
В марте 2021 года HeadHunter купил портал Dream Job и позже дополнительно встроил интерфейс оценки работодателя на свой сайт. Видимо, количество отзывов резко увеличилось настолько, что их стало сложно обрабатывать в ручном режиме. В результате, задача модерации отзывов была переведена в термины классификации и организован чемпионат на платформе Boosters для решения этой задачи.
Соревнования по анализу данных, в которых целевую переменную можно разметить ручками, принято проводить в Docker-формате. Однако, соревнование длилось 3,5 месяца и в целях учета интересов как организаторов, так и участников, проходило в 3 этапа. В соревновании участвовала команда лаборатории машинного обучения Альфа-Банка: я, Андрей Сон — специалист по интеллектуальному анализу данных, и Женя Смирнов — руководитель лаборатории.
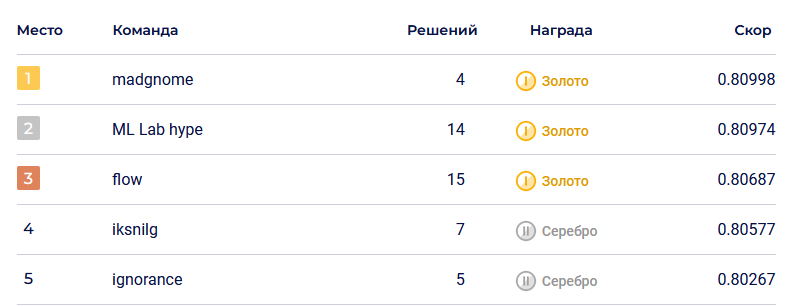
Мы заняли второе место, чуть не дотянув до первого — разрыв составлял 0.0001 метрики. Дальше подробно расскажем, что происходило на каждом этапе, какие перед нами стояли задачи и как мы их решали.

Описание соревнования
Подробное описание находится на странице соревнования на Boosters, здесь же пройдёмся кратко. Соревнование проходило в 3 этапа.
На первом этапе почти 3 месяца проходил отбор Топ 20% участников по сабмитам в формате CSV на 50% тестовых данных (Public Leaderboard).
На втором проводилось классическое Docker-соревнование на оставшихся 50% тестовых данных (Private Leaderboard). Время выполнения алгоритма ограничивалось 1 часом. Размер каждого сабмита не должен был превышать 1 Гб.
На заключительном этапе модели тестировали на реальных свежих данных, собранных за март.
Характеристики среды исполнения: 8 vCPU, 62 GB RAM, Nvidia Tesla V100 32 GB.
Первый этап
На первом этапе все команды получили массив данных, содержащий 51 000 отзывов. Каждый отзыв был разбит отдельно на позитивную и негативную часть. В качестве дополнительных признаков предоставлялась информация о городе проживания человека, написавшего отзыв и его занимаемой должности. Также были категориальные признаки с оценкой от 1 до 5: зарплаты, команды, менеджмента, карьерного роста, условий труда и времени на отдых/восстановление.
Описание данных
Ниже предоставлен сэмпл датасета. Таблица разбита на две части для удобного просмотра.
id | city | position | positive | negative | salary |
1 | Челябинск | Техник-электрик, обслуживание зданий | Ни чего ни чего ни чего ни чего | Всё всё Всё всё Всё всё Всё всё Всё всё Всё всё | 2 |
2 | Санкт-Петербург | Старший специалист группы приёмки | Есть исключительно хорошие руководители. | Удачи хорошем управляющим в компании. | 5 |
3 | Нижний Новгород | Кладовщик | Уютная столовая .раздевалка | График работы. Обучение сотрудников | 2 |
4 | Москва | Инженер эксплуатации радиоподсистемы | Не соблюдают трудовой кодекс, переработки 7 дней… | Рабская эксплуатация работников | 4 |
5 | Москва | NaN | Я работаю в компании почти 2 года, платят всегда вовремя… | Для карьерного роста на многие вакансии нужен большой опыт… | 5 |
id | team | managment | career | workplace | rest_recovery | target |
1 | 2 | 1 | 1 | 1 | 1 | 3,8 |
2 | 3 | 4 | 3 | 5 | 2 | 8 |
3 | 1 | 3 | 2 | 2 | 1 | 8 |
4 | 5 | 1 | 1 | 1 | 1 | 1 |
5 | 5 | 5 | 4 | 5 | 5 | 0 |
Участникам предлагалось предсказать пройдет ли отзыв модерацию (категория 0) или нет (категории 1-8). Если нет — указать причину, по которой он не прошел. Причем причин могло быть сразу несколько, поэтому стояла задача мульти-лейбл классификации.
Всего уникальных комбинаций причин отказа было 44. Самыми популярными категориями были 8 и 0 – это 24 100 и 21 000 отзыва, соответственно. Выборка была достаточно сбалансированной относительно этих двух классов и крайне несбалансированной относительно остальных классов.
Категории отзывов
Расшифровку категорий организаторы не предоставили, но немного посэмплив отзывы и, прочитав правила публикации отзывов на сайте Dream Job, мы смогли составить данный список описаний категорий (1-8 категория):
Содержащие ненормативную, обсценную, неуважительную, вульгарную и непристойную для профессионального сообщества лексику. Замена букв точками, пробелами между буквами, слитное написание слов, намеренные опечатки также оставляют нам право не публиковать подобные отзывы на сайте.
Рекламирующие услуги или товары компании, не имеющие ничего общего с оценкой условий труда в компании; отзывы, содержащие призыв к диалогу и адвокатирование интересов компании; отзывы, имеющие признаки накрутки и заказного написания, вне зависимости от их тональности и содержимого.
Спам-символы. Такие отзывы содержат одинаковый текст в разных полях в форме для отзыва.
Оскорбляющие. Затрагивающие религиозную, политическую тематику, задевающие чувства целых групп лиц, меньшинств.
Содержащие персональные данные сотрудников, например, имена, почту, номера телефонов. Под это правило подпадают и инициалы или косвенные и неявные намеки на отдельных лиц.
Содержащие неконструктивное обвинение, оскорбление в адрес коллег и/или работодателя. Сюда же попадают отзывы с негативной оценочной характеристикой конкретных сотрудников, которые могут быть расценены как оскорбление личности и/или причинить вред профессиональной репутации отдельному человеку или кругу лиц, задеть их честь или достоинство.
Отзывы родственников или друзей. Все отзывы должны быть написаны лично вами и содержать собственный опыт работы в компании. Сюда же попадают отзывы кандидатов и соискателей на вакансию, не сотрудников компании.
Игнорирующие плюсы или минусы компании и написанные только лишь в позитивном или негативном ключе, повторяющиеся отзывы.
Средняя длина отзыва с позитивной и негативной частью – 30 слов.
В целом соревнование заполнилось достаточно шумной разметкой, что не позволяло моделям добиться высокого качества.
Метрикой, в данной задаче, был mean F1 score с усреднением по сэмплам. Другими словами, сначала значение F1 считается отдельно для каждого ревью, а потом усредняется для всего датасета. В день можно было делать 3 сабмита.
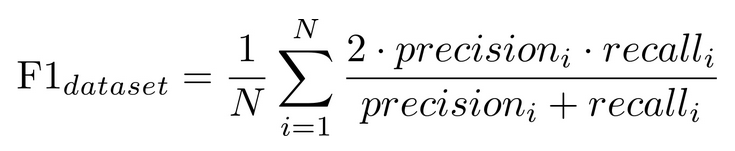
Подготовка данных
Прежде всего необходимо было подготовить таргет к моделированию, который изначально представлял собой текстовую строку, где причины отказа были перечислены через запятую. В подготовку также входил классический анализ датасета на проверку nanов, дубликатов и различных распределений.
Самый популярный способ работать с мультилейбл задачей – перейти к бинарной.
Для каждого класса мы ставим метку 1, если он присутствует в таргете, или 0, если наоборот. Такой подход позволяет использовать BCE Loss при обучении.
Пример «нового»:
target | target_0 | target_1 | … | target_8 |
0 | 1 | 0 | … | 0 |
8 | 0 | 0 | … | 1 |
1,8 | 0 | 1 | … | 1 |
К сожалению, датасет оказался не очень чистым – мы смогли найти nan в позитивных и/или негативных частях отзывов, а также одинаковые отзывы (дубликаты), но принадлежащие разным классам. Отзывы, содержащие nan мы со спокойно душой выкинули, потому что таких отзывов не было в тестовой части. Из дубликатов оставили только первое появление дублирующего сэмпла — невозможно было понять на основе отзыва, какой класс «истинный» для него.
Также мы смогли обнаружить, что класс 3 состоит из рандомных символов, например: ‘**********’ или “12341234”. Но при этом не все отзывы, содержащие только такие последовательности символов, относятся к классу 3. Поэтому мы решили переразметить такие сэмплы.
Бэйзлайн
Ни для кого не секрет, что BERT архитектуры — это SOTA подход для решения большинства NLP задач.
Поэтому в качестве модели мы выбрали DeepPavlov/distilrubert-base-cased-conversational, которым пользовались весь первый этап. Её оказалось достаточно, чтобы с достаточно большим запасом пройти на второй этап, заняв третье место.
Оптимайзер выбрали AdamW, а linear schedule with warmup в качестве шедьюла. Все инструменты использовали из библиотеки transformers (Hugging Face). Категориальные признаки мы объединили с последним слоем BERTа, выучив для них отдельные эмбеддинги.
Осталось понять, как лучше скармливать отзывы BERTу, имея четыре различных текстовых поля?
Самый очевидный подход — объединить поля в единый текст. Но при этом мы потеряем информацию о структуре отзыва: BERT не сможет понять, что ему на вход приходит 4 различных предложения, а не одно. Чтобы решить эту проблемы мы добавили разделяющие теги между полями, сохранив изначальную структуру.
Финальный отзыв выглядит примерно так:
'[ГОРОД]' + ' ' + city + ' ' + '[ДОЛЖНОСТЬ]' + ' ' + position + ' ' + '[ПОЗИТИВ]' + ' ' + positive + ' ' + '[НЕГАТИВ]' + ' ' + negative
Такой подход работал чуть лучше, чем классический разделитель BERTа ‘[SEP]’, поскольку он содержал в себе больше информации об отзыве.
Кросс-валидировались с помощью классического StratifiedKFold на 5 фолдах. Результирующий скор при значительных улучшениях позитивно коррелировал с public таблицей, а далее и с private. Обучение на 5 фолдах и усреднение предсказаний от пяти моделей давало 0.808 F1 на public, что даже под конец первого этапа давало восьмое место.
Немного поподробнее расскажу, как получались предсказания. На выходе, после финального линейного слоя, модель формировала матрицу размерности batch_size x n_targets. Пропустив через сигмоиду, каждое значение можно было конвертировать в вероятность принадлежности к классу.
Установив некоторую границу, можно было оставлять предсказания классов, вероятности которых больше её и наоборот. В качестве изначальной границы установили значение 0.3. Если с первого раза ни одна вероятность не попала выше этого диапазона, значение мы опускали каждый раз на 0.05. Значения границ подбирались на кросс-валидации.
Улучшения
MLM pretrain. BERT модели чаще всего натренированы на огромных корпусах документов, например, Википедии и текстов новостей, впитывая всевозможные контекстные знания, что позволяет хорошо обучаться под любые задачи. Однако при работе со специфичными доменами BERT может плохо обобщаться, не имея представления о семантических связях неизвестной лексики.
В нашем случае DeepPavlov/distilrubert-base-cased-conversational уже натренирован на домене близком к соревнованию. Но почему бы не попробовать дообучиться дополнительно на предоставленных отзывах?
Так и сделали:
обучились на MLM задаче в течение двух эпох на имеющихся отзывах;
использовали полученные веса;
а также обновленный словарь в качестве инициализации модели;
получили прирост на 0.002, выбив 0.810 F1 на public.
Layer-wise Learning Rate Decay. Данный метод подразумевает применение к последним слоям BERT высокую скорость обучения и низкую к первым. Цель — модифицировать нижние слои, кодирующие общую информацию, меньше чем верхние слои, которые вырабатывают признаки более специфичные к доменной задаче. Применение этого трюка помогло достичь 0.811 F1.
ArcFace. Анализ ошибок показал, что многие классы плохо отделяются друг от друга. Особенно это было заметно для класса 0 и 8, которые модель путала между собой с завидной периодичностью. Мы подумали, что можем помочь модели лучше предсказывать, сделав эмбеддинги классов различными. В этом нам помог ArcFace loss, который активно применяется в задачах распознавания лиц и матчинга. Обучив модель на BCE + ArcFace наш результат вырос до 0.813 F1.
Постпроцессинг. Последнее значительное улучшение на первом этапе произошло после того, как мы подробно почитали Телеграмм-канал по соревнованию от Boosters. Stanislav Sopov обнаружил, что специальный символ \xa0 (неразрывный пробел), в основном, содержится в отзывах, прошедших модерацию (класс 0). Соответственно, выбрав отзывы с данным символом и заменив их предсказания на класс 0, можно попробовать улучшить финальный скор. И действительно, такая манипуляция давала прирост до 0.814 F1.
Второй этап
Достаточно сильно отличался от первого и появились некоторые ограничения.
Прежде всего стояло ограничение на посылку в 1 Гб. Это не позволяло использовать «толстые» BERTы, модели, обученные на n разных фолдах и различных ансамблей, что могло давать значительный прирост на первом этапе.
Организаторы предоставили размеченный public тест первого этапа, который было логично использовать.
Один из участников нашей команды ушел в отпуск почти на весь второй этап — на 6 дней.
Рабочая неделя выдалась загруженной.
Всё вместе сложилось и мы не смогли протестировать все имеющиеся идеи и подходы.
Первый шаг. Первом делом мы провели наше решение с первого этапа, но с одним изменением. Пять моделей было физически невозможно запихнуть в архив и мы обучили модель сразу на всем датасете. Количество эпох необходимых для обучения на всем датасете сразу равнялось количеству эпох, необходимых для обучения на фолде, во время кросс-валидации минус один. Такой сабмит давал 0.8143 F1.
Второй шаг. Дальше логично было попробовать добавить новые данные для обучения. Решение в лоб не дало результата — скор упал до 0.8112 F1.
Мы предположили, что модель переобучается и подтвердили догадки на кросс-валидации: здесь важно было добавить новые данные только в трейн часть, не изменив тестовую, для адекватной оценки. В итоге побороть переобучение мы смогли классическим способом — добавив дропаут 0.2 перед головой модели модели, а также дополнительно уменьшив количество эпох ещё на одну.
Модель с дополнительной регуляризацией и обученная вместе с новыми данными давала 0.8186 F1.
Финальная архитектура на рисунке.
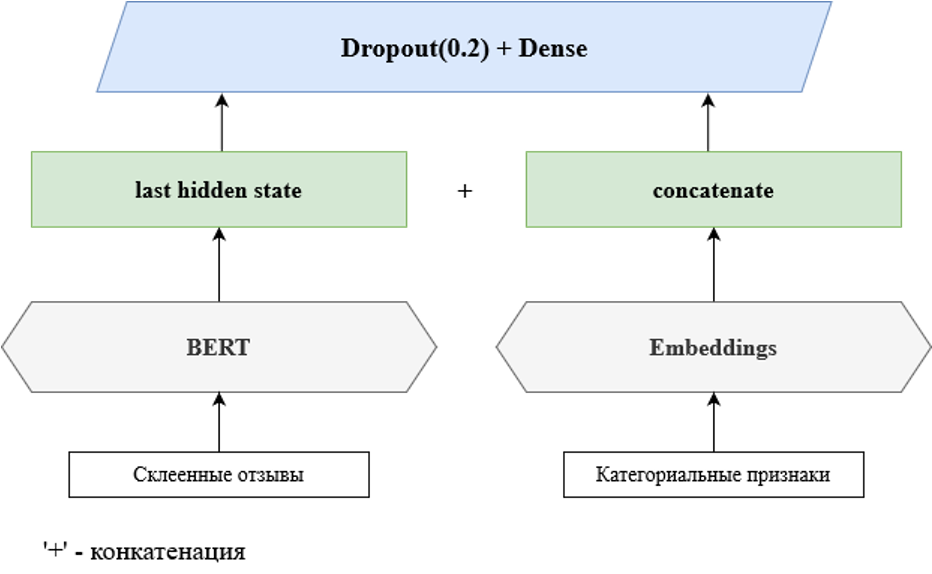
Третий шаг. Следующее улучшение на втором этапе — выбор чуть более толстого BERT: вместе дистиллированной версии мы попробовали использовать обычную — DeepPavlov/rubert-base-cased-conversational. Смена бэкбоуна дала прирост до 0.8207 F1, что давало третье место на тот момент.
Но мы хотели занять первое, поэтому решили как-то дополнительно улучшить скор за последние пару дней. Обычно в соревнованиях по машинному обучению последние недели выделяют на различные ансамбли и стэкинги, что достаточно сильно бустит скор. Но в нашем случае улучшение ансамблем отпадало, поскольку при использовании DeepPavlov/rubert-base-cased-conversational в посылке оставалось всего 300 Мб.
Мы прибегли к следующему трюку:
помимо финального линейного слоя мы подали последний скрытый слой BERTa, законкаченный с эмбеддингами категориальных признаков;
на вход — SVM (SVC) из библиотеки cuML, которая позволяет использовать GPU при обучении классических моделей;
SVM обучили прямо в контейнере на трейн фичах BERTа, которые получили также в контейнере, прогнав через BERT трейн данные в eval режиме.
Кроме предсказаний самого BERTа, мы дополнительно получили вероятности из обученного SVM, создав тем самым мини-ансамбль. Такой подход не давал сильный буст в таблице - 0.8209 F1, но сильно улучшал скор на кросс-валидации, в итоге став нашим лучшим решением на приватных данных.
В итоге — второе место.
Эпилог
Что мы пробовали, но не зашло:
Различные архитектуры BERTа: предобученные под классификацию токсичных комментариев, мульти язычные архитектуры.
Сверточные и рекуррентные сети.
Различные модификации модели: конкат последних трех слоев BERTа, дополнительные линейные слои, self-attention, multi-sample dropout, реинициализация последних слоев.
Аугментации: back-translation, замена слов токенами [‘MASK’] во время обучения, свап позитивной и негативной части во время обучения.
Постпроцессинг пар: замена предсказания пары на индивидуальную категорию на основе разницы в вероятностях категорий.
Label smoothing loss, focal loss.
Отдельно хочется поблагодарить организаторов за интересное соревнование. Надеюсь, наше решение сможет улучшить модерацию отзывов. Дополнительно можно посмотреть разбор решений, проведенный в онлайн формате, где своими подходами также делятся участники с четвёртого и третьего места.
Статьи, которые могут быть интересны:
Эксперименты на 3,5 квадратах: качнул сетап от «бомж-уровня» до «мини-студии»
Как у нас почти получилось сделать автономного робота для «Битвы Роботов»
Как дизайнеру с помощью макетов оптимизировать процессы и сэкономить время
База об организации процесса разметки: команда, онбординг, метрики
Подписывайтесь на блог и Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
