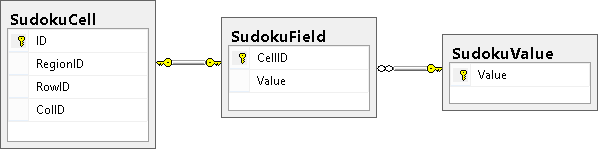
Вышла новая версия LinqTestable — библиотеки для тестирования запросов к бд через ORM
5 мин
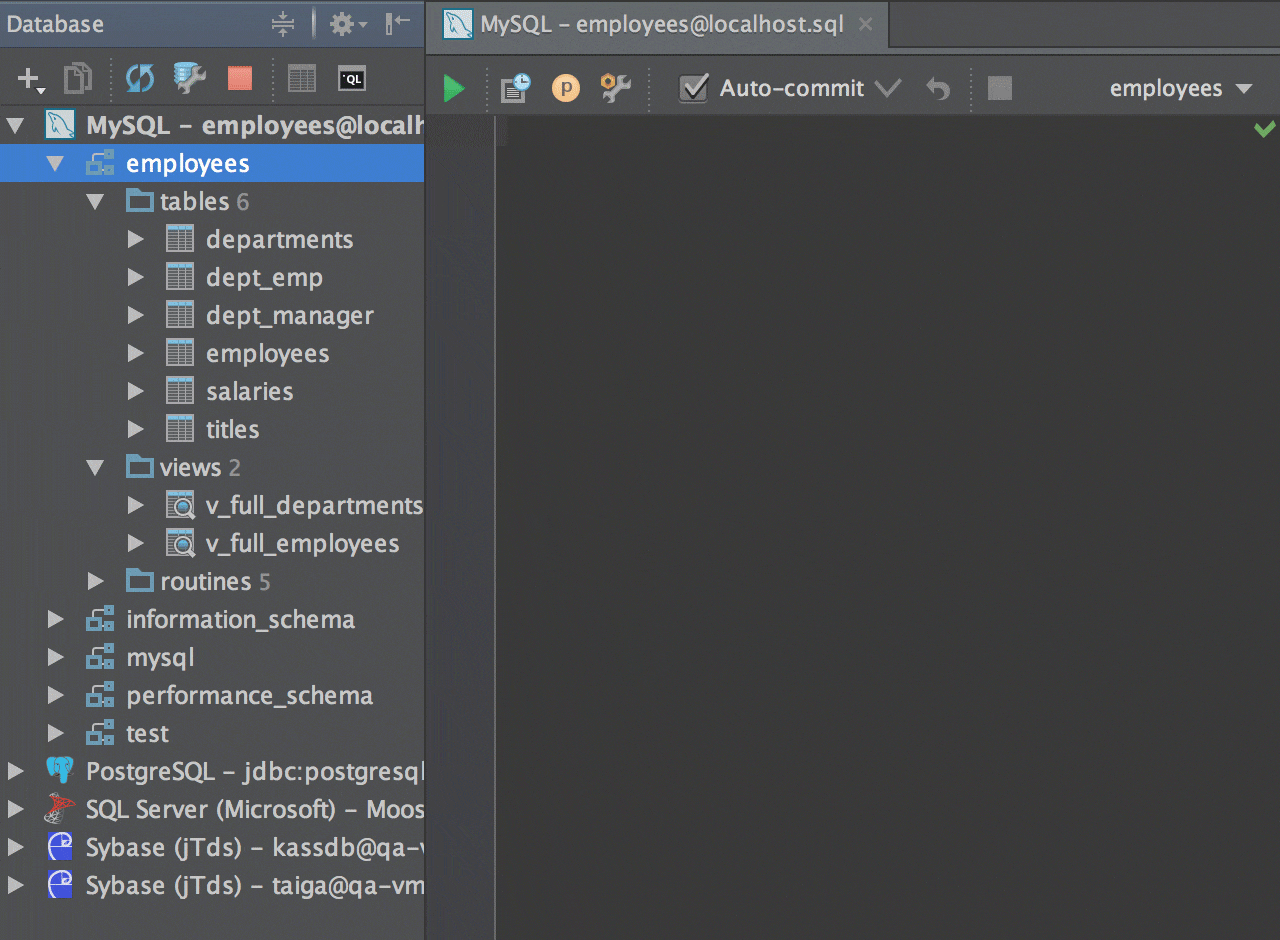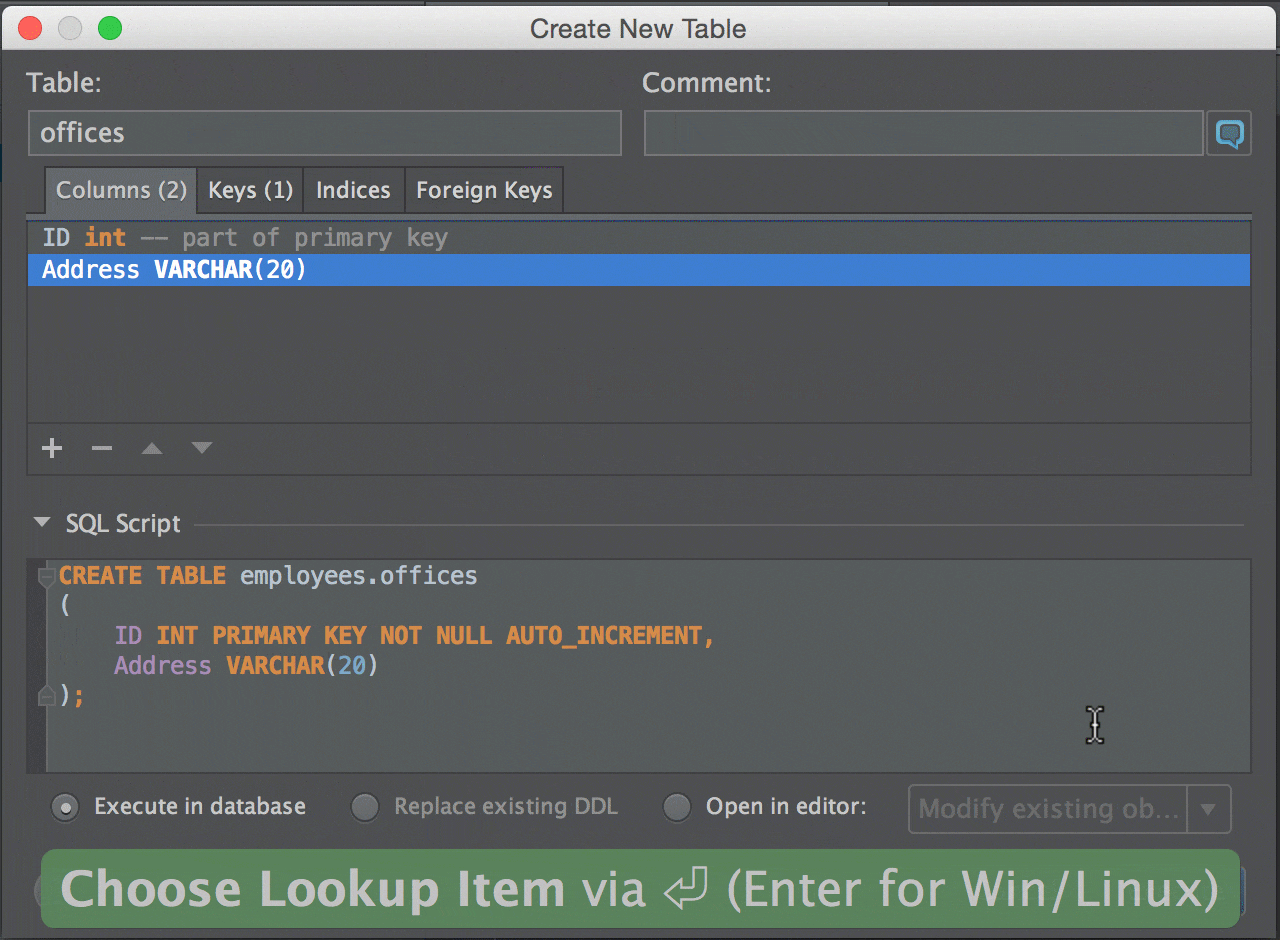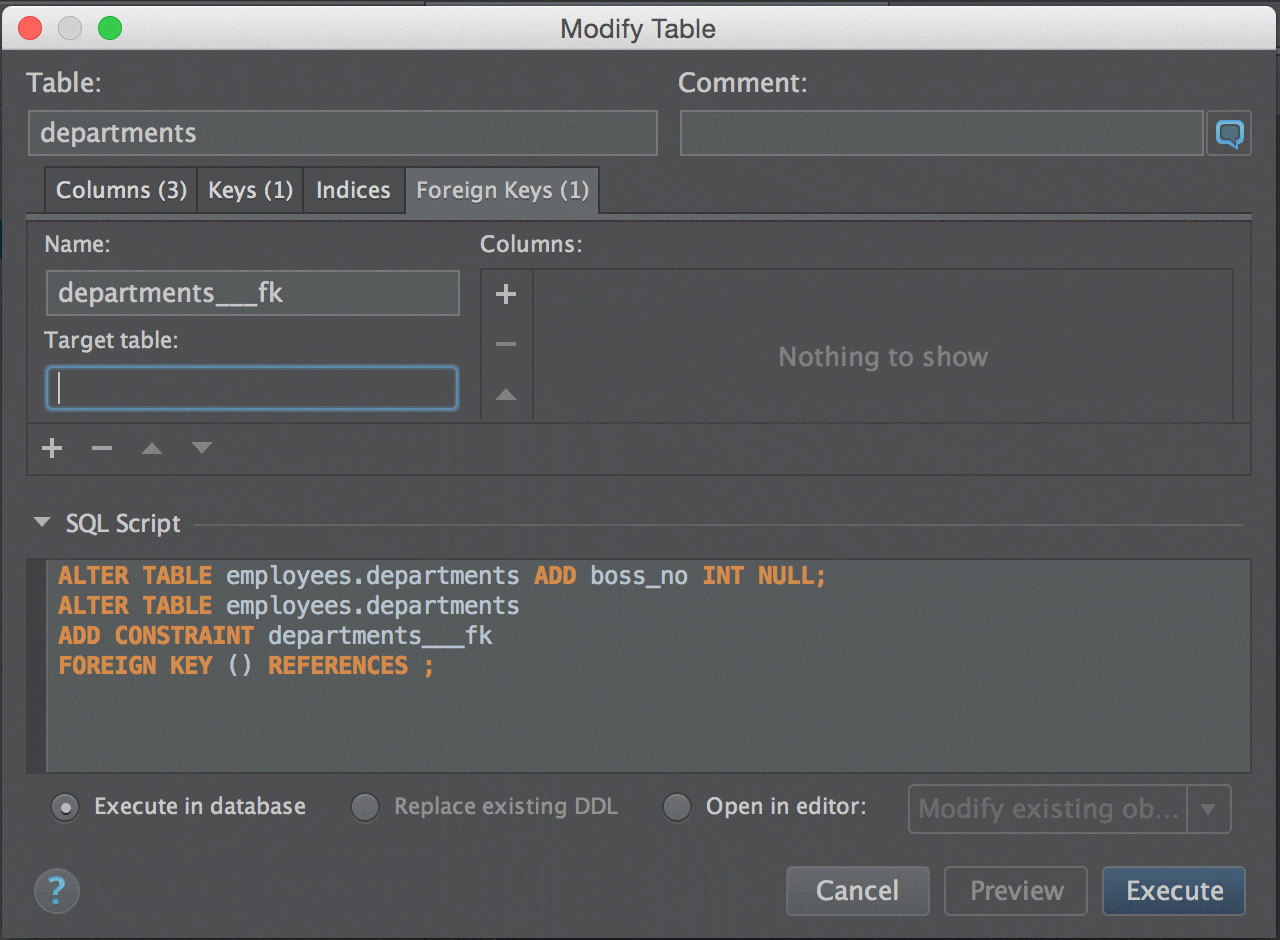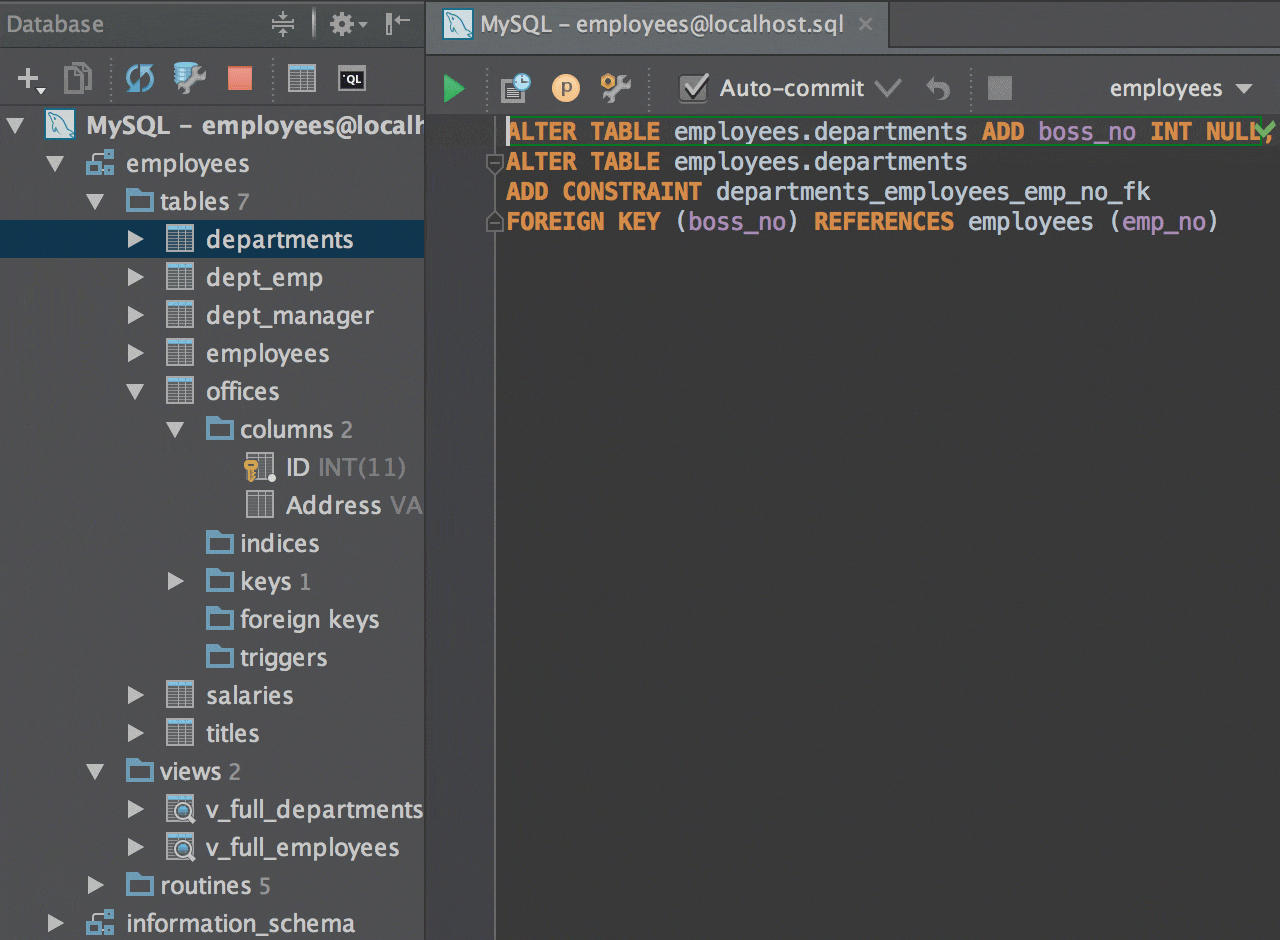
LinqTestable — это библиотека, помогающая преодолеть в тестах концептуальный разрыв между ООП и реляционной БД, возникающий из-за разницы поведения NULL-а в этих двух парадигмах. Например, сравнение NULL == NULL возвращает истину в объектных языках, и ложь в реляционной модели. Помимо этого, NULL.SomeField вернёт NULL в реляционной модели и выбросит NullReferenceException в C#. LinqTestable предназначена для решения этой проблемы.

 Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.
Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.

 СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.
СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.