
“Absolute statements are the root of all evil.
The key is balance. There are no answers, only questions.”
????
Автор статьи: zolkko.
Оптимизации
Когда говорят про оптимизацию в контексте ПО, часто подразумевают оптимизацию производительности программиста и/или оптимизацию самого ПО.
Исходя из YAGNI-принципа, Python позволяет программисту сосредоточиться на реализации ПО, избавив его от необходимости заботиться о низкоуровневых вещах: регионах памяти, в которых выделяются объекты, освобождении памяти, соглашениях о вызовах.
На обратную проблему в одной из его лекций о Haskell указал Саймон Джонс. У него был слайд со стрелкой, закрашенной градиентом. В начале было написано “no types”, посередине — “Haskell”, в конце — “Coq”. Указав на Coq, он сказал: “This stresses power over usability. Right?! You need a PhD here!”[1]. Несмотря на то, что это была шутка, мантра Python — одна из любимых программистами особенностей этого языка. По моему опыту, это то, что позволяет выпускать готовый продукт несколько быстрее.
Что касается оптимизации ПО, в разных источниках об этом говорится по-разному, но я ее для себя делю на три уровня:
- на уровне архитектуры
- высокоуровневая, алгоритмы и структуры данных
- низкоуровневая
Интересная особенность здесь вот в чем: чем выше уровень, на котором проводится оптимизация, тем она эффективнее. Обычно так. С другой стороны, чем на более высоком уровне мы проводим оптимизацию, тем раньше это нужно сделать: понятное дело, в конце проекта переделывать архитектуру приложения сложнее. К тому же, заранее проблематично идентифицировать, где будет бутылочное горлышко, да и в целом хочется избегать преждевременных оптимизаций, т. к. в случае изменения требований менять ПО становиться сложнее.
Оптимизация на уровне выполнения
Наверное, самая логичная и правильная (в плане трудоемкости) стратегия для низкоуровневой оптимизации Python-кода — применение специальных инструментов таких как PyPy, Pyston и прочих. Связано это с тем, что часто используемый код Cpython уже оптимален, а попытка добавления любой строчки приведет, скорее, к деградации производительности. Кроме того, невозможно применять классические методы оптимизации из-за динамической типизации Python.
Эту проблему, в том числе, отмечал Kevin Modzelewski на Pyston Talk 2015[2]. По его словам, можно рассчитывать примерно на 10 % runtime. Комбинируя же различные техники — JIT, tracing JIT, эвристический анализ, Pyston — можно добиться прироста производительности на 25 %.
А вот один бенчмарк-график, взятый из его доклада:
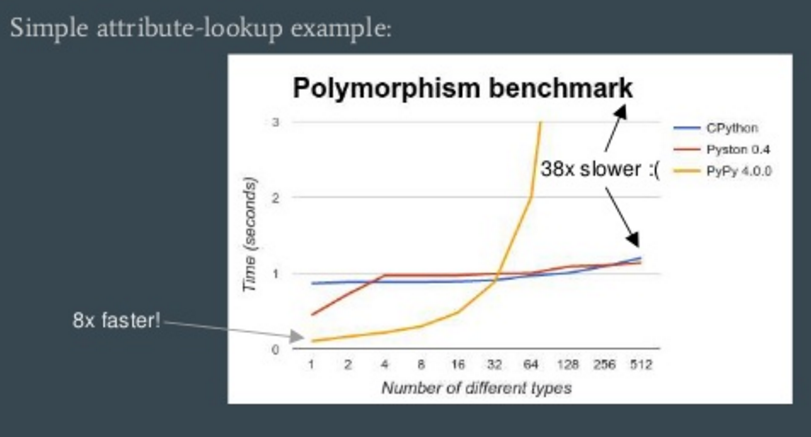
На графике видно, что в какой-то момент PyPy становится в 38 раз медленнее обычного Cpython. Результат наводит на мысль, что, применяя такой инструментарий, нужно обязательно измерять производительность. Причем делать это нужно на реальных данные, в условиях, приближенных к реальным условия исполнения ПО. И желательно выполнять такое упражнение при каждом обновлении версий интерпретаторов. Здесь можно привести цитату “If you make an optimization and don’t measure to confirm the performance increase, all you know for certain is that you’ve made your code harder to read”[3].
Оптимизация на уровне исходного кода
Аналогичную проблему можно выявить и при оптимизации на уровне языка за счет использования идиоматичного производительного кода. Для иллюстрации привожу пример небольшой программы (не совсем идиоматичной[4]), в которой определяются список слов и три функции, преобразующие его в список слов из заглавных букв:
LST = list(map(''.join, product('abc', repeat=10)))
def foo():
return map(str.upper, LST)
def bar():
res = []
for i in LST:
res.append(i.upper())
return res
def baz():
return [i.upper() for i in LST]
В ней три логически эквивалентных функции различаются семантически и производительностью. При этом семантика относительно производительности не говорит ничего. Во всяком случае, для неискушенного Python-программиста — while 1: pass vs while: True: pass — магия, которая рискует стать мистификацией при переходе на Python 3.
Модули CPython
Еще один вариант низкоуровневой оптимизации Python — модули расширения.Вынося часть логики в модуль расширения, в ряде случаев можно добиться неплохой производительности с прогнозируемым результатом.
Инструментарий
Многие доступные Python-инструментов предлагают разнообразный функционал, начиная с генерации кода для CUDA и заканчивая прозрачной интеграцией с numpy или C++. Однако ниже я буду рассматривать их поведение только в контексте написания модулей расширений на специально выбранном пограничном примере:
def add_mul_two(a, b):
acc = 0
i = 0
while i < 1000:
acc += a + b
i += 1
return acc
Как видно CPython исполняет его буквально:
12 SETUP_LOOP 40 (to 55)
15 LOAD_FAST 3 (i)
18 LOAD_CONST 2 (1000)
21 COMPARE_OP 0 (<)
24 POP_JUMP_IF_FALSE 54
27 LOAD_FAST 2 (acc)
30 LOAD_FAST 0 (a)
33 LOAD_FAST 1 (b)
36 BINARY_ADD
37 INPLACE_ADD
38 STORE_FAST 2 (acc)
41 LOAD_FAST 3 (i)
44 LOAD_CONST 3 (1)
47 INPLACE_ADD
48 STORE_FAST 3 (i)
51 JUMP_ABSOLUTE 15
54 POP_BLOCK
Поправить ситуацию можно, написав простейший модуль расширения на C.
Для этого нужно определить минимальную функцию инициализации модуля:
// example.c
void initexample(void)
{
Py_InitModule("example", NULL);
}
Эта функция называется так, потому что фактически выполнение инструкции импорта…
import example
IMPORT_NAME 0 (example)
STORE_FAST 0 (example)
…будет приводить к выполнению…
// ceval.c
...
w = GETITEM(names, oparg);
v = PyDict_GetItemString(f->f_builtins, "__import__");
...
x = PyEval_CallObject(v, w);
...
…встроенной функции builtin___import__ (bltinmodule.c), и дальше по цепочке вызовов:
dl_funcptr _PyImport_GetDynLoadFunc(const char *fqname, const char *shortname, const char *pathname, FILE *fp)
{
char funcname[258];
PyOS_snprintf(funcname, sizeof(funcname), "init%.200s", shortname);
return dl_loadmod(Py_GetProgramName(), pathname, funcname);
}
Во всяком случае для некоторых платформ и при определенных условиях: CPython собран с поддержкой динамически загружаемых модулей расширений, модуль еще не загружался, имя файла модуля имеет определенное и специфичное для конкретной платформы расширение и т. п.
Далее определяется метод модуля…
static PyObject * add_mul_two(PyObject * self, PyObject * args);
static PyMethodDef ExampleMethods[] = {
{"add_mul_two", add_mul_two, METH_VARARGS, ""},
{NULL, NULL, 0, NULL}
};
void initexample(void) {
Py_InitModule("example", ExampleMethods);
}
…и сама его реализация. Т. к. в данном случае точно известны типы входных переменных, функцию можно определить так:
PyObject * add_mul_two(PyObject * self, PyObject * args) {
int a, b, acc = 0;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
PyErr_SetNone(PyExc_ValueError);
return NULL;
}
for (int i = 0; i < 1000; i++)
acc += a + b;
return Py_BuildValue("i", acc);
}
На выходе получится бинарный код, примерно такой же, который можно получить, используя Numba…
___main__.add_mul_two$1.int32.int32:
addl %r8d, %ecx
imull $1000, %ecx, %eax
movl %eax, (%rdi)
xorl %eax, %eax
retq
…но написав только две строчки и не выходя за рамки одного языка программирования.
@jit(int32(int32, int32), nopython=True)
Кроме этого кода, numba генерирует…
add_mul_two.inspect_asm().values()[0].decode('string_escape')
…функцию-обертку вида:
_wrapper.__main__.add_mul_two$1.int32.int32:
...
movq %rdi, %r14
movabsq $_.const.add_mul_two, %r10
movabsq $_PyArg_UnpackTuple, %r11
...
movabsq $_PyNumber_Long, %r15
callq *%r15
movq %rax, %rbx
xorl %r14d, %r14d
testq %rbx, %rbx
je LBB1_8
movabsq $_PyLong_AsLongLong, %rax
…
Ее задача — разобрать входные аргументы согласно описанным в декораторе сигнатурам и, если это получилось, выполнить скомпилированную версию. Этот метод кажется очень заманчивым, но, если, например, вынести тело цикла в отдельную функцию, ее тоже нужно будет обрамлять декоратором или отключать nopython.
Cython — следующий претендент. Он представляет собой надмножество Python с поддержкой вызова C функций и определения C типов. Поэтому в простейшем случае add_mul_two функция на нем будет выглядеть аналогично Cpython. Однако обширный функционал не дается просто так, и, в отличии от C-версии, результирующий файл получится почти 2000 строк CPython API-вида:
__pyx_t_2 = PyNumber_Add(__pyx_v_a, __pyx_v_b);
if (unlikely(!__pyx_t_2)) {
__pyx_filename = __pyx_f[0];
__pyx_lineno = 14; __pyx_clineno = __LINE__;
goto __pyx_L1_error;
}
__Pyx_GOTREF(__pyx_t_2);
__pyx_t_3 = PyNumber_InPlaceAdd(__pyx_v_acc, __pyx_t_2);
if (unlikely(!__pyx_t_3)) {
__pyx_filename = __pyx_f[0]; __pyx_lineno = 14;
__pyx_clineno = __LINE__; goto __pyx_L1_error;
}
Улучшить ситуацию в плане специфичности, но не по объему кода, можно было бы написав, например, реализацию самой функции на C, а Cython использовать для определения обертки…
int cadd_mul_two(int a, int b) {
int32_t acc = 0;
for (int i = 0; i < 1000; i++)
acc += a + b;
return acc;
}
cdef extern from "example_func.h":
int cadd_mul_two(int, int)
def add_two(a, b):
return cadd_two(a, b)
cythonize("sample.pyx", sources=[ 'example_func.c' ])
…получая при этом практически идеальный вариант, но в таком случае уже нужно писать на C, Cython, Python.
__pyx_t_1 = __Pyx_PyInt_As_int32_t(__pyx_v_a); if (unlikely((__pyx_t_1 == (int32_t)-1) && PyErr_Occurred())) {__pyx_filename = __pyx_f[0]; __pyx_
__pyx_t_2 = __Pyx_PyInt_As_int32_t(__pyx_v_b); if (unlikely((__pyx_t_2 == (int32_t)-1) && PyErr_Occurred())) {__pyx_filename = __pyx_f[0]; __pyx_
__pyx_t_3 = __Pyx_PyInt_From_int32_t(cadd_two(__pyx_t_1, __pyx_t_2)); if (unlikely(!__pyx_t_3)) {__pyx_filename = __pyx_f[0]; __pyx_lineno = 8; _
Rust
Чтобы сделать модуль на Rust, нужно всего лишь объявить extern-функцию c no_mangle…
#[no_mangle]
pub extern fn initexample() {
unsafe {
Py_InitModule4_64(&SAMPLE[0] as *const _,
&METHODS[0] as *const _,
0 as *const _,
0,
PYTHON_API_VERSION);
};
}
…и описать типы:
type PyCFunction = unsafe extern "C"
fn (slf: *mut isize, args: *mut isize) -> *mut isize;
#[repr(C)]
struct PyMethodDef {
pub ml_name: *const i8,
pub ml_meth: Option<PyCFunction>,
pub ml_flags: i32,
pub ml_doc: *const i8,
}
unsafe impl Sync for PyMethodDef { }
Как и в C, нужно объявить PyMethod:
lazy_static! {
static ref METHODS: Vec = { vec![
PyMethodDef {
ml_name: &ADD_MUL_TWO[0] as *const _,
ml_meth: Some(add_mul_two),
},
...
] };
}
Из-за того, что в CPython много вызовов C API, придется написать еще и такое:
#[link(name="python2.7")]
extern {
fn Py_InitModule4_64(name: *const i8,
methods: *const PyMethodDef,
doc: *const i8, s: isize, apiver: usize) -> *mut isize;
fn PyArg_ParseTuple(arg1: *mut isize,
arg2: *const i8, ...) -> isize;
fn Py_BuildValue(arg1: *const i8, ...) -> *mut isize;
}
Зато в итоге мы получим вот такую вот красивую функцию:
#[allow(unused_variables)]
unsafe extern "C" fn add_mul_two(slf: *mut isize,
args: *mut isize) -> *mut isize {
let mut a: i32 = 0;
let mut b: i32 = 0;
if PyArg_ParseTuple(args,
&II_ARGS[0] as *const _,
&a as *const i32, &b as *const i32) == 0 {
return 0 as *mut _;
}
let mut acc: i32 = 0;
for i in 0..1000 { acc += a + b; }
Py_BuildValue(&I_ARGS[0] as *const _, acc)
}
Или, при желании…
let acc: i32 = (0..).take(1000)
.map(|_| a + b)
.fold(0, |acc, x| acc + x);
…эта функция тоже будет компилироваться в две машинные инструкции:
__ZN7add_mul_two20h391818698d43ab0ffcaE:
...
callq 0x7a002 ## symbol stub for: _PyArg_ParseTuple
testq %rax, %rax
je 0x14e3
movl -0x8(%rbp), %eax
addl -0x4(%rbp), %eax
imull $0x3e8, %eax, %esi ## imm = 0x3E8
leaq _ref5540(%rip), %rdi ## literal pool for: "h"
...
Минусы у такого подхода следующие:
- только CPython API 2.7 и если нужно так же Python 3, то придётся много кода продублировать
- если попытаться сократить размер бинарника за счёт no_std, то кода будет её больше
- в том числе т.к. Ряд структур данных в Rust отличаются от C. Так например Rust использует паскаль-строки и для взаимодействия с C придётся использовать что-то подобное std::ffi::CString
Но, к счастью, есть замечательный проект rust-cpython, который не только уже описал все необходимые CpythonAPI но и предоставляет к ним высокоуровневые абстракции, и при этом поддерживает Python 2.x и 3.x. Код получается примерно таким:
[package]
name = "example"
version = "0.1.0"
[lib]
name = "example"
crate-type = ["dylib"]
[dependencies]
interpolate_idents = "0.0.9"
[dependencies.cpython]
version = "0.0.5"
default-features = false
features = ["python27-sys"]
#![feature(slice_patterns)]
#![feature(plugin)]
#![plugin(interpolate_idents)]
#[macro_use]
extern crate cpython;
use cpython::{PyObject, PyResult, Python, PyTuple, PyDict, ToPyObject, PythonObject};
fn add_two(py: Python, args: &PyTuple, _: Option<&PyDict>) -> PyResult<PyObject> {
match args.as_slice() {
[ref a_obj, ref b_obj] => {
let a = a_obj.extract::<i32>(py).unwrap();
let b = b_obj.extract::<i32>(py).unwrap();
let mut acc:i32 = 0;
for _ in 0..1000 {
acc += a + b;
}
Ok(acc.to_py_object(py).into_object())
},
_ => Ok(py.None())
}
}
py_module_initializer!(example, |py, module| {
try!(module.add(py, "add_two", py_fn!(add_two)));
Ok(())
});
Здесь используется nightly Rust, по сути, только для sclice_pattens и PyTuple.as_slice.
Зато, как мне кажется, Rust в такой ситуации предлагает решение с мощными высокоуровневыми абстракциями, возможностью тонкой настройки алгоритмов и структур данных, эффективный и прогнозируемый результат оптимизаций. Т. е. выглядит достойной альтернативой другим инструментам.
Код примеров, использованный в статье, можно посмотреть
здесь.
Bibliography
1: Simon Peyton Jones, Adventure with Types in Haskell — Simon Peyton Jones (Lecture 2), 2014, youtu.be/brE_dyedGm0?t=536
2: Kevin Modzelewski, 2015/11/10 Pyston Meetup, 2015, www.youtube.com/watch?v=NdB9XoBg5zI
3: Martin Fowler, Yet Another OptimizationArticle, 2002, martinfowler.com/ieeeSoftware/yetOptimization.pdf
4: Raymond Hettinger, Transforming Code into Beautiful, Idiomatic Python, 2013, www.youtube.com/watch?v=OSGv2VnC0go
