
Оформление сложных условий
4 мин
Условный оператор в обычной своей форме источником проблем является сравнительно редко. Однако само условие порой оказывается достаточно сложным и встает на пути к мечте любого разработчика. Речь, конечно же, о красивом и читаемом коде.
Возможно, я не там искал, но ни разу в стандартах оформления кода не встречал упоминаний о том, как быть со сложными условиями. Разобраться с ними — и есть цель данной статьи.
Так как с высасыванием из пальца у меня проблемы, в качестве источника примеров взята часть исходников GCC 4.8.2, для авторов которых стандарты оформления — не пустой звук. Используя примеры, буду приводить файл и строку начала, чтобы желающие могли убедиться, что все честно.
Возможно, я не там искал, но ни разу в стандартах оформления кода не встречал упоминаний о том, как быть со сложными условиями. Разобраться с ними — и есть цель данной статьи.
Так как с высасыванием из пальца у меня проблемы, в качестве источника примеров взята часть исходников GCC 4.8.2, для авторов которых стандарты оформления — не пустой звук. Используя примеры, буду приводить файл и строку начала, чтобы желающие могли убедиться, что все честно.
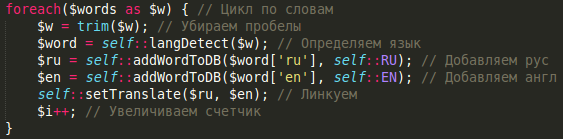 В последнее время, набирает популярность мысль, что комментарии в коде — дело не обязательное, и даже вредное. Буквально вчера вечером, общаясь со знакомым молодым программистом, попросившим посмотреть его код, я обнаружил, что комменты отсутствовали вовсе, даже привычные описания методов. На мой удивленный смайлик, был ответ: “Комментарии — первый признак плохого кода”. И черт бы с ним, с начинающим программистом, но я периодически читаю что-то похожее в блогах, и слышу от коллег. Может программирование в очередной раз сделало шаг вперед, а я, среди отстающих? Под катом, немного размышлений, о том, когда и почему стоит или не стоит комментировать свой код.
В последнее время, набирает популярность мысль, что комментарии в коде — дело не обязательное, и даже вредное. Буквально вчера вечером, общаясь со знакомым молодым программистом, попросившим посмотреть его код, я обнаружил, что комменты отсутствовали вовсе, даже привычные описания методов. На мой удивленный смайлик, был ответ: “Комментарии — первый признак плохого кода”. И черт бы с ним, с начинающим программистом, но я периодически читаю что-то похожее в блогах, и слышу от коллег. Может программирование в очередной раз сделало шаг вперед, а я, среди отстающих? Под катом, немного размышлений, о том, когда и почему стоит или не стоит комментировать свой код. За годы присутствия на хабре я прочитал немало статей на тему того, как должен выглядеть идеальный код. И поменьше статьей о том, как конкретно достигать этого идеала. Также стоит отметить, что весьма значительная часть всех этих материалов была переводом западных источников, что, вероятно, является следствием более зрелой отрасли IT «за рубежом», со всеми вытекающими вопросами и проблемами.
За годы присутствия на хабре я прочитал немало статей на тему того, как должен выглядеть идеальный код. И поменьше статьей о том, как конкретно достигать этого идеала. Также стоит отметить, что весьма значительная часть всех этих материалов была переводом западных источников, что, вероятно, является следствием более зрелой отрасли IT «за рубежом», со всеми вытекающими вопросами и проблемами.




