В первой части мы разобрали «тройное рукопожатие» TCP и некоторые технологии — TCP Fast Open, контроль потока и перегрузкой и масштабирование окна. Во второй части узнаем, что такое TCP Slow Start, как оптимизировать скорость передачи данных и увеличить начальное окно, а также соберем все рекомендации по оптимизации TCP/IP стека воедино.
Медленный старт (Slow-Start)
Несмотря на присутствие контроля потока в TCP, сетевой коллапс накопления был реальной проблемой в середине 80-х. Проблема была в том, что хотя контроль потока не позволяет отправителю «утопить» получателя в данных, не существовало механизма, который бы не дал бы это сделать с сетью. Ведь ни отправитель, ни получатель не знают ширину канала в момент начала соединения, и поэтому им нужен какой-то механизм, чтобы адаптировать скорость под изменяющиеся условия в сети.
Например, если вы находитесь дома и скачиваете большое видео с удаленного сервера, который загрузил весь ваш даунлинк, чтобы обеспечить максимум скорости. Потом другой пользователь из вашего дома решил скачать объемное обновление ПО. Доступный канал для видео внезапно становится намного меньше, и сервер, отправляющий видео, должен изменить свою скорость отправки данных. Если он продолжит с прежней скоростью, данные просто «набьются в кучу» на каком-то промежуточном гейтвэе, и пакеты будут «роняться», что означает неэффективное использование сети.
В 1988 году Ван Якобсон и Майкл Дж. Карелс разработали для борьбы с этой проблемой несколько алгоритмов: медленный старт, предотвращение перегрузки, быстрая повторная передача и быстрое восстановление. Они вскоре стали обязательной частью спецификации TCP. Считается, что благодаря этим алгоритмам удалось избежать глобальных проблем с интернетом в конце 80-х/начале 90-х, когда трафик рос экспоненциально.
Чтобы понять, как работает медленный старт, вернемся к примеру с клиентом в Нью-Йорке, пытающемуся скачать файл с сервера в Лондоне. Сначала выполняется тройное рукопожатие, во время которого стороны обмениваются своими значениями окон приема в АСК-пакетах. Когда последний АСК-пакет ушел в сеть, можно начинать обмен данными.
Единственный способ оценить ширину канала между клиентом и сервером – измерить ее во время обмена данными, и это именно то, что делает медленный старт. Сначала сервер инициализирует новую переменную окна перегрузки (cwnd) для TCP-соединения и устанавливает ее значение консервативно, согласно системному значению (в Linux это initcwnd).
Значение переменной cwnd не обменивается между клиентом и сервером. Это будет локальная переменная для сервера в Лондоне. Далее вводится новое правило: максимальный объем данных «в пути» (не подтвержденных через АСК) между сервером и клиентом должно быть наименьшим значением из rwnd и cwnd. Но как серверу и клиенту «договориться» об оптимальных значениях своих окон перегрузки. Ведь условия в сети изменяются постоянно, и хотелось бы, чтобы алгоритм работал без необходимости подстройки каждого TCP-соединения.
Решение: начинать передачу с медленной скоростью и увеличивать окно по мере того, как прием пакетов подтверждается. Это и есть медленный старт.
Начальное значение cwnd исходно устанавливалось в 1 сетевой сегмент. В RFC 2581 это изменили на 4 сегмента, и далее в RFC 6928 – до 10 сегментов.
Таким образом, сервер может отправить до 10 сетевых сегментов клиенту, после чего должен прекратить отправку и ждать подтверждения. Затем, для каждого полученного АСК, сервер может увеличить свое значение cwnd на 1 сегмент. То есть на каждый подтвержденный через АСК пакет, два новых пакета могут быть отправлены. Это означает, что сервер и клиент быстро «занимают» доступный канал.
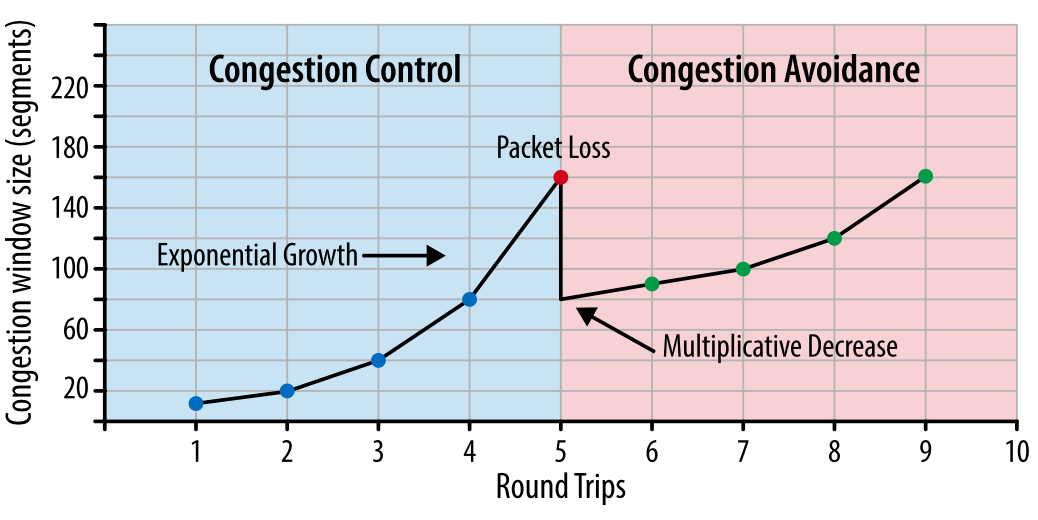
Рис. 1. Контроль за перегрузкой и ее предотвращение.
Каким же образом медленный старт влияет на разработку браузерных приложений? Поскольку каждое TCP-соединение должно пройти через фазу медленного старта, мы не можем сразу использовать весь доступный канал. Все начинается с маленького окна перегрузки, которое постепенно растет. Таким образом время, которое требуется, чтобы достичь заданной скорости передачи, — это функция от круговой задержки и начального значения окна перегрузки.
Время достижения значения cwnd, равного N.
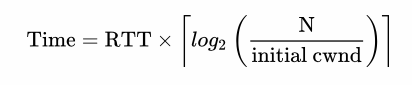
Чтобы ощутить, как это будет на практике, давайте примем следующие предположения:
- Окна приема клиента и сервера: 65 535 байт (64 КБ)
- Начальное значение окна перегрузки: 10 сегментов
- Круговая задержка между Лондоном и Нью-Йорком: 56 миллисекунд
Несмотря на окно приема в 64 КБ, пропускная способность TCP-соединения изначально ограничена окном перегрузки. Чтобы достичь предела в 64 КБ, окно перегрузки должно вырасти до 45 сегментов, что займет 168 миллисекунд.

Тот факт, что клиент и сервер могут быть способны обмениваться мегабитами в секунду между собой, не имеет никакого значения для медленного старта.
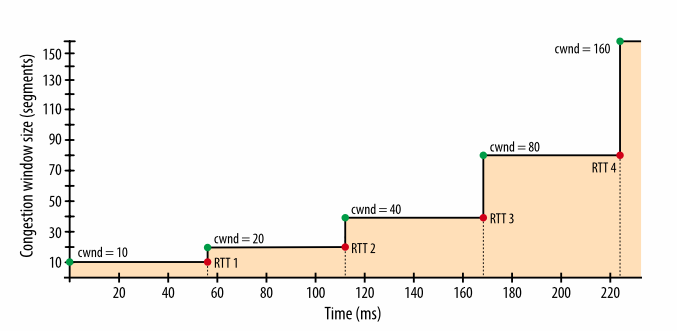
Рис. 2. Рост окна перегрузки.
Чтобы уменьшить время, которое требуется для достижения максимального значения окна перегрузки, можно уменьшить время, требуемое пакетам на путь «туда-обратно» — то есть расположить сервер географически ближе к клиенту.
Медленный старт мало влияет на скачивание крупных файлов или потокового видео, поскольку клиент и сервер достигнут максимальных значений окна перегрузки за несколько десятков или сотен миллисекунд, но это будет одним TCP-соединением.
Однако для многих HTTP-запросов, когда целевой файл относительно небольшой, передача может закончиться до того, как достигнут максимум окна перегрузки. То есть производительность веб-приложений зачастую ограничена временем круговой задержкой между сервером и клиентом.
Перезапуск медленного старта (Slow-Start Restart — SSR)
Дополнительно к регулированию скорости передачи в новых соединениях, TCP также предусматривает механизм перезапуска медленного старта, который сбрасывает значение окна перегрузки, если соединение не использовалось заданный период времени. Логика здесь в том, что условия в сети могли измениться за время бездействия в соединении, и чтобы избежать перегрузки, значение окна сбрасывается до безопасного значения.
Неудивительно, что SSR может оказывать серьезное влияние на производительность долгоживущих TCP-соединений, которые могут временно «простаивать», например, из-за бездействия пользователя. Поэтому лучше отключить SSR на сервере, чтобы улучшить производительность долгоживущих соединений. На Linux проверить статус SSR и отключить его можно следующими командами:
$> sysctl net.ipv4.tcp_slow_start_after_idle $> sysctl -w net.ipv4.tcp_slow_start_after_idle=0
Чтобы продемонстрировать влияние медленного старта на передачу небольшого файла, давайте представим, что клиент из Нью-Йорка запросил файл размером 64 КБ с сервера в Лондоне по новому TCP-соединению при следующих параметрах:
- Круговая задержка: 56 миллисекунд
- Пропускная способность клиента и сервера: 5 Мбит/с
- Окно приема клиента и сервера: 65 535 байт
- Начальное значение окна перегрузки: 10 сегментов (10 х 1460 байт = ~14 КБ)
- Время обработки на сервере для генерации ответа: 40 миллисекунд
- Пакеты не теряются, АСК на каждый пакет, запрос GET умещается в 1 сегмент
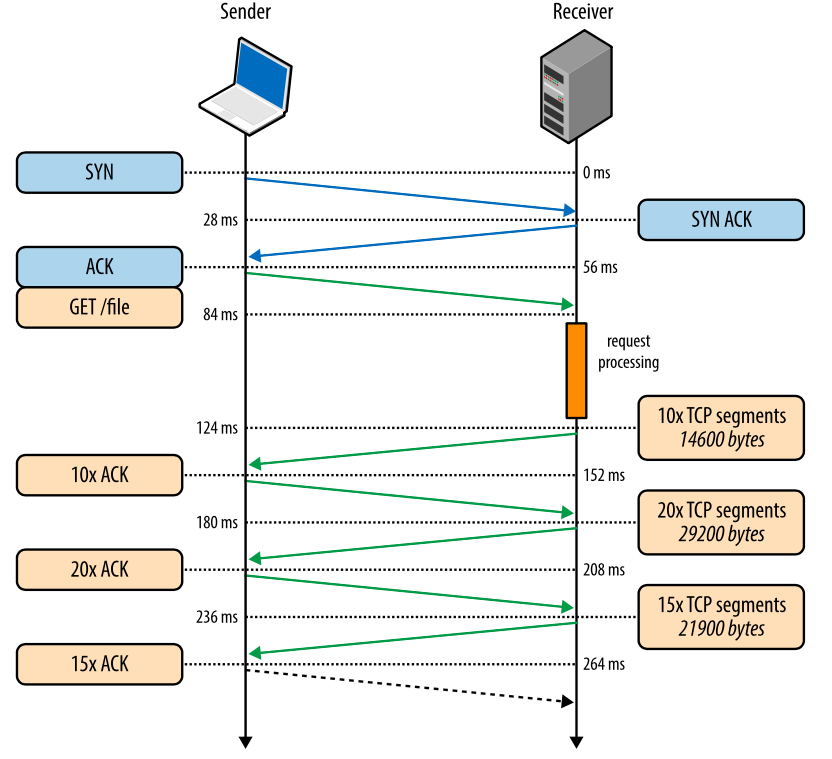
Рис. 3. Скачивание файла через новое TCP-соединение.
- 0 мс: клиент начинает TCP-хэндшейк SYN-пакетом
- 28 мс: сервер отправляет SYN-ACK и задает свой размер rwnd
- 56 мс: клиент подтверждает SYN-ACK, задает свой размер rwnd и сразу шлет запрос HTTP GET
- 84 мс: сервер получает HTTP-запрос
- 124 мс: сервер заканчивает создавать ответ размером 64 КБ и отправляет 10 TCP-сегментов, после чего ожидает АСК (начальное значение cwnd равно 10)
- 152 мс: клиент получает 10 TCP-сегментов и отвечает АСК на каждый
- 180 мс: сервер увеличивает cwnd на каждый полученный АСК и отправляет 20 TCP-сегментов
- 208 мс: клиент получает 20 TCP-сегментов и отвечает АСК на каждый
- 236 мс: сервер увеличивает cwnd на каждый полученный АСК и отправляет 15 оставшихся TCP-сегментов
- 264 мс: клиент получает 15 TCP-сегментов и отвечает АСК на каждый
264 миллисекунды занимает передача файла размеров 64 КБ через новое TCP-соединение. Теперь давайте представим, что клиент повторно использует то же соединение и делает такой же запрос еще раз.
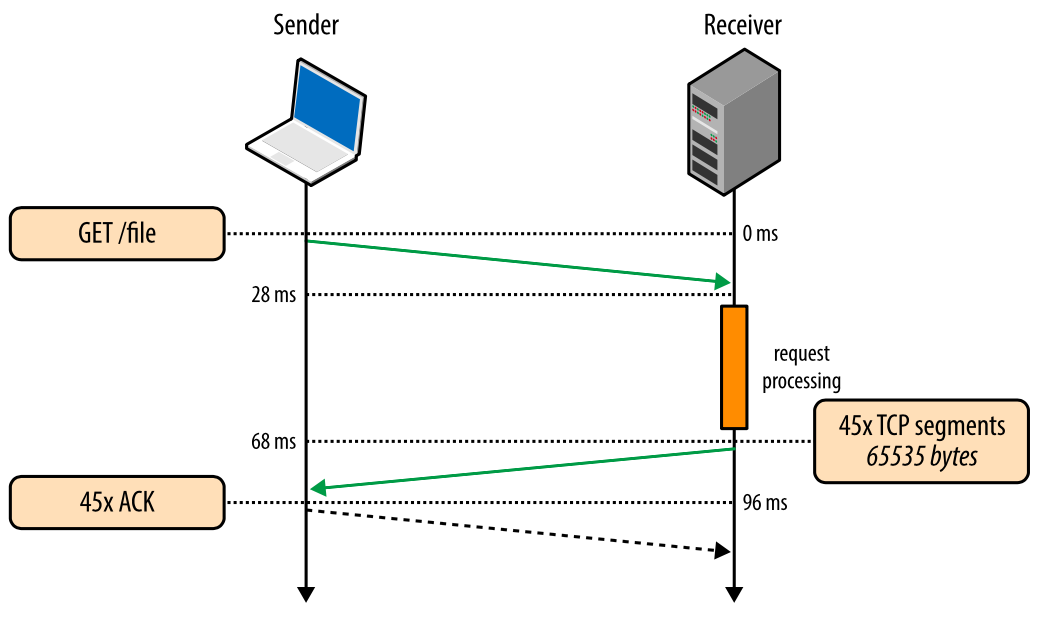
Рис. 4. Скачивание файла через существующее TCP-соединение.
- 0 мс: клиент отправляет НТТР-запрос
- 28 мс: сервер получает НТТР-запрос
- 68 мс: сервер генерирует ответ размером в 64 КБ, но значение cwnd уже больше, чем 45 сегментов, требуемых для отправки этого файла. Поэтому сервер отправляет все сегменты сразу
- 96 мс: клиент получает все 45 сегментов и отвечает АСК на каждый
Тот же самый запрос, сделанный через то же самое соединение, но без затрат времени на хэндшейк и на наращивание пропускной способности через медленный старт, теперь исполняется за 96 миллисекунд, то есть на 275% быстрее!
В обоих случаях тот факт, что клиент и сервер пользуются каналом с пропускной способностью 5 Мбит/с, не оказал никакого влияния на время скачивания файла. Только размеры окон перегрузки и сетевая задержка были ограничивающими факторами. Интересно, что разница в производительности при использовании нового и существующего TCP-соединений будет увеличиваться, если сетевая задержка будет расти.
Как только вы осознаете проблемы с задержками при создании новых соединений, у вас сразу появится желание использовать такие методы оптимизации, как удержание соединения (keepalive), конвейеризация пакетов (pipelining) и мультиплексирование.
Увеличение начального значения окна перегрузки TCP
Это самый простой способ увеличения производительности для всех пользователей или приложений, использующих TCP. Многие операционные системы уже используют новое значение равное 10 в своих обновлениях. Для Linux 10 – значение по умолчанию для окна перегрузки, начиная с версии ядра 2.6.39.
Предотвращение перегрузки
Важно понимать, что TCP использует потерю пакетов как механизм обратной связи, который помогает регулировать производительность. Медленный старт создает соединение с консервативным значением окна перегрузки и пошагово удваивает количество передаваемых за раз данных, пока оно не достигнет окна приема получателя, системного порога sshtresh или пока пакеты не начнут теряться, после чего и включается алгоритм предотвращения перегрузки.
Предотвращение перегрузки построено на предположении, что потеря пакета является индикатором перегрузки в сети. Где-то на пути движения пакетов на линке или на роутере скопились пакеты, и это означает, что нужно уменьшить окно перегрузки, чтобы предотвратить дальнейшее «забитие» сети трафиком.
После того как окно перегрузки уменьшено, применяется отдельный алгоритм для определения того, как должно далее увеличиваться окно. Рано или поздно случится очередная потеря пакета, и процесс повторится. Если вы когда-либо видели похожий на пилу график проходящего через TCP-соединение трафика – это как раз потому, что алгоритмы контроля и предотвращения перегрузки подстраивают окно перегрузки в соответствии с потерями пакетов в сети.
Стоит заметить, что улучшение этих алгоритмов является активной областью как научных изысканий, так и разработки коммерческих продуктов. Существуют варианты, которые лучше работают в сетях определенного типа или для передачи определенного типа файлов и так далее. В зависимости от того, на какой платформе вы работаете, вы используете один из многих вариантов: TCP Tahoe and Reno (исходная реализация), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (по умолчанию на Linux) или Compound TCP (по умолчанию на Windows) и многие другие. Независимо от конкретной реализации, влияния этих алгоритмов на производительность веб-приложений похожи.
Пропорциональное снижение скорости для TCP
Определение оптимального способа восстановления после потери пакета – не самая тривиальная задача. Если вы слишком «агрессивно» реагируете на это, то случайная потеря пакета окажет чрезмерно негативное воздействие на скорость соединения. Если же вы не реагируете достаточно быстро, то, скорее всего, это вызовет дальнейшую потерю пакетов.
Изначально в TCP применялся алгоритм кратного снижения и последовательного увеличения (Multiplicative Decrease and Additive Increase — AIMD): когда теряется пакет, то окно перегрузки уменьшается вдвое, и постепенно увеличивается на заданную величину с каждым проходом пакетов «туда-обратно». Во многих случаях AIMD показал себя как чрезмерно консервативный алгоритм, поэтому были разработаны новые.
Пропорциональное снижение скорости (Proportional Rate Reduction – PRR) – новый алгоритм, описанный в RFC 6937, цель которого является более быстрое восстановление после потери пакета. Согласно замерам Google, где алгоритм и был разработан, он обеспечивает сокращение сетевой задержки в среднем на 3-10% в соединениях с потерями пакетов. PPR включен по умолчанию в Linux 3.2 и выше.
Произведение ширины канала на задержку (Bandwidth-Delay Product – BDP)
Встроенные механизмы борьбы с перегрузкой в TCP имеют важное следствие: оптимальные значения окон для получателя и отправителя должны изменяться согласно круговой задержке и целевой скорости передачи данных. Вспомним, что максимально количество неподтвержденных пакетов «в пути» определено как наименьшее значение из окон приема и перегрузки (rwnd и cwnd). Если у отправителя превышено максимальное количество неподтвержденных пакетов, то он должен прекратить передачу и ожидать, пока получатель не подтвердит какое-то количество пакетов, чтобы отправитель мог снова начать передачу. Сколько он должен ждать? Это определяется круговой задержкой.
BDP определяет, какой максимальный объем данных может быть «в пути»
Если отправитель часто должен останавливаться и ждать АСК-подтверждения ранее отправленных пакетов, это создаст разрыв в потоке данных, который будет ограничивать максимальную скорость соединения. Чтобы избежать этой проблемы, размеры окон должны быть установлены достаточно большими, чтобы можно было отсылать данные, ожидая поступления АСК-подтверждений по ранее отправленным пакетам. Тогда будет возможна максимальная скорость передачи, никаких разрывов. Соответственно, оптимальный размер окна зависит от скорости круговой задержки.
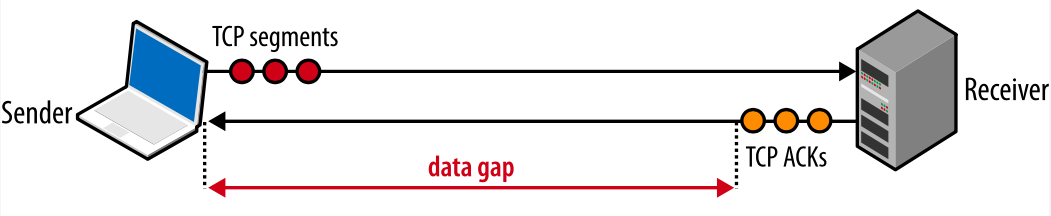
Рис. 5. Разрыв в передаче из-за маленьких значений окон.
Насколько же большими должны быть значения окон приема и перегрузки? Разберем на примере: пусть cwnd и rwnd равны 16 КБ, а круговая задержка равна 100 мс. Тогда:
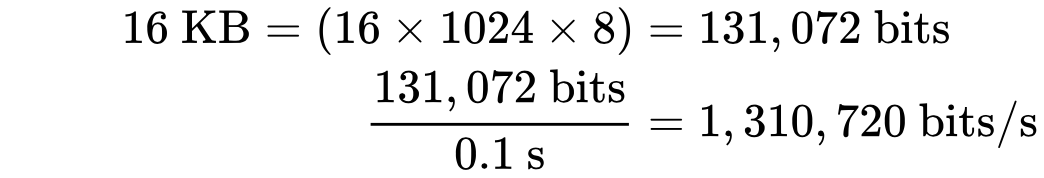
Получается, что какая бы ни была ширина канала между отправителем и получателем, такое соединение никогда не даст скорость больше, чем 1,31 Мбит/с. Чтобы добиться большей скорости, надо или увеличить значение окон, или уменьшить круговую задержку.
Похожим образом мы можем вычислить оптимальное значение окон, зная круговую задержку и требуемую ширину канала. Примем, что время останется тем же (100 мс), а ширина канала отправителя 10 Мбит/с, а получатель находится на высокоскоростном канале в 100 Мбит/с. Предполагая, что у сети между ними нет проблем на промежуточных участках, мы получаем для отправителя:
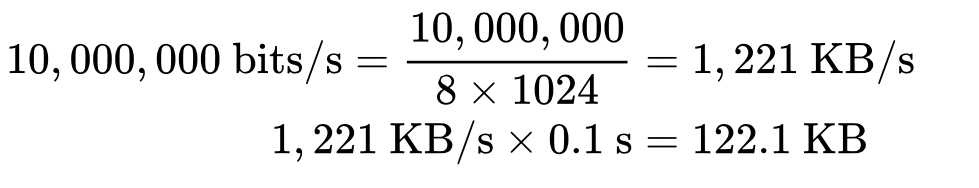
Размер окна должен быть как минимум 122,1 КБ, чтобы полностью занять канал на 10 Мбит/с. Вспомните, что максимальный размер окна приема в TCP равен 64 КБ, если только не включено масштабирование окна (RFC 1323). Еще один повод перепроверить настройки!
Хорошая новость в том, что согласование размеров окон автоматически делается в сетевом стэке. Плохая новость в том, что иногда это может быть ограничивающим фактором. Если вы когда-либо задумывались, почему ваше соединение передает со скоростью, которая составляет лишь небольшую долю от имеющейся ширины канала, это происходит, скорее всего, из-за малого размера окон.
BDP в высокоскоростных локальных сетях
Круговая задержка может являться узким местом и в локальных сетях. Чтобы достичь 1 Гбит/с при круговой задержке в 1 мс, необходимо иметь окно перегрузки не менее чем 122 КБ. Вычисления аналогичны показанным выше.
Блокировка начала очереди (Head-of-line blocking – HOL blocking)
Хотя TCP – популярный протокол, он не является единственным, и не всегда – самым подходящим для каждого конкретного случая. Такие его особенности, как доставка по порядку, не всегда необходимы, и иногда могут увеличить задержку.
Каждый TCP-пакет содержит уникальный номер последовательности, и данные должны поступать по порядку. Если один из пакетов был потерян, то все последующие пакеты хранятся в TCP-буфере получателя, пока потерянный пакет не будет повторно отправлен и не достигнет получателя. Поскольку это происходит в TCP-слое, приложение «не видит» эти повторные отправки или очередь пакетов в буфере, и просто ждет, пока данные не будут доступны. Все, что «видит» приложение – это задержка, возникающая при чтении данных из сокета. Этот эффект известен как блокировка начала очереди.
Блокировка начала очереди освобождает приложения от необходимости заниматься упорядочиванием пакетов, что упрощает код. Но с другой стороны, появляется непредсказуемая задержка поступления пакетов, что негативно влияет на производительность приложений.
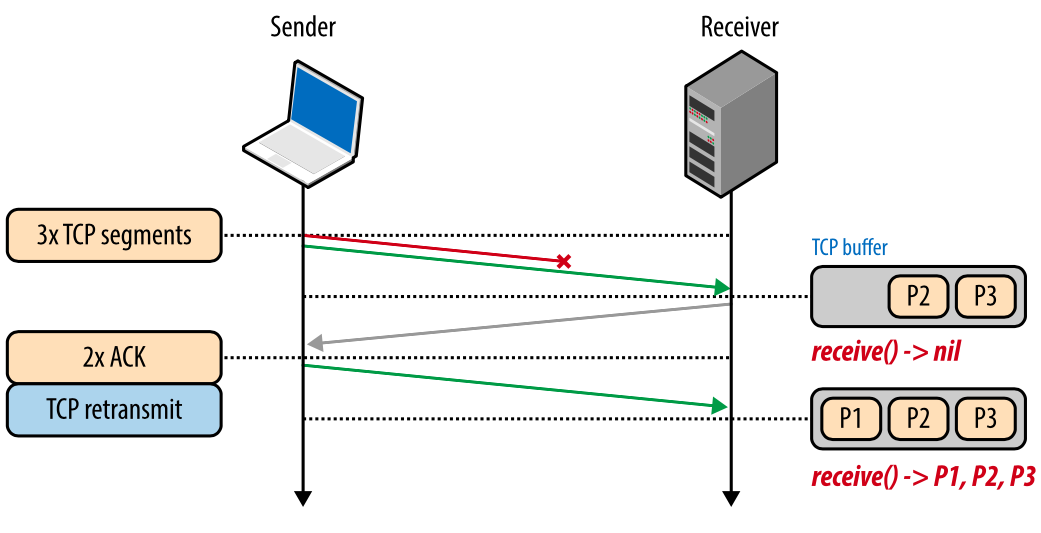
Рис. 6. Блокировка начала очереди.
Некоторым приложениям может не требоваться гарантированная доставка или доставка по порядку. Если каждый пакет – это отдельное сообщение, то доставка по порядку не нужна. А если каждое новое сообщение перезаписывает предыдущие, то и гарантированная доставка также не нужна. Но в TCP нет конфигурации для таких случаев. Все пакеты доставляются по очереди, а если какой-то не доставлен, он отправляется повторно. Приложения, для которых задержка критична, могут использовать альтернативный транспорт, например, UDP.
Потеря пакетов – это нормально
Потеря пакетов даже нужна для того, чтобы обеспечить лучшую производительность TCP. Потерянный пакет работает как механизм обратной связи, который позволяет получателю и отправителю изменить скорость отправки, чтобы избежать перегрузки сети и минимизировать задержку.
Некоторые приложения могут «справиться» с потерей пакета: например, для проигрывания аудио, видео или для передачи состояния в игре, гарантированная доставка или доставка по порядку не обязательны. Поэтому WebRTC использует UDP в качестве основного транспорта.
Если при проигрывании аудио произошла потеря пакета, аудио кодек может просто вставить небольшой разрыв в воспроизведение и продолжать обрабатывать поступающие пакеты. Если разрыв небольшой, пользователь может его и не заметить, а ожидание доставки потерянного пакета может привести к заметной задержке воспроизведения, что будет гораздо хуже для пользователя.
Аналогично, если игра передает свои состояния, то нет смысла ждать пакет, описывающий состояние в момент времени T-1, если у нас уже есть информация о состоянии в момент времени T.
Оптимизация для TCP
TCP – это адаптивный протокол, разработанный для того, чтобы максимально эффективно использовать сеть. Оптимизация для TCP требует понимания того, как TCP реагирует на условия в сети. Приложениям может понадобиться собственный метод обеспечения заданного качества (QoS), чтобы обеспечить стабильную работу для пользователей.
Требования приложений и многочисленные особенности алгоритмов TCP делает их взаимную увязку и оптимизацию в этой области огромным полем для изучения. В этой статье мы лишь коснулись некоторых факторов, которые влияют на производительность TCP. Дополнительные механизмы, такие как выборочные подтверждения (SACK), отложенные подтверждения, быстрая повторная передача и многие другие осложняют понимание и оптимизацию TCP-сессий.
Хотя конкретные детали каждого алгоритма и механизма обратной связи будут продолжать изменяться, ключевые принципы и их последствия останутся:
- Тройное рукопожатие TCP несет серьезную задержку;
- Медленный старт TCP применяется к каждому новому соединению;
- Механизмы контроля потока и перегрузки TCP регулируют пропускную способность всех соединений;
- Пропускная способность TCP регулируется через размер окна перегрузки.
В результате скорость, с которой в TCP-соединении могут передаваться данные в современных высокоскоростных сетях зачастую ограничена круговой задержкой. В то время как ширина каналов продолжает расти, задержка ограничена скоростью света, и во многих случаях именно задержка, а не ширина канала является «узким местом» для TCP.
Настройка конфигурации сервера
Вместо того, чтобы заниматься настройкой каждого отдельного параметра TCP, лучше начать с обновления до последней версии операционной системы. Лучшие практики в работе с TCP продолжают развиваться, и большинство этих изменений уже доступно в последних версиях ОС.
«Обновить ОС на сервере» кажется тривиальным советом. Но на практике многие серверы настроены под определенную версию ядра, и системные администраторы могут быть против обновлений. Да, обновление несет свои риски, но в плане производительности TCP, это, скорее всего, будет самым эффективным действием.
После обновления ОС вам нужно сконфигурировать сервер в соответствии с лучшими практиками:
- Увеличить начальное значение окна перегрузки: это позволит передать больше данных в первом обмене и существенно ускоряет рост окна перегрузки
- Отключить медленный старт: отключение медленного старта после периода простоя соединения улучшит производительность долгоживущих TCP-соединений
- Включить масштабирование окна: это увеличит максимальное значение окна приема и позволит ускорить соединения, где задержка велика
- Включить TCP Fast Open: это даст возможность отправлять данные в начальном SYN-пакете. Это новый алгоритм, его должны поддерживать и клиент и сервер. Изучите, может ли ваше приложение извлечь из него пользу.
Возможно вам понадобится также настроить и другие TCP-параметры. Обратитесь к материалу «TCP Tuning for HTTP», который регулярно обновляется Рабочей группой по HTTP.
Для пользователей Linux ss поможет проверить различную статистику открытых сокетов. В командной строке наберите
ss --options --extended --memory --processes --info
и вы увидите текущие одноранговые соединения (peers) и их настройки.
Настройка приложения
То, как приложение использует соединения может иметь огромное влияние на производительность:
- Любая передача данных занимает время >0. Ищите способы уменьшить объем отправляемых данных.
- Приблизьте ваши данные к клиентам географически
- Повторное использование TCP-соединений может быть важнейшим моментом в улучшении производительности.
Исключение ненужной передачи данных, это, конечно, самый важный вид оптимизации. Если же определенные данные все же нужно передавать, важно убедиться, что для них используется подходящий алгоритм сжатия.
Перенос данных поближе к клиентам посредством размещения серверов по всему миру либо с использованием CDN, поможет уменьшить круговую задержку и значительно повысит производительность TCP.
И наконец, во всех случаях, где это возможно, существующие соединения TCP должны использоваться повторно, чтобы избежать задержек, вызванных алгоритмом медленного старта и контроля перегрузки.
В заключение, вот контрольный список того, что нужно сделать для оптимизации TCP:
- Обновите ОС сервера
- Убедитесь, что параметр cwnd установлен равным 10
- Убедитесь, что масштабирование окон включено
- Отключите медленный старт после простоя соединения
- Включите TCP Fast Open, если это возможно
- Исключите передачу ненужных данных
- Сжимайте передаваемые данные
- Расположите серверы ближе к клиентам географически, чтобы снизить круговую задержку
- Используйте повторно TCP-соединения, где это возможно
- Изучите рекомендации Рабочей группы по HTTP
