25 октября в Минске пройдет первая встреча DataTalks.
 DataTalks – это:
DataTalks – это:
• Неформальные встречи бизнес-аналитиков и специалистов в области анализа данных
• Профессиональное общение и нетворкинг с экспертами Беларуси и СНГ
• Возможность узнать о новейшем опыте применения аналитики данных для решения бизнес-задач в компаниях, работающих на мировом и местном рынках
• Хороший повод задать вопросы экспертам и поделиться собственным опытом.
Для кого? Бизнес-аналитиков, исследователей, менеджеров проектов, информационных архитекторов и системных аналитиков. DataTalks – для всех, кто использует или собирается использовать в своей работе анализ данных или сложные математические алгоритмы, как для отчетности и принятия решений, так и для создания информационных систем.
Первая встреча, по сути, знакомство, будет посвящена выявлению интересных тем в области практического применения анализа данных. Они лягут в основу последующих встреч сообщества аналитиков



 Не все знают, но в Google Play существует вполне легальная возможность выгрузить все комментарии и оценки к своему приложению в отдельный CSV-файл, после чего заняться каким-нибудь анализом, не доступном из гугловской системы. Но делается это с помощью внешней утилиты gsutil, написанной на Python’е. Так что в этом посте будет небольшая инструкция по тому, как это сделать.
Не все знают, но в Google Play существует вполне легальная возможность выгрузить все комментарии и оценки к своему приложению в отдельный CSV-файл, после чего заняться каким-нибудь анализом, не доступном из гугловской системы. Но делается это с помощью внешней утилиты gsutil, написанной на Python’е. Так что в этом посте будет небольшая инструкция по тому, как это сделать.

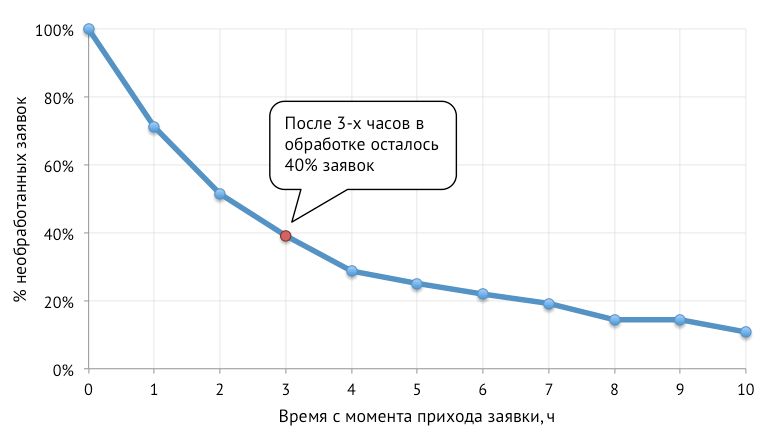
 Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения,
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, 