
Альтернативное использование мощностей GPU?
5 мин
Недавно я опубликовал статью о распределенном рендеринге на GPU — поступили некоторые вопросы и предложения. Поэтому считаю нужным рассказать о теме более развернуто (и с картинками, а то без картинок статьи практически не читают), тем самым привлечь к этой теме больше читателей.
Думаю, этим вопросом заинтересуются обладатели мощных вычислительных систем: майнеры, геймеры, админы других мощных вычислительных систем.
Многие обладатели мощного железа задумывались над тем, а нельзя ли подзаработать на мощности своей железки, пока она стоит бестолку?

Красота моя бестоковая!
Думаю, этим вопросом заинтересуются обладатели мощных вычислительных систем: майнеры, геймеры, админы других мощных вычислительных систем.
Многие обладатели мощного железа задумывались над тем, а нельзя ли подзаработать на мощности своей железки, пока она стоит бестолку?
Красота моя бестоковая!


 В
В 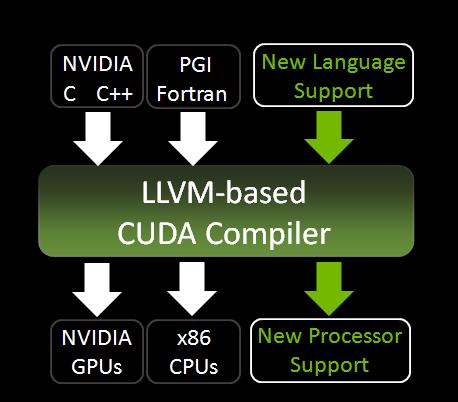
 Отладка параллельного кода – процесс утомительный и умозатратный. Ошибки распараллеливания проблематично отловить из-за недетерминированности поведения параллельных приложений. Более того, если ошибка обнаружена, ее часто сложно воспроизвести снова. Бывает, что после изменения кода, сложно удостовериться, что ошибка устранена, а не замаскирована. Чаще всего, ошибки в параллельной программе являются
Отладка параллельного кода – процесс утомительный и умозатратный. Ошибки распараллеливания проблематично отловить из-за недетерминированности поведения параллельных приложений. Более того, если ошибка обнаружена, ее часто сложно воспроизвести снова. Бывает, что после изменения кода, сложно удостовериться, что ошибка устранена, а не замаскирована. Чаще всего, ошибки в параллельной программе являются