как ее починить. Не уверен, правда, что Консультанты будут достаточно мотивированы что-то менять здесь. Особенно учитывая тот факт, что многие Консультанты открыли свои центры разработки.
2. В этом пункте я бы хотел выделить отдельно и подчеркнуть еще раз вопрос ответственности за конечный результат.
Допустим проект по разработке стартовал, и тот же консультант выполняет роль аудитора в проекте по разработке. Так происходило на тех двух проектах, где мне удалось участвовать в роли деливери менеджера.
Сильными сторонами Консультанта являются презентация, включая самопрезентацию. Основной актив консультанта – это репутация. Консультант продает себя и свою репутацию, каждый день, каждую минуту, каждую секунду. Продавать себя и свою репутацию – это достаточно большая часть работы Консультанта.
Когда Консультант становится аудитором проекта по разработке, то такая ситуация, по-моему, влечет конфликт интересов. Потому что, если на первой фазе программы, до начала проекта по разработке, Консультант в роли консультанта разработал некачественные требования, то тот же Консультант в роли аудитора проекта вряд ли скажет Клиенту что корень проблемы в некачественных требованиях.
Более того, Консультант в роли аудитора проекта, наблюдая, как рушится стройная матрица требований, которую он создавал на предыдущем этапе, может тормозить внедрение процесса управления изменениями в проекте, объясняя это защитой интересов Клиента, защитой Клиента от дополнительных затрат. При этом отсутствие процесса управления изменениями делает проблематичным замену устаревших, нереализуемых, иногда противоречивых требований на актуальные и более значимые для Клиента в моменте требования. В итоге принятие важных решений затягивается, спорные вопросы в части управления требованиями накапливаются.
Причем здесь микросервисная архитектура?
Если вы участвуете в проекте по разработке решения на базе микросервисной архитектуры, в любой роли, на стороне Клиента, Консультанта или Разработчик, и ваша программа с т.з. этапности и разделения ответственности между участниками устроена так как описано выше, то есть высокий риск получить открытые вопросы с требованиями и управлением изменениями, и риск последующего перезапуска проекта в лучшем случае.
Что я подразумеваю перед перезапуском проекта, и почему перезапуск становится необходим. Представьте себе ситуацию, когда Разработчик работал честно, пытался выполнить требования по контракту и даже в иногда в ущерб себе (вспомните, что управление изменениями в данном проекте внедрить достаточно сложно). Стратегические цели проекта не изменились – Клиенту все еще нужно прорывное решение, новый продукт. Но Клиент понял, что требования, которые были поданы Разработчику на входе, либо не реализуемы, либо устарели. Т.е. стратегически все верно, но дальше двигаться невозможно. Консультант-аудитор в этот момент обычно говорит, что он всего лишь аудитор в данном проекте и не в силах повлиять на результат. С высокой вероятностью может реализоваться сценарий, когда Клиент и Исполнитель остаются решать на двоих, что же делать дальше с проектом. В лучшем случае Клиент понимает, что нужно делать то, что было описано чуть выше, о чем ему Разработчик говорил неоднократно. Именно то, что Клиент так и не услышал от Консультанта-аудитора. В этот момент возникает необходимость все же выполнить работу, которую откладывали раньше, а именно, выполнить качественно фазу определения требований, по результатам уточнить архитектуру решения, включить процедуру управления изменениями.
С большой долей вероятности, после уточнения требования полученная уточненная архитектура, будет достаточно сильно отличаться от первоначального варианта. Например, достаточно, поменять один символ в требованиях с RPO = 0 на RPO->0 и уточнить, в каких именно бизнес сценариях или компонентах RPO должно стремиться к нулю или к конкретному значению, отличному от нуля, как в результате проект становится понятным техническим специалистам и реализуемым.
2. Оценка и планирование проекта
Каким образом выполнить оценку затрат на выполнение работ по разработке и запуску в эксплуатацию решения? Есть ли какие-то работы, или затраты, которые нужно учитывать при планировании и оценке?
Часто Заказчик требует выполнить работающий прототип системы еще на фазе выбора подрядчика, чтобы исключить тех Разработчиков, которые не обладают достаточной экспертизой в технологиях, а также проверить способность Разработчика организовать работы. Этап создания прототипа поможет детально разобраться в требованиях и попытаться выполнить меппинг на будущие компоненты системы, которые либо будут представлены в прототипе, либо в целевой системе.
В любом случае сначала нужно вооружиться подходом Domain Driven Design, определить ключевые бизнес области и сущности. Создать предварительную архитектуру решения, разбить на компоненты, оценить связи между ними. После чего наложить нефункциональные требования на полученную компонентную модель и подумать над отказоустойчивостью, масштабированием, кол-вом зависимостей, развертыванием и сопровождением решения. Далее уже можно приступить к верхнеуровневой оценке трудоемкости разработки, тестирования, интеграционного тестирования, UAT и т.п. Вряд ли можно ожидать от экспертов, что оценка работы будет выполнена с точностью, превышающей 50%, потому что слишком много факторов будут влиять на объем работы, о которых будет сказано ниже.
Исходя из кол-ва микросервисов можно также оценить затраты на инфраструктуру для обеспечения процесса разработки и тестирования. Допустим мы определили, что у нас будет несколько десятков микросервисов. Выбрали модель бранчевания Git-flow с релизными ветками, чтобы обеспечить стабильность компонент. Также определили какие окружения вам нужны для процесса разработки. Допустим у каждой команды разработки будет по 2 нейсмпейса с двумя разными ветками. На одном неймспейсе выполняется Дев тестирование, на другом выполняется стабилизация релиза командой разработки. Можно сделать грубое допущение, что каждый контейнер при развертывании и запуске в опершифте потребует 500Мб оперативной памяти. Плюс потребуются ресурсы для нод самого опеншифта. БД и Кафку логично развернуть отдельно, за рамками опеншифта с целью экономии ресурсов и более стабильной работы данных компонент. Плюс необходимо учесть место под хранение логов, трейсов Zipkin. Это только дев-тест окружение. Еще как правило нужно создать окружения интеграционного тестирования, UAT, stage (тестирование развертывания, тестирования работоспособности релиза непосредственно перед деплоем в прод), среду нагрузочного и стресс тестирования. Не забыть про сервера обеспечения процессов CI/CD, DevOps: сервер сборки, сервер хранения артефактов, сервер статического анализа кода, сервер выполнения Unit и интеграционных тестов. В принципе, среды разработки могут быть развернуты в облаке, например в AWS. Стоимость ресурсов AWS известна, можно примерно посчитать сколько получится.
Оценка затрат на тестирование
Если мы допустим, что будем следовать подходу contract first (а как иначе?), постоянно интегрировать решение, все равно, существенные затраты будут лежать в области валидации сквозных сценариев, разбора ошибок, анализа в каком из сервисов возникла проблема и т.п. Чем больше сервисов, тем больше точек интеграции, тем больше затраты на тестирование. Можно точно сказать, что потребуются бОльшие по сравнению с монолитом затраты на интеграционное тестирование и стабилизацию решения в целом. Не важно, как вы это будете делать: автоматизируете сквозные сценарии и будете поднимать экземпляры сервисов при помощи test-containers, используете подход consumer driven contract (например, используя библиотеку pact), либо создадите команду ручного интеграционного тестирования, т.к. автоматизация пока еще не успевает за ходом разработки контрактов. В любом случае нужно будет тратить ресурсы на интеграцию сервисов, ресурсов нужно больше, чем при разработке монолита. Не только по причине больших затрат на разработку и выполнение интеграционных сценариев, но из-за усилий на анализ проблем и на исправление.
3. Построение организационной структуры команды разработки
Одним из известных достоинств микросервисной архитектуры является независимая (по крайней мере до этапа интеграционного тестирования) параллельная разработка разными командами разработки. И это действительно так. Разделив решение на набор сервисов, можно получать на выходе от команд разработок артефакты в виде сборок, которые должны работать совместно, т.к. команды заранее договорились о контракте. Но каким образом принять решение, сколько должно быть команд, какие компоненты какая из команд должна разработать? Т.е. иными словами по какому принципу строить команды.
Задачу формирования команд можно определить, как задачу создания эффективной организационной структуры. Предлагаю оценивать эффективность орг. структуры с точки зрения следующих критериев:
Каждая отдельная команда в структуре должна быть достаточно самостоятельной и при этом оставаться эффективно управляемой.
Из своей практики могу сказать, что отдельная команда разработки не должна быть больше 10-12-ти человек, чтобы удовлетворять данному критерию. Если команда больше, то командой становится сложно управлять. Если команда слишком маленькая, меньше 4-5 человек она не способна решать бизнес задачи самостоятельно и нет перекрытия ресурсов на случай отпуска или болезни.
Общее кол-во зависимостей, входящих и исходящих на другие команды, и как следствие объем вопросов и коммуникаций, которые нужно будет решать вместе, должны быть минимальными. (При условии выполнения критерия 1. Т.к. иначе можно создать команду, которая включает всех участников проекта)
Команды не дублируют функции и не занимаются одной и той же проблемой.
Каждая команда имеет возможность сама сделать сборку своих компонентов, протестировать и доставить до Продуктивной среды.
По аналогии с принципом единственной ответственности SOLID, идеально, когда у команды 1 заказчик (Владелец продукта).
Предлагаю рассмотреть на примерах, какие были случаи, когда орг. структура была оптимизирована в соответствии с принципами выше:
Пример 1
Допустим, в нашем решении существует набор компонент, которые отвечают за достаточно технологические функции и будут использоваться множеством других сервисов.
Например, аутентификация, авторизация, ОТР, нотификации, сервис подписи и валидации подписи документов, оркестратор, инструменты для разработки форматно-логических контролей и другие.
По каким-то причинам набор данных сервисов назван командой разработки архитектуры платформенными сервисами. А у менеджера, отвечающего за проект, по каким-то причинам возникает желание создать команду разработки, которая будет называться Платформа.
Допустим, что команда разработки Платформы должна разработать несколько десятков компонент. Чтобы разработать эти компоненты, требуется несколько десятков человек. Т.е. по сути команда Платформы не будет устойчива, т.к. см. критерий №1 выше. Также у команды Платформы будет несколько заказчиков, например, департамент информационной безопасности в части аутентификации и авторизации, операционный департамент в части инструментов разработки форматно-логических контролей и нотификаций. Что вступает в противоречие с критерием №5. Поэтому лучше сделать несколько отдельных команд разработки технологических или платформенных компонент.
Возможно, есть что-то, что объединяет каким-то образом данные команды разработки «платформенных» компонент? Если посмотреть на зависимости, то от команд, включенных в понятие Платформы, зависит работа менее технологических сервисов. Будем называть такие сервисы бизнес сервисами. Напротив, команды разработки платформенных компонент практически не зависят от других команд разработки. Также от стабильности компонент Платформы и от частоты изменения артефактов Платформы зависит скорость реализации проекта. Например, если компонент, отвечающий за аутентификацию нестабилен, и часто не работает аутентификация на среде интеграции, то выполнение интеграционных тестов может быть заблокировано.
На практике это означает, что для разработки данных компонент стоит привлечь наиболее квалифицированных разработчиков. А с точки зрения дорожной карты работ, разработка требований, архитектура, разработка компонент и стабилизация компонент должна идти с некоторым опережением относительно планов разработки бизнес сервисов.
Также можно вспомнить закон Конвея, который говорит о том, что организационная структура может влиять на архитектуру решения. Например, с выделением Платформы в отдельную организационную единицу потребуется при появлении новых фичей и компонент решать вопрос, является ли компонент платформенным, или нет. Кажется, что вопрос искусственный. На самом деле часто достаточно сложно провести четкую границу и разработать критерии “платформенности”. Как следствие, архитектурные границы при выделении отдельной команды Платформы могут проводиться, повторяя организационную структуру. С этой точки зрения лучше работает более плоская орг. структура, когда все команды разработки одинаковы по значимости, нет избыточных слоев иерархии или группировок команд. Таким образом есть возможность избежать решения вопросов, которые при правильной организации не будут возникать.
Пример 2
Представьте решение, в котором обработка запроса проходит несколько слоев системы: сначала запрос обрабатывается слоем адаптеров, далее запрос обрабатывается слоем бизнес логики. Архитекторы специально выделили эти слои, исходя из требований Заказчика.
Для обработки каждого типа документа для разных линий бизнеса разрабатывается сервис-адаптер и сервис, реализующий бизнес логику. Каждый сервис адаптера выполняет меппинг объекта внешнего API на внутреннюю структуру DTO объектов системы при передаче запроса в сервис бизнес логики.
Давайте представим, что мы принимаем решение разделить команды не по бизнес процессам и типам документов, а по технологическим слоям. Точно так, как архитекторы отразили в архитектурном решении. Например, мы обосновываем наше решение следующим образом: в случае организации команд по бизнес направлениям есть риск сделать сильно связанные компоненты – сервис адаптера и сервис бизнес логики.
Как это будет работать на практике? Во-первых, данные компоненты уже сильно связаны из-за наличия меппинга на уровне адаптера. Поэтому в случае изменений требований, потребуются доработки как со стороны сервиса бизнес логики, так и со стороны сервиса адаптера. Более того, команда, отвечающая за адаптеры, может не обладать экспертизой в бизнес домене в той же мере, как команда разработки бизнес сервиса. Поэтому в случае изменений команде разработки адаптеров может требоваться экспертиза команды разработки бизнес сервиса. И, наоборот, в случае изменений бизнес логики, команда разработки бизнес сервиса связана со сроками команды разработки адаптеров. Далее, если перейти к интеграции компонент. В интеграционное тестирование будут вовлечены сразу две команды. Поскольку экспертиза находится только в одной из команд, то коммуникации становятся достаточно дорогими. А в случае дефектов требуется координировать выпуск сборок сразу двух команд.
В данном случае можно сказать, что данная орг. структура неэффективна с т.з. критерия №2. Даже при простом изменении есть большая вероятность, что кол-во коммуникаций между данными командами будет существенным.
Также, с т.з. критерия №3, данные команды по сути решают одну и ту же бизнес проблему, реализуют те же требования, для одного и тоже бизнес Заказчика. В этом смысле данная организация команд не идеальна.
Требования реализовывались бы эффективней, если бы мы разделили команды не по принципу слоев, а по принципу бизнес направлений, бизнес доменов.
Обычно команды, которые разделены по принципу бизнес направлений или бизнес доменов, работают на конкретного заказчика, могут доставить самостоятельно изменения до прода при необходимости решить конкретную задачу домена, мы называем стримами или бизнес стримами.
Данные примеры взяты из реальных проектов. Какие выводы я сделал из данных примеров и из проектного опыта?
Во-первых, желательно, чтобы орг. структура с точки зрения команд разработки оставалась плоской, без лишних иерархий или группировок. Если не очевидно, как лучше поступить с точки зрения команд разработки, то можно начать с выделения отдельной команды на том же уровне иерархии.
Во-вторых, архитектурные границы и границы ответственности команд не обязательно должны совпадать.
В-третьих, метод группировки и команд и компонент по доменам, по направлениям бизнеса, как правило оказывался достаточно эффективным при прочих равных.
В-четвертых, структура управления командой разработки должна быть выровнена с орг. структурой бизнеса. Чтобы упростить, сократить кол-во коммуникаций, сделать их более эффективными. У команды разработки должен быть куратор (Владелец продукта) со стороны бизнеса.
4. Немного о методологиях и подходах
Иногда коллеги спрашивают меня, какая методология применяется на проекте? На вопрос в такой постановке достаточно сложно ответить просто.
Во-первых, в большом проекте как правило используется набор методологий и подходов.
Например, на уровне планирования программы проектов используется почти водопадная модель с этапами и результатами по этапам. С этапами обычно связаны не только результаты, но и платежи. Почти водопадная, потому что дорожная карта программы может включать этапы, которые идут с наложением по срокам или параллельно.
На операционном уровне объем работ делится на итерации с валидацией результатов каждой итерации. Например, применяется Scrum и его расширенные девиации в виде SAFe и других.
Также некоторые команды могут использовать Kanban. Например, Kanban обычно используется командой сопровождения уровня L2.
Для идентификации зависимостей между командами, для разработки единого плана, используются элементы SAFe, например, планирование инкремента продукта.
Во-вторых, набор применяемых подходов может меняться в зависимости от задачи.
Например, команда, которая работала на этапе разработки по Scrum-у, затем выпустила продукт в прод, начинает поддерживать релиз и параллельно вести разработку новых фичей (если придерживаться принципа “you build it, you own it”, то продукт получается, как правило, более качественным и живет дольше). Таким образом, у команды после выхода в прод релиза может возникнуть дополнительный поток работ, связанный с необходимостью решения критических задач технической поддержки. Тогда часть ресурсов команды планируется на работы по поддержке, а часть на работы по разработки. Как выполняется планирование и организация работ на практике тема отдельной статьи.
Небольшой итог
В принципе возможно себе представить проект, в котором используется одна методология. Действительно методология, а не подход, с определенными шаблонами документов, определенной последовательностью разработки документов. Например, проекты по внедрению “готовых” бизнес приложений используют методологии, специально разработанные для внедрения конкретно этих бизнес приложений. Например, ASAP, Oracle AIM, Oracle AIM for BF и другие.
Либо можно представить себе небольшой проект по разработке и развитию продукта, работающий по Scrum.
Но мне сложно себе представить программу проектов по разработке ПО, в котором использовалась бы одна методология или подход, просто потому что на каждом горизонте планирования, для каждой задачи требуется выбрать наиболее оптимальный инструмент.
4. О влиянии архитектурных решений на успех проекта
Архитектура определяет, насколько эффективным будет решение с точки зрения достижения функциональных и нефункциональных требований. Сложно переоценить влияние архитектуры на конечный результат. Поэтому хотелось бы уточнить некоторые моменты, связанные с разработкой архитектуры и влиянии архитектурных решений на проект разработки продукта на базе микросервисной архитектуры.
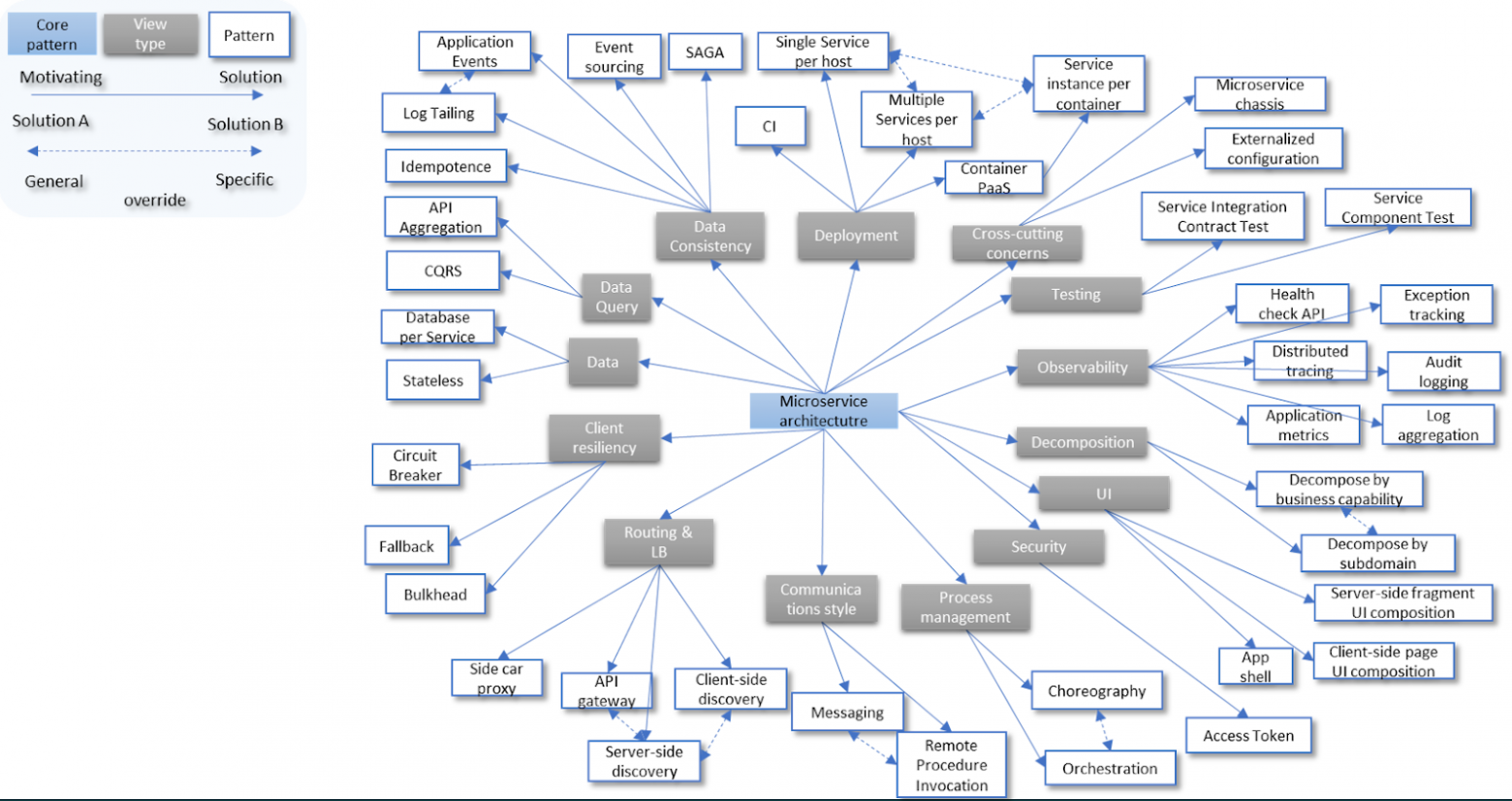
Думаю, каждая команда архитекторов сталкивалась с задачей решить следующие принципиальные вопросы:
Каким образом провести архитектурные границы между сервисами и компонентами?
Какой инструмент выбрать для управления распределенными транзакциями и реализации компенсационной логики? Каким образом обеспечить консистентность данных в условиях децентрализации данных? Как реализовать устойчивую к ненадежным сетевым взаимодействиям архитектуру?
Как использовать по определению монолитные подсистемы, которые не умеют масштабироваться горизонтально достаточно хорошо, и при этом удовлетворить NFR-ам. Я имею ввиду в первую очередь реляционные базы данных.
Темы достаточно обширные и напрямую не относятся к управлению. Но при этом сильно влияют на конечный результат. В рамках данной статьи нам только потребуется применить допущения и ограничения, чтобы можно было двигаться дальше.
В качестве допущений можно взять какое-то кол-во сервисов, например, 100. Допустим, для управления распределенными транзакциями, используется решение с отдельным сервисом-оркестратором. Также в соответствии с архитектурным решением, несколько сервисов могут работать с одним кластером БД.
4.1. Повторное использование кода. Прототипирование. Стандартизация
Во-первых, хотелось бы уточнить, что под кол-вом сервисов здесь понимается не кол-во подов в OpenShift, а кол-во репозиториев в системе контроля версий, например, в Git.
Если определенное архитектурное решение приводит к периодическим изменения большинства сервисов, то подобное решение следует по крайней мере подвергнуть дополнительному критическому анализу.
Например, достаточно легко представить себе, что в проекте используется Spring Framework. И через некоторое время развития проекта возникает задача перейти на новую версию Spring Framework (например, в части Spring Boot) для всего проекта. Это означает, что необходимо сделать как минимум 100 сборок с запуском тестов, сохранить 100 новых артефактов в репозиторий артефактов, выполнить 100*N (где N-кол-во сред в pipeline) деплоиментов на среды и другие работы, связанные с тестированием и развертыванием новых версий сервисов. Хорошо, когда проект уже находится в достаточно зрелой фазе, и все этапы автоматизированы. Но так бывает не везде и не всегда. Я не говорю о том, что использовать Spring не нужно. К счастью библиотеки Spring достаточно стабильны и не требуют постоянного повышения версии.
Но легко себе представить ситуацию, когда, следуя предыдущему опыту разработки, команда решит разработать библиотеку или набор библиотек, чтобы инкапсулировать в библиотеке какой-то общий код. Это известная проблема разделяемых библиотек в условиях микросервисной архитектуры, см. например, в Sam Newman, Building Microservices.
К сожалению, иногда решения делать свои библиотеки и встраивать их в микросервисы встречаются. Не выглядит очевидным тот факт, что небольшое дублирование кода в рамках микросервисной архитектуры, как правило, оказывается дешевле, чем сильная связанность (high coupling) компонент и борьба с гонкой версий в результате использования разделяемых библиотек. Что, кстати совершенно неверно, например, для монолитного решения. Где повторное использование кода – это отлично работающая практика. Не очевидно, если не сделать ретроспективный анализ затрат на разработку и сопровождение. Тогда правильное решение становится очевидным, и обычно приводит к изменению архитектуры таким образом, чтобы избавиться от разделяемых библиотек.
Конечно, нужно описывать принятые на проекте подходы к решению типичных задач, например, в confluence, или сделать архетип микросервиса и коммитить шаблон кода в git. Чтобы команды не изобретали велосипед и имели возможность делать повторяющуюся работу наиболее эффективным образом. Но допустим, у вас на столе решение, которое подразумевает создание библиотеки. Можно всегда задать себе проверочный вопрос, настолько ли эта библиотека необходима? Или: можно ли вместо библиотеки сделать микросервис? В любом случае разработка библиотек с бизнес логикой или структурами сообщений, подключение как зависимости нескольких даже не очень часто изменяемых библиотек в код микросервисов, может превратить микросервисную архитектуру в распределенный монолит со всеми недостатками и монолита и микросервисов.
Если же мы делаем библиотеку, например, для системных целей, то давайте хотя бы вспомним принцип открытости-закрытости, отделим мух от котлет, а интерфейс от реализации. Еще лучше, если положить API библиотеки в отдельный репозиторий, а реализацию в другой. Все же лучше давать возможность переопределять поведение методов на уровне потребителя библиотеки.
То же самое можно сказать и про общие подходы, которые могут повлиять на большое кол-во сервисов, на сервисы или естественные монолиты (базы данных, например), которые используются большим кол-вом сервисов. Перед тем, как предлагать какое-то общесистемное решение, хорошим подходом будет сделать end-to-end работающий прототип, интегрировать с несколькими сервисами, установить на стенд тестирования и валидировать решение с т.з. функциональных и нефункциональных требований. И только затем делать развертывание решения на остальные микросервисы. Т.е. подход путем создания PoC, валидации решений на соответствие требованиям через PoC как правило применялся достаточно эффективно, помогал снижать технологические риски и риски влияния на большое кол-во команд разработки из-за доработок или переделок общесистемных решений.
В качестве еще одного преимущества разработки решения на базе микросервисной архитектуры часто упоминается возможность применить тот язык программирования, который наиболее подходит для решения конкретной задачи. Например, какие-то сервисы могут быть написаны на java, а сервис, который использует алгоритмы машинного обучения на питоне или на C++. Но с точки зрения управления, имеет смысл определить минимальный базис в пространстве возможных технологий и зафиксировать технологический стек. По крайней мере в дальнейшем будет возможность балансировать или ротировать между командами ресурсы при необходимости и выполнять техническую поддержку эффективно.
Даже более того, с т.з. снижения затрат и возможности балансировки ресурсов критически важно стандартизировать подходы к разработке. Например, хорошей практикой было, когда на самом раннем этапе архитекторы и ключевые разработчики фиксировали такие подходы как: подход к оформлению кода, правила описания REST API, работа с логированием, трассировкой, работой с типами данных дата/время, правила описания форматов сообщений кафка, использование общих подходов при работе с разделяемыми ресурсами, например, с пулом соединений БД, определение архетипа микросервиса (шаблона микросервиса) Т.е. кажется разумным стандартизировать те инструменты и подходы, которые затрагивают практически все сервисы или затрагивают разделяемые сервисами общие ресурсы. Остается удивляться, почему это не всегда делается или делается, но не сразу?:)
Приведу простой пример. Можно на самом раннем этапе разработки попросить команду разработки в специальном формате сделать комментарий в файле application.yaml для каждого из параметров микросервиса. Для команды разработки данное требование не влечет каких-то значимых затрат. Тогда системный инженер, тестировщик или специалист службы поддержки смогут, не отвлекая команду разработки, узнать какой конкретно параметр на что влияет, прочитать из первоисточника, из кода в системе контроля версий прямо из той ветки кода, на основании которой собран артефакт. При необходимости, системный инженер может сгенерировать список параметров с описанием параметров и их значений в конкретном неймспейсе и передать такой инструмент тестировщикам или команде сопровождения. При этом выгружаться всегда будет самая актуальная информация автоматически, т.к. информация базируется на данных контроля версий. Это, как говорится, «мелочь, но приятно». Из таких мелочей могут складываться в итоге сэкономленные на этапе тестирования, сопровождения сотни и тысячи человеко-часов.
4.2. Зависимости. Наиболее устойчивые компоненты
Если бы меня спросили, на что в первую очередь следует обращать внимание менеджеру при анализе архитектурных решений, то я бы ответил, что на те артефакты, которые могут показать кол-во зависимостей между компонентами системы и указать на сложность и трудоемкость разработки компонентов. Для меня такими артефактами в первую очередь являются компонентная диаграмма и диаграмма последовательностей. Компонентная диаграмма показывает в статике зависимости между компонентами. А Диаграмма последовательностей отражает поведение, будущий алгоритм работы. Ведь чем сложней поведение, тем как правило сложней и более трудоемко проверить на соответствие критериям качества разработанного кода компонента (т.е. выполнить тестирование).
Также анализ зависимостей может помочь в выявлении тех компонент, которые являются наиболее устойчивыми и при этом могут находиться в “зоне боли”. Это такие компоненты, от работы которых зависят другие компоненты или используются другими компонентами, и при этом сами компоненты достаточно конкретные, не абстрактные. В книге «Чистая архитектура. Искусство разработки программного обеспечения» Мартина Роберта очень доступно описано, на каких принципах строится архитектура приложений, даны определения устойчивости, абстрактности компонент.
Для чего менеджеру нужно знать зависимости и компоненты, которые должны быть наиболее устойчивыми?
Анализ зависимостей поможет в создании эффективной организационной структуры. Об этом уже упоминалось выше.
А выявление устойчивых и конкретных компонент поможет выявить технологические риски и разработать план митигации рисков.
Приведу небольшие примеры.
Пример 1
Мы уже определились чуть выше с решением проблемы распределенных транзакций путем выбора решения с оркестратором распределенных транзакций. На текущий момент (2020 год) существует не так много решений, которые позволяли бы конфигурировать и оркестровать асинхронные транзакции с использованием паттерна saga. Это Uber Cadence и Netflix Conductor. Можно попробовать применить BPM движок для оркестрации, если позволяют NFRs.
В одном из разрабатываемых решений бизнес логика в рамках транзакций могла быть достаточно сложной, обработка транзакции выполняться десятком сервисов, при достаточно жестких нефункциональных требованиях. Поэтому команда архитекторов предложила использовать Uber Cadence в качестве оркестратора.
Данный компонент использовался для обработки практически всеми бизнес сервисами. Поэтому было очень критично проверить данный компонент с т.з. соответствия нефункциональным требованиям в рамках нагрузочного тестирования различных типов. К общему облегчению (архитекторов, менеджеров со стороны Исполнителя и со стороны Заказчика) данный компонент прошел все виды тестов кроме DR теста в части продолжения выполнения незавершенных транзакций после переключения в резервный ЦОД. С учетом особенностей системы, когда пользователями системы являлись внешние системы, а в решении применялся паттерн retry, подразумевавший возможность выполнить повторный запрос со стороны внешней системы, то данное ограничение не являлось блокирующим, и система была принята в эксплуатацию.
Пример 2
В одном из проектов по разработке платформы для крупного Банка исходя из требований к производительности к новой системы команда архитекторов предложила использовать в качестве распределенного L2 кэша и в качестве compute grid компонент Apache Ignite. В то же время в соответствии с нефункциональными требованиями RPO и RTO стремились к нулю. Практически все компоненты, которые сохраняли данные, (т.е. компоненты с сохранением состояния), должны были использовать Apache Ignite как средство хранения данных в оперативной памяти. Некоторые из критических компонент должны были использовать его как compute grid.
На тот момент (2017 год) Apache Ignite не работал в продуктивной эксплуатации в решениях, для которых предъявлялись такого же уровня нефункциональные требования, которые предъявлялись к разрабатываемой системе. В итоге был идентифицирован технологический риск. Как средство митигации риска были запланированы стресс тест и DR тест. В результате данных тестов пришлось изменить требования к производительности, убрать Apache Ignite из стека проекта, оставив достаточно строгие требования в части RPO и RTO, которые были для Заказчика более критичны.
Таким образом, для наиболее устойчивых компонент очень важно успешно выполнить все виды нагрузочного тестирования, включая DR и стресс тест.
4.3. Контроль ресурсов
Одним из достоинств микросервисной архитектуры является возможность создать горизонтально масштабируемую систему. И это действительно так. Но до некоторого предела.
К сожалению, любая микросервисная архитектура имеет границу после которой заканчивается мир микросервисов и начинаются другие миры: мир подсистем виртуализации, управления контейнерами, кластеров баз данных, кластеров брокеров сообщений, систем хранения данных. В конечном счете несколько сервисов могут быть скалированы в несколько подов и поды развернуты автоматически на разных рабочих нодах кластера Kubernetes. Кол-во нод и размер RAM, если и не является ограниченным ресурсом в рамках выделенного ЦОДа, то точно стоит денег при развертывании в облаке. Если несколько сервисов работает с кластером базы данных, то кол-во открытых соединений и время удержания открытых соединений сервисами, частота, время выполнения запросов могут драматически влиять на работу кластера. Место на СХД, IOPS, которые может предоставить СХД также ограничены.
Для менеджера это означает, что изменения требований, доработки могут влиять на ресурсы и нести дополнительные риски. Поэтому желательно вместе с архитекторами и системными инженерами вести контроль ресурсов и учитывать влияние изменений на ресурсы, которые как правило всегда ограничены. Тогда можно на раннем этапе снизить риск, например, таких ситуаций, когда при добавлении таблицы в схему одного из сервисов может стать недостаточным место на СХД.
Дополнительно силами команды системных инженеров можно выполнять регулярное ревью части кода, которая отвечает за контейнеризацию и развертывание контейнера в Kubernetes. Чтобы возможные проблемы выявлять заранее, а не в результате системного мониторинга использования ресурсов или еще хуже, когда проблема сама о себе заявит путем срабатывания предупреждения системы мониторинга в проде.
4.4. Конфигурация сервисов, общий контекст
В данном случае не идет речь про boundary context. Здесь мне проще пояснить на примере решаемую задачу.
Допустим есть требование реализовать авторизацию на базе RBAC модели.
И также есть требование централизованного администрирования ролей пользователей.
Допустим мы определили матрицу ролей и полномочий пользователей для каждого стрима, описали права в разрезе фичей бизнес сервисов. Для реализации возможности конфигурирования ролей пользователей требуется собирать роли пользователей в базе одного из технологических сервисов и предоставлять API для администрирования.
Т.е. каждый бизнес сервис должен уметь опубликовать роли, например, в момент деплоя или старта микросервиса. В случае изменения перечня ролей у пользователя через API технологического сервиса каждый сервис должен получить часть общего контекста конфигурации, хранящейся в данном общем сервисе. Более того, при межсервисном взаимодействии требуется передать информацию о контексте в части ролей пользователя, чтобы другой сервис смог выполнить проверку прав доступа к своим фичам.
С технической точки зрения, здесь нет ничего сложного. Можно публиковать роли несколькими способами и несколькими способами публиковать информацию об изменениях перечня ролей пользователей. Можно решить вопрос с передачей контекста через RESP API и Kafka.
С точки зрения внедрения подобного решения задача превращается в создание общих правил разработки и процесса контроля выполнения данных правил. Важно, чтобы команда архитекторов и разработчиков, разрабатывающая механизмы и подходы управления доступом, принимала активное участие в контроле хода внедрения. Иначе на этапе интеграции сервисов можно получить очень долго сходящийся чарт с дефектами, относящимися к контролю доступа пользователей.
4.5. Простота сопровождения
Несмотря на общую правильность принятых архитектурных решений, новое решение может оказаться достаточно сложным в последующем сопровождении и поддержке, сложным в развитии, добавление новых фичей может стать дорогим и долгим мероприятием. Почему так происходит, и как этого избежать? Наверное, в первую очередь стоит вспомнить в данном разделе принцип KISS (keep it simple, silly). Также просто замечательно, если архитекторы, разработчики задумываются на этапе проектирования о сопровождении и при выборе различных вариантов принимают во внимание в том числе и требования поддержки. Чтобы мотивировать архитекторов и разработчиков задумываться о нуждах поддержки на этапе проектирования можно попробовать привлечь к согласованию архитектурных решений системных инженеров и специалистов, которые имеют реальный опыт сопровождения подобного класса решений в продуктивной эксплуатации. Также иногда неплохо работает подход, когда разработанное решение поддерживается той же командой, что спроектировала и разработала решение.
К сожалению, не могу сказать, что в тех проектах, где приходилось участвовать, вопросам поддержки уделялось достаточное внимание еще на этапе разработки архитектуры. Из-за разных причин, в основном из-за цейтнота в условиях разработки решения по контракту с фиксированной ценой. Также не могу сказать, что внимание не уделялось совсем. Как соблюсти правильный баланс? Этот вопрос для меня остается открытым.
Пример
В одном из проектов команда архитектуры приняла решение создать отдельный микросервис для каждого справочника. Получилось порядка 30-ти микросервисов. Среди данных микросервисов только 2, максимум 3 сервиса действительно стоило выделить в отдельные сервисы (счет, клиент, подразделения банка). Остальные 27 были достаточно небольшими статическими справочниками, которые можно было объединить в один микросервис. Вместо этого мы сделали 30 микросервисов. При изменении общесистемных требований, которые влияли на большинство сервисов (логирование, пагинация, поиск и т.п.) приходилось выпускать 30 артефактов. Плюс нужно мониторить работу данных сервисов, плюс каждый сервис требует ресурсов. Насколько мне известно, команда уже исправила эту архитектурную ошибку.
5. Процессы и подходы
В данном разделе хотелось бы поделиться некоторыми наблюдениями, практиками и открытыми вопросами в области построения и внедрения процессов разработки с учетом особенностей, которые накладывает микросервисная архитектура.
5.1. Разработка и тестирование
5.1.1. Интеграционное тестирование, постоянная интеграция компонент
Основной вызов в проектах, в которых мне приходилось участвовать, находился в области валидации корректной работы интеграционных сценариев и постоянной интеграции микросервисов. Можно разработать отдельные микросервисы достаточно быстро и качественно, создав набор Unit-тестов для валидации работы отдельного сервиса. И уже на этапе прекоммита путем запуска CI-процедур валидировать качество кода отдельного сервиса путем запуска unit-тестов.
Но как выстроить процесс постоянной интеграции в проекте с сотней сервисов и нескольким десятков команд разработки? Каким образом не допускать проблем интеграции, ошибок в API или выявлять ошибки на самом раннем этапе? Хотелось бы сразу заметить, что если отпустить каждую команду разработки на время, сказав, что мы встретимся через месяц или 2 на этапе интеграционного тестирования, то скорей всего, этап интеграционного тестирования просто невозможно будет измерить во времени. Лучше спланировать работу таким образом, чтобы как можно чаще компоненты развертывались на среде интеграционного тестирования и регулярно выполнялись интеграционные сценарии. По крайней мере не реже чем раз в спринт.
Хотел бы перечислить ниже те подходы, которые работали хорошо. И это не значит, что нельзя сделать еще лучше.
1. Contract first. Интеграция на уровне контрактов
Разработка начиналась с фиксирования контрактов и тестов работы контрактов. Команды описывали контракт применяя подход OpenAPI, делали коммит в репозиторий с API, включая примеры запросов и ответов. Далее разрабатывали интеграционный сценарий, выполняли совместное ревью контрактов и сценариев. Тем самым снижались риски получения дефектов на среде интеграционного тестирования. Разработка начиналась с разработки API на mock-ах с валидацией работы контракта на общем окружении. Это касается и REST API между бэком и фронтом, и API для межсервисного взаимодействия (например, разработки Feign Client), и передачи сообщений kafka.
Думаю, стоит немного уточнить, что здесь называется контрактом. В данном случае контракт - это не только структура и набор полей в json, описывающий передаваемый DTO, это еще и контракт в части типов полей, примеров заполнения полей и самое главное, описание ожидаемого поведения одного компонента от другого компонента.
Каким образом описать ожидаемое поведение с примерами запросов и ответов?
Во-первых, при разработке контракта со стороны сервиса - поставщика контракта прикладывались примеры запросов и ответов. Сам контракт проходил ревью со стороны сервисов потребителей.
Во-вторых, со стороны сервиса, который использует контракт другого сервиса, разрабатывались сценарии. Идеально с использованием Gherkin. А со стороны сервиса поставщика контракта, выполнялось ревью сценариев.
Причем на самом раннем этапе проекта я бы предложил сложить все контракты в 1 репозиторий (да, это напоминает монолит, предлагаю вспомнить совет Мартина Фаулера, “Monolith first”). В разные папки, конечно. С обязательным привлечением к ревью лидов тех компонент, которые потребляют измененный контракт и с привлечением архитекторов для ревью всех без исключения коммитов в части изменения АПИ. В итоге затраты на ревью, некоторые неудобства монолитности единого репозитория с контрактами окупится в дальнейшем меньшим объемом доработок и дефектов. Открытый вопрос, который здесь возникает, в какой момент времени и каким образом нужно перейти от единого репозитория с АПИ к нескольким независимым артефактам. Предлагаю оставить этот вопрос пока открытым.
2. Выполнение DoD проверяется на стенде интеграционного тестирования
Любые демонстрации новых фичей владельцу продукта проводились только на среде интеграционного тестирования. Самые ранние первые релизы ставились на среду интеграции.
Чем раньше команда разработки узнает, что компонент должен развернуться и работать достаточно стабильно не только на стенде разработки, но и на общем стенде, тем быстрей команда начнет заниматься автоматизацией развертывания и учиться проходить установленные для интеграционного стенда критерии качества.
3. Quality gate для установки на интеграционных стенд
Правила развертывания на интеграционный стенд в большей степени повторяли правила развертывания в прод.
Таким образом, можно было выставить критерии качества к процедурам развертывания, к качеству кода для всех компонент, контролировать исполнение и прохождение критериев отдельными командами. Например, правило установки номера версии в соответствии с https://semver.org/ очень помогало выстраивать коммуникации между командами. Если команда, которая использует сервис-поставщика контракта видит, что поменялся номер патча этого сервиса, то значит версия обратно совместима. И если с повышением номера патча контракт перестает работать так, как ожидалось, то, это баг, незапланированное изменение. Нужно либо вернуть обратную совместимость, либо запланировать доработки совместно с сервисами потребителями, либо исправить дефект.
Не секрет, что чем на более позднем этапе выявлен дефект, тем дороже его исправление, дороже иногда на порядки. Отдельные недоработки, отсутствие функциональности на ранних этапах разработки допустимы. Но наличие дефектов, неработоспособность того, что должно работать не ломая интеграционный тест, лучше сразу делать предметом работы над ошибками с целью исправить подход сейчас, чтобы не терять темп в будущем. Причины могут оказаться совершенно разными, например, часто команды под давлением менеджеров торопились, не закончив внутренние тесты или регрессионные тесты, выдавали артефакт на среду интеграции. Поэтому важно контролировать выполнение критериев качества для поставки на среду интеграции. Еще раз повторю, данные критерии должны быть такими, как будто мы ставим артефакт в прод.
4. Привлечение поддержки к интеграции
К поддержке работоспособности стенда, к разбору ошибок на самом раннем этапе привлекались будущие специалисты сопровождения уровней L2, L3.
Это позволяло специалистом сопровождения узнать о решении гораздо больше, чем они могли бы узнать из последующего обучения.
5. Поддержка обратной совместимости
Начиная с определенного этапа разработки, от команд разработки требовалось планировать работы с учетом поддержки обратной совместимости. На каком этапе требовать от команд поддерживать обратную совместимость? С одной стороны, у нас есть контракт, и интеграционные тесты, которые могут не полностью покрывать все сценарии тестирования и все сценарии использования тем более. С другой стороны, есть план работ, и не все фичи, которые могут повлиять на изменение контракта (включая ожидаемое потребителем поведение) еще могут быть разработаны, чтобы достоверно сказать, что контракт уже не поменяется и достаточно стабилен. Обычно, когда успешно прошел первый интеграционный тест между компонентами, и по всем фичам закончен технический дизайн, выполнено ревью контрактов, можно начинать требовать обратную совместимость от сервисов-поставщиков контракта.
6. Отладка и тестирование с возможностью подключения к интеграционному стенду
Хорошей практикой является интеграция среды разработки при отладке и тестировании сервисов-потребителей контракта с сервисами-поставщиками контакта, развернутыми на более стабильной среде (среде интеграционного тестирования). Это позволит, во-первых, снизить затраты на инфраструктуру (не нужно деплоить в среду разработки отдельной команды дополнительные сервисы другой команды). А, во-вторых, командам разработки снизить работы по развертыванию и поддержке на своих стендах сервисов для тестирования, от которых они зависят. Командам разработки компонент, от которых зависят другие компоненты, данный подход привьет культуру выпуска стабильных версий компонент на среду интеграционного тестирования и поддержке обратной совместимости. Это позволяло на раннем этапе выявить возможные нарушения обратной совместимости сервисами-поставщиками контракта. Параллельно экономить ресурсы RAM кластера OpenShifit в контуре разработки.
7. Использование BDD
Имеет смысл использовать BDD для интеграционного тестирования, в частности описывать сценарии в формализованном виде на самом раннем этапе (идеально еще на этапе анализа). Это также означает, что у вас либо уже есть фреймворк автоматизации для конкретной доменной области, либо вы до начала разработки начали создавать сценарии и автоматизировать ключевые слова сценариев (например, описанных при помощи Gherkin). Тогда на последующих этапах можно сэкономить за счет автоматически повторяемых регрессионных тестов, за счет более раннего выявления дефектов.
Еще одно преимущество BDD состоит в том, что если меняются требования и меняется пользовательский сценарий, мы можем уточнить совместно с бизнес анализом перечень формально описанных сценариев тестирования, которые изменятся. Таким образом, с одной стороны сужая требуемый объем тестирования и с другой стороны уточняя скоуп доработок.
Слабой стороной BDD являются предпосылки, при которых этот подход работает. Иначе получится лишь имитация подхода. Это следующие предпосылки:
Cценарии тестирования описываются еще на этапе анализа и проектирования фичи, для описания используется структурированный язык, например Gherkin.
Ревью сценариев. Если кто-то пишет сценарии, то кто-то должен контролировать качество разработки сценариев. Поскольку сценарии разрабатываются до разработки кода, то к ревью может выполнить на данном этапе Команда аналитиков или ключевых пользователей, которые уже в контексте и обладают бизнес экспертизой. Не все аналитики могут или хотят даже читать Gherkin сценарии (требования к аналитикам возрастают). Как обходной путь можно включить в команду анализа тестировщика, желающего развиваться в аналитика, который сможет распространить культуру и митигировать недостаток экспертизы у аналитиков.
Чтобы эффективно автоматизировать сценарии Gherkin, часто применяют фреймворки. Фреймворк позволяет выделить часто используемые сценарии в операторы, ключевые слова. Например, "я как внешний пользователь, имея пароль и логин, когда выполняю аутентификацию по паролю и логину в личный кабинет, должен получить JWT, который пройдет валидацию". Чтобы ключевые слова (выделено курсивом) автоматизировать, и затем переиспользовать в других сценариях, нужны работающие компоненты подсистемы аутентификации или хотя бы моки сервиса аутентификации. А чтобы получить рабочие компоненты, нужно выполнить тестирование подсистемы. Похоже на проблему курицы и яйца. Т.е. получается, что фреймворк нужно писать параллельно с системой и постоянно развивать. Часто в проектах с фиксированной ценой, выполняемых по водопадной модели обеспечить итерационный параллельный подход не получается.
8. Автоматизация интеграционных сценариев.
BDD подход прекрасно совмещается с автоматизацией интеграционных сценариев.
Если взять интеграционные сценарии и проранжировать их по стоимости автоматизации и по приоритету (например, выбрать сценарий, которые затрагивает наиболее устойчивые компоненты). То очевидно, что можно определить наиболее критичные и самые дешевые сценарии, чтобы запланировать их к реализации в первую очередь либо силами команды автоматизированного тестирования, либо силами команды разработки.
Например, сценарий двухфакторной аутентификации. Этот сценарий затрагивает сразу несколько критических компонент бэка, таких как api-gateway, сервис аутентификации, OTP, нотификаций по SMS. Во-вторых, с точки зрения автоматизации не является сильно трудозатратным, но является переиспользуемым в других тестах.
Имеет смысл также запланировать ночные сборки с последующем запуском автоматизированных интеграционных тестов.
9. Стабильность и доступность интеграционной среды
Желательно определить, какие из компонент должны быть наиболее стабильными, чтобы не пришлось постоянно чинить среду интеграционного тестирования. Возможно, обновление таких компонентов на интеграционной среде будет построено несколько иначе, с большим вниманием к качеству, к подходу к развертыванию и откату. Например, развертывать их в режиме blue green deployment, чтобы не оказывать влияние на большой проект, не вызвать простой проектной команды.
Что работало не очень хорошо или работало, но могло бы работать лучше?
Скорей всего, не работало, потому что мы просто не научились использовать данные подходы и технологии. Тем не менее.
Consumer Driven Contract, например с использованием библиотеки PACT.
Идея выглядит красиво. И в принципе есть здравый смысл в том, чтобы использовать при тестировании компонента-поставщика контракта тесты, которые написаны компонентом-потребителем контракта. Например, для тестирования интеграции между фронтом и бэком.
Но внедрение подхода и в частности библиотеки PACT требует существенной доработки CI/CD и как, оказалось, необходимы доработки в самой библиотеке, когда нужно сделать реальный интеграционный тест. Т.е. затраты на тестирование с данным подходом превышают затраты на разработку автотестов с использованием более классических подходов.
Test containers. Несмотря на то, что этот подход действительно работает, он достаточно дорогой во внедрении. Можно применять в достаточно сложных случаях интеграции для валидации критических компонент.
Попытки применить waterfall подход для разработки на базе микросервсной архитектуры и особенно в части интеграционного тестирования, выделить интеграционное тестирование в некоторую фазу. Такой подход приводит к огромным рискам задержек в поставке, снижению качества системы, ненужному героизму на данном этапе интеграции и выгоранию команды.
Конечно важно контролировать зависимости и планировать инкремент продукта. Но не надо ждать пока все разработки будут закончены. Важно интегрировать контракты на как можно раннем этапе.
5.1.2. Стратегия бранчевания
В проектах использовали стратегию бранчевания GitFlow с релизными ветками с небольшими девиациями.
Одним из преимуществ данной стратегии состоит в том, что она предлагает явные итерации разработки фичей, которые должны войти в следующий релиз и этап стабилизации релиза. Эти итерации хорошо комбинируются с недельными циклами всегда можно сделать кратными длине спринта в Scrum.

5.1.3. Ревью кода
Возможно это выглядит банальным, но если в проекте больше сотни репозиториев кода, в разработку вовлечено несколько десятков команд разработки желательно установить правила ревью, общие для всех команд.
Очень желательно начать с установки в качестве владельца репозитория кода компонента лидера команды разработки данного компонента. Таким образом фиксируется владелец и персональная ответственность владельца за качество того кода, который находится в репозитории. Установка процедуры ревью в команде, контроль исполнения процедур ревью – это ответственность лидера разработки.
Поэтому было очень странно узнать в одном из проектов, что владельцем репозиториев являются архитекторы, а не лиды разработки. Что приводило к небольшому недопониманию в процессе выдачи прав на репозитории.
Как инструмент для ревью кода обычно в проектах разработки используем Gerrit.
В качестве подхода используется как минимум двухстадийный процесс ревью, с использованием pull request, когда ревью должны сделать 1 или несколько коллег, а вливать код в ветку develop на основании pull request может либо лидер разработки, либо в его отсутствие тот, кто его замещает.
5.2. Технический дизайн
Это процесс и одновременно этап в SDLC продукта или отдельной фичи, который позволяет трансформировать архитектурное решение в набор конкретных задач разработки с указанием конкретных подходов, инструментов языка программирования с учетом существующей кодовой базы.
В общем случае в качестве результата работы архитектора можно получить набор схем и диаграмм, отражающих принципиальные связи между компонентами системы.
Чтобы данные схемы и диаграммы превратились в работающий код, требуется сделать дополнительное более детальное проектирование и планирование. Например, уточнить какие классы должны быть созданы или изменены в каких слоях приложения, с каких компонент лучше начать разработку. В этом заключается суть технического дизайна.
Технический дизайн выполняется совместно, как архитектором так и лидом разработки. Как правило , лид разработки готовит тех дизайн, ревью делает архитектор.
В качестве результатов технического дизайна можно ожидать, что будут определены конкретные компоненты, слои внутри компонент, в которых требуется доработка. Будет описаны детали реализации в виде диаграмм классов или API. Будут созданы задачи в джире, оценена трудоемкость и порядок разработки.
К процессу ревью технического дизайна кроме лида разработки и архитектора также подключаются деливери менеджер, лид тестирования и лиды разработки зависимых компонент.
5.3. Этапы поставки и контроль качества
Каждая разработка, фича проходит заранее определенные этапы жизненного цикла. При этом качество результатов, получаемых на выходе одного этапа, влияет на качество результатов, которые будут получены на следующем этапе. Возникает задача определения критериев качества артефактов, получаемых на каждом из этапов.
Например, возьмем набор сторей в джире, которые формируют бэклог продукта. Очень желательно определить критерии качества сторей, которые могут быть взяты в следующий спринт командой разработки. Часто такие критерии называются Definition of Ready сторей разработки. Например, закончен ли технических дизайн, выполнены ли оценки, определен ли сценарий демонстрации фичи, определен ли DoD для стори, выполнялась ли командой разработки с привлечением аналитиков и тестировщиков декомпозиция, анализ стори и т.п.
Очень часто приходилось наблюдать, как команды по каким-то причинам не уделяли достаточного внимания разбиению требований на стори, на участие команды в декомпозиции задач стори, на описание того, что же в итоге должно быть сделано. При этом не нужно описывать трактаты в джире. Важно, чтобы каждый участник процесса разработки понял, что должно быть сделано, и ожидаемые результаты зафиксированы в виде чек листа DoD и задач. В противном случае аналитики, архитекторы, разработчики и тестировщики вместо того, чтобы фокусироваться на решении конкретных задач в рамках ограниченного во времени спринта будут пытаться в течение спринта завершить то, что должно быть сделано в рамках предыдущего спринта – завершить анализ или технических дизайн, декомпозировать задачи, отвлекая друг друга.
Для этапа разработки и тестирования также определяются критерии качества (Definition of Done), такие как успешное прохождение сценариев тестирование и публикация отчета о тестировании, например в report portal, и другие критерии.
Еще раз хотел бы подчеркнуть, что если есть вопросы к качеству результатов определенного этапа разработки, то имеет смысл в первую очередь проверить критерии качества артефактов на входе данный этап.
5.4. DevSecOps
По статистике CI/CD сервера на одном из проектов с 20-ю командами разработки, которые разрабатывали около 100 микросервисов, ежемесячно в пиковые месяцы выполнялось до 4 тыс сборок, 6 тыс деплойментов (включая среды разработки), 11 тыс прекоммитных проверок, 2.5 тыс посткоммитных проверок и другие задачи. После вывода в опытную эксплуатацию решения ежедневно на продуктивную среду доставлялось до 10-15 hot-fix версий микросервисов. Проект выполнялся бы гораздо медленней и темпы разработки были бы гораздо ниже, если бы процессы CI/CD не были бы автоматизированы. Думаю, что очень большая доля успеха проекта по разработке решения на микросервисной архитектуре приходится на область автоматизации CI/CD процессов, проверок выполнения обязательных шагов процесса, процессов тестирования, проверок соответствия артефактам критериям качества.

Для проекта разработки с несколькими сотнями разработчиков и тестировщиков час простоя кластера сред разработки и тестирования, серверов CI/CD стоят несколько человеко недель или даже человеко-месяцев. Поэтому к инфраструктуре сред разработки и тестирования предъявляются соответствующие требования отказоустойчивости, масштабируемости. Обязательно использование средств мониторинга инфраструктуры сред разработки и тестирования.
Интересный случай, который повторялся дважды на двух разных проектах. На ранних этапах проекта, когда не все скрипты по запуску инфраструктуры были отлажены, были попытки со стороны спонсора проекта экономить на ресурсах сред разработки, останавливая кластера разработки в облаке на ночные часы. Однако последующее восстановление работы, прогрев серверов отнимал время команды и в итоге стоимость простоя команды в первый час рабочего дня была больше, чем стоимость инфраструктуры. Экономить на инфраструктуре становилось возможным только когда автоматизация была отлажена.
В тех проектах, где мне приходилось участвовать, использовался акселератор для автоматизации CI/CD. Это специализированная платформа, опробованная на нескольких проектах. Данная платформа разворачивалась в облаке, например, в AWS и/или на серверах. При установке платформы автоматически развертывается кластер OpenShift, SonarQube, Nexus, Jenkins, ELK, Grafana, Kibana, Gerrit, Git, дэшборды для мониторинга и др. компоненты. Из коробки сразу доступны Jenkins-задания для пре-коммитов, пост-коммитов, сборки кода, сборки сервиса в контейнер, задания включают проверки на соответствия процессам ревью кода, стратегии бранчевания, присвоения версии компонента и др. В зависимости от выбранного на проекте подхода и стека устанавливаются инструменты автоматизированного функционального, нагрузочного тестирования, тестирования безопасности. К платформе прилагается стандартные поддерживаемые процессы CI/CD.
Если бы мы не использовали акселератор, то перед выполнением проекта по разработке, следовало бы выполнить проект по созданию инфраструктуры и процесcов CI/CD. На подобный проект может потребоваться еще несколько месяцев.
5.5. Постоянное совершенствование процессов
Производство программного обеспечения очень похоже на дискретное производство и многие практики, которые используются в разработке ПО пришли в ИТ из реального производства.
Во-первых, это практика постоянных непрерывных улучшений (Кайдзен). Даже в самом передовом проекте всегда найдется множество вещей, которые можно улучшить.
Для того, чтобы понять, что можно улучшить, ретроспективы с командами просто необходимы.
Во-вторых, это практика бережливого производства LEAN. Практика помогает определить те процессы, которые увеличивают ценность продукта, и сконцентрироваться на улучшении именно этих процессов. Анализ процессов с точки зрения потерь также бывает полезен.
6. Внедрение
Разработать качественный продукт еще не означает что данным продуктом смогут воспользоваться конечные пользователи. Потому что кроме разработки продукта или решения, кроме тестирования, стабилизации требуется выполнять целый ряд работ с целью подготовить решение и внешние окружение к продуктивной эксплуатации.
Думаю, что лучше всех в вопросе планирования работ по внедрению решения в прод преуспели те компании, которые постоянно занимаются внедрением уже готовых платформ путем их конфигурации и настройки. Это мир ERP систем: SAP, OEBS, 1C и другие. Не уверен насчет 1С, но консультанты SAP или OEBS, по-моему, отлично планируют и выполняют проекты внедрения (не разработки). Как правило, используется методология с определенным списком результатов-документов, которые должны быть разработаны и перечнем работ, которые должны быть выполнены, чтобы внедрение было успешным. Выше уже упоминались такие методологии как ASAP, Oracle AIM.
Более того, некоторые компании пошли дальше. Значительные риски проекта могут лежать в области сопротивления конечных пользователей изменениям. Большинство людей вообще не очень любят изменения. Поэтому часто к большим проектам по внедрению, например внедрению SAP, подключается отдельная команда из практики, которая специализируется на Управлении изменениями. Задача этой команды сделать переход на новое решение для ключевых пользователей как можно более мягким, больше похожим на интересное захватывающее приключение, чем на постоянное преодоление самих себя. Команда выполняет планирование обучения пользователей и специалистов сопровождения; разрабатывает маркетинговых материалы о том «как и почему мы будем жить лучше с новой системой», планирует и внедряет изменения в организационной структуре, описывает изменения и внедряет новые рабочие процедуры и т.п.
Думаю, что деливери менеджер или менеджер по разработке не всегда может быть вовлечен в подобные активности. Здесь я просто хотел подчеркнуть, что путь до прода не обеспечивается только разработкой и тестированием. Часто требуется помогать коллегам, занимающимся внедрением, сделать переход как можно более мягким.
7. Мониторинг и сопровождение
7.1. Мониторинг
В чем точно команда разработки может помочь себе, системным инженерам и специалистам разных уровней поддержки, это в упрощении сопровождения и в детальном мониторинге работы системы.
Очень сложно представить, каким образом можно без мониторинга выполнять сопровождение системы, состоящей из нескольких сотен сервисов.
Как определить, работает ли сервис, работает ли он стабильно, есть ли проблемы и насколько проблемы критичны? На эти вопросы может ответить команда разработки, определив перечень бизнес метрик и системных метрик, которые будут собираться и передаваться в систему мониторинга. Чтобы при работе в проде держать на контроле все ключевые метрики и принимать соответствующие решения до возникновения инцидента. А в случае возникновения инцидента, максимально оперативно определить источник проблемы и восстановить нормальную работу.
Также иногда со стороны пользователей или со стороны Заказчика могут возникать вопросы о работе системы, об SLA. Система мониторинга часто позволяет ответить на вопросы о работе системы, используя фактический материал: показатели, метрики, статистику, накопленную в системе мониторинга.
Особенно важно отслеживать бизнес метрики, которые имеют денежное выражение.
Например, кол-во посылаемых системой SMS. Каждое SMS тарифицируется, стоит определенных денег. На основании профиля нагрузки можно настроить предупреждение (аллерт) на случай, если система не запланированно станет отправлять большее SMS чем обычно при определенном уровне нагрузки.
Неработоспособность некоторых компонентов может приносить убытки для пользователей прямо или опосредованно. Например, один из компонентов системы оказался на критическом пути. Компонент не успели протестировать во время нагрузочного тестирования. Во время эксплуатации компонент оказался недостаточно стабильным под нагрузкой. Компонент отвечал за передачу страховым компаниям информации о подтверждающих документах от страхователя при заключении полиса электронного ОСАГО. В этом виде страхования присутствует много мошенников, и если страховая компания не сможет проверить достоверность документов на этапе получения заявления от страхователя, то впоследствии может понести убытки. Мониторинг позволил выявить проблему и настроить обходной путь, пока команда разработки исправляла проблему в коде целевым образом.
Каким образом определить необходимый перечень метрик для мониторинга решения в прод? Заранее определить перечень метрик? Конечно, такое упражнение может быть полезным. Но без итераций, к сожалению, будет сложно выстроить качественную систему мониторинга.
Эффективным оказывался подход, когда мониторинг отлаживался в процессе выполнения нагрузочного тестирования. Несколько итераций выполнения нагрузочного тестирования позволяют настроить бизнес и системные метрики таким образом, чтобы иметь возможность осуществлять сопровождение решения в проде. Настройке и отладке мониторинга в процессе нагрузочного тестирования способствует близость характеристик стенда нагрузочного тестирования и продуктивной среды.
Определить перечень бизнес метрик помогали аналитики. Перечень системных метрик, мониторинг ресурсов разрабатывался вместе командой системных инженеров (DevOps) и командой нагрузочного тестирования.
7.2. Сопровождение
В рамках данной статьи предлагаю ограничиться только рассмотрением подходов в организации сопровождения 3-го уровня.
Какие виды работ обычно включают в понятие 3-го уровня сопровождения:
Технический мониторинг системы
Регулярные работы на проде, администрирование: бэкапирование, очистка, выполнение анализа запросов в БД и т.п.
Выполнение запросов по заданию: например, получить данные аудита или восстановить данные из бэкапа.
Планирование и контроль процесса установки обновлений на прод.
Выявление потенциальных проблем, которые могут влиять на стабильность работы.
Выявление дефектов и устранение дефектов в коде, которые могут влиять критически на работу системы в проде.
С точки зрения доступа к продуктивной системе все виды работы, кроме 6-ой подразумевают доступ к проду у команды, которая занимается сопровождением. Также можно сказать, что 6-ой вид работ подразумевает полный цикл работ по разработке, включая анализ требований, архитектуру, все виды тестирования.
Каким образом построить команду или команды L3?
Выбор подхода к построению команд сопровождения в Банках часто зависит от требований безопасности. Также могут приниматься во внимание и другие факторы: договорные обязательства и ограничения бюджетов (например, бюджет по договору разработки закончился, но есть договор сопровождения, и есть бюджет по данному договору).
Например, в Банках часто различают команды Run the Bank (поддержка и сопровождение прода) и Change the Bank (разработка, включая устранение дефектов). Команда разработки не имеет доступа к проду. Команда, занимающаяся сопровождением Прода не ведет разработку. Поскольку мой фокус находится в области разработки систем для финансовых институтов, то другие подходы к разделению ответственности встречались достаточно редко. Практически у всех Банков одинаковые требования к безопасности - только очень ограниченный круг лиц может выполнять работы на проде.
Однако и в Банках в некоторых случаях используют другие модели, по крайней мере пробуют использовать.
Например, пытаются создать команды сопровождения, включающие команды разработки. По моим наблюдениям не всегда получается сделать такую структуру эффективной. Основные сложности возникают при подходе, когда по каким-то причинам принимается решение создать команду разработки, которая будет заниматься исключительно сопровождением и исправлять дефекты. Какие это сложности?
По сути нужно повторить экспертизу в команде сопровождения с точки зрения разработки. И если работы по развитию продукта продолжаются, т.е. команды разработки, отвечающие за развитие продукта и за сопровождение продукта, существуют вместе, то возникает дублирование ресурсов аналитиков, архитекторов, разработчиков, тестировщиков, системных инженеров. Поскольку качественных специалистов всегда не хватает, то экспертиза в снижается как в одной так и в другой команде.
Команды будут работать с одним и тем же репозиторием кода. Потребуется решить вопрос ответственности за код. В разделе про ревью кода был сформулирован принцип, что у репозитория должен быть только 1 владелец. Если пытаться сохранить этот принцип, то какой-то лид разработки будет ведущим, а какой-то ведомым. Либо придется отказываться от данного принципа. Также нужно сформулировать процессы разработки и уточнить процедуру отведения веток и закрытия веток. В каком случае нужно отвести хотфикс, в каком случае нужно отвести релиз. В какой момент нужно закрыть ветку и т.п. Т.е. возникает административный оверхед на операционном уровне.
Требуется решить вопрос с инфраструктурой для контура разработки отдельной команды разработки. Отдельные ветки требуется тестировать на изолированных контурах разработки.
Достаточно сложно поддерживать высокую мотивацию среди сильных разработчиков или просто амбициозных разработчиков в команде сопровождения. Многие разработчики хотят иметь возможность не только устранять дефекты, но и разрабатывать новые фичи. При этом для устранения некоторых дефектов требуются разработчики высокой квалификации.
Не очевидны критерии, по которым делятся работы между командами. Для исправления ошибки в требованиях или архитектурной ошибки может потребоваться разработка новых компонент или существенная переработка существующих компонент.
Почему так происходит мне сложно судить. Думаю, что причины могут быть разные, начиная от договорных отношений и бюджетирования, заканчивая реальным желанием менеджеров сделать эффективней, основываясь на предыдущем опыте работы в проекта не по разработке, а по внедрению ERP приложений, например SAP. Где большинство изменений делается на уровне настроек, в крайнем случае выполняется доработка на ABAP, при этом скрипт на ABAP тоже является по сути настройкой с точки зрения платформы SAP. При этом в процессе выполнения настроек в ERP как правило нет репозиториев, нет веток кода, есть очередь запросов на перенос настроек из окружения в окружение.
Если действительно нужно сделать что-то новое - кардинально поменять архитектуру решения без прерывания операционных процессов бизнеса, то в этом случае, думаю, есть смысл создавать отдельную команду разработки.
В большинстве же случаев с точки зрения видов работ, относящихся к разработке хорошо работал принцип: тот кто разработал, тот и устранял дефекты, выполнял сопровождение (you build it, you own it).
8. Микросервисная архитектура. Границы применимости
Когда возникает запрос на микросервисную архитектуру у Заказчиков? Почему монолит не может решить всех проблем.
Предлагаю оставить за периметром те случаи, когда команде разработки интересно попробовать новые технологии. Желание пробовать новое и развиваться - достойно всяческих похвал. Но реальное финансирование на проект можно получить лишь путем обоснования перед акционерами возврата инвестиций.
Какие задачи бизнеса можно решить при помощи микросервисов, которые не могут решить монолитные решения?
Немного истории. На примере Банков, развитие ИТ я очень условно разделил на следующие большие этапы:
Этап | Требование бизнеса | Решение |
1. Автоматизация учета | Выполнять требования регулятора (бухгалтерский, налоговый учет и отчетность) | Бэкофис: автоматизированные банковские системы |
2. Автоматизация отдельных процессов и интеграция процессов. Консолидация данных | Внедрить TOM, обеспечить управленческую отчетность, оптимизировать цепочку процессов | - BPM решения - КХД |
3. Цифровизация каналов взаимодействия с клиентом | Предложить удобную модель взаимодействия клиента с банком (он-лайн) | - ДБО решения (ДБО - дистанционное банковское обслуживание, мобильный банк) - Маркетплейсы |
4. Создание экосистемы | Использовать цифровые каналы для синергии всех бизнесов. Подстроиться под поведение клиента, | - Омниканальные системы, соединяющие сервисы общей экосистемы, включая не совсем привычные для Банка сервисы вроде доставки еды на дом |
Для реализации этапов 3 и тем более 4 очевидно к решению предъявляются повышенные требования к доступности, отказоустойчивости, надежности, масштабированию, восстановлению после сбоя. В офисе банка, оператор может попросить клиента чуть подождать, параллельно работая в нескольких системах. Бывает, что в случае недоступности одной из систем, можно заполнить бумажный документ, отпустить клиента, а учет в системе выполнить позже, когда система заработает, станет доступна. Когда же клиент использует мобильный банк или веб-приложение, то клиент ожидает, что сервис доступен всегда, также как Google, Yandex или Facebook. А почему должно быть по-другому?
Но даже не в этом главная задача. Чтобы подстроиться под поведение, читайте привычки клиента, необходимо сделать много небольших изменений в ИТ ландшафте банка. Сотни, тысячи изменений, которые максимально оперативно должны быть доставлены до прода. Если такие изменения делать в монолите, то получим множество коммитов в достаточно большой кодовой базе монолитного решения. В результате изолировать изменения будет сложно и также сложно оценить влияние изменений на работу системы. Придется каждый релиз выполнять большой объем интеграционного тестирования и регрессионного тестирования. А это затраты и самое главное время (time to market).
Далее, многие Банки сейчас находятся только на этапе совершенствования своих ДБО и омникальных решений (2019 год).
Как правило, это проекты с огромным объемом работ по интеграции систем Банка и созданию фронтэнда клиента над бэкэндом Банка. И как уже упоминалось выше, микросервисная архитектура позволяет до определенной степени выполнять разработку параллельными командами, каждая из которых инкапсулирует код в отдельном репозитории, выполняет контроль качества своего компонента, обеспечивает доставку компонента до прода. Поэтому проект в целом можно выполнить быстрей, быстрей достигнуть целей, не упустить ожидаемою выгоду.
Когда же не стоит использовать микросервисную архитектуру в проекте?
У меня нет четкого ответа на этот вопрос, думаю все же в следующих случаях стоит задуматься:
Во-первых, достаточно сложно сделать проект успешным в рамках контракта с фиксированной ценой. Опыта в создании таких проектов мало (а в 2023 году с учетом событий 2022 года стало меньше экспертизы в РФ), очень велик риск не попасть в оценки.
Во-вторых, ничто не бывает бесплатным. Обеспечение требований доступности, масштабируемости, отказоустойчивости, низкого T2M, возможность параллельной разработки требуют усилий, времени, железа. Соответственно, решение при тех же функциональных возможностях (если вынести за скобки нефункциональные требования) по стоимости с переходом на микросервисную архитектуру будет дороже. Бизнес может быть не готов к росту бюджета. Бесполезно использовать для обоснования бизнесу оценки по аналогии или экспертные оценки. Промышленные решения для управления контейнерами появились около 6-ти лет назад (2014 год, Kubernetes). Скорей всего в России, кол-во команд, которые сделали работающие в продуктиве решения, исчисляется десятками. Команд, которые выполнили проект в первоначальный срок, единицы. О командах, которые выполнили проект в рамках изначального бюджета и в срок на базе микросервисной архитектуры, мне было бы очень интересно узнать:)
В-третьих, когда нет команды (в первую очередь ДевОпс и архитекторов), которые выполняли подобный проект. Скорей всего проект выйдет за все разумные границы и врят ли может быть успешен. Есть определенный порог входа в данную область, и есть определенные подходы, которые команда может проверить только в реальных условиях.
В-четвертых, когда можно построить архитектуру, которая будет удовлетворять требованиям без использования микросервисов. И при этом данная архитектура приведет к более низкой стоимости владения.
Заключение
Если вы смогли дочитать до конца и смогли найти что-то полезное для себя, то спасибо вам за труд.
Если вы сразу после прочтения вы не бросились переписывать монолит на микросервисы, или искать проект по разработке решения на базе микросервисной архитектуры, а немного задумались над тем насколько это будет применимо для вас, то это отлично. Потому что мне удалось донести основную мысль, несмотря на большое кол-во текста. Проект по разработке на базе микросервисной архитектуры - это не просто с точки зрения управления. Если вы не боитесь сложностей, нового опыта, тогда такой проект для вас.

