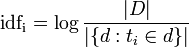SGVsbG8gd29ybGQh или история base64
3 мин
Краткая предыстория
Вообще, все началось давно. Настолько давно, что вряд ли остались свидетели holy wars тех дней, когда решалось — сколько же бит должно быть в байте.
Это сейчас нам кажется само собой разумеющимся, что 1 байт = 8 бит, что в байте можно закодировать 256 различных значений. Но когда-то было совсем не так. История помнит и семибитные кодировки, и шестибитные, и даже более экзотические системы (например — ЭВМ «Сетунь», которая использовала троичную логику, то есть один троичный бит — трит мог иметь три, а не два значения, для нее было справедливо соотношение 1 трайт = 6 тритам). Но если оставить в стороне всякую экзотику, то мэйнстримом все-таки были кодировки, в которых 6, 7 или 8 бит в байте.
Шестибитная кодировка (например — BCD) позволяла закодировать в одном байте 64 различных значения, что, как казалось, было вполне достаточно для кодирования алфавитно-цифровых символов, а «лишний» седьмой бит расширял кодировку уже до 128 символов.
Однако скоро восьмибитный байт стал общепринятым.