Комментарии 44
А порядок этих советов какой? Внезапный переход от выбора языка к табуляции в строковых литералах... Вызывает легкую оторпь
Нумерация советов не с 0. И за границы массива вышли в 61м :)
Очередная статья с очевидными советами из "Чистый код" и методологии эффективной и "правильной" разработки? Когда же уже люди напишут одну идеальную статью и будут пересылать её всем и вся? Математику же не объясняют каждые два года с нуля, потому что предыдущую объясняющую статью долго искать.
А по делу: если в языках программирования, современных технологиях, движках, методологиях, паттернах и практиках столько проблем и спорных моментов, то не повод ли это критически переосмыслить, выявить проблемы и решить их, а не давать советы "ты сюда не ходи, ты туда ходи..."? Раз многие советы для многих ЯП повторяются, то может их захардкодить в каких-то высокоуровневых статических анализаторах, которые имеют внутренние плагины трансляции этих правил в специфичные для каждого языка? Как сделали С относительно Ассемблера, который упростил огромное кол-во операций. А ещё лучше сделать автогенераторы* (даже алгоритмические, не нейросетевые) необходимого кода и правильного интерфейса с учётом этих "правил"? А ещё лучше сделать генератор всего кода и нужно лишь настраивать нюансы. Большинство же интерфейсов/классов/типов однотипные, их достаточно легко абстрагировать и можно генерировать через конфигуратор, а не писать заново код, заново тестировать, заново дебажить... Да и для шаблонов проектирования как будто бы уже давно нужно было бы сделать фреймворк, а не каждый раз реализовывать заново. Или я чего-то не знаю? Или это такой сговор айтишников, чтобы продолжать писать один и тот же код раз за разом? Вы сами-то не устали?
Следующим шагом было бы создание универсального автоматического тестировщика и аналитика, который следил бы за состоянием уже работающих машин сам и маячил бы, когда что-то не так. А аналитик отгружал бы аналитику в нужной форме. Почему до сих пор выпускают статьи как это всё писать кодом, а не настраивать - не понимаю. Может мне кто-то объяснить из старших/опытных? (у меня три года опыт работы, и тот в весьма специфичных кейсах).
* - генерировать (а не интерпретировать) для эффективности и оптимизаций на местах использования + переносимость и ручное допиливание. Хотя для JIT можно и конфигуратором для интерпретатора оставлять, если JIT умеет оптимизировать и такое.
Как Вы думаете, что на Хабре делает статья Директора по маркетингу компании, которая делает статический анализатор для C,C++,C#,Java? :)
И весьма недурной анализатор, надо сказать.
Пиарит анализатор статьями о работе анализатора и показывающими (по задумке) их компетентность в этих технологиях.
Анализатор уже возникших типичных ошибок или предупреждение о тех, которые могут случиться.
Я призываю избавляться от причин возникновения таких ошибок, а не устранять последствия.
Например: говорят "хороших программистов не хватает", стараются увеличить их количество. Но может стоит развернуть мышление в сторону уменьшения необходимости писать много сложного (и не очень) кода, а не в ускорение написания/этого кода (например за счёт уменьшения времени расследования ошибок)?..
То же и про ошибки: если кода будет меньше и он будет строже организован, то ошибок в нём потенциально будет меньше.
Вы таки хотите сказать, что можно выстроить работу людей так, чтобы они никогда не ошибались?
На минутку, разработка ПО - это манипулирование сложной ментальной моделью, ограниченными мощностями нашего мозга, да и ещё детали ментальной модели разные? А ведь любая деталь имеет значение. И если она выпадает - то это путь для возникновения ошибки.
Скажите, Вы свой код хотя бы недельной давности когда-нибудь читали? Вы уверены, что всегда понимаете то, что неделю назад хотели этим кодом сказать?
Анализаторы хороши уже тем, что рутинизируют тривиальные, но почему-то распространённые ошибки. И позволяют выявлять ошибочные паттерны. Путь развития статического анализа - это выявление всё более сложных ошибок, их формализация и формирование базы, которая позволит подобные ошибки выявлять у других разработчиков, делая мир лучше. Ну да, за деньги, ок. Если хорошо делают, то имеют право иметь свой хлеб с маслом и даже с икрой, если будут те, кто платит.
(Тут подумалось, что задачи очень схожие с формированием вирусной базы для антивирусов).
И да, в действительно крупных конторах при разработке софта требуется использовать статический анализ, и рекомендуется использовать как минимум два разных статических анализатора. Речь про Boeing, NASA, ESA и многие другие.
Используйте странные числа. Так ваша программа будет выглядеть умнее и солиднее. Согласитесь, что такие строки смотрятся хардкорно: qw = ty / 65 — 29 * s;Никогда не понимал этих рекомендаций. Получается, что любые числа без привязки к символьным псевдонимам — странные? Как нужно правильно переписать эту формулу? Не уверен, что так лучше:
const int sixtyfive = 65;
const int twentynine = 29;
qw = ty/sixtyfive - twentynine * s;Я понимаю конечно, что имелось в виду что-то типа
средняя_продолжительность_жизни_у_мужчин_опасных_профессий=65;twentynine = 29sqrt_of_pi=1.7724538509055160273Что такое sqrt_of_pi я понимаю, а что такое twentynine не очень. Почему 29, а не 30, например?
А почему именно корень из пи, а не логарифм от шести вы тоже понимаете?
Я понимаю, что автор использовал именно корень от пи, а не что-то другое. -1 шаг на то, чтобы разобраться как работает формула.
Вообще, я согласен, что бывают случаи, когда не нужны именованные переменные. Обычно, это формулы, из других источников. Например конвертация цветов из RGB в HSV не требует объяснения, что это за переменные, но требует ссылки на то место, откуда они взялись. Я сам писал классификатор роста, которые превращал рост в "низкий", "средний" и "высокий" на верхней и нижней границы среднего роста. Константы были получены от заказчика и забиты в код как есть, без названий типа "верхняя граница низкого роста", т.к. из кода было всё очевидно.
В то же время, я против потери информации. Если использовали формулу из внешнего источника - добавь ссылку в комментарии. Если подобрал коэффициенты и хз почему они работают - добавь комментарий. Если коэффициентами в формуле можно поиграть - занеси их в константы, будет как конфиг. Если число из предметной области, назови его, облегчи труд идущего следом.
А за константы вида twentynine, нужно заворачивать ПР, ибо они не добавляют ничего кроме шума.
По-хорошему, в такой ситуации и qw должен быть некой осмысленной переменной в противном случае выдуманные формулы ведут к выдуманным проблемам.
Это уже другой вопрос. (Предположительно) qw может хранить промежуточное значение, которое используется для переменных q и w. А названия q и w выбраны такими потому, потому что именно так они назывались в первоисточнике.
Вредный совет N14. double == doubleА здесь интересно, что на этот вредный совет вы дали ещё более вредную альтернативу. Потому что погрешность вычислений вовсе не обязательно будет укладываться в DBL_EPSILON, и в вашем примере внезапно тоже.
Притензия непонятна. Там сказано, что погрешность может быть большой или малой. И даны отсылки. Предложите свой вариант правильного подхода. :)
Претензия в том, что описанное решение не решает проблему, а только усугубляет её, создавая иллюзию того, что проблема решена. В вашем примере разница между 0.49999999999999994 и 0.5 очевидно большем DBL_EPSILON. Более того, заранее эту погрешность предсказать невозможно, потому что она будет зависеть от множества факторов, и чтобы контролировать погрешность этот контроль нужно вводить в вычисления явным образом. Кроме того, если в коде написано double x=0.5 не факт, что значение x будет точно 0.5 — оно может измениться в процессе парсинга.
А правильных подходов тут даже несколько.
1) сравнивание double с константой вполне корректная операция, если программист точно знает, что он делает. Но дробные константы для double нужно вводить только через битовое представление или int8;
2) использовать тип decimal,
3) приводить сначала к целочисленному типу а только потом сравнивать. Не if(x==0.5) и не if(abs(x-0.5)<eps) а if((int)(10*x)==5)
В третьем варианте Вы допустили ошибку.
Тем, что явно тип округления не прописал? Согласен, недочёт.
Размер указателя и int — это всегда 4 байта. Смело используйте это число. Число 4 смотрится намного изящнее, чем корявое выражение с оператором sizeof.А ещё можно явно писать int4/int8/etc. А для указателя использовать тип «указатель», который можно переопределить глобально.
Вообще складывается ощущение, что большинство антипаттернов — это проблемы языка, а не программиста, там практически каждый можно оспорить с контр-аргументом.
Плохо, когда начинают использовать этот язык только потому, что это "круто"
Забавно, что есть организации, которые до сих пор показывают промо кандидатам, которых они нанимают, как они с гордостью произносят "мы используем си плас плас"
вы столкнётесь с эффектом "разбитых окон".
Это кстати поясняет, почему у яблок настолько плохой код. Xcode практически невозможно отучить ругаться не по делу. Поэтому пол проекта будет светить жёлтым.
Вы же не против пообщаться о паттернах? Решение
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) ||
((ch >= 0x0FF21) && (ch <= 0x0FF3A)) ||
((ch >= 0x0FF41) && (ch <= 0x0FF5A)))плохо вне зависимости от того, записано оно в столбик или строчку. Правильное решение — ввести дополнительный слой абстракции в виде нового класса с методами bool in_range(a,b) и bool out_of_range(a,b), тогда эти кучи проверок в одном if будут намного более читабельны.
а класс то вам зачем...
Потому что это си++, а не си. ООП парадигма. Чтобы проверку вхождения в диапазон вызывать как метод. А математические операции, которые не имеют смысла, не реализовывать. Тогда не получится ошибиться, складывая километры с помидорами из-за опечатки в названии переменной (ну типа seed вместо speed), потому что из-за разных типов компилятор обругается.
О нет, только не класс! Про это будет в "Вредный совет N56. Больше классов!".
Вы же даже не знаете исходной задачи, а уже готовы предложить "правильное решение" и налепить классов.
Конечно, есть же boost!
О! Моё воспалённое сознание предлагает сделать класс с адекватным именем, который в конструкторе получает искомый синтаксис, и вычисляет принадлежность к некоторому классу символов (непереводимая игра слов) внутри operator bool()
Хочу послушать за адекватное имя для проверки вхождения числа в указанные диапазоны. открытые, закрытые, полуоткрытые. А потом в объединение диапазонов. И пересечение. Мы еще про константные диапазоны и переменные поговорим, конечно же.
Буде оно так нужно, был бы ворох библиотек для такой радости -- однако вместо этого ворох местных и местячковых вариантов in_range, где на одной странице с и без проверки вхождения правой границы:
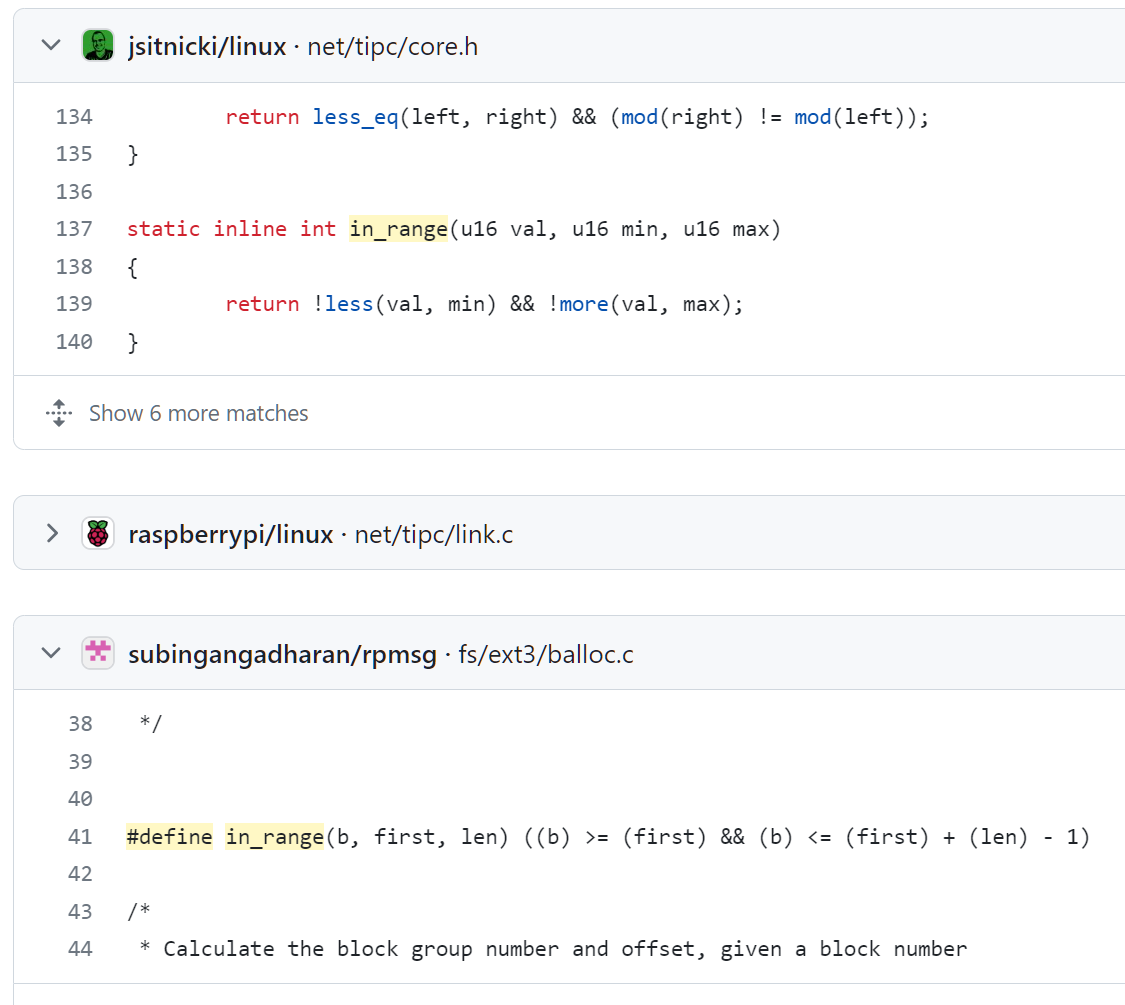
Буде оно так нужно, был бы ворох библиотек для такой радости — однако вместо этого ворох местных и местячковых вариантовИспользование #define для определения функции выдаёт си-программиста с головой. Понятно, что им сложно в ООП стиле мыслить.
Хочу послушать за адекватное имя для проверки вхождения числа в указанные диапазоныМожно и без имён обойтись, через перегрузку операторов сравнения. На шарпе мне потребовалось 3 класса, чтобы такая конструкция компилировалась:
IntE x = 12;
if ((3 <= x < 7) | (11 < x <= 13))
{
...
}Согласен, выглядит красиво (надеюсь, | это опечатка а не требование использовать | вместо ||).
минусов вижу два -- x таки не просто число, и обеспечить бесшовность для смесей с разными комбинациями (одно сравнение и несколько сравнений) в одном выражении надо постараться. Плюс, неопределённость "x <= 3" это bool или что -- обычно плохо.
Красивым мне кажется решение когда можно "x in [3...7)" записать.
Real barycentric_rational_imp<Real>::operator()(Real x) const
{
...
if (x == m_x[i])
{
return m_y[i];
}
...
}А рядом подробный комментарий,
60 антипаттернов для С++ программиста, часть 1 (совет 1 — 5)