Этот материал будет полезен для COO, бизнес-аналитиков и топ-менеджеров компаний. Хотя в тексте присутствуют некоторые технические детали, они не будут слишком обременительными. Цель материала: показать общую логику, которую мы использовали для извлечения и анализа данных.
Контекст
Компания Фикус, один из лидеров Российского рынка по озеленению корпоративных и общественных пространств. Уже год мы с ними внедряем ИИ-решения по всему контуру бизнеса: от саппорт-службы для потенциальных заказчиков до разработки персональных ассистентов сотрудникам.
Осенью 2023 года в компании произошли значимые организационные изменения в одном из ключевых подразделений. Руководитель отдела ушел, и команда воспользовалась этим моментом для устранения проблемных мест в рабочих процессах. До этого момента в функционировании отдела наблюдалась определенная неясность и несогласованность, которые требовали исправления. Генеральный директор предложил извлечь и проанализировать данные из корпоративных информационных систем, чтобы выявить реальную схему управления и взаимодействия внутри команды, которая отличалась от официально утвержденных бизнес-процессов.
Решение
Компания активно использует систему управления Kaiten, где за несколько лет накопилось большое количество информации, включая дискуссии, комментарии и обсуждение проектов. Эти данные легли в основу нашей работы.
Извлечение и связывание данных
Честно говоря, мы оказались в выгодном положении по нескольким причинам:
а) Компания последовательно применяет сквозные методологии управления проектами и канбан. Сквозное управление вовлекает участников практически всех отделов на разных этапах и позволяет системно накапливать информацию. До 2022 года "Фикус" работал в Trello, а затем перешел на Kaiten.
б) Кайтен предоставляет API и легко выдергивать информацию любую хранимую информацию. Если система управления выстроена хорошо (а в компании она выстроена хорошо) , у нас может быть много полезных данных в одном месте, что существенно ускоряет процесс майнинга.
Первым шагом мы извлекли два JSON-файла:
- JSON со всей информацией по проектам за 2023 год;
- JSON со всеми комментариями за тот же период.
def get_kaiten_cards(token, **params): url = 'URL' headers = { 'Accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': f'Bearer {token}' } response = requests.get(url, headers=headers, params=params) if response.status_code == 200: return response.json() else: response.raise_for_status() def get_all_kaiten_cards_for_period(token, start_date, end_date): offset = 0 limit = 100 all_cards = [] while True: response_cards = get_kaiten_cards(token, limit=limit, offset=offset, created_after=start_date, created_before=end_date) if not response_cards: break all_cards.extend(response_cards) if len(response_cards) < limit: break offset += limit return all_cards def save_to_json(data, filename): with open(filename, 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=4) def load_from_json(filename): with open(filename, 'r', encoding='utf-8') as f: return json.load(f) def get_card_comments(token, card_id): url = f'.../api/latest/cards/{card_id}/comments' headers = { 'Accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': f'Bearer {token}' } response = requests.get(url, headers=headers) try: response.raise_for_status() return response.json() except requests.exceptions.HTTPError as e: print(f"Ошибка при получении комментариев для карточки {card_id}: {e}") return [] if __name__ == "__main__": token = 'TOKEN' start_date = "2023-01-01T00:00:00Z" end_date = datetime.now().isoformat() + "Z" cards_filename = "kaiten_cards.json" comments_filename = "kaiten_comments.json" all_comments = [] if os.path.exists(cards_filename): cards = load_from_json(cards_filename) for card in cards: card_id = card.get("id") if card_id: comments = get_card_comments(token, card_id) all_comments.extend(comments) save_to_json(all_comments, comments_filename) else: print(f"Файл {cards_filename} не найден.")
Далее мы связали все комментарии, которые были оставлены в ИС, с проектами и сотрудниками, которые их оставляли.

Визуализация данных
Уже на этом этапе, когда мы еще не приступили к анализу сообщений, стало любопытно визуализировать связанные данные с помощью Neo4J. Получился такой граф:
Использование настольной базы данных Neo4j ограничивало нас в возможностях визуализации: не удается изменить размер вершин в графах в зависимости от количества отправленных комментариев, что могло бы наглядно показать коммуникационную нагрузку участников. В качестве альтернативы так же использовали Bloom – онлайн инструмент от Neo4j для визуализации данных, однако и он не предоставил достаточной наглядности в представлении данных, хотя по размерам кластеров здесь мы уже могли увидеть кто из сотрудников оставил больше всего комментариев.

Тем не менее, нас такой формат визуализации не устроил, поэтому я выбрал Plotly – гибкую библиотеку Python, которая отлично подходит для решения моих задач.
В этом случае мы использовали данные об авторах сообщений и упоминаниях сотрудников в комментариях, чтобы создать новый граф. Чем больше упоминаний, тем больше размер вершины в графе. Для балансировки графа мы использовали формулу центральности по степени. Параметр «центральность» помогает оценить важность каждой вершины графа (сотрудника), основываясь на ее позиции в структуре. В результате мы получили следующую визуализацию:
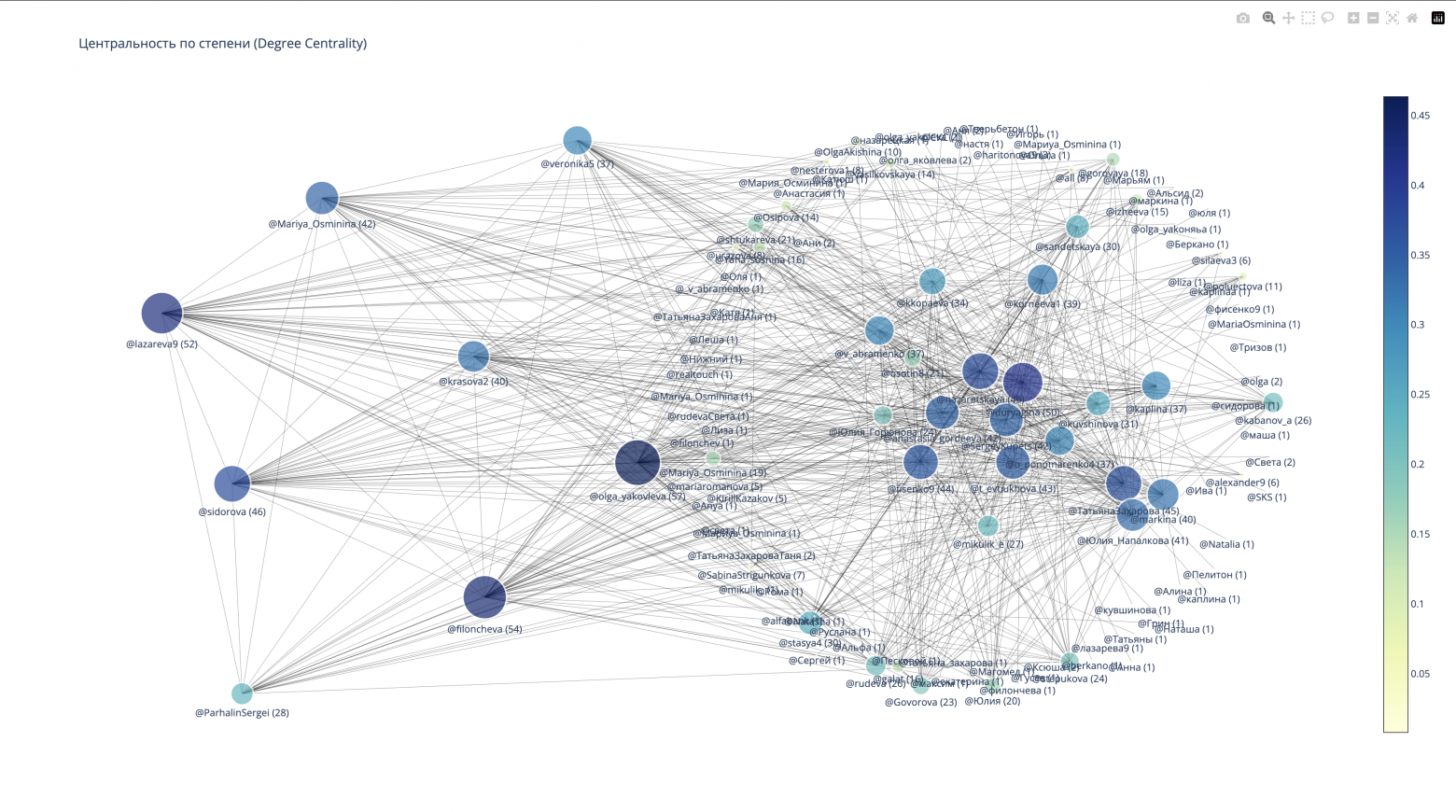
Это уже можно использовать для анализа и позволяет нам определить ключевых участников бизнес-процессов. Интенсивность коммуникаций с некоторыми сотрудниками (определяется диаметром и положением вершин графа) указывает на то, что без их участия задачи не могут быть продвинуты вперед или, наоборот, двигаются только благодаря их участию. Необходимо тщательно проанализировать сообщения и на их основе сформулировать дальнейшие задачи, что и будет сделано в следующем этапе.
Кроме того, существует понятие «информационной нагрузки». Если ключевые сотрудники (с точки зрения замыкания на себя основных бизнес-процессов) перегружены сообщениями, у них остается меньше времени на выполнение основной работы. Наша задача – минимизировать эту нагрузку. Как – предмет внутренних обсуждений, в этой статье касаться этого не будем.
Майнинг бизнес-процессов с помощью LLM
Теперь давайте перейдем к следующему этапу. Нам необходимо определить, какие бизнес-процессы действительно функционируют в компании. Важно также узнать, какие ожидания у коллег при взаимодействии, какие проблемы решаются в процессе, и какие компоненты включает каждый процесс. Для этого мы использовали модель генеративного ИИ из семейства GPT (gpt-3.5-turbo), которая проанализировала сообщения в информационной системе. Получилась такая таблица:
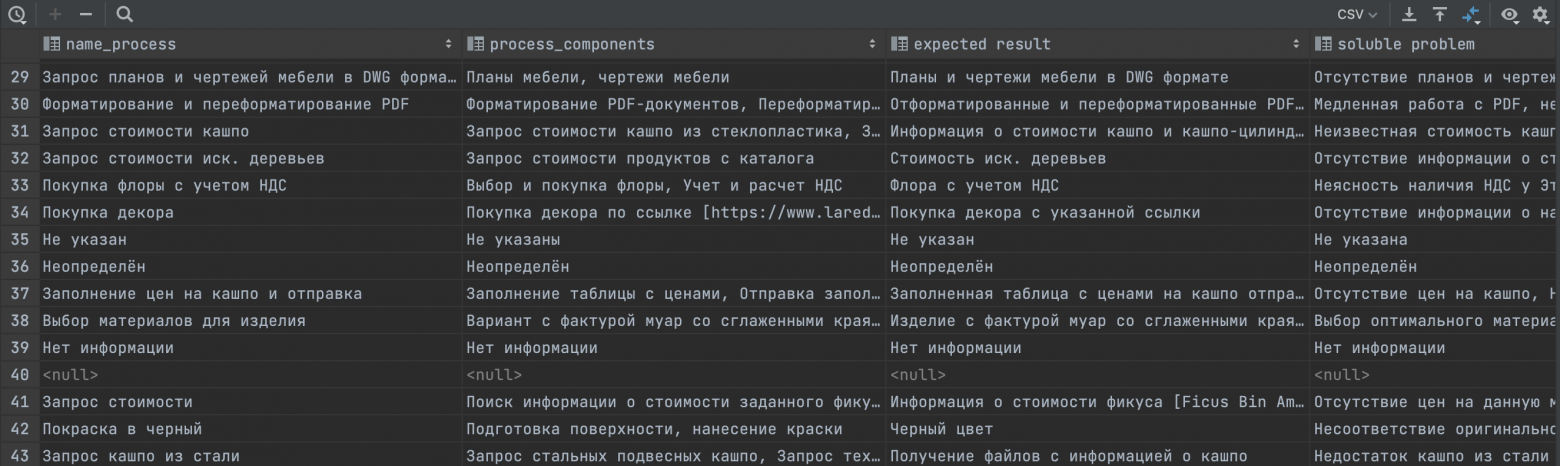
После обработки всех сообщений с помощью LLM, мы провели очистку данных, удалив пустые строки и дублирующиеся значения. Затем мы выделили авторов сообщений и всех, кто был упомянут в сообщениях и снова создали граф, в котором к вершинам (сотрудникам) были привязаны упоминаемые в сообщениях процессы.
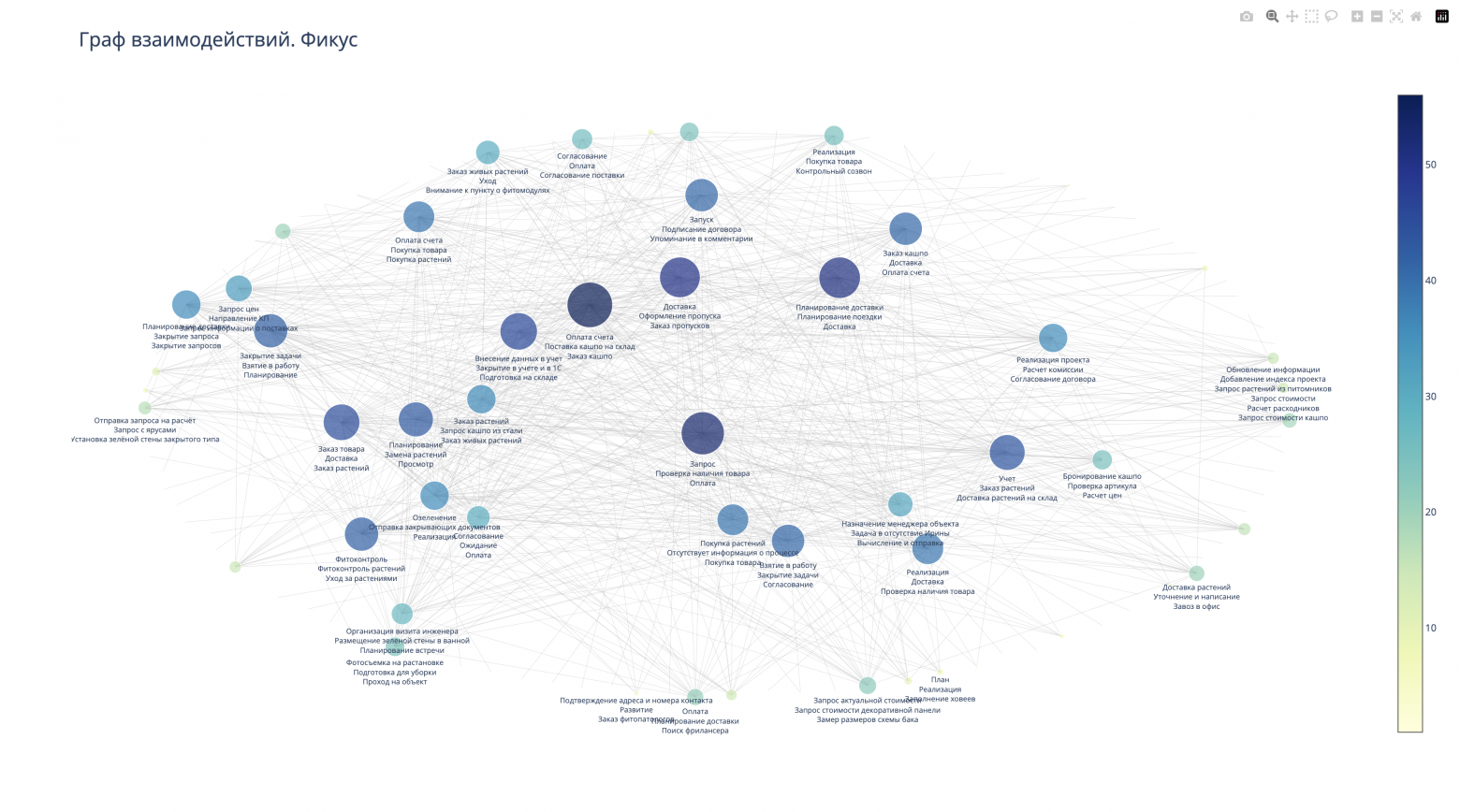
В результате, как и требовалось, мы получили социальный граф бизнес-процессов "Как есть". Далее вместо упоминания процессов, мы можем ожидания от выполненной работы, решаемые проблемы, компоненты процесса и другие намайненные с помощью LLM данные. Например так:
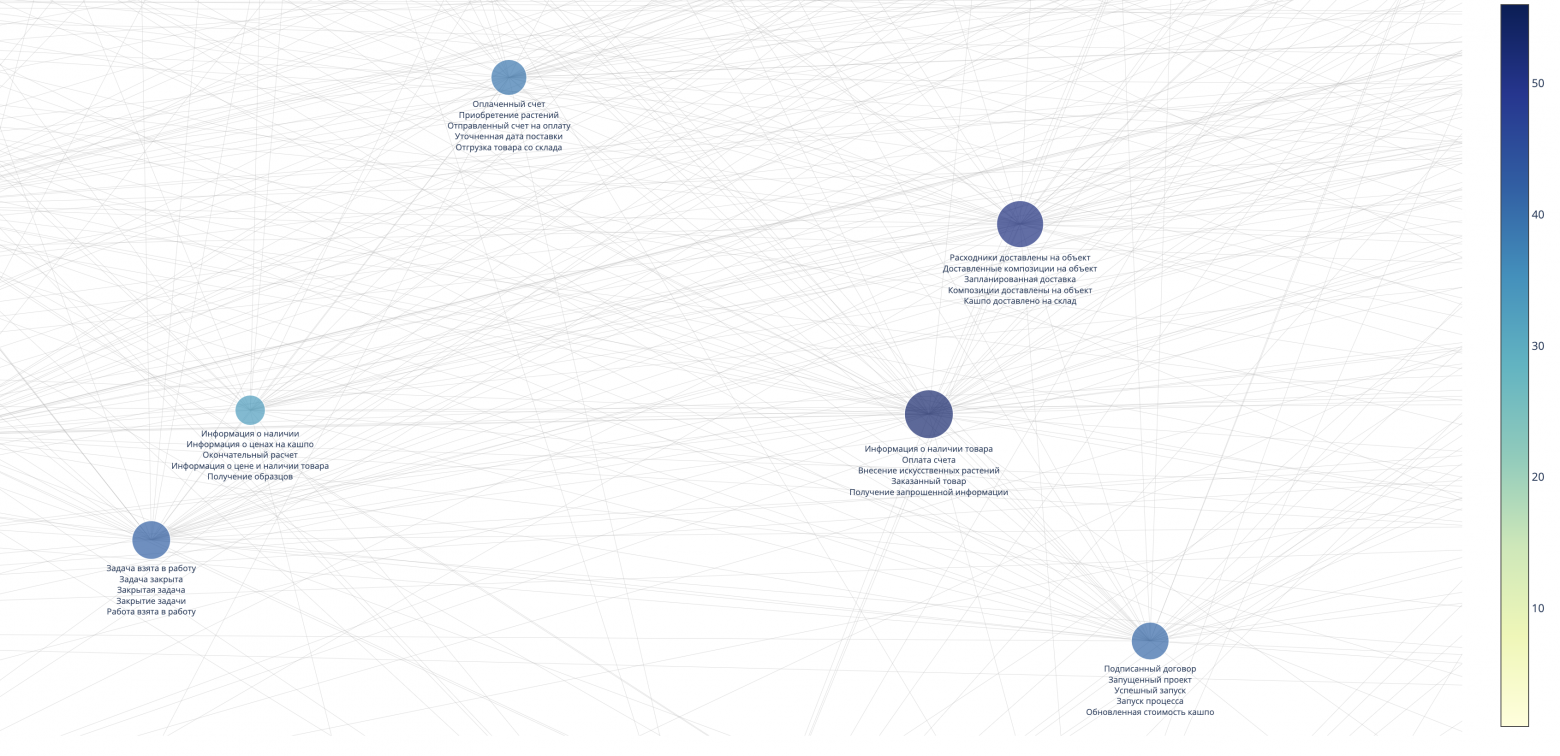
Таким образом, на основе собранной нами информации и визуализации, мы можем принимать те или иные управленческие решения, которые будут опираться на реальное положение дел в компании.
Заключение
Это не предел использования данных. Мы могли бы так же проследить появление бизнес-процессов в течение времени, посмотреть задержки (сколько занимает по времени тот или иной процесс на основе разницы между полученным комментарием и откликом) и много чего еще. Но это предмет для другой статьи.
Спасибо, что дочитали до конца.

