
В процессе улучшения подходов к менеджменту зависимостей компонентов нашей Операционной Системы появилась необходимость перейти от монолитной статической сборочной системы на основе CI/CD инструментов к динамическому распределённому подходу с порождением сотен и тысяч автономных задач. Как выяснилось в процессе, это не самый радужный сценарий использования систем автоматизации, но вполне достижимый.
В результате был спроектирован и внедрён динамический сборочный конвейер на базе Jenkins, масштабируемый как горизонтально, так и вертикально. В статье расскажем как он устроен, решение каких проблем потребовало адресной оптимизации по скорости выполнения, и какие подводные камни повсплывали.
Также частично раскроем информацию о том, как мы выполняем распределённую сборку дистрибутивов.
Ожидается много текста и примеров кода.
Введение: отправная точка
К моменту постановки задачи основной сборочный конвейер дистрибутива опирался на Jenkins в качестве среды автоматизации, Docker с развернутыми средствами разработки для воспроизводства эталонного сборочного окружения и Gitea в роли системы управления исходным кодом. Кроме того, использовался ряд дополнительных инструментов для тестирования, управления дефектами, project-management и пр.
Основным камнем преткновения являлась централизованная иерархия ключевых репозиториев, составляющих дистрибутив, выполненная по принципу мета-репов с подключением сабмодулей. Если на уровне подсистем и отдельных команд разработчиков такой подход ещё выдерживает критику, то на этапе объединения в единое окружение все телодвижения команд упираются в необходимость предложения правок в мета-репозитории мейнтейнеров. С одной стороны, это существенно ограничивает свободу действий мейнтейнеров при работе над собственными инфраструктурными прожектами. С другой, никак не связанные с ними разработчики также должны отслеживать чужую кухню и блокировать свои работы до апрува правок в сборочные репы. Автоматизации эта проблема подлежит весьма условно и время от времени дает сбои. Основная цель в этом случае — разграничение объектов контроля и минимизация дедлоков/простоев.
Стоит ли упоминать, что и контроль зависимостей в таком ключе является неоправданно сложным квестом?
Вторая проблема, частично являющаяся следствием первой — невозможность полноценного распараллеливания сборки по сборочным серверам. Монолитность иерархии приводит как к необходимости ручного распределения (хоть и однократно, но в крайне ограниченном объеме) сборочных заданий по имеющимся серверам, так и невозможности в произвольный момент времени радикально нарастить перечень серверов.
За годы, и уже десятилетия борьбы, в том числе и с этими проблемами, мы неоднократно проходили стадию
Щас купим новый трушный сервер и тогда заживём
Новый сервер можно и нужно покупать, но это не отменяет перманентной потребности в расширении вычислительных мощностей. Регулярно появляются новые задачи и необходимость выполнения отдельных сборок с уникальными параметрами. Навскидку:
- Инженерные nightly билды
- Релизные билды с учетом специфичных требований различных систем сертификации
- Контрольные дебаг-билды и билды с code-coverage
- Отдельные контрольные билды в рамках концепции безопасной разработки
- Поддержка нескольких дистрибутивов с разными конфигурациями и адресным применением вышеперечисленных опций
В условиях наличия обширного пласта регулярно простаивающих высокопроизводительных машин разработчиков, вертикальное масштабирование сборочных мощностей в ущерб горизонтальному не выглядит как достаточное условие, хотя и необходимое. А во время подготовки и стабилизации релиза «жаба» начинает капитально душить, и сборки, в идеале, хотелось бы видеть каждый час и даже быстрее.
Нельзя сказать, что действовавший сборочный пайплайн был плох. За последние 6 мажорных релизов осечек он не давал. Но с какого-то момента накопленные требования и общее повышение зрелости процессов разработки привели к утрате целесообразности дальнейшего вложения ресурсов в поддержку «status quo».
Построение графа зависимостей
Первым шагом отказались от мета-репозиториев мейнтейнеров. В каждый сборочный репозиторий, представляющий самостоятельный объект сборки, был добавлен дескриптор для используемой пакетной системы. Это позволяет командам хранить свои игрушки прямо в собственных репах и решать все свои вопросы в пределах атомарного PR без привлечения внешних для команды специалистов.
Для разработчиков задача существенно упростилась. А вот мейнтейнеры лишились основного инструмента. На замену пришлось запилить отдельный конвейер, выполняющий построение сборочной иерархии в виде дерева зависимостей.
Начали со скрипта обхода репозиториев через HTTP API. Он выполняет обход всех доступных пользователю (от имени которого выполняется скрипт с правами RO) репозиториев на сервере и производит извлечение дескрипторов. Пример кода получения результатов выполнения поддерживаемых запросов под спойлером:
import json
import requests
from requests.adapters import HTTPAdapter, Retry
def http_api_request( url, max_pages, params = '' ):
jsons = []
token = {'content-type': 'application/json',
'accept': 'application/json',
'Authorization': 'token xxxxxxxxxxxxxxxxxxxxxxxxx...'}
session = requests.Session()
retries = Retry( total = 5, backoff_factor = 0.5,
status_forcelist = [500, 502, 503, 504] )
session.mount( 'http://', HTTPAdapter( max_retries=retries ) )
try:
page = 0
while ( True ):
reply = session.get( url + '?limit=100&page=' +
str( page + 1 ) + params,
headers = token )
json_ = reply.json()
if (json_ == None) or (len( json_ ) == 0):
break
else:
jsons.append( json_ )
if (max_pages != 0) and (page + 1 >= max_pages):
break
page += 1
except Exception as e:
print( 'Error: failed on "' + url + '" (message: "' +
str( e ) + '")' )
exit( 1 )
return jsonsТипичные дескрипторы обычно содержат ссылку на скачиваемый репозиторий и соответствующий коммит. Таким образом, завершённый набор файлов-дескрипторов полностью определяет билд дистрибутива. Это достаточно удобно для хранения вместо набора бинарей или архивов, особенно для промежуточных билдов.
Для построения и анализа самого графа использовали networkx. Выбор обусловлен поддержкой формата .dot, в котором хранит графы проект Graphviz, используемый в дальнейшем для визуализации.
Поиск некоторых аномалий в зависимостях:
- Отсутствие циклов на графе. Наличие хотя бы одного цикла в нашем случае является ошибкой:
import networkx as nx
...
graph = nx.DiGraph( nx.nx_pydot.read_dot( fname ) )
cycles = nx.simple_cycles( graph )
cycle = ''
for nodes in cycles:
for node in nodes:
cycle += '"' + node + '" → '
cycle += '"' + nodes[0] + '"'
break
return cycle- Поиск изолированных вершин. Наличие вершин без пред-/пост- зависимостей в нашем случае является ошибкой:
nodes = ''
for node in graph.nodes():
if graph.degree( node ) == 0:
nodes += node
return nodesСкрипт контролирует и другие аномалии, связанные уже с особенностями пакетного менеджера. Оформлено всё это «хозяйство» в виде автономной задачи в Jenkins, чтобы разработчики в любой команде могли убедиться, что их репозитории включены в дистрибутив непротиворечивым образом.
Результирующий граф «нарезается по слоям», что определяет очерёдность сборки. Множество дескрипторов некоторого «слоя» мощностью M, совместно с тиражированием каждого дескриптора по N поддерживаемым процессорным архитектурам, составляет полный объем потенциально распараллеливаемых сборочных задач M x N на слой. Как разработчикам, так и мейнтейнерам предоставляется сгенерированная тут же простейшая «веб-морда», чтобы визуально посмотреть что они включили в билд, на каком этапе собирается интересующий компонент, правильно ли расставлены зависимости и т.п. Кроме того, формируется слепок вторичных дескрипторов (по архитектурам) и файл с их распределением по слоям для последующей стадии конвейера — сборки.
Тестовый набор пакетов для собственных экспериментов мейнтейнеров на раннем этапе внедрения распределённой системы сборки (каждый дескриптор может продуцировать несколько пакетов, например, *-dev и *-runtime):
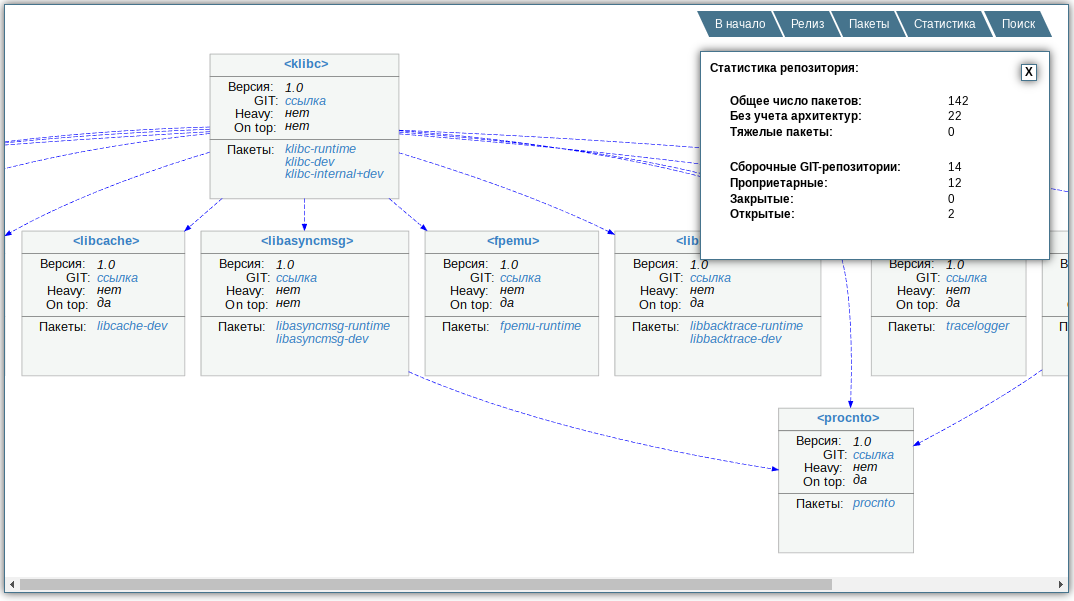
На всё про всё, с учетом обхода 500+ репов в один поток, выполнения анализа и генерации выходных материалов, уходит чуть меньше двух минут, поскольку ещё на берегу сформировали договоренности о точном именовании дескрипторов и их расположении в репозиториях. Так при обходе не нужно парсить все иерархии исходников.
С визуализацией графа капитально помогает Graphviz, поскольку умеет рисовать в SVG. Ну а подпатчить его руками и добавить ссылки — дело не хитрое >}.
Поиск сделали по-простому — распарсили в отдельный .js контент страниц с описанием пакетов и подгрузили его на все страницы:
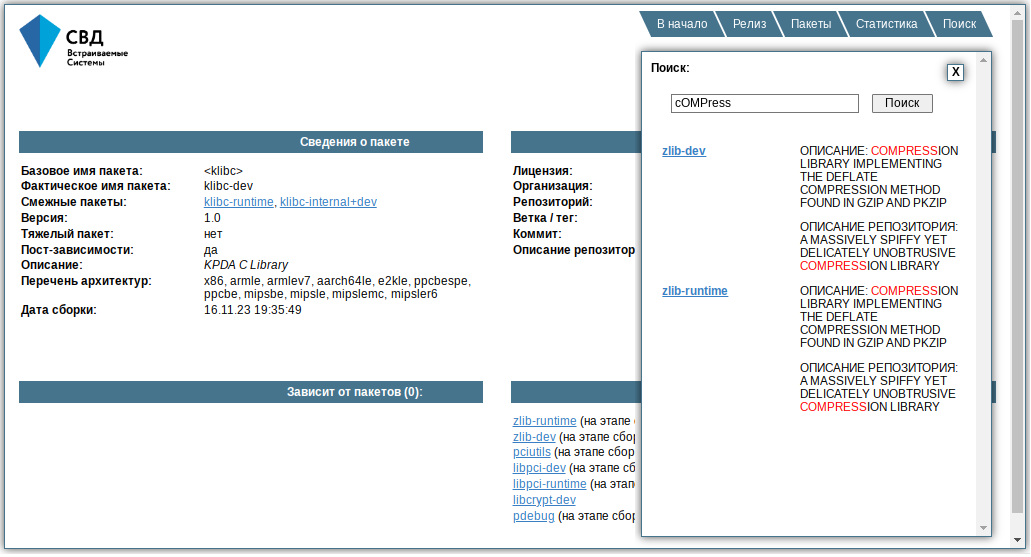
Масштабирование серверов
Сразу отмечу, что автор не является разработчиком на Java или DevOps-инженером. На всё это «хозяйство» пришлось смотреть с опытом системного программиста. Какие-то замечания, безусловно, будут обоснованы, как и упрёки в невладении сакральным знанием. Однако, анализ ряда архитектурных решений Jenkins, а также производных от них ограничений, и сейчас, постфактум, вызывает выгорание окружающего пространства в радиусе нескольких парсеков. Данный нюанс не отменяет того обстоятельства, что цель в итоге успешно достигнута.
Только теперь мы подобрались к Jenkins и построению динамического конвейера. Под спойлером термины в том виде, как мы их трактуем для себя; они могут упростить понимание изложенного далее:
pipeline— множество взаимосвязанных задач, направленных на решение общей целиjob— отдельная задача, исполняемая Jenkins на отдельном узле (сервере) и в отдельном контейнереbuild— запущенный на исполнение job, обычно обладающий артефактами по результатам работы (в статье явно не используется, билдом называется сборка дистрибутива ОС)build ID (BID)— уникальный целочисленный идентификатор билдаstage— часть build, характеризующая некоторую последовательность действий на языке, производном от Groovy (т.к. имеет свои особенности и ограничения)step— отдельный шаг в stage, часто связанный с вызовом конкретного плагина Jenkins (примеры: writeFile, readFile)CPS— одна из причин, почему в Jenkins нельзя использовать нормальный Groovyslot— максимальное число одновременно исполняемых job / build на сервере (настраивается администратором Jenkins для каждого сервера)
Пример pipeline, который может на практике оказаться как статическим, так и динамическим:

Все имеющиеся сервера были занесены в библиотеку профилей и отранжированы по уменьшению производительности:
- число ядер и потоков CPU для определения предельного числа параллельно исполняемых сборочных потоков на задачу
- число slot-ов для определения максимального числа параллельно запускаемых сборочных задач
- интегральный коэффициент производительности (для расстановки приоритетов серверам: чем больше коэффициент, тем больше вероятность назначения ему задачи)
Перед порождением вороха сборочных задач определяется доступность серверов. Сделать это можно двумя способами:
- Спросить у Jenkins:
if ( Jenkins.getInstance().getNode( "<сервер>" ).toComputer().isOnline() ) {
...
} else {
...
}- Попытаться запустить тестовый job на всех серверах разом и, если посчастливится, даже разбудить кого-то из них:
def jobs = [:]
def statuses = [:]
for ( server in servers ) {
def name = server.name
statuses["${name}"] = ''
jobs[server.name] = {
try {
timeout( time: <X>, unit: 'MINUTES' ) {
def job = build job: '<job-name>',
parameters: [...],
propagate: false,
wait: true
catchError( buildResult: 'SUCCESS', stageResult: 'FAILURE' ) {
if ( (job.result != "SUCCESS") && (job.result != "UNSTABLE") )
statuses["${name}"] = 'FAILURE'
}
if ( job.result == "SUCCESS" ) {
statuses["${name}"] = 'SUCCESS'
/* Здесь можно скопировать из job-а артефакты, определив,
* например, свободное пространство на SSD/HDD */
copyArtifacts( ... );
}
}
} catch ( ... ) {
/* Чтобы отличить таймаут от прерывания задачи придется заморочиться:
* stackoverflow.com/questions/51260440 */
}
}
}
parallel jobsПервый вариант проще, но не позволяет выводить сервера из suspend-а. В тоже время, без таймаута во втором варианте, job, запущенный на отсутствующем сервере, будет висеть вечно и толку от такого пайплайна не будет. Но сам перехват таймаута достаточно некрасивый — см. ссылку в коде. Также придется потратить время на настройку таймаутов засыпания/пробуждения серверов (в Jenkins) и таймаута ожидания job-а в своем коде. На практике эти параметры оказались достаточно недетерминированными, пришлось их брать с хорошим запасом.
Горизонтальное масштабирование в таком варианте достигается простым подключением новой машины к Jenkins и добавлением её профиля в код (всё это легко выносится в JenkinsLib). Отключили сервер на обслуживание? Скатертью ему дорога, билд дистрибутива не завалится.
Вертикальное масштабирование осуществляется как обычно — обновлением комплектации текущих серверов.
Оптимизация динамического пайплайна
В последнем примере кода приводится один из не самых частых вариантов динамического запуска кода в параллель, причем, не через тиражирование stage-ей или step-ов. Распараллеливанию здесь подлежат именно job-ы, что позволяет контролировать общее их количество и сопоставлять с доступными слотами и производительностью серверов. По классике это сделать сложнее, т.к. в модели вычислений Jenkins статусы каждой отдельной операции или stage формализованы никак плохо.
Именно на таком подходе базируется весь динамический пайплайн, позволяя порождать неограниченное и заранее неизвестное число побочных задач, отслеживать статусы их завершения и распределять нагрузку по всему парку серверов с изменяющейся конфигурацией.
На словах выглядит неплохо, но первые же эксперименты привели к ощущению, что Jenkins как-то подозрительно сильно тупит даже на самом порождении задач. Синтетическая генерация ничего не выполняющих тестовых job-ов в количестве 142 штуки длится на пустом месте 15 минут. Поскольку пиковое число таких задач ожидалось в районе нескольких тысяч, тратить эти часы на пустом месте откровенно не хотелось. К тому же, эффект практически не зависел от производительности и числа вовлечённых серверов, что потенциально минимизировало любой эффект от распределённой сборки.
Был написан простейший тест, выполняющий создание сотни мелких файлов:
echo "Запись 100 файлов"
for ( int i = 0; i < 100; i++ )
writeFile file: 'test-' + i.toString(), text: 'empty' + i.toString()
echo "Чтение 100 файлов"
for ( int i = 0; i < 100; i++ )
if ( fileExists( 'test-' + i.toString() ) ) {
try {
def readContent = readFile 'test-' + i.toString()
} catch (Exception e) {
echo "Error: " + 'test-' + i.toString()
}
} else
echo "Файл не найден: " + 'test-' + i.toString()
echo "Shell тест"
sh '''
for ((i = 0 ; i < 100; i++)); do
echo 'empty' > shell-file-${i}
done
for ((i = 0 ; i < 100; i++)); do
if [ -f shell-file-${i} ]; then
VAR=`cat shell-file-${i}`
fi
done
'''
echo "Shell тест завершён"Результаты знатно впечатлили. Shell-реализация работает менее секунды, Groovy-реализация от 35 до 45 на разных серверах. Из 15 минут выше около 6 занимала именно запись различных логов. Переделывание на Shell откровенно дурно пахло и, как выяснилось позднее, не было способно решить проблему в принципе.
Проблема оказалась комплексной. By design, один из режимов работы Jenkins подразумевает повышение живучести инстансов сервиса за счет параноидального кэширования всего и вся на хард. В нашем случае это явно было избыточным — "померла, значит померла", лучше перезапустим сборку билда, чем будем 24x7 ловить тормоза. При отключении durabilityHint( 'PERFORMANCE_OPTIMIZED' ) тест стал показывать сопоставимое время, не демонстрируя зависимость от реализации. Время синтетического билда упало до 6.25 мин.
Уже сильно лучше, но всё равно выглядит плохо. В процессе раскуривания логов и подключения на горячую к контейнерам Jenkins обнаружили, что на одном из серверов только что запущенный докер почти минуту что-то делает с загрузкой одного ядра CPU. Поскольку каждый job запускается в параллель на разных серверах, но абсолютно синхронно (см. дальше про асинхронность), а сборка компонентов дистрибутива осуществляется по «слоям», это неизбежно приведёт к повторению таких сценариев снова и снова. На этом сервере нам не фортануло с fakeroot has become extremely slow inside docker. Полечили опциями запуска docker, время упало уже до 4.1 мин.
Далее выяснилось, что квест с медленностью отдельных step-операций до конца так и не закончился. Из-за вынесения большей части утилитарного кода в разделяемую библиотеку и унификации интерфейсов к методам библиотечного класса, сложилась ситуация как в комбинированном тесте по мотивам предшествующего:
echo "start"
for ( int i = 0; i < 100; i++ )
sh """echo 'empty' > complex-file-${i}"""
for ( int i = 0; i < 100; i++ )
def stdout = sh( script: """if [ -f complex-file-${i} ]; then
cat complex-file-${i}
fi""", returnStdout: true )
echo "stop"По неизвестной до сих пор причине этот код медленнее любой из предшествующих реализаций, причем в несколько раз. Без отключения maximum durability mode он работает около полутора минут, с отключением все равно более 15 секунд. Мультипликативный эффект суммарно ожидался уже в пределах десятков минут, что также крайне абыдно! Приговорили многократный запуск sh-step, выделили весь его код в отдельный метод. Результат распределения стал укладываться в 2.7 мин. Дальше сам Jenkins решили не мучить, поскольку эффект ожидался минимальным, да и оставались вопросы с более очевидным профитом от оптимизации — балансировка нагрузки и асинхронность.
Как уже было сказано выше, код, с помощью которого мы будим сервера, лёг в основу генератора сборочных job-ов. Действуя по принципу
def jobs = [:]
for ( ... ) {
jobs[key] = {
...
}
}
parallel jobsи имея M x N задач для распараллеливания, стали ставить эксперименты по группировке дескрипторов:
- можно собирать все архитектуры одного пакета группой в одной задаче
- или не группировать вовсе и максимизировать вовлечение всех серверов
После включения сборки компонентов во втором случае на тестовом наборе позитивный эффект варьируется от 15% до 20%.
Другим фактором балансировки нагрузки стало выделение «тяжелых» задач и запуск их на выделенных серверах, независимо от числа доступных слотов и, отдавая предпочтение наиболее производительным из них. А обход «тяжелых» задач перед остальными вообще дает им эксклюзивный доступ к вычислительным мощностям: ровно одна архитектура/компонент на сервер. В тестовом наборе такие сценарии не затрагивались, поскольку ресурсоемкие задачи отсутствовали как класс. В боевом исполнении эффект уже измерялся часами, поскольку именно тяжелые задачи изначально и были основной трудоемкостью.
Внимательный специалист в последнем фрагменте кода заметит огромную дыру — он абсолютно синхронен. Допустим, что на X — 1 сервере запущена сборка такого же числа обычных задач, а на последнем ровно одна «тяжелая». Это приведёт к тому, что подавляющее большинство серверов будет большую часть времени простаивать.
Много времени потратили на борьбу с CPS и его паталогической нелюбовью к closures, перепробовали следующие варианты:
- Перво-наперво, попробовали смастерить привычный на системном уровне пул-потоков. Тут же нагуглился POSIX-подобный класс Thread и даже с почти классическим методом join(), правда без аналога pthread_timedjoin*(). В Jenkins банальные потоки просто не заработали. Как можно было сломать базовую многопоточность я понять отказываюсь, даже учитывая особенности сервиса. Fail!
- У используемого step-плагина имеется намёк на асинхронность в виде waitForBuild(). Ему честно передается BID, но вот сам
build job ...при таком сценарии перестаёт возвращать ID честно запущенного асинхронного job-а. Частичный Fail, т.к. job все-таки стал асинхронным! - Искали путь запуска в неблокирующем режиме конструкции parallel. Разработчики Jenkins вообще в эту сторону не думали. И снова Fail!
В итоге и эту проблему преодолели, но иначе. У самого Jenkins с асинхронностью совсем дела плохи.
Резюме
Надеемся, что статья оказалась занимательной и наш опыт будет кому-то полезен. Если данная тематика, в целом, окажется читателям интересной, можем в будущем рассказать, как организовали отсутствующую у Jenkins асинхронность для этого динамического пайплайна и каков общий достигнутый бонус.
Подписывайтесь на наш канал, чтобы быть в курсе свежих новостей


