
Аномальное голосование на сайте «Российская общественная инициатива» (РОИ)
2 мин
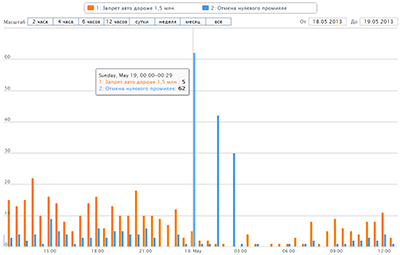 По результатам мониторинга голосования на сайте «Российская общественная инициатива» (РОИ), обнаружились интересные подробности. Складывается ощущение, что кто-то очень не хочет, чтобы инициатива известного оппозиционера стала первой набравшей 100 тысяч голосов. А поскольку пиарить свою инициативу, как это делает Алексей Н. это сильно хлопотно, то на арену выходят другие методы, привычные в оффлайн голосованиях.
По результатам мониторинга голосования на сайте «Российская общественная инициатива» (РОИ), обнаружились интересные подробности. Складывается ощущение, что кто-то очень не хочет, чтобы инициатива известного оппозиционера стала первой набравшей 100 тысяч голосов. А поскольку пиарить свою инициативу, как это делает Алексей Н. это сильно хлопотно, то на арену выходят другие методы, привычные в оффлайн голосованиях.Я немного проапгрейдил график, чтобы выводилось не только абсолютные цифры, но и относительные. Добавилось 2 типа – относительный и прирост. Первый показывает изменения графика относительно начала выбранного отрезка времени, а второй – прирост голосов в виде столбчатой диаграммы (данные группируются в зависимости от масштаба графика).
 Группа исследователей из IBM, используя информацию о перемещениях 500 тыс. пользователей мобильной связи, разработали модель для улучшения маршрутов общественного транспорта.
Группа исследователей из IBM, используя информацию о перемещениях 500 тыс. пользователей мобильной связи, разработали модель для улучшения маршрутов общественного транспорта.  В одних только США на работу колл-центров служб поддержки пользователей ежегодно тратится 112 миллиардов долларов. При этом половина из 270 миллиардов обращений остаётся нерешённой. Почти каждый может вспомнить множество примеров, когда звонок в службу поддержки превращался в длительный квест по выслушиванию записанных стандартных фраз и нажиманию цифровых кнопок только для того, чтобы пообщаться с живым человеком и обнаружить, что он и сам толком не разбирается в вашей проблеме.
В одних только США на работу колл-центров служб поддержки пользователей ежегодно тратится 112 миллиардов долларов. При этом половина из 270 миллиардов обращений остаётся нерешённой. Почти каждый может вспомнить множество примеров, когда звонок в службу поддержки превращался в длительный квест по выслушиванию записанных стандартных фраз и нажиманию цифровых кнопок только для того, чтобы пообщаться с живым человеком и обнаружить, что он и сам толком не разбирается в вашей проблеме.  На Coursera сейчас идёт курс
На Coursera сейчас идёт курс  В данной статье я хочу рассказать вам об недавно приключившейся со мной ситуации и принятому пути ее решения. Я не профессиональный программист, однако небольшой опыт мне помог решить данную задачу.
В данной статье я хочу рассказать вам об недавно приключившейся со мной ситуации и принятому пути ее решения. Я не профессиональный программист, однако небольшой опыт мне помог решить данную задачу. 
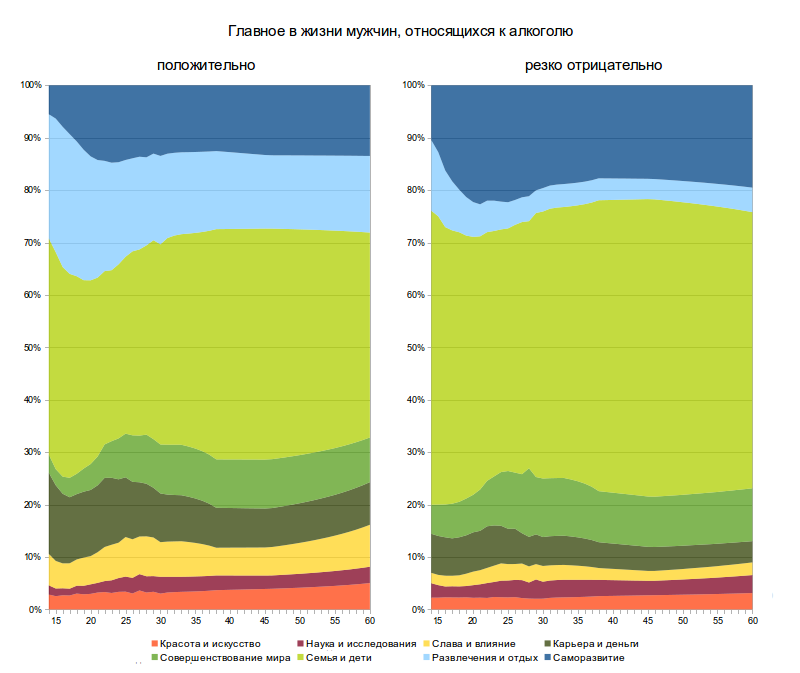
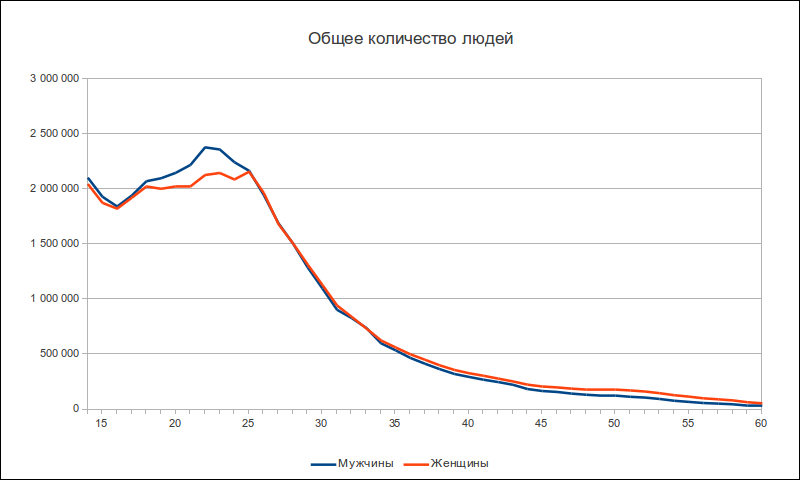







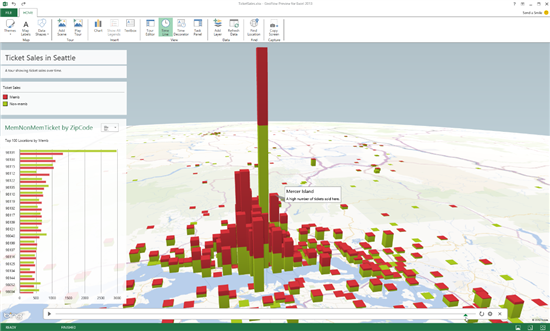
 Привет. В этом посте мы продолжим экспериментировать с
Привет. В этом посте мы продолжим экспериментировать с