Именно этот вопрос возник у нас в процессе игры в "Города" пока мы ехали из Екатеринбурга в Тюмень, а названия городов то и дело заканчивались на "К". В тот момент город Курган был назван уже 25 раз. И нас озарило... Спарсим данные с RuWiki и посмотрим сколько городов в России начинаются и заканчиваются на букву К!

Наш подробный пайплайн исследования названий городов России:
1) Сбор данных
Мы решили спарсить данные с названиями городов и датой их первого упоминания с RuWiki.
Пример кода для парсинга данных с сайтов (Спасибо эре вайб кодинга)):
import requests from bs4 import BeautifulSoup import csv url = "https://ru.ruwiki.ru/wiki/Список_городов_России" resp = requests.get(url) resp.raise_for_status() soup = BeautifulSoup(resp.text, "html.parser") # находим основную таблицу списка городов table = soup.find("table") rows = table.find_all("tr") results = [] for row in rows[1:]: # пропускаем заголовок cols = row.find_all(["td","th"]) if len(cols) >= 7: # номер, герб, город, регион, округ, население, основание city = cols[2].get_text(strip=True) #берем 2 колонку first_mention = cols[6].get_text(strip=True) results.append((city, first_mention)) # сохраняем в CSV with open("cities_first_mention.csv", "w", newline="", encoding="utf-8") as f: writer = csv.writer(f) writer.writerow(["Город", "Основание/Первое упоминание"]) writer.writerows(results) print(f"Записано {len(results)} строк.")
2) Нормализация данных
Данные с RuWiki не всегда однородные: в названиях могут быть пробелы, а даты находиться в форматах «1147» и «XII век». С помощью регулярок названия городов приведены к единому виду - убрали лишние пробелы, а также преобразовали века в годы: например, XII век → 1100.
import re def extract_year(text): # Проверяем, что входное значение — строка, иначе возвращаем None if not isinstance(text, str): return None text = text.lower() # приводим текст к нижнему регистру для упрощения поиска # ищем обычный год в формате 1000–1999 или 500–999 year_match = re.search(r'\b(1[0-9]{3}|[5-9][0-9]{2})\b', text) if year_match: return int(year_match.group()) # если нашли год — возвращаем его как число # ищем века, записанные римскими цифрами century_match = re.search(r'([ivxlcdm]+)\s*век', text) if century_match: roman = century_match.group(1).upper() # получаем римское число и переводим в верхний регистр roman_map = { 'I':1,'V':5,'X':10,'L':50,'C':100,'D':500,'M':1000 } # Конвертация римских цифр в арабское число value = 0 prev = 0 for c in roman[::-1]: # идём с конца строки if roman_map[c] < prev: # если меньшая цифра перед большей — вычитаем value -= roman_map[c] else: # иначе прибавляем value += roman_map[c] prev = roman_map[c] return (value - 1) * 100 # переводим век в начало века (например, XII в 1100) # Если ни обычный год, ни век не найдены — возвращаем None return None
3) Диахронический анализ (временная динамика)
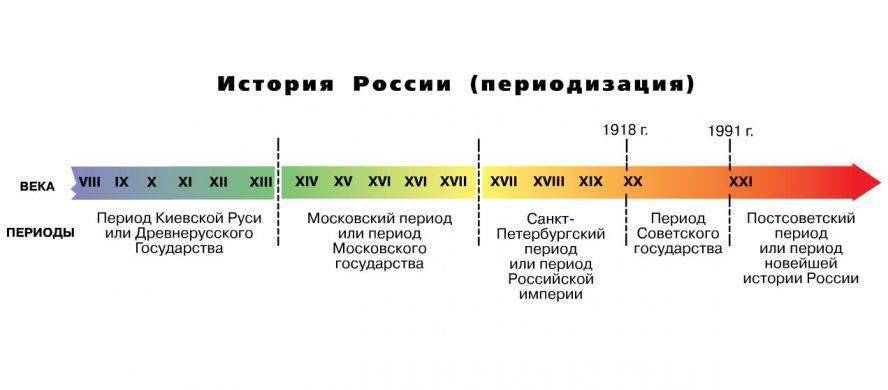
Помимо того, что мы достали годы, хотелось сгруппировать даты по различным историческим периодам, чтобы в дальнейшем анализировать уже более мелкие группы.

Всё это получилось реализовать с помощью простых if, elif, else:
def period_historical(year): if year is None: return None elif year < 1300: # VIII–XIII век return "Киевская Русь / Древнерусское государство" elif year < 1700: # XIV–XVI век return "Московский период" elif year < 1917: # XVII–1916 return "Период Российской империи" elif year < 1991: # 1917–1990 return "Советский период" else: # после 1991 return "Постсоветский период"
С помощью pandas загружается CSV с названиями городов и годом их основания. Функция period_historical присваивает каждому городу исторический период: Киевская Русь, Московский период, Российская империя, Советский и Постсоветский. С помощью value_counts() и упорядочивания категорий по хронологии. И, конечно, визуализация:3 matplotlib строит столбчатую диаграмму, где видно количество городов, основанных в каждом периоде.

matplotlib, где видно количество городов, основанных в каждом периоде. 4) Алфавитный анализ
Скрипт считает, сколько городов начинается с каждой буквы алфавита, и строит столбчатую диаграмму распределения по буквам.
import matplotlib.pyplot as plt # Получаем первую букву каждого города df["first_letter"] = ( df["Город"] # берем название города .str.strip() # убираем пробелы по краям .str.upper() # приводим букву к верхнему регистру .str[0] # берём только первую букву ) # Считаем количество городов на каждую букву и сортируем по алфавиту letter_counts = ( df["first_letter"] .value_counts() # подсчёт уникальных букв .sort_index() # сортировка по алфавиту ) # Строим столбчатую диаграмму plt.figure() letter_counts.plot(kind="bar") # гистограмма plt.xlabel("Первая буква названия города") # подпись оси X plt.ylabel("Количество городов") # подпись оси Y plt.title("Распределение названий городов России по начальной букве") # заголовок plt.xticks(rotation=0) # подписи букв горизонтально plt.tight_layout() # подгонка графика plt.show() # отображение графика

Подобная операция была выполнена для определения количества городов, заканчивающихся на какую-либо из букв алфавита.

И снова буква К в победителях) Городов, начинающихся на К: 175 Городов, заканчивающихся на К: 404 (не Error)).
5) Интересные закономерности:
Большинство городов основано в период Российской империи;
Буква «К» доминирует в названиях городов России, причем не только в начале слов, но и в конце;
Городов, начинающихся на Й - 1!!! Городов, заканчивающихся на Й, заметно больше - 80! Так что можно выигрывать за счет этого)));
Города-дубликаты! Найдено 27 близняшек))

Самые короткие названия (2-3 буквы): Уфа, Ом, Як. Длинные названия состоят из 15–20 букв, например Северодвинск, Новокузнецк, Новосибирск.


{kind=link}