В ИТ главное — это три буквы
Задача любой ИТ-инфраструктуры сводится к обеспечению надежной платформы для бизнес-процессов компании. Традиционно считается, что качество информационно-технологической инфраструктуры оценивается по трем основным параметрам: доступность, безопасность, надёжность. Однако оценка по данной тройке никак не связана с бизнесом и прямыми доходами / потерями компании.
В ИТ правят три главные буквы. Если во главе иерархии ИТ не стоят буквы «RUB», значит вы строите свою ИТ-инфраструктуру неправильно. Конечно, строить напрямую ИТ, отталкиваясь только от доходов/расходов, сложно, поэтому существует иерархия «трех букв» — от самых важных к более частным. SLA, RPO, RTO, GRC – все это специалисты в индустрии знают и давно используют в построении инфраструктур. К сожалению, не всегда связывая эти показатели в сквозную иерархию.

Многие компании сегодня строят инфраструктуру для будущего используя вчерашние технологии на позавчерашней архитектуре. И вместе с тем, ускоряющееся развитие ИТ показывает, что современные сервисы кардинально меняют не только бизнес, но и общество – люди цифровой эпохи привыкли, что для доступа к любой информации достаточно нескольких секунд. ИТ из непонятной техномагии стало обыденностью для широких масс, такой же как бургерная или кофейня. Это добавило новые чрезвычайно важные три буквы в ИТ. Эти буквы — TTM (Time to market) — время до запуска продуктивного сервиса на рынок.

SDS
С другой стороны, из глубин технологий поднимался кракен, переворачивающий традиционные ИТ и уклад жизни. По мере роста вычислительной мощности процессоров x86 первым щупальцем стали программные системы хранения данных. Классические системы хранения были очень специфическими железками, наполненными “заказным кремнием”, различными аппаратными проприетарными ускорителями и специализированным софтом. А администрировал ее специально обученный человек, которому в компании практически поклонялись как жрецу темного культа. Расширить работающую в компании систему хранения данных был целый проект, с массой расчетов и согласований — ведь дорого же!
Дороговизна и сложность подстегнули на создание программных систем хранения данных поверх обычного x86 железа с обычной ОС общего назначения — Windows, Linux, FreeBSD или Solaris. От сложной заказной железки остался только софт, работающий даже не в ядре, а на пользовательском уровне. Первые программные системы были конечно довольно просты и ограничены в функциональности, зачастую представляли собой специализированные нишевые решения, но время шло. И вот уже даже большие вендоры систем хранения начали отказываться от специализированных аппаратных решений — TTM для таких систем уже не выдерживал конкуренции, а стоимость ошибки стала очень высока. Фактически, за редким исключением, даже классические системы хранения к 2020 году стали самыми обычными x86 серверами, просто с красивыми пластиковыми мордочками и кучей полок с дисками.
Второе щупальце надвигающегося кракена — это появление и массовое принятие рынком технологии флэш-памяти, которая и стала бетонным столбом, ломающим спину слону.
Производительность магнитных дисков не менялась уже много лет и процессоры контроллеров СХД вполне справлялись с сотнями дисков. Но увы, количество рано или поздно переходит в качество — и СХД уже среднего уровня, не говоря уже о начальном, имеет ограничение сверху по осмысленному количеству флэш-дисков. С определенного количества (буквально от десяти дисков) производительность системы не то что перестает расти, а еще может начать снижаться из-за необходимости обрабатывать все больший объем. Ведь вычислительная мощность и пропускная способность контроллеров не меняется с ростом емкости. Решением, по идее, стало появление scale-out систем, способных собирать множество независимых полок с дисками и процессорными ресурсами в единый кластер, выглядящий снаружи как единая многоконтроллерная СХД. Оставался всего один шаг.
Гиперконвергенция
Самым очевидным шагом в будущее стало объединение до того разрозненных точек хранения данных и их обработки. Иными словами, почему бы не реализовать распределенную СХД не на отдельных серверах, а прямо на хостах виртуализации, отказавшись тем самым от специальной сети хранения и выделенного железа, и совместив таким образом функции. Кракен проснулся.
Но позвольте, скажете вы, ведь совмещение — это конвергенция. Откуда взялась эта глупая приставка гипер?
Впервые с термином конвергентные системы на рынок врываются маркетологи. Под конвергентной системой продавались обычные классические серверы + СХД + коммутаторы. Просто под одним партномером. Или даже не продавались, а выпускалась бумага под названием “референсная архитектура”.
…
Конвергентная архитектура, иными словами, подразумевает использование одних и тех же аппаратных сервисов как для исполнения ВМ, так и для их хранения на локальных дисках. Ну а поскольку должна быть отказоустойчивость — в конвергентной архитектуре есть слой распределенной SDS.
Получаем:
- Классическая система — софт, СХД, коммутация и серверы идут из разных мест, совмещаются руками заказчика/интегратора. Отдельные контракты на поддержку.
- Конвергентная система — все из одних рук, единая поддержка, единый партномер. Не путать с самосбором от одного вендора.
И, получается, что термин под нашу конвергентную архитектуру уже занят. Ровно та же ситуация, что с супервизором.
Гиперконвергентная система — конвергентная система с конвергентной архитектурой.
Определения взяты из статьи “Общая теория и археология виртуализации”, в написании которой я принимал живейшее участие.
Что же дает гиперконвергентный подход в приложении к упомянутым трем буквам?
- Старт с минимального объема (и минимальных затрат)
- Емкость хранения растет вместе с вычислительной мощностью
- Каждый узел системы является ее контроллером — и снимается проблема “стеклянного потолка” (диски могут, а контроллер уже нет)
- Резко упрощается управление подсистемой хранения
За последний пункт гиперконвергентные системы очень не любят старорежимные администраторы систем хранения данных, привыкшие администрировать очереди на портах Fibre Channel. Выделение пространства происходит буквально в несколько кликов мыши из консоли управления виртуальной инфраструктурой.
Иными словами, быстрее гиперконвергентных систем в запуске продукта только облака, но облака подходят не всем и/или не всегда.
Если вы администратор-технарь и дочитали до сюда — возрадуйтесь, общие слова закончились и теперь я расскажу о своем личном взгляде на систему Cisco Hyperflex, которая досталась мне в цепкие лапы для проведения различных над ней тестов.
Cisco Hyperflex
Почему Cisco
Компания Cisco известна прежде всего как доминирующий вендор на рынке сетевого оборудования, но при этом она достаточно широко присутствует и в других сегментах рынка ЦОД, предлагая и серверные, и гиперконвергентные решения, а также системы автоматизации и управления.
Удивительно, но к 2020 году все еще находятся люди: “Серверы Cisco? А у кого она их берет?”
Серверами Cisco начала заниматься аж в 2009 году, выбрав путь активно росших в то время блейд-решений. Идея Cisco состояла в том, чтобы реализовать подход анонимных вычислителей. В итоге получилась система UCS (Unified Computing System), состоящая из двух специализированных коммутаторов (их назвали Fabric Interconnect), и от 1 до 20 шасси (8 лезвий половинного размера) или до 160 серверов. Шасси при этом стало вообще тупо железкой с питанием, вся логика и коммутация вынесена в Fabric Interconnect; шасси – просто способ разместить серверы и подключить их к системе. Fabric Interconnect отвечает полностью за все взаимодействие серверов с внешним миром — и Ethernet, и FC, и управление. Казалось бы, блейды и блейды, что тут такого, кроме внешней коммутации, а не как у всех в рамках шасси.
Ключевой момент в реализации тех самых “анонимных вычислителей”. В рамках концепции Cisco UCS у серверов нет никакой индивидуальности, кроме серийного номера. Ни MAC, ни WWN, ни чего либо еще. Система управления UCS, работающая на Fabric Interconnect, построена на базе серверных профилей и шаблонов. После подключения пачки серверов в шасси им необходимо назначить соответствующий профиль, в рамках которого и задаются все идентифицирующие адреса и идентификаторы. Конечно, если серверов у вас всего с десяток, то не стоила бы овчинка выделки. Но когда их хотя бы два, а то и целых три десятка — это уже серьезное преимущество. Становится просто и быстро мигрировать конфигурации, или, что гораздо важнее, тиражировать серверные конфигурации в нужном количестве, применять изменения сразу к большому количеству серверов, по сути управляя набором серверов (например, фермой виртуализации) как одним объектом. Подход, предложенный в рамках UCS-системы, позволяет при правильном подходе серьезно упростить жизнь администраторам, повысить гибкость и заметно снижает риски, поэтому блейды UCS буквально за 2-3 года стали самой продаваемой блейд-платформой в Западном полушарии, а в мировом масштабе являются сегодня одной из двух доминирующих платформ, наряду с HPE.
Довольно быстро стало понятно, что тот же самый подход на базе универсальной фабрики с интегрированным управлением на основе политик и шаблонов, в полной мере востребован и применим не только к блейдам, но и к стоечным серверам. И в этом смысле, стоечные серверы Cisco, подключенные к Fabric Interconnect, получают все те же самые преимущества, за счет которых блейды стали настолько популярны.
Сегодня я буду говорить о HyperFlex – гиперконвергентном решении от Cisco, построенном на стоечных серверах, подключенных к Fabric Interconnect. Что делает HyperFlex интересным и достойным рассмотрения в обзоре:
- В решении Cisco мы можем наблюдать, так сказать, «супер»гиперконвергенцию – в отличие от большинства других решений на рынке, сетевая инфраструктура является неотделимой частью HyperFlex; сеть настраивается автоматически при запуске, и, наряду с серверами, гипервизором и ПО хранения попадает под зонтик поддержки HyperFlex как единого законченного решения;
- Дедупликация и компрессия – на рынке гиперконвергенции наличием этих функций особо никого не удивить; спецификой HyperFlex является то, что они включены постоянно, в том числе на гибридных конфигурациях; все тесты производительности проводятся всегда с включенными дедупликацией и компрессией, и это стоит учитывать при анализе результатов.
- Масштабируемость «в разные стороны» — либо просто добавлением дисков «на лету», либо добавлением в кластер узлов с дисками, либо добавлением в кластер узлов без дисков;
- А так же интеграция в рамках одной и той же пары Fabric Interconnect с другими серверами Cisco в любых форм-факторах, возможность интеграции с существующими SAN сетями, в том числе и на базе native FC;
- Высокая доступность и катастрофоустойчивость “искаропки” – асинхронная репликация, растянутый кластер, интеграция со средствами резервного копирования;
- Поскольку сетевое оборудование Cisco не просто есть во многих ЦОД, а является стандартом, использование гиперконвергенции от того же вендора может быть интересным как с технической, так и с финансовой точки зрения;
- Если верить аналитикам, а мы им конечно же верим, Cisco является одним из трех лидирующих поставщиков ПО HCI, растет быстрее всех в процентном соотношении, HyperFlex достаточно широко распространен и в мире, и в России, и странах СНГ.
Принцип работы
HyperFlex — это настоящая гиперконвергентная система с выделенными контроллерными ВМ. Напомню, что принципиальное преимущество такой архитектуры — потенциальная портабельность под разные гипервизоры. На сегодня у Cisco реализована поддержка VMware ESXi и Microsoft Hyper-V, но вполне возможно что появится и один из вариантов KVM по мере роста его популярности в корпоративном сегменте.
Рассмотрим механизм работы на примере ESXi.
В контроллерную ВМ (далее CVM) напрямую прокинуты устройства по технологии VM_DIRECT_PATH — кэширующий диск и диски уровня хранения. Поэтому исключаем влияние дискового стека гипервизора на производительность. В сам гипервизор устанавливаются дополнительные VIB пакеты:
- IO Visor: обеспечивает точку монтирования NFS датастора для гипервизора
- VAAI: обеспечивает интеграцию VMware с API для «умных СХД»
Блоки виртуальных дисков распределяются равномерно по всем хостам в кластере с относительно небольшой гранулярностью. Когда ВМ на хосте производит какие то дисковые операции, через дисковый стек гипервизора операция уходит в датастор, далее в IO Visor, а он далее обращается к CVM, отвечающей за данные блоки. При этом CVM может находиться на любом хосте в кластере. В условиях весьма ограниченных ресурсов IO Visor никаких таблиц метаданных разумеется там нет и выбор обусловлен математически. Далее CVM, к которой пришел запрос, его обрабатывает. В случае с чтением — отдает данные либо из одного из уровней кэширования (оперативная память, кэш на запись, кэш на чтение) либо с дисков своего хоста. В случае с записью — пишет в локальный журнал, и дублирует операцию на одну (RF2) или две (RF3) CVM.
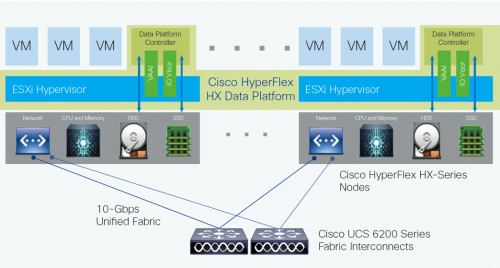
Пожалуй, этого вполне достаточно для понимания принципа работы в рамках данной публикации, а иначе буду отнимать хлеб у тренеров Cisco, и будет мне стыдно. На самом деле нет, но все равно достаточно.
Вопрос о синтетических тестах
— Штурман, приборы!
— 36!
— Что 36?
— А что приборы?
Примерно так на сегодня выглядит большинство синтетических тестов систем хранения данных. Почему так?
До относительно недавнего времени большинство СХД были плоскими с равномерным доступом. Что это означает?
Общее доступное дисковое пространство было собрано из дисков с одинаковыми характеристиками. Например 300 дисков 15k. И производительность была одинаковой по всему пространству. С появлением технологии многоуровневого хранения, СХД стали неплоскими — производительность различается внутри одного дискового пространства. Причем не просто различается, а еще и непредсказуемо, в зависимости от алгоритмов и возможностей конкретной модели СХД.
И все было бы не так интересно, не появись гиперконвергентные системы с локализацией данных. Помимо неравномерности самого дискового пространства (тиринги, флэш кэши) появляется еще и неравномерность доступа к нему — в зависимости от того, на локальных дисках узла лежит одна из копий данных или за ней необходимо обращаться по сети. Все это приводит к тому, что цифры синтетических тестов могут быть совершенно любыми, и никак не говорить ни о чем практически значимом. Как например расход топлива у автомобиля по рекламной брошюре, который вам никогда не удастся достичь в реальной жизни.
Вопрос о сайзинге
Обратной стороной цифр синтетических тестов стали цифры сайзинга и спецификации из-под клавиатуры пресейлов. Пресейлы в данном случае делятся на две категории — одни просто тупо забьют ваше ТЗ в конфигуратор вендора, а вторые будут считать сами, поскольку понимают как оно вообще работает. Но со вторыми вам придется подробно рассматривать что же вы написали в своем ТЗ.
Как известно, без внятного ТЗ — результат ХЗ.

Из практического опыта — при сайзинге довольно тяжелой гиперконвергентной системы в конкурсе у одного из заказчиков я лично после пилота снял показатели нагрузки с системы и сравнил их с тем, что было написано в ТЗ. Получилось как в анекдоте:
— Рабинович, а правда, что вы таки выиграли миллион в лотерею?
— Ой ну кто вам такое сказал? Не миллион, а десять рублей, не в лотерею, а в преферанс, и не выиграл, а проиграл.
Иными словами, классическая ситуация GIGO — Garbage In Garbage Out — Мусор на входе = Мусор на выходе.
Практический применимый сайзинг для гиперконвергенции почти гарантированно бывает двух типов: возьмем ка мы с запасом, или долго будем гонять пилот и снимать показатели.
Есть еще один момент с сайзингом и оценкой спецификаций. Разные системы по-разному построены и по-разному работают с дисками, по-разному взаимодействуют их контроллеры. Поэтому практически бессмысленно сравнивать “лоб-в-лоб” по спецификациям количество и объем дисков. У вас есть некое ТЗ, в рамках которого вы понимаете уровень нагрузки. И далее есть некоторое количество КП, в рамках которых вам предлагают различные системы, удовлетворяющие требованиям по производительности и надежности. Какая принципиальная разница, сколько именно стоит дисков и какого типа в системе 1, и что в системе 2 их больше/меньше, если и та и другая успешно справляется с задачей.
Поскольку производительность зачастую определяется контроллерами, живущими на тех же хостах, что и виртуальные машины, для некоторых типов нагрузок она может весьма значительно плавать просто от того, что в разных кластерах стоят процессоры с разной частотой при прочих равных.
Иными словами, даже самый опытный пресейл-архитектор-архимаг не скажет вам спецификацию точнее, чем вы сформулируете требования, и точнее, чем “ну где-то сэм-восэм” без пилотных проектов.
Про снапшоты
HyperFlex умеет делать свои «нативные» снапшоты виртуальных машин по технологии Redirect-on-Write. И вот здесь надо остановиться отдельно для рассмотрения разных технологий снапшотов.
Вначале существовали снапшоты типа Copy-on-Write (CoW), в качестве классического пример можно взять нативные снапшоты VMware vSphere. Принцип работы, что с vmdk поверх VMFS или NFS, что с нативными файловыми системами типа VSAN, один и тот же. После создания CoW снапшота оригинальные данные (блоки или файлы vmdk) замораживаются, а при попытке записи в замороженные блоки создается их копия и данные пишутся уже в новый блок / файл (дельта файл для vmdk). В итоге по мере роста дерева снапшотов увеличивается количество “паразитных” обращений к диску, не несущих никакого продуктивного смысла, и падает производительность / растут задержки.
Потом были придуманы снапшоты Redirect-on-Write (RoW), в которых вместо создания копий блоков с данными создается копия метаданных, а запись просто идет дальше без задержек и дополнительных чтений и проверок. При правильной реализации RoW снапшоты имеют практически нулевое влияние на производительность дисковой системы. Вторым эффектом работы с метаданными вместо самих живых данных является не только моментальное создание снапшотов, но и клонов ВМ, которые сразу после создания вообще не занимают места (системный оверхед на служебные файлы ВМ не считаем).
И третий, ключевой момент, радикально отличающий RoW от CoW снапшотов для продуктивных систем — это моментальное удаление снапшота. Казалось бы, что тут такого? Однако надо вспомнить как работают CoW снапшоты и что удаление снапшота на самом деле не удаление дельты, а ее коммит. И вот здесь время ее коммита чрезвычайно зависит от размера накопившейся дельты и производительности дисковой системы. RoW снапшоты коммитятся моментально просто потому что сколько бы терабайт разницы не накопилось, удаление (коммит) RoW снапшота — это обновление таблицы метаданных.
И вот здесь появляется интересное применение RoW снапшотов — уронить RPO до значений в десятки минут. Делать бэкапы каждые 30 минут в общем случае практически нереально, а в большинстве случаев их делают вообще раз в сутки, что дает RPO 24 часа. Но мы при этом можем просто делать RoW снапшоты по расписанию, доводя RPO до 15-30 минут, и хранить их сутки-двое. Без штрафа к производительности, расходуя только емкость.
Но есть некоторые нюансы.
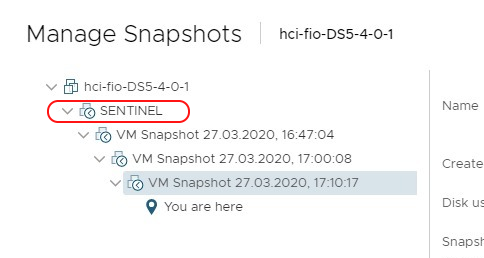
Для корректной работы нативных снапшотов и интеграции с VMware, HyperFlex требует наличия служебного снапшота, который называется Sentinel. Sentinel снапшот создается автоматически при первом создании снапшота для данной ВМ через HXConnect, и его не стоит удалять, к нему не стоит «возвращаться», нужно просто смириться с тем, что в интерфейсе в списке снапшотов самым первым идет этот служебный снапшот Sentinel.
Снапшоты HyperFlex могут выполняться в режиме «crash-consistent», либо в режиме «application-consistent”. Второй тип предполагает «сброс буферов» внутри ВМ, требует наличие VMTools, и запускается если в меню создания снапшотов в HXConnect поставить галочку «Quiesce».
Помимо снапшотов HyperFlex, никто не запрещает использование «родных» снапшотов VMware. Стоит для конкретной виртуальной машины определиться, какие снапшоты вы будете использовать, и в дальнейшем на эту технологию ориентироваться, «не мешая» для одной ВМ разные снапшоты.
В рамках теста я пробовал создавать снапшоты и проверять их FIO. И таки да, могу подтвердить что снапшоты действительно RoW, на производительность не влияют. Снапшоты действительно создаются быстро (несколько секунд в зависимости от профиля нагрузки и размера датасета), по результатам могу дать следующую рекомендацию: если в Вашей нагрузке много случайных операций записи, то следует запускать создание снапшота из интерфейса HXConnect, с галочкой “Quiesce” и с предварительным наличием снапшота Sentinel.
Тесты
Тестовая платформа
В цепкие лапы попала следующая платформа:
- 4 x C220 M4 (2630v4 10c x 2.20 GHz, 256, 800 + 6 * 960)
- vSphere 6.7
- HX Data Platform 4.0.2
Тест для четких пацыков
Какое же тестирование без КристалДиска? Правильно, такого быть не может, нормальные пацаны всегда кристалдиск запускают! Ну чо, раз надо — значит надо.

Для кристал диска создана специально ВМ с 2 vCPU 4GB и Windows 7 на борту. Ох и задолбался я на нее патчи ставить, я вам скажу! Тест проведен в лучших традициях лучших домов ЛондОну и Парижу — а именно просто добавлен один виртуальный диск next-next-finish без всяких мыслей и запущен тест. Да, и к слову, разумеется сам CrystalDiskMark не занимается тестированием, это просто интерфейс, а непосредственно нагружает дисковую систему всем известный пакет DiskSpd, включенный в комплект.
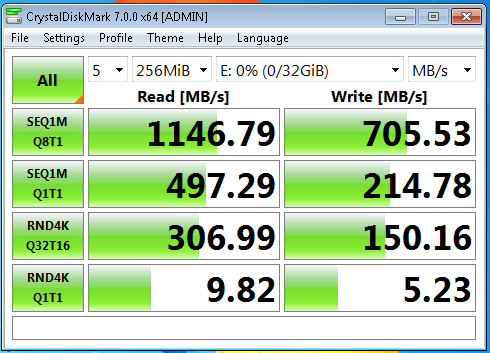
Что мне буквально бросилось в глаза — это почему-то всеми пропускаемый выбор единиц измерения в правом верхнем углу. И алле-оп!
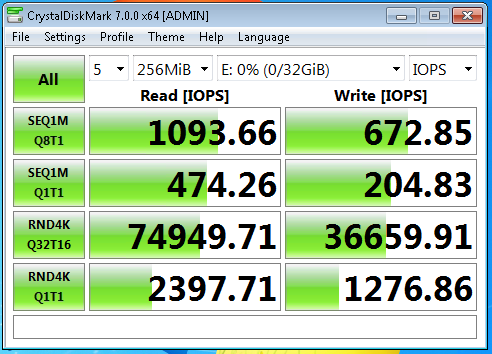
Слушайте, ну честно скажу — вообще не ожидал от микромашинки в режиме next-next-finish 75 тыс IOPS и более 1 гигабайта в секунду!
Мягко говоря, далеко не у каждой компании в России есть нагрузки, суммарно превышающие эти показатели.
Дальнейшие тесты проводились при помощи VMware HCI Bench и Nutanix XRay, как “идеологически враждебные” HyperFlex’у и соответственно, ожидалось, что пленных не берем. Цифры оказались чрезвычайно близкие, поэтому в качестве основы взяты результаты от пакета XRay просто потому что у него более удобная система отчетности и готовые шаблоны нагрузок.
Для тех же, кто не доверяет никому, и желает тотального контроля над процессом, напоминаю о своей статье по построению собственной системы для генерации нагрузки на гиперконвергентную платформу — "Тестирование производительности гиперконвергентных систем и SDS своими руками"
Achtung! Uwaga! Pozor!
Все дальнейшие результаты и их интерпретации — мнение автора статьи, и приведены сами по себе в рамках исследования системы. Большая часть тестов является голой синтетикой и применима только для понимания предельных показателей в экстремальных и вырожденных случаях, которых в реальной жизни вы никогда не достигнете.
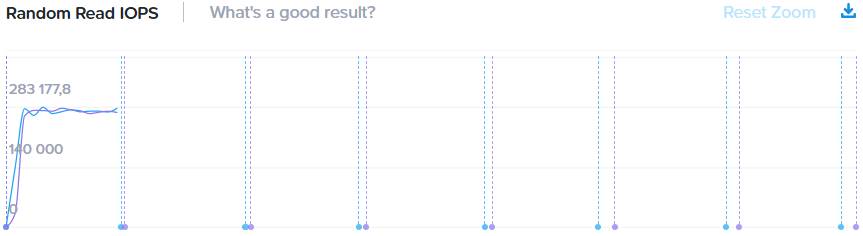
FourCorners Microbenchmark
4х-угольный микротест призван оценить систему “по быстрому” на предельные теоретические показатели и пиковую производительность контроллеров. Практическое применение для этого теста — проверка системы сразу после запуска на предмет наличия ошибок конфигурации и окружения, прежде всего сетевого. Т.е. если вы регулярно запускаете подобные системы, то просто знаете каких цифр нужно ожидать “если все хорошо”.
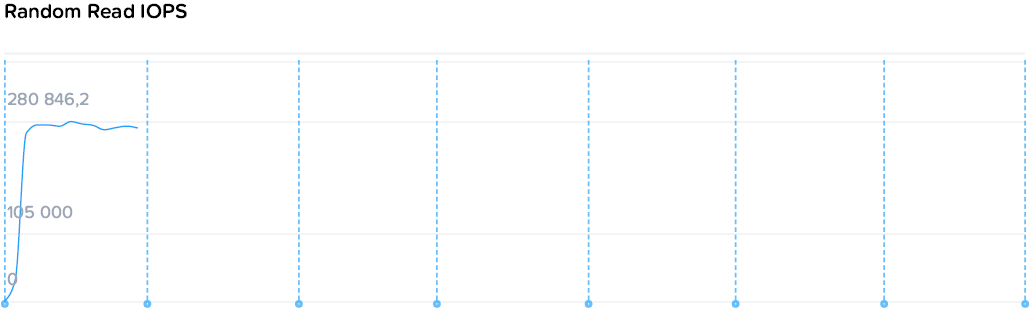
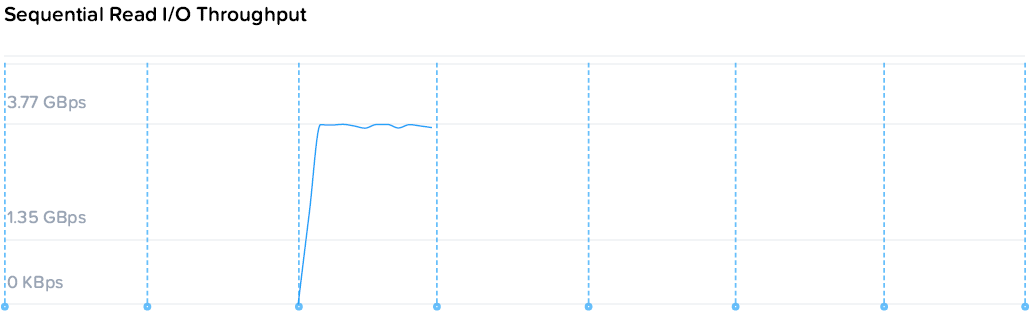
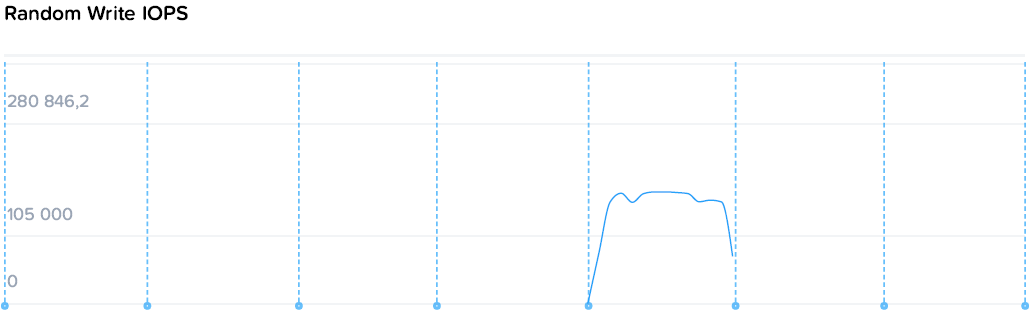
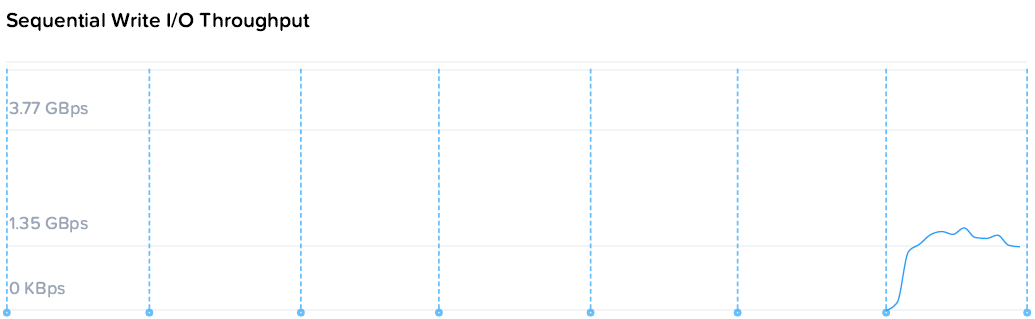
Итоговые цифры: 280k/174k IOPS, 3.77/1.72 GBps (чтение/запись)
Как же вели себя наши контроллеры?
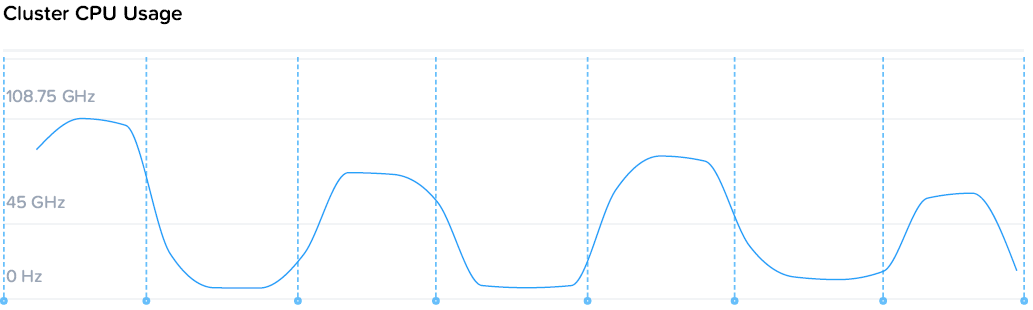
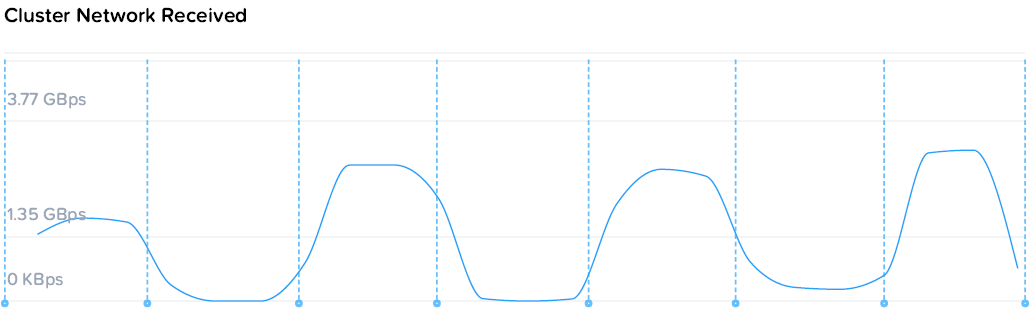
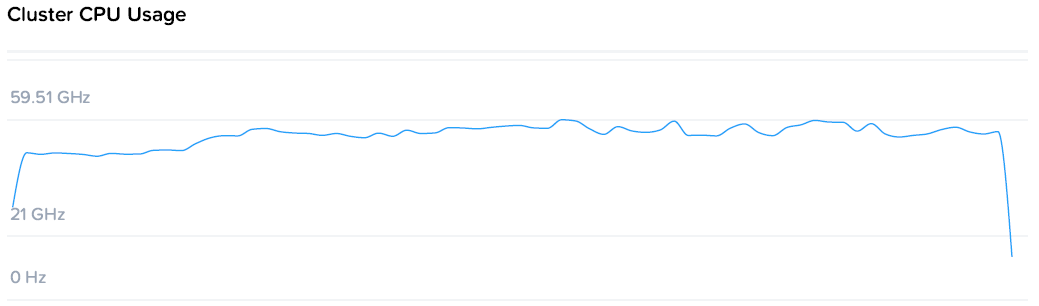
Из чего можно заметить, что суммарное потребление ресурсов на 4 контроллера и 4 ВМ нагрузки составило 49 ядер по 2.2. По статистике VMware загрузка CPU контроллеров была до 80%, т.е. фактически производительность была ограничена производительностью контроллеров, а конкретно процессоров. Скорость же последовательных операций конкретно уперлась в скорость 10G сети.
Давайте попробую еще раз. Пиковая производительность на маленьком 4-х узловом кластере с не самыми быстрыми процессорами 2.2GHz почти 300 тыс IOPS в 4U высоты.
Разговор “а вот у нас больше / меньше на 10, 20 или даже 40%” практически лишен смысла из-за порядка цифр. То же самое как начать меряться “а у меня машина может 240, у меня 280” при том, что ограничение 80.
280k / 4 узла дает пиковую производительность 70k / узел, что например превышает цифры из калькулятора VMware VSAN, считающего, что узел AF выдает не более 46k на дисковую группу. В нашем же случае здесь в терминологии VMware как раз одна дисковая группа, фактически работающая на скорости x1,8.
Влияние размера блока датастора
При создании датастора HyperFlex можно выбрать размер блока данных — 4к или 8к.
На что это повлияет? Запустим все тот же четырехугольный тест.
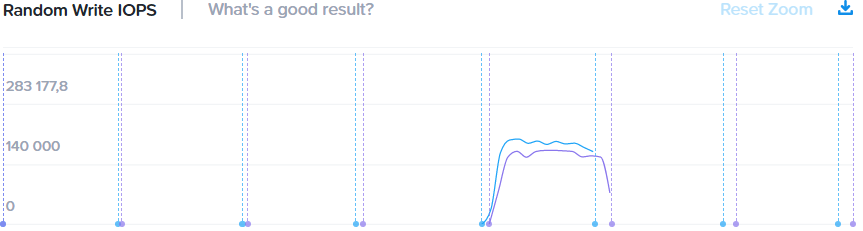
Если с чтением картина практически идентична, то вот запись наоборот, имеет значение. Четырехугольный тест использует нагрузку 8k.
Итоговые цифры: 280k/280k, 172-158k/200-180k (4k 8k). При совпадении размера блока получается +15% производительности на запись. Если у вас предполагается значительное количество записи малым блоком (4k) в нагрузке — создавайте датастор для именно этой нагрузки с блоком 4k, иначе используйте 8k.
OLTP Simulator
Значительно более близкую к реальности картину дает другой тест. В рамках него запускают два генератора с профилем, приближенном к транзакционной СУБД и уровнем нагрузки 6000+400 IOPS. Здесь измеряется задержка, которая должна оставаться на стабильно низком уровне.
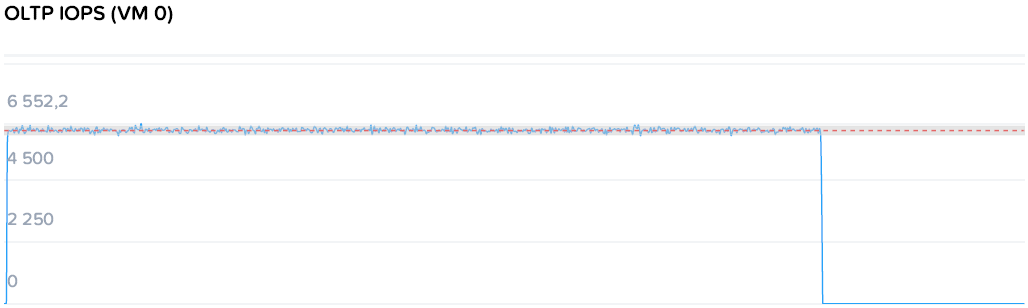
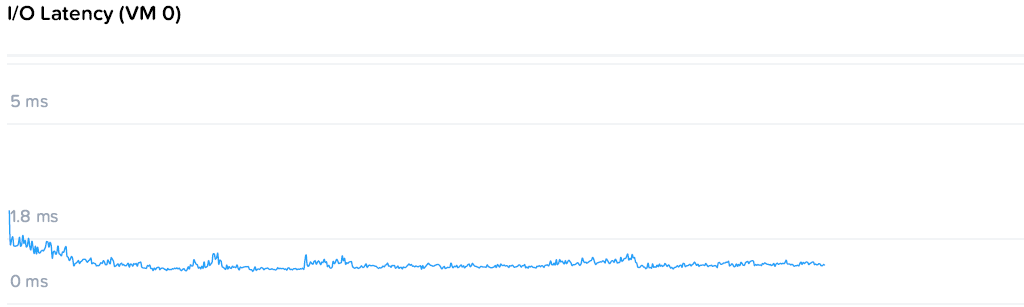
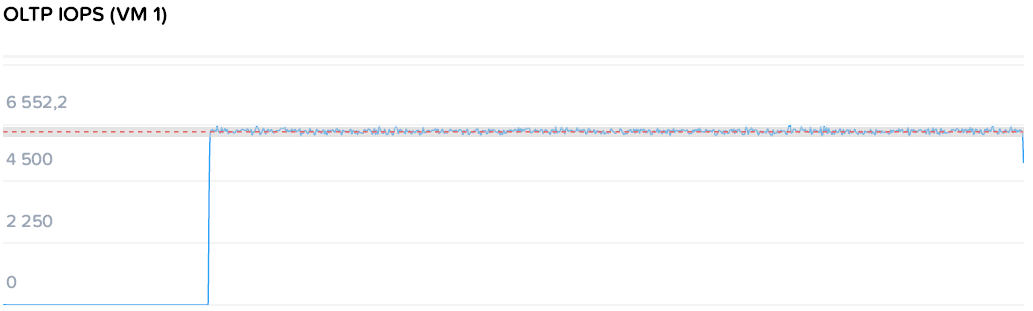
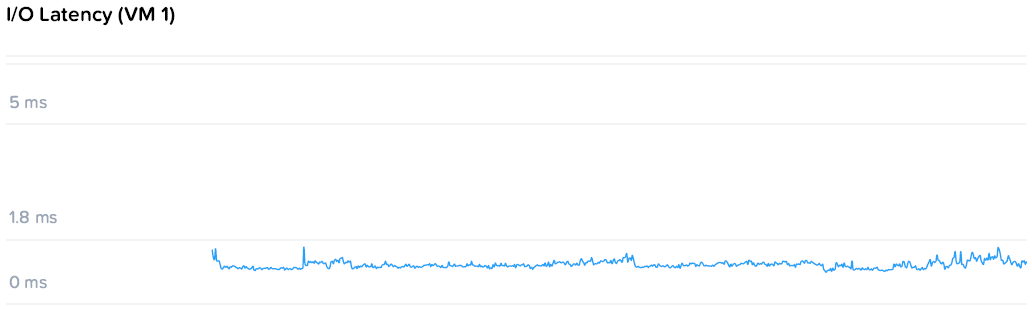
Задержка для ВМ нагрузки составляла 1.07 / 1.08 мс. В целом отличный результат, но давайте добавим жару!
Database Colocation: High Intensity
Как поведет себе транзакционная база, зависящая от задержек, если вдруг образуется шумный последовательный сосед. Ну очень шумный.
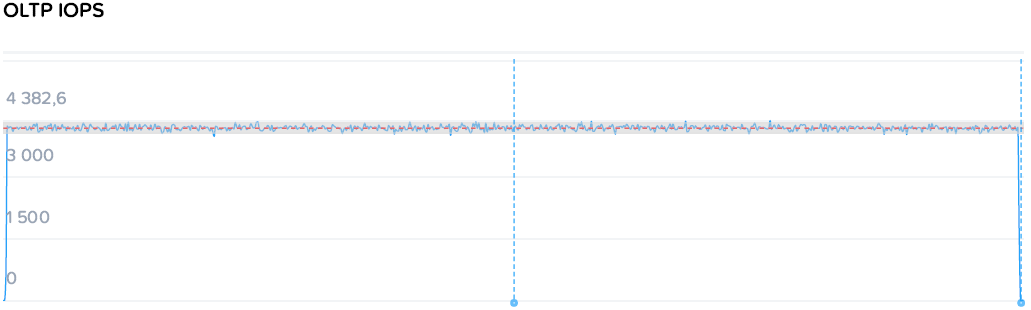
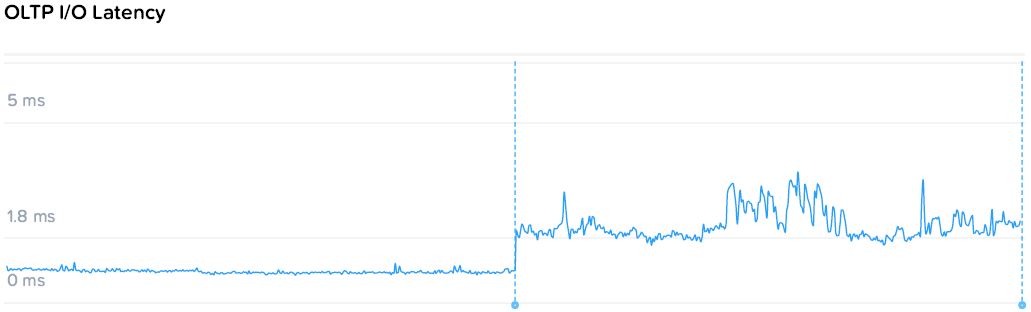
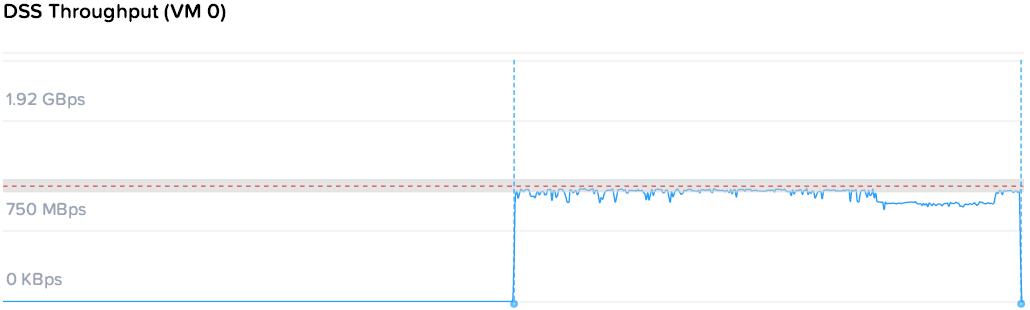
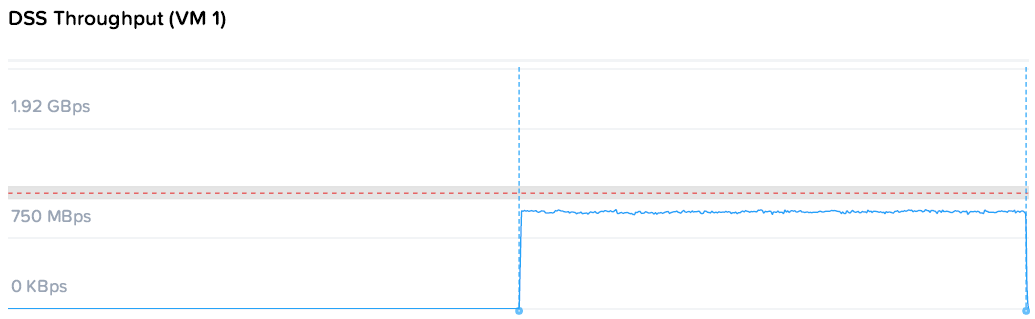
Итак, OLTP база на узле 1 генерирует 4200 IOPS при 0.85 мс задержки. Что же происходит после того как DSS система внезапно начинает отжирать ресурсы на последовательных операциях?
Два генератора на узлах 2 и 3 нагружают платформу на 1.18 / 1.08 GBps соответственно, те 2.26 GBps суммарно. Задержка на OLTP конечно растет и становится менее плоской, но среднее значение остается 1.85мс, и свои 4200 IOPS база получает без каких либо проблем.
Snapshot Impact
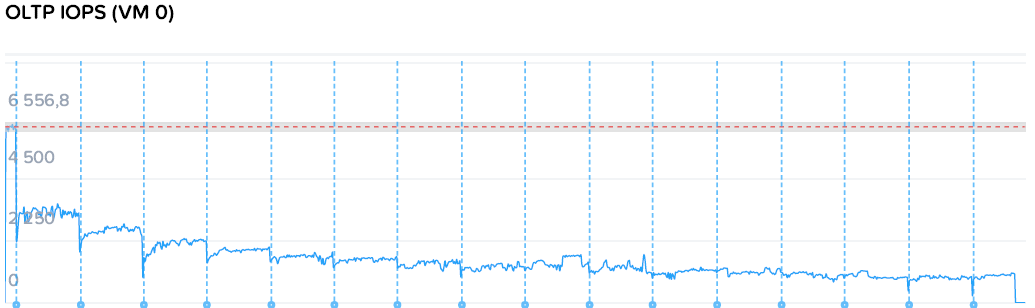
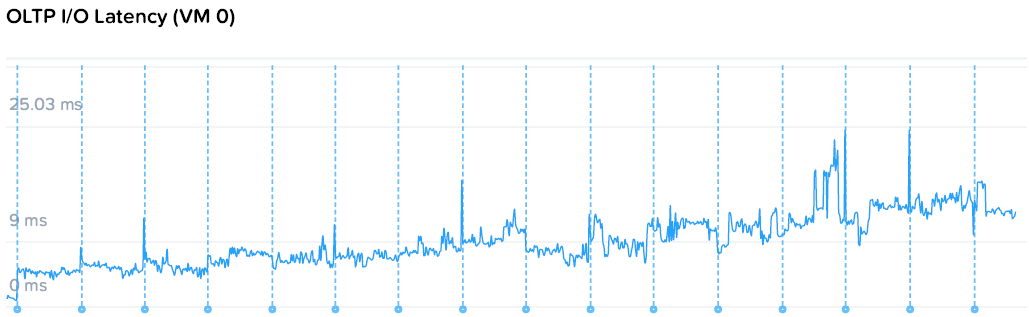
Система последовательно делает несколько мгновенных снимков раз в час на OLTP базе. Ничего удивительного в графике нет, и более того — это вообще показатель как работают классические снапшоты VMware, поскольку Nutanix XRay не умеет работать с нативными снапшотами кроме своих собственных. Не надо на регулярной основе пользоваться снапшотами vSphere, ведь не все йогурты одинаково полезны.
Нативные снапшоты HyperFlex работают значительно лучше, пользуйтесь ими, и ваши волосы станут мягкими и шелковистыми!
Big Data Ingestion
А как HyperFlex переварит большое количество данных, залитых последовательно? Ну скажем 1ТБ.
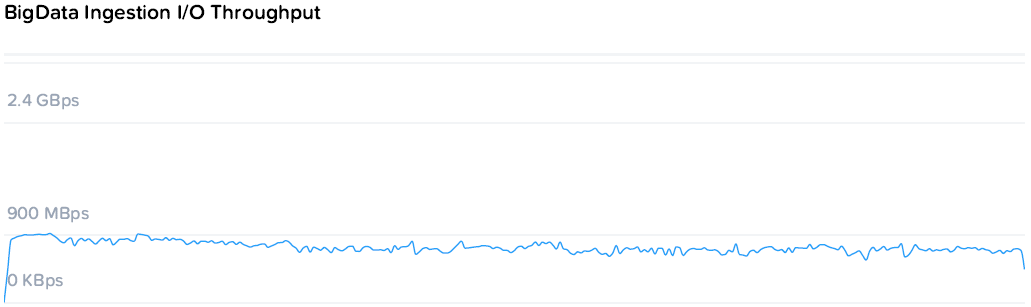
Тест занял 27 минут, включая клонирование, настройку и запуск генераторов.
Throughput Scalability
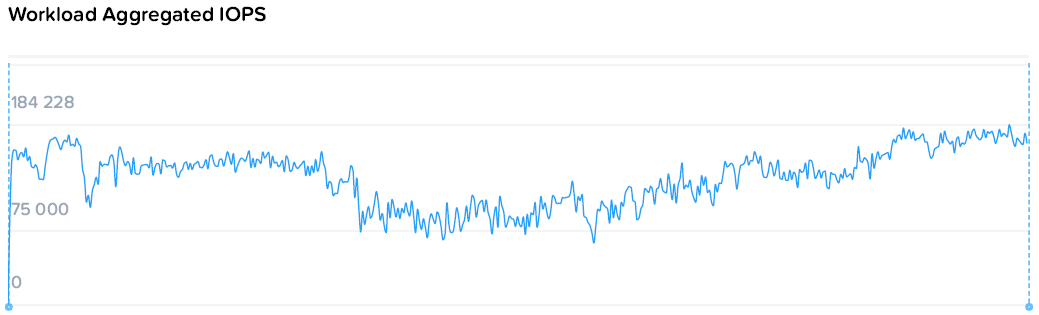
А теперь постепенно загрузим весь кластер и посмотрим на установившиеся цифры. Для начала случайным чтением, потом записью.
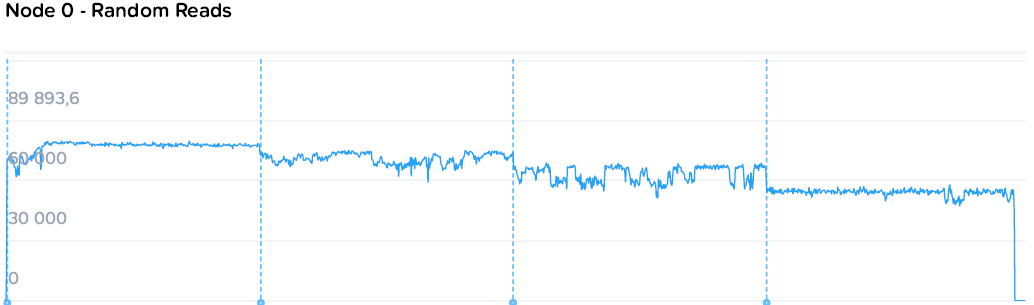
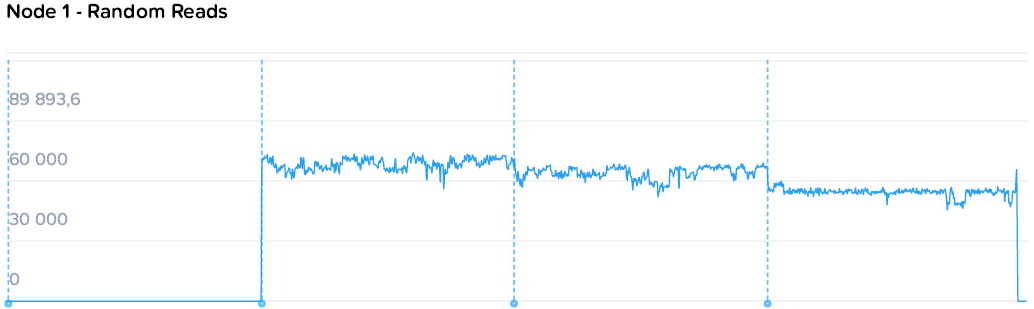
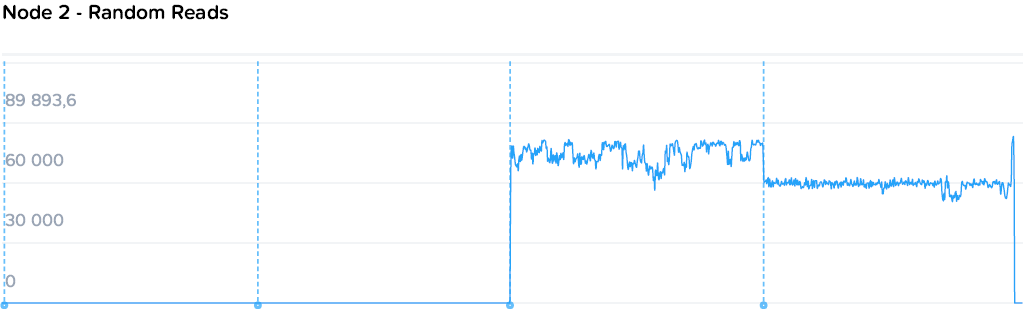
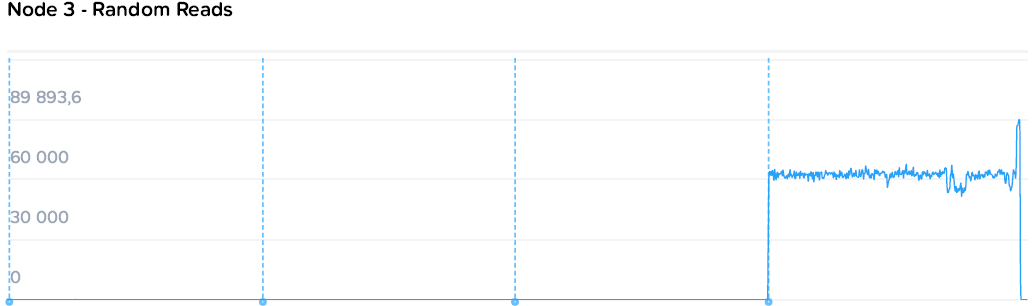

Наблюдаем стабильную картину с постепенным снижением производительности на машину нагрузки с 78k до 55-57k IOPS, с ровными полками. При этом происходит стабильный рост общей производительности с 78 до 220k IOPS.
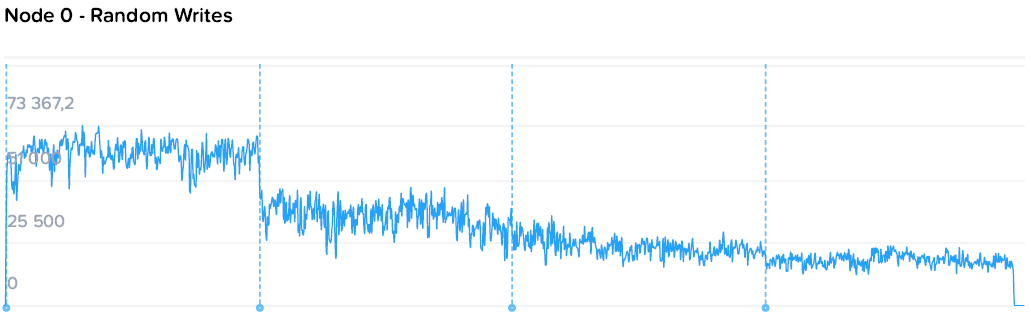
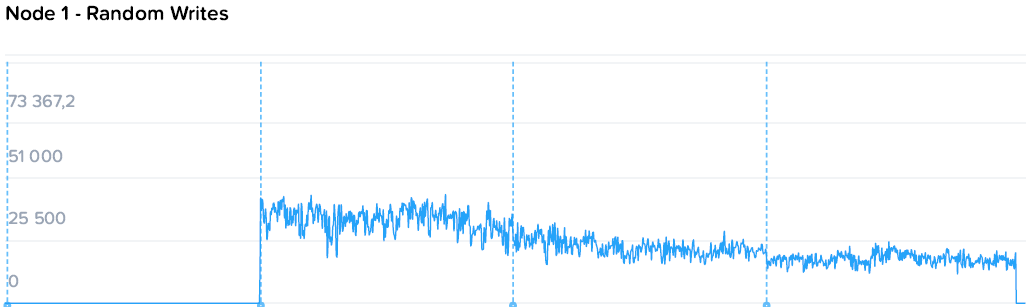
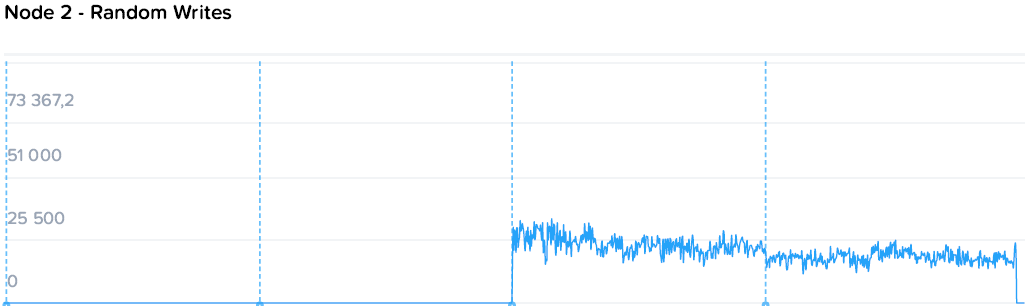
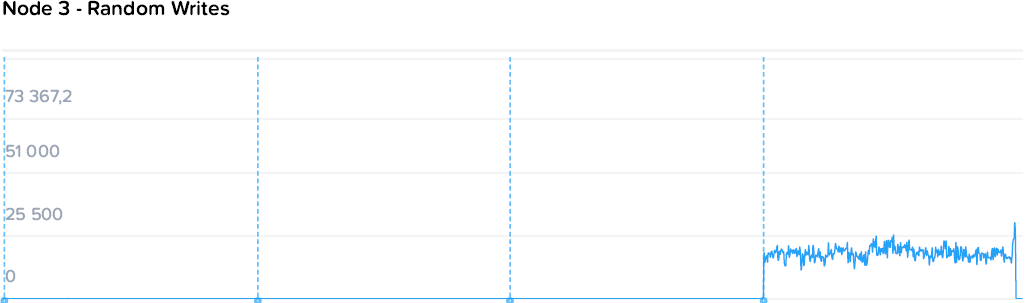
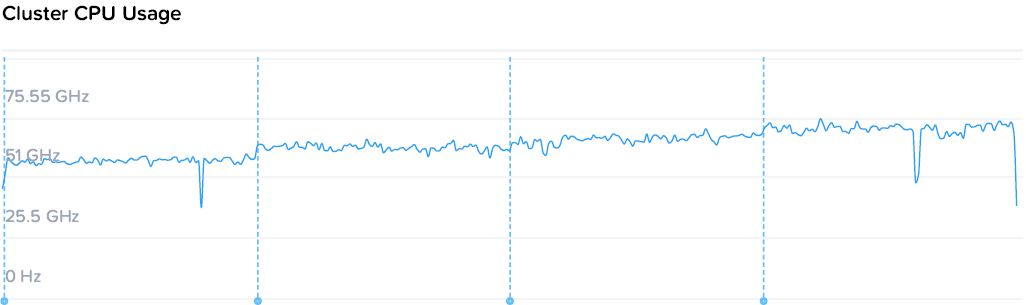
Запись идет чуть менее гладкими, но все же стабильными полками от 64k до 19-21k на машину. При этом уровень нагрузки на контроллеры значительно ниже. Если при чтении общий уровень загрузки процессоров вырос с 44 до 109, то на записи с 57 до 73 GHz.
Здесь можно наблюдать простейший и самый очевидный пример особенностей гиперконвергентных систем — единственный потребитель просто не в состоянии полностью утилизировать все ресурсы системы, а при добавлении нагрузки значимого падения производительности не происходит. То падение, что мы наблюдаем — это уже результат экстремальных синтетических нагрузок, призванных выжать все до последней капли, чего практически не бывает в обычном продуктиве.
Ломаем OLTP
К этому времени даже скучно стало насколько предсказуем HyperFlex. Срочно надо что нибудь сломать!
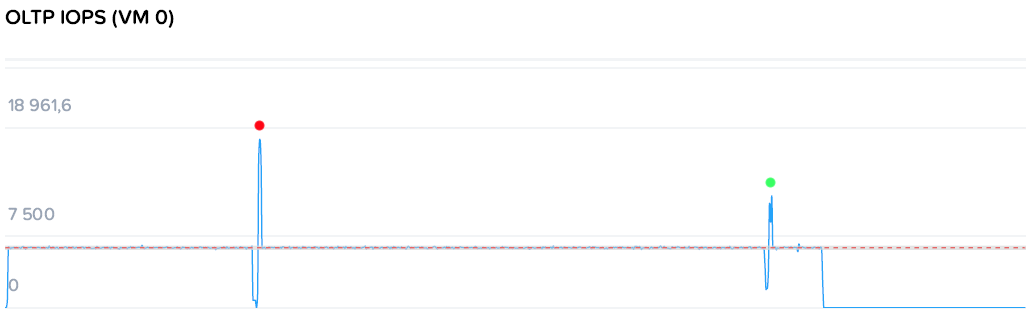
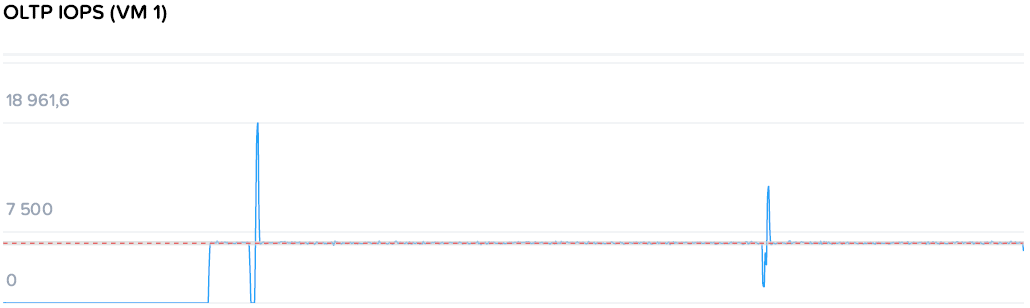
Красной точкой отмечен момент выключения контроллерной ВМ на одном из хостов с нагрузкой.
Поскольку по умолчанию ребилд в HyperFlex начинается сразу только при потере диска, а при потере узла таймаут 2 часа, то зеленой точкой отмечен момент принудительного ребилда.
login as: admin
HyperFlex StorageController 4.0(2a)
admin@192.168.***.***'s password:
<b>admin@SpringpathController0VY9B6ERXT:~$</b> stcli rebalance status
rebalanceStatus:
percentComplete: 0
rebalanceState: cluster_rebalance_not_running
rebalanceEnabled: True
<b>admin@SpringpathController0VY9B6ERXT:~$</b> stcli rebalance start -f
msgstr: Successfully started rebalance
params:
msgid: Successfully started rebalance
<b>admin@SpringpathController0VY9B6ERXT:~$</b> stcli rebalance status
rebalanceStatus:
percentComplete: 16
rebalanceState: cluster_rebalance_ongoing
rebalanceEnabled: True
<b>admin@SpringpathController0VY9B6ERXT:~$</b>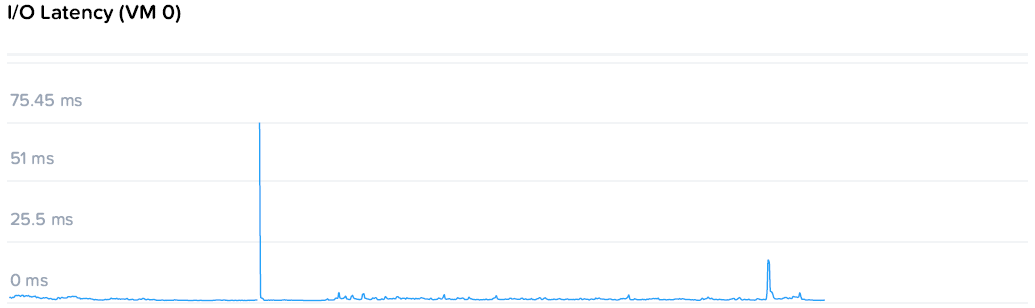
Операции замерли на пару секунд и снова продолжились, практически никак замечая ребилда. Это в стабильном состоянии, когда далеко до перегрузки кластера.
Почему 2 часа по мнению Cisco не проблема, хотя у конкурентов есть цифры и поменьше? Cisco настоятельно рекомендуют использовать RF3 в качестве базового уровня защиты данных для всего, кроме машин, которых особо не жалко. Вы решили поставить патчи или что-то сделать с хостом, выключили его. И есть шанс, что именно в этот момент выйдет из строя еще один хост — и тогда в случае RF2 все встанет колом, а при RF3 останется одна активная копия данных. И да, действительно, 2 часа при аварии вполне можно пережить на RF2 пока не начнется восстановление до RF3.
Ломай меня полностью!
Ломать — так ломать. Нагрузим по полной. В данном случае я создал тест с профилем, более-менее напоминающем реальную нагрузку (70% read, 20% random, 8k, 6d 128q).
Угадаете где выключалась CVM, а где начался ребилд?
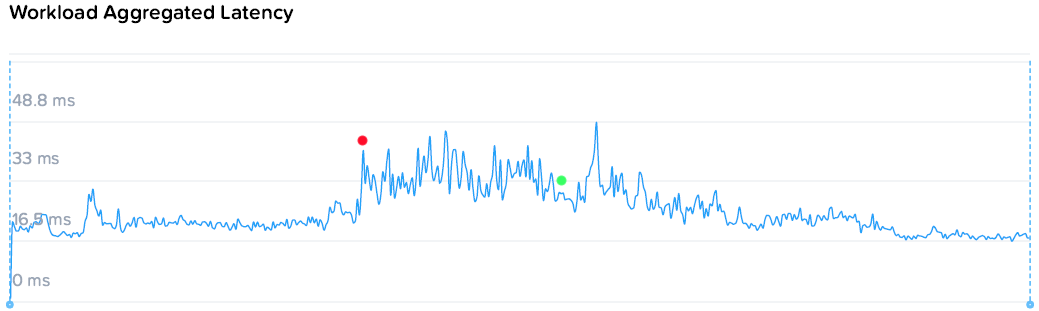
В ситуации с ребилдом HyperFlex показал себя достаточно хорошо, не вызвав катастрофического падения производительности или многократного роста задержек даже при нагрузке под самые помидоры. Единственное, чего очень бы хотелось — уважаемая Cisco, сделайте таймаут все таки поменьше 2 часов по умолчанию.
Выводы
Для выводов напомню цели проведенного тестирования: исследовать систему Cisco HyperFlex на сегодняшний день, без рассмотрения истории, исследовать ее производительность с использованием синтетики и сделать выводы о ее применимости для реального продуктива.
Вывод 1, по производительности. Производительность весьма хороша, иных комментариев тут и не дашь. Поскольку на тесте у меня была система хоть и предыдущего поколения, тут можно сказать ровно одно — на HyperFlex All Flash вы упретесь в емкость, в процессор, в память, но не в диски. Кроме разве что 1% сверхнагруженных приложений, но с ними и так разговор надо вести персонально. Нативные RoW снапшоты работают.
Вывод 2, по доступности. Система после обнаружения сбоя достаточно хорошо (без падения производительности в разы) отрабатывает восстановление количества копий данных. Есть небольшая претензия в 2-часовом таймауте по умолчанию до начала восстановления (при потере хоста), но с учетом настоятельно рекомендуемого RF3, это скорее придирка. Восстановление после выхода из строя диска начинается сразу.
Вывод 3, по цене и сравнению с конкурентами. Цена на систему может варьироваться в разы в зависимости от конфигурации под конкретный проект. Огромную долю стоимости проекта составит лицензирование системного и прикладного ПО, которое будет работать поверх инфраструктурной платформы. Поэтому единственный вариант сравнения с конкурентами — это сравнение конкретных коммерческих предложений, удовлетворяющих техническим требованиям, конкретно для вашей компании под конкретный проект.
Итоговый вывод: система рабочая, вполне зрелая для применения в продуктиве на апрель 2020, если рекомендации вендора читать и применять, а не курить.
