Интересный получился 2025 год: с одной стороны нахлынула волна хайпа вокруг AI‑агентов, с другой стороны не меньшая волна скептицизма и критики остудила пыл многих. Мол, это всё дорогая игрушка — поиграли, забыли, выбросили.
На примере разработки AI‑консультанта для своей компании поговорим о системном подходе к проектированию архитектуры production‑ready AI‑агентов, который мы применяем при создании агентских систем для бизнеса. Да-да, именно систем, включая всё критически необходимое для того, чтобы агенты не стали игрушкой, а приносили пользу и оправдывали своё назначение.
Поехали...
AI как автоматизация и системный подход
А мы считаем так. Если рассматривать искусственный интеллект как одно из средств автоматизации, повышения эффективности бизнеса, других задач, то это неизбежное будущее, поскольку автоматизация она у нас уже давно была, есть и, конечно же, будет.
Ну и как любая качественная автоматизация, в ней роль играет не какая‑то одна программная единица, программный компонент, а вся система и системный подход.
Без системного подхода агент — просто дорогая игрушка. Это ключевой тезис, который мы будем раскрывать в этом материале.

Наш "подопытный" агент
Чтобы наше повествование не было скучным, мы будем его выстраивать на примере разработки AI‑агента для себя.

В первую версию агента заложим следующие задачи:
Взаимодействие с клиентами — первичная коммуникация.
Информирование клиентов о компании и предоставляемых услугах.
Работа с портфолио — поиск информации в кейсах, программах обучения, тренингах по искусственному интеллекту.
Управление заявками — создание заявок, отслеживание статуса.
Планирование встреч — назначение созвонов с экспертами.
Теоретический минимум: что такое ReAct-агент
Буквально минутка такого теоретического ликбеза — что же такое AI‑агент архитектурно? Мы будем строить нашего агента на основе архитектуры ReAct (Reason + Act).

В центре этой архитектуры у нас есть языковая модель (LLM), которая взаимодействует непосредственно с пользователем. Она обрабатывает входящий запрос, понимает (Reason), надо ли сразу дать ответ или воспользоваться историей сообщений, или своей какой‑то параметрической памятью.
Ну, например, поздороваться, попрощаться, пожелать всего хорошего. Или же необходимо воспользоваться (Act) дополнительными инструментами, которыми агент снабжён:
Обратиться в базу знаний для поиска информации по кейсам, портфолио, образовательным программам.
Воспользоваться способностью Retrieve — извлекать информацию.
Вызвать другие инструменты для взаимодействия с CRM‑системой — подать заявку, посмотреть её статус или назначить встречу, добавить в календаре встречу с экспертом.
Архитектура нашего агента
Архитектурно это в нашем случае будет выглядеть следующим образом.
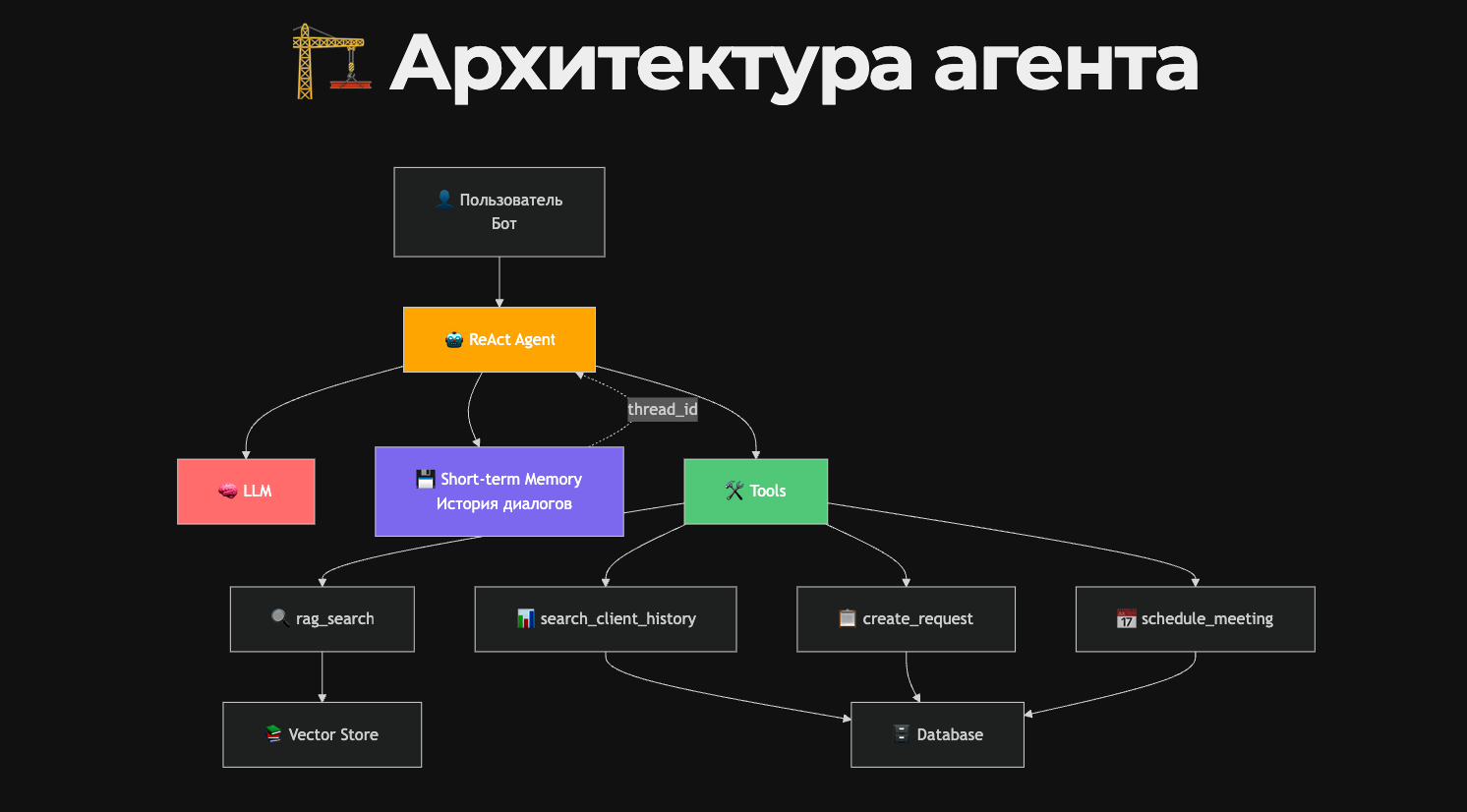
У нас пользователь будет взаимодействовать с системой через бота. Соответственно, на бэкенде будет наш ReAct‑агент, которым будет управлять языковая модель.
Также у нас будет:
Short‑term memory — как минимум, для хранения истории диалогов.
Набор инструментов — тот самый поиск информации по портфолио, образовательным программам на основе векторного хранилища, семантического хранилища информации и документов.
Функциональные инструменты — поиск информации по клиенту, по его заявкам, создание новой заявки или регистрация новой встречи.
Эти инструменты уже будут взаимодействовать с какой‑то базой данных. На данный момент нам это не принципиально — мы сегодня рассматриваем архитектурную составляющую.
Инструменты агента
Давайте по каждому инструменту пройдёмся чуть‑чуть подробнее.
📅 schedule_meeting
Назначение встречи с клиентом в определённую дату и время.

Этот инструмент агент будет вызывать, когда пользователь:
Захочет встретиться с экспертом.
Попросит записать его на консультацию.
Задаст какие‑то вопросы, которые подводят к назначению встреч, например: «Когда можем обсудить проект?»
Диалог придёт к фазе, когда необходимо назначить встречу.
Мы агента проинформируем, проинструктируем о том, что необходимо собрать все параметры перед вызовом, проверить корректность даты и времени.
📊 search_client_history
Поиск истории взаимодействия клиента с компанией.

Агент будет использовать этот инструмент, когда пользователь задаст вопрос:
«Какие у меня заявки?»
«Когда моя следующая встреча?»
«Над какими проектами работаем?»
«Какой у нас статус по такому‑то проекту?»
В общем, любая уточняющая информация по истории взаимодействия.
Обращаться он будет внутри в CRM‑систему за деталями с возможностью:
Поискать по тексту.
Отфильтровать по типу заявки.
Отфильтровать по статусу.
📋 create_request
Создание заявки на консультацию, разработку или обучение.

По сути, самый основной инструмент, который будет лида — нашего клиента, в нашу базу данных помещать.
Он будет использоваться, когда:
Клиент попросит записаться на консультацию.
Диалог подойдёт к фазе, что необходимо записаться на консультацию.
Клиент захочет заказать разработку AI‑агента, AI‑системы.
Клиент захочет записаться на обучение какое‑то конкретное.
Будет собирать контакты клиента, фиксировать подробное описание его запроса и тип.
🔍 rag_search
Поиск информации о компании, услугах, кейсах
Мы дальше переходим к более расширенному уже инструменту, где мы остановимся чуть‑чуть подробнее. Это RAG Search — поиск информации о компании, услугах, кейсах по базе знаний, базе данных.
Этот инструмент позволит нашему агенту обладать информацией, которой нет в его параметрической памяти языковой модели, потому что на основе этой информации не обучалась языковая модель, но тем не менее мы её туда предоставим.

Агент будет вызывать этот инструмент, когда будут запросы о:
Компании, услугах, экспертизе
Кейсах, проектах
Программах обучения
Агент при вызове инструмента будет формировать поисковый запрос на основе всей истории диалога, переписки, последнего вопроса пользователя. А инструмент, соответственно, будет возвращать релевантные чанки (говоря по‑русски, фрагменты документов), найденные в этих источниках.
RAG: Retrieval Augmented Generation
Как мы уже сказали, под капотом этого инструмента у нас будет технология Retrieval Augmented Generation (RAG).
Её суть — это поиск релевантной информации в документах для генерации точных ответов.
Документы для индексации
Давайте посмотрим на эти четыре PDF‑документа, которые в первой версии агента будут проиндексированы и загружены:
Портфолио компании с кейсами (PDF на 25 страниц)
Программы консалтинга и обучения (3 PDF по 10 страниц)
Архитектура RAG-пайплайна
А теперь рассмотрим архитектуру нашего RAG‑пайплайна, который у нас используется внутри инструмента.

Поток данных:
Пользовательский запрос поступает в агента.
Агент, учитывая всю историю взаимодействия с пользователем и последний вопрос, формирует поисковую фразу.
Поисковая фраза отправляется как аргумент
queryв наш инструментrag_search— это точка входа в наш RAG‑пайплайн.Производится поиск информации.
Ранжирование найденных чанков.
Отсечение топ‑k чанков — фрагментов документов, которые уже мы будем отдавать обратно агенту.
Агент использует их для формирования ответа
Либо агент может принять решение, что ему нужно изменить свой запрос и повторно вызвать
rag_searchс другими аргументами.
Advanced RAG
Важно отметить — что мы сразу применяем технологии Advanced RAG.
Query Transformation
Агент выполняет у нас функцию Query Rewrite или Query Transformation. То есть преобразование всей истории переписки и пользовательского сообщения в конкретный поисковый запрос.
Hybrid Retrieval
Дальше, на этапе извлечения информации, у нас используется семантический и лексический полнотекстовый поиск.

Таким образом, мы используем два этих источника для поиска релевантных фрагментов, после чего мы их объединяем. У нас получается на выходе уже top-40 документов (этот параметр будет настраиваемый).
Reranking c Cross‑Encoder
Далее найденные фрагменты документов отправляем в следующий элемент Reranker, где у нас используется модель Cross‑Encoder.

Cross‑Encoder будет ранжировать каждый документ с пользовательским вопросом и определять степень их близости, релевантности. Возвращать агенту мы будем наиболее релевантных top-5 документов.
Индексация документов
На этапе индексации документов, который предшествует всему поиску и наполнению баз (векторных и частотного полнотекстового поиска), мы для первой версии нашего агента, будем использовать простой подход:

Загружаем все документы
Разбиваем на чанки (chunking, splitting) — на фрагменты определённой длины
— Размер чанка: 500 токенов
— Метод: скользящее окно (overlap)
— Пересечение: 100 токенов с предыдущим чанкомВычисляем векторное представление чанка (vector embedding) и помещаем в семантическое/векторное хранилище.
Добавляем чанк в полнотекстовый индекс BM25.
Системный промпт — мозг и сердце агента
Разобрали мы с вами все инструменты, которыми будет вооружён наш агент, но осталось разобрать то главное связующее звено, которым мы задаём поведение агента. Мож��о назвать это сердцем и мозгом агента — это его системный промпт.
Из чего же он у нас будет состоять?
Информация о компании
Первое — мы в него положим информацию о компании. Вернее, мы будем загружать в него информацию о компании из отдельного файла, где она будет у нас храниться для удобства сопровождения и изменения этой информации.
Мы расскажем, чем наше агентство занимается. И самое главное — ещё дадим агенту сразу информацию нашу контактную, которой он сможет делиться с нашими клиентами, если диалог будет заходить до непосредственного взаимодействия с экспертами.
Правила ответов
Следующий блок — правила ответов. Соответственно, то, как правильно агент должен отвечать, на наш взгляд:

Важно отметить, что размещение наиболее часто востребованной информации в промпте, наравне с четкими правилами поиска информации, помогает избежать лишних вызовов инструментов и повысить скорость ответа.
Правила работы с инструментами

Переходим к инструментам. Несмотря на то, что информация об инструментах автоматически добавляется к агенту через метаинформацию (при вызове LLM), бывает полезно дополнительно его проинструктировать:
Чем отличается один инструмент от другого?
Когда использовать один, когда второй, когда третий?
Задать правила безопасности
Можно проинструктировать по особенностям, например, работы с датами

Примеры и антипаттерны
Дальше в системном промпте стоит указать примеры и антипаттерны работы с инструментами, общий алгоритм взаимодействия.

Сразу оговорюсь, что эти все особенности системного промпта, его тщательность, проработанность — она зависит, конечно, от языковой модели, которую мы будем применять, от её уровня зрелости и качества.
Более слабые, более маленькие модели, локальные — потребуют более тщательно проработанного системного промпта. Более умные модели ведут себя умнее, и их надо меньше инструктировать. Поэтому понятие и версия системного промпта всегда идёт в связке с языковой моделью, с которой применяется.
Резюме первой части

Итак, мы с вами рассмотрели всё самое необходимое, чтобы перейти к созданию агента.
С этой архитектурой можно приступать к реализации. Если воспользоваться AI‑driven подходом к разработке, то создание агента с такой архитектурой займёт буквально пару часов.
Мы разобрали архитектуру агента: ReAct, инструменты, RAG, системный промпт. Это солидный архитектурный фундамент — те самые видимые 20% системы, которые определяют, как агент думает, действует и взаимодействует с пользователем.
Но большая часть настоящей production‑ready агентской системы «невидимая». О ней мы поговорим во второй части этой серии.
Что дальше?
Во второй части этой серии (выйдет через 1–2 недели) мы разберём:
🛠️ Model Context Protocol для инструментов — стандартизация и переиспользование инструментов
🛡️ Guards и безопасность — защита от нежелательного поведения агента
🔒 Rate Limiters — контроль частоты вызовов и расходов
🔐 PII Protection — защита персональных данных в промптах
⚠️ Human‑in‑the‑loop для критичных операций — подтверждение важных действий человеком
📊 Observability для мониторинга — трейсы, метрики и логирование системы
🧪 Evaluation для тестирования online и offline — RAGAS, LLM‑as‑Judge, dataset management
👍 User Feedback — сбор обратной связи и continuous learning
Чтобы методика проектирования стала не просто знанием, а практическим навыком, который позволит вам создавать production‑ready агентские системы — применяйте её на практике!
На программах обучения по разработке production‑ready AI‑агентов мы обучаем AI‑кодингу ИИ‑агентов с правильной архитектурой — от RAG и ReACt до Guards, Evaluation и Observability.
Прямо сейчас действует новогодняя комбо‑акция 🎅 на все программы 2026 года.
Больше полезного, свежего и практического контента про AI‑агенты и AI‑driven разработку публикую в Telegram‑канале AI.Dialogs.
По вопросам консалтинга, корпоративного обучения или внедрения AI‑агентов в ваш бизнес обращайтесь напрямую в Telegram smirnoff_ai.

