
DaData.ru — сервис автоматической проверки, исправления и дедупликации контактных данных (ФИО, адресов, телефонов, email, паспортов).
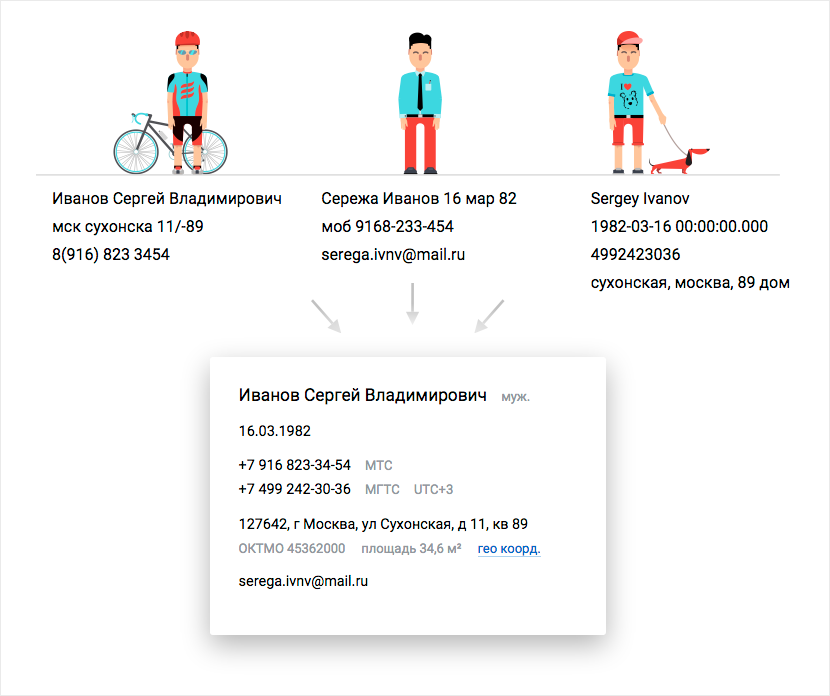
У меня в телефоне 453 контакта. Среди них встречаются дубли: один и тот же человек записан то как «Леха», то как «Алексей Мегафон», а то и как «Зиновьев, Алексей Иванович». У Лехи указан скайп и день рождения, у «Алексея Николаевича» — емейл и основной мобильный номер, а у «Мегафона» — запасной номер от понятнокакого оператора.
В телефонных контактах дубли неприятны, но не особо напрягают. Хуже, когда такая чехарда начинается с клиентской базой компании.
Проблема
Когда контактные данные клиентов «размазаны» по нескольким Excel-файлам или базам данных, они усложняют жизнь:
- Непонятно, во сколько обходится клиент. В 2003 году Виктор Петрович обратился в «МойТвойСтрах» и застраховал жизнь, в 2007 году — автомобиль, а в 2012 — дом. В результате его три раза завели в учетные системы. Автоматически посчитать прибыли и убытки по Виктору Петровичу невозможно, сколько для него должна стоить страховка — непонятно.
- Рассылка превращается в кошмар. Маркетолог Вика вручную копирует и объединяет телефоны и емейлы из десятка эксель-файлов. Торопится, ругается, ошибается. Впопыхах теряет две тысячи контактов. Когда это выясняется, директор очень недоволен Викой.
- Взбешенные клиенты. У провайдера «Связьинтерком» клиенты дублируются в трех разных базах (компания работает 20 лет, накопила знатный ИТ-зоопарк). В результате клиент Федор раз за разом получает повторные рекламные письма, звонки и смс. Когда терпение Федора заканчивается, он уходит в «Гуттелеком».
Решение
Найти и
Кому пригодится:
- Маркетологу. Построить единый список клиентов из десятка excel-файлов — для рассылки или загрузки в CRM.
- Отделу продаж. Составить реестр ФИО и телефонов из нескольких баз — для телемаркетинга.
- Торговой компании. Найти одинаковые торговые точки от разных дилеров, сравнив по адресу — для правильного подсчета прибыли торговой точки.
- И, в конечном счете, — разработчику. Решить задачи бизнеса, не заработав седых волос и не убив на это лучшие годы жизни.
Проще, чем писать свой велосипед
Пффф, найти дубли, подумаешь. Вот, не благодарите:
address1 == address2
Ах да, могут же еще быть опечатки. Тогда так:
similarity (address1, address2) > 0.95
Ну-ка:
> similarity (
"мск сухонска 11/-89",
"сухонская, москва, 11 дом, кв89") > 0.95
False
Получается, данные сначала нужно нормализовать, привести к «каноническому» виду («мск сухонска 11/-89» → «127642, г Москва, ул Сухонская, д 11, кв 89»). И сравнивать с осторожностью, а то получится так:
> similarity (
"Москва, Тверская-Ямская 1-я, д 20",
"Москва, Тверская-Ямская 3-я, д 20") > 0.95
True # упс
А еще не забыть при поиске дублей:
- проверять по нескольким сценариям: ФИО + дата рождения + телефон, ФИО + адрес, адрес + телефон + email — чтобы не пропустить дубли, у которых часть полей не заполнена;
- придумать эффективный алгоритм, иначе сложность O(n2) на 100 тыс. клиентов даст ~½1010 сравнений клиентов между собой;
- различать «гарантированные» (можно автоматически объединять) и не гарантированные (сначала проверить вручную) дубликаты — иначе наобъединяете лишнего.
Не самое простое дело. А в Дадате все уже готово.
Точнее, чем проверять вручную
Люди часто ошибаются в адресах и телефонах, или пишут одно и то же по-разному:
г. Новосибирск, ул. Жемчужная, д. 2
жмчужная нск 2, подъезд 4
Советский район, Новосибирская область,
улица Жемчужная, дом 2, квартира 98
Поэтому вручную сравнивать клиентов тяжело: человек не воспринимает эти данные как одинаковые. Конечно, можно нанять 200 операторов, чтобы они прошерстили всю базу. Работать будут долго, обойдется дорого, а в результате все равно много дублей пропустят.
Дадата обработает 100 тысяч записей за полчаса и разобьет данные на три группы:
- уникальные: клиенты, которые есть только в одном экземпляре;
- похожие: люди со сходством по атрибутике, не недостаточно сильным, чтобы автоматически объединить;
- одинаковые: точно одни и те же люди.

Одинаковых Дадата объединит сама. А похожих лучше посмотреть вручную:
«Овчинников Федор, 12.10.1990, Самара Кирова 12» и «Fedor ovchinnikov, Samara, fedor@thefedor.ru» — один и тот же человек? Можно поднять историю его заказов и разобраться, Дадата здесь не поможет.
Как работает и сколько стоит
Дадата использует готовые алгоритмы сравнения ФИО, адресов и телефонов с учетом ошибок и опечаток. За восемь лет мы отладили их на проектах с крупными корпоративными заказчиками и теперь даем доступ всем.
Когда Дадата объединяет похожих клиентов, от каждого берет лучшее: ФИО, адрес, телефон. Если адресов или телефонов несколько, берет все. Одинаковые — объединяет в один.
Если клиенты недостаточно похожи, чтобы объединить, сообщает об этом:
| Таких клиентов объединим Елена Баева, родилась 10.11.1990 г Москва, ул Норильская, д 17, кв 25 Елена Баева Нарильская мск, дом 17 кв25, этаж 4 |
А этих — нет (отец и сын) Алексей Ефремов, 18.06.1951 г Новошахтинск, ул Красных Зорь, д 7 Алексей Ефремов, 12.03.1976 г Новошахтинск, ул Красных Зорь, д 7 |
Работает с файлами, API пока нет. Напишите в комментариях, если нужно (и как стали бы использовать).
Стоит 25 копеек за запись в файле (10 000 записей = 2 500 рублей). Статистика по файлу и просмотр 100 записей — бесплатно. Попробуйте сами.
