Очень долго хотел написать статью, но не хватало времени. Нигде (в том числе на Хабре) не нашёл такой простой альтернативы munin, как описанная в этой статье.
Я backend developer и очень часто на моих проектах не бывает выделенных админов (особенно в самом начале жизни продукта), поэтому я уже давно занимаюсь базовым администрированием серверов (начальная установка-настройка, бекапы, репликация, мониторинг и т.д.). Мне это очень нравится и я всё время узнаю что-то новое в этом направлении.
В большинстве случаев для проекта хватает одного сервера и мне как старшему разработчику (и просто ответственному человеку) всегда нужно было контролировать его ресурсы, чтобы понимать когда мы упрёмся в его ограничения. Для этих целей было достаточно munin.
Он легко устанавливается и имеет небольшие требования. Он написан на perl и использует кольцевую базу данных (RRDtool).
Для мониторинга ресурсов сервера его всегда хватало, а для мониторинга доступности сервера использовался бесплатный сервис наподобие uptimerobot.com.
Я использую такую комбинацию для мониторинга своих домашних проектов на виртуальном сервере.
Если проект вырастает из одного сервера, тогда на втором сервере достаточно установить munin-node, а на первом — добавить в конфиге одну строчку для сбора метрик со второго сервера. Графики по обоим серверам будут раздельные, что не удобно для просмотра общей картины — на каком сервере заканчивается свободное место на диске, а на каком оперативная память. Эту ситуации можно исправить добавив в конфиг уже десяток строчек для агрегации одного графика с метриками с обоих серверов. Соответственно целесообразно это делать только для самых основных метрик. Если в конфиге сделать ошибку, то придётся долго читать в логах, что именно к ней привело и не найдя информации попытаться исправить ситуацию «методом тыка».
Стоит ли говорить, что для большего количества серверов это превращается в самый настоящий ад. Может это из-за того, что munin был разработан в 2003 году и изначально не был рассчитан на это.
Определил для себя необходимые качества, которыми должна обладать новая система мониторинга:
Я перечислю, всё что я рассматривал.
Почти тоже самое, что munin только на php. В качестве базы данных можно использовать rrdtool как у munin или mysql. Первый релиз: 2001 год.
Почти тоже самое, что и предыдущие, написана на php, в качестве базы данных — rrdtool. Первый релиз: 1998 год.
Ещё более простая система, чем предыдущие. Написан на c, в качестве базы данных — rrdtool. Первый релиз: 2005 год.
Состоит из трёх компонент, написанных на python:
carbon собирает метрики их записывает их в бд
whisper — собственная rrdtool-подобная бд
graphite-web — интерфейс
Первый релиз: 2008 год.
Профессиональная система мониторинга, используется большинством админов. Есть практически всё, включая уведомления на почту (для slack и telegram можно написать простой bash-скрипт). Тяжёлая для пользователя и для сервера. Раньше приходилось пользоваться, впечатления, как будто вернулся с jira на mantis.
Ядро написано на c, веб интерфейс — на php. В качестве базы данных может использовать: MySQL, PostgreSQL, SQLite, Oracle или IBM DB2. Первый релиз: 2001 год.
Достойная альтернатива Zabbix. Написан на с. Первый релиз: 1999 год.
Форк Nagios. В качестве бд может использовать: MySQL, Oracle, and PostgreSQL. Первый релиз: 2009 год.
Все вышеперечисленные системы достойны уважения. Они легко устанавливаются из пакетов в большинстве linux-дистрибутивов и уже давно используются в продакшене на многих серверах, поддерживаются, но очень слабо развиваются и имеют устаревший интерфейс.
В половине продуктов используются sql-базы данных, что является не оптимальным для хранения исторических данных (метрик). С одной стороны эти бд универсальны, а с другой — создают большую нагрузку на диски, а данные занимают больше места при хранении.
Для таких задач больше подходят современные бд временных рядов такие как ClickHouse.
Системы мониторинга нового поколения используют базы данных временных рядов, одни из них включают их в свой состав как неотделимую часть, другие используют как отдельную компоненту, а третью могут работать вообще без бд.
Вообще не требует базы данных, но может выгружать метрики в Graphite, OpenTSDB, Prometheus, InfluxDB. Написана на c и python. Первый релиз: 2016 год.
Состоит из трёх компонент, написанных на go:
prometheus — ядро, собственная встроенная база данных и веб-интерфейс.
node_exporter — агент, который может быть установлен на другой сервер и пересылать метрики в ядро, работает только с prometheus.
alertmanager — система уведомлений.
Первый релиз: 2014 год.
Состоит из четырёх компонент, написанных на go которые могут работать со сторонними продуктами:
telegraf — агент, который может быть установлен на другой сервер и пересылать метрики, а также логи в базы influxdb, elasticsearch, prometheus или graphite, а также в несколько серверов очередей.
influxdb — база данных, которая может принимать данные из telegraf, netdata или collectd.
chronograf — веб интерфейс для визуализации метрик из бд.
kapacitor — система уведомлений.
Первый релиз: 2013 год.
Отдельно хотелось бы упомянуть такой продукт, как grafana, она написана на go и позволяет визуализировать данные из influxdb, elasticsearch, clickhouse, prometheus, graphite, а также отправлять уведомления на почту, в slack и telegram.
Первый релиз: 2014 год.
В интернете и на Хабре, в том числе, полно примеров использования различных компонент из разных продуктов, чтобы получить то что надо именно тебе.
carbon (агент) -> whisper (бд) -> grafana (интерфейс)
netdata (в качестве агента) -> null / influxdb / elasticsearch / prometheus / graphite (в качестве бд) -> grafana (интерфейс)
node_exporter (агент) -> prometheus (в качестве бд) -> grafana (интерфейс)
collectd (агент) -> influxdb (бд) -> grafana (интерфейс)
zabbix (агент+сервер) -> mysql -> grafana (интерфейс)
telegraf (агент) -> elasticsearch (бд) -> kibana (интерфейс)
… и т.д.
Видел упоминание даже о такой связке:
… (агент) -> clickhouse (бд) -> grafana (интерфейс)
В большинстве случаев в качестве интерфейса использовалась grafana, даже если она была в связке с продуктом, который уже содержал собственный интерфейс (prometheus, graphite-web).
Поэтому (а также в силу её универсальности, простоты и удобства) в качестве интерфейса я остановился на grafana и приступил к выбору базы данных: prometheus отпал потому что не хотелось тянуть весь его функционал вместе с интерфейсом только из-за одной бд, graphite — бд предыдущего десятилетия, переработанная rrdtool-бд предыдущего столетия, ну и собственно я остановился на influxdb и как выяснилось — не один я сделал такой выбор.
Также для себя я решил выбрать telegraf, потому что он удовлетворял моим потребностям (большое количество метрик и возможность написания своих плагинов на bash), а также работает с разными бд, что может быть полезно в будущем.
Итоговая связка у меня получилась такая:
telegraf (агент) -> influxdb (бд) -> grafana (интерфейс+уведомления)
Все компоненты не содержат ничего лишнего и написаны на go. Единственное, чего я боялся — то что эта связку будет трудна в установке и настройке, но как вы сможете видеть ниже — это было зря.
Итак, короткая инструкция по установке TIG:
influxdb
Теперь можно делать запросы к базе (правда данных там ещё пока нет):
telegraf
Telegraf автоматически создаст базу в influxdb с именем «telegraf», логином «telegraf» и паролем «metricsmetricsmetricsmetrics».
grafana
Интерфейс доступен по адресу
Изначально в интерфейсе ничего не будет, потому что графана ничего не знает о данных.
1) Нужно зайти в источники и указать influxdb (бд: telegraf)
2) Нужно создать свой дашборд с нужными метриками (уйдёт очень много времени) или импортировать уже готовый, например:
928 — позволяет видеть все метрики по выбранному хосту
914 — тоже самое
61 — позволяет метрики по выбранным хостам на одном графике
Grafana имеет отличный инструмент для импорта сторонних дашбордов (достаточно указать его номер), вы также можете создать свой дашборд и поделиться им с сообществом.
Вот список всех дашбордов, работающие с данными из influxdb, которые были собраны с помощью коллектора telegraf.
Все порты на ваших серверах должны быть открыты только с тех ip, которым вы доверяете либо в используемых продуктах должна быть включена авторизация и изменены пароли по-умолчанию (я делаю и то и другое).
influxdb
В influxdb по-умолчанию отключена авторизация и кто угодно может делать что угодно. По-этому если на сервере нет файервола, то крайне рекомендую включить авторизацию:
telegraf
grafana
В настройках источников, нужно указать для influxdb новый логин: «grafana» и пароль «password_for_grafana» из пункта выше.
Также в интерфейсе нужно сменить пароль по-умолчанию для пользователя admin.
Update: добавил пункт к своим критериям «бесплатно и с открытым исходным кодом», забыл его указать с самого начала, а теперь мне советуют кучу платного/условно-бесплатного/триального/закрытого софта. Тут бы с бесплатным разобраться.
Update2: сейчас группа энтузиастов создаёт таблицу в google docs, сравнивая различные системы мониторинга по ключевым параметрам (Language, Bytes/point, Clustering). Работа кипит, текущий срез под катом.
Update3: ещё одно сравнение Open-Source TSDB в Google Docs. Чуть более проработанное, но систем меньше AnyKey80lvl
P.S.: если я опустил какие-то моменты в описании настройки-установки, то пишите в комментариях и я обновлю статью. Опечатки — в личку.
P.P.S.: конечно этого никто не услышит (исходя из предыдущего опыта написания статей), но я всё равно должен попробовать: не задавайте вопросы в личку на хабре, вк, фб и т.д., а пишите комментарии здесь.
P.P.P.S.: размер статьи и потраченное на неё время сильно выбились из начального «бюджета», надеюсь, что результаты этой работы будут для кого-то полезны.
Я backend developer и очень часто на моих проектах не бывает выделенных админов (особенно в самом начале жизни продукта), поэтому я уже давно занимаюсь базовым администрированием серверов (начальная установка-настройка, бекапы, репликация, мониторинг и т.д.). Мне это очень нравится и я всё время узнаю что-то новое в этом направлении.
В большинстве случаев для проекта хватает одного сервера и мне как старшему разработчику (и просто ответственному человеку) всегда нужно было контролировать его ресурсы, чтобы понимать когда мы упрёмся в его ограничения. Для этих целей было достаточно munin.
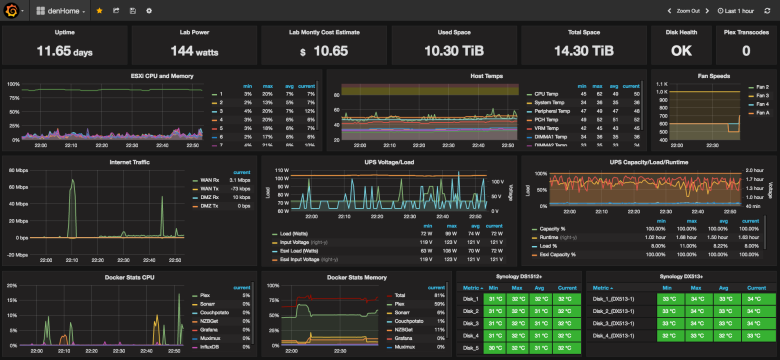
Интерфейс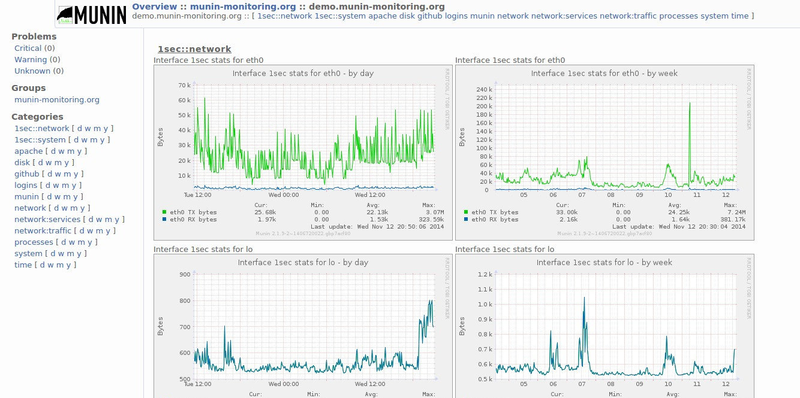
Munin
Он легко устанавливается и имеет небольшие требования. Он написан на perl и использует кольцевую базу данных (RRDtool).
Пример установки
Выполняем команды:
apt-get install munin munin-node
service munin-node start
Теперь munin-node будет собирать метрики системы и писать их в бд, а munin раз в 5 минут будет генерировать из этой бд html-отчёты и класть их в папку /var/cache/munin/www
Для удобного просмотра этих отчётов можно создать простой конфиг для nginx
Собственно и всё. Уже можно смотреть любые графики использования процессора, памяти, жёсткого диска, сети и многого другого за день/неделю/месяц/год. Чаще всего меня интересовала нагрузка чтения/записи на жёсткий диск, потому что узким местом всегда была база данных.
apt-get install munin munin-node
service munin-node start
Теперь munin-node будет собирать метрики системы и писать их в бд, а munin раз в 5 минут будет генерировать из этой бд html-отчёты и класть их в папку /var/cache/munin/www
Для удобного просмотра этих отчётов можно создать простой конфиг для nginx
server { listen 80; server_name munin.myserver.ru; root /var/cache/munin/www; index index.html; }
Собственно и всё. Уже можно смотреть любые графики использования процессора, памяти, жёсткого диска, сети и многого другого за день/неделю/месяц/год. Чаще всего меня интересовала нагрузка чтения/записи на жёсткий диск, потому что узким местом всегда была база данных.
Для мониторинга ресурсов сервера его всегда хватало, а для мониторинга доступности сервера использовался бесплатный сервис наподобие uptimerobot.com.
Я использую такую комбинацию для мониторинга своих домашних проектов на виртуальном сервере.
Если проект вырастает из одного сервера, тогда на втором сервере достаточно установить munin-node, а на первом — добавить в конфиге одну строчку для сбора метрик со второго сервера. Графики по обоим серверам будут раздельные, что не удобно для просмотра общей картины — на каком сервере заканчивается свободное место на диске, а на каком оперативная память. Эту ситуации можно исправить добавив в конфиг уже десяток строчек для агрегации одного графика с метриками с обоих серверов. Соответственно целесообразно это делать только для самых основных метрик. Если в конфиге сделать ошибку, то придётся долго читать в логах, что именно к ней привело и не найдя информации попытаться исправить ситуацию «методом тыка».
Стоит ли говорить, что для большего количества серверов это превращается в самый настоящий ад. Может это из-за того, что munin был разработан в 2003 году и изначально не был рассчитан на это.
Альтернативы munin для мониторинга нескольких серверов
Определил для себя необходимые качества, которыми должна обладать новая система мониторинга:
- количество метрик не меньше чем у munin (у него их около 30 базовых графиков и ещё около 200 плагинов в комплекте)
- возможность написания собственных плагинов на bash (у меня было два таких плагина)
- иметь небольшие требования к серверу
- возможность вывода метрик с разных серверов на одном графике без правки конфигов
- уведомления на почту, в slack и telegram
- Time Series Database более мощную чем RRDtool
- простая установка
- ничего лишнего
- бесплатно и с открытым исходным кодом
Я перечислю, всё что я рассматривал.
Cacti
Почти тоже самое, что munin только на php. В качестве базы данных можно использовать rrdtool как у munin или mysql. Первый релиз: 2001 год.
Интерфейс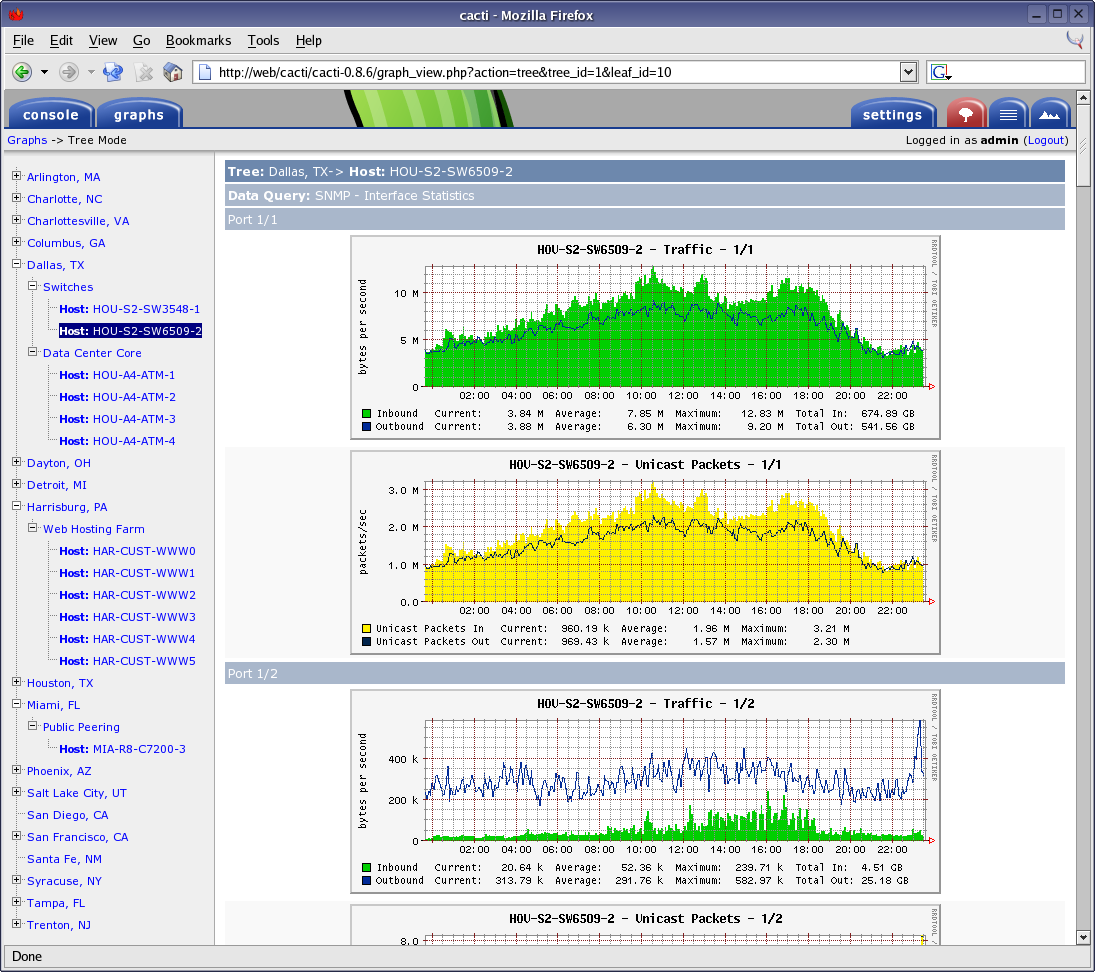
Ganglia
Почти тоже самое, что и предыдущие, написана на php, в качестве базы данных — rrdtool. Первый релиз: 1998 год.
Интерфейс
Collectd
Ещё более простая система, чем предыдущие. Написан на c, в качестве базы данных — rrdtool. Первый релиз: 2005 год.
Интерфейс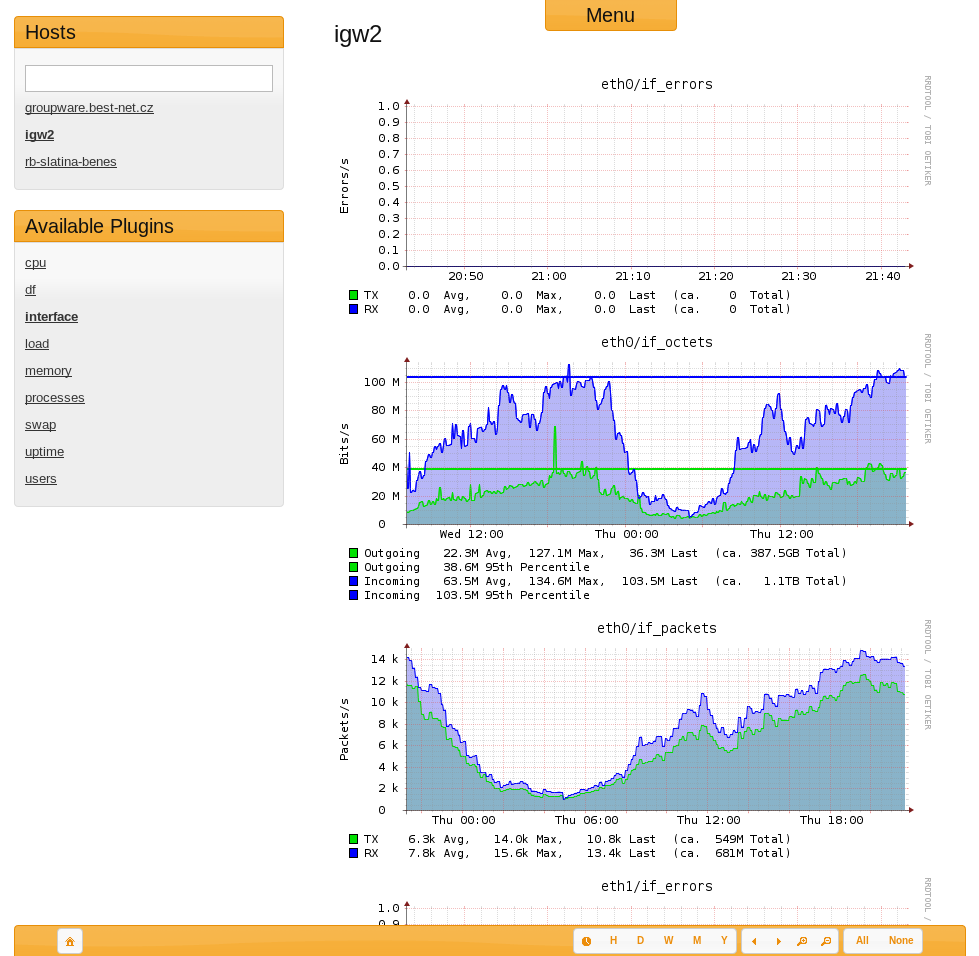
Graphite
Состоит из трёх компонент, написанных на python:
carbon собирает метрики их записывает их в бд
whisper — собственная rrdtool-подобная бд
graphite-web — интерфейс
Первый релиз: 2008 год.
Интерфейс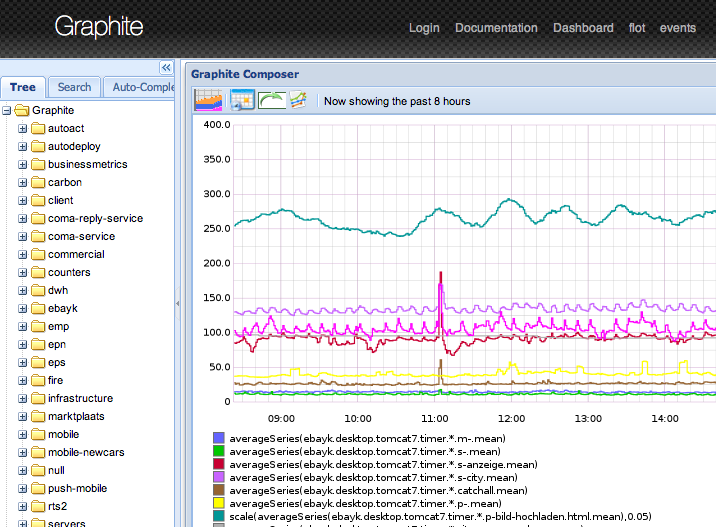
Zabbix
Профессиональная система мониторинга, используется большинством админов. Есть практически всё, включая уведомления на почту (для slack и telegram можно написать простой bash-скрипт). Тяжёлая для пользователя и для сервера. Раньше приходилось пользоваться, впечатления, как будто вернулся с jira на mantis.
Ядро написано на c, веб интерфейс — на php. В качестве базы данных может использовать: MySQL, PostgreSQL, SQLite, Oracle или IBM DB2. Первый релиз: 2001 год.
Интерфейс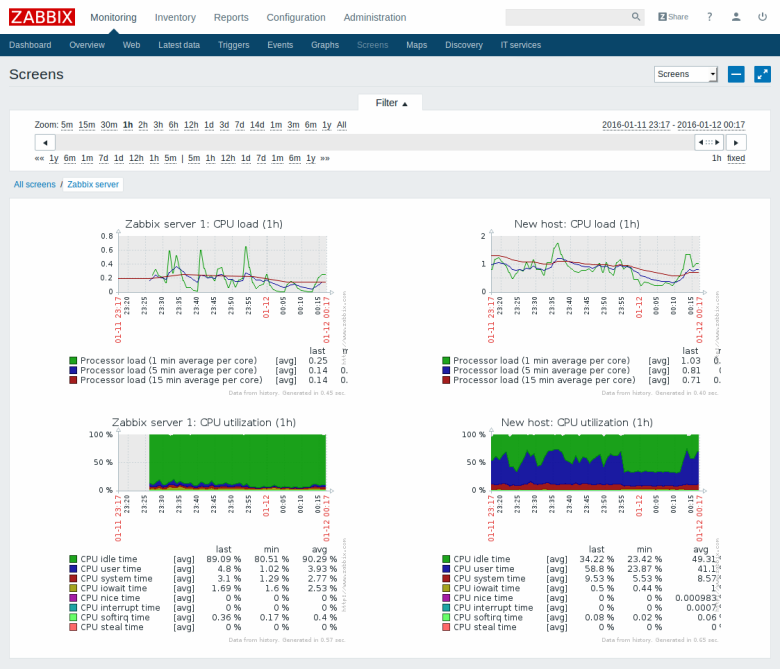
Nagios
Достойная альтернатива Zabbix. Написан на с. Первый релиз: 1999 год.
Интерфейс
Icinga
Форк Nagios. В качестве бд может использовать: MySQL, Oracle, and PostgreSQL. Первый релиз: 2009 год.
Интерфейс
Небольшое отступление
Все вышеперечисленные системы достойны уважения. Они легко устанавливаются из пакетов в большинстве linux-дистрибутивов и уже давно используются в продакшене на многих серверах, поддерживаются, но очень слабо развиваются и имеют устаревший интерфейс.
В половине продуктов используются sql-базы данных, что является не оптимальным для хранения исторических данных (метрик). С одной стороны эти бд универсальны, а с другой — создают большую нагрузку на диски, а данные занимают больше места при хранении.
Для таких задач больше подходят современные бд временных рядов такие как ClickHouse.
Системы мониторинга нового поколения используют базы данных временных рядов, одни из них включают их в свой состав как неотделимую часть, другие используют как отдельную компоненту, а третью могут работать вообще без бд.
Netdata
Вообще не требует базы данных, но может выгружать метрики в Graphite, OpenTSDB, Prometheus, InfluxDB. Написана на c и python. Первый релиз: 2016 год.
Интерфейс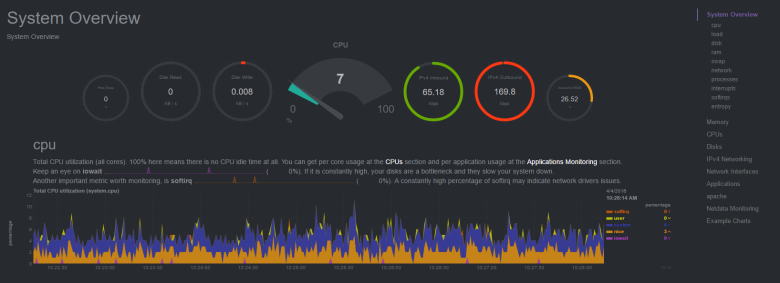
Prometheus
Состоит из трёх компонент, написанных на go:
prometheus — ядро, собственная встроенная база данных и веб-интерфейс.
node_exporter — агент, который может быть установлен на другой сервер и пересылать метрики в ядро, работает только с prometheus.
alertmanager — система уведомлений.
Первый релиз: 2014 год.
Интерфейс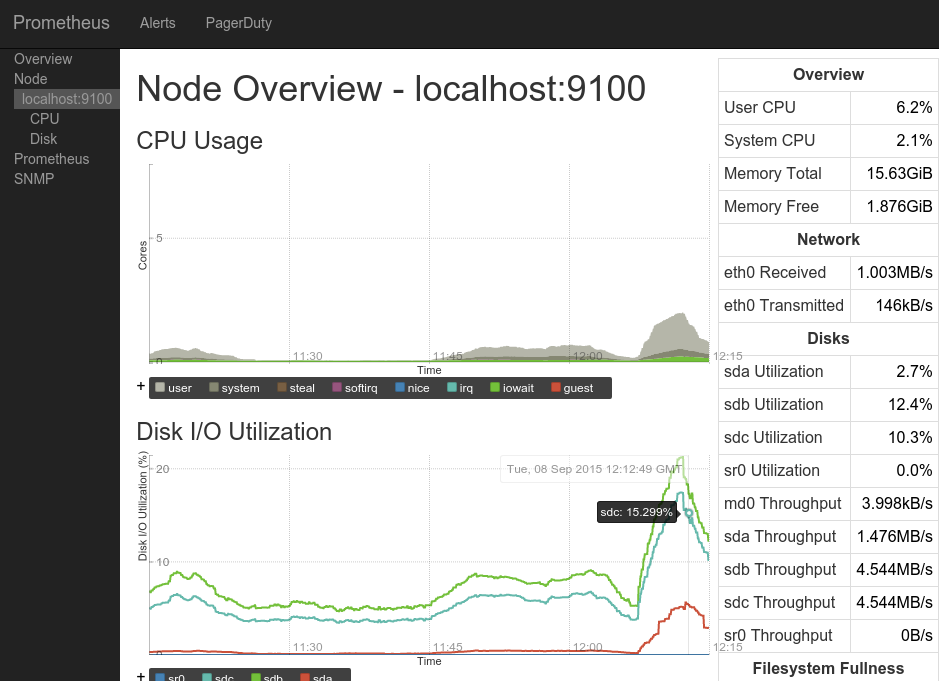
InfluxData (TICK Stack)
Состоит из четырёх компонент, написанных на go которые могут работать со сторонними продуктами:
telegraf — агент, который может быть установлен на другой сервер и пересылать метрики, а также логи в базы influxdb, elasticsearch, prometheus или graphite, а также в несколько серверов очередей.
influxdb — база данных, которая может принимать данные из telegraf, netdata или collectd.
chronograf — веб интерфейс для визуализации метрик из бд.
kapacitor — система уведомлений.
Первый релиз: 2013 год.
Интерфейс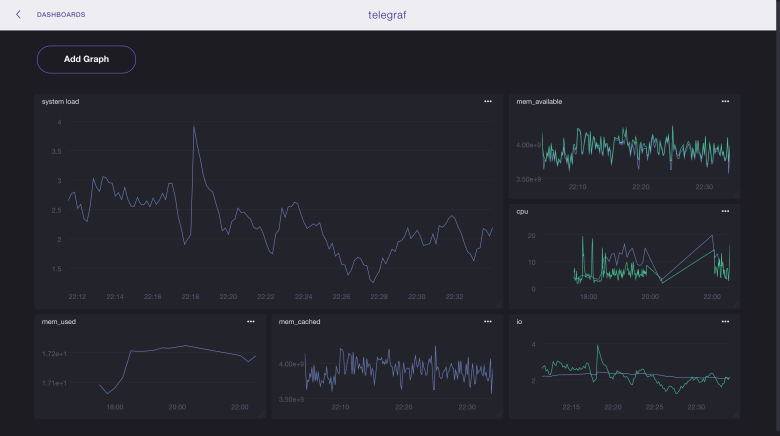
Отдельно хотелось бы упомянуть такой продукт, как grafana, она написана на go и позволяет визуализировать данные из influxdb, elasticsearch, clickhouse, prometheus, graphite, а также отправлять уведомления на почту, в slack и telegram.
Первый релиз: 2014 год.
Интерфейс
Выбираем лучшее
В интернете и на Хабре, в том числе, полно примеров использования различных компонент из разных продуктов, чтобы получить то что надо именно тебе.
carbon (агент) -> whisper (бд) -> grafana (интерфейс)
netdata (в качестве агента) -> null / influxdb / elasticsearch / prometheus / graphite (в качестве бд) -> grafana (интерфейс)
node_exporter (агент) -> prometheus (в качестве бд) -> grafana (интерфейс)
collectd (агент) -> influxdb (бд) -> grafana (интерфейс)
zabbix (агент+сервер) -> mysql -> grafana (интерфейс)
telegraf (агент) -> elasticsearch (бд) -> kibana (интерфейс)
… и т.д.
Видел упоминание даже о такой связке:
… (агент) -> clickhouse (бд) -> grafana (интерфейс)
В большинстве случаев в качестве интерфейса использовалась grafana, даже если она была в связке с продуктом, который уже содержал собственный интерфейс (prometheus, graphite-web).
Поэтому (а также в силу её универсальности, простоты и удобства) в качестве интерфейса я остановился на grafana и приступил к выбору базы данных: prometheus отпал потому что не хотелось тянуть весь его функционал вместе с интерфейсом только из-за одной бд, graphite — бд предыдущего десятилетия, переработанная rrdtool-бд предыдущего столетия, ну и собственно я остановился на influxdb и как выяснилось — не один я сделал такой выбор.
Также для себя я решил выбрать telegraf, потому что он удовлетворял моим потребностям (большое количество метрик и возможность написания своих плагинов на bash), а также работает с разными бд, что может быть полезно в будущем.
Итоговая связка у меня получилась такая:
telegraf (агент) -> influxdb (бд) -> grafana (интерфейс+уведомления)
Все компоненты не содержат ничего лишнего и написаны на go. Единственное, чего я боялся — то что эта связку будет трудна в установке и настройке, но как вы сможете видеть ниже — это было зря.
Итак, короткая инструкция по установке TIG:
influxdb
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.2.2.x86_64.rpm && yum localinstall influxdb-1.2.2.x86_64.rpm #centos wget https://dl.influxdata.com/influxdb/releases/influxdb_1.2.4_amd64.deb && dpkg -i influxdb_1.2.4_amd64.deb #ubuntu systemctl start influxdb systemctl enable influxdb
Теперь можно делать запросы к базе (правда данных там ещё пока нет):
http://localhost:8086/query?q=select+*+from+telegraf..cputelegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.2.1.x86_64.rpm && yum -y localinstall telegraf-1.2.1.x86_64.rpm #centos wget https://dl.influxdata.com/telegraf/releases/telegraf_1.3.2-1_amd64.deb && dpkg -i telegraf_1.3.2-1_amd64.deb #ubuntu #в случае установки на сервер отличный от того где находится influxdb необходимо в конфиге /etc/telegraf/telegraf.conf в секции [[outputs.influxdb]] поменять параметр urls = ["http://localhost:8086"]: sed -i 's| urls = ["http://localhost:8086"]| urls = ["http://myserver.ru:8086"]|g' /etc/telegraf/telegraf.conf systemctl start telegraf systemctl enable telegraf
Telegraf автоматически создаст базу в influxdb с именем «telegraf», логином «telegraf» и паролем «metricsmetricsmetricsmetrics».
grafana
yum install https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.3.2-1.x86_64.rpm #centos wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.3.2_amd64.deb && dpkg -i grafana_4.3.2_amd64.deb #ubuntu systemctl start grafana-server systemctl enable grafana-server
Интерфейс доступен по адресу
http://myserver.ru:3000. Логин: admin, пароль: admin.Изначально в интерфейсе ничего не будет, потому что графана ничего не знает о данных.
1) Нужно зайти в источники и указать influxdb (бд: telegraf)
2) Нужно создать свой дашборд с нужными метриками (уйдёт очень много времени) или импортировать уже готовый, например:
928 — позволяет видеть все метрики по выбранному хосту
914 — тоже самое
61 — позволяет метрики по выбранным хостам на одном графике
Grafana имеет отличный инструмент для импорта сторонних дашбордов (достаточно указать его номер), вы также можете создать свой дашборд и поделиться им с сообществом.
Вот список всех дашбордов, работающие с данными из influxdb, которые были собраны с помощью коллектора telegraf.
Акцент на безопасность
Все порты на ваших серверах должны быть открыты только с тех ip, которым вы доверяете либо в используемых продуктах должна быть включена авторизация и изменены пароли по-умолчанию (я делаю и то и другое).
influxdb
В influxdb по-умолчанию отключена авторизация и кто угодно может делать что угодно. По-этому если на сервере нет файервола, то крайне рекомендую включить авторизацию:
#Создаём базу и пользователей: influx -execute 'CREATE DATABASE telegraf' influx -execute 'CREATE USER admin WITH PASSWORD "password_for_admin" WITH ALL PRIVILEGES' influx -execute 'CREATE USER telegraf WITH PASSWORD "password_for_telegraf"' influx -execute 'CREATE USER grafana WITH PASSWORD "password_for_grafana"' influx -execute 'GRANT WRITE ON "telegraf" TO "telegraf"' #чтобы telegraf мог писать метрики в бд influx -execute 'GRANT READ ON "telegraf" TO "grafana"' #чтобы grafana могла читать метрики из бд #в конфиге /etc/influxdb/influxdb.conf в секции [http] меняем параметр auth-enabled для включения авторизации: sed -i 's| # auth-enabled = false| auth-enabled = true|g' /etc/influxdb/influxdb.conf systemctl restart influxdb
telegraf
#в конфиге /etc/telegraf/telegraf.conf в секции [[outputs.influxdb]] меняем пароль на созданный в предыдущем пункте: sed -i 's| # password = "metricsmetricsmetricsmetrics"| password = "password_for_telegraf"|g' /etc/telegraf/telegraf.conf systemctl restart telegraf
grafana
В настройках источников, нужно указать для influxdb новый логин: «grafana» и пароль «password_for_grafana» из пункта выше.
Также в интерфейсе нужно сменить пароль по-умолчанию для пользователя admin.
Admin -> profile -> change password
Update: добавил пункт к своим критериям «бесплатно и с открытым исходным кодом», забыл его указать с самого начала, а теперь мне советуют кучу платного/условно-бесплатного/триального/закрытого софта. Тут бы с бесплатным разобраться.
Как я выбирал
1) сначала посмотрел на сравнение систем мониторинга на английской википедии
2) посмотрел на гитхабе топовые проекты
3) посмотрел, что есть на эту тему на хабре
4) погуглил какие системы сейчас в тренеде
2) посмотрел на гитхабе топовые проекты
3) посмотрел, что есть на эту тему на хабре
4) погуглил какие системы сейчас в тренеде
Update2: сейчас группа энтузиастов создаёт таблицу в google docs, сравнивая различные системы мониторинга по ключевым параметрам (Language, Bytes/point, Clustering). Работа кипит, текущий срез под катом.
Скриншот на момент 15:15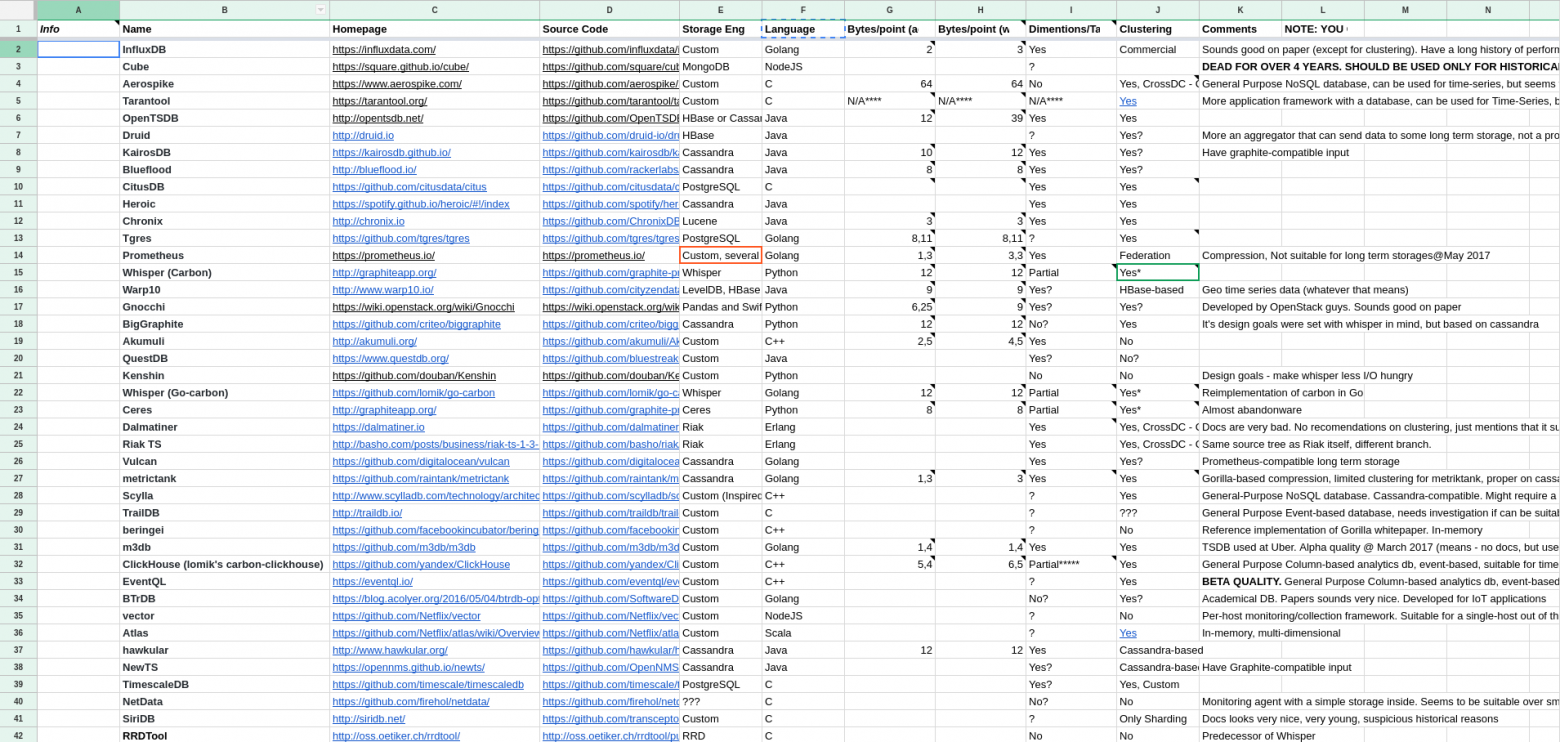

Update3: ещё одно сравнение Open-Source TSDB в Google Docs. Чуть более проработанное, но систем меньше AnyKey80lvl
P.S.: если я опустил какие-то моменты в описании настройки-установки, то пишите в комментариях и я обновлю статью. Опечатки — в личку.
P.P.S.: конечно этого никто не услышит (исходя из предыдущего опыта написания статей), но я всё равно должен попробовать: не задавайте вопросы в личку на хабре, вк, фб и т.д., а пишите комментарии здесь.
P.P.P.S.: размер статьи и потраченное на неё время сильно выбились из начального «бюджета», надеюсь, что результаты этой работы будут для кого-то полезны.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Что вы используете для мониторинга?
11.71%munin206
7.5%cacti132
0.45%ganglia8
3.64%collectd64
4.95%graphite87
51.39%zabbix904
10.8%nagios190
2.96%icinga52
3.18%netdata56
9.38%prometheus165
8.19%influxdb+telegraf144
22.63%grafana (в качестве интерфейса)398
2.96%внешняя система мониторинга (saas)52
6.03%самописная система106
11.26%другое198
Проголосовали 1759 пользователей. Воздержался 891 пользователь.

