Протокол Handlersocket в деталях
9 мин
Всем здрасьте. Решил опубликовать русскую версию своей же статьи «HandlerSocket protocol explained», опубликованной по адресу http://wk-photo.ru/en/events/view/handlersocket-protocol-explained/.
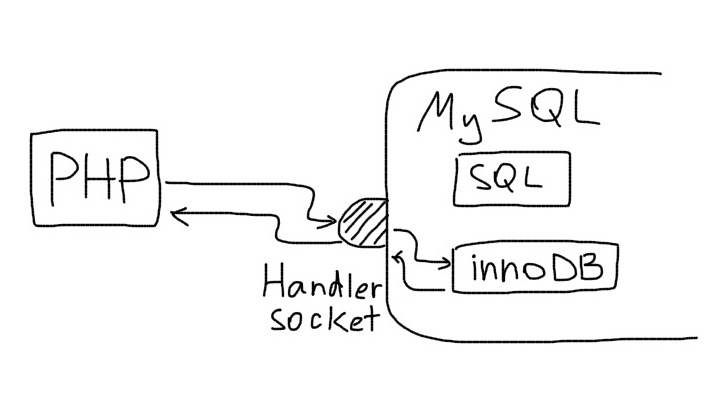
Итак, вы шли-шли и пришли к HandlerSocket. Чистый мёд. Это дьявольски быстрый вуду. А используемый протокол реально простой, как две копейки. Ну и если уж начистоту, кому важны детали протокола, если все равно будет использоваться какая-то библиотека, которая обо всем позаботится? Если, несмотря ни на что, вы все-таки хотите знать, что за неонка там внутре, можете нагуглить эту страницу. Несколько часов — и вы эксперт. Ну или вы хотите все и за 15 минут. Тогда добро поржаловать под кат!
Итак, вы шли-шли и пришли к HandlerSocket. Чистый мёд. Это дьявольски быстрый вуду. А используемый протокол реально простой, как две копейки. Ну и если уж начистоту, кому важны детали протокола, если все равно будет использоваться какая-то библиотека, которая обо всем позаботится? Если, несмотря ни на что, вы все-таки хотите знать, что за неонка там внутре, можете нагуглить эту страницу. Несколько часов — и вы эксперт. Ну или вы хотите все и за 15 минут. Тогда добро поржаловать под кат!
 Давным-давно (кажется, в прошлую среду) попался ко мне в руки дамп базы данных MySQL, который следовало немедленно развернуть на моей машине. Зачем это было нужно и откуда взялся дамп, рассказывать не буду, вряд ли это кому-то интересно. Важно то, что дамп был от MySQL 4.1.22 и снят он был при помощи одного широко известного
Давным-давно (кажется, в прошлую среду) попался ко мне в руки дамп базы данных MySQL, который следовало немедленно развернуть на моей машине. Зачем это было нужно и откуда взялся дамп, рассказывать не буду, вряд ли это кому-то интересно. Важно то, что дамп был от MySQL 4.1.22 и снят он был при помощи одного широко известного