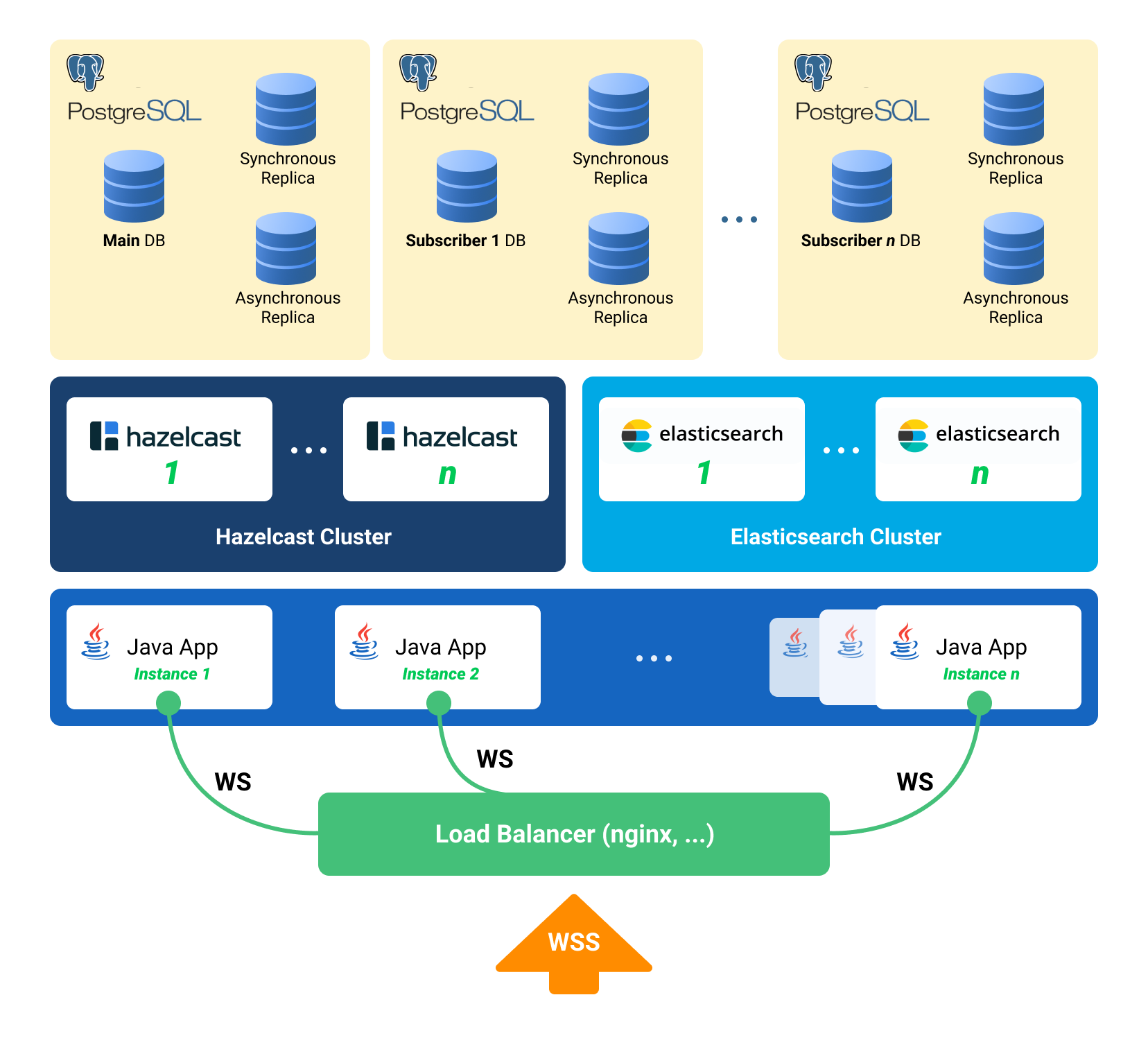
Экспресс-обзор производительности PostgreSQL 10.5 в новейших облачных сервисах Яндекс.Облака
3 мин
Буквально на днях Яндекс открыл доступ для beta-пользователей к своему новому сервису — Яндекс.Облако. Так вышло, что это событие совпало с необходимостью выбора облачной платформы для одного из наших внутренних проектов и я решил сразу протестировать производительность решений Яндекса.
Для теста я взял PostgreSQL и старый добрый pgbench. Выбор на СУБД пал потому что было интересно протестировать и сравнить производительность не только виртуальных машин, то и managed database сервисов.
Disclaimer: автор не является ни профессиональным админом, ни DBA, ни специалистом по настройке облачных решений. Тестирование проводилось сугубо в личных целях и на объективность не претендует, поэтому прошу воспринимать статью «as is». Внутри не будет какого-то глубокого разбора, но будет экспресс-сравнение с Selectel VPC (на разных дисках) и различными конфигурациями AWS EC2/RDS в части производительности и стоимости решений. Возможно, это сэкономит кому-то немного времени.
Подробности Yandex.Cloud vs Selectel VPC vs AWS под катом.
Для теста я взял PostgreSQL и старый добрый pgbench. Выбор на СУБД пал потому что было интересно протестировать и сравнить производительность не только виртуальных машин, то и managed database сервисов.
Disclaimer: автор не является ни профессиональным админом, ни DBA, ни специалистом по настройке облачных решений. Тестирование проводилось сугубо в личных целях и на объективность не претендует, поэтому прошу воспринимать статью «as is». Внутри не будет какого-то глубокого разбора, но будет экспресс-сравнение с Selectel VPC (на разных дисках) и различными конфигурациями AWS EC2/RDS в части производительности и стоимости решений. Возможно, это сэкономит кому-то немного времени.
Подробности Yandex.Cloud vs Selectel VPC vs AWS под катом.






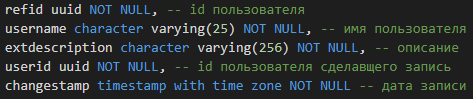


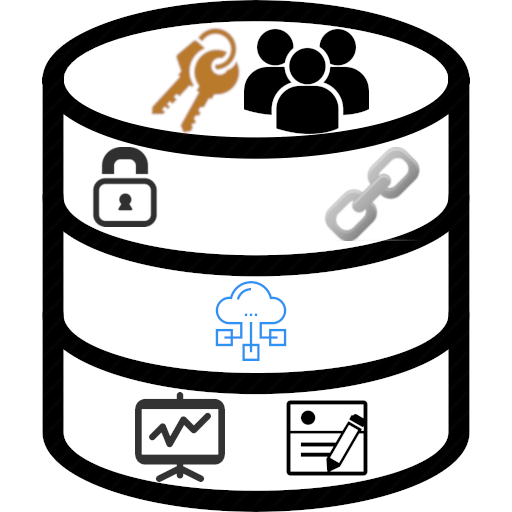 Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.
Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.