Этот материал создан инженерами студии MS-1. Оригинал на английском языке доступен в блоге Arm. |

World of Tanks Blitz — сессионный танковый шутер, уже более 8 лет разрабатываемый MS-1 (старейшей и крупнейшей мобильной студией Wargaming). В 2014 году игра вышла на iOS и Android, через пару лет — на десктопах (Windows и Mac), а в 2020-м — на Nintendo Switch. Основными платформами для нас остаются Android и iOS, и тут стоит отметить, что мы стремимся делать Blitz очень масштабируемой в плане производительности: от мобильных устройств категории «super low end» до современных флагманов.
Производительность критически важна для любой игры. Наша команда из почти 200 человек, организованных в независимые кросс-дисциплинарные группы, выпускает примерно 10 обновлений в год. Чтобы поддерживать такой высокий темп (и такие масштабы) разработки, нам приходится автоматизировать многие процессы; тестирование производительности здесь не исключение. В этом материале мы покажем, как использование CI-тестирования помогает нам обеспечивать игрокам оптимальный пользовательский опыт в World of Tanks Blitz. Мы затронем следующие темы:
обзор методологии автоматизированного тестирования производительности;
профилирование CPU;
роль Arm Mobile Studio и Arm Performance Advisor в нашем воркфлоу.
Тестирование производительности World of Tanks Blitz: обзор
Если оставить в стороне игровое лобби и рассматривать только сам по себе геймплей (бои на картах), то тестирование производительности включает в себя контроль следующих метрик:
потребляемая процессом память;
время загрузки карты;
и, конечно же, время кадра.
Автоматизированные тесты мейнлайн-билдов запускаются каждую ночь. QA-инженеры также запускают эти тесты, валидируя набор изменений, содержащий:
1.изменения контента
либо
2.изменения в коде, потенциально способные повлиять на производительность.
Мы запускаем тесты, используя CI-сервер, где тестовые устройства выполняют роль build-агентов. Наша ферма для тестов состоит из более чем 30 устройств, представляющих все поддерживаемые платформы и весь спектр производительности.
Мы стараемся отлавливать проблемы до того, как они попадут в мейнлайн, но, если такое все же произойдет, ночные тесты это покажут. Поскольку контента и поддерживаемых моделей устройств у нас много, мы сделали специальный дэшборд для отображения результатов всех ночных тестов. К примеру, вот так он выглядит для теста времени загрузки карты (это лишь часть таблицы, в которой 13 столбцов и 30 рядов).
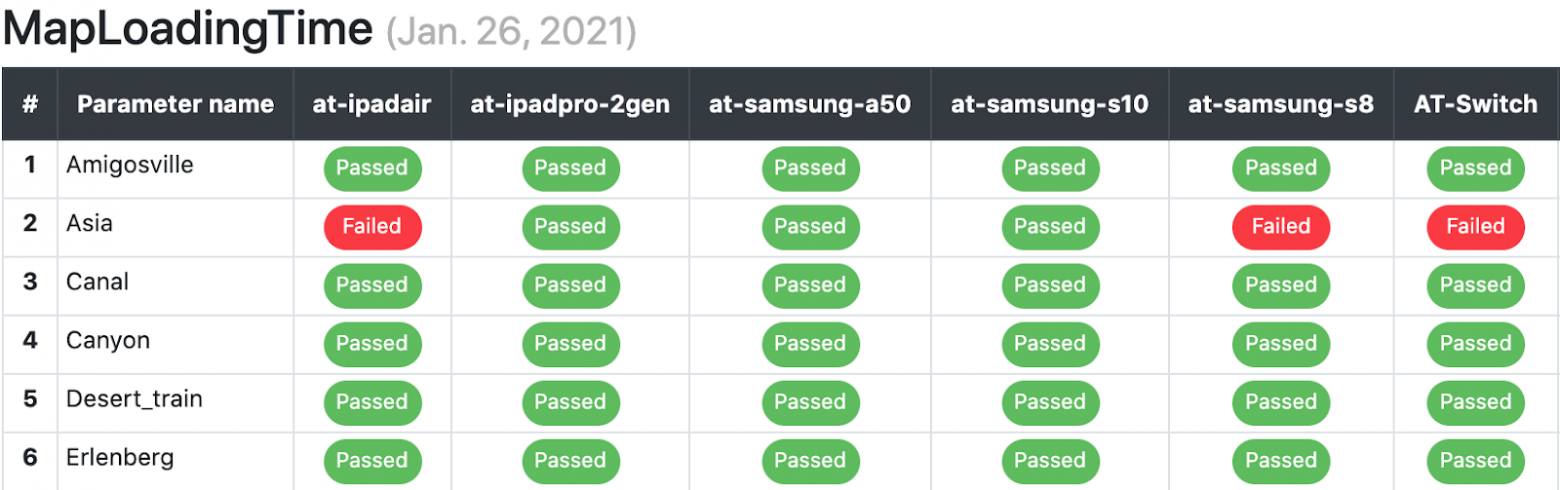
Для нашего масштаба и темпа разработки очень важно иметь здоровый мейнлайн: поскольку мы придерживаемся принципа ранней интеграции и при сборке билда для тестирования фиче-бранч всегда сливается с мейнлайном, то проблема в мейнлайне может быть интерпретирована как проблема в фиче-бранче. По этой причине у нас строгий регламент решения проблем, выявленных в мейнлайне: фича, вызывающая проблему, должна быть отключена или откачена в течение одного рабочего дня после создания соответствующей задачи.
Учитывая, сколько в нашей игре контента и сколько платформ и уровней производительности устройств мы поддерживаем, тяжело представить процесс разработки без автоматизированных тестов производительности.
Если бы мы запускали все тесты, которые активируются каждую ночь автоматизированными процессами, нам бы пришлось посвятить им все время 2–3 специалистов, работающих на полный день. Но скорее мы бы пошли на компромисс — по покрытию тестами устройств или контента, или по частоте проведения регрессионных тестов, и это негативно сказалось бы на скорости разработки.
Тестирование нового контента и фичей, в котором задействуются тесты производительности, занимало бы на 10–20% больше времени. Также в мейнлайн попадало бы больше проблемных изменений, так как ручные тесты менее надежны.
Необходимость детализации данных в отчетах
Выше упоминалось, что для нас критически важно решать проблемы в мейнлайне в течение одного рабочего дня. Но так как у нас много независимых команд со своей специализацией, для начала нужно быстро разобраться, какая из них ответственна за проблему. Хотя тесты и запускаются каждую ночь, при нашем масштабе разработки за один день в мейнлайн вливается 10–15 нетривиальных пулл-реквестов. Не всегда удается понять, какой именно из них привел к проблеме, просто взглянув на код. Поэтому мы хотим иметь в отчетах автотестов как можно больше деталей о том, что именно привело к изменению той или иной метрики.
Кроме определения команды, ответственной за решение проблемы в мейнлайне, дополнительные данные в отчетах очень полезны при тестировании фичей. Увидев в отчете детализированные данные (например, какая именно функция стала выполняться дольше), программист может понять, где проблема, даже без ручного профилирования игры. Точно так же создатели контента, имея доступ к такой информации, могут сразу понять, что нужно оптимизировать.
К примеру, для тестов памяти мы используем специальные сборки с Memory Profiler. Это позволяет делить всю используемую память на категории (их около 30) и видеть в отчетах не просто одно значение (общее потребление памяти процессом), а гораздо более детальную картину.
Для теста времени загрузки карты отчет содержит только одно значение (время загрузки).

Но при наличии проблемы в артефактах теста можно найти json-файл для Chrome Profiler.

Чтобы разобраться с увеличившимся временем загрузки карты, достаточно скачать json-файлы двух прогонов теста, открыть их в chrome://tracing и сравнить.
Мы довольно долго думали над удобным способом представления деталей в отчетах тестов FPS. Но прежде чем показать, что у нас получилось, немного расскажем о самом нашем подходе к данной категории тестов.
FPS-тесты: обзор
Тесты FPS сделаны на основе реплеев: после добавления каждой новой карты (а их в игре уже 30) проводится плейтест, затем выбирается один его реплей и помещается в репозиторий. После этого данный реплей попадает на тестирование FPS.
Реплей — это, по сути, запись всех сообщений с сервера, а также части клиентского состояния (например, углов поворота камеры). По сравнению с тестами, заскриптованными вручную, такой подход имеет ряд преимуществ и недостатков.
Преимущества
Тесты очень близки к тому, что видят игроки: в ходе реплея происходят всевозможные геймплейные события, а в кадре есть все графические составляющие (и UI, и частицы) в тех же количествах, что и в реальных игровых ситуациях.
Тесты для новых карт получить довольно легко: нет этапа скриптования, нужен только плейтест. Конечно, с точки зрения проверки карты подобный тест нельзя назвать полным — проверяется только путь, по которому ехал конкретный игрок. Но для проверки контента у нас есть отдельные тесты, где камера последовательно ставится в точки на сетке 8x8 и в каждой точке делает оборот с шагом 45 градусов.
Недостатки
Тесты занимают существенное время. Тест для одной карты длится около 4 минут; умножив это на количество карт (30), мы получим 2 часа.
В реплее состояние игры меняется очень динамично, и бывает непросто соотнести короткую просадку FPS с каким-то конкретным участком реплея.
Как профайлер CPU улучшает отчеты FPS-тестов
Долгое время единственным результатом, который мы видели в отчетах, было среднее значение FPS. Также в артефактах тестового запуска можно было найти график изменений FPS в ходе реплея с шагом в секунду. Такой подход имел серьезный недостаток — единичные длинные кадры никак не обнаруживались в тестах. Осознав это, мы решили не просто измерять длину каждого отдельного кадра, а пойти дальше и задействовать в автотестах встроенный в наш движок профайлер CPU. Чтобы профайлер не влиял на время кадра на устройствах категории «low end», пришлось ограничить количество меток в каждом кадре. Для этого мы добавили функционал тегов: каждая метка в коде тегируется, а мы можем включать или выключать группы меток. По умолчанию при запуске автотеста у нас не более 70 меток на один кадр.

Включение профайлера в автотестах открывает новую возможность: можно задавать бюджеты на время работы отдельных функций. Это позволяет отлавливать пики в нагрузке определенных систем. Кроме того, бюджетирование упрощает принятие решений о вводе новых систем в игру. К примеру, когда мы несколько лет назад принимали решение включить автоматический лэйаутинг UI-контролов в бою, мы предварительно убедились, что FPS при этом не меняется существенным образом. После внедрения профайлера мы были крайне удивлены тем, как много времени в кадре мы иногда тратим на автоматический лэйаутинг. Правильным подходом было бы определить бюджет еще до ввода новой системы (к примеру, «Лэйаутинг должен работать не больше 1 мс на кадр на Samsung S8») и далее контролировать выполнение этого условия с помощью автотестов, чтобы изменения в коде или контенте не приводили к превышению бюджета.
В конце реплея мы анализируем трейс профайлера и складываем в артефакты json для Chrome Tracing, в котором остаются только те кадры, где какие-то функции превысили свой бюджет. В примере ниже можно видеть несколько десятков кадров, где функция Scene::Update исполнялась дольше, чем ей положено:
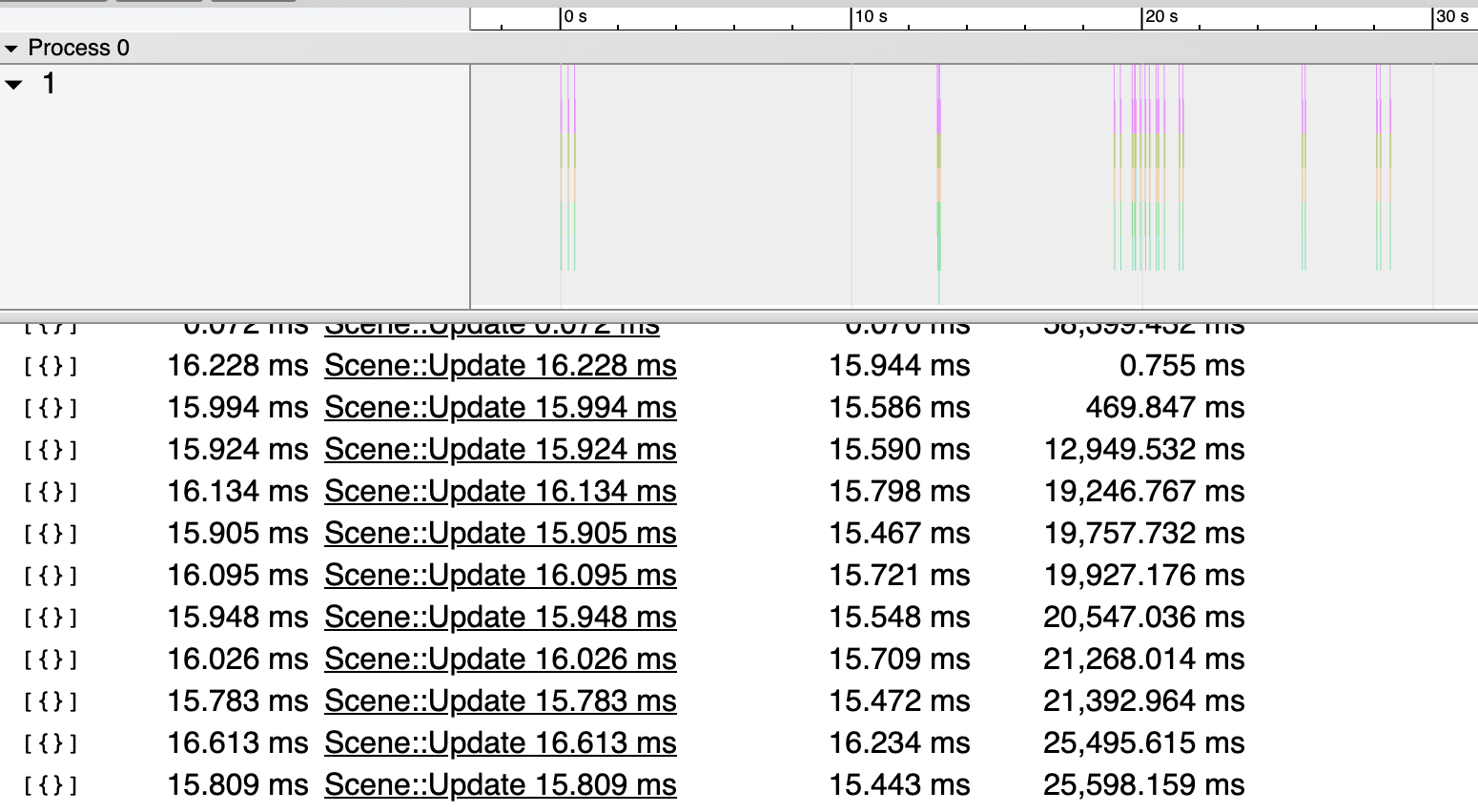
С пиками все относительно просто, но как отследить небольшие увеличения времени работы каких-либо функций? Сравнивать два трейса длиной 4 минуты не казалось приемлемым решением, поэтому мы решили начать со статистики. Для небольшого набора самых интересных функций мы подсчитываем количество кадров, в которых время исполнения функции попадало в некоторый диапазон, и получаем частотное распределение.

Далее мы шлем эти данные в bigquery и визуализируем их, используя datastudio.

На схеме выше видно, что количество кадров, для которых функция Engine::OnFrame выполнялась 24–28 мс, значительно выросло 27 сентября. Для выяснения причины проблемы можно применить простую последовательность:
опускаемся вниз на один уровень по колстэку;
последовательно выбираем в фильтре дэшборда функции с этого уровня колстэка, пока не найдем ту, что вызывает проблему;
если мы еще не на самом нижнем уровне, возвращаемся к шагу 1.
Если мы дошли до самого нижнего уровня и обнаружили функцию-«виновницу», это замечательно. Но что, если время исполнения всех функций выросло более-менее равномерно? На это может быть несколько причин.
С большой вероятностью это троттлинг, одна из основных сложностей в тестировании производительности на мобильных устройствах. Мы решили эту проблему, разместив ферму тестовых устройств в комнате с охлаждением. И пусть таким образом мы создали немного нереалистичные условия тестирования, но по, крайней мере, добились стабильных результатов на большинстве устройств.
Появился новый поток, конкурирующий за процессорное время с нашим кодом. Идентифицировать его поможет семплирующий профайлер.
Хотя внедрение инструментирующего CPU-профайлера в тесты не отменило необходимость использовать семплирующий профайлер, оно многократно уменьшило количество случаев, когда это было необходимо. Один случай описан выше; другой — микрооптимизация, когда нужно оценивать время исполнения отдельных инструкций в ассемблере.
Вернемся к нашей «проблеме 27 сентября». Применив приведенную выше последовательность действий, мы выяснили, что функция-«виновница» — rhi::DevicePresent. Эта функция просто вызывает переключение буфера, так что «бутылочное горлышко» явно на стороне GPU! Но как нам узнать из отчетов, что именно заставило GPU обрабатывать кадры медленнее?
GPU-метрики
Внимательный читатель мог заметить выше на скриншоте из datastudio, что одно из значений в фильтре не похоже на название функции: «DrawCallCount». Кроме него, есть еще несколько подобных метрик: «PrimitiveCount», «TriangleCount», «VertexCount». К сожалению, это вся информация, которую мы можем собрать на стороне CPU, чтобы выяснить, что вызвало замедление на стороне GPU. Но чтобы разобраться с «проблемой 27 сентября», хватило и этого.
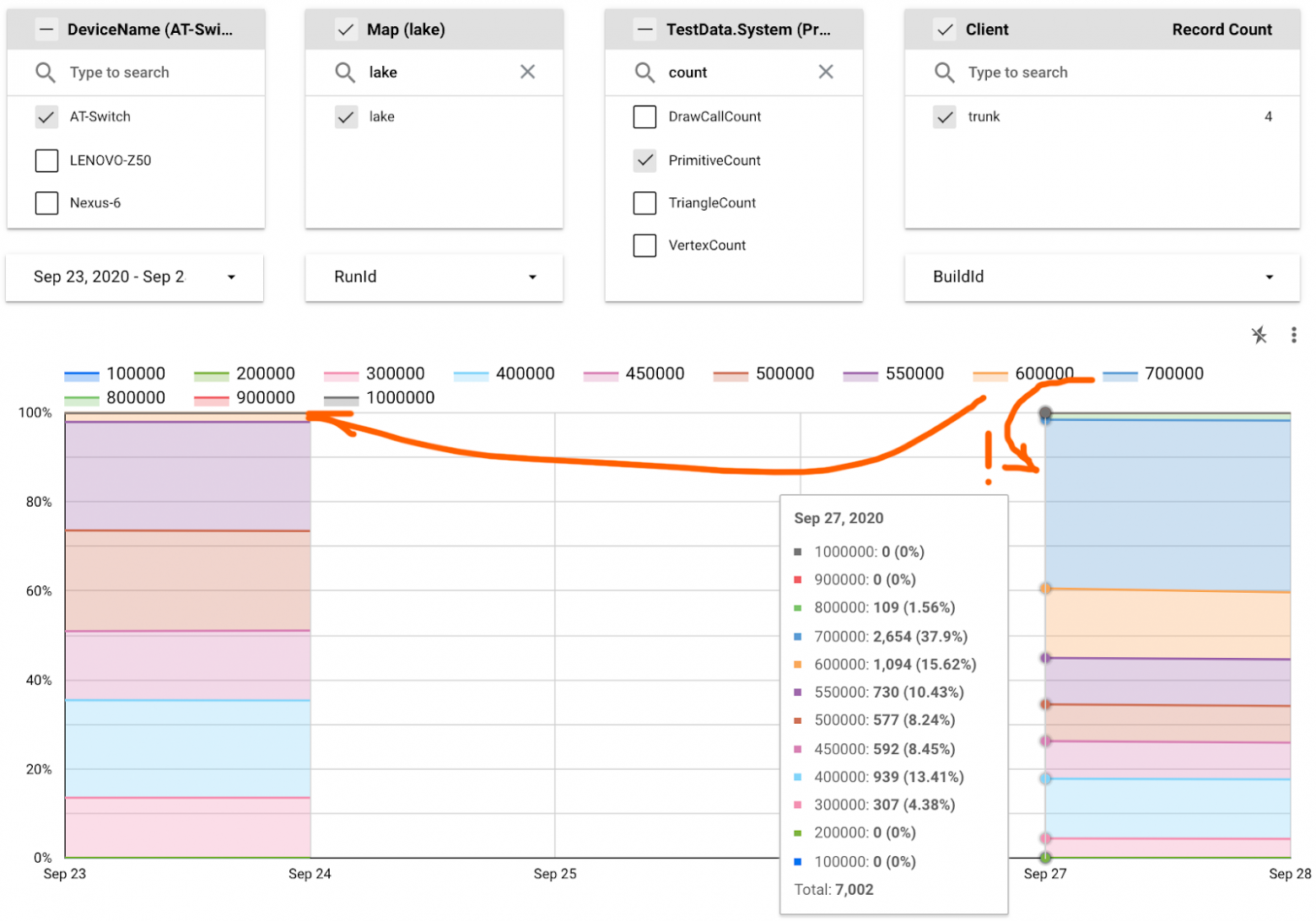
Оказалось, что во многих кадрах мы стали рисовать на 150K больше примитивов. Сопоставив эту информацию со списком пулл-реквестов, которые были влиты в промежутке времени между двумя запусками теста (на графике видно, что между запусками прошло 3 дня, но два из них были выходными, когда тесты не запускались), мы быстро обнаружили задачу-«виновницу».
Но что, если бы источником проблемы было бы усложнение шейдера? Или изменение порядка отрисовки и, как следствие, выросший overdraw? Или мы случайно начали бы сохранять буфер глубины в основную память, значительно увеличив объем передаваемых по шине данных?
Эти метрики сложно (в случае с overdraw) или невозможно (в случаях со сложностью шейдеров и объеме данных, копируемых в основную память) отслеживать внутри самой игры. И здесь на помощь приходит Arm Mobile Studio Pro.
Как Arm Mobile Studio Pro позволяет анализировать нагрузку на GPU
Arm Mobile Studio Pro дает возможность записывать значения с аппаратных счетчиков (hardware counters) для GPU семейства Mali в ходе выполнения автотеста на CI-сервере, помогая нам решать три типа задач:
в регрессионных тестах искать ответ на вопрос «Что именно поменялось на стороне GPU?»;
в тестах нового контента определять, где именно находится «бутылочное горлышко» и что надо оптимизировать;
при внедрении новых графических фич делать осознанный выбор целевых устройств (как упоминалось в самом начале, мы поддерживаем очень широкий спектр устройств, поэтому графические фичи, как правило, включаются через настройки меню).
Для нас очень важно, что в Arm Mobile Studio есть инструмент под названием Performance Advisor. Он представляет трейс профайлера, записанный в ходе теста, в виде легко читаемого html-отчета.
Давайте посмотрим, как Arm Mobile Studio Pro (и в частности, Performance Advisor) ускоряют решение задач типа 3.
Недавно мы добавили в движок декали, и перед техническим художником встала задача определить бюджет по перекрытию геометрии карты декалями. Суть этой задачи состояла в том, чтобы:
определить целевые устройства, на которых мы хотели бы сделать доступной новую фичу;
подготовить тестовый контент, добавив декали на существующую карту, для которой уже имелись бы результаты тестов FPS;
запустить автотест билда с измененным контентом на целевых устройствах;
оценить результат; если FPS значительно снизится, надо либо пересматривать бюджет для контента и возвращаться к этапу 2, либо пересматривать список целевых устройств.
PA (Performance Advisor) значительно упрощает этап 4. Допустим, на этапе 1 мы выбрали в качестве таргетного устройства Samsung Galaxy A50 с Mali-G72 MP3. Вот как выглядит первая часть отчета PA о запуске на этом устройстве теста на высоких настройках качества (пока без декалей).
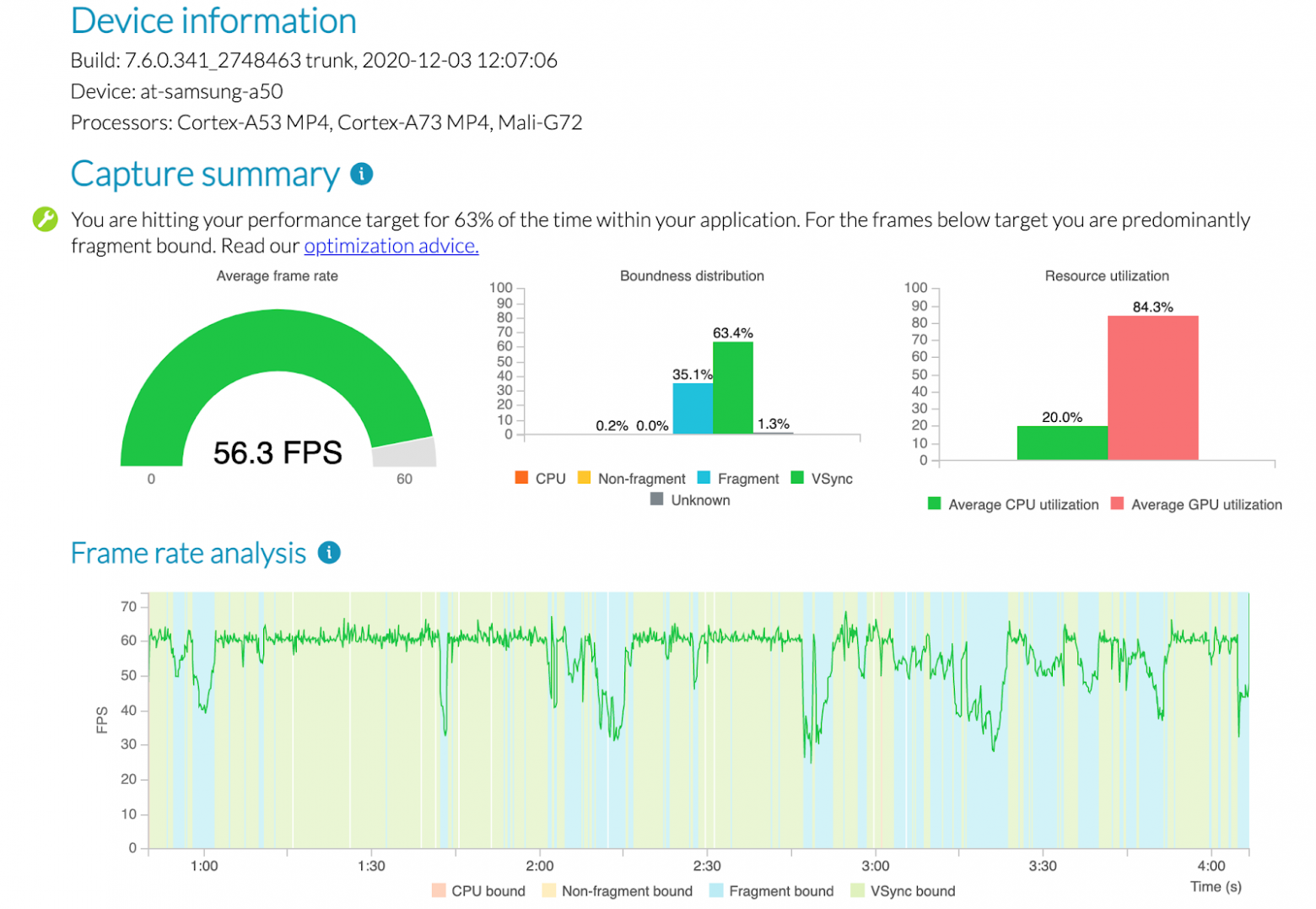
Главные наблюдения:
FPS местами опускался до 30, что мы могли узнать и без Arm Mobile Studio Pro;
в проблемных местах устройство явно было fragment bound (упиралось во фрагментный шейдер) — вот это уже интересно, можно строить прогнозы относительно контента с декалями.
Запускаем тест для билда с декалями, находим в артефактах сгенерированный PA html-отчет и открываем его.
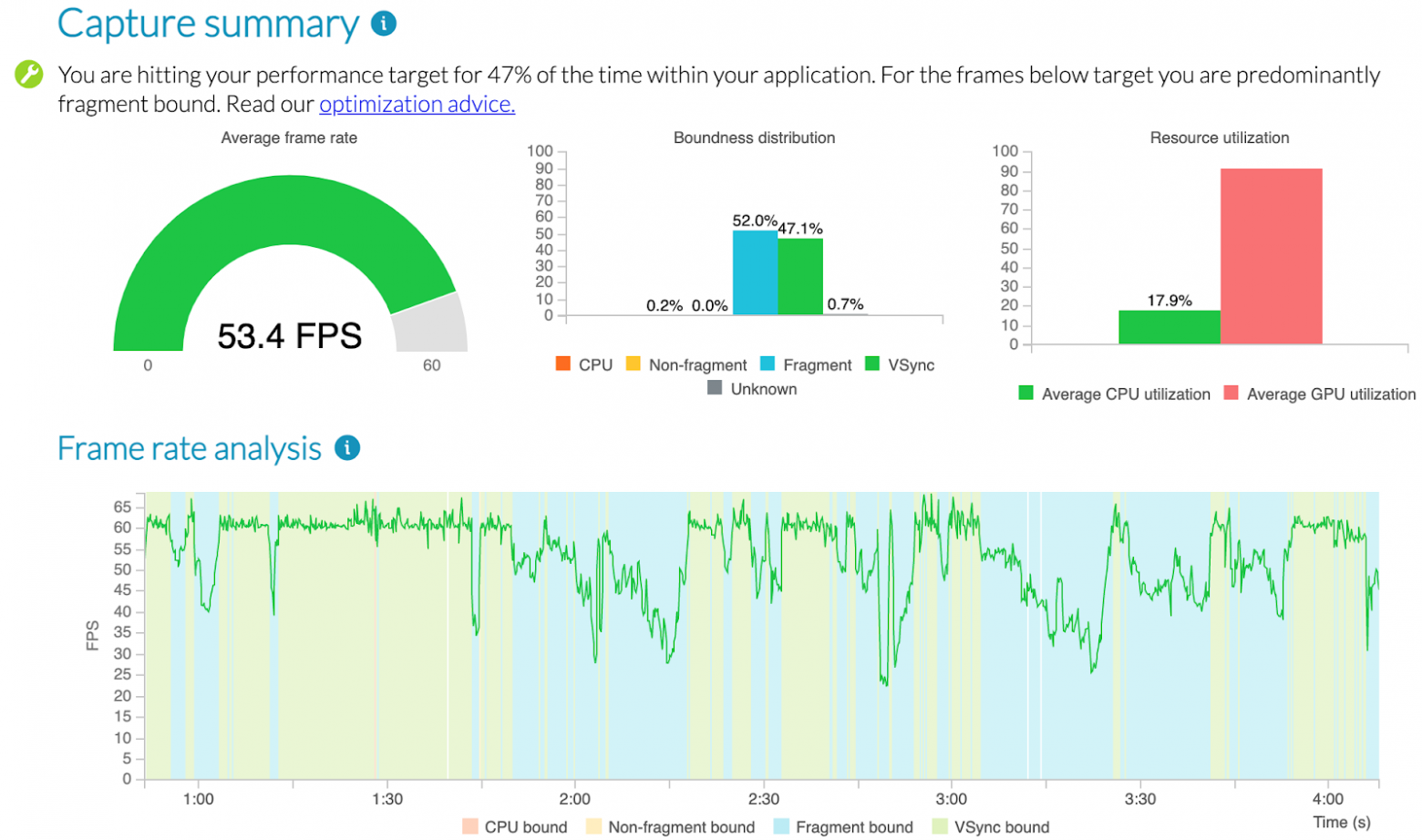
Ну что ж, на данном устройстве и с тем количеством декалей, которое добавил технический художник в первой итерации, доля fragment-bound-кадров значительно выросла. Вперед, к следующей итерации!
Не во всех случаях PA сможет явно указать вам на «бутылочное горлышко». К примеру, на мощных устройствах мы нередко видим значительную долю unknown boundness.
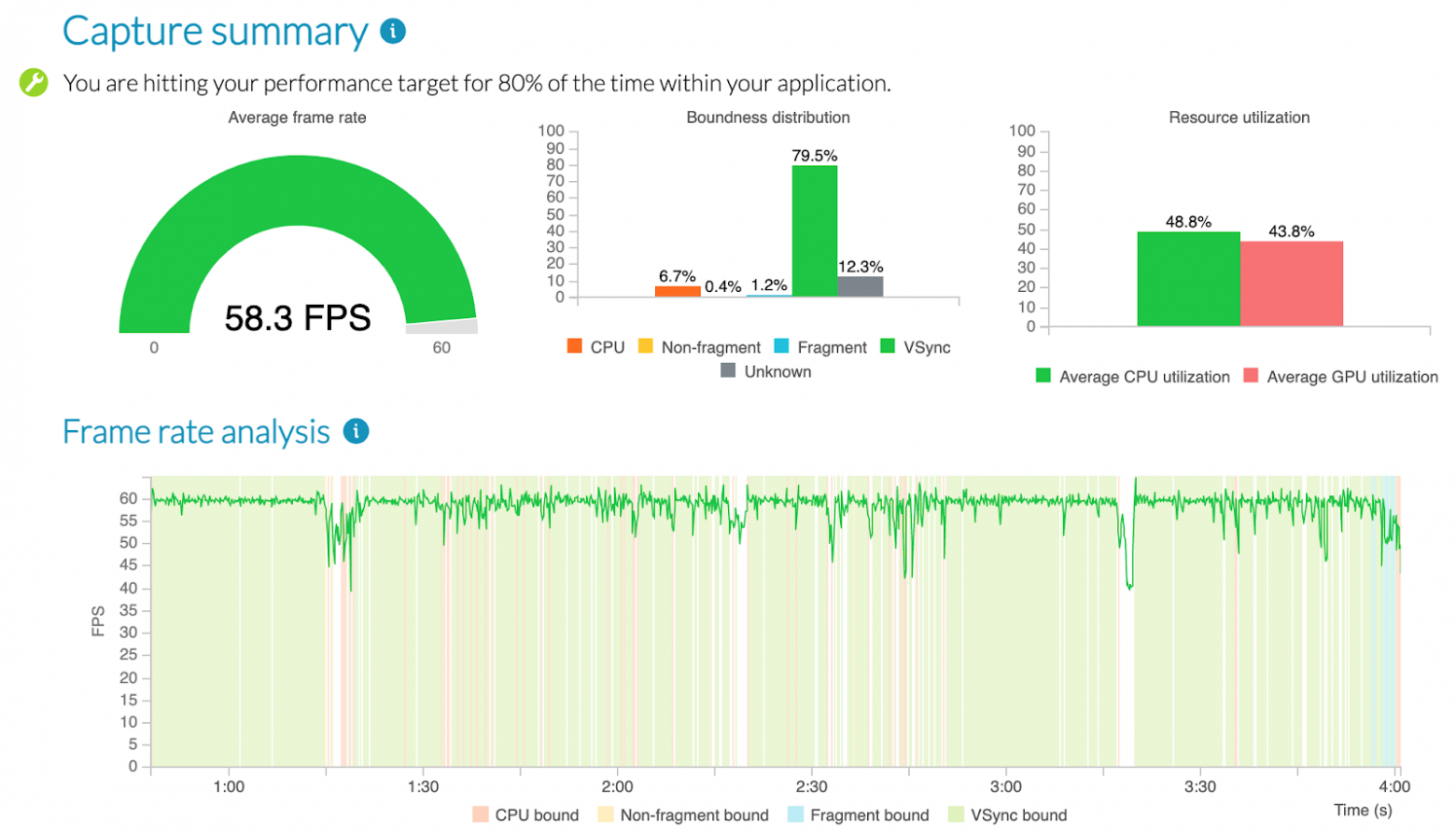
В такой ситуации помогут полные трейсы профайлера, которые можно скачать из артефактов запуска теста и проанализировать, используя Streamline. К счастью, аппаратные счетчики детально описаны в документации, а инженеры ARM всегда готовы помочь консультацией.
Следует отметить, что Arm Mobile Studio Pro легко и быстро интегрировалась в наш CI-воркфлоу. Помимо удобных отчетов PA и полных трейсов профайлера, мы получили также json-файл со средними значениями и центилями для всех метрик, которые отображаются на графиках в отчете PA. Некоторые из них мы в самом ближайшем будущем планируем начать отправлять в bigquery и визуализировать, используя datastudio — по аналогии с тем, как мы делаем это для данных нашего CPU-профайлера. Сами метрики описаны здесь.
Хотя Arm Mobile Studio Pro позволяет нам получать дополнительные данные только для GPU семейства Mali, это самые распространенные GPU у наших игроков. Также многие выводы, которые мы можем сделать из тестов на устройствах с GPU семейства Mali, остаются валидными и для других устройств (к примеру, если нагрузка на шину данных выросла на Mali, с большой вероятностью она вырастет и на других Android-устройствах, а вероятно, и на других платформах).

Так что спасибо Arm: ваши тулзы позволили решить нашу проблему с недостатком информации о работе GPU в отчетах автотестов.
Заключение
В MS-1 мы обожаем автоматизировать рутинные задачи. Тесты производительности были автоматизированы уже давно, но пространство для роста оставалось.
Усилия, которые мы в последнее время вложили в повышение информативности отчетов автотестов, позволили создать автоматизированный фреймворк, который экономит время, уходящее на тестирование и исследование источников проблем. Теперь мы в состоянии идентифицировать многие проблемы с кодом и контентом, минуя скучную фазу ручного профилирования. Сбор данных профилирования в автоматизированной тестовой среде не только делает их более доступными, но и повышает их качество:
стабильная тестовая среда дает более стабильные данные (что особенно важно для мобильных устройств, где на результаты тестов может повлиять разница в 3–5 °C в температуре помещения);
доступность исторических данных позволяет отделять значимые изменения тестируемых метрик от шума.
А качество данных, в свою очередь, существенно влияет на скорость их анализа.
Мы полагаем, что автоматизированное тестирование производительности необходимо любой студии игровой разработки среднего или крупного размера. Оно не просто экономит рабочее время команды, но также важно для качества тестирования и управления рисками: с автотестами, запускающимися каждую ночь, вам не придется беспокоиться, что проблемы с производительностью внезапно обнаружатся во время финального плейтеста и нарушат ваше расписание релизов.
