Перевод поста Стивена Вольфрама (Stephen Wolfram) "Mathematical Notation: Past and Future (2000)".
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе и подготовке публикации
Содержание
Резюме
Введение
История
Компьютеры
Будущее
Примечания
— Эмпирические законы для математических обозначений
— Печатные обозначения против экранных
— Письменные обозначения
— Шрифты и символы
— Поиск математических формул
— Невизуальные обозначения
— Доказательства
— Отбор символов
— Частотное распределение символов
— Части речи в математической нотации
Стенограмма речи, представленной на секции «MathML и математика в сети» первой Международной Конференции MathML в 2000-м году.
Резюме
Большинство математических обозначений существуют уже более пятисот лет. Я рассмотрю, как они разрабатывались, что было в античные и средневековые времена, какие обозначения вводили Лейбниц, Эйлер, Пеано и другие, как они получили распространение в 19 и 20 веках. Будет рассмотрен вопрос о схожести математических обозначений с тем, что объединяет обычные человеческие языки. Я расскажу об основных принципах, которые были обнаружены для обычных человеческих языков, какие из них применяются в математических обозначениях и какие нет.
Согласно историческим тенденциям, математическая нотация, как и естественный язык, могла бы оказаться невероятно сложной для понимания компьютером. Но за последние пять лет мы внедрили в Mathematica возможности к пониманию чего-то очень близкого к стандартной математической нотации. Я расскажу о ключевых идеях, которые сделали это возможным, а также о тех особенностях в математических обозначениях, которые мы попутно обнаружили.
Большие математические выражения — в отличии от фрагментов обычного текста — часто представляют собой результаты вычислений и создаются автоматически. Я расскажу об обработке подобных выражений и о том, что мы предприняли для того, чтобы сделать их более понятными для людей.
Традиционная математическая нотация представляет математические объекты, а не математические процессы. Я расскажу о попытках разработать нотацию для алгоритмов, об опыте реализации этого в APL, Mathematica, в программах для автоматических доказательств и других системах.
Обычный язык состоит их строк текста; математическая нотация часто также содержит двумерные структуры. Будет обсуждён вопрос о применении в математической нотации более общих структур и как они соотносятся с пределом познавательных возможностей людей.
Сфера приложения конкретного естественного языка обычно ограничивает сферу мышления тех, кто его использует. Я рассмотрю то, как традиционная математическая нотация ограничивает возможности математики, а также то, на что могут быть похожи обобщения математики.
Введение
Когда собиралась эта конференция, люди подумали, что было бы здорово пригласить кого-то для выступления с речью об основаниях и общих принципах математической нотации. И был очевидный кандидат — Флориан Каджори — автор классической книги под названием «История математических обозначений». Но после небольшого расследования оказалось, что есть техническая проблема в приглашении доктора Каджори — он умер как минимум лет семьдесят назад.
Так что мне придётся его заменять.
Полагаю, других вариантов особо-то и не было. Поскольку оказывается, что нет почти никого, кто жив на данный момент и кто занимался фундаментальными исследованиями математической нотации.
В прошлом математической нотацией занимались обычно в контексте систематизации математики. Так, Лейбниц и некоторые другие люди интересовались подобными вещами в середине 17 века. Бэббидж написал тяжеловесный труд по этой теме в 1821 году. И на рубеже 19 и 20 веков, в период серьёзного развития абстрактной алгебры и математической логики, происходит очередной всплеск интереса и деятельности в этой теме. Но после этого не было почти ничего.
Однако не особо удивительно, что я стал интересоваться подобными вещами. Потому что с Mathematica одной из моих главных целей было сделать ещё один большой шаг в области систематизации математики. А более общей моей целью в отношении Mathematica было распространить вычислительную мощь на все виды технической и математической работы. Эта задача имеет две части: то, как вычисления происходят внутри, и то, как люди направляют эти вычисления для получения того, что они хотят.
Одно из самых больших достижений Mathematica, о котором, вероятно, большинство из вас знает, заключается в сочетании высокой общности вычислений изнутри и сохранении практичности, основанной на преобразованиях символьных выражений, где символьные выражения могут представлять данные, графику, документы, формулы — да что угодно.
Однако недостаточно просто проводить вычисления. Необходимо так же, чтобы люди каким-то образом сообщали Mathematica о том, какие вычисления они хотят произвести. И основной способ дать людям взаимодействовать с чем-то столь сложным — использовать что-то вроде языка.
Обычно языки появляются в ходе некоторого поэтапного исторического процесса. Но компьютерные языки в историческом плане сильно отличаются. Многие были созданы практически полностью разом, зачастую одним человеком.
Так что включает в себя эта работа?
Ну, вот в чём заключалась для меня эта работа в отношении Mathematica: я попробовал представить, какие вообще вычисления люди будут производить, какие фрагменты в этой вычислительной работе повторяются снова и снова. А затем, собственно, я дал имена этим фрагментам и внедрил в качестве встроенных функций в Mathematica.
В основном мы отталкивались от английского языка, так как имена этих фрагментов основаны на простых английских словах. То есть это значит, что человек, который просто знает английский, уже сможет кое-что понять из написанного в Mathematica.
Однако, разумеется, язык Mathematica — не английский. Это скорее сильно адаптированный фрагмент английского языка, оптимизированный для передачи информации о вычислениях в Mathematica.
Можно было бы думать, что, пожалуй, было бы неплохо объясняться с Mathematica на обычном английском языке. В конце концов, мы уже знаем английский язык, так что нам было бы необязательно изучать что-то новое, чтобы объясняться с Mathematica.
Однако я считаю, что есть весьма весомые причины того, почему лучше думать на языке Mathematica, чем на английском, когда мы размышляем о разного рода вычислениях, которые производит Mathematica.
Однако мы так же знаем, заставить компьютер полностью понимать естественный язык — задача крайне сложная.
Хорошо, так что насчёт математической нотации?
Большинство людей, которые работают в Mathematica, знакомы по крайней мере с некоторыми математическими обозначениями, так что, казалось бы, было бы весьма удобно объясняться с Mathematica в рамках привычной математической нотации.
Но можно было бы подумать, что это не будет работать. Можно было бы подумать, что ситуация выльется в нечто, напоминающее ситуацию с естественными языками.
Однако есть один удивительный факт — он весьма удивил меня. В отличие от естественных человеческих языков, для обычной математической нотации можно сделать очень хорошее приближение, которое компьютер сможет понимать. Это одна из самых серьёзных вещей, которую мы разработали для третьей версии Mathematica в 1997 году [текущая версия Wolfram Mathematica — 10.4.1 — вышла в апреле 2016 г. — прим. ред.]. И как минимум некоторая часть того, что у нас получилось, вошла в спецификацию MathML.
Сегодня я хочу поговорить о некоторых общих принципах в математической нотации, которые мне довелось обнаружить, и то, что это означает в контексте сегодняшних дней и будущего.
В действительности, это не математическая проблема. Это куда ближе к лингвистике. Речь не о том, какой бы могла быть математическая нотация, а о том, какова используемая математическая нотация в действительности — как она развивалась в ходе истории и как связана с ограничениями человеческого познания.
Я думаю, математическая нотация — весьма интересное поле исследования для лингвистики.
Как можно было заметить, лингвистика в основном изучала разговорные языки. Даже пунктуация осталась практически без внимания. И, насколько мне известно, никаких серьёзных исследований математической нотации с точки зрения лингвистики никогда не проводилось.
Обычно в лингвистике выделяют несколько направлений. В одном занимаются вопросами исторических изменений в языках. В другом изучается то, как влияет изучение языка на отдельных людей. В третьем создаются эмпирические модели каких-то языковых структур.
История
Давайте сперва поговорим об истории.
Откуда произошли все те математические обозначения, которые мы в настоящее время используем?
Это тесно связано с историей самой математики, так что нам придётся коснуться немного этого вопроса. Часто можно услышать мнение, что сегодняшняя математика есть единственная мыслимая её реализация. То, какими бы могли быть произвольные абстрактные построения.
И за последние девять лет, что я занимался одним большим научным проектом, я ясно понял, что такой взгляд на математику не является верным. Математика в том виде, в котором она используется — это учение не о произвольных абстрактных системах. Это учение о конкретной абстрактной системе, которая исторически возникла в математике. И если заглянуть в прошлое, то можно увидеть, что есть три основные направления, из которых появилась математика в том виде, в котором мы сейчас её знаем — это арифметика, геометрия и логика.
Все эти традиции довольно стары. Арифметика берёт своё начало со времён древнего Вавилона. Возможно, и геометрия тоже приходит из тех времён, но точно уже была известна в древнем Египте. Логика приходит из древней Греции.
И мы можем наблюдать, что развитие математической нотации — языка математики — сильно связано с этими направлениями, особенно с арифметикой и логикой.
Следует понимать, что все три направления появлялись в различных сферах человеческого бытия, и это сильно повлияло на используемые в них обозначения.
Арифметика, вероятно, возникла из нужд торговли, для таких вещей, как, к примеру, счёт денег, а затем арифметику подхватили астрология и астрономия. Геометрия, по всей видимости, возникла из землемерческих и подобных задач. А логика, как известно, родилась из попытки систематизировать аргументы, приведённые на естественном языке.
Примечательно, кстати, что другая, очень старая область знаний, о которой я упомяну позднее — грамматика — по сути никогда не интегрировалась с математикой, по крайней мере до совсем недавнего времени.
Итак, давайте поговорим о ранних традициях в обозначениях в математике.
Во-первых, есть арифметика. И самая базовая вещь для арифметики — числа. Так какие обозначения использовались для чисел?
Что ж, первое представление чисел, о котором доподлинно известно — высечки на костях, сделанные 25 тысяч лет назад. Это была унарная система: чтобы представить число 7, нужно было сделать 7 высечек, ну и так далее.
Конечно, мы не можем точно знать, что именно это представление чисел было самым первым. Я имею ввиду, что мы могли и не найти свидетельств каких-то других, более ранних представлений чисел. Однако, если кто-то в те времена изобрёл какое-то необычное представление для чисел, и разместил их, к примеру, в наскальной живописи, то мы можем никогда и не узнать, что это было представление чисел — мы можем воспринимать это просто как какие-то фрагменты украшений.
Таким образом, числа можно представлять в унарной форме. И такое впечатление, что эта идея возрождалась множество раз и в различных частях света.
Но если посмотреть на то, что произошло помимо этого, то можно обнаружить довольно много различий. Это немного напоминает то, как различные виды конструкций для предложений, глаголов и прочее реализованы в различных естественных языках.
И, фактически, один из самых важных вопросов относительно чисел, который, как я полагаю, будет всплывать ещё много раз — насколько сильным должно быть соответствие между обычным естественным языком и языком математики?
Или вот вопрос: он связан с позиционной нотацией и повторным использованием цифр.
Как можно заметить, в естественных языках обычно есть такие слова, как "десять", "сто", "тысяча", "миллион" и так далее. Однако в математике мы можем представить десять как "один нуль" (10), сто как "один нуль нуль" (100), тысячу как "один нуль нуль нуль" (1000) и так далее. Мы можем повторно использовать эту одну цифру и получать что-то новое, в зависимости от того, где в числе она будет появляться.
Что ж, это сложная идея, и людям потребовались тысячи лет, чтобы её действительно принять и осознать. А их неспособность принять её ранее имела большие последствия в используемых ими обозначениях как для чисел, так и для других вещей.
Как это часто бывает в истории, верные идеи появляются очень рано и долгое время остаются в забвении. Более пяти тысяч лет назад вавилоняне, и возможно даже до них ещё и шумеры разработали идею о позиционном представлении чисел. Их система счисления была шестидесятеричная, а не десятичная, как у нас. От них мы унаследовали представление секунд, минут и часов в существующей ныне форме. Но у них была идея использования одних и тех же цифр для обозначения множителей различных степеней шестидесяти.
Вот пример их обозначений.

Из этой картинки можно понять, почему археология столь трудна. Это очень маленький кусок обожжённой глины. Было найдено около полумиллиона подобных вавилонских табличек. И примерно одна из тысячи — то есть всего около 400 — содержат какие-то математические записи. Что, кстати, выше отношения математических текстов к обычным в современном интернете. Вообще, пока MathML не получил достаточного распространения, это является достаточно сложным вопросом.
Но, в любом случае, маленькие обозначения на этой табличке выглядят слегка похожими на отпечатки лапок крошечных птиц. Но почти 50 лет назад в конце концов исследователи определили, что эта клинописная табличка времён Хаммурапи — около 1750 года до н.э. — фактически является таблицей того, что мы сейчас называем пифагорейскими тройками.
Что ж, эти вавилонские знания были утеряны для человечества почти на 3000 лет. И вместо этого использовались схемы, основанные на естественных языках, с отдельными символами для десяти, ста и так далее.
Так, к примеру, у египтян для обозначения тысячи использовался символ цветка лотоса, для сотни тысяч — птица, ну и так далее. Каждая степень десяти для её обозначения имела отдельный символ.
А затем появилась другая очень важная идея, до которой не додумались ни вавилоняне, ни египтяне. Она заключалась в обозначении чисел цифрами — то есть не обозначать число семь семью единицами чего-то, а лишь одним символом.
Однако, у греков, возможно, как и у финикийцев ранее, эта идея уже была. Ну, на самом деле, она была несколько отличной. Она заключалась в том, чтобы обозначать последовательность чисел через последовательность букв в их алфавите. То есть альфе соответствовала единица, бете — двойка и так далее.
Вот как выглядит список чисел в греческом обозначении [вы можете скачать Wolfram Language Package, позволяющий представить числа в различных древних нотациях здесь — прим. ред.].

(Думаю, именно так сисадмины из Академии Платона адаптировали бы свою версию Mathematica; их воображаемую -600-ю (или около того) версию Mathematica.)
С этой системой счисления сопряжено множество проблем. Например, есть серьёзная проблема управления версиями: даже если вы решаете удалить какие-то буквы из своего алфавита, то вы должны оставить их в числах, иначе все ваши ранее записанные числа будут некорректными.
То есть это значит, что есть различные устаревшие греческие буквы, оставшиеся в системе счисления — как коппа для обозначения числа 90 и сампи для обозначения числа 900. Однако я включил их в набор символов для Mathematica, потому здесь прекрасно работает греческая форма записи чисел.
Спустя некоторое время римляне разработали свою форму записи чисел, с которой мы хорошо знакомы.
Пускай сейчас и не совсем ясно, что их цифры изначально задумывались как буквы, однако об этом следует помнить.
Итак, давайте попробуем римскую форму записи чисел.

Это тоже довольно неудобный способ записи, особенно для больших чисел.
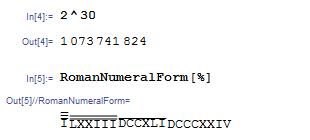
Тут есть несколько интересных моментов. К примеру, длина представляемого числа рекурсивно возрастает с размером числа.
И в целом, подобное представление для больших чисел полно неприятных моментов. К примеру, когда Архимед писал свою работу о количестве песчинок, объём которых эквивалентен объёму вселенной (Архимед оценил их количество в 1051, однако, полагаю, правильный ответ будет около 1090), то он использовал обычные слова вместо обозначений, чтобы описать столь большое число.
Но на самом деле есть более серьёзная понятийная проблема с идеей о представлении цифр как букв: становится трудно придумать представление символьных переменных — каких-то символьных объектов, за которыми стоят числа. Потому что любую букву, которую можно было бы использовать для этого символьного объекта, можно будет спутать с цифрой или фрагментом числа.
Общая идея о символьном обозначении каких-то объектов через буквы известна довольно давно. Евклид, по сути, использовал эту идею в своих трудах по геометрии.
К сожалению, не сохранилось оригиналов работ Евклида. Однако имеются на несколько сот лет более молодые версии его работ. Вот одна, написанная на греческом языке.

И на этих геометрических фигурах можно увидеть точки, которые имеют символьное представление в виде греческих букв. И в описании теорем есть множество моментов, в которых точки, линии и углы имеют символьное представление в виде букв. Так что идея о символьном представлении каких-то объектов в виде букв берёт своё начало как минимум от Евклида.
Однако эта идея могла появиться и раньше. Если бы я умел читать на вавилонском, я бы, вероятно, смог бы сказать вам точно. Вот вавилонская табличка, в которой представляется квадратный корень из двух, и которая использует вавилонские буквы для обозначений.

Полагаю, обожжённая глина более долговечна, чем папирус, и получается, что мы знаем о том, что писали вавилоняне больше, чем о том, что писали люди вроде Евклида.
Вообще, эта неспособность увидеть возможность вводить имена для числовых переменных есть интересный случай, когда языки или обозначения ограничивают наше мышление. Это то, что несомненно обсуждается в обычной лингвистике. В наиболее распространённой формулировке эта идея звучит как гипотеза Сепира-Уорфа (гипотеза лингвистической относительности).
Разумеется, для тех из нас, кто потратил некоторую часть своей жизни на разработку компьютерных языков, эта идея представляется очень важной. То есть я точно знаю, что если я буду думать на языке Mathematica, то многие концепции будут достаточно просты для моего понимания, и они будут совсем не такими простыми, если я буду думать на каком-то другом языке.
Но, в любом случае, без переменных всё было бы гораздо сложнее. Например, как вы представите многочлен?
Ну, Диофант — тот самый, что придумал диофантовы уравнения — сталкивался с проблемой представления многочленов в середине 2 века н.э. В итоге он пришёл к использованию определённых основанных на буквах имён для квадратов, кубов и прочего. Вот как это работало.
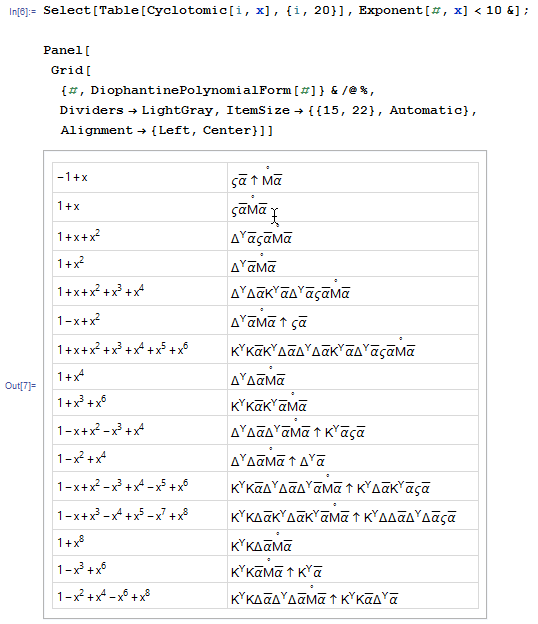
По крайней мере сейчас нам показалось бы чрезвычайно трудным понять обозначения Диофанта для полиномов. Это пример не очень хороших обозначений. Полагаю, главная причина, помимо ограниченной расширяемости, состоит в том, что эти обозначения делают математические связи между полиномами неочевидными и не выделяют наиболее интересные нам моменты.
Есть и другие схемы задания полиномов без переменных, как, например, китайская схема, которая включала создание двухмерного массива коэффициентов.
Проблема здесь, опять-таки, в расширяемости. И эта проблема с основанными на графике обозначениями всплывает снова и снова: лист бумаги, папирус или что бы то ни было — они все ограничены двумя измерениями.
Хорошо, так что насчёт буквенного обозначения переменных?
Полагаю, что они могли бы появиться лишь после появления чего-то похожего на нашу современную нотацию. И она до определённого времени не появлялась. Были какие-то намёки в индо-арабских обозначениях в середине первого тысячелетия, однако установилось всё лишь к его концу. А на запад эта идея пришла лишь с работой Фибоначчи о вычислениях в 13 веке.
Фибоначчи, разумеется, был тем самым, кто говорил о числах Фибоначчи применительно к задаче о кроликах, однако в действительности эти числа известны были уже более тысячи лет, и служили они для описания форм индийской поэзии. И я всегда находил случай с числами Фибоначчи удивительным и отрезвляющим эпизодом в истории математики: возникнув на заре западной математики, столь привычные и фундаментальные, они начали становиться популярными лишь в 80-е.
В любом случае, также интересно заметить, что идея разбивки цифр в группы по три, чтобы сделать большие числа более читаемыми, имеется уже в книге Фибоначчи 1202 года, хотя я думаю, что он говорил об использовании скобок над числами, а не о разделяющих запятых.
После Фибоначчи наше современное представление для чисел постепенно становится всё популярнее, и ко времени начала книгопечатания в 15 веке оно уже было универсальным, хотя ещё и оставались несколько чудных моментов.
Но алгебраических переменных в полном их смысле тогда ещё не было. Они появились лишь после Виета в конце 16 века и обрели популярность лишь в 17 веке. То есть у Коперника и его современников их ещё не было. Как в основном и у Кеплера. Эти учёные для описания каких-то математических концепций использовали обычный текст, иногда структурированный как у Евклида.
Кстати, даже несмотря на то, что математическая нотация в те времена была не очень хорошо проработана, системы символьных обозначений в алхимии, астрологии и музыке были довольно развиты. Так, к примеру, Кеплер в начале 17 века использовал нечто, похожее на современную музыкальную нотацию, объясняя свою «музыку сфер» для отношений планетарных орбит.
Со времён Виета буквенные обозначения для переменных стали привычным делом. Обычно, кстати, он использовал гласные для неизвестных и согласные — для известных.
Вот как Виет записывал многочлены в форме, которую он называл "zetetics", а сейчас мы бы это назвали просто символьной алгеброй:
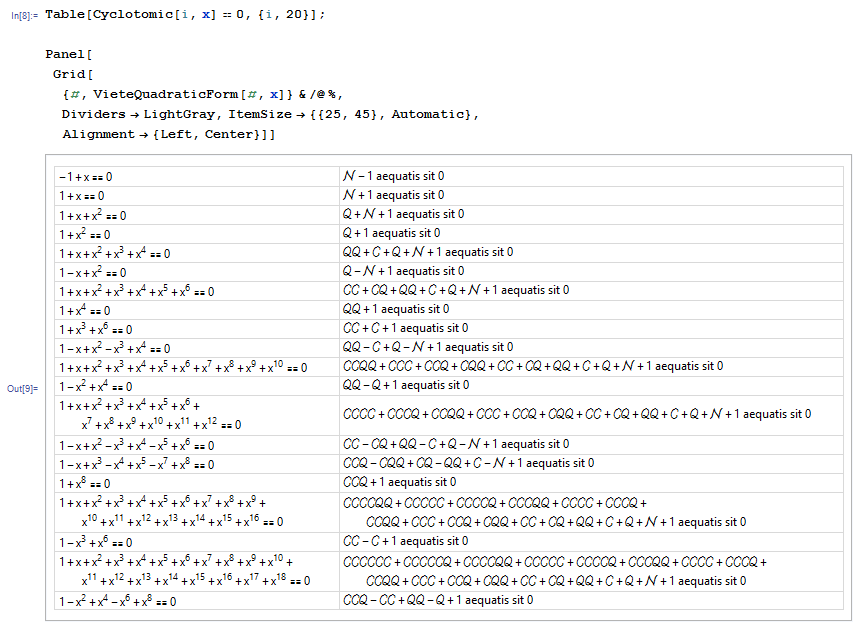
Можно увидеть, что он использует слова для обозначения операций, в основном так, чтобы их нельзя было спутать с переменными.
Так как раньше представляли операции, в каком виде?
Идея о том, что операции есть нечто, что можно в какой-то форме представить, добиралась до умов людей довольно долго. Вавилоняне обычно не использовали символы для операций — для сложения они просто записывали слагаемые друг за другом. И в целом они были предрасположены записывать всё в виде таблиц, так что им не требовалось как-то обозначать операции.
У египтян были некоторые обозначения для операций: для сложения они использовали пару идущих вперёд ног, а для вычитания — идущих назад.
А современный знак +, который, вероятно, является сокращением от "et" на латыни (означает «и»), появился лишь в конце 15 века.
А вот кое-что из 1579 года, что выглядит весьма современным, написанное в основном на английском, пока не начнёшь понимать, что те забавные загогулины — это не иксы, а специальные небуквенные символы, которые представляют различные степени для переменных.

В первой половине 17 века произошла своего рода революция в математической нотации, после которой она практически обрела свой современный вид. Было создано современное обозначение квадратного корня, который ранее обозначался как Rx — это обозначение сейчас используется в медицинских рецептах. И в основном алгебраическая нотация приобрела свой современный вид.
Уильям Отред был одним из тех людей, кто серьёзно занимался этим вопросом. Изобретение логарифмической линейки — одна из вещей, которая сделала его известным. На самом деле о нём практически ничего неизвестно. Он не был крупным математиком, однако сделал много полезного в области преподавания, с такими людьми, как Кристофер Рен и его учениками. Странно, что я ничего не слышал о нём в школе, особенно если учесть, что мы учились в одной и той же школе, только он на 400 лет ранее. Однако изобретение логарифмической линейки было недостаточным для того, чтобы увековечить своё имя в истории математики.
Но, в любом случае, он серьёзно занимался нотацией. Он придумал обозначать умножение крестиком, и он продвинул идею о представлении алгебры посредством обозначений вместо слов — так, как это делал Виет. И, фактически, он изобрёл довольно много других обозначений, подобно тильде для таких предикатов, как IntegerQ.

После Отреда и его сотоварищей эти обозначения быстро установились. Были и альтернативные обозначения, как изображения убывающей и растущей лун для обозначения арифметических операций — прекрасный пример плохого и нерасширяемого дизайна. Однако в основном использовались современные обозначения.
Вот пример.

Это фрагмент рукописи Ньютона Principia, из которой ясно, что он в основном использовал современные алгебраические обозначения. Думаю, именно Ньютон придумал использовать отрицательные степени вместо дробей для обратных величин и прочего. Principia содержит весьма мало обозначений, за исключением этих алгебраических вещей и представления разного материала в стиле Евклида. И в действительности Ньютон не особо интересовался обозначениями. Он даже хотел использовать точечные обозначения для своих флюксий.
Чего не скажешь о Лейбнице. Лейбниц много внимания уделял вопросам нотации. В действительности, он считал, что правильные обозначения есть ключ ко многим человеческим вопросам. Он был своего рода дипломат-аналитик, курсирующий между различными странами, со всеми их различными языками, и т.д. У него была идея, что если создать некий универсальный логический язык, то тогда все люди смогли бы понимать друг друга и имели бы возможность объяснить всё что угодно.
Были и другие люди, которые размышляли о подобном, преимущественно с позиции обычных естественных языков и логики. Один из примеров — довольно специфичный персонаж по имени Раймонд Лул, живший в 14 веке, который заявлял, что изобрёл некие логические колёса, дающие ответы на все вопросы мира.
Но так или иначе, Лейбниц разработал те вещи, которые были интересны и с позиций математики. То, что он хотел сделать, должно было так или иначе объединить все виды обозначений в математике в некоторый точный естественный язык с подобным математике способом описания и решения различных проблем, или даже больше — объединить ещё и все используемые естественные языки.
Ну, как и многие другие свои проекты, Лейбниц так и не воплотил это в жизнь. Однако он занимался самыми разными направлениями математики и серьёзно относился к разработке обозначений для них. Наиболее известные его обозначения были введены им в 1675 году. Для обозначения интегралов он использовал "omn.", возможно, как сокращение от omnium. Но в пятницу 29 октября 1675 года он написал следующее.

На этом фрагменте бумаги можно увидеть знак интеграла. Он задумывал его как вытянутую S. Несомненно, это и есть современное обозначение интеграла. Ну, между обозначениями интегралов тогда и сейчас почти нет никакой разницы.
Затем в четверг 11 ноября того же года он обозначил дифференциал как "d". На самом деле, Лейбниц считал это обозначение не самым лучшим и планировал придумать ему какую-нибудь замену. Но, как мы все знаем, этого не произошло.
Что ж, Лейбниц вёл переписку касательно обозначений с самыми разными людьми. Он видел себя кем-то вроде председателя комитета стандартов математических обозначений — так бы мы сказали сейчас. Он считал, что обозначения должны быть максимально краткими. К примеру, Лейбниц говорил: "Зачем использовать две точки для обозначения деления, когда можно использовать лишь одну?".
Некоторые из продвигаемых им идей так и не получили распространения. К примеру, используя буквы для обозначения переменных, он использовал астрономические знаки для обозначения выражений. Довольно интересная идея, на самом деле.
Так он обозначал функции.

Помимо этих моментов и некоторых исключений наподобие символа пересечения квадратов, который Лейбниц использовал для обозначения равенства, его обозначения практически неизменными дошли до наших дней.
В 18 веке Эйлер активно пользовался обозначениями. Однако, по сути, он следовал по пути Лейбница. Полагаю, он был первым, кто всерьёз начал использовать греческие буквы наравне с латинскими для обозначения переменных.
Есть и некоторые другие обозначения, которые появились вскоре после Лейбница. Следующий пример из книги, вышедшей через несколько лет после смерти Ньютона. Это учебник алгебры, и он содержит весьма традиционные алгебраические обозначения, уже в печатном виде.

А вот книга Лопиталя, напечатанная примерно в то же время, в которой уже практически современная алгебраическая нотация.

И, наконец, вот пример от Эйлера, содержащий весьма современные обозначения для интегралов и прочего.

Эйлер — популяризировал современное обозначение для числа пи, которое первоначально было предложено Уильямом Джонсом, который рассматривал его как сокращение от слова периметр.
Предложенная Лейбницем и сотоварищами нотация довольно долго оставалась неизменной. Происходили небольшие изменения, как, к примеру квадрат x x получил написание x2. Однако практически ничего нового не появилось.
Однако в конце 19 века наблюдается новый всплеск интереса к математической нотации, сопряжённый с развитием математической логики. Были некоторые нововведения, сделанные физиками, такими как Максвелл и Гиббс, в основном для векторов и векторного анализа, как следствие развития абстрактной алгебры. Однако наиболее значимые изменения были сделаны людьми, начиная с Фреге и приблизительно с 1879 года, которые занимались математической логикой.
Эти люди в своих устремлениях были близки к Лейбницу. Они хотели разработать нотацию, которая представляла бы не только математические формулы, но и математические выводы и доказательства. В середине 19 века Буль показал, что основы логики высказываний можно представлять в терминах математики. Однако Фреге и его единомышленники хотели пойти дальше и представить так как логику высказываний, так и любые математические суждения в соответствующих математических терминах и обозначениях.
Фреге решил, что для решения этой задачи потребуются графические обозначения. Вот фрагмент его так называемой "концептуальной нотации".

К сожалению, в ней трудно разобраться. И в действительности, если посмотреть на историю обозначений в целом, то часто можно встретить попытки изобретения графических обозначений, которые оказывались трудными для понимания. Но в любом случае, обозначения Фреге уж точно не стали популярными.
Потом был Пеано, самый главный энтузиаст в области математической нотации. Он делал ставку на линейное представление обозначений. Вот пример:

Вообще говоря, в 80-х годах 19 века Пеано разработал то, что очень близко к обозначениям, которые используются в большинстве современных теоретико-множественных концепций.
Однако, как и Лейбниц, Пеано не желал останавливаться лишь на универсальной нотации для математики. Он хотел разработать универсальный язык для всего. Эта идея реализовалась у него в то, что он назвал интерлингва — язык на основе упрощённой латыни. Затем он написал нечто вроде краткого изложения математики, назвав это Formulario Mathematico, которое было основано на его обозначениях для формул, и труд этот был написал на этой производной от латыни — на интерлингве.
Интерлингва, подобно эсперанто, который появился примерно в это же время, так и не получил широкого распространения. Однако этого нельзя сказать об обозначениях Пеано. Сперва о них никто ничего толком и не слышал. Но затем Уайтхед и Рассел написали свой труд Principia Mathematica, в котором использовались обозначения Пеано.
Думаю, Уайтхед и Рассел выиграли бы приз в номинации "самая насыщенная математическими обозначениями работа, которая когда-либо была сделана без помощи вычислительных устройств". Вот пример типичной страницы из Principia Mathematica.

У них были все мыслимые виды обозначений. Частая история, когда авторы впереди своих издателей: Рассел сам разрабатывал шрифты для многих используемых им обозначений.
И, разумеется, тогда речь шла не о шрифтах TrueType или о Type 1, а о самых настоящих кусках свинца. Я о том, что Рассела можно было встретить с тележкой, полной свинцовых оттисков, катящему её в издательство Кембриджского университета для обеспечения корректной вёрстки его книг.
Но, несмотря на все эти усилия, результаты были довольно гротескными и малопонятными. Я думаю, это довольно ясно, что Рассел и Уайтхед зашли слишком далеко со своими обозначениями.
И хотя область математической логики немного прояснилась в результате деятельности Рассела и Уайтхеда, она всё ещё остаётся наименее стандартизированной и содержащей самую сложную нотацию.
Но что насчёт более распространённых составляющих математики?
Какое-то время в начале 20 века то, что было сделано в математической логике, ещё не произвело никакого эффекта. Однако ситуация резко начала меняться с движением Бурбаки, которое начало разрастаться во Франции в примерное сороковые года.
Бурбаки придавали особое значение гораздо более абстрактному, логико-ориентированному подходу к математике. В частности, они акцентировали внимание на использовании обозначений там, где это только возможно, любым способом сводя использование потенциально неточного текста к минимуму.
Где-то с сороковых работы в области чистой математики претерпели серьёзные изменения, что можно заметить в соответствующих журналах, в работах международного математического сообщества и прочих источниках подобного рода. Изменения заключались в переходе от работ, полных текста и лишь с основными алгебраическими и вычислительными выкладками к работам, насыщенными обозначениями.
Конечно, эта тенденция коснулась не всех областей математики. Это в некотором роде то, чем занимаются в лингвистике обычных естественных языков. По устаревшим используемым математическим обозначениям можно заметить, как различные области, их использующие, отстают от основной магистрали математического развития. Так, к примеру, можно сказать, что физика осталась где-то в конце 19 века, используя уже устаревшую математическую нотацию тех времён.
Есть один момент, который постоянно проявляется в этой области — нотация, как и обычные языки, сильно разделяет людей. Я имею в виду, что между теми, кто понимает конкретные обозначения, и теми, кто не понимает, имеется большой барьер. Это кажется довольно мистическим, напоминая ситуацию с алхимиками и оккультистами — математическая нотация полна знаков и символов, которые люди в обычной жизни не используют, и большинство людей их не понимают.
На самом деле, довольно любопытно, что с недавних пор в рекламе появился тренд на использование математических обозначений. Думаю, по какой-то причине математическая нотация стала чем-то вроде шика. Вот один актуальный пример рекламы.

Отношение к математическим обозначениям, к примеру, в школьном образовании, часто напоминает мне отношение к символам секретных сообществ и тому подобному.
Что ж, это был краткий конспект некоторых наиболее важных эпизодов истории математической нотации.
В ходе исторических процессов некоторые обозначения перестали использоваться. Помимо некоторых областей, таких как математическая логика, она стала весьма стандартизированной. Разница в используемых разными людьми обозначениях минимальна. Как и в ситуации с любым обычным языком, математические записи практически всегда выглядят одинаково.
Компьютеры
Вот вопрос: можно ли сделать так, чтобы компьютеры понимали эти обозначения?
Это зависит от того, насколько они систематизированы и как много смысла можно извлечь из некоторого заданного фрагмента математической записи.
Ну, надеюсь, мне удалось донести мысль о том, что нотация развивалась в результате непродуманных случайных исторических процессов. Было несколько людей, таких как Лейбниц и Пеано, которые пытались подойти к этому вопросу более системно. Но в основном обозначения появлялись по ходу решения каких-то конкретных задач — подобно тому, как это происходит в обычных разговорных языках.
И одна из вещей, которая меня удивила, заключается в том, что по сути никогда не проводилось интроспективного изучения структуры математической нотации.
Грамматика обычных разговорных языков развивалась веками. Без сомнения, многие римские и греческие философы и ораторы уделяли ей много внимания. И, по сути, уже примерно в 500 года до н. э. Панини удивительно подробно и ясно расписал грамматику для санскрита. Фактически, грамматика Панини была удивительно похожа по структуре на спецификацию правил создания компьютерных языков в форме Бэкуса-Наура, которая используется в настоящее время.
И были грамматики не только для языков — в последнее столетие появилось бесконечное количество научных работ по правильному использованию языка и тому подобному.
Но, несмотря на всю эту активность в отношении обычных языков, по сути, абсолютно ничего не было сделано для языка математики и математической нотации. Это действительно довольно странно.
Были даже математики, которые работали над грамматиками обычных языков. Ранним примером являлся Джон Уоллис, который придумал формулу произведения Уоллиса для числа пи, и вот он писал работы по грамматике английского языка в 1658 году. Уоллис был тем самым человеком, который начал всю эту суматоху с правильным использованием "will" или "shall".
В начале 20 века в математической логике говорили о разных слоях правильно сформированного математического выражения: переменные внутри функций внутри предикатов внутри функций внутри соединительных слов внутри кванторов. Но не о том, что же это всё значило для обозначений выражений.
Некоторая определённость появилась в 50-е годы 20 века, когда Хомский и Бакус, независимо разработали идею контекстно-свободных языков. Идея пришла походу работы над правилами подстановки в математической логике, в основном благодаря Эмилю Посту в 20-х годах 20 века. Но, любопытно, что и у Хомского, и у Бакуса возникла одна и та же идея именно в 1950-е.
Бакус применил её к компьютерным языкам: сперва к Fortran, затем к ALGOL. И он заметил, что алгебраические выражения могут быть представлены в контекстно-свободной грамматике.
Хомский применил эту идею к обычному человеческому языку. И он отмечал, что с некоторой степенью точности обычные человеческие языки так же могут быть представлены контекстно-свободными грамматиками.
Конечно, лингвисты включая Хомского, потратили годы на демонстрацию того, насколько всё же эта идея не соответствует действительности. Но вещь, которую я всегда отмечал, а с научной точки зрения считал самой важной, состоит в том, что в первом приближении это всё-таки истина — то, что обычные естественные языки контекстно-свободны.
Итак, Хомский изучал обычный язык, а Бакус изучал такие вещи, как ALGOL. Однако никто из них не рассматривал вопрос разработки более продвинутой математики, чем простой алгебраический язык. И, насколько я могу судить, практически никто с тех времён не занимался этим вопросом.
Но, если вы хотите посмотреть, сможете ли вы интерпретировать некоторые математические обозначения, вы должны знать, грамматику какого типа они используют.
Сейчас я должен сказать вам, что считал математическую нотацию чем-то слишком случайным для того, чтобы её мог корректно интерпретировать компьютер. В начале девяностых мы горели идеей предоставить возможность Mathematica работать с математической нотацией. И по ходу реализации этой идеи нам пришлось разобраться с тем, что происходит с математической нотацией.
Нил Сойффер потратил множество лет, работая над редактированием и интерпретацией математической нотации, и когда он присоединился к нам в 1991, он пытаться убедить меня, что с математической нотацией вполне можно работать — как с вводом, так и с выводом.
Часть с выводом данных была довольно простой: в конце концов, TROFF и TEX уже проделали большую работу в этом направлении.
Вопрос заключался во вводе данных.
На самом деле, мы уже кое-что выяснили для себя касательно вывода. Мы поняли, что хотя бы на некотором уровне многие математические обозначения могут быть представлены в некоторой контекстно-свободной форме. Поскольку многие знают подобный принцип из, скажем, TEX, то можно было бы всё настроить через работу со вложенными структурами.
Но что насчёт входных данных? Один из самых важных моментов заключался в том, с чем всегда сталкиваются при парсинге: если у вас есть строка текста с операторами и операндами, то как задать, что и с чем группируется?
Итак, допустим, у вас есть подобное математическое выражение.
Sin[x+1]^2+ArcSin[x+1]+c(x+1)+f[x+1]
Что оно означает? Чтобы это понять, нужно знать приоритеты операторов — какие действуют сильнее, а какие слабее в отношении операндов.
Я подозревал, что для этого нет какого-то серьёзного обоснования ни в каких статьях, посвящённых математике. И я решил исследовать это. Я прошёлся по самой разнообразной математической литературе, показывал разным людям какие-то случайные фрагменты математической нотации и спрашивал у них, как бы они их интерпретировали. И я обнаружил весьма любопытную вещь: была удивительная слаженность мнений людей в определении приоритетов операторов. Таким образом, можно утверждать: имеется определённая последовательность приоритетов математических операторов.
Можно с некоторой уверенностью сказать, что люди представляют именно эту последовательность приоритетов, когда смотрят на фрагменты математической нотации.
Обнаружив этот факт, я стал значительно более оптимистично оценивать возможность интерпретации вводимых математических обозначений. Один из способов, с помощью которого всегда можно это реализовать — использовать шаблоны. То есть достаточно просто иметь шаблон для интеграла и заполнять ячейки подынтегрального выражения, переменной и так далее. И когда шаблон вставляется в документ, то всё выглядит как надо, однако всё ещё содержится информация о том, что это за шаблон, и программа понимает, как это интерпретировать. И многие программы действительно так и работают.
Но в целом это крайне неудобно. Потому что если вы попытаетесь быстро вводить данные или редактировать, вы будете обнаруживать, что компьютер вам бикает (beeping) и не даёт делать те вещи, которые, очевидно, должны быть вам доступны для реализации.
Дать людям возможность ввода в свободной форме — значительно более сложная задача. Но это то, что мы хотим реализовать.
Итак, что это влечёт?
Прежде всего, математический синтаксис должен быть тщательно продуманным и однозначным. Очевидно, получить подобный синтаксис можно, если использовать обычный язык программирования с основанным на строках синтаксисом. Но тогда вы не получите знакомую математическую нотацию.
Вот ключевая проблема: традиционная математическая нотация содержит неоднозначности. По крайней мере, если вы захотите представить её в достаточно общем виде. Возьмём, к примеру, "i". Что это — Sqrt[-1] или переменная "i"?
В обычном текстовом InputForm в Mathematica все подобные неоднозначности решены простым путём: все встроенные объекты Mathematica начинаются с заглавной буквы.
Но заглавная "I" не очень то и похожа на то, чем обозначается Sqrt[-1] в математических текстах. И что с этим делать? И вот ключевая идея: можно сделать другой символ, который вроде тоже прописная «i», однако это будет не обычная прописная «i», а квадратный корень из -1.
Можно было бы подумать: Ну, а почему бы просто не использовать две «i», которые бы выглядели одинаково, — прям как в математических текстах — однако из них будет особой? Ну, это бы точно сбивало с толку. Вы должны будете знать, какую именно «i» вы печатаете, а если вы её куда-то передвинете или сделаете что-то подобное, то получится неразбериха.
Итак, значит, должно быть два "i". Как должна выглядеть особая версия этого символа?
У нас была идея — использовать двойное начертание для символа. Мы перепробовали самые разные графические представления. Но идея с двойным начертанием оказалась лучшей. В некотором роде она отвечает традиции в математике обозначать специфичные объекты двойным начертанием.
Так, к примеру, прописная R могла бы быть переменной в математических записях. А вот R с двойным начертанием — уже специфический объект, которым обозначают множество действительных чисел.
Таким образом, "i" с двойным начертанием есть специфичный объект, который мы называем ImaginaryI. Вот как это работает:
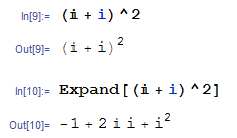
Идея с двойным начертанием решает множество проблем.
В том числе и самую большую — интегралы. Допустим, вы пытаетесь разработать синтаксис для интегралов. Один из ключевых вопросов — что может означать "d" в интеграле? Что, если это параметр в подынтегральном выражении? Или переменная? Получается ужасная путаница.
Всё становится очень просто, если использовать DifferentialD или "d" с двойным начертанием. И получается хорошо определённый синтаксис.
Можно проинтегрировать x в степени d, деленное на квадратный корень от x+1. Вот как это работает:

Оказывается, что требуется всего лишь несколько маленьких изменений в основании математического обозначения, чтобы сделать его однозначным. Это удивительно. И весьма здорово. Потому что вы можете просто ввести что-то, состоящее из математических обозначений, в свободной форме, и оно будет прекрасно понято системой. И это то, что мы реализовали в Mathematica 3.
Конечно, чтобы всё работало так, как надо, нужно разобраться с некоторыми нюансами. К примеру, иметь возможность вводить что бы то ни было эффективным и легко запоминающимся путём. Мы долго думали над этим. И мы придумали несколько хороших и общих схем для реализации подобного.
Одна из них — ввод таких вещей, как степени, в качестве верхних индексов. В обычном текстовом вводе для обозначения степени используется символ ^. Идея заключается в использовании control — ^, с помощью которой можно вводить явный верхний индекс. Та же идея для сочетания control — /, с помощью которого можно вводить «двухэтажную» дробь.
Наличие ясного набора принципов подобных этому важно для того, чтобы заставить всё вместе работать на практике. И оно работает. Вот как мог бы выглядеть ввод довольно сложного выражения:
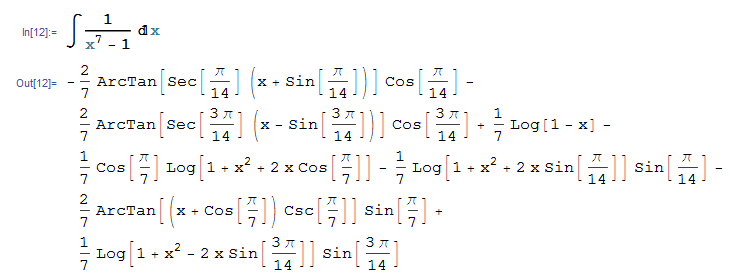
Но мы можем брать фрагменты из этого результата и работать с ними.

И смысл в том, что это выражение полностью понятно для Mathematica, то есть оно может быть вычислено. Из этого следует, что результаты выполнения (Out) — объекты той же природы, что и входные данные (In), то есть их можно редактировать, использовать их части по отдельности, использовать их фрагменты в качестве входных данных и так далее.
Чтобы заставить всё это работать, нам пришлось обобщить обычные языки программирования и кое-что проанализировать. Прежде была внедрена возможность работать с целым «зоопарком» специальных символов в качестве операторов. Однако, вероятно, более важно то, что мы внедрили поддержку двумерных структур. Так, помимо префиксных операторов, имеется поддержка оверфиксных операторов и прочего.
Если вы посмотрите на это выражение, вы можете сказать, что оно не совсем похоже на традиционную математическую нотацию. Но оно очень близко. И оно несомненно содержит все особенности структуры и форм записи обычной математической нотации. И важная вещь заключается в том, что ни у кого, владеющим обычной математической нотацией, не возникнет трудностей в интерпретации этого выражения.
Конечно, есть некоторые косметические отличия от того, что можно было бы увидеть в обычном учебнике по математике. К примеру, как записываются тригонометрические функции, ну и тому подобное.
Однако я готов поспорить, что StandardForm в Mathematica лучше и яснее для представления этого выражения. И в книге, которую я писал много лет о научном проекте, которым я занимался, для представления чего бы то ни было я использовал только StandardForm.
Однако если нужно полное соответствие с обычными учебниками, то понадобится уже что-то другое. И вот другая важная идея, реализованная в Mathematica 3: разделить StandardForm и TraditionalForm.
Любое выражение я всегда могу сконвертировать в TraditionalForm.
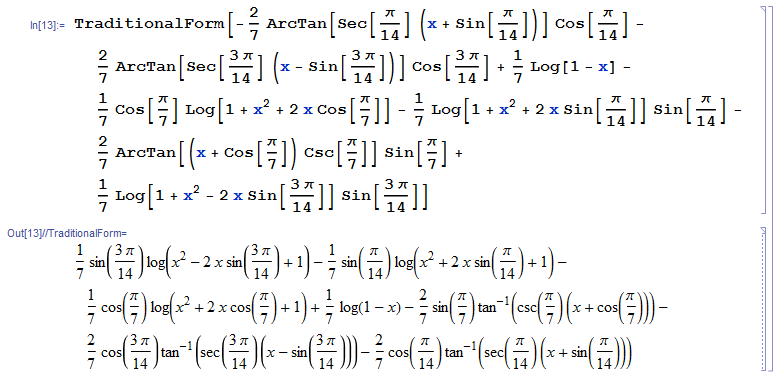
И в действительности TraditionalForm всегда содержит достаточно информации, чтобы быть однозначно сконвертированным обратно в StandardForm.
Но TraditionalForm выглядит практически как обычные математические обозначения. Со всеми этими довольно странными вещами в традиционной математической нотации, как запись синус в квадрате x вместо синус x в квадрате и так далее.
Так что насчёт ввода TraditionalForm?
Вы могли заметить пунктир справа от ячейки [в других выводах ячейки были скрыты для упрощения картинок — прим. ред.]. Они означают, что есть какой-то опасный момент. Однако давайте попробуем кое-что отредактировать.
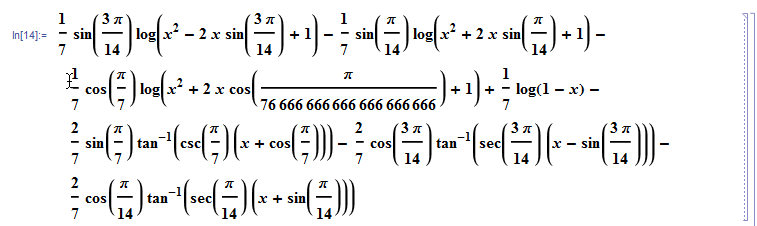
Мы прекрасно можем всё редактировать. Давайте посмотрим, что случится, если мы попытаемся это вычислить.
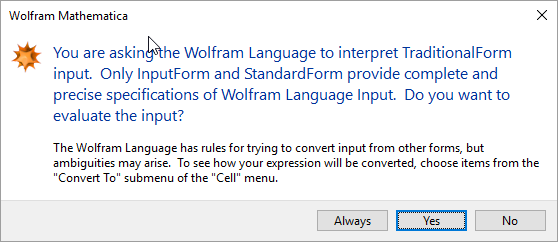
Вот, возникло предупреждение. В любом случае, всё равно продолжим.
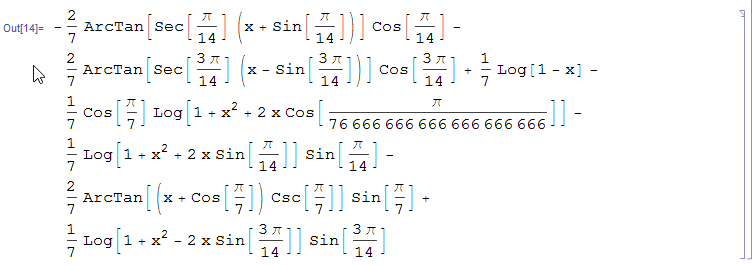
Что ж, система поняла, что мы хотим.
Фактически, у нас есть несколько сотен эвристических правил интерпретации выражений в традиционной форме. И они работают весьма хорошо. Достаточно хорошо, чтобы пройти через большие объёмы устаревших математических обозначений, определённых, скажем, в TEX, и автоматически и однозначно сконвертировать их в осмысленные данные в Mathematica.
И эта возможность весьма вдохновляет. Потому что для того же устаревшего текста на естественном языке нет никакого способа сконвертировать его во что-то значимое. Однако в математике есть такая возможность.
Конечно, есть некоторые вещи, связанные с математикой, в основном на стороне выхода, с которыми существенно больше сложностей, чем с обычным текстом. Часть проблемы в том, что от математики часто ожидают автоматической работы. Нельзя автоматически сгенерировать много текста, который будет достаточно осмысленным. Однако в математике производятся вычисления, которые могут выдавать большие выражения.
Так что вам нужно придумывать, как разбивать выражение по строкам так, чтобы всё выглядело достаточно аккуратно, и в Mathematica мы хорошо поработали над этой задачей. И с ней связано несколько интересных вопросов, как, например, то, что во время редактирования выражения оптимальное разбиение на строки постоянно может меняться по ходу работы.
И это значит, что будут возникать такие противные моменты, как если вы печатаете, и вдруг курсор перескакивает назад. Что ж, эту проблему, полагаю, мы решили довольно изящным образом. Давайте рассмотрим пример.
Вы видели это? Была забавная анимация, которая появляется на мгновение, когда курсор должен передвинуться назад. Возможно, вы её заметили. Однако если бы вы печатали, вы бы, вероятно, и не заметили бы, что курсор передвинулся назад, хотя вы могли бы её и заметить, потому что эта анимация заставляет ваши глаза автоматически посмотреть на это место. С точки зрения физиологии, полагаю, это работает за счёт нервных импульсов, которые поступают не в зрительную кору, а прямо в мозговой ствол, который контролирует движения глаз. Итак, эта анимация заставляет вас подсознательно переместить свой взор в нужное место.
Таким образом, мы смогли найти способ интерпретировать стандартную математическую нотацию. Означает ли это, что теперь вся работа в Mathematica должна теперь проводиться в рамках традиционных математических обозначений? Должны ли мы ввести специальные символы для всех представленных операций в Mathematica? Таким образом можно получить весьма компактную нотацию. Но насколько это разумно? Будет ли это читаемо?
Пожалуй, ответом будет нет.
Думаю, тут сокрыт фундаментальный принцип: кто-то хочет всё представлять в обозначениях, и не использовать ничего другого.
А кому-то не нужны специальные обозначения. А кто-то пользуется в Mathematica FullForm. Однако с этой формой весьма утомительно работать. Возможно, именно поэтому синтаксис языков наподобие LISP кажется столь трудным — по сути это синтаксис FullForm в Mathematica.
Другая возможность заключается в том, что всему можно присвоить специальные обозначения. Получится что-то наподобие APL или каких-то фрагментов математической логики. Вот пример этого.

Довольно трудно читать.
Вот другой пример из оригинальной статьи Тьюринга, в которой содержатся обозначения для универсальной машины Тьюринга, опять-таки — пример не самой лучшей нотации.

Она тоже относительно нечитабельная.
Вопрос заключается в том, что же находится между двумя такими крайностями, как LISP и APL. Думаю, эта проблема очень близка к той, что возникала при использовании очень коротких имён для команд.
К примеру, Unix. Ранние версии Unix весьма здорово смотрелись, когда там было небольшое количество коротких для набора команд. Но система разрасталась. И через какое-то время было уже большое количество команд, состоящих из небольшого количества символов. И большинство простых смертных не смогли бы их запомнить. И всё стало выглядеть совершенно непонятным.
Та же ситуация, что и с математической или другой нотацией, если на то пошло. Люди могут работать лишь с небольшим количеством специальных форм и символов. Возможно, с несколькими десятками. Соизмеримым с длиной алфавита. Но не более. А если дать им больше, особенно все и сразу, в голове у них будет полная неразбериха.
Это следует немного конкретизировать. Вот, к примеру, множество различных операторов отношений.

Но большинство из них по сути состоят из небольшого количества элементов, так что с ними проблем быть не должно.
Конечно, принципиально люди могут выучить очень большое количество символов. Потому что в языках наподобие китайского или японского имеются тысячи иероглифов. Однако людям требуется несколько дополнительных лет для обучения чтению на этих языках в сравнении с теми, которые используют обычный алфавит.
Если говорить о символах, кстати, полагаю, что людям гораздо легче справится с какими-то новыми символами в качестве переменных, нежели в качестве операторов. И весьма занятно рассмотреть этот вопрос с точки зрения истории.
Один из наиболее любопытных моментов — во все времена и практически без исключения в качестве переменных использовались лишь латинские и греческие символы. Ну, Кантор ввёл алеф, взятый из иврита, для своих кардинальных чисел бесконечных множеств. И некоторые люди утверждают, что символ частной производной — русская д, хотя я думаю, что на самом деле это не так. Однако нет никаких других символов, которые были бы заимствованы из других языков и получили бы распространение.
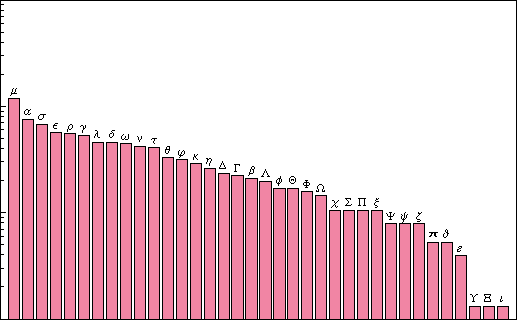
Кстати, наверняка вам известно, что в английском языке буква "e" — самая популярная, затем идёт "t", ну и так далее. И мне стало любопытно, каково распределение по частоте использования букв в математике. Потому я исследовал сайт MathWorld, в котором содержится большое количество математической информации — более 13 500 записей, и посмотрел, каково распределение для различных букв [к сожалению, эту картинку, сделанную Стивеном, не удалось осовременить — прим. ред.].
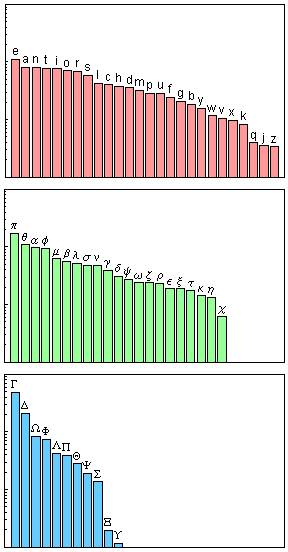
Можно увидеть, что "e" — самая популярная. И весьма странно, что "a" занимает второе место. Это очень необычно. Можно увидеть, что строчная π — наиболее популярная, за которой идут θ, α, φ, μ, β и так далее. А среди прописных самые популярные — Γ и Δ.
Хорошо. Я немного рассказал об обозначениях, которые в принципе можно использовать в математике. Так какая нотация лучше всего подходит для использования?
Большинство людей, использующих математическую нотацию, наверняка задавались этим вопросом. Однако для математики нет никакого аналога, подобного "Современному использованию английского языка" Фаулера для английского языка. Была небольшая книжка под названием Математика в печати, изданная AMS, однако она в основном о типографских приёмах.
В результате мы не имеем хорошо расписанных принципов, аналогичным вещам наподобие инфинитивов с отдельными частицами в английском языке.
Если вы используете StandardForm в Mathematica, вам это больше не потребуется. Потому что всё, что вы введёте, будет однозначно интерпретировано. Однако для TraditionalForm следует придерживаться некоторых принципов. К примеру, не писать
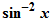 , потому что не совсем ясно, что это означает.
, потому что не совсем ясно, что это означает.Будущее
Чтобы закончить, позвольте мне рассказать немного о будущем математической нотации.
Какой, к примеру, должна бы быть новая нотация?
В какой-нибудь книге символов будет содержаться около 2500 символов, популярных в тех или иных областях и не являющимися буквами языков. И с правильным написанием символов, многие из них могли бы идеально сочетаться с математическими символами.
Для чего же их использовать?
Первая приходящая на ум возможность — нотация для представления программ и математических операций. В Mathematica, к примеру, представлено довольно много текстовых операторов, используемых в программах. И я долгое время считал, что было бы здорово иметь возможность использовать для них какие-то специальные символы вместо комбинаций обычных символов ASCII [последние версии Mathematica полностью поддерживают Unicode — прим. ред.].
Оказывается, иногда это можно реализовать весьма просто. Поскольку мы выбрали символы ASCII, то часто можно получить некоторые символы, очень близкие по написанию, но более изящные. К примеру, если в Mathematica набрать ->, то эта стрелочка автоматически превратиться в более изящную
 . И это всё реализуемо за счёт того, что парсер в Mathematica может работать в том числе и со специальными символами.
. И это всё реализуемо за счёт того, что парсер в Mathematica может работать в том числе и со специальными символами.Я часто размышлял о том, как бы расширить всё это. И вот, постепенно появляются новые идеи. Обратите внимание на знак решётки #, или номерной знак, или, как его ещё иногда называют, октоторп, который мы используем в тех местах, в которые передаётся параметр чистой функции. Он напоминает квадрат с щупальцами. И в будущем, возможно, он будет обозначаться симпатичным квадратиком с маленькими засечками, и будет означать место для передачи параметра в функцию. И он будет более гладким, не похожим на фрагмент обычного кода, чем-то вроде пиктограммы.
Насколько далеко можно зайти в этом направлении — представлении вещей в визуальной форме или в виде пиктограмм? Ясно, что такие вещи, как блок-схемы в инженерии, коммутативные диаграммы в чистой математике, технологические схемы — все хорошо справляются со своими задачами. По крайней мере до настоящего момента. Но как долго это может продолжаться?
Не думаю, что уж очень долго. Думаю, некоторые приближаются к некоторым фундаментальным ограничениям людей в обработке лингвистической информации.
Когда языки более или менее контекстно-свободные, имеют древовидную структуру, с ними можно многое сделать. Наша буферная память из пяти элементов памяти и что бы то ни было спокойно сможет их разобрать. Конечно, если у нас будет слишком много вспомогательных предложений даже на контекстно-свободном языке, то будет вероятность исчерпать стековое пространство и попасть впросак. Но, если стек не будет заходить слишком глубоко, то всё будет работать как надо.
Но что насчёт сетей? Можем ли мы понимать произвольные сети? Я имею в виду — почему у нас должны быть только префиксные, инфиксные, оверфиксные операторы? Почему бы операторам не получать свои аргументы через какие-то связи внутри сети?
Меня особенно интересовал этот вопрос в контексте того, что я занимался некоторыми научными вопросами касательно сетей. И мне действительно хотелось бы получить некоторое языковое представление для сетей. Но не смотря на то, что я уделил этому вопросу довольно много времени — не думаю, что мой мозг смог бы работать с подобными сетями так же, как с обычными языковыми или математическими конструкциями, имеющими одномерную или двумерную контекстно-свободную структуру. Так что я думаю, что это, возможно, то место, до которого нотация не сможет добраться.
Вообще, как я упоминал выше, это частый случай, когда язык или нотация ограничивают наше пространство мыслимого.
Итак, что это значит для математики?
В своём научном проекте я разрабатывал некоторые основные обобщения того, что люди обычно относят к математике. И вопрос в том, какие обозначения могут быть использованы для абстрактного представления подобных вещей.
Что ж, я не смог пока что полностью ответить на этот вопрос. Однако я обнаружил, что, по крайней мере в большинстве случаев, графическое представление или представление в виде пиктограмм гораздо эффективнее обозначений в виде конструкций на обычных языках.
Возвращаясь к самому началу этого разговора, ситуация напоминает то, что происходило тысячи лет в геометрии. В геометрии мы знаем, как представить что-то в графическом виде. Ещё со времён древнего Вавилона. И чуть более ста лет назад стало ясно, как можно формулировать геометрические задачи с точки зрения алгебры.
Однако мы всё ещё не знаем простого и ясного способа представлять геометрические схемы в обозначениях на естественном языке. И моя догадка состоит в том, что практически все эти математические вещи лишь в небольшом количестве могут быть представлены в обозначениях на естественном языке.
Однако мы — люди — легко воспринимаем лишь эти обозначения на естественном языке. Так что мы склонны изучать те вещи, которые могут быть представлены этим способом. Конечно, подобные вещи не могут быть тем, что происходит в природе и вселенной.
Но это уже совсем другая история. Так что я лучше закончу на этом.
Большое спасибо.
Примечания
В ходе обсуждения после выступления и во время общения с другими людьми на конференции возникло несколько моментов, которые следовало бы обсудить.
Эмпирические законы для математических обозначений
При изучении обычного естественного языка были обнаружены различные историко-эмпирические законы. Пример — Закон Гримма, которые описывает переносы в согласных на индоевропейских языках. Мне было любопытно, можно ли найти подобные историко-эмпирические законы для математического обозначения.
Дана Скотт предложила такой вариант: тенденция к удалению явных параметров.
Как пример, в 60 годах 19 века часто каждый компонент вектора именовался отдельно. Но затем компоненты стали помечать индексами — как ai. И вскоре после этого — в основном после работ Гиббса — векторы стали представлять как один объект, обозначаемый, скажем, как
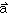 или a.
или a.С тензорами всё не так просто. Нотацию, избегающую явных индексов, обычно называют координатно-свободной. И подобная нотация — частое явление в чистой математике. Однако в физике данный подход считается слишком абстрактным, потому явные индексы используются повсеместно.
В отношении функций так же имеется тенденция явно не упоминать параметры. В чистой математике, когда функции рассматриваются через сопоставления, они часто упоминаются лишь по своему имени — просто f, без каких-либо параметров.
Однако это будет хорошо только тогда, когда у функции только один параметр. Когда параметров несколько, обычно становится непонятно, как будут работать те потоки данных, которые ассоциированы с параметрами.
Однако, ещё в 20-х годах 20 века было показано, что можно использовать так называемые комбинаторы для определения подобных потоков данных без какого-либо явного указания параметров.
Комбинаторы не использовались в основных течениях математики, однако время от времени становились популярными в теории вычислений, хотя их популярность заметно поубавилась из-за несовместимости с идеей о типах данных.
Комбинаторы довольно легко задать в Mathematica через задание функции с составным заголовком. Вот как можно определить стандартные комбинаторы:
k[x_][y_]:=i x
s[x_][y_][z_]:= x[z][y[z]]
Если определить целое число n, по сути, в унарной системе, используя Nest[s[s[k[s]][k]],k[s[k][k]],n], то тогда сложение можно будет определить как s[k[s]][s[k[s[k[s]]]][s[k[k]]]], умножение как s[k[s]][k], а степень — s[k[s[s[k][k]]]][k]. Никакие переменные не требуются.
Проблема заключается в том, что выражения получаются непонятными, и с этим ничего не поделать. Я пытался найти какие-то способы для более ясного представления их и сопряжённых с ними вычислений. Я добился небольшого прогресса, однако нельзя сказать, что задача была решена.
Печатные обозначения против экранных
Некоторые спрашивали о разнице в возможностях печатных и экранных обозначений.
Чтобы можно было понимать обозначения, они должны быть похожими, и разница между ними не должна быть очень большой.
Но есть некоторые очевидные возможности.
Во-первых, на экране легко можно использовать цвет. Можно было бы подумать, что было каким-то образом удобно использовать разные цвета для переменных. Мой опыт говорит о том, что это удобно для разъяснения формулы. Однако всё станет весьма запутанным, если, к примеру, красному x и зелёному x будут соответствовать разные переменные.
Другая возможность состоит в том, чтобы иметь в формуле какие-то анимированные элементы. Полагаю, что они будут столь же раздражающими, как и мигающий текст, и не будут особо полезными.
Пожалуй, идея получше — иметь возможность скрывать и разворачивать определённые части выражения — как группы ячеек в ноутбуке Mathematica. Тогда будет возможность сразу получить представление обо всём выражении, а если интересны детали, то разворачивать его далее и далее.
Письменные обозначения
Некоторые могли бы подумать, что я уж слишком много времени уделил графическим обозначениям.
Хотелось бы прояснить, что я нахожу довольно затруднительным графические обозначения обычных математических действий и операций. В своей книге A New Kind of Science я повсеместно использую графику, и мне не представляется никакого другого способа делать то, что я делаю.
И в традиционной науке, и в математике есть множество графических обозначений, которые прекрасно работают, пускай и в основном для статичных конструкций.
Теория графов — очевидный пример использования графического представления.
К ним близки структурные диаграммы из химии и диаграммы Фейнмана из физики.
В математике имеются методы для групповых теоретических вычислений, представленные отчасти благодаря Предрагу Цвитановицу, и вот они основаны на графическом обозначении.
И в лингвистике, к примеру, распространены диаграммы для предложений, показывающие дерево лингвистических компонентов и способы их группировки для образования предложения.
Все эти обозначения, однако, становятся малопригодными в случаях исследования каких-то очень крупных объектов. Однако в диаграммах Фейнмана обычно используется две петли, а пять петель — максимум, для которого когда-либо были сделаны явные общие вычисления.
Шрифты и символы
Я обещал рассказать кое-что о символах и шрифтах.
В Mathematica 3 нам пришлось проделать большую работу чтобы разработать шрифты для более чем 1100 символов, имеющих отношение к математической и технической нотации.
Получение правильной формы — даже для греческих букв — часто было достаточно сложным. С одной стороны, мы хотели сохранить некоторую традиционность в написании, а с другой — сделать греческие буквы максимально непохожими на английские и какие бы то ни было другие.
В конце концов я сделал эскизы для большинства символов. Вот к чему мы пришли для греческих букв. Мы разработали Times-подобный шрифт, моноширинный наподобие Courier, а сейчас разрабатываем sans serif. Разработать шрифт Courier было непростой задачей. Нужно, к примеру, было придумать, как сделать так, чтобы йота занимала весь слот под символ.
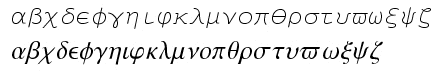
Так же сложности были со скриптовыми и готическими (фактурными) шрифтами. Часто в этих шрифтах буквы настолько непохожи на обычные английские, что становятся абсолютно нечитаемыми. Мы хотели, чтобы эти шрифты вписывались в соответствующую им тему, и, тем не менее, обладали бы теми же габаритами, что и обычные английские буквы.
Вот, что у нас получилось:

Веб сайт fonts.wolfram.com, в котором собрана вся детальная информация о символах и шрифтах, разумеется, если они имеют отношение к Mathematica и её шрифтам.
Поиск математических формул
Некоторые люди спрашивали о поиске математических формул [после создания Wolfram|Alpha появился гигантский объем баз данных, доступных в языке Wolfram Language, теперь можно получить огромный массив информации о любых формулах с помощью функции MathematicalFunctionData — прим. ред.].
Очевидно легко сказать, что же такое поиск обычного текста. Единственная вопрос заключается в эквивалентности строчных и прописных букв.
Для математических формул всё сложнее, потому что есть ещё много различных эквивалентностей. Если спрашивать о всех возможных эквивалентностях, то всё станет слишком сложным. Но, если спросить об эквивалентностях, которые просто подразумевают замену одной переменной другой, то всегда можно определить, эквивалентны ли два выражения.
Однако, для этого потребуется мощь обнаружителя одинаковых паттернов Mathematica.
Мы планируем встроить возможности по поиску формул в наш сайт functions.wolfram.com, однако тут я не буду останавливаться на подробностях.
Невизуальные обозначения
Кто-то спрашивал о невизуальных обозначениях.
Первая мысль, которая у меня возникла, заключалась в том, что человеческое зрение даёт гораздо больше информации, чем, скажем, слух. В конце концов, с нашими глазами соединён миллион нервных окончаний, а с ушами лишь 50 000.
В Mathematica встроены возможности по генерации звуков начиная со второй версии, которая была выпущена в 1991 году. И были некоторые моменты, когда эта функция оказывалась полезной для понимания каких-то данных.
Однако я никогда не находил подобную функцию полезной для чего-то, связанного с обозначениями.
Доказательства
Кто-то спрашивал о представлении доказательств.
Самая большая проблема заключается в представлении длинных доказательств, которые были автоматически найдены с помощью компьютера.
Большое количество работы было проделано для представления доказательств в Mathematica. Примером является проект Theorema.
Самые сложные для представления доказательства — скажем, в логике — представляют из себя некоторую последовательность преобразований. Вот пример такого доказательства:
Даны аксиомы Шеффера для логики (f это NAND):
{f[f[a,a],f[a,a]]==a,f[a,f[b,f[b,b]]]==f[a,a], f[f[a,f[b,c]],f[a,f[b,c]]]==f[f[f[b,b],a],f[f[c,c],a]]}
Доказать коммутативность, то есть что f[a,b]==f[b,a]:
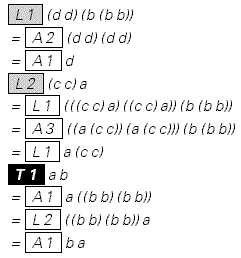
Замечание (a b) есть Nand[a,b]. В этом доказательстве L == лемма, A == аксиома, и T == теорема.
Отбор символов
Я хотел бы кое-что рассказать о выборе символов для использования в математической нотации.
Существует около 2500 часто используемых символов, которые не встречаются в обычном тексте.
Некоторые из них слишком картинны — скажем, обозначение для хрупких предметов. Некоторые слишком витиеватые. Некоторые полны чёрной заливки, так что они будут слишком сильно выделяться на странице (символ радиации, например).
Но некоторые могут быть вполне приемлемыми.
Если заглянуть в историю, часто можно наблюдать картину, как со временем написание некоторых символов упрощается.
Особой проблемой, с которой я не так давно столкнулся, был выбор хорошего обозначения для таких логических операций, как NAND, NOR, XOR.
В литературе по логике NAND обозначается по-разному:

Ни одно из этих обозначений мне особо не нравилось. В основном они наполнены тонкими линиями и недостаточно цельны для того, чтобы представлять бинарные операторы. Однако они передают своё содержание.
Я пришёл к следующему обозначению для оператора NAND, который основан на стандартном, однако имеющим улучшенную визуальную форму. Вот текущая версия того, к чему я пришёл:
Частотное распределение символов
Я упоминал о частотном распределении греческих букв в MathWorld.
В дополнение к этому я также посчитал количество различных объектов, именуемых с помощью букв, которые появляются в словаре физических терминов и математических сокращений. Вот результаты.
В более ранних образцах математической нотации, скажем, в 17 веке, обычные слова шли вперемешку с различными символами.
Однако всё более в таких сферах, как математика и физика, проявлялась тенденция к исключению слов из обозначений и именования переменных одной или двумя буквами.
В некоторых областях инженерии и социальных наук, куда математика дошла не так давно и не является слишком абстрактной, обычные слова гораздо чаще можно встретить в качестве имён переменных.
Та же история с современными тенденциями в программировании. И всё работает хорошо, пока формулы достаточно просты. Однако по мере усложнения формул нарушается их визуальный баланс, и становится уже сложно разглядеть их общую структуру.
Части речи в математической нотации
В разговоре о соответствии языка математики и обычного языка я хотел упомянуть вопрос частей речи.
Насколько я знаю, во всех обычных языках есть глаголы и существительные, и в большинстве из них есть прилагательные, наречия и др.
В математической нотации можно представлять переменные как существительные и глаголы как операторы.
А что насчёт других частей речи?
Вещи наподобие иногда играют роль союзов, как и в обычных языках (примечательно, что во всех языках есть отдельные слова для AND и OR, однако ни в одном нет слова для NAND). А в качестве префиксного оператора может рассматриваться как прилагательное.
Однако не до конца ясно, в какой мере различные виды лингвистических структур, связанные с частями речи на обычном языке, отражены в математическом обозначении.
По вопросам о технологиях Wolfram пишите на info-russia@wolfram.com
