
Поиск повторений в двумерном массиве, или вычислительная сложность на примере
7 мин
Доброго времени суток, уважаемое хабрасообщество.
Когда я учился в институте на втором или третьем курсе (то есть, в общем, не так и давно), был у меня, помимо прочих, предмет под названием «алгоритмы и структуры данных». Рассказывали там, однако, не только про сами алгоритмы и структуры, но и о таком понятии, как «вычислительная сложность». Признаюсь, тогда это меня не очень заинтересовало.
«Наверняка заморачиваться с исследованием алгоритма на пространственную и временную сложность нужно только при разработке либо очень высокопроизводительных/высоконагруженных систем, либо при работе с действительно большими объемами данных», — примерно такие мысли посещали меня (да и, наверное, не только меня) тогда.
Однако недавно мне пришлось сильно изменить свое мнение из-за простой, казалось бы, задачи.
Когда я учился в институте на втором или третьем курсе (то есть, в общем, не так и давно), был у меня, помимо прочих, предмет под названием «алгоритмы и структуры данных». Рассказывали там, однако, не только про сами алгоритмы и структуры, но и о таком понятии, как «вычислительная сложность». Признаюсь, тогда это меня не очень заинтересовало.
«Наверняка заморачиваться с исследованием алгоритма на пространственную и временную сложность нужно только при разработке либо очень высокопроизводительных/высоконагруженных систем, либо при работе с действительно большими объемами данных», — примерно такие мысли посещали меня (да и, наверное, не только меня) тогда.
Однако недавно мне пришлось сильно изменить свое мнение из-за простой, казалось бы, задачи.
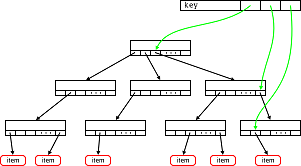 Этот топик повествует об использовании Radix Tree на практическом примере.
Этот топик повествует об использовании Radix Tree на практическом примере.  «От желудка иглобрюхих рыб отходят мешковидные выросты. При появлении опасности они наполняются водой или воздухом, из-за чего рыба становится похожой на раздувшийся шар
«От желудка иглобрюхих рыб отходят мешковидные выросты. При появлении опасности они наполняются водой или воздухом, из-за чего рыба становится похожой на раздувшийся шар