
В данной статье я хотел бы поделиться своими мыслями об идеальном языке программирования общего назначения. В первую очередь — о языке, который мог бы заменить С++.
Так случилось, что языки программирования — мое хобби и мой основной интерес в сфере IT. Наверное, любой программист иногда мечтает создать свой собственный — идеальный — язык программирования. Для меня это нечто большее, чем просто мечта, фактически я уже давно собираю всю информацию по различным языкам и проектирую свой собственный язык.
На разных ресурсах я регулярно высказываюсь по вопросам этой тематики. В этой статье я попытался собрать основные мысли воедино. Мы рассмотрим основные недостатки С++, особенности других языков, которые так или иначе можно сравнивать с С++, и — самое интересное — потребности программистов в языковых фичах, на примере библиотеки Boost.
Данная статья не претендует на какую-то техническую полезность (хотя если она будет кому-то полезна, это замечательно). Это статья — приглашение к обсуждению.
С++ далеко не идеален. Думаю, любой С++ программист согласится со мной.
Недостатки С++ — это в первую очередь тяжелое наследие Си: ужасная система инклудов и полное отсутствие модульности. Включение заголовочного файла приводит по сути к включению всего содержимого файла в единицу компиляции; поскольку заголовочные файлы включают друг друга, а современные библиотеки могут содержать десятки тысяч заголовочных файлов… разумеется, это не может не сказываться на времени компиляции. Иногда помогают различные решения-хаки типа «precompiled headers» (pch), но, как показывает практика, эти решения тоже далеко не идеальны. Например, Visual C++ не позволяет создавать общие pch для нескольких проектов одного solution (при том, что в precompiled headers как правило включают действительно общие и неизменяемые заголовки — такие как stl, boost и т.п.).
Ну и конечно внутренний перфекционизм, свойственный любому программисту, решительно протестует против такой реализации — по сути костыля, подпорки под неправильную изначально архитектуру.
#define true false
Конечно же «лексический» препроцессор, еще один привет от Си, тяжелое и намертво приросшее наследие unix-way (да, когда-то это действительно была отдельная программа, и да, существуют альтернативные препроцессоры, например m4… но сейчас препроцессор однозначно воспринимается как часть языка). Но совершенно очевидно, что языку нужен некий набор возможностей, решающий задачи препроцессора (а точнее система синтаксических макросов), и это не должна быть нестандартная сторонняя программа, никак не связанная с языком.
И из относительно нового — тьюринг-полнота шаблонов, породившая адские конструкции метапрограммирования на этих самых шаблонах. Изначально предполагалось, разумеется, что шаблонные функции и классы будут использоваться исключительно для написания универсальных алгоритмов и структур данных, не зависящих от типа обрабатываемых/хранимых данных. Прекрасное применение! Но.
Отсутствие встроенных синтаксических макросов и вечное чувство голода по фичам заставили программистов создать на шаблонах полноценные метаязыки, с метатипами, метаалгоритмами, с вычислениями, выполняющимися компилятором во время компиляции… Что же в этом плохого? Да ничего, кроме того, что это — по сути своей костыли.
Но просто неприятно, когда например ключевые слова (struct) используются совсем не для того, для чего они предназначены. Ну и конечно неадекватные сообщения об ошибках, нередко возникающие из-за случайной опечатки и занимающие десятки (если не сотни) строк на одну ошибку… это поистине ужасно.
Разумеется, в С++ хватает и других недостатков — по мелочам. Так или иначе, многие из них учтены в следующем поколении языков прикладного программирования — Java и C#. Кстати, на мой вкус C# развивается наиболее динамично и органично впитывает в себя фичи из многих других языков; это отличный пример красивого и сбалансированного языка (а значит, и отличный образец, на который можно смотреть при проектировании новых языков). Но ни Java, ни C# все-же не являются языками системного программирования.
Нельзя не отметить и еще одну группу новых (относительно С++) языков, к которым я бы отнес D, Go, Rust, Swift, Nim, и заодно относительно старый Objective C (за его очень интересную особенность — рантайм).
Что же в этих языках интересного?
Начнем с D. Язык разрабатывался как «улучшенный С++», и действительно — многие концепции сделаны более грамотно. Аккуратно реализовано контрактное программирование, есть ФП, есть некая реализация метапрограммирования (но можно сделать лучше!). Язык компилируется в нативный код, а значит, может претендовать на «системность». Но я бы не выделил в D какой-то одной фичи, которая затмевает все. Тем ни менее, складывается впечатление, что язык пошел по пути С++ в части накопления «хаков», это особенно заметно при изучении кода компилятора (чем я периодически занимаюсь).
Go. Среди приятных вещей — структурная типизация интерфейсов. Возможность крайне интересная, сразу хочется воспользоваться…
Еще стоит упомянуть embedding вместо наследования. Когда смотришь на это, думаешь — а ведь это должно быть еще в Си! Настолько это просто в реализации — и, тем ни менее, как элегантно выглядит это решение. Встроенная в язык поддержка многопоточности тоже радует.
Rust. Основная фича — потрясающая система умных указателей и проверок во время компиляции. Да, это стоит брать в идеальный язык… хотя многие жалуются, что система переусложнена. В действительности в ней нет ничего лишнего, хотя я бы не стал отказываться и от классических указателей (в Rust кстати от них не отказываются, они просто завернуты в unsafe). Можно ли такое совместить? Можно. Нет ничего страшного в возможностях, страшно их отсутствие.
И еще я бы хотел упомянуть Objective C. Язык достаточно старый, но людям незнакомым с миром OSX найдут в нем много интересного. Это особая реализация ООП, в частности отправка сообщений вместо прямого вызова методов, система селекторов и метаклассов. Пришедшие в язык из Smalltalk, эти фичи позволяют в компилируемом языке делать многие удивительные вещи, достижимые только в интерпретируемых скриптах — в частности, добавлять методы в классы прямо во время выполнения программы! По-моему, прекрасная возможность.
Следующий интересный вопрос — соотношение фич языка и того, что можно вынести в библиотеки. Так сложилось, что долгое время именно С++ был самым мощным языком программирования универсального назначения (да и сейчас пожалуй остается им, несмотря на все недостатки). Альтернатив не было, но сам по себе С++ долгое время развивался достаточно медленно, а программистам всегда хочется большего! Так или иначе, но стали появляться и развиваться различные библиотеки. Несмотря на то, что стандартная библиотека уже была, многие другие библиотеки и фреймворки часто дублировали ее функциональность своими классами. Яркий пример — строки. Казалось бы, в С++ есть стандартная строка (std::string), но нет — практически каждая более-менее крупная библиотека имеет свою реализацию строк. CString (MFC/ATL), QString (Qt), TString (VCL), wxString (wxWidgets).
Та же участь постигла различные контейнеры (динамические массивы и списки), базовые классы для различных иерархий (object — правда надо признать что в стандартной библиотеке ничего подобного нет). Я уже не говорю про переопоределения простых типов, встречающиеся практически в каждой небольшой программе (даже не библиотеке). Помните всяческие UINT, uint, u32, DWORD, uint32_t… Но наиболее интересным объектом для исследования дизайна языка является пожалуй библиотека Boost (как официальная ее часть, так и библиотеки в статусе Under Constuction, находящиеся в Boost Incubator и прочие неофициальные расширения). К ней мы еще вернемся.
Сейчас же можно сказать, что С++ выглядит так: небольшое языковое ядро, небольшая стандартная библиотека, и множество сторонних библиотек, пересекающихся друг с другом и частично со стандартной библиотекой и захватывающих разные области ответственности — от эмуляции языковых фич до прикладных задач. Многие библиотеки опираются только на ядро. Примерно так:

Маленькое языковое ядро не поддерживает многие языковые фичи и провоцирует программистов писать «эмуляцию языковых возможностей». Поскольку программистов много, то и соответствующих эмуляций много; они как правило несовместимы между собой; громоздки (т.к. построены на нестандартном и/или неочевидном использовании существующих языковых возможностей); трудны в компиляции и отладке, да и вообще в понимании. С другой стороны, маленькое ядро позволяет языку не содержать ничего лишнего и это хорошо (более того, это необходимо для системного программирования). Противоречие? На самом деле разрешимое противоречие. Вот моя схема организации идеального языка:
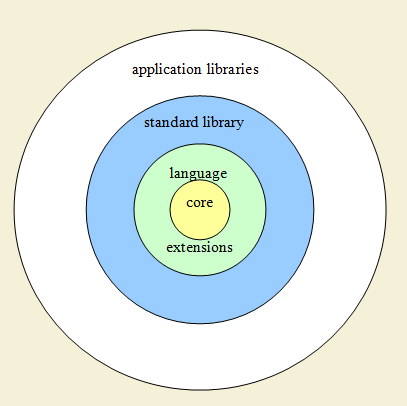
В центре — базовое языковое ядро. Вокруг него — «language extensions», языковые расширения — некие части языка, которые поддерживаются синтаксически, но которые можно включать и отключать при сборке проекта, а также заменять на свои реализации; дальше — стандартная библиотека, поддерживающая все что относится к программированию общего назначения; и вокруг — прикладные библиотеки, которые не пытаются эмулировать функции ядра, а решают чисто прикладные задачи. Прикладные библиотеки должны реализовывать специфические вещи. Это существенно важно — разница между общим и специфическим. Работа с графикой, с сетью, с железом; специфическая математика, криптография, прикладные библиотеки для каких-то особых областей; работа с разными файловыми форматами, с базами данных, с различными сервисами… все это специфические, прикладные направления, и они безусловно должны реализовывать в виде библиотек. А вот рефлексия или многопоточность, функции высшего порядка или сопрограммы — это фундаментальные с точки зрения языка вещи, и они должны поддерживаться в языке (некоторые — с возможностью замены реализации по умолчанию на что-то другое).
Вернемся к библиотеке Boost. Поговорим о Бусте как о ярчайшем примере того, что языки развиваются гораздо медленнее, чем того хотят программисты. Добрая половина библиотек Буста — это по сути эмуляция языковых фич. Возможно, когда нибудь я напишу отдельные статьи про библиотеки Буста… здесь же — лишь краткий обзор того, что там есть — в причем контексте включения этих фич непосредственно в язык программирования. У Буста есть своя классификация библиотек, с которой я не вполне согласен (хотя и цели классификации у меня другие). Часть библиотек безусловно относится к группе «стандартная библиотека»; часть — вообще прикладные библиотеки; но значительная часть — это именно то, чего не хватает в самом языке, в ядре! Я не буду здесь приводить ни своего деления, ни описания библиотек (это тема отдельной статьи, а то и нескольких). Вместо этого я просто дам список (неполный!) тех библиотек библиотек Буста, которые я бы отнес к языковому ядру:
- integer — метаинформация и трейты для целочисленных типов
- multiprecision — обертка для библиотек работы с числами произвольной точности GMP, MPIR, MPFR
- any — универсальный динамический тип
- optional — опциональный тип, maybe; по идее должен быть встроен в язык и интегрирован с nullable
- variant — алгебраический тип данных (sum-type, tagged union)
- preprocessor — метапрограммирование на сишном препроцессоре
- inentity_type — хелпер для генерации уникальных имен типов
- assign — мультиоперации, связанные с заполнением контейнеров
- mpl — контейнеры типов и операции над ними
- fusion — контейнеры типов и значений и операции над ними
- tuple — кортежи
- bind — функциональные объекты, создаваемые с помощью частичного применение функций
- function — функциональные объекты
- lambda — лямбда-функции; кстати, кое-в чем превосходящие лямбды из c++11;
- local_function — эмуляция вложенных функций
- signals2 — сигналы и слоты
- context — сохранение и восстановление состояния потока (стека и регистров)
- coroutine — реализация сопрограмм
- foreach — цикл по коллекциям
- parameter — эмуляция именованных аргументов фунций
- scope_exit — языковая конструкция, в языке D это называется scope(exit), scope(success), scope(failure), в Go — defer
- type_erasure — альтернативная реализация рантайм полиморфизма
- predef — метаинформация об ОС, компиляторе, платформе...,
- typeof — эмуляция оператора typeof / decltype
- endian — работа с числами с разным порядком байт
Напомню, что это далеко не полный список (и еще я даже не рассматриваю здесь библиотеки расширений Буста, а там тоже немало интересного — например Contract, Hana, Introspection, Mirror, Reflection...). Отмечу, что далеко не все библиотеки следует включать в языковое ядро: в общем случае, достаточно включить в ядро лишь некоторую небольшую (и по сути общую для многих библиотек) часть, и может оказаться, что многие библиотеки из этого списка вообще окажутся не нужны. Также включение в языковое ядро позволит избежать многих ограничений, накладываемых на существующие искусственные реализации различных фич. Такие прекрасные возможности, как алгебраические типы данных, универсальный динамический тип any, опциональные типы, именованные параметры конечно же лучше всего реализовать на уровне языка.
Теперь перейдем к «Language Extensions». Что это такое и зачем я это ввел?
На самом деле такие «расширения» так или иначе существуют и в С++, просто их никто не выделяет в отдельную группу. Пример — система выделения памяти в С++. Интерфейс языкового ядра — это операторы new и delete как таковые; в языковом ядре четко прописан их синтаксис, а в документации — их семантика (выделение и освобождение памяти). При этом язык предоставляет стандартную реализацию, но при желании можно переопределить эти операторы и написать свою систему выделения памяти. Второй пример — идентификация типа во время выполнения, RTTI. Пример демонстрирует другой аспект — отключаемость расширений.
Я имею большой опыт работы с микроконтроллерами, там при очень малом объеме бортовой памяти приходилось выделять память только статически — никакой «кучи» не было, и уж тем более не было RTTI.
Разница между Core и Extensions только в том, что элементы core нельзя переопределить; так, условный оператор if однозначен, его логика зашита в ядро и нет никакой возможности заменить его реализацию на что-то другое. Расширения же прописаны в ядре на уровне синтаксиса, также в языке предоставляется некая реализация по умолчанию, которая устроит 95% программистов; оставшимся 5% предлагается написать свою реализацию, тем ни менее соответствующую языковым интерфейсам, или отключить ее вовсе — для специфических случаев.
Другими такими расширениями могли бы стать
- сборка мусора (см. Rust — Gc)
- управление памятью с помощью подсчета ссылок (см. Rust — Rc, Arc)
- длинная арифметика (здесь важно то, что арифметика должна быть интегрирована в язык в том числе на уровне литералов; и длинные константы типа 128-битных чисел должны записываться естественным путем — в виде числовых литералов, одинаково для всех реализаций!)
- многопоточность (оператор go в языке go)
- рефлексия (да, существует масса способов реализовать ее вручную — но лучше компилятора с этой задачей все равно никто не справится)
- виртуальность и мультиметоды
- сигналы и слоты
- динамика в стиле objc
- встроенные скрипты
- rtti
- обработка исключений (существуют разные способы ее реализации; а бывают случаи когда она вообще не нужна)
- floating point (да, на некоторых микроконтроллерах нет FPU и работу с плавающей точкой эмулирует библиотека)
и наверное многое другое, что я не вспомнил сразу.
Под конец хочу остановиться на одном философском принципе, который лежит в основе моего представления об идеальном языке программирования. Обычно в ходе обсуждения на форумах, когда начинаешь говорить что в языке Х нет фичи Y, обязательно найдется кто-нибудь, кто скажет: ну как же, вот если взять фичи A, B и С, и прикрутить к ним костыли D, E и F, то мы получим почти Y. Да, это так. Но мне такой подход не нравится. Можно представить, что таких программистов устроит некоторый сложный путь через лабиринт. Пройти лабиринт можно, но путь кривой и неочевидный. Мне же хочется, чтобы вместо лабиринта была просторная площадь, по которой из любой точки в любую другую можно было бы пройти по прямой. Просто по прямой.

