
Отпуск. Где? Когда? R
4 мин
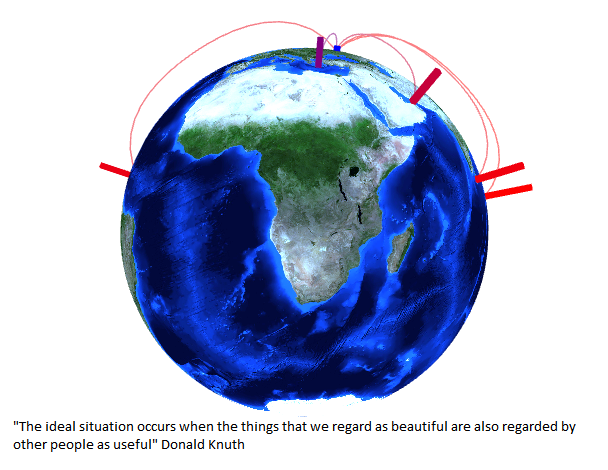 В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир».
В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир». 






 Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.