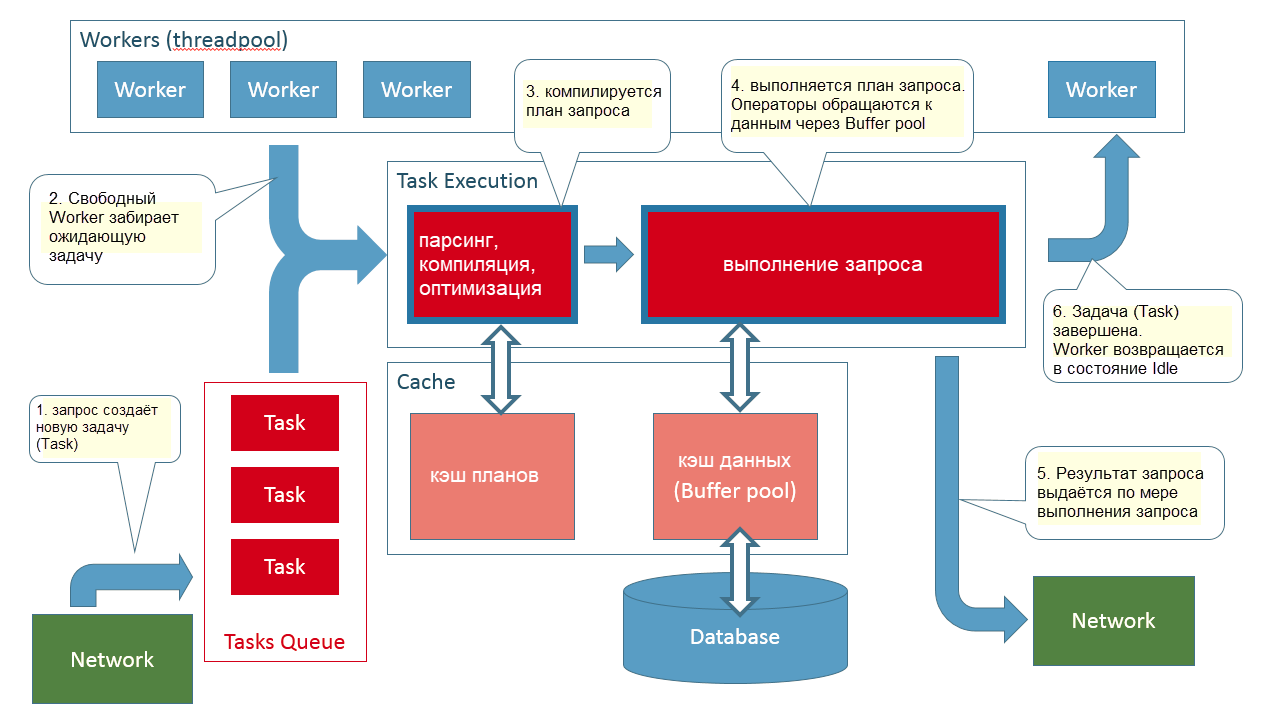
В этой статье попытаемся понять, как изменились процедуры обслуживания индексов для таблиц Microsoft SQL Server в современных условиях: при размещении файлов данных и журнала транзакций на SSD-дисках, многократном увеличении числа процессорных ядер и в условиях, когда оперативная память сервера стала измеряться Терабайтами.Действительно, мир стал другим. С тех пор как появились первые версии SQL Server, многое изменилось и многие методики, основанные на старых компьютерных ресурсах, работают уже не так эффективно, как прежде, когда без них невозможно было обойтись. Одной из таких методик, которая с давних пор воспринимается чуть ли не «серебряной пулей», а на деле превратилась в миф, является обязательная дефрагментация индексов, если в данные индекса достаточно часто вносятся изменения. Цель статьи развеять этот миф.
В своей документации, Майкрософт обращает наше внимание на то, что не стоит выполнять обслуживание индексов, не убедившись, что это принесёт пользу. Вот цитата:
«Чтобы избежать ненужного использования ресурсов, что может негативно влиять на рабочие нагрузки запросов, корпорация Майкрософт рекомендует не применять обслуживание индекса без предварительной оценки. Следует опытным путем оценить повышение производительности от обслуживания индексов для каждой рабочей нагрузки, используя рекомендуемую стратегию, и сопоставить его с затратами ресурсов и влиянием на рабочую нагрузку, которые потребуются для достижения этих преимуществ.»
В том же документе рассматриваются причины повышения производительности запросов после обслуживания индексов и делается замечание, что не всегда это связано с дефрагментацией, бывают и иные причины. Вот ещё одна цитата: