Комментарии 171
Начиная от использования новых возможностей языка, заканчивая нежеланием разработчиков всю жизнь возиться с языком (и костылями) двадцатилетней давности
Ну так вариантов-то нету, апдейтов миллиарды лет не было
После того, как релизнут теорию струн, он автоматически спортируется на теорию струн (это show-stopper для теории струн).
по идее нету там никаких миллиардов
Возможно, не вполне удачно?
Переход на новый стандарт, как мы предполагали, позволил бы нам писать многие вещи элегантней, проще и надежней, упрощал поддержку и сопровождение кода.
И мы не ошиблись.
См. также раздел «Итоги» статьи, в частности
После миграции у разработчиков появилось больше возможностей. Если раньше у нас была своя доработанная версия STL и один неймспейс std, то теперь у нас в неймспейсе std находятся стандартные классы из встроенных библиотек компилятора, в неймспейсе stdx – наши, оптимизированные для наших задач строки и контейнеры, в boost – свежая версия boost. И разработчик использует те классы, которые оптимально подходят для решения его задач.
Использовать новые возможности, имея часть кода в старом стандарте, часто очень затруднительно, а иногда просто невозможно.
С другой стороны, после того, как оно завелось, дало сразу процентов 20 прироста производительности.
Я уже 100 лет не писал на C++, но вот такой вопрос: использование char16_t не добавит головной боли пользователям, если вдруг им понадобится вбивать имена или названия на китайском, лаосском, кхмерском и прочих экзотических алфавитах?
UTF-8 дает универсальность, а UTF-16 — скорость обработки. Для 1С скорость обработки оказалась в приоритете.
{kind=link}
1. Почему вы не использовали везде максимальный размер wchar_t из существующих систем = 4 байта? Эффективность расширения стандарта на порядок выше, чем при его урезании.
2. Если вы уже пришли к использованию компилятора GCC для Linux, то как же вас угораздило продолжить компилировать в VS2005 под Win?? Вы же могли компилировать под обе платформы используя одну версию GCC. Сколько головной боли ушло бы с упразднением третьего компилятора, 2 против 3.
2. Visual C++ это до сих пор наилучший выбор при компиляции под Windows. GCC не обеспечивает инфраструктуру для продуктивной и комфортной работы под Windows.
2. Я, разумеется, снимаю шляпу перед вашим профессионализмом, и вашего главного специалиста по С++, которого вы упомянули вначале статьи, но, по-моему, тут имеет место заблуждение…
В IDE Visual Studio (как инфраструктуре для продуктивной и комфортной работы) вы можете использовать любой компилятор, и CLang и GCC и MSVC.
Но начиная с C++11 GCC "превосходит любую доступную версию MSVC по качеству сгенерированного кода", это очевидная аксиома… Плюс именно своевременная и грамотная поддержка новых стандартов C++ и является главной вишенкой на GCC, как не парадоксально это бы ни звучало (мол как сам Microsoft может запаздывать со своим же компилятором!? Вот так и может и завидно регулярно.).
Но тут, разумеется, вопрос не в убеждениях. Надо компилировать и сравнивать производительность. Просто несколько огорчает, что в 2018 году вот так на веру берется MSVC, да еще для такого мега-кроссплатформенного национального проекта… как-то это не современно, на мой взгляд.
Надо компилировать и сравнивать производительность. Просто несколько огорчает, что в 2018 году вот так на веру берется MSVC
А где в статье сказано про веру? ;)
MSVC был выбран по объективным причинам.
Одна из основных причин — отладочная информация и отладчик. GCC не умеет генерировать полноценные pdb чтобы использовать отладчик из Visual Studio или WinDBG. И при этом не имеет отладчика под Windows. Далее, все остальные инструменты под Windows, профилировщики и прочее работают только с pdb.
То же самое относится и к clang.
Качество сгенерированного кода msvc нас устраивает более чем, для нашей кодовой базы оно даже в каких-то случаях лучше, нежели в gcc под Linux.
В чем именно неполноценность генерации pdb в GCC? Если может помните на вскидку, вот прямо пример, что такого вам не выгрузил в pdb GCC 7?
Насколько я помню, время проприетарного PDB от Microsoft и форматов STABS или DWARF-2 от GNU tools прошло году эдак в 2010.
Сейчас GCC выдает стандартный PDB, а для любых сред, кроме Win, по сути дела всегда применяется отладчик GDB.
Для VisualStudio, пожалуйста, используйте WinGDB, уже стало классикой, по-моему.
У JetBrains свой встроенный GUI для GDB.
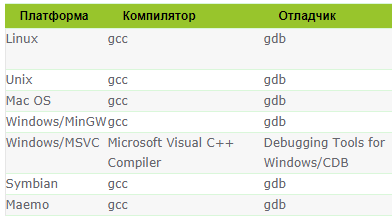
Из таблицы хорошо видно, что если закрыть глаза на CLang (тут я, увы, не специалист), то вы могли вообще для всех сред использовать одну единственную среду разработки с одним компилятором и отладчиком. Да вы просто могли поднять уровень разработки на уровень БОГ! в плане унификации))
И если в очередном C++, например, меняется реализация std::map, и единственный компилятор GCC начинает с ключом оптимизации __attribute__((optimize(«O3»))) аллоцировать память, а без ключа — нет, то это поведение становится ПРЕДСКАЗУЕМО для всех платформ, под которые вы работаете.
Отладчик Visual Studio является основным инструментом под Windows для нас и тут мы наталкиваемся на проблемы с поддержкой pdb.
Использовать одну и ту же среду во всех случаях — это нереально. Ведь у нас помимо Windows также есть Linux, macOS, веб-клиент, Android и iOS.
Хорошая новость — в clang сделали пробную версию генератора PDB, не без помощи Майкрософт, открывшей информацию по PDB. Но все это пока на ранней стадии.
Мне конечно использование gcc/mingw тоже нравится больше. Ими можно компилировать из-под линукса, из разных автоматизированных систем, итд.
Если у вас есть много свободного времени, вы можете расковырять генератор PDB от clang и прикрутить его к gcc для решения проблемы отладки.
Лучше с самого начала не закладываться на особенности компилятора, не создавать технический долг, который рано или поздно придётся выплачивать.
github.com/rainers/cv2pdb
уже давно использую его чтобы выводить красивый стектрейс через dbghelp
Почему вы не использовали везде максимальный размер wchar_t из существующих систем = 4 байта? Эффективность расширения стандарта на порядок выше, чем при его урезании.
Использование wchar_t не означает автоматически правильную обработку строк без каких-либо усилий со стороны программиста. При работе со строками нельзя забывать, в какой кодировке они находятся.
Если взять Юникод, то один даже четырёхбайтовый wchar_t не способен представить все графемы таким образом, чтобы не оставить возможностей для ошибки. Как минимум, популярные ныне эмоджи могут требовать нескольких code points.
Поэтому при прочих равных лучше уж взять тип данных, размер и семантика которого не зависит от платформы, под которую собирается код.
Реальный мир часто абсурден. Хотя лично я тоже убеждённый сторонник повсеместного использования Юникода для представления текстов, но есть некоторые вещи, которые Юникод представить не в состоянии. Вроде некоторых имён. Однако, это не технический вопрос об устройстве стандарта, а больше вопрос администрирования консорциума, который отказывается добавлять в стандарт редко используемые или «повторяющиеся» символы.
Также с не-Юникодом точно придётся контактировать на границах системы, за которыми бушуют океаны легаси-кодировок, будь то файлы в КОИ-8 или HTTP, который по умолчанию использует Latin-1.
Если взять Юникод, то один даже четырёхбайтовый wchar_t не способен представить все графемы таким образом, чтобы не оставить возможностей для ошибки. Как минимум, популярные ныне эмоджи могут требовать нескольких code points.
4 байта (UTF-32) как раз полностью покрывает весь Unicode. Выбор размера char влияет лишь на способ представления, но не на сами символы, поэтому в UTF-16 приходится использовать суррогатную пару. Более того, использование UTF-32 как раз лишает программиста головной боли связанной с обработкой текста, как набора Unicode символов, поскольку в таком случае у тебя в памяти лежит массив char'ов, где каждый char — это конкретный символ Unicode.
Все неприятности начинаются уже при работе непосредственно с самим Unicode.
Если опустить проблемы связанные с поддержкой новых версий стандарта, когда твоя библиотека тупо может не знать о существовании каких-нибудь новых диапазонов, то всплывает, например, проблема комбинирования символов.
С одной стороны, не так может оказаться страшно, если комбинацию нескольких символов можно с помощью алгоритмов нормализации привести к одному символу того же Unicode. Как в примере с википедии:
й й — первая буква состоит из 1 unicode символа, а вторая — из 2. (можете скопировать в блокнот, сохранить в UTF-16 и посмотреть в HEX)
Но вот уже проблемой становится, когда попадается нестандартные комбинации, типа «белая женщина-врач», являющейся комбинацией символов «женщина» (U+1F469), «модификатора — белый цвет» (U+1F3FB), «символ медицины» (U+2695) и zero-width joiner (U+200D) между ними. Такая комбинация вообще не декларируется стандартом и эмодзи такого в Unicode нет по понятным причинам.
Более того, использование UTF-32 как раз лишает программиста головной боли связанной с обработкой текста, как набора Unicode символов, поскольку в таком случае у тебя в памяти лежит массив char'ов, где каждый char — это конкретный символ Unicode.
Вот именно что не решает. Как раз из-за комбинаций, образующих одну визуальную единицу. Когда я выделяю в текстовом поле «⚕️» — а что вы видите в своём браузере? что хабраредактор сделал с моим текстом? — и копирую этот символ, то обычно ожидается, что скопируются все четыре code points, из которых он состоит:
- U+1F469 WOMAN
- U+200D ZERO WIDTH JOINER
- U+2695 STAFF OF AESCULAPIUS
- U+FE0F VARIATION SELECTOR-16
Не один wchar_t, а четыре. Откуда-то текстовое поле должно знать, что в этом конкретном случае надо поступать именно так. Здесь, правда, ситуация немного натянутая: текстовое поле как бы занимается отображением текста, так что оно-то и так в курсе, сколько визуального места занимает каждая последовательность байтов, кодирующая тот или иной текст.
Программист здесь может ошибиться, например, в операции «взять первый символ» в строке, реализовав её как string[0]. Если используется UTF-8, то эта операция вернёт некорректный UTF-8 текст из одного байта 0xF0. Если используется UTF-32, то эта операция даст технически корректный текст, но будет семантически неверной, так как потеряет все пришлёпнутые сзади модификаторы.
Юникод — это фундаментально кодировка с переменной длиной графем. Работать с текстом в основном надо либо на визуальном уровне графем (иногда их частей) для отображения и редактирования, либо на уровне байтов для передачи и хранения. Формат представления никак не помогает правильно работать с графемами: что в UTF-32, что в UTF-8 надо знать отдельные правила их обработки. В любом случае для обработки графем придётся жить с тем, что один условный char в массиве не соответствует одной графеме.
Для передачи и хранения вообще удобнее работать как раз с массивом байтов, так как длина массива байтов в байтах и порядок байтов в байте не зависит от операционной системы, архитектуры процессора и компилятора. С этой точки зрения UTF-8 является идеальным форматом. У UTF-16 есть преимущество в компактности для текстов на языках, символы которых в UTF-8 кодируются тремя байтами. (Плюс, есть исторически сложившиеся API, принимающие именно UTF-16.) У UTF-32… есть много лишнего места, разве что. Это удобное промежуточное представление для преобразований между форматами, но для хранения и обработки UTF-32 подходит не очень.
Юникод — это же в первую очередь таблица «индекс — символ», а проблема вывода лежит в области обработки массива таких индексов.
Согласитесь, что проще оперировать голыми int'ами, как в случае той же «женщины-врача» — это по сути конкретная последовательность {0x1F469, 0x200D, 0x2695, 0x200D, 0xFE0F}. При обработке, в таком случае, нас ждёт всего одна операция — поиск такой последовательности в массиве. В случае же работы с каким-нибудь UTF-8 перед тем, как искать последовательность потребуется перекодировать данные для получения опять же набора int'ов.
Только не подумайте, что я топлю за использование 4 байтов. Накладные расходы на хранение таких данных, особенно при работе с большим количеством строк, как тут — это слишком.
Только когда приходит время отправлять текст в сеть или записывать его на диск — а они работают только с байтами — в случае UTF-32 приходится выбирать, записать U+1F469 как {0x00, 0x01, 0xF4, 0x69} или как {0x69, 0xF4, 0x01, 0x00}, аналогично для UTF-16 — {0xD8, 0x3D, 0xDC, 0x69} или {0x3D, 0xD8, 0x69, 0xDC}, тогда как в UTF-8 вариант только один: {0xF0, 0x9F, 0x91, 0xA9}.
А ещё можно вот какой финт сделать в UTF-32:
1) Нормализуем.
2) Заменяем все нестандартные последовательности на свои индексы из пользовательских диапазонов.
3) Теперь с таким массивом действительно можно работать, как с массивом визуальных единиц не боясь повредить данные.
И я понимаю, что проблема порядка байт остаётся, но я же говорю не о проблеме хранения и передачи, а об удобстве обработки таких данных.
Идея с использованием неиспользуемых значений в UTF-32 интересная. В 4 байта же действительно можно разместить ещё 4096 дополнительных Юникодов, если использовать лишние битики. Не знаю, будет ли какой-то существенный выигрыш в производительности от такой замены и нестандартного представления, но идея однозначно интересная! Спасибо.
По поводу второго пункта — очень странная идея использовать gcc везде, я бы еще понял, если бы вы clang предложили, но gcc после ухода с него андроида постепенно уходит в легаси. Симбиан и Маемо в 2018 году никому не нужны, ios — clang, андроид — clang, win — msvc или clang, linux — gcc или clang.
Ну и под вин ничего лучше msvc все же нет, несмотря на усилия clang (а не gcc) в этом плане. Как и лучше IDE, чем Visual Studio, при всем уважении к CLion. И по части стандартов msvc сильно подтянулся, хотя до clang не дотягивает.
Т.е. в плане унификации, сейчас GCC все же более удобен.
СLang — будем посмотреть))
Ну так как 1C на микроконтроллерах не работает и вряд ли будет, то это к теме поста отношения не имеет. Соглашусь, что в embedded gcc может быть и сильнее — не сильно погружен, не могу всерьез комментировать — но игнорировать iOS и Android тоже нельзя — а там gcc (уже) нет. Так что с тезисом про унификацию согласиться не могу.
При этом ее полезность тоже не стоит переоценивать — у нас в компании легко собирается продукт под gcc разных версий, clang разных версий и MSVC разных версий — наверное, 6 вариантов суммарно — и не могу сказать, чтобы это было как-то так уж сложно сейчас. Основные проблемы в АПИ платформы, а тут никакой компилятор не поможет.
Даже демо платформы ( platform.demo.1c.ru/demo83 ) до сих пор не переведено на типа актуальную 8.3.13, а остается на 8.3.12.
Остается надеяться, что 1С в ближайшее время таки справится с проблемами, связанными с таким серьезным переходом.
В типовых или в самописных?
Простой пример, динамический список ведет себя непредсказуемо как элемент формы — при клике позиционирует выбранную строку всегда посередине. Запрос дин. списка очень простой (выборка из документа даты, номера, автора). 95% процентов пользователей работают через веб-клиент. Если действительно интересны выявленные проблемы, могу еще раз провести тесты на 8.3.13 и передать результаты.
Самостоятельно разработанные конфигурации.
Но по стандартам и методикам 1С,
При выходе новых версий платформы 1С публикует изменения стандартов.
Так что конфигурации может потребоваться модифицировать для работоспособности в новых версиях платформы.
с нормализованной схемой БД.
А это про что, можете пояснить?
В 1С объекты БД явно не создаются, это делает платформа, и в этот механизм вмешиваться не рекомендуется.
Простой пример, динамический список ведет себя непредсказуемо как элемент формы — при клике позиционирует выбранную строку всегда посередине. Запрос дин. списка очень простой (выборка из документа даты, номера, автора). 95% процентов пользователей работают через веб-клиент. Если действительно интересны выявленные проблемы, могу еще раз провести тесты на 8.3.13 и передать результаты.
Если не сложно — сделайте пожалуйста.
Воспроизведутся проблемы — шлите конфигурацию, будем чинить.
При выходе новых версий платформы 1С публикует изменения стандартов.
Так что конфигурации может потребоваться модифицировать для работоспособности в новых версиях платформы.
Мы это учитывает.
А это про что, можете пояснить?
В 1С объекты БД явно не создаются, это делает платформа, и в этот механизм вмешиваться не рекомендуется.
В работу платформы на уровне SQL не лезем. Чтобы писать запросы, нужно понимать что из себя представляет БД 1С. А мы знаем, что это таблицы в СУБД. Поэтому при проектировании структуры объектов конфигурации оперируем понятием «таблица», но с использованием тонкостей 1С (периодичность регистров сведений, регистры остатков, оборотов и т.п.). Соответственно, приводим схему данных в такое состояние, когда у нас нету избыточности. Или нехватки данных (статья на ИТС про самодостаточность регистров).
Если не сложно — сделайте пожалуйста.
Воспроизведутся проблемы — шлите конфигурацию, будем чинить.
Хорошо. Результаты лучше в личку?
Вообще, это наверное, с молодостью проходит — восторженныая радость при слежении за обновлениями и переворотом в технологиях. Со временем обновления ОС, IDE, библиотек и сервисов вызывают лишь чувство досады, иногда тревоги, иногда — испанского стыда, но больше просто легкое раздражение, что опять придетмя ковырять то, что давно в продакшне.
Как раз сейчас в С++ контейнеры особенно модернизируются. Например, для того, чтобы эффективно работала в С++17 вот какая изящная конструкция множественной итерации.
for (auto [x,y,z] : zip( xs, ys, zs )) {
// ...
}Сейчас вы вынужденны применять для этой задачи все тот же сторонний Boost (реализация которого иногда тяжеловата, т.к. он опирается на существующие контейнеры, создавая над ними обертки)
for(auto&& t : zip_range(contA, contB)) {
t.get<0>(items) = t.get<1>(items);
}И, кстати, для окончательного отказа от указателей, в пользу новых интеллектуальных указателей или модернизированных ссылок (С++17) также придется оптимизировать/переписать реализацию всего, где происходят итерации по массивам.
В итоге-то новая версия стала работать быстрее или медленнее, что с памятью стало?
Новая версия платформы на типовых сценариях работает не медленнее старой.
И потребляет при этом не больше памяти, чем старая.
И потребляет при этом не больше памяти, чем старая.
Коллеги на проф. форуме неоднократно описывали обратное. Например:
partners.v8.1c.ru/forum/t/1723890/m/1747082
Новая версия платформы на типовых сценариях работает не медленнее старой.
И потребляет при этом не больше памяти, чем старая.
Перед релизом мы тестируем на типовых сценариях.
Когда нам присылают сценарии, на которых есть деградация по производительности/памяти — мы, по мере возможности, фиксим платформу и исправляем ситуацию.
Все возможные сценарии, как вы понимаете, перебрать в принципе невозможно.
И попутно угробили работоспособность конфигурации 1С: ЖКХ
А что случилось с 1С:ЖКХ на новой платформе?
Про общую скорость работы я вообще промолчу, она все хуже и хуже
На каких сценариях она все хуже и хуже?
Ошибки:
{ВнешняяОбработка.МенеджерОбъектов.МодульОбъекта(9)}: (EObjectNotFound) Object «СЗК_ЗащищеннаяОбработка» is not found
{ВнешняяОбработка.МенеджерОбъектов.МодульОбъекта(9)}: (EBadFileFormat) Bad file format
Вылетает при попытке доступа к Зданиям при создании или редактировании.
2. Бухгалтера с каждым новым обновлением платформы поднимают вонь что так работать невозможно, что тормозит ужасно. Мне сравнивать не с чем, я так, по сути немного помогаю по мелочи, но и сам тыкаясь по разделам ощущаю что оно довольно медленно ворочается даже на почти пустой базе под ЖКХ, особенно при сохранении данных. При этом сервер на котором стоит платформа, БД и работают тонкие клиенты даже не напрягается. БД — SQL Server.
Это что-нибудь из вот этого комплекса?
Или речь совсем о другом?
Конфигурация, насколько понимаю, не от 1С.
Перестала работать после обновления платформы до последней версии. Не помню, правда, какая то версия была. Сами разработчики конфигурации говорят что работает стабильно на 12й версии, а 13я глючная (это с их же слов). При этом откатиться назад нельзя т.к. станут несовместимы какие-то другие конфигурации.
Вот эта: vgkh.ru/jsk/jkh/capabilities.php
Тут вопросы к разработчикам конфигурации.
Они декларировали совместимость конфигурации с той платформой, на которой появляются проблемы?
При этом откатиться назад нельзя т.к. станут несовместимы какие-то другие конфигурации.
Насколько знаю — можно поставить разные версии платформы даже на один сервер и разные конфигурации запускать под разными версиями платформы. Или у вас не та ситуация?
Вариант с разными версиями прекрасен во всей своей костыльности.
Все это звучит прямо как «мы тут что-то сломали, но это не наша проблема».
Вот реально платишь хренову тучу денег за гемор с лицензиями, с обновлениями, с сопровождением, с переносом данных и т.д. и т.п.
Я к этому всему имею немного косвенное отношение т.к. моя задача была перенести данные из существующей системы в 1С и потом это все интегрировать в кабинет пользователя. И понеслось…
Да кто ж его разберет теперь декларировали или нетДак тот, кто обновлял — тот и разберёт)
Где туча денег? Если не обновлять конфигурации, то можно ничего не платить. Если обновлять то можно покупать итс.техно за 12500 в год. Это примерно 1 МРОТ. А для базовых версий обновления бесплатны. Вы уверены, что это туча денег?
Про не обновлять конфигурацию, я надеюсь, вы пошутили… Конечно, можно в целях крайней экономии к этому варианту прийти, но тогда уж проще и дешевле использовать аналогичные продукты, если такие имеются на рынке.
ИТС на локальную сеть нужен один. Остальные лицензии — это разовые затраты, компьютер же бесплатно никто не дает? Обновление типовых конфигураций с появлением расширений можно доверить роботу, да расширения бывают отваливаются, но для меня это не критично. Не обновляться вообще? Легко на вмененке или упрощенке.
Я так понял что основная проблема была «угловые скобки у нас были разделены пробелами». Зато теперь модно, молодёжно:
— увеличили потребление памяти (всеобщий тренд)
— стало требовать свежее железо для сборки (наконец-то можно обновить пакр)
— winxp в пролёте
— теперь нужны более дорогие специалисты для поддержки кодовой базы (а то лезут тут всякие)
— тесты стали тоже требовать больше ресурсов
— функционал тот же но исполняемый файл солиднее и капризней
— зато теперь можно использовать свежий boost (а не эти костыли)
«Небыло печали купила баба порося»: Кодовая база стала меньше? Время сборки уменьшилось? Время на устранение багов сократилось или стало более предсказуемым? Или просто доработать чтобы компилировалось и проходило тесты? В чем огромный плюс проведённо титанической работы особенно для клиента?
В целом ваш высококвалифицированный разработчик просто красавчик. Его плюсы затмевают ваши минусы. Предлагаю повысить ему зарплату.
MSVC прекрасно компилирует бинари под xp вне зависимости от стандарта языка, нужно просто соответствующий тулчейн выбрать.Собирать то он собирает, но работать не будет. И никто с этим заморачиваться не захочет.
это не «более дешевый» специалист, это просто плохой специалистДело не в плохой/хороший. Сравните объём ненужного в новом стандарте, объём знаний который надо запихать в студента за ограниченное время. Думаете качество знаний в таких условиях тоже будет расти? Так что затраты на обучение новых специалистов будут непрерывно расти пока не придёт понимание что дорогонах.
Сделали бы уже новый С++ явно не совместимым со старым вместо того что-бы регулярно собирается и выдумывать как еще фишку прикрутить к 38 летнему старью, оставив старьём.
Ведь по факту получаем что каждый раз нужна работа по переводу кода на новый стандарт C++ разве это не странно при наличии обратной совместимости?
сейчас набежит школота и скажет, что я ниосилятор. Да, признаю, просто невозможно успевать за развитием с++.
Просто есть баланс: латать по-чуть-чуть и прямо сейчас (получают маленькие проблемы, которые потихоньку можно править). Или переписать все, например, на той же Джава. И сколько человеко-часов единомоментно тогда придется потратить? К тому же, простого пути миграции с одной экосистемы языка на другую нет. Поэтому технический долг нарастает.
Вообще это печально постоянно жертвуют здравым смыслом ради непонятно чего. И потом тыкают лозунгом мы не хотим платить за то что не используем. Зато потом за это платят все остальные.
И пример ситуации, когда v141_xp генерирует нерабочий бинарь, вы конечно привести сможете.
Например 1, [2](http://qaru.site/questions/847528/vs2017-and-missing-api-ms-win-core-rtlsupport-l1-2-0dll-on-win7xp), 3Чисто из любопытства, зачем вы заходите на помоечные сайты типа qaru?
Все материалы там взяты cо StackOverflow и подвергнуты автоматическому переводу.
К примеру, вот оригинал второй ссылки на SO: https://stackoverflow.com/questions/45745336/vs2017-and-missing-api-ms-win-core-rtlsupport-l1-2-0-dll-on-win7-xp
2. Косяк разработчика: почему-то
— он взял не те библиотеки (onecore вместо x86)
— не воспользовался статической линковкой
— не воспользовался Redist
3. Проблема не сколько с MSVC, сколько с Windows SDK.
Работа семейства функций _stat исправлена ещё в Universal C Runtime 10.0.10586 (плюс ещё одна причина использовать Redist, вместо того, чтобы таскать всю эту пачку из 40+ библиотек с собой)
- делали ли код-фриз на время переноса? Если нет, то не было потом проблем со слиянием багфиксов предыдущих релизов и крайней версии, перенесенной на новый тулинг С++?
- Используете ли техники статического анализа кода? Например, продукт PVS Studio www.viva64.com/ru/pvs-studio
- Не появилось ли проблем у пользователей при миграции между версиями? Т.к. бинарные данные изменили формат/layout или еще что-нибудь
1. Код-фриз не делали, работы над стволом и новым стандартом велись параллельно. После обновления, в некоторых случаях, конечно, есть проблемы переноса исправлений в старые версии платформы (без поддержки стандарта C++14).
2. Конечно используем на постоянной основе. PVS Studio основной инструмент.
3. Формат бинарных данных затронут не был. Только алгоритмы обработки. Так что проблем с этим не было.
Тесты после перехода показали проседание производительности (местами до 20-30%) и увеличение потребляемой памяти (до 10-15%) по сравнению со старой версией кода. Это было, в частности, связано с неоптимальной работой стандартных строк. Поэтому строку нам опять пришлось использовать свою, слегка доработанную.
Любопытно. Если бы у Вас не было альтернативной реализации строки под рукой, то Вы бы никогда и не провели такой тест, верно?
Если это только отдельные места, где производительность просела до 20-30%, то может надо было эти места оптимизировать или даже (крамола!) кое-где забить на это? Всё-таки отказ от стандартной строки это серьёзный шаг.
Всё-таки отказ от стандартной строки это серьёзный шаг.
Мы этот шаг сделали довольно давно :)
По моему опыту, любые проекты, много работающие со строками, используют свою реализацию строк, по ряду причин, не последняя из которых — быстродействие. Из того что видел сам — платформы двух больших западных ERP (это даже частично сам писал), и вот еще 1С. Из того, про что слышал — уже упомянутый Facebook, например.
Когда запуск ускорите? А то получается, как с MS Offise и LibreOffice. Первый запускается вечность, а второй на той же конфигурации раза в три быстрее при первом запуске и раз в 20 при повторном. Только вот у вас к сожалению конкурентов нет.
И потом, переход на UTF-8 может оказаться несравнимо тяжелее, нежели переход на новый стандарт, ситуацию нужно тщательно анализировать, учесть все возможные выигрыши и потери.
Это безумно большая цифра для программного кода, с таким объёмом он уже должен обрести собственное сознание…
Возможно имелось в виду общее количество строк?
Вместе с пустыми хидерами со стандартной шапкой, отсутствием кода и смысла. Почти любой проект содержит 99% подобного мусора, кроме самых мелких — для них ещё всё впереди.
В этом случае можно достичь большей оптимизации — просто удалив воду. Алгоритм при этом не пострадает, я уверен в этом.
Это безумно большая цифра для программного кода
Чем же эта цифра пугает. 10 миллионов строк. В половине строк по одному символу ({ и }), еще четверть строк (если не больше) — комментарии и т.д.
Посмотрите на код Firefox или что-то в этом духе. А вы говорите "безумно большая цифра".
А вся статья изложена в заголовке:
Как мы перевели 10 миллионов строк кода C++ на стандарт C++14 (а потом и на C++17)
www.visualcapitalist.com/millions-lines-of-code
Используются ли дополнительные инструкции процессора в коде, или вся надежда на компилятор, что он верно сам увидит и соптимизирует.
Вариант выпуска нескольких наборов бинарников, условно «под старые процессоры» / «под новые процессоры» хотя бы для Windows платформы не рассматривался?
По поводу двух редакций — сейчас фактически так и есть, 32-битная платформа для старого железа и ОС, 64-битная платформа — для современных. В том числе для этого мы сделали 64-битный клиент и Конфигуратор.
Речь шла о клиентских компьютерах и, соответственно, процессорах. С серверными такой проблемы нет.— с какого момента с серверными бинарниками нет проблемы, простите?
Если приходится выискивать древние высокочастотные Xeon для того, чтобы оно быстрее работало, а новые не дают прироста скорости от слова совсем.
Серверные бинарники компилируются и оптимизируются под какую версию CPU сейчас?
Высокая частота и новые инструкции в процессорах не должны коррелировать.
64-битные бинарники собираются с generic x64 инструкциями, включающими в себя, например, sse2 и cmov. AVX не используется, да и мест в платформе таких практически нет, где бы от них был явный выигрыш.
И вот, что странно. На новых Xeon те же приложения IIS почему-то работают заметно быстрее, а вот 1С — нет. Даже медленнее.
Нет оптимизации или «специфика вычислений» сказывается?
У нас был свой класс для строк, т.к. у нас в силу специфики нашего софта строковые операции используются очень широко и для нас это критично
и при этом нет нормальной возможности использовать регулярки…
Ну а если серьезно — мы периодически возвращаемся к этому вопросу, но окончательного решения пока так и не приняли. Регулярные выражения — это «веревка достаточной длины чтобы выстрелить себе в ногу». Введение ее в платформу, развитие и поддержка — очень серьезная задача, влекущая за собой, помимо вложения в нее ресурсов, как плюсы, так и минусы.
Чего будет больше — вопрос очень непростой.
А ресурсы… Я не C++ программист, но думаю задействовать стандартную библиотеку особого труда не составит.
задействовать стандартную библиотеку особого труда не составит.
А какую считать стандартной?
Далее, после выбора стандарта, надо документировать, обучать, поддерживать работу на разных ОС и т.д. и т.п.
Т.е. все это — весьма серьезная активность. Плюсы реализации которой, как я уже говорил, неочевидны. А не просто задействовать стандартную библиотеку.
Для решения generic задач стандартная строка вполне подходит.
Для решения задач частных, по моему опыту, каждый большой проект пишет строку для себя, под свои потребности и специфику, либо с нуля, либо беря за основу ту же Facebook-строку из folly например.
Т.е. польза для комьюнити от вливания нашей строки в стандарт будет, мягко говоря, спорной — наша строка хороша для наших задач, и не факт, что оптимально подойдет для других проектов.
Классов строк в open-source библиотеках немало (и в стандарт они не вошли!), и добавление нашей реализации ничего нового не привнесет.
1. В связи с переходом на стандарт C++17 в платформе 14 планируется ли нативная поддержка регулярных выражений?
2. Планируется ли развитие Механизма анализа данных в сторону ML (machine learning)?
Прокомментируйте пожалуйста, если это не секрет.
1. В связи с переходом на стандарт C++17 в платформе 14 планируется ли нативная поддержка регулярных выражений?
Пока не планируется.
2. Планируется ли развитие Механизма анализа данных в сторону ML (machine learning)?
Прокомментируйте пожалуйста, если это не секрет.
Секрет :)
Объявлялось же недавно что планируется добавить возможности работы с машинным обучением. Вроде уже где то даже обкатывается.
Хм, а ссылку можно?
«Фирма „1С“. Состояние дел, стратегия и развитие корпоративного направления» Нуралиев Борис, директор, «1С»
но запись трансляции целиком я почему то не смог найти, хотя смотрел интересующие меня вещи в ней, а по ссылке почему то записи именно этого доклада нет.
Тесты после перехода показали проседание производительности (местами до 20-30%) и увеличение потребляемой памяти (до 10-15%) по сравнению со старой версией кода. Это было, в частности, связано с неоптимальной работой стандартных строк. Поэтому строку нам опять пришлось использовать свою, слегка доработанную.
Из написанного не до конца понятно производительность вернулась на прежний уровень или нет после изменений?
1) Сделайте в конфигураторе, возможность группировать те же общие модули (хотя бы их) либо по подсистемам (про отбор по подсистемам я в курсе), либо (что лучше) вообще сделать возможность создания произвольных групп. Например создать группу «Работа с подключаемым оборудованием» или «Мои модули», а то в современных конфигурациях написанных на базе БСП и БПО, такое большое количество модулей, что становится тяжело с ними работать. При этом можно (и наверное даже нужно), чтобы эта иерархия была прозрачная для кода (тогда ничего не придется существенно изменять).
2) Для динамических списков, не хватает возможности выборки временной таблицы, бывает что есть достаточно большой объём тяжелой «статичной» информации, которую и дорого считывать постоянно, да и нет особой необходимости. Я понимаю, что это вступает в конфликт с «Динамическим считыванием», но можно же как-то разделить части запроса, какие считываются один раз, а какие данные обновляются динамически?
3) При работе с внешними источниками данных, не хватает возможности создания произвольных запросов к базе на её диалекте. Бывают ситуации, когда оптимально написать прямой запрос к базе, имея все возможности базы данных, а не только те, которые предоставляет 1С. Да, есть функции, но опять же, их нельзя создать средствами ВИД.
4) В некоторых ситуациях, в целях оптимизации дорогого вызова сервера (особенно на медленных сетях), очень не хватает событий вроде «ПередВызовомСервераНаКлиенте», «ПриВызовеСервераСКлиента», «ПередЗавершениемВызоваСервераСКлиента», «ПриЗавершенииВызоваСервераНаКлиенте». Ибо есть необходимость, каких-то периодических обращений к серверу, для получения «команд», информации и пр., при этом нет «срочности» получения информации, было бы удобно, перед вызовом сервера (как из кода, так и внутренние потребности 1С, например обновление динамического списка и пр.), в событии «ПередВызовомСервераНаКлиенте» сформировать некую произвольную структуру необходимой информации, в событии «ПриВызовеСервераСКлиента» получать её с клиента и обрабатывать ну и в событии «ПриЗавершенииВызоваСервераНаКлиенте» получать запрошенные данные с сервера. Это бы позволило минимизировать обмен с сервером и формировать некие «пакеты» на запрос к серверу. А так несколько обработчиков которым периодически нужно вызывать сервер, в разных местах + потребность платформы в вызовах сервера = Излишние обращения к серверу, которые на медленных сетях порой очень дорогие! (интернет же не везде хороший)
5) Ну и упоминавшаяся уже в комментариях, необходимость в регулярных выражениях, ибо технически, платформа умеет с ними работать (проверка типа в XDTO), но прямого доступа из кода нет. Лично для меня, это уже вторично, в некоторых местах, использую хак проверки через XDTO, хотя этот способ как мне кажется, достаточно дорог в отличии от нативной поддержки.
6) Возможность расчета контрольной суммы (Хеширование) на клиенте. Как-то не логично передавать 5 гиговый файл на сервер, только для того чтобы узнать его контрольную сумму, в данный момент приходится использовать консольные программы для этого.
7) Сделайте возможность deflate упаковки строк, сама платформа активно использует этот алгоритм в тех или иных местах, однако, разработчику данный механизм не доступен (если не рассматривать хаки через ZIP файл)
Что-то было ещё, но уже забыл. В целом мне очень нравится курс, который вы взяли начиная с 8.3.9, добавляя всё больше и больше, очень вкусных возможностей, в том числе которые «казалось бы» не нужны в «бухгалтерской» программе.
Спасибо!
А то я в последнее время приобрёл привычку сжимать исходник, чтобы колёсико мышки меньше изнашивалось.
Раньше делал так:
if(condition)
{
code
}
else
{
code
}А теперь делаю так:
if(condition){
code
}else{
code
}А вишь оно как… П == Прогресс.
PS. нагрузочные тесты? Не, не слышал.
* берем крайнюю версию платформы (8.3.13.1513, если склероз не изменяет)
* берем крайнюю версию Бухгалтерии (3.0.65.сколькототам)
* запускаем 10 штук баз одновременно (файловых, на не самом поганом немецком хостинге, на честно купленной Windows Server 2008 R2)
* сидим и курим ЧАС, пока оно взлетит
Загрузка процессора (всех четырех ядер) — 5-10%
Никаких тюнингов и выпендриваний — всё by default.
Вот как так вот?
Я такое кунг-фу не умею.
Чтобы так убить работу — я не умею.
PS. TPC говорит, что лучше, чем на этом сервере — технически существовать не может.
Шутка, конечно, но тем не менее.
можете пожалуйста рассказать какой % кода написан на C++, а какой на других языках (без учета веб клиента, сервера взаимодейстивия, EDT и прочих явно написанных на других языках элементов инфраструктуры 1С). Надеюсь это не какая-то тайна, можно очень примерно (90 на 10, 80 на 20 и тд). Особенно интересно сколько места в платформе занимает Java и есть ли она там вообще. Если всё же Java там есть было бы супер услышать несколько примеров какие блоки на ней реализованы. Спасибо!
Я сейчас не в офисе, с разработчиками проконсультироваться не могу. Но, насколько помню, если отбросить все вами перечисленное — С++ занимает 97%-99%. Несколько визуальных контролов (точно помню про планировщик и форматированный документ) написаны с применением JavaScript.
Java, насколько помню, применяется только в EDT и Сервере Взаимодействия. Возможно еще где-то в утилитах администрирования, но 100% не уверен.
Я сам бОльшую часть своего рабочего времени занимаюсь оптимизацией производительности баз 1С, не смотря на то что сертификата Эксперт у меня нет, потому что руки не доходят.
Что хотелось бы и не понятно почему в 1С разработчики это упорно игнорируют, хотя те же преподаватели на курсах говорят что было бы здорово если бы это было:
1) Конструктор Индексов объектов баз данных.
Поясню — не я проектирую справочники\ документы с 20-80 реквизитами и не я автор РЛС на несколько реквизитов в одной таблице. Эту проблему можно было бы достаточно малой кровью, но сейчас 3 пути решения, которые озвучиваются на том же обучении:
N1 Ничего не делать.
N2 Реализовать через вспомогательные объекты (как правило Регистры сведений), но делать 10-15 регистров сведений к тому же справочнику номенклатуры не очень здорово + требуется большая переработка существующего функционала. Да это работает, но иногда чудовищные затраты по времени.
N3 Нарушить лицензионное соглашение и добавить индексы на уровне БД и поосле реструктуризации следить за ними, потому что платформа скидывает индексы в по дефолту. Так себе решение, мало кто может это позволить, ибо решение N2 дорого сейчас, а решение N3 дорого всегда.
А бОльший пул проблем можно часто решить просто добавлением 1-2 соответствующих индексов.
2) Нет человеческого инструмента анализа логов.
Объясню: ЦУП — долго, не качественно. На том же обучении — из 5ти попыток только одна смогла проанализировать логи. Для софта за 100 000 с намеком на энтерпрайз по моему плохо.
— Скрипты на perl — неплохое решение, из рекомендуемого gitBash — чтение идет в 1 поток и скорость неудовлетворительна. У одного заказчика установка любого софта запрещена, и я еле еле вынес логи на флешке для анализа, тот же GitBash мне не поставили.
— Самописки. Каждый ваяет как может. Я написал нормализатор на Python и загружаю в SQL.
— Кто то ипользует ELK.
Но есть ситуации когда заказчик ультимативно требует только инструменты Вендора.
Не понятно почему нельзя выпустить инструмент и продавать его за деньги, если он будет лишен недостатков ЦУП — спрос будет, я сам куплю его на свои в первый же день выхода. Тем более для держателей формата тех журнала и тех кто знает основные проблемы это задача не несподъемная.
Просто по своему опыту — 30 гб логов ТЖ нормализуются в CSV на достаточно посредственной машине с HDD диском за 5-15 минут, все зависит от загруженности диска другими задачами.
Тот же Сергей Старых aka TormozIT сделал очень неплохой и достаточно быстрый анализатор логов ТЖ на 1С в инструментах разработчика, но том из — за того что данные после разбора хранятся на форме — не получится анализировать что то большое.
Большое спасибо за внимание.
Как мы перевели 10 миллионов строк кода C++ на стандарт C++14 (а потом и на C++17)