Комментарии 145
2. На ОС Эльбрус можно пересобрать и запускать NET приложения? Имеется вот такой функциональный язык программирования написанный для NET. и Вот такой компилятор
Насколько его реально будет пересобрать под Эльбрус ОС?
Мне кажется для МЦСТ опенсорс жизненно необходим — даст толчок и реальные перспективы. Пусть не OpenHardware, но хотя бы частично т.к. имхо слишком мало ресурсов чтобы все самим пилить в закрытых НИИ.
В общем, сумлеваюсь я насчет открытия. Увы.
Хотя, может и не откроют. Мол, это прямой путь к воспроизведению инфраструктуры.
у США авианосцы собраны на винде, у ФСБ есть исходники винды, но нет авианосцев
en.wikipedia.org/wiki/Elbrus_(computer)#cite_note-2
The S-400 works equally well in 360 degrees of activity area. Its phased array radar antenna with Elbrus-90 computer ensures the detection range of up to 600 kilometres.
Никаких проблем из-за открытости архитектуры нет.
Вот как разработчика у которого мцст компилятор один из десятка в основном все устраивает, они даже +- актуальность поддерживают, но вот того кто принимал решение о том в какой кодировке писать вывод сообщений хочется повесить за одно место на заборе
www.mcst.ru/elbrus_prog
Wait until completed…
Warmup
…
[1] ArithemticsBenchmark
ArithemticsBenchmark 1225 ms 7346.94 pts 244897959.18 Iters/s
Iterrations: 300000000, Ratio: 0.030
[2] MathBenchmark
MathBenchmark 41640 ms 2401.54 pts 4803073.97 Iters/s
Iterrations: 200000000, Ratio: 0.500
[3] CallBenchmark
CallBenchmark 882 ms 22675.74 pts 2267573696.15 Iters/s
Iterrations: 2000000000, Ratio: 0.010
[4] IfElseBenchmark
IfElseBenchmark 2218 ms 9017.13 pts 901713255.18 Iters/s
Iterrations: 2000000000, Ratio: 0.010
[5] StringManipulation
StringManipulation 4424 ms 11301.99 pts 1130198.92 Iters/s
Iterrations: 5000000, Ratio: 10.000
[6] MemoryBenchmark
int 4k: 10067.65 MB/s
int 512k: 10416.00 MB/s
int 8M: 10010.26 MB/s
int 32M: 10035.99 MB/s
long 4k: 10731.46 MB/s
long 512k: 10643.05 MB/s
long 8M: 10754.82 MB/s
long 32M: 10666.66 MB/s
Average: 10415.74 MB/s
MemoryBenchmark 2867 ms 10415.74 pts 10415.74 MB/s
Iterrations: 500000, Ratio: 1.000
[7] RandomMemoryBenchmark
Random int 4k: 1045.85 MB/s
Random int 512k: 1050.56 MB/s
Random int 8M: 1057.99 MB/s
Random long 4k: 1063.21 MB/s
Random long 512k: 1020.64 MB/s
Random long 8M: 1054.85 MB/s
Average: 1048.85 MB/s
RandomMemoryBenchmark 20526 ms 2097.71 pts 1048.85 MB/s
Iterrations: 500000, Ratio: 2.000
[8] Scimark2Benchmark
SciMark 2.0a
Composite Score: 1472.12
FFT Mflops: 1841.86 (N=1024)
SOR Mflops: 1402.95 (100 x 100)
Monte Carlo Mflops: 244.48
Sparse matmult Mflops: 1240.62 (N=1000, nz=5000)
LU Mflops: 2630.70 (100x100):
Scimark2Benchmark 25875 ms 14721.23 pts 1472.12 CompositeScore
Iterrations: 1, Ratio: 10.000
[9] DhrystoneBenchmark
##########################################
Dhrystone Benchmark, Version 2.1 (Language: JavaScript)
Optimization Non-optimised
Final values (* implementation-dependent):
Int_Glob: O.K. 5 Bool_Glob: O.K. true
Ch_1_Glob: O.K. A Ch_2_Glob: O.K. B
Arr_1_Glob[8]: O.K. 7 Arr_2_Glob8/7: O.K. 20000010
Ptr_Glob-> Ptr_Comp: * true
Discr: O.K. 0 Enum_Comp: O.K. 2
Int_Comp: O.K. 17 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Next_Ptr_Glob-> Ptr_Comp: * true same as above
Discr: O.K. 0 Enum_Comp: O.K. 1
Int_Comp: O.K. 18 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Int_1_Loc: O.K. 5 Int_2_Loc: O.K. 13
Int_3_Loc: O.K. 7
Enum_Loc: O.K. 1
Str_1_Loc: O.K. DHRYSTONE PROGRAM, 1'ST STRING
Str_2_Loc: O.K. DHRYSTONE PROGRAM, 2'ND STRING
Nanoseconds one Dhrystone run: 204
Dhrystones per Second: 4910385
VAX MIPS rating = 2794
DhrystoneBenchmark 4074 ms 11179.02 pts 2794.76 DMIPS
Iterrations: 1, Ratio: 4.000
[10] WhetstoneBenchmark
Whetstone Benchmark JavaScript Version, Tue, 29 Dec 2020 04:48:54 GMT
1 Pass
Test Result MFLOPS MOPS millisecs
N1 floating point -1.123980363 1527.45 0.0126
N2 floating point -1.131185123 1198.93 0.1121
N3 if then else 1.000000000 1260.66 0.0821
N4 fixed point 12.000000000 3683.35 0.0855
N5 sin,cos etc. 0.499029132 262.96 0.3164
N6 floating point 0.999993890 283.42 1.9032
N7 assignments 3.000000000 773.22 0.2390
N8 exp,sqrt etc. 0.998281679 144.75 0.2570
MWIPS 3324.59 3.0079
WhetstoneBenchmark 24148 ms 3324.59 pts 3324.59 MWIPS
Iterrations: 1, Ratio: 1.000
[11] LinpackBenchmark
Running Linpack 2000x2000 in JavaScript
Norma is 0.49999936918999666
Residual is 4.4959869160976496e-12
Normalised residual is 20.25
Machine result.Eepsilon is 2.220446049250313e-16
x[0]-1 is 4.440892098500626e-13
x[n-1]-1 is -3.997469022465339e-12
Time is 1.96
MFLOPS: 2727.954
LinpackBenchmark 2232 ms 27279.54 pts 2727.95 MFLOPS
Iterrations: 1, Ratio: 10.000
[12] HashBenchmark
HashBenchmark 12947 ms 1544.76 pts 154475.94 Iters/s
Iterrations: 2000000, Ratio: 10.000
Total: 143058 ms 123305.91 pts
Single-thread results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Win32,Chrome 87,0,0,7346.94,2401.54,22675.74,9017.13,11301.99,10415.74,2097.71,14721.23,11179.02,3324.59,27279.54,1544.76,123305.91,143058
Single-thread Units results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Win32,Chrome 87,0,0,244897959.18,4803073.97,2267573696.15,901713255.18,1130198.92,10415.74,1048.85,1472.12,2794.76,3324.59,2727.95,154475.94,123305.91,143058
Wait until completed…
Warmup
…
[1] ArithemticsBenchmark
ArithemticsBenchmark 1253 ms 7182.76 pts 239425379.09 Iters/s
Iterrations: 300000000, Ratio: 0.030
[2] MathBenchmark
MathBenchmark 15026 ms 6655.13 pts 13310262.21 Iters/s
Iterrations: 200000000, Ratio: 0.500
[3] CallBenchmark
CallBenchmark 907 ms 22050.72 pts 2205071664.83 Iters/s
Iterrations: 2000000000, Ratio: 0.010
[4] IfElseBenchmark
IfElseBenchmark 2553 ms 7833.92 pts 783392087.74 Iters/s
Iterrations: 2000000000, Ratio: 0.010
[5] StringManipulation
StringManipulation 7460 ms 6702.41 pts 670241.29 Iters/s
Iterrations: 5000000, Ratio: 10.000
[6] MemoryBenchmark
int 4k: 6543.13 MB/s
int 512k: 6520.87 MB/s
int 8M: 6539.36 MB/s
int 32M: 6572.39 MB/s
long 4k: 6643.28 MB/s
long 512k: 6746.11 MB/s
long 8M: 6719.45 MB/s
long 32M: 6707.90 MB/s
Average: 6624.06 MB/s
MemoryBenchmark 4461 ms 6624.06 pts 6624.06 MB/s
Iterrations: 500000, Ratio: 1.000
[7] RandomMemoryBenchmark
Random int 4k: 183.02 MB/s
Random int 512k: 184.61 MB/s
Random int 8M: 183.78 MB/s
Random long 4k: 184.96 MB/s
Random long 512k: 176.82 MB/s
Random long 8M: 184.25 MB/s
Average: 182.91 MB/s
RandomMemoryBenchmark 117589 ms 365.81 pts 182.91 MB/s
Iterrations: 500000, Ratio: 2.000
[8] Scimark2Benchmark
SciMark 2.0a
Composite Score: 925.19
FFT Mflops: 818.89 (N=1024)
SOR Mflops: 1323.91 (100 x 100)
Monte Carlo Mflops: 806.72
Sparse matmult Mflops: 573.12 (N=1000, nz=5000)
LU Mflops: 1103.30 (100x100):
Scimark2Benchmark 24939 ms 9251.88 pts 925.19 CompositeScore
Iterrations: 1, Ratio: 10.000
[9] DhrystoneBenchmark
##########################################
Dhrystone Benchmark, Version 2.1 (Language: JavaScript)
Optimization Non-optimised
Final values (* implementation-dependent):
Int_Glob: O.K. 5 Bool_Glob: O.K. true
Ch_1_Glob: O.K. A Ch_2_Glob: O.K. B
Arr_1_Glob[8]: O.K. 7 Arr_2_Glob8/7: O.K. 20000010
Ptr_Glob-> Ptr_Comp: * true
Discr: O.K. 0 Enum_Comp: O.K. 2
Int_Comp: O.K. 17 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Next_Ptr_Glob-> Ptr_Comp: * true same as above
Discr: O.K. 0 Enum_Comp: O.K. 1
Int_Comp: O.K. 18 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Int_1_Loc: O.K. 5 Int_2_Loc: O.K. 13
Int_3_Loc: O.K. 7
Enum_Loc: O.K. 1
Str_1_Loc: O.K. DHRYSTONE PROGRAM, 1'ST STRING
Str_2_Loc: O.K. DHRYSTONE PROGRAM, 2'ND STRING
Nanoseconds one Dhrystone run: 306
Dhrystones per Second: 3265839
VAX MIPS rating = 1858
DhrystoneBenchmark 6124 ms 7435.04 pts 1858.76 DMIPS
Iterrations: 1, Ratio: 4.000
[10] WhetstoneBenchmark
Whetstone Benchmark JavaScript Version, Tue, 29 Dec 2020 05:59:20 GMT
1 Pass
Test Result MFLOPS MOPS millisecs
N1 floating point -1.123980363 1498.83 0.0128
N2 floating point -1.131185123 1236.43 0.1087
N3 if then else 1.000000000 1892.14 0.0547
N4 fixed point 12.000000000 3025.94 0.1041
N5 sin,cos etc. 0.499029132 304.54 0.2732
N6 floating point 0.999988899 686.43 0.7858
N7 assignments 3.000000000 943.82 0.1958
N8 exp,sqrt etc. 0.998281679 148.44 0.2506
MWIPS 5600.01 1.7857
WhetstoneBenchmark 17446 ms 5600.01 pts 5600.01 MWIPS
Iterrations: 1, Ratio: 1.000
[11] LinpackBenchmark
Running Linpack 2000x2000 in JavaScript
Norma is 0.49999936918999666
Residual is 4.4959869160976496e-12
Normalised residual is 20.25
Machine result.Eepsilon is 2.220446049250313e-16
x[0]-1 is 4.440892098500626e-13
x[n-1]-1 is -3.997469022465339e-12
Time is 4.4
MFLOPS: 1213.112
LinpackBenchmark 4639 ms 12131.12 pts 1213.11 MFLOPS
Iterrations: 1, Ratio: 10.000
[12] HashBenchmark
HashBenchmark 15736 ms 1270.97 pts 127097.10 Iters/s
Iterrations: 2000000, Ratio: 10.000
Total: 218133 ms 93103.84 pts
Single-thread results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Win32,Firefox 84,0,0,7182.76,6655.13,22050.72,7833.92,6702.41,6624.06,365.81,9251.88,7435.04,5600.01,12131.12,1270.97,93103.84,218133
Single-thread Units results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Win32,Firefox 84,0,0,239425379.09,13310262.21,2205071664.83,783392087.74,670241.29,6624.06,182.91,925.19,1858.76,5600.01,1213.11,127097.10,93103.84,218133
24 шаг уже минут 10-15 висит просто, без какой-либо нагрузки. 22 шаг как-то сильно хуже, чем 21. Может он в ядрах путается?)
…
Bench
[1] ArithemticsBenchmark
ArithemticsBenchmark 900.90 ms 9989.94 pts 333018630.73 Iter/s
Iterrations: 300000000, Ratio: 0.03
[2] ParallelArithemticsBenchmark
ParallelArithemticsBenchmark 1842.10 ms 121888.92 pts 162857846.87 Iter/s
Iterrations: 300000000, Ratio: 0.03
[3] MathBenchmark
MathBenchmark 9131.87 ms 10950.66 pts 21901326.42 Iter/s
Iterrations: 200000000, Ratio: 0.5
[4] ParallelMathBenchmark
ParallelMathBenchmark 17008.26 ms 148134.91 pts 11758992.88 Iter/s
Iterrations: 200000000, Ratio: 0.5
[5] CallBenchmark
CallBenchmark 211.00 ms 2435.90 pts 243589631.32 Iter/s
Iterrations: 2000000000, Ratio: 0.01
[6] ParallelCallBenchmark
ParallelCallBenchmark 10943.29 ms 49416.33 pts 182760401.41 Iter/s
Iterrations: 2000000000, Ratio: 0.01
[7] IfElseBenchmark
IfElseBenchmark 2299.46 ms 8697.70 pts 869770596.70 Iter/s
Iterrations: 2000000000, Ratio: 0.01
[8] ParallelIfElseBenchmark
ParallelIfElseBenchmark 5218.86 ms 95948.53 pts 383225484.74 Iter/s
Iterrations: 2000000000, Ratio: 0.01
[9] StringManipulation
StringManipulation 3212.08 ms 15566.26 pts 1556627.77 Iter/s
Iterrations: 5000000, Ratio: 10
[10] ParallelStringManipulation
ParallelStringManipulation 175031.77 ms 6948.26 pts 28566.24 Iter/s
Iterrations: 5000000, Ratio: 10
[11] MemoryBenchmark
int 4k: 15960.61 MB/s
int 512k: 15931.75 MB/s
int 8M: 15946.45 MB/s
int 32M: 15946.45 MB/s
long 4k: 29804.46 MB/s
long 512k: 29932.20 MB/s
long 8M: 29652.65 MB/s
long 32M: 15946.45 MB/s
Average: 22871.35 MB/s
MemoryBenchmark 1263.08 ms 22871.35 pts 22871.35 MB/s
Iterrations: 500000, Ratio: 1
[12] ParallelMemoryBenchmark
ParallelMemoryBenchmark 19063.85 ms 294881.19 pts 294881.19 MB/s
Iterrations: 500000, Ratio: 1
[13] RandomMemoryBenchmark
Random int 4k: 7302.13 MB/s
Random int 512k: 5529.64 MB/s
Random int 8M: 4286.81 MB/s
Random long 4k: 16519.04 MB/s
Random long 512k: 11265.34 MB/s
Random long 8M: 8841.72 MB/s
Average: 8957.45 MB/s
RandomMemoryBenchmark 2094.69 ms 17914.89 pts 8957.45 MB/s
Iterrations: 500000, Ratio: 2
[14] ParallelRandomMemoryBenchmark
ParallelRandomMemoryBenchmark 6251.18 ms 309787.00 pts 154893.50 MB/s
Iterrations: 500000, Ratio: 2
[15] Scimark2Benchmark
SciMark 2.0a
Composite Score: 1203.5679118222222
FFT (1024): 1744.24064
SOR (100x100): 963.477504
Monte Carlo: 178.95697066666665
Sparse matmult (N=1000, nz=5000): 1310.72
LU (100x100): 1820.4444444444443
Scimark2Benchmark 14160.70 ms 12035.68 pts 1203.57 CompositeScore
Iterrations: 0, Ratio: 10
[16] ParallelScimark2Benchmark
ParallelScimark2Benchmark 15423.60 ms 138352.40 pts 13835.24 CompositeScore
Iterrations: 0, Ratio: 10
[17] DhrystoneBenchmark
##########################################
Dhrystone Benchmark, Version 2.1 (Language: C#)
Optimization Optimised
Final values (* implementation-dependent):
Int_Glob: O.K. 5 Bool_Glob: O.K. True
Ch_1_Glob: O.K. A Ch_2_Glob: O.K. B
Arr_1_Glob[8]: O.K. 7 Arr_2_Glob8/7: O.K. 20000010
Ptr_Glob-> Ptr_Comp: * True
Discr: O.K. 0 Enum_Comp: O.K. 2
Int_Comp: O.K. 17 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Next_Ptr_Glob-> Ptr_Comp: * True same as above
Discr: O.K. 0 Enum_Comp: O.K. 1
Int_Comp: O.K. 18 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Int_1_Loc: O.K. 5 Int_2_Loc: O.K. 13
Int_3_Loc: O.K. 7 Enum_Loc: O.K. 1
Str_1_Loc: O.K. DHRYSTONE PROGRAM, 1'ST STRING
Str_2_Loc: O.K. DHRYSTONE PROGRAM, 2'ND STRING
Nanoseconds one Dhrystone run: 67.90249202145719
Dhrystones per Second: 14727000
VAX MIPS rating = 8381.900967558338
DhrystoneBenchmark 1427.43 ms 33527.60 pts 8381.90 DMIPS
Iterrations: 0, Ratio: 4
[18] ParallelDhrystoneBenchmark
ParallelDhrystoneBenchmark 3086.24 ms 371348.89 pts 92837.22 DMIPS
Iterrations: 0, Ratio: 4
[19] WhetstoneBenchmark
Double Precision C# Whetstone Benchmark
With run time input data
Calibrate
0.00 Seconds 1 Passes (x 100)
0.01 Seconds 5 Passes (x 100)
0.06 Seconds 25 Passes (x 100)
0.27 Seconds 125 Passes (x 100)
1.36 Seconds 625 Passes (x 100)
6.77 Seconds 3125 Passes (x 100)
Use 46173 passes (x 100)
Double Precision C# Whetstone Benchmark
??
Loop content Result MFLOPS MOPS Seconds
N1 doubleing point -1.12441415430186997 1557.440 0.569
N2 doubleing point -1.12239951147841022 1268.257 4.893
N3 if then else 1.00000000000000000 4187.261 1.141
N4 fixed point 12.00000000000000000 5071.976 2.868
N5 sin,cos etc. 0.49907428465337139 351.322 10.935
N6 doubleing point 0.99999988495278092 423.539 58.804
N7 assignments 3.00000000000000000 1014.650 8.410
N8 exp,sqrt etc. 0.75095530233199626 176.686 9.721
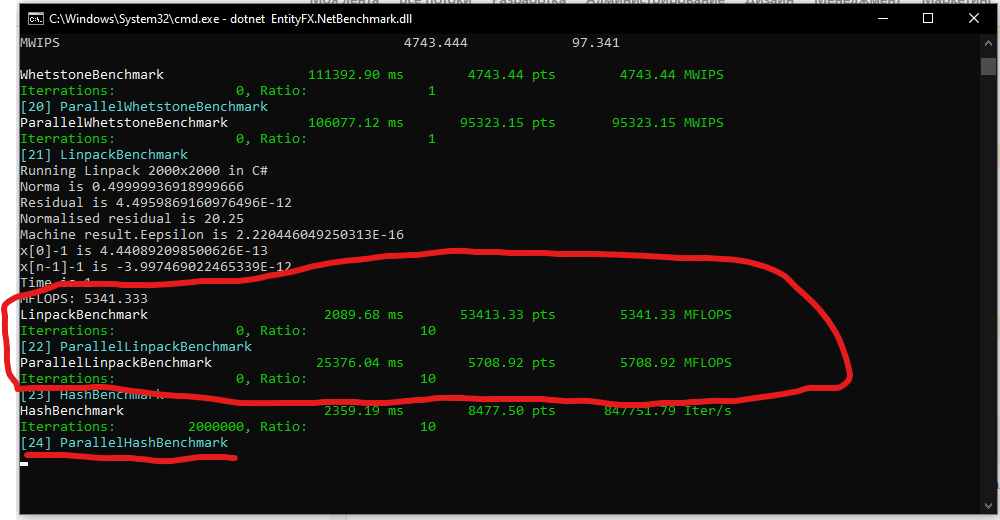
MWIPS 4743.444 97.341
WhetstoneBenchmark 111392.90 ms 4743.44 pts 4743.44 MWIPS
Iterrations: 0, Ratio: 1
[20] ParallelWhetstoneBenchmark
ParallelWhetstoneBenchmark 106077.12 ms 95323.15 pts 95323.15 MWIPS
Iterrations: 0, Ratio: 1
[21] LinpackBenchmark
Running Linpack 2000x2000 in C#
Norma is 0.49999936918999666
Residual is 4.4959869160976496E-12
Normalised residual is 20.25
Machine result.Eepsilon is 2.220446049250313E-16
x[0]-1 is 4.440892098500626E-13
x[n-1]-1 is -3.997469022465339E-12
Time is 1
MFLOPS: 5341.333
LinpackBenchmark 2089.68 ms 53413.33 pts 5341.33 MFLOPS
Iterrations: 0, Ratio: 10
[22] ParallelLinpackBenchmark
ParallelLinpackBenchmark 25376.04 ms 5708.92 pts 5708.92 MFLOPS
Iterrations: 0, Ratio: 10
[23] HashBenchmark
HashBenchmark 2359.19 ms 8477.50 pts 847751.79 Iter/s
Iterrations: 2000000, Ratio: 10
[24] ParallelHashBenchmark
ParallelHashBenchmark 2688246.77 ms 179.69 pts 743.98 Iter/s
Iterrations: 2000000, Ratio: 10
Total: 3224112.04 ms 1838542.44 pts
Single-thread results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Microsoft Windows NT 10.0.21277.0,3.1.10,24,4217970688,9989.94,10950.66,2435.90,8697.70,15566.26,22871.35,17914.89,12035.68,33527.60,4743.44,53413.33,8477.50,1838542.44,3224112.04
All results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,ParallelArithemticsBenchmark,MathBenchmark,ParallelMathBenchmark,CallBenchmark,ParallelCallBenchmark,IfElseBenchmark,ParallelIfElseBenchmark,StringManipulation,ParallelStringManipulation,MemoryBenchmark,ParallelMemoryBenchmark,RandomMemoryBenchmark,ParallelRandomMemoryBenchmark,Scimark2Benchmark,ParallelScimark2Benchmark,DhrystoneBenchmark,ParallelDhrystoneBenchmark,WhetstoneBenchmark,ParallelWhetstoneBenchmark,LinpackBenchmark,ParallelLinpackBenchmark,HashBenchmark,ParallelHashBenchmark,Total Points,Total Time (ms)
Microsoft Windows NT 10.0.21277.0;3.1.10;24,4218003456,9989.94,121888.92,10950.66,148134.91,2435.90,49416.33,8697.70,95948.53,15566.26,6948.26,22871.35,294881.19,17914.89,309787.00,12035.68,138352.40,33527.60,371348.89,4743.44,95323.15,53413.33,5708.92,8477.50,179.69,1838542.44,3224112.04
Single-thread Units results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Microsoft Windows NT 10.0.21277.0,3.1.10;24,4218007552,333018630.73,21901326.42,243589631.32,869770596.70,1556627.77,22871.35,8957.45,1203.57,8381.90,4743.44,5341.33,847751.79,1838542.44,3224112.04
Units results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,ParallelArithemticsBenchmark,MathBenchmark,ParallelMathBenchmark,CallBenchmark,ParallelCallBenchmark,IfElseBenchmark,ParallelIfElseBenchmark,StringManipulation,ParallelStringManipulation,MemoryBenchmark,ParallelMemoryBenchmark,RandomMemoryBenchmark,ParallelRandomMemoryBenchmark,Scimark2Benchmark,ParallelScimark2Benchmark,DhrystoneBenchmark,ParallelDhrystoneBenchmark,WhetstoneBenchmark,ParallelWhetstoneBenchmark,LinpackBenchmark,ParallelLinpackBenchmark,HashBenchmark,ParallelHashBenchmark,Total Points,Total Time (ms)
Microsoft Windows NT 10.0.21277.0,3.1.10,24,4218007552,333018630.73,162857846.87,21901326.42,11758992.88,243589631.32,182760401.41,869770596.70,383225484.74,1556627.77,28566.24,22871.35,294881.19,8957.45,154893.50,1203.57,13835.24,8381.90,92837.22,4743.44,95323.15,5341.33,5708.92,847751.79,743.98,1838542.44,3224112.04
Wait until completed…
Warmup
…
[1] ArithemticsBenchmark
ArithemticsBenchmark 1388 ms 6484.15 pts 216138328.53 Iters/s
Iterrations: 300000000, Ratio: 0.030
[2] MathBenchmark
MathBenchmark 47343 ms 2112.24 pts 4224489.36 Iters/s
Iterrations: 200000000, Ratio: 0.500
[3] CallBenchmark
CallBenchmark 931 ms 21482.28 pts 2148227712.14 Iters/s
Iterrations: 2000000000, Ratio: 0.010
[4] IfElseBenchmark
IfElseBenchmark 2786 ms 7178.75 pts 717875089.73 Iters/s
Iterrations: 2000000000, Ratio: 0.010
[5] StringManipulation
StringManipulation 5601 ms 8926.98 pts 892697.73 Iters/s
Iterrations: 5000000, Ratio: 10.000
[6] MemoryBenchmark
int 4k: 8189.20 MB/s
int 512k: 8381.97 MB/s
int 8M: 8306.38 MB/s
int 32M: 8116.43 MB/s
long 4k: 6240.02 MB/s
long 512k: 6289.86 MB/s
long 8M: 6431.63 MB/s
long 32M: 6226.47 MB/s
Average: 7272.75 MB/s
MemoryBenchmark 4128 ms 7272.75 pts 7272.75 MB/s
Iterrations: 500000, Ratio: 1.000
[7] RandomMemoryBenchmark
Random int 4k: 939.00 MB/s
Random int 512k: 930.00 MB/s
Random int 8M: 941.63 MB/s
Random long 4k: 943.99 MB/s
Random long 512k: 928.45 MB/s
Random long 8M: 926.66 MB/s
Average: 934.96 MB/s
RandomMemoryBenchmark 23018 ms 1869.91 pts 934.96 MB/s
Iterrations: 500000, Ratio: 2.000
[8] Scimark2Benchmark
SciMark 2.0a
Composite Score: 1410.51
FFT Mflops: 1727.83 (N=1024)
SOR Mflops: 1390.30 (100 x 100)
Monte Carlo Mflops: 236.61
Sparse matmult Mflops: 1148.75 (N=1000, nz=5000)
LU Mflops: 2549.05 (100x100):
Scimark2Benchmark 26598 ms 14105.06 pts 1410.51 CompositeScore
Iterrations: 1, Ratio: 10.000
[9] DhrystoneBenchmark
##########################################
Dhrystone Benchmark, Version 2.1 (Language: JavaScript)
Optimization Non-optimised
Final values (* implementation-dependent):
Int_Glob: O.K. 5 Bool_Glob: O.K. true
Ch_1_Glob: O.K. A Ch_2_Glob: O.K. B
Arr_1_Glob[8]: O.K. 7 Arr_2_Glob8/7: O.K. 20000010
Ptr_Glob-> Ptr_Comp: * true
Discr: O.K. 0 Enum_Comp: O.K. 2
Int_Comp: O.K. 17 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Next_Ptr_Glob-> Ptr_Comp: * true same as above
Discr: O.K. 0 Enum_Comp: O.K. 1
Int_Comp: O.K. 18 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Int_1_Loc: O.K. 5 Int_2_Loc: O.K. 13
Int_3_Loc: O.K. 7
Enum_Loc: O.K. 1
Str_1_Loc: O.K. DHRYSTONE PROGRAM, 1'ST STRING
Str_2_Loc: O.K. DHRYSTONE PROGRAM, 2'ND STRING
Nanoseconds one Dhrystone run: 282
Dhrystones per Second: 3545470
VAX MIPS rating = 2017
DhrystoneBenchmark 5641 ms 8071.65 pts 2017.91 DMIPS
Iterrations: 1, Ratio: 4.000
[10] WhetstoneBenchmark
Whetstone Benchmark JavaScript Version, Tue, 29 Dec 2020 11:42:22 GMT
1 Pass
Test Result MFLOPS MOPS millisecs
N1 floating point -1.123980363 1473.52 0.0130
N2 floating point -1.131185123 1154.64 0.1164
N3 if then else 1.000000000 1198.47 0.0864
N4 fixed point 12.000000000 3536.94 0.0891
N5 sin,cos etc. 0.499029132 232.53 0.3578
N6 floating point 0.999998881 229.53 2.3500
N7 assignments 3.000000000 779.75 0.2370
N8 exp,sqrt etc. 0.998281679 138.39 0.2688
MWIPS 2842.16 3.5184
WhetstoneBenchmark 20683 ms 2842.16 pts 2842.16 MWIPS
Iterrations: 1, Ratio: 1.000
[11] LinpackBenchmark
Running Linpack 2000x2000 in JavaScript
Norma is 0.49999936918999666
Residual is 4.4959869160976496e-12
Normalised residual is 20.25
Machine result.Eepsilon is 2.220446049250313e-16
x[0]-1 is 4.440892098500626e-13
x[n-1]-1 is -3.997469022465339e-12
Time is 3.04
MFLOPS: 1755.285
LinpackBenchmark 3374 ms 17552.85 pts 1755.29 MFLOPS
Iterrations: 1, Ratio: 10.000
[12] HashBenchmark
HashBenchmark 16343 ms 1223.77 pts 122376.55 Iters/s
Iterrations: 2000000, Ratio: 10.000
Total: 157834 ms 99122.54 pts
Single-thread results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Win32,Chrome 87,0,0,6484.15,2112.24,21482.28,7178.75,8926.98,7272.75,1869.91,14105.06,8071.65,2842.16,17552.85,1223.77,99122.54,157834
Single-thread Units results
Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms)
Win32,Chrome 87,0,0,216138328.53,4224489.36,2148227712.14,717875089.73,892697.73,7272.75,934.96,1410.51,2017.91,2842.16,1755.29,122376.55,99122.54,157834
Другие способы:
Доработка компилятора LCC.
Архитектурно-специфические доработки в самой ОС.
…
PGO Стоит еще отметить.
В недавнем посте от gaijin рассказали о почти 4x росте скорости в модуле обработки звука из-за двухфазной сборки.
www.elbrus.ru/elbrus_arch

www.notebookcheck.net/Apple-M1-Processor-Benchmarks-and-Specs.503613.0.html
kraken 1.1 min: 489, avg: 502 (меньше-лучше)
sunspider v1 86.1 ms
octane v2 avg: 62170, max: 62227 Points (больше-лучше)
При этом АМД это DDR3, а Эльбрус это DDR4 и в тестах потокового копирования Эльбрус уделывает АМД как бог черепаху: 23000 против 6500? Что не так с памятью у Эльбруса?
Так же я не понял сравнение Java, почему топовый Эльбрус медленнее предыдущего поколения почти в 3 раза, при этом вроде как Java оптимизирована под Эльбрус? Например 2 205 000 000 против 770 000 000.
Почему именно с ним сравниваете?
что бы не переходить на логарифмический масштаб в результатах сравнения…
По плавающей точке Эльбрус круто обгоняет i7, но фокус в том, что у Эльбруса используется оптимизированный под платформу код, а у i7 не используется AVX. Если для использовать i7-2600 использовать компилятор от Intel (или тонко оптимизировать код) и включить AVX, то они тоже оказываются равны (возможно Эльбрус всё же будет заметно быстрее на некоторых задачах).
Короче, да — топовый Эльбрус даже если под него заоптимизировать все программы в 2-3 раза медленнее посредственного (i7-2600 был ориентирован на планшеты, моноблоки и небольшие настольные ПК и потому никогда не был образцом производительности) Интела выпуска 2011 года. И, боюсь, ничего тут уже не поможет.
В принципе, согласен в начале 2011 i7-2600 был одним из лучших процессоров Intel для настольных ПК.
Достаточно для чего?
Для программирования чем быстрее проц — тем лучше, там нет какой-то определённой границы "вот столько вот достаточно", на которой происходили бы качественные изменения.
Это надо для графики и научных расчетов. Для бизнес приложений — нафиг.
В geekbench 5, большинство топовых смартфонов сейчас набирают больше попугаев, чем самый быстрый из эльбрусов.
Так что реально оно применимо только там, где есть попытки применять security by obscurity.
Вы пытаетесь сравнить несравнимое, да и Эльбрусы под другое заточены.
Ну как «заточены»? Они ни для чего конкретно не заточены, это по сути универсальный процессор общего назначения. Только очень дорогой и не очень быстрый.
— доступна всем (за 1.5года у очень многих появилась)
— можно применять везде (ComputeModule — в промышленном и военном секторах) — температуры и гарантированный срок выпуска в 8 лет позволяют
— вроде и open-source софт, но не совсем (вся малинка управляется закрытым кодом видеоядра);
— вроде и open-source железо, но не совсем (разводка плат есть, но клон не создадите, т.к. сам чип вам не продадут);
То тогда у Эльбруса были бы шансы. А сейчас уже и рыпаться поздно — ARM занял нишу.
Да, и не двигается оно никуда — военные в лучших традициях совка похоронили архитектуру «чтоб врагам не досталась», а госфинансирование привело к тому, что вывести это на коммерческий рынок уже просто невозможно по организационным причинам. Опять, же деньги у государства кончились.
В результате всё сводится к тому, что в 2022/23 году при оптимистичном раскладе появится дорогущий 16-ядерный Эльбрус, который будет отставать от массового сегмента более чем на порядок и по цене и по производительности (и Интел и АМД планируют у тому времени иметь 16 ядер в бюджетом сегменте). Более того, есть ощущение, что тот топовый Эльбрус он будет конкурировать уже с мобильным сегментом.
И мы получаем ситуацию, когда Эльбрус отстаёт от сравнимых конкурентов уже на два порядка. И избежать этого нельзя уже никак.
не в киберпанк же играть?
для рабочих станций норм должен быть…
сейчас разработка софта сильно отстаёт от разработки железа, скорость развития железа сильно замедлилась, я лет 5 назад даже не поверил бы, что Эльбрус может заменить терминалы в госструктуре… а сейчас мне кажется уже мог бы…
К сожалению, если вы берёте компьютер с характеристиками десятилетней давности по цене пяти современных, то через пару лет вы получаете груду бесполезного железа и напрасно потраченные деньги. Ну, и общая экономическая эффективность такого действа начинает на порядки отличаться от того, что делается в остальном мире, что тоже вносит свой вклад в общее отставание.
Экономика и ничего более.
Софт же тоже развивается, сейчас везде тулят тот же Electron, который на старом железе вообще будет еле ворочаться, да, даже тяжёлые сайты сейчас будут еле шевелиться на на старом железе. Нет, вы можете весь софт свой писать, но даже в этом случае гораздо разумнее не закапывать деньги, а потратить силы на разработку того софта под современные платформы, получить офигенный конкурентный софт, и никакое импортозамещение не нужно.
а так же я верю, что существует в экономике мультипликативный эффект, который минимум 1к5, а по некоторым оценкам 1к6-1к10…
таким образом нужно цену 325 смело делить на 5
— — — — — — — — — госсектор должен оптимизировать свой софт и развивать отечку РЭА — это смысл и обязанность государства, а вкладывать в чужую экономику — ну такое себе…
если не мотивировать собственных разработчиков, то не будет шансов даже приблизиться на одну десятую к текущему уровню производительности топов…
— — — — — — — — — три года назад нам не верили, что мы сможем разработать лучшие камеры для контроля космического пространства, сейчас наши камеры дают производительность и точность в разы лучше чем у конкурентов и десятки камер стоят на дежурстве, это я к тому, что нужно иногда доверять отечественным разработчикам железа и мотивировать их — использую изделия, давая обратную связь…
ps: я извиняюсь, просто реально хочу надеяться, что наша электроника хотя бы чутка встанет с колен…
Учитывая, что это режим режим трансляции x86 -> e2k. То в нативном у Эльбруса не так все плохо, а возможно даже и оучше. Под те задачи, которые он создан, создается и ПО под него заточенное, отличный проц. Сравнивать нужно нативные режимы, а не трансляцию, так как львиная доля производительности заложена в компиляторе.
Тот софт, что есть, даже оптимизированный, тоже никаких чудес не показывает — да, там цифры получше в плавающей точке и векторных вычислениях, но интел тестируют без AVX. А если сравнить с оптимизированным кодом для AVX/AVX2 то всё станет на свои места.
Например:
Эльбрус — 5.9 Dhrystones/MHz; i7-2600 — 6.49.
Linpack: Эльбрус — 0.84 на МГц; i7-2600 — 1.27;
CoreMark: Эльбрус — 88994.16; i7-2600 — 119670.91;
Это я на мегагерц частоты привожу, так как иначе Эльбрус начинает в разы проигрывать.
Короче, в нативном коде Эльбрус точно так же отстаёт от древнего i7-2600. И при этом Интел ещё имеет резерв в виде компиляции тестов компилятором Интел, а не GCC, если уж совсем по-честному.
И где же обещанная производительность в нативном коде?
В каком таком месте он отличный если на порядки проигрывает по всем параметрам всем текущим и будущим конкурентам категорически не понятно.
для самосвала скорость и ускорение — не самые важные характеристики
и конкурировать эльбрус ни с кем не будет в ближайшие десять лет, такой задачи тоже нет
А сейчас уже и рыпаться поздно — ARM занял нишу
Ту нишу которую занял арм, эльбрус с текущей его архитектурой занять неспособен.
Его ниша это серваки, пекарни, схд и все что занимает сегодня интел/амд.
Вообще в 2007/8м 4С был бы очень неплохой процессор и нашел бы своего потребителя, в 18/19м надо было уже выкатывать 16C. Но мцст работает на госконтракты им выгоднее делать процессоры для полок Э-S, Э-2C+, Э-1C+, Э-8CB а не продукт. Поэтому имеем что имеем.
Я не о том, в нынешнем виде эльбрус это не рыночный продукт, а "спецзаказ. изделие" и вечная институтская разработка. Даже бессмысленно говорить о каких то перспективах что то занять на рынке. Тем не менее ARM сегодня занимает ниши от Cortex-M0/3 контроллеров до A57 в телефонах, ноутбуки/серверы арм пытается штурмовать, но пока не особо видно каких то перспектив по причине отсутствия стандартизированного железа и необходимых фичь.
Речь о том что в эльбрусе слишком жирное ядро с кучей алу и устройств, и там чисто архитектурно нельзя вырезать лишнее что бы получился контроллер или маломощный встраиваемый процессор типа arm11. Технически то наверное это можно сделать но под него сразу надо будет не только код перекомпилировать но и менять оптимизации в компиляторе. Когда эту архитектуру в 90х задумывали даже АРМ еще не знал что он будет архитектурой для мобилок, его создавали так же для компьютеров. Но время шло, рынок изменился а эльбрус не особо. Так что чисто концептуально он заточен на большие компьютеры, на которых сегодня доминируют интел/амд.
Я правильно понимаю что наши хоть что-то сделали?
Имею ввиду, Intel это долгие годы разработки, огромная техническая база, а Эльбрус это выделенный бюджет + 5-10 лет разработки (или сколько там) с пустого места, и они почти сравнялись с показателями 2010 года.
Это же отлично?
Если так то у меня для эльбруса плохие новости.
а) делать что-то на отзываемой лицензии, но современное, мощное, с хорошей поддержкой, актуальнейшим софтом и т.д. С некоторым риском потерять доступ к новым версиям в случае отзыва лицензии (старые-то уже никуда не денутся), но с возможностью самостоятельно развивать имеющиеся ядра, если лицензию отзовут.
б) делать что-то самостоятельно, без шансов убрать отставание на десяток лет, с весьма ограниченными ресурсами, но зато без риска лишиться лицензии на ядро.
Притом, оба варианта с реальным риском в случае санкций потерять доступ к IP-модулям обвязки, а самое неприятное — потерять доступ к производству, ибо фабрик-то в России все равно нет и не предвидится в обозримом будущем. И отзыв лицензии в таком ключе далеко не самая большая неприятность.
А, вы про арм… так это, М1 — продукт эпла с бюджетом титаника.
Там кроме М1, который превосходит современный х86/х64, есть куда более попсовый массовый А78, который несколько недотягивает до современного х86/х64, но при этом порвёт в клочья любой Эльбрус.
Причём после лишения лицензии вычеркивайте пункт про актуальный софт — его актуальность придётся держать так же вам, как и ваше «развитие имеющегося ядра», только ещё и помощи по имеющемуся лишаетесь.
Хм. И много ли вы знаете актуального софта, который не работает на процессорах десятилетней давности?
Это вы сейчас примерно описали АМД три года назад?)
Компанию, которая даже не в лучшие годы вкладывала в R&D миллиарды долларов, имеет шестидесятилетнюю историю разработки чипов, доступ к лучшим специалистам отрасли? Нет, её я в виду не имел.
Кстати, не напомните мне, какие концептуальные проблемы вылезли у многих «современных, мощных и тэпэ» систем разной степени глубины по причине того, что они забили на безопасность?
Концептуальных — никаких не вылезло. Есть ряд теоретических, неизвестных в реальном мире уязвимостей, к тому же достаточно сложных в применении. На продажи, к слову, это вообще никак не повлияло.
Кроме того, нет никаких оснований считать, что кучи уязвимостей нет и в отечественных разработках, а единственная причина, почему о них не знают на публике — это потому что ими просто крайне мало кто пользуется.
но его организовать проще всего, если ты не китай
А какая разница для, допустим, американских законодателей, что в очередном санкционном законе написать: «запретить лицензировать процессорные ядра» или «запретить производить чипы»? В мире аж шесть контрактных производителей, которые могут выпускать 28нм-чипы, к тому же это явно не предел мечтаний, и есть желание использовать более тонкие проектные нормы, и тут рынок резко сужается аж до двух производителей — TSMC и Samsung
Так мы ядро сами улучшаем или нет, я не понял?
Вот тут я уже не понял. Улучшение ядра обязательно как-то должно ломать совместимость, что ли? Зачем? Ничто не мешает улучшать ядро, не занимаясь подобным мазохизмом.
Угу, сейчас появился. Теперь надо доказать, что его могут продать для всяких серверов и суперкомпов для расчёта ядерных взрывов или там для военных.
Хм. А что мешает продать его независимому чипмейкеру, не входящему в оборонную промышленность? Ну т.е. так, как поступают во всём мире? А оборонщики покупают свои чипы уже у дистрибьютора.
Вообще-то, вполне себе доказанных. И проблема была в концепции. Настолько, что интел вплоть до отключения HT предлагал как решение, потому что пофиксить не мог.
И тем не менее, когда хайп/паника улеглась, практически все обошлись без этих патчей, и никто не стал жертвовать производительностью ради мифической угрозы.
Ну вот нидерланды пришлось давить через политические рычаги, чтоб те китайцам не продали новую линию.
Разница наглядна?
Не очень. Государство Нидерланды не производит и не продаёт степперы. Степперы производит и продаёт коммерческая компания ASML, которая, к слову, в значительной мере американская. Давить на неё через политические рычаги… ну, очевидно, данный бизнес достаточно ценен во всём мире, чтобы с ним подобные вопросы решать более тонко, нежели тупо рубить топором санкций. С российскими компаниями никто так церемониться не будет.
14 нм и китайцев, кстати, тоже есть.
Эти шесть упомянутых мной производителей — это включая китайцев. 14нм — это не панацея, а временная передышка. Математика такова, что технологически компания, использующая более тонкий процесс, всегда будет иметь хорошую фору по потенциальному быстродействию и энергоэффективности.
б) Эльбрус + 10-ток других оригинальных архитектур +новомодные компании с RISC-V архитектурой
Я за все варианты вместе взятые. Особенно когда все это не за деньги налогоплательщиков.
И под это «не понятно что» напоминаю, никто софт писать не будет, никогда.
И под это «не понятно что» напоминаю, никто софт писать не будет, никогда.
Если производительности непонятно чего хватит для пользовательских задач на рабочих станциях в госке ( разумеется мы говорим не про высокопроизводительные сервера и/или игры в киберпанк) к чему, как видно по бенчам, ситуация уже приближается. А также если решением свыше будет принят перевод госки на непонятно что — то софтописатели (по крайней мере отечественные) в очередь выстроятся для запрыгивая на поезд продаж своего софта в этот сектор.
Емнип, несколько лет назад, когда e2k еще нельзя было просто купить в магазине, мсцт через бюрократизм нда и прочих согласований, давал удаленно пощупать платформу. Ну и в множестве /home/$ были определенные пересечения с множеством habr.com/ru/users/$ — лично видел xD
5-10 лет разработки (или сколько там) с пустого места
15-20 лет разработки, если быть точнее. А система команд и высокоуровневая архитектура уже более 40 лет развивается. Так что не совсем с пустого места, строго говоря.
Будем ждать нативного NetCore для e2k.
От кого?
mcst.ru/elbrus_prog
Здесь можно посмотреть про систему команд и описание архитектуры.
Новогодние бенчмарки компьютеров Эльбрус
Core i7 2600 — 32 нанометра
Эльбрус 8СВ — 28 нанометров.
Получается что VLIW архитектура не может компенсировать отставание по техпроцессу, процессор получился все таки медленным.
Или софт еще очень недоделан.
Причина медленности — второе. Вот нужно было — улучшили PHP и Java. Браузерный JS сделали. Сам проц любит компилируемые языки, которые положат заранее во VLIW оптимально. Вот на 2С3/12С/16С должно быть гораздо быстрее с их 2 ГГц.
salsa.debian.org/benchmarksgame-team/benchmarksgame
Особенно полезно было бы для сравнения производительности разных языков, так как бенчмарки там годами допиливаются с точки зрения оптимизаций, есть обвязка, рисующая красивые и понятные графики и показывающая насколько какой компилятор работает медленее или быстрее (а также с измерением потребления ресурсов). Возможно между железом не самый оптимальный набор софта, но с точки зрения исследования производительности java vs c vs c++ vs php vs python будет более показательно, как мне кажется.
Как я уже сказал выше, он разивается достаточно давно и специально заточен под сравнение различных компиляторов (там множество тестов и их тщательно оптимизируют для каждого из тестируемых компиляторов). Кажется что это была бы более интересная и показательная синтетика даже для сравнения различных процессоров.
Посмотрим как в будущем будут себя показывать, пока есть куда стремиться
В своем блоге я предложил создать облако Elbrus 16C, такое как Amazon AWS или Microsoft Azure, чтобы оно стало техническим и коммерческим успехом.
sovecomo.wordpress.com/2021/01/05/временные-рамки-возможного-облака-эл
А про то, чтобы крупные российские компании туда захотели переносить что-то — это вообще невыполнимая задача, потому что им это никоим образом не интересно по-умолчанию. Чтобы стало интересно надо из списка исключить тех, у кого свои ДЦ и десятилетия опыта содержания своей инфраструктуры и дополнительно сделать это выгодным для них (что отдельная сложная задача и напрямую упирается в соотношение цена/производительность железа).
p.s. и я не уверен что Ваша оценка в цене датацентра верна.
чтобы сделать платформу удобной, стабильной, быстрой и надежной…
… и конкурентоспособной по соотношению «цена/возможности» с другими решениями.
Это не говоря уже о том, что облако должно быть не просто «большим», а «большим и при этом его мощности должны быть максимально сданы в аренду клиентам». Без второго условия ваше правило становится с ног на голову — чем облако больше, тем дороже для пользователя.
потому что есть более крупные где-то еще…
Бизнес обычно пытается предоставить что-то, что нужно рынку. В данном случаи должен быть ответ на вопрос «что бизнес может дать?» (он же «зачем?»)
Облако Эльбруса было бы в основном для России
Сейчас в России, если не ошибаюсь, несколько десятков облачных (или SaaS) провайдеров. Именно тех, которые держат российские компании.
а не для Запада, они бы этого не допустили…
Кто они? Чего бы не допустили? Не очень понятно, если честно.
Если Вы про Эльбрус на запад предоставлять — да я думаю МЦСТ не против, только не нужно.
Если наоборот, про облачного провайдера из России на запад — так собственно для западных компаний, когда они хотят соблюдать российские законы о ПД, это один из выборов сейчас. Конечно хороший вопрос сколько компаний используют облака, сколько держат свое, а сколько ничего не делают, но это уже отдельный вопрос.
1. Ваша оценка стоимости ничем не обоснована, так как стоимость 1 датацентра не публикуется, а также зависит от кучи параметров типа местности, желаемых характеристик датацентра и так далее и тому подобного. Вообще правильным подходом было бы прикинуть размеры (в серверах), прикинуть какая надежность нужна и посмотреть сколько за постройку такого просят те же компании в России, которые на этом специализируются (таковые есть). Но с этого момента у Вас хотя бы будет примерное понимание необходимой площади и хотя бы можно будет прикинуть сколько будет стоить построить здание и обеспечить его генераторами. Тут стоит не забыть, что далеко не в любой точке есть оптика, а если есть оптика то от нескольких независимых операторов, а если иесть то оператор может предоставить нужной ширины канал. Не везде можно найти несколько независимых поставщиков электроэнергии, не везде можно построить здание нужных размеров, не везде будет дешево его охлаждать. Короче много очень специфических тонкостей, которые очень сильно сузят круг доступных мест и повлияют на итоговую цену. И мы еще не трогаем процесс рассчета сети и требований к сети у ЦОДов облаков (советую посмотреть что найдете из публичного про это).
2. В современном мире, от гипервизора ожидаются низкие накладные расходы, то есть поддержка аппаратной виртуализации обязательна, а в Эльбрусах она заявлена только в 16С. Так что о «облаке» на 4С можно забыть
3. Попробуйте прикинуть стоимость услуг. Она будет зависеть и от расходов (электричество на питание и охлаждение это мягко говоря основные расходы датацентра) и от плотности размещения железа (сколько вы сможете предоставить условных виртуальных машин без оверселлинга по цпу и оперативной памяти, сколько диска сможете предоставить и так далее). И не забудьте, что сделать хранилище на 1 ПБ недостаточно, нужно еще уметь отдавать трафик (пропускная способность, ее требования для CDN отличаются от требований для SAN), шифровать его и т.п.
4. Уточните как Netflix, Dropbox и Spotify используют облака. Они не очень многословны, но говорят достаточно много о своей инфраструктуре. У Вас сейчас неверное понимание паттернов использования (например Dropbox еще в рамках IPO своего описывал как они увозили хранилища с амазона и почему)
5. Вы немного недооцениваете паттерн использования облак «как хранилища». У них вышло потому что они для себя уже решили задачу как быстро и надежно отдавать контент близко к пользователю (охват того же CDN от амазона начинался с нескольких датацентров на каждом континенте, то же и у других). Иначе — в чем преимущество решения из двух датацентров где-то в России? Кому они сделают лучше и как?
6. Собственно вытекает из (5). Основной пункт который продавал облака их первым клиентам — они делали жизнь другим компаниям проще. Например больше не надо было делать свой CDN или платить компаниям, на нем специализирующимся (которые тоже не всех устраивали по ряду причин), если тебе понадобилась виртуалочка в США, Европе и Австралии для твоих клиентов — один клик и через пару минут она готова. То есть это в первую очередь сервис, который решает реальные проблемы.
7. Вытекающий из (6). Недостаточно построить датацентр, нужно еще сделать софт, котоырй клиенты будут использовать (API, веб-интерфейсы, интеграция с имеющимися штуками типа Terraform'а).
8. Касательно тех у кого есть ЦОД — чтобы подтолкнуть их рыночным способом (особенно крупняк, на который Вы почему-то целитесь в первую очередь) Вам надо предложить им что-то что они не могут за разумное время сделать самостоятельно. А тут проблема в том, что как раз крупняку, который Вы перечислили, арендовать чужие облака вот совсем не интересно и никаким образом интересно не станет (единственный способ — скупить все Эльбрусы на годы вперед и протолкнуть закон, обязывающий комерческие организации использовать Эльбрусы для чего нибудь, и что-то мне подсказывает что такое решение будет нарушать несколько законов РФ).
Это очень кратко и без особых деталей я бы сказал.
Я все еще верю, что это нужно сделать, это нужно начать…
Главный момент того, о чем я написал это целесообразность. Такое облако, чтобы в него ехали, должно предоставлять что-то, что не предоставляют другие (сейчас российских облаков уже хватает, войти на рынок будет не так просто даже со стандартными предложениями).
Вообще у любого бизнеса или инициативы должен быть четкий ответ на вопрос «зачем?».
ладно, если у нынешнего 8С Эльбрус нет виртуализации, то виртуальную машину можно продать на физическом выделенном процессоре
Это уже не виртуальная машниа будет. Но, допустим, ок. Какая цена будет у такого решения, ориентировочно?
Вот только, где возможно посидеть за Эльбрусом?
Есть какой-нибудь процессор, доступный для физических лиц?

Сейчас процесс получения доступа упростился: генерируете SSH-ключ у себя на компьютере, отправляете его публичный ключ (именно публичный, не приватный) через форму на веб-странице, и затем получаете оповещение с результатом в Телеге, которую вы оставили в форме на той же странице.
http://elbrus.6te.net/
Новогодние бенчмарки компьютеров Эльбрус