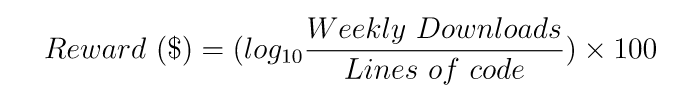Всем доброго времени суток.
В данной статье я решил поделиться опытом, накопленным за многие годы работы во front-end`е. Как и все вы, я был молод и мечтал создать что-то бессмертное. Ах, как я был молод, и как же я был глуп. Ничего вечного не существует и всё рано или поздно умирает. Однако, можно создать то, что протянет гораздо дольше обычного и даже будет адаптироваться к изменениям какое-то время. Поэтому сегодня предлагаю поговорить о паттернах проектирования для front-end приложений, выборе технологий и о том, чего делать не стоит. В этой статье буду проводить много аналогий со строительной тематикой и причиной тому небезызвестная история: «Если бы программисты строили дома».
Из чего строить?
Тут как бы все просто, но не всегда явно. Как говорится, давайте разбираться. Суперновые технологии с прорывными идеями сразу мимо. Вы меня спросите почему? Так давайте пофантазируем на тему того, что вы взяли их в проект: через года полтора сам проект не получил поддержки сообщества, а его создатель забил на него. Вы остались с нерелевантным стеком, отсутствием возможности найти разработчиков для создания кода и дальнейшей поддержки проекта. Нет обновлений, читай через два года у вас на руках старая коричневая субстанция.
Посмотрим и на обратную сторону медали: беря сверхнадежное решение, которому много лет, вы обрекаете проект на скорый апдейт или умирание. Знавал я одну крупную компанию, которая использовала java 8. Мотивация звучала так: она надежна как швейцарский нож. На минуточку, на дворе 2021 год и она устарела не только морально, но и технически (на момент написания, актуальной версией является java 17).