Индексы в PostgreSQL — 3
9 мин
В первой статье мы рассмотрели механизм индексирования PostgreSQL, во второй — интерфейс методов доступа, и теперь готовы к разговору о конкретных типах индексов. Начнем с хеш-индекса.
Hash
Устройство
Общая теория
Многие современные языки программирования включают хеш-таблицы в качестве базового типа данных. Внешне это выглядит, как обычный массив, но в качестве индекса используется не целое число, а любой тип данных (например, строка). Хеш-индекс в PostgreSQL устроен похожим образом. Как это работает?
Как правило, типы данных имеют очень большие диапазоны допустимых значений: сколько различных строк можно теоретически представить в столбце типа text? В то же время, сколько разных значений реально хранится в текстовом столбце какой-нибудь таблицы? Обычно не так много.
Идея хеширования состоит в том, чтобы значению любого типа данных сопоставить некоторое небольшое число (от 0 до N−1, всего N значений). Такое сопоставление называют хеш-функцией. Полученное число можно использовать как индекс обычного массива, куда и складывать ссылки на строки таблицы (TID). Элементы такого массива называют корзинами хеш-таблицы — в одной корзине могут лежать несколько TID-ов, если одно и то же проиндексированное значение встречается в разных строках.
Хеш-функция тем лучше, чем равномернее она распределяет исходные значения по корзинам. Но даже хорошая функция будет иногда давать одинаковый результат для разных входных значений — это называется коллизией. Так что в одной корзине могут оказаться TID-ы, соответствующие разным ключам, и поэтому полученные из индекса TID-ы необходимо перепроверять.
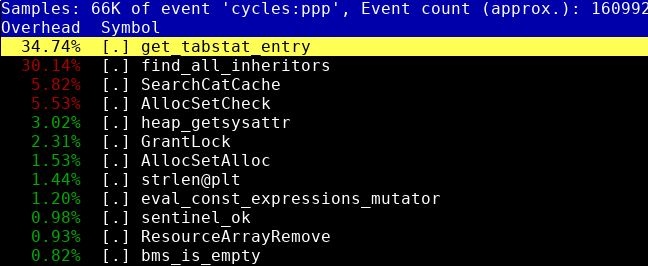




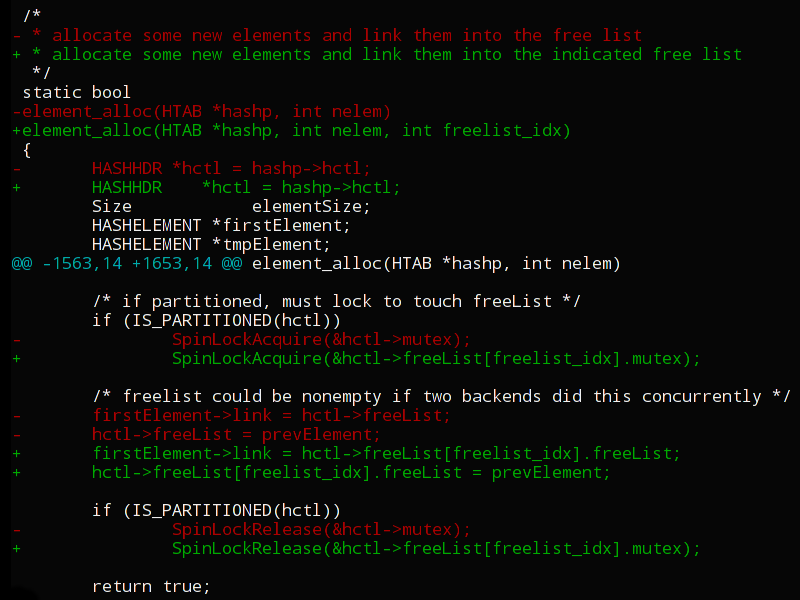

 В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.
В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.