

В этой статье мы поговорим о подробностях реализации и работе разных JIT-компиляторов, а также о стратегиях оптимизации. Обсуждать будем достаточно подробно, однако многие важные концепции опустим. То есть в этой статье не будет достаточной информации, чтобы прийти к обоснованным заключениям при любых сравнениях реализаций и языков.
Чтобы получить базовое представление о JIT-компиляторах, почитайте эту статью.
Небольшое примечание:
Я часто буду описывать поведение оптимизации и утверждать, что она, вероятно, есть и в каком-нибудь другом компиляторе. Хотя я не всегда проверяю, есть ли эта оптимизация в другом JIT (иногда всё неоднозначно), но если знаю точно, то укажу на это. Я также приведу примеры кода, чтобы показать, где может быть применена оптимизация, но это не точно, ведь приоритет может быть отдан другой оптимизации. Могут быть и какие-то общие упрощения, но не больше, чем в большинстве подобных постов.
Основные вехи
- Метатрассировка в работе Pypy
- Как языки GraalVM поддерживают расширения на C
- Деоптимизация
- Инлайнинг и OSR
- Океаны нод
- Многоуровневое использование JIT
(Мета)трассировка
LuaJIT использует так называемую трассировку (tracing). Pypy выполняет метатрассировку, то есть использует систему для генерирования интерпретаторов трассировки и JIT. Pypy и LuaJIT — это не образцовые реализации Python и Lua, а самостоятельные проекты. Я бы охарактеризовал LuaJIT как шокирующе быструю, и она сама себя описывает как одну из самых быстрых динамических языковых реализаций — и я этому безоговорочно верю.
Чтобы понять, когда начинать трассировку, цикл интерпретации ищет «горячие» циклы (концепция «горячего» кода универсальна для всех JIT-компиляторов!). Затем компилятор «трассирует» цикл, записывая исполняемые операции для компилирования хорошо оптимизированного машинного кода. В LuaJIT компиляция выполняется на основе трасс с промежуточным представлением, похожим на инструкции, которое уникально для LuaJIT.
Как трассировка реализована в Pypy
Pypy начинает трассировать функцию после 1619 исполнений и компилирует ещё после 1039 исполнений, то есть нужно около 3000 исполнений функции, чтобы она начала работать быстрее. Эти значения тщательно подбирались командой Pypy, и вообще в мире компиляторов многие константы подбираются продуманно.
Динамические языки затрудняют оптимизацию. Нижеприведённый код может быть статически удалён более строгим языком, потому что
False всегда будет ложным. Однако в Python 2 этого нельзя гарантировать до момента исполнения.if False:
print("FALSE")
Для любой разумной программы это условие всегда будет ложным. К сожалению, значение
False может быть переопределено, и выражение будет в цикле, его могут переопределить где-то в другом месте. Поэтому Pypy может создать «защитника». Если защитник не справляется, JIT возвращается к циклу интерпретирования. Затем Pypy с помощью ещё одной константы (200), которая называется trace eagerness, решает, нужно ли компилировать остаток нового пути до конца цикла. Этот подпуть называется мостом (bridge).Кроме того, Pypy предоставляет эти константы как аргументы, которые можно настраивать в ходе исполнения наряду с конфигурацией развёртки (unrolling), то есть расширения цикла, и инлайнинга! И вдобавок он предоставляет хуки, которые мы можем увидеть после завершения компилирования.
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
Выше я написал программу на чистом Python с компилирующим хуком для вывода на экран типа применённой компиляции. Также код выводит в конце данные, в которых видно количество защитников. Для этого программы я получил одну компиляцию цикла и 66 защитников. Когда я заменил выражение
if простым проходом вне цикла for, осталось только 59 защитников.for i in range(10000):
pass # removing the `if False` saved 7 guards!
Добавив эти две строки в цикл
for, я получил две компиляции, одна из которых относилась к типу «мост»!if random.randint(1, 100) < 20:
False = True
Погоди, ты же говорил про метатрассировку!
Идею метатрассировки можно описать как «напиши интерпретатор, и получи компилятор бесплатно!», или «преврати свой интерпретатор в JIT-компилятор!». Писать компилятор трудно, и если можно получить его бесплатно, то идея крутая. Pypy «содержит» интерпретатор и компилятор, но в нём нет явной реализации традиционного компилятора.
В Pypy есть инструмент RPython (созданный для Pypy). Это фреймворк для написания интерпретаторов. Его язык относится к разновидности Python и обеспечивает статическую типизацию. На этом языке и нужно писать интерпретатор. Язык не предназначен для программирования на типизированном Python, потому что не содержит стандартных библиотек или пакетов. Любая программа на RPython является корректной Python-программой. Код на RPython транспилируется в С, а затем компилируется. Таким образом, метакомпилятор на этом языке существует в виде скомпилированной программы на С.
Приставка «мета» в слове метатрассировка означает, что трассировка выполняется при исполнении интерпретатора, а не программы. Он ведёт себя более-менее как любой другой интерпретатор, но может отслеживать свои операции и предназначен для оптимизации трасс с помощью обновления своего пути прохождения. С дальнейшей трассировкой путь интерпретатора становится более оптимизированным. Хорошо оптимизированный интерпретатор идёт по специфическому пути. А используемый в этом пути машинный код, полученный при компилировании RPython, может использоваться в окончательной компиляции.
Короче, «компилятор» в Pypy компилирует ваш интерпретатор, поэтому Pypy иногда называют метакомпилятором. Он компилирует не столько программу, которую вы исполняете, сколько путь оптимизированного интерпретатора.
Концепция метатрассировки может показаться непонятной, поэтому для иллюстрации я написал очень плохую программу, которая понимает только
a = 0 и a++to.# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
Если я запущу этот горячий цикл:
a = 0
a++
a++
Трассы могут выглядеть так:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
Но компилятор — не какой особенный отдельный модуль, он встроен в интерпретатор. Поэтому цикл интерпретации будет выглядеть так:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
Введение в JVM
Я четыре месяца писал на языке TruffleRuby на основе Graal, и влюбился в него.
Hotspot (названа так потому, что ищет горячие точки) — это виртуальная машина, поставляемая со стандартными инсталляциями Java. В ней содержится несколько компиляторов для реализации многоуровневого компилирования. Кодовая база Hotspot в 250 000 строк открыта, в ней есть три сборщика мусора. Виртуалка отлично справляется с JIT-компиляцией, в некоторых бенчмарках она работает не хуже C++ impls (по этому поводу столько
Используемые в Hotspot стратегии вдохновили многих авторов последующих JIT-компиляторов, структур языковых виртуальных машин, и особенно Javascript-движков. Также Hotspot породила волну таких JVM-языков, как Scala, Kotlin, JRuby и Jython. JRuby и Jython — забавные реализации Ruby и Python, которые компилируют исходный код в JVM-байткод, который потом исполняет Hotspot. Все эти проекты относительно успешно ускоряют языки Python и Ruby (Ruby больше, чем Python) без реализации всего инструментария, как в случае с Pypy. Ещё Hotspot уникальна тем, что она является JIT для менее динамических языков (хотя технически она представляет собой JIT для JVM-байткода, а не для Java).

GraalVM — это JavaVM с частью кода на Java. Она может исполнять любой JVM-язык (Java, Scala, Kotlin и т.д.). На также поддерживает Native Image, чтобы работать с AOT-компилированным кодом через Substrate VM. Значительная доля Scala-сервисов Twitter работает на Graal, что говорит о качестве виртуальной машины, и кое в чём она лучше JVM, хотя и написана на Java.
И это ещё не всё! GraalVM также предоставляет Truffle: фреймворк для реализации языков с помощью создания AST-интерпретаторов (Abstract Syntax Tree). В Truffle нет явного шага, когда создается JVM-байткод, как в обычном языке JVM. Cкорее, Truffle просто воспользуется интерпретатором и будет общаться с Graal для создания машинного кода непосредственно с профилированием и так называемой частичной оценкой. Рассмотрение частичной оценки выходит за рамки статьи, если вкратце: этот метод исповедует философию метатрассировки «напиши интерпретатор, и получи компилятор бесплатно!», но подходит к ней иначе.
TruffleJS — Truffle-реализация Javascript, которая опережает движок V8 по ряду показателей, что действительно впечатляет, потому что V8 разрабатывался на много лет дольше, Google вложила в него кучу денег и сил, над ним работали офигенные специалисты. TruffleJS не «лучше» V8 (или любого другого JS-движка) по большинству критериев, но это знак надежды для Graal.
Неожиданно отличные стратегии JIT-компилирования
Интерпретирование C
У JIT-реализаций часто возникает проблема с поддержкой С-расширений. Стандартные интерпретаторы, такие как Lua, Python, Ruby и PHP, имеют API для С, что позволяет пользователям собирать на этом языке пакеты, значительно ускоряя исполнение. Многие пакеты написаны на С, например, numpy, функции стандартной библиотеки вроде
rand. Все эти С-расширения крайне важны для того, чтобы интерпретируемые языки работали быстро.По ряду причин поддерживать C-расширения трудно. Самая очевидная причина в том, что API разработан с учётом особенностей внутренней реализации. Более того, поддерживать С-расширения легче, когда интерпретатор написан на С, так что JRuby не может поддерживать С-расширения, но у него есть API для Java-расширений. В Pypy недавно появилась бета-версия поддержки С-расширений, хотя в её работоспособности я не уверен в связи с законом Хайрама. LuaJIT поддерживает С-расширения, в том числе и дополнительные фичи в своих С-расширениях (LuaJIT — просто офигенная штука!)
Graal решает эту проблему с помощью Sulong, движка, который на GraalVM исполняет LLVM-байткод, преобразуя его в язык Truffle. LLVM — это набор инструментов, и нам достаточно знать, что С можно скомпилировать в LLVM-байткод (у Julia тоже есть LLVM-бэкенд!). Это странно, но решение заключается в том, чтобы взять хороший компилируемые язык с более чем сорокалетней историей, и интерпретировать его! Конечно, он работает совсем не так быстро, как правильно скомпилированный С, но зато мы получаем несколько преимуществ.
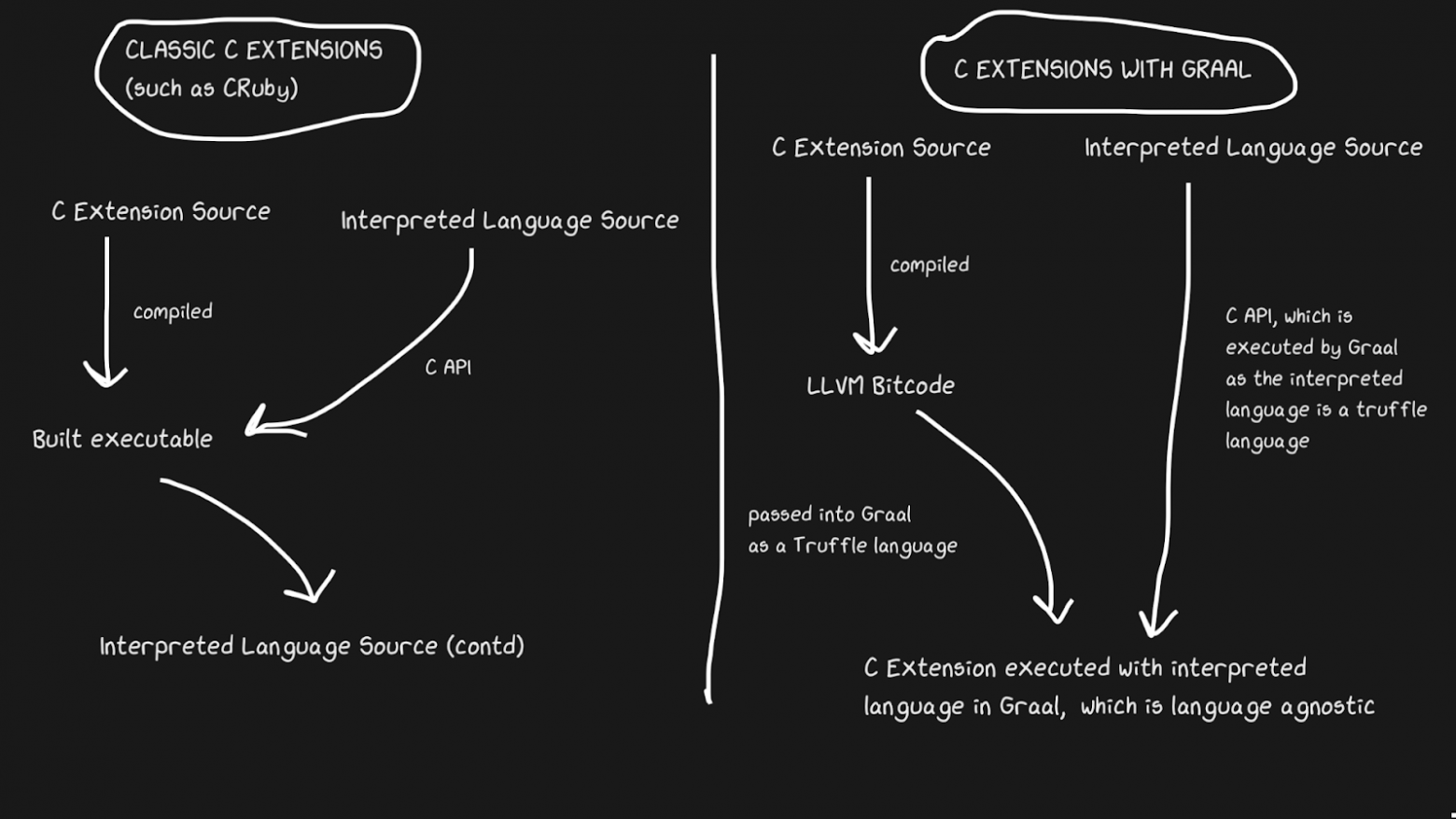
LLVM-байткод уже довольно низкоуровневый, то есть применять JIT к этому промежуточному представлению не так неэффективно, как к С. Часть расходов нам возмещается тем, что байткод можно оптимизировать вместе с остальной частью Ruby-программы, а скомпилированную С-программу мы оптимизировать не сможем. Все эти удаления фрагментов памяти, инлайнинги, удаления мёртвых фрагментов кода и прочее можно применять к коду на С и Ruby, вместо того, чтобы вызывать бинарник на С из Ruby-кода. По некоторым параметрам С-расширения TruffleRuby работают быстрее С-расширений CRuby.
Чтобы эта система работала, вам следует знать, что Truffle является полностью независимым от языка, и накладные расходы на переключение между С, Java или любым другим языком внутри Graal будут минимальны.
Способность Graal работать с Sulong является частью их полиглот-возможностей, что обеспечивает высокую взаимозаменяемость языков. Это не только хорошо для компилятора, но ещё и доказывает возможность легко использовать несколько языков в одном «приложении».
Вернёмся к интерпретируемому коду, он быстрее
Мы знаем, что JIT содержат в себе интерпретатор и компилятор, и что для ускорения работы они переходят от интерпретатора к компилятору. Pypy создаёт мостики для обратного пути, хотя с точки зрения Graal и Hotspot это деоптимизация. Мы говорим не о совершенно разных понятиях, но под деоптимизацией понимается возврат к интерпретатору в качестве сознательной оптимизации, а не решение неизбежностей динамического языка. Hotspot и Graal активно используют деоптимизацию, особенно Graal, потому что у разработчиков есть жёсткий контроль над компиляцией, и им нужно ещё больше контроля над компилированием ради оптимизаций (по сравнению, скажем, с Pypy). Также деоптимизация используется в JS-движках, о чём я буду много рассказывать, поскольку от неё зависит работа JavaScript в Chrome и Node.js.
Чтобы быстро применить деоптимизацию, важно убедиться в максимально быстром переключении между компилятором и интерпретатором. При самой наивной реализации интерпретатор придётся «догонять» компилятор, чтобы выполнить деоптимизацию. Дополнительные сложности связаны с деоптимизацией асинхронных потоков. Graal создаёт набор фреймов и сопоставляет его со сгенерированным кодом, чтобы вернуться к интерпретатору. С помощью безопасных состояний (safepoints) можно сделать так, что Java-поток встанет на паузу и скажет: «Привет, сборщик мусора, мне нужно остановиться?», так что обработка потоков не требует больших накладных расходов. Получилось довольно грубо, но работает достаточно быстро, чтобы деоптимизация оказалась хорошей стратегией.

Аналогично примеру с мостиками в Pypy, деоптимизировать можно и партизанский патчинг (monkey patching) функций. Получается элегантнее, поскольку мы добавляем деоптимизирующий код не тогда, когда защитник терпит неудачу, а когда применяется партизанский патчинг.
Отличный пример JIT-деоптимизации: переполнение преобразования (conversion overflow), это неофициальный термин. Речь о ситуации, когда внутренне представлен/выделен определённый тип (например,
int32), но его нужно преобразовать в int64. TruffleRuby делает это с помощью деоптимизаций, как и V8.Скажем, если в Ruby задать
var = 0, вы получите int32 (в Ruby это называется Fixnum и Bignum, но я буду использовать обозначения int32 и int64). Выполняя операцию с var, вам нужно проверить, не возникает ли переполнения значения. Но одно дело проверить, а компилировать код, который обрабатывает переполнения, получается дорого, особенно учитывая частоту числовых операций.Даже не посмотрев на скомпилированные инструкции, можно увидеть, как как эта деоптимизация уменьшает объём кода.
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
В TruffleRuby деоптимизируется только первый прогон конкретной операции, так что мы не тратим на это ресурсы при каждом переполнении операции.
WET-код — быстрый код. Инлайнинг и OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
В V8 деоптимизируются даже такие тривиальности, как эти триггеры! С помощью опций вроде
--trace-deopt и --trace-opt вы можете собрать много информации о JIT, а также модифицировать поведение. В Graal есть очень полезные инструменты, но я буду пользоваться V8, потому что он у многих установлен.Деоптимизацию запускает последняя строка (
foo(1, 2)), что вызывает недоумение, ведь именно этот вызов сделан в цикле! Мы получим сообщение «Insufficient type feedback for call» (полный список причин деоптимизации лежит здесь, и в нём есть забавная причина «no reason»). В результате создаётся фрейм ввода, отображающий литералы 1 и 2.Так зачем деоптимизировать? V8 достаточно умён, чтобы выполнить приведение типов: когда
i относится к типу integer, литералы передаются тоже как integer.Чтобы разобраться в этом, давайте заменим последнюю строку на
foo(i, i +1). Но деоптимизация всё равно применяется, только в этот раз сообщение другое: «Insufficient type feedback for binary operation». ПОЧЕМУ?! Ведь это точно такая же операция, которая исполняется в цикле, с теми же переменными!Ответ, друг мой, кроется в замещении в стеке (on-stack replacement, OSR). Инлайнинг — это мощная оптимизация компилятора (не только JIT), при которой функции перестают быть функциями, а содержимое передаётся в места вызова. JIT-компиляторы для увеличения скорости могут инлайнить с помощью изменения кода в ходе исполнения (компилируемые языки могут инлайнить только статически).
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
Так что V8 скомпилирует
foo, определит, что её можно инлайнить, и инлайнит с помощью OSR. Однако движок делает это только для кода внутри цикла, потому что это горячий путь, а последняя строка ещё отсутствует в интерпретаторе на момент инлайнинга. Поэтому у V8 пока нет достаточно обратной связи о типе функции foo, ведь не она используется в цикле, а её инлайненная версия. Если применить --no-use-osr, тогда деоптимизации не будет, вне зависимости от того, что мы передадим, литерал или i. Однако без инлайнинга даже ничтожные миллион итераций будут работать заметно медленнее. JIT-компиляторы действительно воплощают принцип «решений нет, только компромиссы». Деоптимизации дороги, но они не идут в сравнение со стоимостью поиска методов и инлайнинга, предпочтительного в этом случае.Инлайнинг невероятно эффективен! Я запустил вышеприведённый код с парой дополнительных нулей, и при отключённом инлайнинге он работал вчетверо медленнее.

Хотя эта статья посвящена JIT, инлайнинг эффективен и в компилируемых языках. Все LLVM-языки активно применяют инлайнинг, потому что и LLVM тоже будет это делать, хотя Julia инлайнит и без LLVM, это в её природе. JIT могут инлайнить с помощью эвристик, получаемых в ходе исполнения, и способны переключаться между режимами без инлайнинга и с инлайнингом посредством OSR.
Заметка о JIT и LLVM
LLVM предоставляет кучу инструментов, связанных с компилированием. Julia работает с LLVM (обратите внимание, что это большой инструментарий, и каждый язык использует его по-разному), также, как и Rust, Swift и Crystal. Достаточно сказать, что это большой и замечательный проект, который также поддерживает JIT, хотя в LLVM нет значимых встроенных динамических JIT. На четвёртом уровне компилирования JavaScriptCore какое-то время использовался LLVM-бэкенд, но его заменили меньше двух лет назад. С тех пор этот инструментарий не слишком хорошо подходит для динамических JIT, в основном потому, что он не предназначен для работы в условиях динамичности. В Pypy его пытались применить 5-6 раз, но остановились на JSC. При использовании LLVM возможности allocation sinking и перемещения кода (code motion) были ограничены. Также невозможно было использовать мощные JIT-возможности вроде range-inferencing (это как приведение типов, но с известным диапазоном значения). Но куда важнее, что с LLVM на компилирование тратится очень много ресурсов.
А если вместо промежуточного представления на основе инструкций у нас будет большой граф, который модифицирует себя?
Мы поговорили об LLVM-байткоде и о Python/Ruby/Java-байткоде в качестве промежуточного представления. Все они выглядят как некий язык в виде инструкций. В Hotspot, Graal и V8 применяется промежуточное представление «Sea of Nodes» (появилось в Hotspot), которое является более низкоуровневым AST. Это эффективное представление, потому что значительная часть профилирования основана на представлении об определённом пути, который редко используется (или пересекается в случае какого-то шаблона). Обратите внимание, что эти AST компиляторов отличаются от AST парсеров.
Обычно я придерживаюсь позиции «попробуйте сделать дома!», но рассматривать графы довольно трудно, хотя и очень интересно, а зачастую и крайне полезно для понимания работы компилятора. Я, например, не могу прочитать все графики не только из-за нехватки знаний, но и из-за пределов вычислительных возможностей моего мозга (параметры компилятора могут помочь избавиться от поведения, которое меня не интересует).

В случае с V8 мы применим инструмент D8 с флагом
--print-ast. Для Graal это будет --vm.Dgraal.Dump=Truffle:2. На экран будет выводиться текст (отформатированный так, чтобы получался граф). Не знаю, как разработчики V8 генерируют визуальные графы, но в Oracle есть «Ideal Graph Visualizer», который применён на предыдущей иллюстрации. У меня не было сил переустанавливать IGV, поэтому я взял графы у Криса Ситона (Chris Seaton), сгенерированные с помощью Seafoam, чьи исходники сейчас закрыты.Ладно, давайте взглянем на JavaScript AST!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
Этот код я прогнал через
d8 --print-ast test.js, хотя нас интересует только функция accumulate. Посмотрите, что я вызвал её только один раз, то есть мне не нужно ждать выполнения компиляции, чтобы получить AST. Так выглядит AST (я убрал некоторые маловажные строки):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
Парсить такое сложно, но это похоже на AST парсера (верно не для всех программ). А следующее AST сгенерировано с помощью Acorn.js
Заметное отличие — определения переменных. В AST парсера нет явного определения параметров, а объявление цикла спрятано в ноду
ForStatement. В AST уровня компилятора все объявления сгруппированы с адресами и метаданными.AST компилятора также использует это дурацкое выражение
VAR PROXY. AST парсера не может определить связи между именами и переменными (по адресам) из-за поднятия переменных (hoisting), оценки (eval) и прочего. Так что AST компилятора использует переменные PROXY, которые позднее связываются с фактической переменной.// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
А так выглядит AST той же программы, полученное с помощью Graal!

Выглядит куда проще. Красным обозначен поток управления, синим — поток данных, стрелками — направления. Обратите внимание, что хотя этот граф проще, чем AST из V8, это не означает, что Graal лучше упростил программу. Просто он сгенерирован на основе Java, который куда менее динамичен. Тот же граф Graal, сгенерированный из Ruby, будет ближе к первой версии.
Забавно, что AST в Graal будут меняться в зависимости от исполнения кода. Этот граф сгенерирован с отключённым OSR и инлайнигом, при многократном вызове функции со случайными параметрами, чтобы она не была оптимизирована. И дамп снабдит вас целой пачкой графов! В Graal для оптимизации программ применяется специализированное AST (V8 делает аналогичные оптимизации, но не на уровне AST). Когда сохраняешь в Graal графы, то получаешь больше десяти схем с разными уровнями оптимизации. При перезаписи нод они заменяют себя (специализируют) другими нодами.
Вышеприведённый граф — прекрасный пример специализации при динамически типизируемом языке (картинка взята из «One VM to Rule Them All», 2013). Причина существования этого процесса тесно связана с тем, как работает частичная оценка — всё дело в специализации.
Ура JIT скомпилировал код! Давай скомпилируем снова! И снова!
Выше я упоминал про «многоуровневость», давайте уже об этом поговорим. Идея простая: если мы ещё не готовы создавать полностью оптимизированный код, но интерпретация до сих пор обходится дорого, мы можем выполнить предварительную компиляцию, а затем финальную, когда будем готовы сгенерировать более оптимизированный код.
Hotspot — это многоуровневый JIT с двумя компиляторами: C1 и C2. C1 выполняет быструю компиляцию и запускает код, затем проводит полное профилирование, чтобы получить скомпилированный с помощью С2 код. Это может помочь решить многие проблемы с прогревом. Не оптимизированный скомпилированный код всё-равно быстрее интерпретации. Кроме того, С1 и С2 компилируют не весь код. Если функция выглядит достаточно просто, с большой вероятностью С2 нам не поможет и даже не будет запускаться (ещё и сэкономим время на профилировании!). Если С1 занят компилированием, тогда профилирование может продолжиться, работа С1 будет прервана и запущено компилирование с помощью С2.

В JavaScript Core уровней ещё больше! П сути, там три JIT. Интерпретатор JSC выполняет лёгкое профилирование, затем переходит к Baseline JIT, затем к DFG (Data Flow Graph) JIT, и наконец к FTL (Faster than Light) JIT. С таким количеством уровней смысл деоптимизации больше не ограничивается переходом от компилятора к интерпретатору, деоптимизация может выполняться начиная с DFG и заканчивая Baseline JIT (это не так в случае Hotspot C2->C1). Все деоптимизации и переходы на следующий уровень выполняются с помощью OSR (замещения в стеке).
Baseline JIT подключается примерно после 100 исполнений, а DFG JIT — примерно после 1000 (с некоторыми исключениями). Это означает, что JIT получает скомпилированный код гораздо быстрее, чем тот же Pypy (у которого это занимает около 3000 исполнений). Многоуровневость позволяет JIT пытаться соотнести длительность исполнения кода с длительностью его оптимизации. Есть куча уловок, какой вид оптимизации (инлайнинг, приведение типов и т.д.) исполнять на каждом из уровней, и поэтому такая стратегия является оптимальной.
Полезные источники
- How LuaJIT's Trace Compiler Works from Mike Pall
- Impact of Meta-tracing on VMs by Laurie Tratt
- Pypy Escape Analysis
- Why Users aren't More Happy with VMs by Laurie Tratt
- Про JS-движки:
- Про деоптимизации:
- Про Graal:
- Про частичную оценку:
- Разное:
