Сравнительный анализ HDFS 3 с HDFS 2
3 мин
В нашей компании СберТех (Сбербанк Технологии) на данный момент используется HDFS 2.8.4 так как у него есть ряд преимуществ, таких как экосистема Hadoop, быстрая работа с большими объемами данных, он хорош в аналитике и многое другое. Но в декабре 2017 года Apache Software Foundation выпустила новую версию открытого фреймворка для разработки и выполнения распределённых программ — Hadoop 3.0.0, которая включает в себя ряд существенных улучшений по сравнению с предыдущей основной линией выпуска (hadoop-2.x). Одно из самых важных и интересующих нас обновлений это поддержка кодов избыточности (Erasure Coding). Поэтому была поставлена задача сравнить данные версии между собой.
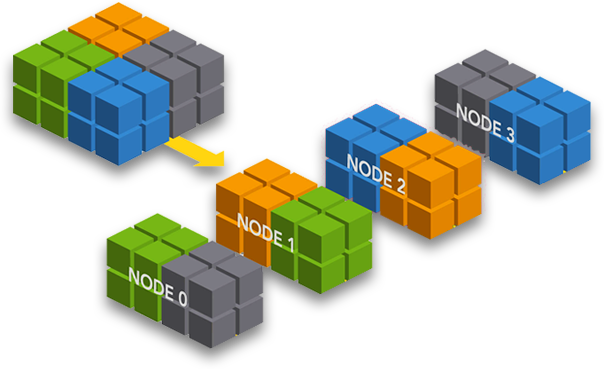
Компанией СберТех на данную исследовательскую работу было выделено 10 виртуальных машин размером по 40 Гбайт. Так как политика кодирования RS(10,4) требует минимум 14 машин, то протестировать ее не получится.
На одной из машин будет расположен NameNode помимо DataNode. Тестирования будет проводиться при следующих политиках кодирования:
А также, используя репликацию с фактором репликации равным 3.
Размер блока данных был выбран равным 32 Мб.
Компанией СберТех на данную исследовательскую работу было выделено 10 виртуальных машин размером по 40 Гбайт. Так как политика кодирования RS(10,4) требует минимум 14 машин, то протестировать ее не получится.
На одной из машин будет расположен NameNode помимо DataNode. Тестирования будет проводиться при следующих политиках кодирования:
- XOR(2,1)
- RS(3,2)
- RS(6,3)
А также, используя репликацию с фактором репликации равным 3.
Размер блока данных был выбран равным 32 Мб.