Здесь рассказано, как именно Linux обрабатывает системные вызовы в архитектуре x86-64, и почему при профилировании они выглядят как дорогостоящие операции.
При помощи системных вызовов пользовательские программы общаются с операционной системой. В частности, системные вызовы открывают файлы, считывают текущее время, создают процессы и делают многое другое. Без системных вызовов не обойтись, но они и не так дёшевы.
Если вы когда-либо рассматривали флеймграф, то могли заметить, что системные вызовы в нём часто фигурируют как яркие пятна. Инженеры тратят много времени на их урезание. Существуют целые фичи, цель которых — сократить для различных программ количество случаев, в которых приходится переключаться на взаимодействие с ядром. Таковы, например, io_uring для объединения операций ввода/вывода в пакеты или eBPF для выполнения кода внутри ядра.
Почему же системные вызовы такие дорогие? Прежде всего, отметим, что при каждом вызове выполняется лишь небольшой фрагмент кода ядра. Значительно дороже обходится то, что ему сопутствует: при каждом переходе в режим ядра процессору приходится отменять оптимизации, опустошать конвейеры и сбрасывать состояние предиктора, а затем при возврате всё это восстанавливать. Именно из-за таких разрушений системные вызовы на практике обходятся гораздо дороже, чем может показаться из исходного кода.
В этой статье рассмотрено, что именно происходит при выполнении системного вызова под Linux в архитектурах x86-64. Мы проследим пути входа в ядро и выхода из него, проанализируем прямые издержки, а затем углубимся в изучение побочных эффектов, возникающих на уровне микроархитектуры. Всё это поможет понять, почему минимизация системных вызовов — это такая важная оптимизация.
Базовая информация о системных вызовах
Начнём с беглого обзора системных вызовов. В ядре предусмотрены процедуры для предоставления конкретных сервисов в пользовательском пространстве. Они находятся в ядре, так как им требуется привилегированный доступ к регистрам, инструкциям или аппаратным устройствам. Например, чтобы считать файл с диска, нужно обратиться к контроллеру диска, а для создания нового процесса требуется выделить аппаратные ресурсы. Обе операции — привилегированные, и поэтому они реализованы как системные вызовы.
Чтобы выполнить системный вызов, приходится задействовать механизм, переключающий выполнение программы из пользовательского пространства в пространство ядра. В архитектуре x86-64 это делается при помощи инструкции syscall, где номер системного вызова записывается в rax, а аргументы — в регистры (rdi, rsi, rdx, r10, r9, r8), а затем вызывается syscall:
# установка аргументов для выполнения системного вызова read movq $1, %rax movq $1, %rdi movq $buf, %rsi movq $size, %rdx syscall # здесь входим в ядро movq %rax, %rbx
Процессор, наткнувшись на такую инструкцию, переключается в режим ядра и переходит на путь входа, ведущий к зарегистрированному системному вызову. Ядро завершает переключение контекста (переходя к новым таблицам страниц и стеку), а затем принимается выполнять реализацию конкретного системного вызова.
Завершив работу, системный вызов записывает возвращаемое значение в регистр rax и возвращается. Для возврата требуется ещё раз переключиться в привилегированный режим, а для этого — обратить всё, что было сделано при входе; восстановить пользовательскую таблицу страниц, стек и регистры.
Далее схематически показано, какую последовательность шагов нужно проделать, чтобы выполнить системный вызов (в данном случае — read).
, а затем возвращает управление обратно в пользовательское пространство.")
На рисунке:
Код из пользовательского пространства устанавливает аргументы для системного вызова
read.Системный вызов выполняется при помощи инструкции
syscall.Инструкция переключается в режим ядра и переходит в обработчик входа в системный вызов; на данном этапе ядро переключается на работу с собственной таблицей страниц и стеком.
Далее ядро переходит к реализации системного вызова
read.После возврата ядро восстанавливает таблицу страниц из пользовательского пространства и стек, а далее управление передаётся следующей пользовательской инструкции.
Теперь, когда мы в общем виде рассмотрели весь процесс, давайте подробнее изучим обработчик системных вызовов, действующий в ядре Linux, и постараемся детально разобрать каждый шаг.
Внутри обработчика системных вызовов Linux
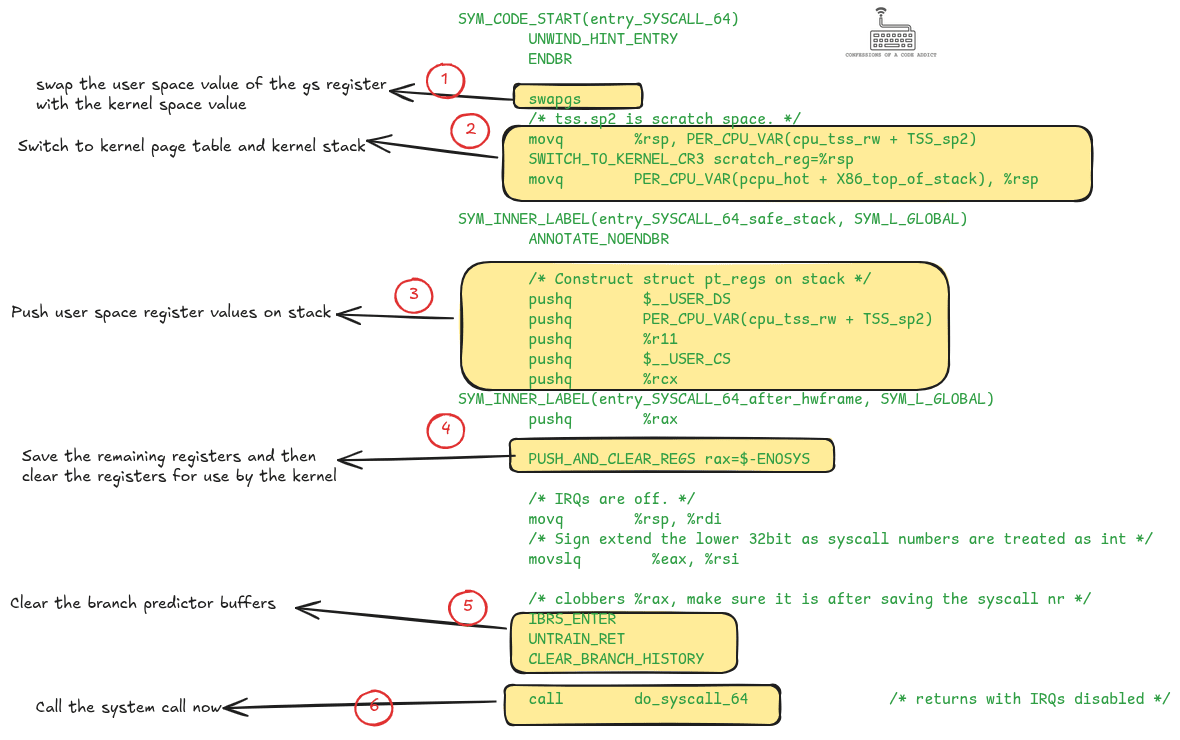
Когда инициируется системный вызов, ЦП переходит к специально выделенному в ядре обработчику системных вызовов. На следующей схеме приведён код ядра Linux для такого обработчика, действующего в архитектуре x86-64. Взято из файла entry_64.S. На схеме проиллюстрировано, какие шаги должно выполнить ядро перед тем как, собственно, перейти к самому системному вызову. Давайте кратко обсудим каждый из них.
 код для входа в системный вызов из ядра Linux (entry_64.S). Рисунок аннотирован так, чтобы было понятнее, какие шаги выполняет ядро до того, как перейти, собственно, к инициированию системного вызова.")
Замена регистра GS
GS — это сегментный регистр из архитектуры x86. В пользовательском пространстве он применяется преимущественно в качестве локальной памяти потока (TLS). В пространстве ядра он служит для реализации попроцессорных переменных, таких как указатель, направленный на выполняемую в настоящий момент задачу. Таким образом, первым делом ядро восстанавливает именно для регистра GS значение, соответствующее режиму ядра.
Переключение на таблицу страниц ядра и стек ядра
В ядре Linux есть собственная таблица страниц с отображениями на соответствующие страницы памяти ядра. Чтобы иметь доступ к её памяти, ядро должно сначала восстановить эту таблицу страниц. Это делается при помощи макроса SWITCH_TO_KERNEL_CR3.
В архитектуре x86 управляющий регистр CR3 предназначен для хранения адреса корня таблицы страниц. Именно поэтому макрос для переключения таблиц страниц называется SWITCH_TO_KERNEL_CR3.
У ядра есть собственный отдельный стек фиксированного размера для выполнения кода на стороне ядра. В описываемый момент регистр rsp всё ещё указывает на стек пользовательского пространства, так что ядро сохраняет его в пространстве для временных значений (scratch space), а затем восстанавливает собственный указатель стека из переменной, выделенной на этот процессор.
При возврате от системного вызова ядро восстанавливает пользовательскую таблицу страниц и стек, обращая эти операции. Этот код не показан на схеме, но выполняется прямо после шага “call do_syscall_64”.
Сохранение регистров пользовательского про��транства
На данном этапе в регистрах ЦП по-прежнему содержатся те значения, которые там были в период выполнения кода из пользовательского пространства. При выполнении кода ядра они были бы затёрты, и, чтобы этого не произошло, ядро сохраняет значения в стеке ядра. После этого оно в целях безопасности осуществляет санацию регистров. Всё это показано на схеме в рамках 3 и 4.
Как попытаться защититься от атак со спекулятивным выполнением команд
Вот что происходит в коде на трёх следующих этапах:
Активация IBRS (indirect branch restricted speculation)
Разобучение буфера стека возврата
Очистка буфера с историей ветвлений
Все эти методы призваны уменьшить вред от атак, связанных со спекулятивным выполнением кода, например, spectre (v1 и v2) и retbleed. Спекулятивное выполнение — это применяемая в современных процессорах оптимизация, при которой процессор прогнозирует итог выполнения ветвлений кода и спекулятивно выполняет инструкции, следуя по спрогнозированному пути. Если соблюдать при этом достаточную точность, то производительность кода серьёзно возрастает.
Однако обнаруживаются уязвимости, возникающие в тех случаях, когда вредоносная пользовательская программа может злонамеренно обучить предиктор ветвлений. Так она вынудит ЦП спекулятивно выполнять код внутри ядра именно по тем путям, которые заданы злоумышленником. В самом деле, эти спекулятивные пути никак не изменяют логическую последовательность выполнения кода в ядре, но из-за атаки возможны утечки информации через микроархитектурные побочные каналы, например через кэш.
Меры защиты помогают перестраховаться так, чтобы состояние контролируемого пользователем предиктора ветвлений не влияло на спекулятивное выполнение кода в ядре. Но это даётся ценой значительного снижения производительности. Ниже мы разберём эти примеры подробнее, когда будем обсуждать, как системные вызовы влияют на прогнозирование ветвлений.
Выполнение системного вызова и возврат обратно в пользовательское пространство
После всех вышеперечисленных шагов ядро, наконец, вызывает функцию do_syscall_64. Именно здесь фактически и происходит системный вызов. Мы не будем подробно рассматривать эту функцию, поскольку нас интересует не столько экскурсия по коду ядра, сколько влияние системных вызовов на производительность.
По завершении системного вызова функция do_syscall_64 сразу возвращается. После этого ядро восстанавливает состояние пользовательского пространства, в том числе регистры, таблицу страниц и стек, а затем возвращает управление пользовательскому пространству. На следующей схеме показан код, идущий после do_syscall_64 — обратите на него особое внимание.
. Здесь продемонстрировано, как ядро восстанавливает пользовательские регистры, таблицы страниц и состояние, а только затем возвращает управление в пользовательское пространство.")
entry_64.S). Здесь продемонстрировано, как ядро восстанавливает пользовательские регистры, таблицы страниц и состояние, а только затем возвращает управление в пользовательское пространство.Теперь, когда мы рассмотрели весь код, выполняемый в ядре для входа в системный вызов и выхода из него, можем обсудить, какие издержки при этом возникают. Они делятся на две категории:
Прямые издержки, связанные с кодом, выполняемым при входе и возврате.
Косвенные издержки, обусловленные микроархитектурными побочными эффектами (напр., очисткой буфера с историей ветвлений и буфера возврата стека).
В этой статье обсуждаются преимущественно косвенные издержки, возникающие из-за системных вызовов. Но, прежде, чем углубляться в эту тему, давайте по-быстрому расставим бенчмарки, которые помогут нам измерить влияние прямых издержек.
Прямые издержки от системных вызовов
Прямые издержки от разных системных вызовов в основном не отличаются, поскольку каждый системный вызов при входе и выходе должен выполнять одни и те же шаги. Эти издержки можно грубо измерить при помощи простого бенчмарка, сравнив, сколько тактов процессора тратится на выполнение системного вызова clock_gettime в ядре, а сколько — в пользовательском пространстве.
Системный вызов clock_gettime считывает системное время, например, часы реального времени (время в секундах, истекших с начала эпохи Unix) или монотонные часы (время в секундах, истекших с момента загрузки ядра). В программах такая возможность используется очень часто. Например, в Java под капотом её использует функция System.currentTimeMillis(), а в Python — time.time() и time.perf_counter().
Из-за дороговизны системных вызовов в Linux применяется оптимизация vDSO (виртуальный динамический разделяемый объект). Это короткий путь к системным вызовам, прокладываемый из пользовательского пространства: ядро отображает код системного вызова на адресное пространство каждого процесса, благодаря чему системные вызовы могут выполняться как вызовы обычных функций, то есть без входа в ядро.
Таким образом, можно написать бенчмарк, измеряющий, сколько времени требуется для выполнения clock_gettime в пользовательском пространстве с применением vDSO и сравнить эти данные с аналогичным временем, затрачиваемым в ядре, когда выполнение идёт через интерфейс syscall. Далее идёт код нашей программы для бенчмаркинга.
#define _GNU_SOURCE #include <sys/syscall.h> #include <unistd.h> #include <stdint.h> #include <stdio.h> #include <time.h> #include <x86intrin.h> int main() { const int ITERS = 100000; uint32_t cpuid; struct timespec ts; // Прогреваем одновременно версии syscall и libc for (int i = 0; i < 10000; i++) { syscall(SYS_clock_gettime, CLOCK_MONOTONIC, &ts); clock_gettime(CLOCK_MONOTONIC, &ts); } // Тест 1: напрямую через интерфейс syscall _mm_lfence(); uint64_t start1 = __rdtsc(); long sink1 = 0; for (int i = 0; i < ITERS; i++) { long ret = syscall(SYS_clock_gettime, CLOCK_MONOTONIC, &ts); sink1 += ret + ts.tv_sec + ts.tv_nsec; // используем результаты для предотвращения оптимизации } uint64_t end1 = __rdtscp(&cpuid); _mm_lfence(); // Тест 2: libc clock_gettime _mm_lfence(); uint64_t start2 = __rdtsc(); long sink2 = 0; for (int i = 0; i < ITERS; i++) { int ret = clock_gettime(CLOCK_MONOTONIC, &ts); sink2 += ret + ts.tv_sec + ts.tv_nsec; // используем результаты для предотвращения оптимизации } uint64_t end2 = __rdtscp(&cpuid); _mm_lfence(); // Предотвращаем удаление мёртвого кода if (sink1 == 42 || sink2 == 42) fprintf(stderr, "x\n"); double cycles_per_syscall = (double)(end1 - start1) / ITERS; double cycles_per_libc = (double)(end2 - start2) / ITERS; printf("Direct syscall cycles per call ~ %.1f\n", cycles_per_syscall); printf("Libc wrapper cycles per call ~ %.1f\n", cycles_per_libc); printf("Difference ~ %.1f cycles (%.1f%% %s)\n", cycles_per_libc - cycles_per_syscall, 100.0 * (cycles_per_libc - cycles_per_syscall) / cycles_per_syscall, cycles_per_libc > cycles_per_syscall ? "slower" : "faster"); return 0; }
Замечание о rdtsc: Как правило, clock_gettime() используется для измерения хронометража. Но здесь мы расставляем бенчмарки для самого clock_gettime(), поэтому нам требуется что-то более точное. rdtsc — это инструкция x86, считывающая значение 64‑разрядного счётчика временных меток (TSC) в ЦП. Этот счётчик работает с фиксированной частотой (напр., 2.3 ГГц на моей машине). Измерив его значение до и после операции, можно узнать, сколько тактов процессора затрачивается на операцию.
У меня на ноутбуке программа производит следующий вывод:
➜ ./clock_gettime_comparison Direct syscall cycles per call ~ 1428.8 Libc wrapper cycles per call ~ 157.0 Difference ~ -1271.9 cycles (-89.0% faster)
Версия с vDSO работает на порядок быстрее и убедительно демонстрирует, насколько дорого обходится путь в системный вызов и к выходу из него по сравнению с вызовом обычной функции.
Эту оценку следует воспринимать с долей скепсиса, поскольку в рамках этого бенчмарка скорость кода измерялась внутри цикла, а производительность цикла как такового может страдать из-за косвенных побочных эффектов, связанных со входом в ядро и выходом из него. Об этом поговорим далее.
Притом, что этот бенчмарк позволяет выделить прямые издержки, в реальных ситуациях производительность также страдает из-за косвенных затрат, обусловленных микроархитектурными эффектами ЦП. Давайте далее о них и поговорим.
Косвенные издержки системных вызовов
Системные вызовы также сопряжены с косвенными издержками, поскольку на пути ко входу в ядро мы нарушаем микроархитектурное состояние ЦП. Эти побочные эффекты влияют на микроархитектурное состояние процесса в ЦП, и утрата этого состояния может привести к временному ухудшению производительности кода в пользовательском пространстве.
На микроархитектурном уровне ЦП реализует несколько оптимизаций, такие как конвейеризация инструкций, суперскалярность и прогнозирование ветвлений. Эти оптимизации при��ваны улучшить в программе пропускную способность по инструкциям, то есть, сколько инструкций ЦП может выполнить за цикл. Чем выше пропускная способность, тем быстрее выполняется программа.
Может потребоваться несколько циклов ЦП, чтобы программа перешла в такое стабильное состояние, в котором эти оптимизации начинают окупаться. Но, выполняя системные вызовы, это состояние можно утратить, в результате чего производительность программы может упасть.
Мы поговорим о косвенных издержках системных вызовов, обсудив разные затрагиваемые при этом компоненты микроархитектуры. Начнём с конвейера инструкций, а затем поговорим о буферах предиктора ветвлений.
Влияние на конвейер инструкций
В ядре Linux вообще не увидишь кода, который касался бы конвейера инструкций — напротив, это делается самим ЦП. Прежде, чем переключиться в режим ядра, центральный процессор опустошает конвейер инструкций, чтобы гарантировать, что код пользовательского пространства никак не помешает выполняться коду ядра. Это влияет на производительность кода пользовательского пространства именно на этапе возврата системного вызова. Чтобы понять, как это делается, давайте освежим в памяти основы конвейеризации инструкций.
У ЦП есть множество ресурсов для выполнения — например, регистры, функциональные блоки, буферы для загрузки и сохранения и т.д. Чтобы всеми ими эффективно пользоваться, необходимо организовать параллельное выполнение сразу многих инструкций в программе, а это делается при помощи конвейеризации инструкций и создания суперскалярной архитектуры.
При конвейеризации выполнение инструкции подразделяется на несколько этапов, подобно работе на заводском сборочном конвейере. В каждом такте процессора инструкция переходит от одного этапа к другому, и поэтому в каждом такте процессор может приступать к выполнению новой инструкции.
Например, на следующей схеме показан пятиэтапный конвейер. Как видите, для его заполнения берётся сразу пять инструкций, и по окончании данной итерации первая инструкция возвращается. Затем конвейер переходит в стабильное состояние и может обеспечить пропускную способность в одну инструкцию за цикл. Это очень упрощённый пример; современные процессоры с архитектурой x86 могут иметь гораздо более глубокие конвейеры, например, по 20-30 циклов.
| Выборка | Декодирование | Чтение памяти | АЛУ | Запись в память |
Такт 1 | И1 |
|
|
|
|
Такт 2 | И2 | И1 |
|
|
|
Такт 3 | И3 | И2 | И1 |
|
|
Такт 4 | И4 | И3 | И2 | И1 |
|
| И5 | И4 | И3 | И2 | И1 |
Пример простого конвейера, состоящего из пяти операций (выборка, декодирование, чтение из памяти, АЛУ, запись в память), демонстрирующий, как от такта к такту перекрывается выполнение многих инструкций
Кроме того, современные процессоры суперскалярные. В них есть множество таких конвейеров, благодаря чему на каждом такте они могут выдавать и выполнять многочисленные инструкции. Например, процессор с шириной 4 может на каждом такте начинать выполнение 4 новых инструкций и завершать выполнение ещё 4. Если на таком процессоре работает конвейер глубиной 20, то «на лету» он может держать в стабильном состоянии до 80 инструкций.
Таким образом, обычно процессор параллельно занимается выполнением десятков инструкций из пользовательского пространства. Но, когда поступает системный вызов, ЦП сначала должен удостовериться в завершении всех ожидающих пользовательских инструкций, и только потом может переходить в ядро.
Поэтому, когда системный вызов возвращается в пользовательское пространство, можно считать, что конвейер инструкций почти пуст — ведь процессор не допускает в конвейер инструкции, которые выстроились за системным вызовом. В этот момент конвейер возобновляет работу почти с нуля, и может пройти немало времени, пока он снова достигнет такой производительности, какую показывает в стабильном состоянии.
Для сравнения рассмотрим сценарий, в котором системного вызова не происходит: ЦП остаётся в стабильном состоянии, конвейеры заполнены, а пропускная способность при обработке инструкций остаётся высокой. Иными словами, единственный системный вызов может сбить темп десятков инструкций, которые выполняются прямо сейчас.
В архитектуре x86-64 инструкция syscall применяется для выполнения системного вызова. Вот как о ней сказано в мануале Intel:
«Упорядочивание инструкций: инструкции, следующие за SYSCALL, могут выбираться из памяти ещё до того, как закончится выполнение более ранних инструкций. Но они не будут выполнены (даже спекулятивно) прежде, чем завершится выполнение всех инструкций, предшествующих SYSCALL. Позднейшие инструкции могут быть выполнены до того, как станут глобально видимы данные, сохранённые более ранними инструкциями».
Таким образом, ЦП действительно сначала опустошает конвейер, а только потом передаёт управление ядру.
Как это сказывается на прогнозировании ветвлений
Следующий важный аспект влияния системных вызовов на производительность программ из пользовательского пространства связан с очисткой буферов предиктора ветвлений. Их можно сгруппировать в виде трёх категорий улучшений, применяемых ядром — все их мы видели в коде ядра выше.
Очистка буфера истории ветвлений
Разобучение буфера возврата стека
Включение/отключение IBRS
Первые две категории серьёзнейшим образом косвенно сказываются на производительности пользовательского кода. Включение/отключение IBRS не влияет на производительность кода в пользовательском пространстве, но влечёт прямые издержки при выполнении системного вызова. Правда, об этом мы здесь тоже поговорим, поскольку логически эта тема связана с прогнозированием ветвлений. Далее мы сначала рассмотрим, как устроено прогнозирование ветвлений, а затем обсудим всё по порядку.
Понятие о прогнозировании ветвлений
Благодаря конвейеризации инструкций и суперскалярному выполнению ЦП может параллельно выполнять множество инструкций, причём в свободном порядке.
Когда ЦП натыкается на ветвящуюся инструкцию, например на условие if, он может ещё не знать, к чему приведёт выполнение условия, так как обработка этого набора инструкций ещё может продолжаться. Если процессору необходимо дождаться окончания выполнения этих инструкций, чтобы знать результат ветвления, то конвейер может надолго застопориться — и производительность снизится.
Чтобы это оптимизировать, в ЦП реализуются так называемые предикторы ветвлений, которые могут спрогнозировать, по какому адресу в итоге завершится выполнение данной ветки, опираясь на уже известные по опыту работы паттерны ветвления. Благодаря этому ЦП может спекулятивно выполнить инструкцию, расположенную по спрогнозированному адресу и, соответственно, не простаивать. Если прогноз оправдается, то ЦП сэкономит множество тактов, и пропускная способность при обработке инструкций останется высокой.
Однако если прогноз окажется неверным, то ЦП придётся отбросить результаты спекулятивного выполнения этих инструкций, опустошить конвейер инструкций и выбрать те инструкции, которые находятся по верному адресу. На современных процессорах это может обходиться в 20-30 тактов (в зависимости от глубины конвейера).
Очистка буфера истории ветвлений
В коде ядра видно, что оно вызывает макрос CLEAR_BRANCH_HISTORY, который очищает буфер истории ветвлений (BHB).
BHB — это буфер в предикторе ветвлений, заучивающий глобальные паттерны, наблюдаемые в истории веток. Благодаря этой информации предиктор ветвлений может точнее прогнозировать исход глубоко вложенных и сложных паттернов ветвления. Ситуация напоминает следующую: вы запомнили несколько последних перекрёстков, которые миновали, и теперь лучше представляете, куда сворачивать далее.
Но на то, чтобы BHB собрал достаточно полную историю для предиктора веток, и тот стал генерировать точные прогнозы, может уйти немало времени. Поэтому всякий раз, когда вы выполняете в вашем коде системный вызов, и если при этом ядро очищает BHB, то вы теряете всё это состояние. В результате после возврата от системного вызова в вашем коде может возрастать количество неверно спрогнозированных ветвлений. Из-за этого может существенно испортиться производительность приложений, работающих в пользовательском пространстве.
Замечание о новых ЦП: такая очистка BHB была добавлена в ядро как мера противодействия атакам через спекулятивное выполнение кода, например, Spectre V2. В последние годы производители ЦП стали вносить аппаратные улучшения, благодаря которым в ядре уже нет необходимости очищать BHB. Например, консультант из Intel сообщает, что, если ваш ЦП оборудован «улучшенным IBRS» (об IBRS мы поговорим ниже), то нет необходимости очищать BHB. Таким образом, не все процессоры сталкиваются со снижением производительности по этой причине.
Если вы хотите проверить, очищает ли ваше ядро BHB, то посмотрите вывод lscpu. Если увидите в разделе об уязвимостях «BHI SW loop» — это означает, что при системных вызовах ядро очищает BHB.
Кроме того, если вы уверены, что никогда не выполняете недоверенного кода, то можете вручную отключить такую перестраховку, сняв специальный флаг, действующий во время загрузки.
Разобучение буфера возврата стека
Далее поговорим о разобучении буфера возврата стека (RSB). RSB — это ещё один буфер в предикторе ветвлений, при помощи которого прогнозируется адрес возврата для вызовов функций.
Но почему вообще нужно предсказывать адрес возврата? Здесь всё дело опять в неупорядоченном выполнении. Бывает так, что ЦП требуется выполнить инструкцию возврата, даже пока другие инструкции данной функции всё ещё выполняются. В этот момент ЦП ещё не знает адрес возврата. Адрес возврата хранится в памяти стека процесса, но обращения к памяти идут медленно. Поэтому ЦП при таком прогнозе использует буфер RSB.
При каждом вызове функции ЦП записывает адрес возврата в RSB. При выполнении инструкции возврата ЦП выталкивает один адрес из этого буфера и переходит по данному адресу. Поскольку этот буфер находится прямо в ЦП, доступ к нему происходит очень быстро.
Однако из-за этого также возникают уязвимости, например Retbleed. При такой атаке применяется тщательно подобранный код из пользовательского пространства, способный повлиять на то, как именно ЦП прогнозирует адреса возврата. Из-за такой атаки ЦП начинает спекулятивно выполнять инструкции не в той части ядра, где нужно. Притом, что такое спекулятивное выполнение не меняет логику ядра как таковую, в описываемом случае могут возникать утечки информации через побочные каналы. Чтобы этого избежать, буфер RSB при входе в ядро нужно разобучать.
При возврате системного вызова разобучение RSB сразу сказывается на производительности пользовательского кода, поскольку теперь RSB остался без состояния. Без обученного RSB процессору приходится прибегать к более медленному косвенному предиктору ветвлений, вероятность ошибки в котором выше.
Замечание о том, каких ЦП это касается: не во всех моделях процессоров ядро очищает RSB. Насколько известно, уязвимости, основанные на очистке RSB (retbleed и SRSO) затрагивают только процессоры AMD. Кроме того, если у вас в ЦП предусмотрены аппаратные оптимизации, например улучшенный IBRS, ядро эту операцию не выполняет (макрос UNTRAIN_RET на таких устройствах получает статус noop).
Опять же, в ядре можно отключить такую оптимизацию, но только в случае уверенности, что вы никогда не будете выполнять на этом процессоре недоверенный код.
Вход в режим IBRS и выход из него
Наконец, поговорим о косвенной спекуляции, ограниченной пределами ветки (IBRS). Как мы уже видели, ядро выполняет IBRS_ENTER при входе в системный вызов и IBRS_EXIT при возврате из него. Итак, что такое IBRS, и как это сказывается на производительности?
IBRS — это аппаратная возможность, ограничивающая косвенный предиктор ветвлений, когда он работает в режиме ядра. Фактически, IBRS не позволяет пользовательскому пространству, обучающемуся на косвенном прогнозировании ветвлений, как-либо влиять на косвенное прогнозирование ветвлений внутри ядра.
Косвенными называются такие ветвления в коде, чей целевой адрес не входит в состав инструкции, но известен только во время выполнения. Типичный пример такого рода — вызов через указатель функции на языке C (напр., (*fp)()), где конкретный финальный адрес зависит от того, какую именно функцию указатель удерживает в данный момент. Другой пример — вызов виртуальной функции в C++ или таблица переходов, сгенерированная для большого оператора switch. Во всех этих случаях ЦП может воспользоваться косвенным предиктором ветвлений и, исходя из известной истории ветвлений, попытаться угадать, к какому адресу в итоге придёт выполнение функции.
Когда были обнаружены Spectre и связанные с ней уязвимости, оказалось, что один из векторов атаки развивается так: заставить ЦП прогнозировать внутри ядра неверные финальные точки ветвлений. Влияя из пользовательского пространства на состояние предиктора ветвлений, злоумышленник мог заставить ЦП спекулятивно выполнять инструкции в не подходящих для этого точках ядра. Из-за этого чувствительные данные ядра могли утекать через побочные каналы, например через кэш.
Чтобы сгладить последствия такой атаки, нужно ограничить возможности косвенного предиктора ветвлений, когда он выполняется в режиме ядра. Это делается при помощи IBRS. Включая и выключая сам IBRS, мы никак не влияем на производительность кода, выполняемого в пользовательском пространстве, но сама эта операция требует выполнять дополнительные инструкции, которые превращаются в издержки, возникающие при каждом системном вызове.
Правда, в новейших ЦП есть фича под названием «улучшенный IBRS», которая автоматически активирует IBRS при переключении в режим ядра. На таких машинах макросы IBRS_ENTER и IBRS_EXIT, действующие в ядре, превращаются в noop.
В совокупности все эти меры объясняют, почему косвенные затраты на системные вызовы могут так существенно отличаться в разных поколениях и конфигурациях ЦП. На практике это означает, что всего один системный вызов может не только привести к опустошению конвейера, но и частично ослепить предиктор ветвлений. Из‑за этого ЦП будет вынужден заново заучивать паттерны и замедлять ваш код, пока «все не вспомнит». Здесь наиболее важно, что истинная стоимость системного вызова складывается не только из пары инструкций, выполняемых в ядре, но и из разрушительного воздействия, оказываемого системным вызовом на оптимизации, сделанные ЦП. Из‑за этого системные вызовы обходятся гораздо дороже, чем кажется на первый взгляд. Вот почему минимизация системных вызовов — столь мощная стратегия оптимизации. Тем не менее, пусть и медленно, производители ЦП добавляют аппаратные оптимизации, благодаря которым описанные здесь программные оптимизации устаревают и уже не так серьёзно снижают издержки, связанные с производительностью.
Как на практике сократить количество системных вызовов
Итак, что же делать вам как разработчику? Вот несколько идей на вооружение:
· Пользуйтесь vDSO: для таких вызовов, как clock_gettime, предпочтителен путь vDSO, позволяющий не входить в ядро.
· Кэшируйте дешёвые значения: некоторые значения, добытые через системные вызовы, редко меняются в течение жизненного цикла программы. Можете смело кэшировать их один раз, а затем переиспользовать — так можно будет не повторять многие системные вызовы.
· Оптимизируйте системные вызовы, связанные с вводом/выводом: существуют различные стратегии и паттерны, удобные для оптимизации системных вызовов, связанных с вводом/выводом (I/O). Например:
* Предпочтителен буферизованный I/O, а не необработанные системные вызовы для чтения/записи
* Пользуйтесь операциями рассредоточения/сосредоточения (scatter/gather), например, readv/writev, чтобы объединять несколько буферов в пакеты
* Если ваша система позволяет, пользуйтесь mmap, а не многократными вызовами для чтения/записи
· Пакетные операции: через такие интерфейсы, как io_uring, можно отправлять множество запросов на ввод/вывод, помещая их в разделяемую очередь в пользовательском пространстве — и затем ядро может обрабатывать эти операции порционно. В результате программе не так часто придётся обращаться к ядру.
· Передавайте работу в ядро: с появлением eBPF становится всё проще переносить элементы логики приложений на обработку в само ядро. Кроме наиболее распространённых практических случаев, таких как фильтрация пакетов, в новых фреймворках можно делегировать ядру такие задачи, как отслеживание соблюдения политик, мониторинг и даже (частично) обработку данных. В таких случаях пользовательская программа не станет делать многократные системные вызовы, а вместо этого будет загружать в ядро маленькие программы, срабатывающие именно в тот момент, когда произойдёт определённое событие. В таком случае можно вообще избавиться от переходов между ядром и пользовательским пространством.
В этих приёмах нет никакого волшебства, но все они следуют общему принципу: чем меньше таких переходов, тем меньше разрушительных изменений. Всякий раз, когда удаётся обойтись без системного вызова, вы не только экономите вызов функции в ядре, но и избавляете ЦП от скрытых затрат, связанных с возвращением в обычный рабочий режим.
Заключение
Мы разобрали множество деталей в, казалось бы, маленькой выдержке из кода ядра. Суть проста: системный вызов стоит гораздо дороже, чем сумма тех немногочисленных инструкций, которые выполняются в ядре. Он нарушает ритм работы ЦП, так как опустошает конвейеры, сбрасывает предикторы и заставляет всё начинать сначала. Вот почему при профилировании системные вызовы выделяются как яркие точки, и почему специалисты так тщательно стараются их избегать.
Стратегии, рассмотренные нами ранее (vDSO, кэширование, оптимизация ввода/вывода, пакетное объединение операций при помощи io_uring и передача работы в ядро) служат одной цели: минимизировать эти разрушения. Они не позволят полностью избавиться от издержек, связанных с системными вызовами, но именно они делают разницу между кодом, в котором масса времени тратится на ожидание в ядре, и кодом, который позволяет постоянно гонять ЦП на полной скорости.
Системные вызовы работают на стыке между ядром и железом. Они необходимы, но имеют свою цену. Чтобы писать быстрый софт, чрезвычайно важно понимать эту цену и уметь ею управлять.


{kind=link}
{kind=link}