
Был ли эффект от регулярных тренировок? Я проанализировал данные своих предыдущих тренировок с помощью нескольких общепринятых методов и получил неоднозначные результаты.

Это продолжение серии статей про анализ данных персональных тренировок из набора FIT-файлов, которые создаются при использовании носимых устройств, в том числе фитнес-браслетов, часов, смартфонов и т. п.
В предыдущих трех статьях я рассказал о том, как получить доступ к данным совершенных тренировок, как можно визуализировать показатели на графике и как можно провести их пространственный анализ.
В этой же статье я затрону тему анализа эффективности тренировок и расскажу, какие математические модели существуют для оценки их прогресса. Для решения поставленных задач я использовал несколько библиотек Python, предназначенных для работы с данными и построения моделей линейной регрессии – Pandas, Numpy, Matplotlib, Scipy, Statsmodel.
При дальнейшем анализе моих тренировок я решил сфокусироваться на велотренировках в помещении, и у меня на это пять причин:
Минимальный набор оборудования необходимый для сбора данных велотренировок в помещении включает в себя сам велосипед и станок, пульсометр, датчик каденса, мощемер и приложение (на компьютере, смартфоне или смарт-приставке телевизора), которое записывает данные со всех датчиков.
К ключевым показателям тренировки относятся:
Данные со всех датчиков регистрируются в момент времени (каждую секунду). Если рассматривать FIT-файл, то упомянутые данные для каждой тренировки хранятся в сообщении Record, обобщенные данные – в Session.
Стоит отметить, что уровень точности сенсоров и их стабильности все же не претендует на абсолютную значимость результатов анализа, и сам анализ интересен исключительно с любительской точки зрения.
Наиболее доступным вариантом измерения текущей формы велосипедиста является FTP тест, где FTP – Functional Threshold Power – или значение мощности, которую может держать спортсмен в течение часа.
FTP тестирование при регулярных тренировках проводится примерно раз в четыре недели. Стандартный протокол включает в себя несколько интервалов:
Среднее значение мощности ключевого интервала умножается на 0.95. Для сопоставимости FTP обычно соотносится с весом тела спортсмена и выражается в ваттах на килограмм.
Пример одного из проведенных FTP тестов приведен ниже на рисунке. Профиль тренировки FTP теста за 28 января 2021 года включает в себя 1 – разминку, 2 – 5 минут максимального усилия, 3 – отдых, 4 – 20 минут максимального усилия, 5 – заминка (всего 45 минут).

Как построить подобный график с помощью matplotlib, я рассказывал в этой статье, код доступен здесь.
Расчет FTP довольно простой и заключается в выделении ряда значений мощности (20 минутный интервал), и нахождении среднего значения. Полученное среднее умножается на 0.95. Порядковый номер секунды из таблицы Record можно создать с помощью фукнции SQL RANK:
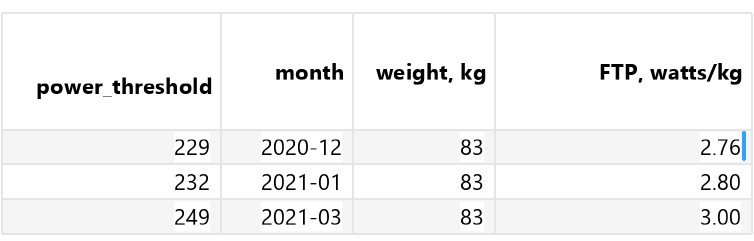
Для упомянутого выше теста я получил значение мощности Power_threshold = 232 ватт, FTP — 2,8 ватт/кг. Всего в сезоне было проведено три FTP-теста. Сопоставляя их результаты в динамике можно сделать вывод, что прогресс в наборе спортивной формы есть.
Использование значения FTP широко распространено среди велогонщиков, так как является сопоставимым между спортсменами. Свой уровень можно оценить, используя таблицу Энди Коггана.
Проба PWC170 (Physical Working Capacity at 170 bpm) рекомендована ВОЗ для оценки физической работоспособности человека и выражается в величинах той мощности физической нагрузки, при которой ЧСС достигает величины 170 ударов в минуту.
Выбор этого значения обусловлен тем, что адекватное функционирование кардиореспираторной системы с физиологической точки зрения ограничивается диапазоном ЧСС от 100 до 170 ударов в минуту, а также тем, что взаимосвязь между ЧСС и мощностью выполняемой физической нагрузки имеет линейный характер у большинства здоровых людей вплоть до ЧСС, равной 170 ударов в минуту.
Тест состоит из следующих интервалов:
Далее определяется значение PWC170 с помощью графической интерполяции или математически с помощью формулы:
Сопоставление результатов теста во времени позволяет судить об улучшении или ухудшении формы спортсмена.
Данный вид теста я не проводил, так как узнал о нем после, но попробовал его воспроизвести в немного измененном виде, используя имеющиеся у меня данные тренировок.
Исходя из таблицы с вариантами первой нагрузки, я определил значение 130 ватт и сделал следующий запрос к таблице Record:
Вложенный запрос выбирает только велотренировки в помещении (sub_sport = 'virtual_activity') в сезон 2020-2021 гг, установлен предел для значений мощности от 125 до 135 (так как определенное значение обычно выдерживать на станке сложно), heart_rate > 90 для исключения пропущенных и некорректных значений, каденс средний от 80 до 90.
Далее строим график распределения значений ЧСС при нагрузке в 130 ватт для первого и последнего месяцев тренировок:
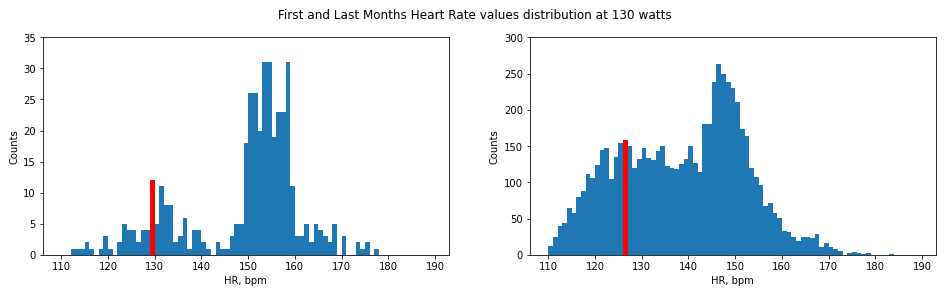
График напоминает бимодальное распределение с двумя пиками. Первый пик (исходя из значений пульса), скорее всего, относится к восстановительным тренировкам и разминкам, тогда как второй – к интервалам интенсивной тренировки. Первый пик больше соотносится с тестом PWC170, поэтому я выбрал наиболее часто встречающееся значение с первого пика как ЧСС первой нагрузки f1.
Таким образом, получим значение f1=130 уд/мин для первого месяца и f1 = 127 уд/мин для последнего месяца тренировок. В таблице для определения значения второй нагрузки интервалу от 120 до 129 уд/мин соответствует значение 180 ватт.
Аналогично построим график распределения значений ЧСС при нагрузке 180 ватт, изменив интервал в запросе на power between 175 and 185.

График напоминает отрицательно асимметричное нормальное распределение (скошено влево) с одним пиком – выберем его значение как ЧСС второй нагрузки.
Рассчитаем значение PWC170 (W3) для первого и последнего месяцев, используя метод графической интерполяции:
Построим графики линейной зависимости ЧСС от мощности для первого и последнего месяцев:
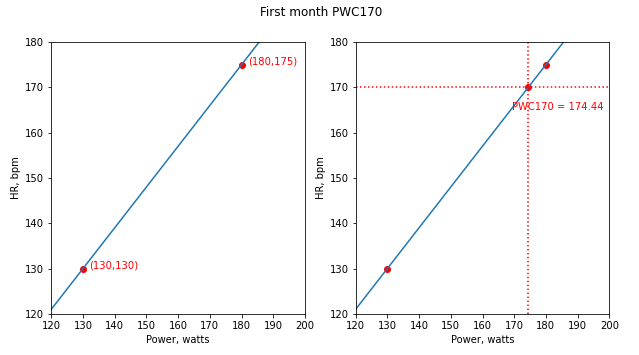
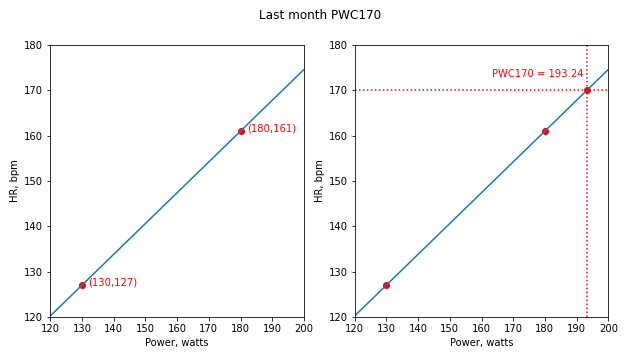
При сопоставлении двух полученных значений PWC170 для первого и последнего месяцев – 174.44 и 193.24 ватт можно сделать вывод, что прогресс есть. Однако тест нельзя назвать выполненным по стандартному протоколу.
Подтвердить точность использованной методики можно только проанализировав гораздо больше данных от разных людей. В будущих сезонах попробую провести тест максимально приближенно к оригинальной методике для получения более значимых результатов.
В пробе PWC170 упоминался тезис о том, что существует линейная зависимость между ЧСС и мощностью выполняемой физической нагрузки у большинства здоровых людей вплоть до определенного уровня.
Несколько найденных статей в открытом доступе также используют это допущение и применяют модель линейной регрессии для вычисления градиента, который должен отображать текущее физическое состояние спортсмена.
В другой статье предложен вариант расчета значений ЧСС через значение мощности по следующей формуле:
Также приводится пример из приложения с открытым кодом Golden Cheetah, где существует функция построения графика зависимости ЧСС от мощности.
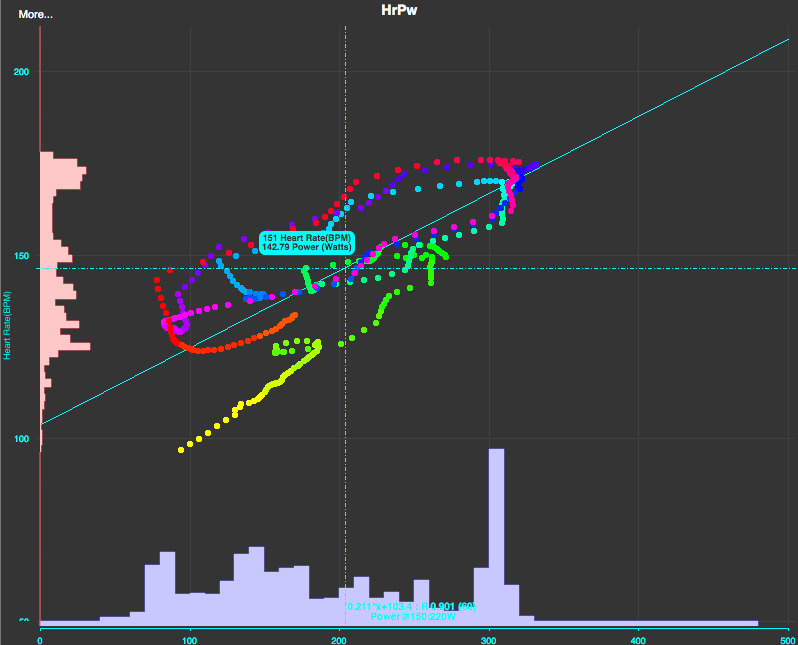
Я сделал предположение, что изменение угла наклона прямой (значение коэффициента k) может служить индикатором изменения формы спортсмена. Если значение k уменьшается, значит при большем увеличении мощности, значении ЧСС будет увеличиваться на меньшее значение.
Для анализа я решил использовать интервал разминки для каждой тренировки, в течение которого сохраняются приблизительно сопоставимые условия:
Я проанализировал стандартный график ЧСС, мощности и каденса для каждой из 48 тренировок за сезон 2020-2021. Для 28 из 48 тренировок я смог выделить интервал разминки от 7 до 9 минут для дальнейшего анализа.
На рисунке ниже приведены графики двух тренировок: для первой возможно выделить 7 минутный интервал разминки со стабильным каденсом и равномерным увеличением мощности (со 2 по 9 минуты), для второй – возможности не было ввиду наличия кратковременного увеличения мощности на 5-6 минуте.

Для каждой тренировки я подготовил датафрейм определенного заранее интервала разминки из таблицы Record. Каждая запись в таблице Record соответствует 1 секунде тренировки. Ниже приведен пример кода для выгрузки данных с 1 по 10 минуту тренировки:
Пример датафрейма с исходными данными интервала разминки:

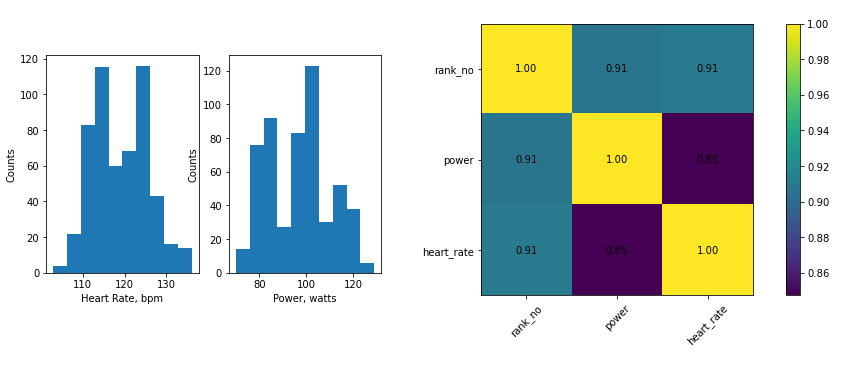
Перед началом построения модели я убедился, что данные из датафрейма имеют нормальное распределение (или напоминает), отсутствуют шумы и рассчитал коэффициент парной корреляции (для power, heart_rate он оказался равен 0.85).
Для расчета модели линейной регрессии я использовал модуль Python Statsmodel и наиболее распространенный метод Ordinary Least Squares (OLS):
Используя рассчитанные коэффициенты k, я построил график, отображающий распределение значений ЧСС (HR [bpm]) в зависимости от мощности (Power[watts]), а также добавил прямую регрессии.

Анализируя ключевые параметры рассчитанной модели (R squared = 0.718, SE = 0.011, p<0.05, F=1372), можно сделать вывод, что уравнение HR[bpm] = 78.25+0.42*Power[watts] хорошо описывает взаимосвязь двух переменных.
Используя описанный метод, я рассчитал модели для оставшихся 27 тренировок, распределенных в течение сезона. Средний коэффициент детерминации для всех моделей превысил значение 0.64.
Отобразив на графике все получившиеся значения коэффициента k, можно сделать вывод, что обозначить разницу между первым и последним месяцем или определить тренд во динамике не является возможным — значения коэффициента k варьируются без определенной закономерности на протяжении сезона тренировок.

Отмечу, что более высокое значение коэффициента k соотносится с более низкой (худшей) тренировочной формой. Другими словами, при низкой тренировочной форме при равном увеличении мощности пульс будет повышаться больше по сравнению с высокой (лучшей) тренировочной формой.
Имея рассчитанные коэффициенты k для тренировок в динамике, я решил сопоставить их с интенсивностью тренировок и попытаться найти явную или неявную зависимость.
Для расчета интенсивности каждой тренировки, я использовал показатель Training Stress Score (TSS), предложенный Training Peaks. TSS позволяет оценивать тренировки на основе их относительной интенсивности, продолжительности и частоты занятий.
Значение TSS рассчитывается по следующей формуле:
В формуле: sec – продолжительность тренировки в секундах, NP – нормализованная мощность, IF – фактор интенсивности [IF = NP/FTP], FTP – значение FTP (в данном случае значение power threshold в ваттах).
Для определения значения TSS нужно дополнительно ввести понятие нормализованной мощности (NP) как метода усреднения затраченной мощности для компенсации различий в условиях (интервалах) тренировки. Подробнее о том, как рассчитывается показатель NP можно прочитать здесь.
Расчет значений TSS для всех тренировок, где доступен показатель FTP, я сделал с помощью функций Python:
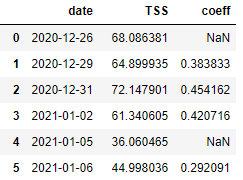
Объединим датасет с рассчитанным значением TSS с предыдущим, где хранятся параметры моделей линейной регрессии, и выберем поля date, TSS, coeff для конечного датасета:
Рассчитаем дополнительно значение Exponential Moving Average (EMA) для TSS, так как оно позволяет увидеть эффект от нескольких тренировок, проведенных за определенный промежуток времени (я выбрал для себя семь дней, span=7). Этот метод используется при оценке состояния спортсмена в планах Training Peaks.
Создадим новый датасет ds, где количество строк будет совпадать с разницей дней между последней и первой тренировкой выбранного периода. В моем случае это 95 дней (с 26 декабря 2020 по 30 марта 2021 включительно):
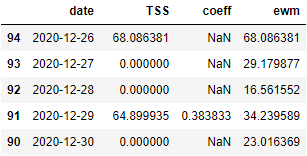
Объединим новый датасет с предыдущим с помощью left join и рассчитаем значение EMA для каждой даты, даже когда тренировок не было:
Построим совмещенный график с отображением значений TSS, EMA для TSS, коэффициентов k и их средним значением:

Анализируя график, каких-либо очевидных закономерностей выявить не удается, однако стоит отметить зависимость коэффициента k от хода EMA. В общем случае можно предположить, что наличие дней отдыха или восстановительных тренировок перед днем тренировки приводят к более низкому значению k (или лучшей тренировочной форме), и наоборот – наличие высокоинтенсивной или нескольких среднеинтенсивных тренировок перед днем тренировки приведет к более высокому значению коэффициента k (или худшей тренировочной форме).
Проведя анализ эффективности тренировок разными методами (FTP, PWC170, линейная регрессия), можно сделать вывод, что для понимания динамики тренировочной формы спортсмена можно косвенно использовать данные совершенных тренировок и в определенном контексте.
Конечно прямых выводов и закономерностей в этой случае получить не видится возможным на этом этапе анализа и с имеющимся набором данных.
Для более четкого и правильного анализа эффективности сезона тренировок, я бы попробовал провести в будущих сезонах отдельные тесты (например, полностью следуя стандартному протоколу PWC170), как дополнение к регулярному тренировочному плану.
Git-проект с примерами кода доступен по ссылке.

Это продолжение серии статей про анализ данных персональных тренировок из набора FIT-файлов, которые создаются при использовании носимых устройств, в том числе фитнес-браслетов, часов, смартфонов и т. п.
В предыдущих трех статьях я рассказал о том, как получить доступ к данным совершенных тренировок, как можно визуализировать показатели на графике и как можно провести их пространственный анализ.
В этой же статье я затрону тему анализа эффективности тренировок и расскажу, какие математические модели существуют для оценки их прогресса. Для решения поставленных задач я использовал несколько библиотек Python, предназначенных для работы с данными и построения моделей линейной регрессии – Pandas, Numpy, Matplotlib, Scipy, Statsmodel.
Какие тренировки я исследовал
При дальнейшем анализе моих тренировок я решил сфокусироваться на велотренировках в помещении, и у меня на это пять причин:
- Наличие более сотни записей с этого вида тренировок, совершенных за последние два года на одном виде станка с использованием одних и тех же сенсоров (мощемер, датчик каденса и пульсометр) и одного и того же приложения;
- Тренировки проводились в зимний сезон в помещении при относительно одинаковых условиях, то есть исключается фактор разных метеоусловий (температура воздуха, сила ветра, влажность);
- Тренировки проводились регулярно приблизительно в одно и то же время суток и дни недели;
- Относительная сопоставимость условий проведения тренировок позволяет сравнивать между собой имеющиеся данные;
- И последняя – непосредственный интерес был ли прогресс в тренировочном плане.
Минимальный набор оборудования необходимый для сбора данных велотренировок в помещении включает в себя сам велосипед и станок, пульсометр, датчик каденса, мощемер и приложение (на компьютере, смартфоне или смарт-приставке телевизора), которое записывает данные со всех датчиков.
К ключевым показателям тренировки относятся:
- Мощность (power, watts) – прилагаемая на педали сила, умноженная на скорость. Измеряется в ваттах и демонстрирует эффективность той работы, которую вы выполняете, крутя педали;
- Каденс (cadence, rpm) – частота педалирования или по-другому количество оборотов педалей велосипедиста, сделанных за одну минуту;
- Пульс (heart rate, bpm) – частота сердечных сокращений (ЧСС) или по-другому количество ударов сердца в минуту.
Данные со всех датчиков регистрируются в момент времени (каждую секунду). Если рассматривать FIT-файл, то упомянутые данные для каждой тренировки хранятся в сообщении Record, обобщенные данные – в Session.
Стоит отметить, что уровень точности сенсоров и их стабильности все же не претендует на абсолютную значимость результатов анализа, и сам анализ интересен исключительно с любительской точки зрения.
Анализ результатов FTP теста
Наиболее доступным вариантом измерения текущей формы велосипедиста является FTP тест, где FTP – Functional Threshold Power – или значение мощности, которую может держать спортсмен в течение часа.
FTP тестирование при регулярных тренировках проводится примерно раз в четыре недели. Стандартный протокол включает в себя несколько интервалов:
- Разминка с переменным каденсом;
- 5 минут максимального усилия;
- Восстановление/отдых;
- 20 минут максимального усилия (ключевой интервал);
- Заминка.
Среднее значение мощности ключевого интервала умножается на 0.95. Для сопоставимости FTP обычно соотносится с весом тела спортсмена и выражается в ваттах на килограмм.
Сопоставление результатов FTP тестов
Пример одного из проведенных FTP тестов приведен ниже на рисунке. Профиль тренировки FTP теста за 28 января 2021 года включает в себя 1 – разминку, 2 – 5 минут максимального усилия, 3 – отдых, 4 – 20 минут максимального усилия, 5 – заминка (всего 45 минут).
Как построить подобный график с помощью matplotlib, я рассказывал в этой статье, код доступен здесь.
Расчет FTP довольно простой и заключается в выделении ряда значений мощности (20 минутный интервал), и нахождении среднего значения. Полученное среднее умножается на 0.95. Порядковый номер секунды из таблицы Record можно создать с помощью фукнции SQL RANK:
# importing libraries
import psycopg2
import pandas as pd
activity_id = 80286974365
# connecting to a training record data
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="******")
df = pd.read_sql_query("""select timestamp, heart_rate, cadence, power,
rank() over (order by timestamp asc) as rank_no
from record
where activity_id ={} order by timestamp asc""".format(activity_id), conn)
# ftp calculation
start = 20*60
end = 40*60
df = df.loc[((df['rank_no'] > start) & (df['rank_no'] < end))]
ftp = df['power'].mean()*0.95
Для упомянутого выше теста я получил значение мощности Power_threshold = 232 ватт, FTP — 2,8 ватт/кг. Всего в сезоне было проведено три FTP-теста. Сопоставляя их результаты в динамике можно сделать вывод, что прогресс в наборе спортивной формы есть.
Использование значения FTP широко распространено среди велогонщиков, так как является сопоставимым между спортсменами. Свой уровень можно оценить, используя таблицу Энди Коггана.
Использование методики PWC170
Проба PWC170 (Physical Working Capacity at 170 bpm) рекомендована ВОЗ для оценки физической работоспособности человека и выражается в величинах той мощности физической нагрузки, при которой ЧСС достигает величины 170 ударов в минуту.
Выбор этого значения обусловлен тем, что адекватное функционирование кардиореспираторной системы с физиологической точки зрения ограничивается диапазоном ЧСС от 100 до 170 ударов в минуту, а также тем, что взаимосвязь между ЧСС и мощностью выполняемой физической нагрузки имеет линейный характер у большинства здоровых людей вплоть до ЧСС, равной 170 ударов в минуту.
Тест состоит из следующих интервалов:
- 5 минут первой нагрузки W1 (нагрузка выставляется исходя из веса человека). На последних минутах фиксируется значение ЧСС f1;
- 3 минуты отдыха;
- 5 минут второй нагрузки W2 (нагрузка выставляется исходя из мощности первой нагрузки и значении ЧСС, на котором эта нагрузка была завершена). На последних минутах фиксируется значение ЧСС f2.
Далее определяется значение PWC170 с помощью графической интерполяции или математически с помощью формулы:

Сопоставление результатов теста во времени позволяет судить об улучшении или ухудшении формы спортсмена.
Расчет PWC170
Данный вид теста я не проводил, так как узнал о нем после, но попробовал его воспроизвести в немного измененном виде, используя имеющиеся у меня данные тренировок.
Исходя из таблицы с вариантами первой нагрузки, я определил значение 130 ватт и сделал следующий запрос к таблице Record:
select to_char(timestamp, 'YYYY-MM') as month, heart_rate from record
where activity_id in (select activity_id from session where sub_sport = 'virtual_activity'
and timestamp::text between '2020-10-31' and '2021-04-01')
and power between 125 and 135 and heart_rate > 80 and cadence between 80 and 90Вложенный запрос выбирает только велотренировки в помещении (sub_sport = 'virtual_activity') в сезон 2020-2021 гг, установлен предел для значений мощности от 125 до 135 (так как определенное значение обычно выдерживать на станке сложно), heart_rate > 90 для исключения пропущенных и некорректных значений, каденс средний от 80 до 90.
Далее строим график распределения значений ЧСС при нагрузке в 130 ватт для первого и последнего месяцев тренировок:
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
fig, (ax1, ax2) = plt.subplots(1,2)
fig.suptitle('First and Last Months Heart Rate values distribution at 130 watts')
N1, bins1, patches1 = ax1.hist(w1_df11.heart_rate, bins=np.arange(110,190,1))
for i in range(19,20):
patches1[i].set_facecolor('r')
ax1.set_ylim(0, 35)
ax1.set_xlabel("HR, bpm")
ax1.set_ylabel("Counts")
N2, bins2, patches2 = ax2.hist(w1_df03.heart_rate, bins=np.arange(110,190,1))
for i in range(16,17):
patches2[i].set_facecolor('r')
ax2.set_ylim(0, 300)
ax2.set_xlabel("HR, bpm")
ax2.set_ylabel("Counts")
plt.rcParams['figure.figsize'] = [16, 4]
plt.show()
График напоминает бимодальное распределение с двумя пиками. Первый пик (исходя из значений пульса), скорее всего, относится к восстановительным тренировкам и разминкам, тогда как второй – к интервалам интенсивной тренировки. Первый пик больше соотносится с тестом PWC170, поэтому я выбрал наиболее часто встречающееся значение с первого пика как ЧСС первой нагрузки f1.
Таким образом, получим значение f1=130 уд/мин для первого месяца и f1 = 127 уд/мин для последнего месяца тренировок. В таблице для определения значения второй нагрузки интервалу от 120 до 129 уд/мин соответствует значение 180 ватт.
Аналогично построим график распределения значений ЧСС при нагрузке 180 ватт, изменив интервал в запросе на power between 175 and 185.
График напоминает отрицательно асимметричное нормальное распределение (скошено влево) с одним пиком – выберем его значение как ЧСС второй нагрузки.
Применение метода графической интерполяции
Рассчитаем значение PWC170 (W3) для первого и последнего месяцев, используя метод графической интерполяции:
from scipy.interpolate import interp1d
y_interp = interp1d([f1, f2], [W1, W2], fill_value="extrapolate")
f3 = 170
W3 = y_interp(f3)Построим графики линейной зависимости ЧСС от мощности для первого и последнего месяцев:
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(1,2)
fig.suptitle('First month PWC170')
ax1.plot([W1, W2], [f1, f2], 'ro')
ax1.axline((W1, f1), (W2, f2))
ax1.text(W2+2, f2, "({},{})".format(W2, f2), size=10, color='r')
ax1.text(W1+2, f1, "({},{})".format(W1, f1), size=10, color='r')
ax1.set_xlim([120, 200])
ax1.set_ylim([120, 180])
ax1.set_xlabel("Power, watts")
ax1.set_ylabel("HR, bpm")
ax2.plot([W1, W2, W3], [f1, f2, f3], 'ro')
ax2.axline((W1, f1), (W2, f2))
ax2.axvline(x=W3, color='r', linestyle=':')
ax2.axhline(y=f3, color='r', linestyle=':')
ax2.text(W3-5, f3-5, "PWC170 = {}".format(np.round(W3, 2)), size=10, color='r')
ax2.set_xlim([120, 200])
ax2.set_ylim([120, 180])
ax2.set_xlabel("Power, watts")
ax2.set_ylabel("HR, bpm")
plt.rcParams['figure.figsize'] = [10, 5]
plt.show()
При сопоставлении двух полученных значений PWC170 для первого и последнего месяцев – 174.44 и 193.24 ватт можно сделать вывод, что прогресс есть. Однако тест нельзя назвать выполненным по стандартному протоколу.
Подтвердить точность использованной методики можно только проанализировав гораздо больше данных от разных людей. В будущих сезонах попробую провести тест максимально приближенно к оригинальной методике для получения более значимых результатов.
Применение метода линейной регрессии
В пробе PWC170 упоминался тезис о том, что существует линейная зависимость между ЧСС и мощностью выполняемой физической нагрузки у большинства здоровых людей вплоть до определенного уровня.
Несколько найденных статей в открытом доступе также используют это допущение и применяют модель линейной регрессии для вычисления градиента, который должен отображать текущее физическое состояние спортсмена.
В другой статье предложен вариант расчета значений ЧСС через значение мощности по следующей формуле:
![$HR [bpm]= b+ (k* Power[watts])$](https://habrastorage.org/getpro/habr/formulas/d72/0ce/b37/d720ceb372a4b27170b07e640042e300.svg)
Также приводится пример из приложения с открытым кодом Golden Cheetah, где существует функция построения графика зависимости ЧСС от мощности.
Какие данные я использовал для анализа
Я сделал предположение, что изменение угла наклона прямой (значение коэффициента k) может служить индикатором изменения формы спортсмена. Если значение k уменьшается, значит при большем увеличении мощности, значении ЧСС будет увеличиваться на меньшее значение.
Для анализа я решил использовать интервал разминки для каждой тренировки, в течение которого сохраняются приблизительно сопоставимые условия:
- Равномерное увеличение мощности при стабильном каденсе;
- Пульс будет всегда ниже порогового и отсутствует влияние предыдущих интервалов, так как это всегда первый интервал в тренировке.
Я проанализировал стандартный график ЧСС, мощности и каденса для каждой из 48 тренировок за сезон 2020-2021. Для 28 из 48 тренировок я смог выделить интервал разминки от 7 до 9 минут для дальнейшего анализа.
На рисунке ниже приведены графики двух тренировок: для первой возможно выделить 7 минутный интервал разминки со стабильным каденсом и равномерным увеличением мощности (со 2 по 9 минуты), для второй – возможности не было ввиду наличия кратковременного увеличения мощности на 5-6 минуте.
Построение модели линейной регрессии
Для каждой тренировки я подготовил датафрейм определенного заранее интервала разминки из таблицы Record. Каждая запись в таблице Record соответствует 1 секунде тренировки. Ниже приведен пример кода для выгрузки данных с 1 по 10 минуту тренировки:
import pandas as pd
import psycopg2
activity_id = 77485450073
start = 1
end = 10
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="******")
df = pd.read_sql_query("""select * from (select record_id, power, heart_rate, rank () over (order by timestamp asc) as rank_no
from record where activity_id = {}) tbl where tbl.rank_no between {} and {}""".format(activity_id, start*60,end*60), conn)
Пример датафрейма с исходными данными интервала разминки:
Перед началом построения модели я убедился, что данные из датафрейма имеют нормальное распределение (или напоминает), отсутствуют шумы и рассчитал коэффициент парной корреляции (для power, heart_rate он оказался равен 0.85).
import pandas as pd
import psycopg2
import matplotlib.pyplot as plt
activity_id = 77485450073
start = 1
end = 10
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="afande")
df = pd.read_sql_query("""select rank_no, power, heart_rate from (select record_id, power, heart_rate,
rank () over (order by timestamp asc) as rank_no
from record where activity_id = {}) tbl
where tbl.rank_no between {} and {}""".format(activity_id, start*60,end*60), conn)
fig, (ax1, ax2) = plt.subplots(1,2)
plt.rcParams['figure.figsize'] = [12, 5]
ax1.hist(df.heart_rate)
# ax1.title('Heart Rate values distribution')
ax1.set_xlabel("Heart Rate, bpm")
ax1.set_ylabel("Counts")
ax2.hist(df.power)
ax2.set_xlabel("Power, watts")
ax2.set_ylabel("Counts")
plt.show()
# Correlation matrix
import numpy as np
from mlxtend.plotting import heatmap
cm = np.corrcoef(df.values.T)
hm = heatmap(cm, row_names=df.columns, column_names=df.columns)
plt.show()Для расчета модели линейной регрессии я использовал модуль Python Statsmodel и наиболее распространенный метод Ordinary Least Squares (OLS):
import statsmodels.api as sm
X = df[['power']]
y = df['heart_rate']
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
predictions = model.predict(X)Используя рассчитанные коэффициенты k, я построил график, отображающий распределение значений ЧСС (HR [bpm]) в зависимости от мощности (Power[watts]), а также добавил прямую регрессии.
import matplotlib.pyplot as plt
import numpy as np
plt.scatter(df.power, df.heart_rate, marker='o', label='record_id', s=8)
plt.suptitle('Power and Heart Rate relation fitted line plot', fontsize=14)
plt.title('HR[bpm] = {}+{}*Power[watts]'.format(round(model.params[0],2), round(model.params[1],2)), fontsize=10)
plt.rcParams['figure.figsize'] = [6, 6]
plt.plot(df.power, model.params[0]+model.params[1]*df.power, color='red')
plt.xlabel("Power, watts")
plt.ylabel("HR, bpm")
plt.show()Анализируя ключевые параметры рассчитанной модели (R squared = 0.718, SE = 0.011, p<0.05, F=1372), можно сделать вывод, что уравнение HR[bpm] = 78.25+0.42*Power[watts] хорошо описывает взаимосвязь двух переменных.
Используя описанный метод, я рассчитал модели для оставшихся 27 тренировок, распределенных в течение сезона. Средний коэффициент детерминации для всех моделей превысил значение 0.64.
Отобразив на графике все получившиеся значения коэффициента k, можно сделать вывод, что обозначить разницу между первым и последним месяцем или определить тренд во динамике не является возможным — значения коэффициента k варьируются без определенной закономерности на протяжении сезона тренировок.
import matplotlib.pyplot as plt
plt.plot(ds.date, ds.coeff, marker="D", linestyle="", alpha=0.8, color="r", label='k on the date')
plt.axhline(y=ds.coeff.mean(), color='red', linestyle=':', label='mean value for k')
plt.rcParams['figure.figsize'] = [12, 4]
plt.title('Distribution of Power coefficient (k) during the training season (HR[bpm] = b+k*Power[watts])')
plt.legend()
plt.show()Отмечу, что более высокое значение коэффициента k соотносится с более низкой (худшей) тренировочной формой. Другими словами, при низкой тренировочной форме при равном увеличении мощности пульс будет повышаться больше по сравнению с высокой (лучшей) тренировочной формой.
Сопоставление коэффициента зависимости ЧСС и мощности с интенсивностью тренировки
Имея рассчитанные коэффициенты k для тренировок в динамике, я решил сопоставить их с интенсивностью тренировок и попытаться найти явную или неявную зависимость.
Расчет Training Stress Score
Для расчета интенсивности каждой тренировки, я использовал показатель Training Stress Score (TSS), предложенный Training Peaks. TSS позволяет оценивать тренировки на основе их относительной интенсивности, продолжительности и частоты занятий.
Значение TSS рассчитывается по следующей формуле:

В формуле: sec – продолжительность тренировки в секундах, NP – нормализованная мощность, IF – фактор интенсивности [IF = NP/FTP], FTP – значение FTP (в данном случае значение power threshold в ваттах).
Для определения значения TSS нужно дополнительно ввести понятие нормализованной мощности (NP) как метода усреднения затраченной мощности для компенсации различий в условиях (интервалах) тренировки. Подробнее о том, как рассчитывается показатель NP можно прочитать здесь.
Расчет значений TSS для всех тренировок, где доступен показатель FTP, я сделал с помощью функций Python:
def normalized_power(activity_id):
df = pd.read_sql_query("""select power, rank () over (order by timestamp asc) as rank_no from record
where activity_id = {}""".format(activity_id), conn)
WindowSize = 30; # second rolling average
NumberSeries = pd.Series(df.power)
NumberSeries = NumberSeries.dropna()
Windows = NumberSeries.rolling(WindowSize)
Power_30s = Windows.mean().dropna()
PowerAvg = round(Power_30s.mean(),0)
NP = round((((Power_30s**4).mean())**0.25),0)
return(NP)
def tss(activity_id, ftp, NP):
sec = pd.read_sql_query("""select count(*) from record
where activity_id = {}""".format(activity_id), conn).iloc[0][0]
TSS = (sec*NP*NP/ftp)/(ftp*3600) *100
return(TSS)
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="******")
tss_df = pd.read_csv('power_zones_data_rf_comparison.csv', index_col=0)
tss_df['NP'] = tss_df.apply(lambda row: normalized_power(row['activity_id']), axis=1)
tss_df['TSS'] = tss_df.apply(lambda row: tss(row['activity_id'], row['power_threshold'], row['NP']), axis=1)
Объединим датасет с рассчитанным значением TSS с предыдущим, где хранятся параметры моделей линейной регрессии, и выберем поля date, TSS, coeff для конечного датасета:
import pandas as pd
df_1 = pd.read_csv('tss.csv', index_col=0)
df_2 = pd.read_csv('results.csv', index_col=0)
df_1 = df_1.merge(df_2, left_on ='activity_id', right_on = 'activity_id', how='left')
df = pd.read_csv('merged.csv', index_col=0)
df = df.loc[df.timestamp > '2020-12-26']
df = df.loc[df.timestamp < '2021-04-01']
df['date'] = pd.to_datetime(df['timestamp']).dt.date
df = df[['date', 'TSS', 'coeff']]
Расчет Exponential Moving Average
Рассчитаем дополнительно значение Exponential Moving Average (EMA) для TSS, так как оно позволяет увидеть эффект от нескольких тренировок, проведенных за определенный промежуток времени (я выбрал для себя семь дней, span=7). Этот метод используется при оценке состояния спортсмена в планах Training Peaks.
Создадим новый датасет ds, где количество строк будет совпадать с разницей дней между последней и первой тренировкой выбранного периода. В моем случае это 95 дней (с 26 декабря 2020 по 30 марта 2021 включительно):
import datetime
base = datetime.datetime.today()
base = max(df.date)
date_list = [base - datetime.timedelta(days=x) for x in range(95)]
ds = pd.DataFrame({'date': date_list})
Объединим новый датасет с предыдущим с помощью left join и рассчитаем значение EMA для каждой даты, даже когда тренировок не было:
ds = pd.merge(ds, df, on='date', how='left')
ds = ds.sort_values(by='date')
ds['TSS'] = ds['TSS'].fillna(0)
ds['ewm'] = ds['TSS'].ewm(span=7).mean()
Анализ результатов
Построим совмещенный график с отображением значений TSS, EMA для TSS, коэффициентов k и их средним значением:
import matplotlib.pyplot as plt
# drawing a chart with three Y axis, more details here - https://matplotlib.org/3.4.3/gallery/ticks_and_spines/multiple_yaxis_with_spines.html
fig, ax = plt.subplots()
fig.subplots_adjust(right=0.65)
# the title of the chart
twin1 = ax.twinx()
twin2 = ax.twinx()
# the distance between second and third y axis
twin2.spines.right.set_position(("axes", 1.1))
# metrics
p1 = ax.bar(ds.date, ds.TSS, color='limegreen', label = 'TSS')
p2 = twin1.plot(ds.date, ds['ewm'], linestyle="--", color='purple', label='EMA for TSS wtih 7-days span')
p3 = twin2.plot(ds.date, ds.coeff, marker="D", linestyle="", alpha=0.8, color="r", label='k value on the date')
# settings for labels and legends
ax.set_ylim(0, 135)
twin1.set_ylim(0, 80)
twin2.set_ylim(0, 1)
plt.axhline(y=ds.coeff.mean(), color='red', linestyle=':', label ='k values mean')
plt.rcParams['figure.figsize'] = [18, 7]
ax.set_xlabel("Dates")
ax.set_ylabel("TSS")
twin1.set_ylabel("EMA")
twin2.set_ylabel("k value")
fig.suptitle('\n'.join(['Distribution of Power coefficient (k) during the training season',
'in comparison to TSS and EMA for TSS with 7-days span']), y=0.95, x=0.45)
fig.legend(loc='center', bbox_to_anchor=(0.4, 0), shadow=False, ncol=2)
plt.show()
Анализируя график, каких-либо очевидных закономерностей выявить не удается, однако стоит отметить зависимость коэффициента k от хода EMA. В общем случае можно предположить, что наличие дней отдыха или восстановительных тренировок перед днем тренировки приводят к более низкому значению k (или лучшей тренировочной форме), и наоборот – наличие высокоинтенсивной или нескольких среднеинтенсивных тренировок перед днем тренировки приведет к более высокому значению коэффициента k (или худшей тренировочной форме).
Итоги
Проведя анализ эффективности тренировок разными методами (FTP, PWC170, линейная регрессия), можно сделать вывод, что для понимания динамики тренировочной формы спортсмена можно косвенно использовать данные совершенных тренировок и в определенном контексте.
Конечно прямых выводов и закономерностей в этой случае получить не видится возможным на этом этапе анализа и с имеющимся набором данных.
Для более четкого и правильного анализа эффективности сезона тренировок, я бы попробовал провести в будущих сезонах отдельные тесты (например, полностью следуя стандартному протоколу PWC170), как дополнение к регулярному тренировочному плану.
Git-проект с примерами кода доступен по ссылке.
