Тем, кто знаком с криптографией с открытым ключом, наверно известны аббревиатуры ECC, ECDH и ECDSA. Первая — это сокращение от Elliptic Curve Cryptography (криптография на эллиптических кривых), остальные — это названия основанных на ней алгоритмов.
Сегодня криптосистемы на эллиптических кривых используются в TLS, PGP и SSH, важнейших технологиях, на которых базируются современный веб и мир ИТ. Я уже не говорю о Bitcoin и других криптовалютах.
До того, как ECC стала популярной, почти все алгоритмы с открытым ключом основывались на RSA, DSA и DH, альтернативных криптосистемах на основе модулярной арифметики. RSA и компания по-прежнему популярны, и часто используются вместе с ECC. Однако несмотря на то, что магия, лежащая в фундаменте RSA и подобных ей алгоритмов легко объяснима и понятна многим, а грубые реализации пишутся довольно просто, основы ECC всё ещё являются для большинства людей загадкой.
В этой серии статей я познакомлю вас с основами мира криптографии на эллиптических кривых. Моя цель — не создание полного и подробного руководства по ECC (в Интернете полно информации по этой теме), а простой обзор ECC и объяснение того, почему её считают безопасной. Я не буду тратить время на долгие математические доказательства или скучные подробности реализации. Также я представлю полезные примеры с визуальными интерактивными инструментами и скриптами.
В частности, я рассмотрю следующие темы:
- Эллиптические кривые над вещественными числами и групповой закон
- Эллиптические кривые над конечными полями и задача дискретного логарифмирования
- Генерирование пар ключей и два алгоритма ECC: ECDH и ECDSA
- Алгоритмы для взлома защиты ECC и сравнение с RSA
Для понимания статьи вам нужно знать основы теории множеств, геометрии и модулярной арифметики, понимать принципы симметричной и асимметричной криптографии. Наконец, вы должны чётко понимать, что такое «простая» и «сложная» задачи и их роли в криптографии.
Готовы? Приступим!
Часть 1: эллиптические кривые над вещественными числами и групповой закон
Эллиптические кривые
Во-первых: что такое эллиптическая кривая? В Wolfram MathWorld есть отличное и исчерпывающее определение. Но для нас достаточно того, что эллиптическая кривая — это просто множество точек, описываемое уравнением:

где
 , (это необходимо, чтобы исключить особые кривые). Приведённое выше уравнение называется обычной формулировкой Вейерштрасса для эллиптических кривых.
, (это необходимо, чтобы исключить особые кривые). Приведённое выше уравнение называется обычной формулировкой Вейерштрасса для эллиптических кривых.
Различные формы эллиптических кривых (
 ,
,  изменяется от 2 до -3).
изменяется от 2 до -3).
Виды особенностей: слева — кривая с точкой возврата (каспом) (
 ). Справа — кривая с самопересечением (
). Справа — кривая с самопересечением ( ). Оба этих примера не являются полноценными эллиптическими кривыми.
). Оба этих примера не являются полноценными эллиптическими кривыми.В зависимости от значений
и  эллиптические кривые могут принимать на плоскости разные формы. Как можно легко увидеть и проверить, эллиптические кривые симметричны относительно оси
эллиптические кривые могут принимать на плоскости разные формы. Как можно легко увидеть и проверить, эллиптические кривые симметричны относительно оси  .
.Для наших целей нам также понадобится, чтобы частью кривой являлась бесконечно удалённая точка (также известная как идеальная точка). С этого момента мы будем обозначать бесконечно удалённую точку символом 0 (ноль).
Если нам требуется явным образом учитывать точку в бесконечности, то определение эллиптической кривой можно уточнить следующим образом:

Группы
В математике группа — это множество, для которого мы определили двоичную операцию, называемую «сложением» и обозначаемую символом +. Чтобы множество
 было группой, сложение нужно определить таким образом, чтобы оно соответствовало четырём следующим свойствам:
было группой, сложение нужно определить таким образом, чтобы оно соответствовало четырём следующим свойствам:- замыкание: если и входят в , то
 входит в ;
входит в ; - ассоциативность:
 ;
; - существует единичный элемент 0, такой, что
 ;
; - у каждого элемента есть обратная величина, то есть: для каждого существует такое , что
 .
.
Если мы добавим пятое требование:
- коммутативность:
 ,
,
то группа называется абелевой группой.
При обычной записи сложения множество целых чисел
 является группой (более того, это абелева группа). Множество натуральных чисел
является группой (более того, это абелева группа). Множество натуральных чисел  , однако, не является группой, потому что не удовлетворяет четвёртому свойству.
, однако, не является группой, потому что не удовлетворяет четвёртому свойству.Группы удобны тем, что если мы докажем соблюдение всех четырёх свойств, то получим автоматически некоторые другие свойства «в нагрузку». Например: единичный элемент уникален; кроме того, обратные величины уникальны, то есть: для каждого
существует единственное , такое, что (и мы можем записать как  ). Непосредственно или косвенно эти и другие свойства групп очень пригодятся нам в будущем.
). Непосредственно или косвенно эти и другие свойства групп очень пригодятся нам в будущем.Групповой закон для эллиптических кривых
Мы можем определить группу для эллиптических кривых. А именно:
- элементы группы являются точками эллиптической кривой;
- единичный элемент — это бесконечно удалённая точка 0;
- обратная величина точки
 — это точка, симметричная относительно оси
— это точка, симметричная относительно оси  ;
; - сложение задаётся следующим правилом: сумма трёх ненулевых точек ,
 и
и  , лежащих на одной прямой, будет равна
, лежащих на одной прямой, будет равна  .
.

Сумма трёх точек, находящихся на одной прямой, равна 0.
Стоит учесть, что в последнем правиле нам требуются только три точки на одной прямой, и порядок расположения этих трёх точек не важен. Это значит, что если три точки
, и лежат на одной прямой, то  . Таким образом мы интуитивно доказали, что наш оператор + обладает свойствами ассоциативности и коммутативности: мы находимся в абелевой группе.
. Таким образом мы интуитивно доказали, что наш оператор + обладает свойствами ассоциативности и коммутативности: мы находимся в абелевой группе.Пока всё идёт отлично. Но как нам вычислить сумму двух произвольных точек?
Геометрическое сложение
Благодаря тому, что мы находимся в абелевой группе, то можем записать
как  . Это уравнение в такой форме позволяет нам вывести геометрический способ вычисления суммы двух точек и : если мы проведём линию, проходящую через и , эта прямая пересечёт третью точку кривой (это подразумевается, потому что , и находятся на одной прямой). Если мы возьмём обратную величину этой точки
. Это уравнение в такой форме позволяет нам вывести геометрический способ вычисления суммы двух точек и : если мы проведём линию, проходящую через и , эта прямая пересечёт третью точку кривой (это подразумевается, потому что , и находятся на одной прямой). Если мы возьмём обратную величину этой точки  , мы найдём сумму
, мы найдём сумму  .
.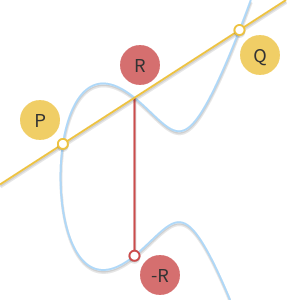
Проводим прямую через
и . Прямая пересекает третью точку . Симметричная ей точка является результатом .Геометрический способ работает, но требует усовершенствования. В частности, нам нужно ответить на несколько вопросов:
- Что если
 или
или  ? Разумеется, мы не сможем провести прямую (0 не находится на плоскости
? Разумеется, мы не сможем провести прямую (0 не находится на плоскости  ). Но поскольку мы определили 0 как единичный элемент,
). Но поскольку мы определили 0 как единичный элемент,  и
и  для любой и любой .
для любой и любой . - Что если
 ? В этом случае прямая, проходящая через две точки, вертикальна, и не пересекает третью точку. Но если является обратной величиной , то
? В этом случае прямая, проходящая через две точки, вертикальна, и не пересекает третью точку. Но если является обратной величиной , то  из определения обратной величины.
из определения обратной величины. - Что если
 ? В этом случае через точку проходит бесконечное количество прямых. Здесь всё становится немного сложнее. Но представим, что точка
? В этом случае через точку проходит бесконечное количество прямых. Здесь всё становится немного сложнее. Но представим, что точка  . Что произойдёт, если мы заставим
. Что произойдёт, если мы заставим  стремиться к , всё больше приближаясь к ней?
стремиться к , всё больше приближаясь к ней?
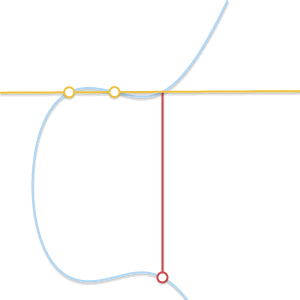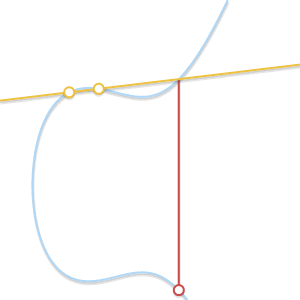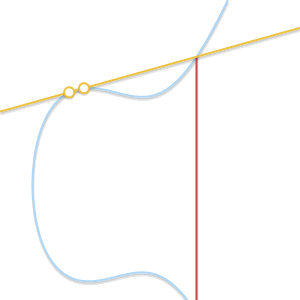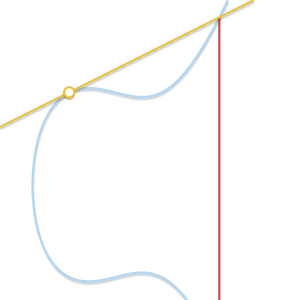
При сближении двух точек проходящая через них прямая становится касательной к кривой.
Поскольку стремится к , прямая, проходящая через и становится касательной к кривой. В свете этого мы можем сказать, что  , где — это точка пересечения между кривой и касательной к кривой в точке .
, где — это точка пересечения между кривой и касательной к кривой в точке . - Что если
 , но третьей точки нет? В этом случае ситуация похожа на предыдущую. На самом деле, в этой ситуации прямая, проходящая через и , является касательной к кривой.
, но третьей точки нет? В этом случае ситуация похожа на предыдущую. На самом деле, в этой ситуации прямая, проходящая через и , является касательной к кривой.

Если наша прямая пересекает только две точки, то это значит, что она является касательной к кривой. Легко увидеть, как результат сложения становится симметричным одной из двух точек.
Предположим, что является точкой касания. В предыдущем случае мы записали  . Это уравнение теперь превращается в
. Это уравнение теперь превращается в  . С другой стороны, если бы точкой касания была , то правильным было бы уравнение
. С другой стороны, если бы точкой касания была , то правильным было бы уравнение  .
.
Геометрический способ теперь полон и учитывает все случаи. С помощью карандаша и линейки мы можем выполнить сложение всех точек любой эллиптической кривой. Если хотите попробовать, взгляните на визуальный инструмент на HTML5/JavaScript, созданный мной для вычисления сумм эллиптических кривых.
Алгебраическое сложение
Если мы хотим, чтобы сложением точек занимался компьютер, нужно превратить геометрический способ в алгебраический. Преобразование вышеизложенных правил в набор уравнений может казаться простым, но на самом деле оно довольно утомительно, потому что требует решения кубических уравнений. Поэтому я изложу только результаты.
Для начала давайте избавимся от самых раздражающих тупиковых ситуаций. Мы уже знаем, что
 , и знаем, что
, и знаем, что  . Поэтому в наших уравнениях мы будем избегать этих двух случаев и рассмотрим только две ненулевые несимметричные точки
. Поэтому в наших уравнениях мы будем избегать этих двух случаев и рассмотрим только две ненулевые несимметричные точки  и
и  .
.Если
и не совпадают ( ), то проходящая через них прямая имеет наклон:
), то проходящая через них прямая имеет наклон:
Пересечение этой прямой с эллиптической кривой — это третья точка
 :
:
или, аналогично:

Поэтому
 (обратите внимание на знаки и помните, что ).
(обратите внимание на знаки и помните, что ).Если бы нам нужно было проверить правильность результата, то пришлось бы проверить, принадлежит ли
кривой и находятся ли , и на одной прямой. Проверка нахождения на одной прямой тривиальна, а проверка принадлежности кривой — нет, потому что нам придётся решать кубическое уравнение, что совсем невесело.Вместо этого давайте поэкспериментируем с примером: согласно визуальному инструменту, при
 и
и  , принадлежащих кривой
, принадлежащих кривой  , их сумма равна
, их сумма равна  . Давайте проверим, соответствует ли это уравнениям:
. Давайте проверим, соответствует ли это уравнениям:
Да, всё верно!
Заметьте, что эти уравнения работают даже в случае, когда точка
или является точкой касания. Давайте проверим на  и
и  .
.
Мы получили результат
 , который совпадает с результатом, полученным в визуальном инструменте.
, который совпадает с результатом, полученным в визуальном инструменте.К случаю
нужно относиться немного иначе: уравнения для  и
и  остаются теми же, но с учётом того, что
остаются теми же, но с учётом того, что  нам придётся использовать для наклона другое уравнение:
нам придётся использовать для наклона другое уравнение:
Заметьте, что, как можно ожидать, это выражение для
 является первой производной:
является первой производной:
Чтобы доказать правильность этого результата, достаточно убедиться, что
принадлежит к кривой и что прямая, проходящая через и , имеет только два пересечения с кривой. Но мы снова не будем доказывать это и вместо этого разберём пример:  .
.
Что даёт нам
 . Верно!
. Верно!Хотя процедура получения результатов очень утомительна, наши уравнения довольно кратки. Всё это благодаря обычной формулировке Вейерштрасса: без неё эти уравнения были бы очень длинными и сложными!
Скалярное умножение
Кроме сложения, мы можем определить и другую операцию: скалярное умножение, то есть:

где
 — натуральное число. Я написал визуальный инструмент и для скалярного умножения, так что можете поэкспериментировать с ним.
— натуральное число. Я написал визуальный инструмент и для скалярного умножения, так что можете поэкспериментировать с ним.При записи в такой форме очевидно, что вычисление
 требует сложений. Если состоит из
требует сложений. Если состоит из  десятичных разрядов, то алгоритм будет иметь сложность
десятичных разрядов, то алгоритм будет иметь сложность  , что не очень хорошо. Но существуют и более быстрые алгоритмы.
, что не очень хорошо. Но существуют и более быстрые алгоритмы.Один из них — алгоритм удвоения-сложения. Принцип его работы проще объяснить на примере. Возьмём
 . В двоичном форме оно имеет вид
. В двоичном форме оно имеет вид  . Такую двоичную форму можно представить как сумму степеней двойки:
. Такую двоичную форму можно представить как сумму степеней двойки:
(Мы взяли каждый двоичный разряд
и умножили на степень двойки.)С учётом этого можно записать:

Алгоритм удвоения-сложения задаёт следующий порядок действий:
- Взять .
- Удвоить его, чтобы получить
 .
. - Сложить и (чтобы получить результат
 ).
). - Удвоить , чтобы получить
 .
. - Сложить с результатом (чтобы получить
 ).
). - Удвоить , получить
 .
. - Не выполнять сложение с .
- Удвоить , чтобы получить
 .
. - Сложить с результатом (чтобы получить
 ).
). - ...
В результате мы вычислим
 , выполнив всего семь удвоений и четыре сложения.
, выполнив всего семь удвоений и четыре сложения.Если вам это понятно не до конца, то вот скрипт на Python, реализующий этот алгоритм:
def bits(n): """ Генерирует двоичные разряды n, начиная с наименее значимого бита. bits(151) -> 1, 1, 1, 0, 1, 0, 0, 1 """ while n: yield n & 1 n >>= 1 def double_and_add(n, x): """ Возвращает результат n * x, вычисленный алгоритмом удвоения-сложения. """ result = 0 addend = x for bit in bits(n): if bit == 1: result += addend addend *= 2 return result
Если удвоение и сложение являются операциями
 , то этот алгоритм имеет сложность
, то этот алгоритм имеет сложность  (или
(или  , если учитывать битовую длину), что довольно неплохо. И, конечно, намного лучше, чем изначальный алгоритм
, если учитывать битовую длину), что довольно неплохо. И, конечно, намного лучше, чем изначальный алгоритм  !
!Логарифм
Для заданных
и у нас есть по крайней мере один полиномиальный алгоритм вычисления  . Но как насчёт обратной задачи? Что если мы знаем и , а нам нужно определить ? Эта задача известна как задача логарифмирования. Мы употребляем слово «логарифм» вместо термина «деление» для согласованности с другими криптосистемами (в которых вместо умножения используется возведение в степень).
. Но как насчёт обратной задачи? Что если мы знаем и , а нам нужно определить ? Эта задача известна как задача логарифмирования. Мы употребляем слово «логарифм» вместо термина «деление» для согласованности с другими криптосистемами (в которых вместо умножения используется возведение в степень).Я не знаю ни одного «простого» алгоритма для решения задачи логарифмирования, однако экспериментируя с умножением, легко обнаружить некоторые закономерности. Например, возьмём кривую
 и точку
и точку  . Мы можем сразу убедиться, что если нечётное, то находится на кривой в левой полуплоскости; если чётное, то — в правой полуплоскости. Если поэкспериментировать ещё, мы, возможно, найдём и другие закономерности, которые приведут нас к написанию алгоритма для эффективного вычисления логарифма этой кривой.
. Мы можем сразу убедиться, что если нечётное, то находится на кривой в левой полуплоскости; если чётное, то — в правой полуплоскости. Если поэкспериментировать ещё, мы, возможно, найдём и другие закономерности, которые приведут нас к написанию алгоритма для эффективного вычисления логарифма этой кривой.Но существует вариация задачи логарифмирования: задача дискретного логарифмирования. Как мы увидим в следующей части, если уменьшить область определения эллиптических кривых, скалярное умножение остаётся «простым», а дискретный логарифм становится «сложной» задачей. Такая двойственность является ключевой особенностью криптографии на эллиптических кривых.
В следующей части мы исследуем конечные поля и задачу дискретной логарифмизации, а также примеры и инструменты для экспериментов.
Часть 2: эллиптические кривые над конечными полями и задача дискретного логарифмирования
В предыдущей части мы обсудили, как эллиптические кривые над вещественными числами можно использовать для определения групп. А именно, мы определили правило сложения точек: сумма трёх точек, лежащих на одной прямой, равна нулю (
). Мы вывели геометрический и алгебраический способы вычисления сложения точек.Затем мы ввели понятие скалярного умножения (
 ) и нашли «простой» алгоритм для вычисления скалярного умножения: удвоение-сложение.
) и нашли «простой» алгоритм для вычисления скалярного умножения: удвоение-сложение.Теперь мы ограничим эллиптические кривые конечными полями, а не вещественными числами, и посмотрим, что это изменит.
Поле целых чисел по модулю p
Конечное поле — это, в первую очередь, множество конечного числа элементов. Примером конечного поля является множество целых чисел по модулю
 , где — простое число. В общем виде это записывается как
, где — простое число. В общем виде это записывается как  ,
,  или
или  . Мы будем использовать последнюю запись.
. Мы будем использовать последнюю запись.Для полей существует две двухместные операции: сложение (+) и умножение (·). Обе они замкнуты, ассоциативны и коммутативны. Для обеих операций существует уникальный единичный элемент и для каждого элемента есть уникальный элемент обратной величины. И, наконец, умножение дистрибутивно относительно сложения:
 .
.Множество целых чисел по модулю
состоит из всех целых чисел от 0 до  . Сложение и умножение работают как в модулярной арифметике. Вот несколько примеров операций над
. Сложение и умножение работают как в модулярной арифметике. Вот несколько примеров операций над  :
:- Сложение:

- Вычитание:

- Умножение:

- Аддитивная инверсия:
 . Действительно:
. Действительно: 
- Мультипликативная инверсия:

Если эти уравнения вам незнакомы и вы хотите изучить основы модулярной арифметики, пройдите курс в Академии Хана.
Как мы уже сказали целые числа по модулю
— это поле, поэтому все перечисленные выше свойства сохраняются. Учтите, что требование того, чтобы было простым числом, очень важно! Множество целых чисел по модулю 4 не является полем: 2 не имеет мультипликативной инверсии (т.е. уравнение  не имеет решений).
не имеет решений).Деление по модулю p
Скоро мы определим эллиптические кривые для
, но прежде нам нужно чётко понимать, что  означает над . Попросту говоря:
означает над . Попросту говоря:  , или, прямым текстом, в числителе и
, или, прямым текстом, в числителе и  в знаменателе равно раз обратная величина . Это нас не удивляет, но даёт нам простой способ выполнения деления: найти обратную величину числа, а затем выполнить простое умножение.
в знаменателе равно раз обратная величина . Это нас не удивляет, но даёт нам простой способ выполнения деления: найти обратную величину числа, а затем выполнить простое умножение.Вычисление обратного числа можно «просто» выполнить с помощью расширенного алгоритма Евклида, который в худшем случае имеет сложность
 (или , если мы учитываем битовую длину).
(или , если мы учитываем битовую длину).Мы не будем вдаваться в подробности расширенного алгоритма Евклида, это не входит в рамки статьи, но я представлю работающую реализацию на Python:
def extended_euclidean_algorithm(a, b): """ Возвращает кортеж из трёх элементов (gcd, x, y), такой, что a * x + b * y == gcd, где gcd - наибольший общий делитель a и b. В этой функции реализуется расширенный алгоритм Евклида и в худшем случае она выполняется O(log b). """ s, old_s = 0, 1 t, old_t = 1, 0 r, old_r = b, a while r != 0: quotient = old_r // r old_r, r = r, old_r - quotient * r old_s, s = s, old_s - quotient * s old_t, t = t, old_t - quotient * t return old_r, old_s, old_t def inverse_of(n, p): """ Возвращает обратную величину n по модулю p. Эта функция возвращает такое целое число m, при котором (n * m) % p == 1. """ gcd, x, y = extended_euclidean_algorithm(n, p) assert (n * x + p * y) % p == gcd if gcd != 1: # Или n равно 0, или p не является простым. raise ValueError( '{} has no multiplicative inverse ' 'modulo {}'.format(n, p)) else: return x % p
Эллиптические кривые над
Теперь у нас есть все необходимые элементы для ограничения эллиптических кривых полем
. Множество точек, которые в предыдущей части имели следующий вид:
теперь превращаются в:

где 0 — по-прежнему точка в бесконечности, а
и — два целых числа в .Кривая
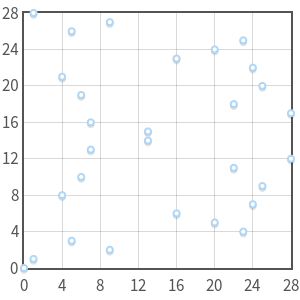
 с
с  . Заметьте, что для каждого существует максимум две точки. Также заметьте симметрию относительно
. Заметьте, что для каждого существует максимум две точки. Также заметьте симметрию относительно  .
.
Кривая
 — особая и имеет тройную точку в
— особая и имеет тройную точку в  . Она не является истинной эллиптической кривой.
. Она не является истинной эллиптической кривой.То, что раньше было непрерывной кривой, теперь стало множеством отдельных точек на плоскости
. Но можно доказать, что несмотря на ограничение области определения, эллиптические кривые над всё равно создают абелеву группу.Сложение точек
Очевидно, что нам нужно немного изменить определение сложения, чтобы оно работало для
. Для вещественных чисел мы сказали, что сумма трёх точек на одной прямой равна нулю (). Мы можем сохранить это определение, но что значит расположение трёх точек на одной прямой над ?Можно сказать, что три точки находятся на одной прямой, если существует прямая, соединяющая их. Разумеется, прямые над
отличаются от прямых над  . Можно сказать, что прямая над — это множество точек
. Можно сказать, что прямая над — это множество точек  , удовлетворяющих уравнению
, удовлетворяющих уравнению  (это стандартное уравнение прямой с добавленной частью "
(это стандартное уравнение прямой с добавленной частью " ").
").
Сложение точек для кривой
 , при
, при  и
и  . Заметьте, как соединяющая точки прямая
. Заметьте, как соединяющая точки прямая  «повторяет» себя на плоскости.
«повторяет» себя на плоскости.Учитывая то, что мы по-прежнему находимся в группе, сложение точек сохраняет уже известные нам свойства:
 (из определения единичного элемента).
(из определения единичного элемента).- Для обратная величина
 — это точка, имеющая ту же абсциссу, но обратную ординату. Или, если угодно,
— это точка, имеющая ту же абсциссу, но обратную ординату. Или, если угодно,  . Например, если кривая над
. Например, если кривая над  имеет точку
имеет точку  , то обратной величиной будет
, то обратной величиной будет  .
. - Кроме того, (из определения обратной величины).
Алгебраическая сумма
Уравнения для выполнения сложений точек в точности такие же, как в предыдущей части, за исключением того, что нам нужно добавлять в конце каждого выражения "
 ". Поэтому, если , и , то можно вычислить следующим способом:
". Поэтому, если , и , то можно вычислить следующим способом:![$\begin{array}{rcl} x_R & = & (m^2 - x_P - x_Q) \bmod{p} \\ y_R & = & [y_P + m(x_R - x_P)] \bmod{p} \\ & = & [y_Q + m(x_R - x_Q)] \bmod{p} \end{array}$](https://habrastorage.org/getpro/habr/formulas/8d4/ee4/757/8d4ee475790e1efc57c80f07220bb800.svg)
Если
, то наклон принимает форму:
Иначе, если
, мы получаем:
Уравнения не изменились, и это не совпадение: на самом деле, эти уравнения работают над любым полем, и над конечным, и над бесконечным (за исключением
 и
и  , которые являются особыми случаями). Я чувствую, что это нужно объяснить. Но есть проблема: для доказательств группового закона обычно требуются сложные математические понятия. Однако я нашёл доказательство Стефана Фридла в котором используются только простейшие концепции. Прочитайте его, если вам интересно, почему эти уравнения работают (почти) над любым полем.
, которые являются особыми случаями). Я чувствую, что это нужно объяснить. Но есть проблема: для доказательств группового закона обычно требуются сложные математические понятия. Однако я нашёл доказательство Стефана Фридла в котором используются только простейшие концепции. Прочитайте его, если вам интересно, почему эти уравнения работают (почти) над любым полем.Вернёмся к кривым — мы не будем определять геометрический способ: на самом деле, с ним возникнут проблемы. Например, в предыдущей части мы сказали, что для вычисления
 нам придётся взять касательную к кривой в . Но при отсутствии непрерывности слово «касательная» теряет всякий смысл. Мы можем найти способ обойти эту и другие проблемы, однако чисто геометрический способ будет слишком сложным и совершенно непрактичным.
нам придётся взять касательную к кривой в . Но при отсутствии непрерывности слово «касательная» теряет всякий смысл. Мы можем найти способ обойти эту и другие проблемы, однако чисто геометрический способ будет слишком сложным и совершенно непрактичным.Вместо этого можно поэкспериментировать с интерактивным инструментом, написанным мной для выполнения сложений точек.
Порядок группы эллиптической кривой
Мы сказали, что эллиптическая кривая, определённая над конечным полем, имеет конечное количество точек. Нам нужно ответить на важный вопрос: сколько же в ней точек?
Во-первых, давайте определим, что количество точек в группе называется порядком группы.
Проверка всех возможных значений для
в интервале от 0 до будет невыполнимым способом подсчёта точек, потому что потребует  шагов, а эта задача «сложна», если — большое простое число.
шагов, а эта задача «сложна», если — большое простое число.К счастью, для вычисления порядка существует более быстрый алгоритм: алгоритм Шуфа. Я не буду вдаваться в его подробности — главное, что он выполняется за полиномиальное время, а именно этого нам и нужно.
Скалярное умножение и циклические подгруппы
Для вещественных чисел умножение можно определить как:
И, повторюсь, мы можем использовать алгоритм удвоения-сложения для выполнения умножения за
, где — это количество бит ). Я написал интерактивный инструмент для скалярного умножения.Умножение точек для эллиптических кривых над
обладает интересным свойством. Возьмём кривую  и точку
и точку  . Теперь вычислим все величины, кратные :
. Теперь вычислим все величины, кратные :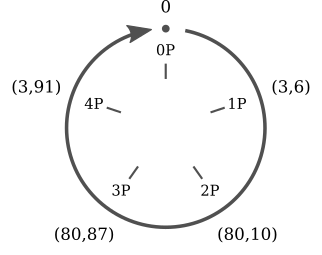
Все значения, кратные
, представляют собой пять различных точек ( , , ,
, , ,  ,
,  ), которые циклически повторяются. Легко заметить сходство между скалярным умножением для эллиптических кривых и сложением в модулярной арифметике.
), которые циклически повторяются. Легко заметить сходство между скалярным умножением для эллиптических кривых и сложением в модулярной арифметике.









- ...
Можно сразу же заметить две особенности: во-первых, значений, кратных
, всего пять: другие точки эллиптической кривой никогда ими не становятся. Во-вторых, они повторяются циклически. Можно записать:




для любого целого
. Заметьте, что благодаря оператору деления с остатком эти пять уравнений можно «ужать» в одно:  .
.Более того, мы можем сразу же показать, что эти пять точек замкнуты относительно операции сложения. Что это значит: как бы я ни суммировал
, , , или , результатом всегда будет одна из этих пяти точек. И снова все остальные точки эллиптической кривой никогда не становятся результатом.То же относится и ко всем остальным точкам, не только к
. На самом деле, если мы возьмём в общем виде:
Что означает: если мы складываем два значения, кратных
, то получаем значение, кратное (т.е. значения, кратные , замкнуты относительно операции сложения). Этого достаточно для того, чтобы доказать, что множество кратных значений — это циклическая подгруппа группы, образованной эллиптической кривой.«Подгруппа» — это группа, являющаяся подмножеством другой группы. «Циклическая подгруппа» — это подгруппа, элементы которой циклически повторяются, как мы показали в предыдущем примере. Точка
называется генератором или базовой точкой циклической подгруппы.Циклические подгруппы — фундамент для ECC и других криптосистем. Позже я объясню, почему это так.
Порядок подгруппы
Можно задаться вопросом, каков порядок подгруппы, порождённой точкой
(или, иными словами, каков порядок ). Для ответа на этот вопрос мы не можем использовать алгоритм Шуфа, потому что этот алгоритм работает только для целых эллиптических кривых, но не для подгрупп. Прежде чем приступить к решению задачи, нам нужно ещё немного информации:- Пока мы определяли порядок как количество точек группы. Это определение по-прежнему действительно, но в циклических подгруппах мы можем дать новое аналогичное определение: порядок — это минимальное положительное целое , такое, что
 .
.
На самом деле, если посмотреть на предыдущий пример, то наша подгруппа состояла из пяти точек, и. - Порядок связан с порядком эллиптической кривой теоремой Лагранжа, согласно которой порядок подгруппы — это делитель порядка исходной группы.
Иными словами, если эллиптическая кривая содержит точек, а одна из подгрупп содержит , то является делителем .
точек, а одна из подгрупп содержит , то является делителем .
Два этих факта вместе дают нам возможность определить порядок подгруппы с базовой точкой
:- Вычисляем порядок эллиптической кривой с помощью алгоритма Шуфа.
- Находим все делители .
- Для каждого делителя порядка вычисляем .
- Наименьшее , такое, что , является порядком подгруппы.
Например, кривая
 над полем
над полем  имеет порядок
имеет порядок  . Её подгруппы могут иметь порядок
. Её подгруппы могут иметь порядок  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  или
или  . Если мы подставим
. Если мы подставим  , то увидим, что
, то увидим, что  ,
,  , ...,
, ...,  , то есть порядок равен
, то есть порядок равен  .
.Учтите, что важно брать наименьший, а не случайный делитель. Если мы будем выбирать случайно, то можем получить
 , что не является порядком подгруппы, но является одним из кратных.
, что не является порядком подгруппы, но является одним из кратных.Ещё один пример: эллиптическая кривая, определяемая уравнением
 над полем , имеет порядок
над полем , имеет порядок  , которое является простым числом. Её подгруппы могут иметь порядок только или
, которое является простым числом. Её подгруппы могут иметь порядок только или  . Как вы можете догадаться, когда , подгруппа содержит только бесконечно удалённую точку; когда
. Как вы можете догадаться, когда , подгруппа содержит только бесконечно удалённую точку; когда  , подгруппа содержит все точки эллиптической кривой.
, подгруппа содержит все точки эллиптической кривой.Поиск базовой точки
Для алгоритмов ECC требуются подгруппы с высоким порядком. Поэтому обычно выбирается эллиптическая кривая, вычисляется её порядок (
), в качестве порядка группы () выбирается большой делитель, а потом находится подходящая базовая точка. То есть мы не выбираем базовую точку, после чего вычисляем её порядок, а производим обратную операцию: сначала выбираем достаточно хороший порядок, а потом ищем подходящую базовую точку. Как же это сделать?Во-первых, нужно ввести ещё одно понятие. Теорема Лагранжа подразумевает, что число
 всегда целое (потому что — делитель ). Число
всегда целое (потому что — делитель ). Число  имеет собственное название: это кофактор подгруппы.
имеет собственное название: это кофактор подгруппы.Теперь рассмотрим, что для каждой точки эллиптической кривой есть
 . Это справедливо, потому что — это кратное любому возможному . Исходя из определения кофактора, мы можем записать:
. Это справедливо, потому что — это кратное любому возможному . Исходя из определения кофактора, мы можем записать:
Теперь допустим, что
— простое число (мы предпочитаем простые порядки по причинам, изложенным в первой части статьи). Это уравнение, записанное в такой форме, говорит нам, что точка  создаёт подгруппу порядка (за исключением случая
создаёт подгруппу порядка (за исключением случая  , в котором подгруппа имеет порядок 1).
, в котором подгруппа имеет порядок 1).В свете этого мы можем определить следующий алгоритм:
- Вычисляем порядок эллиптической кривой.
- Выбираем порядок подгруппы. Чтобы алгоритм сработал, число должно быть простым и быть делителем .
- Вычисляем кофактор .
- Выбираем на кривой случайную точку .
- Вычисляем .
- Если
 равно 0, то возвращаемся к шагу 4. В противном случае мы нашли генератор подгруппы с порядком и кофактором .
равно 0, то возвращаемся к шагу 4. В противном случае мы нашли генератор подгруппы с порядком и кофактором .
Заметьте, что алгоритм работает только если
простое. Если бы не было простым, то порядок мог быть одним из делителей .Дискретный логарифм
Как и в случае с непрерывными эллиптическими кривыми, теперь мы должны обсудить следующий вопрос: если мы знаем
и , то каким будет , такое, что  ?
?Эта задача, известная как задача дискретного логарифмирования для эллиптических кривых, считается «сложной», для которой не обнаружено алгоритма полиномиального времени, выполняемого на классическом компьютере. Однако у этой точки зрения нет математических доказательств.
Эта задача аналогична задаче дискретного логарифмирования, используемой в других криптосистемах, таких как Digital Signature Algorithm (DSA), протокол Диффи-Хеллмана (D-H) и схема Эль-Гамаля. Названия задач совпадают неслучайно. Их разница в том, что в этих алгоритмах используется не скалярное умножение, а возведение в степень по модулю. Их задачу дискретного логарифмирования можно сформулировать так: если известны
и , то каким будет , такое, что  ?
?Обе эти задачи «дискретны», потому что в них используются конечные множества (а конкретнее — циклические подгруппы). И они являются «логарифмами», потому что аналогичны обычным логарифмам.
ECC интересна тем, что на сегодняшний момент задача дискретного логарифмирования для эллиптических кривых кажется «сложнее» по сравнению с другими схожими задачами, используемыми в криптографии. Это подразумевает, что нам потребуется меньше бит для целого
, чтобы получить тот же уровень защиты, что и в других криптосистемах, и мы это подробно рассмотрим в четвёртой, последней, части статьи.Часть 3: ECDH и ECDSA
Параметры области определения
Алгоритмы эллиптических кривых будут работать в циклической подгруппе эллиптической кривой над конечным полем. Поэтому алгоритмам потребуются следующие параметры:
- Простое , задающее размер конечного поля.
- Коэффициенты и уравнения эллиптической кривой.
- Базовая точка , генерирующая подгруппу.
- Порядок подгруппы.
- Кофактор подгруппы.
В результате параметрами области определения для алгоритмов является шестёрка
 .
.Случайные кривые
Когда я говорил, что задача дискретного логарифмирования «сложна», я был не совсем точен. Существуют определённые классы эллиптических кривых, которые довольно слабы и позволяют использовать специальные алгоритмы для эффективного решения задачи дискретного логарифмирования. Например, все кривые, для которых
 (то есть порядок конечного поля равен порядку эллиптической кривой), уязвимы к атаке Смарта, которую можно использовать для решения дискретных логарифмов за полиномиальное время на классических компьютерах.
(то есть порядок конечного поля равен порядку эллиптической кривой), уязвимы к атаке Смарта, которую можно использовать для решения дискретных логарифмов за полиномиальное время на классических компьютерах.Предположим теперь, что я дал вам параметры области определения кривой. Существует вероятность, что я обнаружил неизвестный никому новый класс слабых кривых, и, возможно, я создал «быстрый» алгоритм вычисления дискретных логарифмов для своей кривой. Как я могу убедить вас в обратном, т.е. в том, что мне неизвестно об уязвимостях? Как я могу гарантировать, что кривая «защищена» (в том смысле, что я не смогу её использовать для собственных атак)?
Чтобы решить эту проблему, иногда приходится использовать дополнительный параметр области определения: порождающее значение (seed)
 . Это случайное число, используемое для генерирования коэффициентов и или базовой точки , или того и другого. Эти параметры генерируются вычислением хеша . Хеши, как мы знаем, «просто» вычислить, но «сложно» реверсировать.
. Это случайное число, используемое для генерирования коэффициентов и или базовой точки , или того и другого. Эти параметры генерируются вычислением хеша . Хеши, как мы знаем, «просто» вычислить, но «сложно» реверсировать.
Простая схема генерирования случайной кривой из порождающего значения: хеш случайного числа используется для вычисления различных параметров кривой.
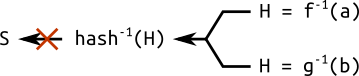
Если бы мы хотели сжульничать и воссоздать хеш из параметров области определения, то нам пришлось бы решать «сложную» задачу: инверсирование хеша.
Сгенерированная с помощью порождающего значения кривая называется проверяемо случайной. Принцип использования хешей для генерирования параметров известен как "nothing up my sleeve" («в рукавах ничего нет»), и широко распространён в криптографии.
Эта хитрость даёт определённую гарантию, что кривая не была специально создана таким образом, чтобы иметь известные её автору уязвимости. На самом деле, если я даю вам кривую вместе с порождающим значением, то это значит, что я не мог произвольно выбирать параметры
и , и можно быть относительно спокойным, что я не смогу использовать специальные атаки. Причина использования слова «относительно» будет объяснена в четвёртой части.Стандартизированный алгоритм генерирования и проверки случайных кривых описан в ANSI X9.62 и основан на SHA-1. Если интересно, можете прочитать об алгоритмах генерирования проверяемо случайных кривых в спецификации SECG (см. «Verifiably Random Curves and Base Point Generators»).
Я написал небольшой скрипт на Python, проверяющий все случайные кривые, поставляемые сейчас с OpenSSL. Крайне рекомендую посмотреть его!
Криптография на эллиптических кривых
Мы потратили много времени, но наконец добрались! Всё просто:
- Закрытый ключ — это случайное целое
 , выбранное из
, выбранное из  (где — порядок подгруппы).
(где — порядок подгруппы). - Открытый ключ — это точка
 (где — базовая точка подгруппы).
(где — базовая точка подгруппы).
Видите? Если мы знаем
и (вместе с другими параметрами области определения), то найти  «просто». Но если мы знаем и , то поиск закрытого ключа является «сложной» задачей, потому что требует решения задачи дискретного логарифмирования.
«просто». Но если мы знаем и , то поиск закрытого ключа является «сложной» задачей, потому что требует решения задачи дискретного логарифмирования.Теперь мы опишем два основанных на этом принципе алгоритма с открытым ключом: ECDH (Elliptic curve Diffie-Hellman, протокол Диффи-Хеллмана на эллиптических кривых), используемый для шифрования, и ECDSA (Elliptic Curve Digital Signature Algorithm), используемый для цифровых подписей.
Шифрование с помощью ECDH
ECDH — это разновидность алгоритма Диффи-Хеллмана для эллиптических кривых. На самом деле это скорее протокол согласования ключей, а не алгоритм шифрования. В сущности, это означает, что ECDH задаёт (в определённой степени) порядок генерирования ключей и обмена ими. Способ шифрования данных с помощью таких ключей мы можем выбирать сами.
Он решает следующую проблему: две стороны (обычно Алиса и Боб) хотят безопасно обмениваться информацией, чтобы третья сторона (посредник, Man In the Middle) мог перехватывать её, но не мог расшифровать. Например, это один из принципов TLS.
Вот как это работает:
- Сначала Алиса и Боб генерируют собственные закрытые и открытые ключи. У Алисы есть закрытый ключ
 и открытый ключ
и открытый ключ  , у Боба есть ключи
, у Боба есть ключи  и
и  . Заметьте, что и Алиса, и Боб используют одинаковые параметры области определения: одну базовую точку на одной эллиптической кривой в одинаковом конечном поле.
. Заметьте, что и Алиса, и Боб используют одинаковые параметры области определения: одну базовую точку на одной эллиптической кривой в одинаковом конечном поле. - Алиса и Боб обмениваются открытыми ключами
 и
и  по незащищённому каналу. Посредник (Man In the Middle) перехватывает и , но не может определить ни , ни , не решив задачу дискретного логарифмирования.
по незащищённому каналу. Посредник (Man In the Middle) перехватывает и , но не может определить ни , ни , не решив задачу дискретного логарифмирования. - Алиса вычисляет
 (с помощью собственного закрытого ключа и открытого ключа Боба), а Боб вычисляет
(с помощью собственного закрытого ключа и открытого ключа Боба), а Боб вычисляет  (с помощью собственного закрытого ключа и открытого ключа Алисы). Учтите, что одинаков и для Алисы, и для Боба. На самом деле:
(с помощью собственного закрытого ключа и открытого ключа Алисы). Учтите, что одинаков и для Алисы, и для Боба. На самом деле:

Однако посреднику известны только
и (вместе с другими параметрами области определения) и он не сможет найти общий секретный ключ . Это известно как задача Диффи-Хеллмана, которую можно сформулировать следующим образом:Каким будет результатдля трёх точек
и
?
Или, аналогично:
Каким будет результатдля трёх целых
и
?
(Последняя формулировка используется в исходном алгоритме Диффи-Хеллмана, основанном на модулярной арифметике.)
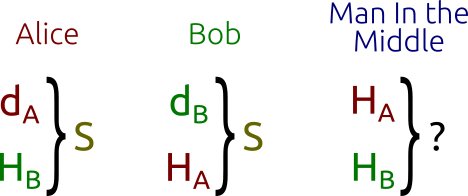
Протокол Диффи-Хеллмана: Алиса и Боб могут «просто» вычислить общий секретный ключ, посреднику же придётся решать «сложную» задачу.
Принцип, лежащий в основе задачи Диффи-Хеллмана, также объяснён в отличном видео Академии Хана на YouTube, в котором чуть позже объясняется алгоритм Диффи-Хеллмана в приложении к модулярной арифметике (не к эллиптическим кривым).
Задача Диффи-Хеллмана для эллиптических кривых считается «сложной». Считается, что она так же «сложна», как задача дискретного логарифмирования, но математических доказательств этому нет. Мы можем только с уверенностью сказать, что она не может быть «сложнее», потому что решение задачи логарифмирования — это способ решения задачи Диффи-Хеллмана.
Получив общий секретный ключ, Алиса и Боб могут обмениваться данными с симметричным шифрованием.
Например, они могут использовать координату
ключа как ключ для шифрования сообщений такими безопасными шифрами, как AES или 3DES. Примерно это и делает TLS, разница в том, что TLS соединяет координату с другими числами, относящимися к подключению, а затем вычисляет хеш получившейся строки байтов.Эксперименты с ECDH
Я написал ещё один скрипт на Python для вычисления закрытых/открытых ключей и общих секретных ключей над эллиптической кривой.
В отличие от показанных ранее примеров, в этом скрипте используется стандартизированная кривая, а не простая кривая на небольшом поле. Я выбрал кривую
secp256k1 группы SECG («Standards for Efficient Cryptography Group», основанной Certicom). Та же самая кривая используется в Bitcoin для цифровых подписей. Вот параметры области определения:- = 0xffffffff ffffffff ffffffff ffffffff ffffffff ffffffff fffffffe fffffc2f
- = 0
- = 7
 = 0x79be667e f9dcbbac 55a06295 ce870b07 029bfcdb 2dce28d9 59f2815b 16f81798
= 0x79be667e f9dcbbac 55a06295 ce870b07 029bfcdb 2dce28d9 59f2815b 16f81798 = 0x483ada77 26a3c465 5da4fbfc 0e1108a8 fd17b448 a6855419 9c47d08f fb10d4b8
= 0x483ada77 26a3c465 5da4fbfc 0e1108a8 fd17b448 a6855419 9c47d08f fb10d4b8- = 0xffffffff ffffffff ffffffff fffffffe baaedce6 af48a03b bfd25e8c d0364141
- = 1
(Эти числа взяты из исходного кода OpenSSL.)
Разумеется, вы можете изменить скрипт и использовать другие кривые и параметры области определения, только обязательно используйте простые поля и обычную формулировку Вейерштрасса, иначе скрипт не будет работать.
Скрипт очень прост и содержит некоторые из описанных выше алгоритмов: сложение точек, удвоение-сложение, ECDH. Рекомендую изучить и запустить его. Он создаёт примерно такие выходные данные:
Curve: secp256k1 Alice's private key: 0xe32868331fa8ef0138de0de85478346aec5e3912b6029ae71691c384237a3eeb Alice's public key: (0x86b1aa5120f079594348c67647679e7ac4c365b2c01330db782b0ba611c1d677, 0x5f4376a23eed633657a90f385ba21068ed7e29859a7fab09e953cc5b3e89beba) Bob's private key: 0xcef147652aa90162e1fff9cf07f2605ea05529ca215a04350a98ecc24aa34342 Bob's public key: (0x4034127647bb7fdab7f1526c7d10be8b28174e2bba35b06ffd8a26fc2c20134a, 0x9e773199edc1ea792b150270ea3317689286c9fe239dd5b9c5cfd9e81b4b632) Shared secret: (0x3e2ffbc3aa8a2836c1689e55cd169ba638b58a3a18803fcf7de153525b28c3cd, 0x43ca148c92af58ebdb525542488a4fe6397809200fe8c61b41a105449507083)
Эфемерное ECDH
Некоторые из вас, возможно, слышали об ECDHE, а не об ECDH. «E» в ECHDE обозначает «Ephemeral» (эфемерное) и связано с тем, что передаваемые ключи временны, а не статичны.
ECDHE используется, например, в TLS, где клиент и сервер генерируют свою пару закрытого-открытого ключа на лету, при установке соединения. Затем ключи подписываются сертификатом TLS (для авторизации) и передаются между сторонами.
Подписывание с помощью ECDSA
Сценарий следующий: Алиса хочет подписать сообщение своим закрытым ключом (
), а Боб хочет проверить подпись с помощью открытого ключа Алисы (). Никто, кроме Алисы не должен иметь возможности создать действительные подписи. Каждый должен иметь возможность проверить подписи.Алиса и Боб снова используют одинаковые параметры области определения. Мы рассмотрим алгоритм ECDSA, разновидность Digital Signature Algorithm, применённого к эллиптическим кривым.
ECDSA работает с хешем сообщения, а не с самим сообщением. Выбор хеш-функции остаётся за нами, но, очевидно, нужно выбирать криптографическую хеш-функцию. Хеш сообщения необходимо урезать, чтобы битовая длина хеша была такой же, что и битовая длина
(порядок подгруппы). Урезанный хеш — это целое число и оно будет обозначаться как  .
.Алгоритм, выполняемый Алисой для подписывания сообщения, работает следующим образом:
- Берём случайное целое , выбранное из (где — это по-прежнему порядок группы).
- Вычисляем точку
 (где — базовая точка подгруппы).
(где — базовая точка подгруппы). - Вычисляем число
 (где
(где  — это координата ).
— это координата ). - Если
 , то выбираем другое и пробуем снова.
, то выбираем другое и пробуем снова. - Вычисляем
 (где — закрытый ключ Алисы, а
(где — закрытый ключ Алисы, а  — мультипликативная инверсия по модулю ).
— мультипликативная инверсия по модулю ). - Если
 , то выбираем другое и пробуем снова.
, то выбираем другое и пробуем снова.
Пара
 является подписью.
является подписью.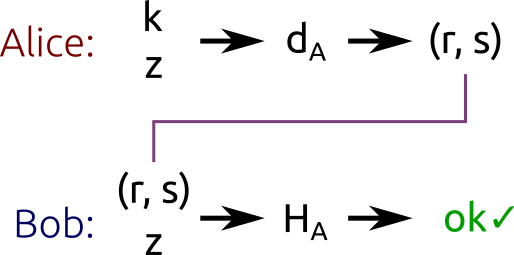
Алиса подписывает хеш
с помощью закрытого ключа и случайного . Боб проверяет правильность подписи сообщения с помощью открытого ключа Алисы .Проще говоря, этот алгоритм сначала генерирует секретный ключ (
). Благодаря умножению точек (которое, как мы знаем, является «простым» в одну сторону и «сложным» в обратную) секретный ключ прячется в  . Затем привязывается к хешу сообщения уравнением .
. Затем привязывается к хешу сообщения уравнением .Учтите, что для вычисления
 мы вычислили обратную величину по модулю . Как было сказано в предыдущей части, это гарантировано сработает только если — простое число. Если подгруппа имеет порядок непростого числа, ECDSA использовать не удастся. Неслучайно все стандартизированные кривые имеют простой порядок, а имеющие непростой порядок неприменимы для ECDSA.
мы вычислили обратную величину по модулю . Как было сказано в предыдущей части, это гарантировано сработает только если — простое число. Если подгруппа имеет порядок непростого числа, ECDSA использовать не удастся. Неслучайно все стандартизированные кривые имеют простой порядок, а имеющие непростой порядок неприменимы для ECDSA.Проверка подписей
Для проверки подписи необходим открытый ключ Алисы
, (урезанный) хеш и, очевидно, подпись .- Вычисляем целое
 .
. - Вычисляем целое
 .
. - Вычисляем точку
 .
.
Подпись действительна, только если
.Корректность алгоритма
С первого взгляда логика алгоритма может быть неочевидной, однако если объединить все ранее записанные нами уравнения, всё становится понятнее.
Начнём с
. Из определения открытого ключа мы знаем, что (где — закрытый ключ). Можно записать:
С учётом определений
 и
и  можно записать:
можно записать:
Здесь мы опустили "
 ", как для краткости, так и потому, что циклическая подгруппа, сгенерированная точкой , имеет порядок , то есть часть "" избыточна.
", как для краткости, так и потому, что циклическая подгруппа, сгенерированная точкой , имеет порядок , то есть часть "" избыточна.Ранее мы определили
. Умножив обе части уравнения уравнения на и поделив на , мы получаем:  . Подставляя этот результат в наше уравнение для , получаем:
. Подставляя этот результат в наше уравнение для , получаем:
Это то же самое уравнение
, которое было у нас на шаге 2 алгоритма генерирования подписи! При генерировании подписей и при их проверке мы вычисляем одну и ту же точку , просто разными наборами уравнений. Именно поэтому алгоритм работает.Экспериментируем с ECDSA
Разумеется, я написал скрипт на Python для генерирования и проверки подписей. Код копирует некоторые части из скрипта ECDH, в частности, параметры области определения и алгоритм генерирования пары закрытого/открытого ключей.
Вот какие выходные данные создаются этим скриптом:
Curve: secp256k1 Private key: 0x9f4c9eb899bd86e0e83ecca659602a15b2edb648e2ae4ee4a256b17bb29a1a1e Public key: (0xabd9791437093d377ca25ea974ddc099eafa3d97c7250d2ea32af6a1556f92a, 0x3fe60f6150b6d87ae8d64b78199b13f26977407c801f233288c97ddc4acca326) Message: b'Hello!' Signature: (0xddcb8b5abfe46902f2ac54ab9cd5cf205e359c03fdf66ead1130826f79d45478, 0x551a5b2cd8465db43254df998ba577cb28e1ee73c5530430395e4fba96610151) Verification: signature matches Message: b'Hi there!' Verification: invalid signature Message: b'Hello!' Public key: (0xc40572bb38dec72b82b3efb1efc8552588b8774149a32e546fb703021cf3b78a, 0x8c6e5c5a9c1ea4cad778072fe955ed1c6a2a92f516f02cab57e0ba7d0765f8bb) Verification: invalid signature
Как видите, скрипт сначала подписывает сообщение (байтовую строку «Hello!»), а затем проверяет подпись. После чего он пробует проверить ту же подпись для другого сообщения («Hi there!») и проверка не удаётся. Наконец, он пробуем проверить проверить подпись для правильного сообщения, но с другим случайным открытым ключом, после чего проверка тоже не удаётся.
Важность k
При генерировании подписей ECDSA важно хранить секретный
по-настоящему в тайне. Если бы мы использовали одну для всех подписей или генератор случайных чисел оказался бы в какой-нибудь степени предсказуемым, то атакующий смог бы определить закрытый ключ!Подобную ошибку сделала Sony несколько лет назад. На игровой консоли PlayStation 3 можно было запускать игры, только подписанные Sony алгоритмом ECDSA. То есть, если бы я хотел создать новую игру для PlayStation 3, я не смог бы распространять её среди пользователей без подписи Sony. Проблема заключалась в том, что все созданные Sony подписи были сгенерированы с помощью статичного
.(Похоже, создатели генератора случайных чисел Sony вдохновлялись или XKCD, или Дилбертом.)
В такой ситуации можно запросто восстановить закрытый ключ
 Sony, купив всего две подписанные игры, после чего извлечь их хеши (
Sony, купив всего две подписанные игры, после чего извлечь их хеши ( и
и  ) и подписи (
) и подписи ( и
и  ) вместе с параметрами области определения. Это делается так:
) вместе с параметрами области определения. Это делается так:- Сначала нужно учесть, что
 (потому что и одинаковы для обеих подписей).
(потому что и одинаковы для обеих подписей). - Принять, что
 (этот результат следует непосредственно из уравнения для ).
(этот результат следует непосредственно из уравнения для ). - Умножить обе части уравнения на :
 .
. - Разделить на
 , чтобы получить
, чтобы получить  .
.
Последнее уравнение позволяет нам вычислить
с помощью всего двух хешей и соответствующих им подписей. Теперь с помощью уравнения для мы можем получить закрытый ключ:
Похожие техники можно применить, если
не статично, но каким-то образом предсказуемо.Часть 4: алгоритмы для взлома защиты ECC и сравнение с RSA
В предыдущей части мы рассмотрели два алгоритма (ECDH and ECDSA) и разобрались, почему задача дискретного логарифмирования для эллиптических кривых играет важную роль для их безопасности. Но, если вы помните, мы сказали, что математических доказательств сложности задачи дискретного логарифмирования нет: мы полагаем, что она «сложна», но не уверены в этом. В первой части статьи мы попробовали оценить, насколько «сложна» она на практике в условиях современных технологий.
Во второй части мы попытались ответить на вопрос: зачем нам нужна криптография на эллиптических кривых, если RSA (и другие криптосистемы, основанные на модулярной арифметике) хорошо работают?
Взлом задачи дискретного логарифмирования
Теперь мы рассмотрим два наиболее эффективных алгоритма вычисления дискретных алгоритмов на эллиптической кривой: алгоритм «baby-step, giant-step» и ρ-алгоритм Полларда.
Прежде чем начать, я напомню, в чём заключается задача дискретного логарифмирования: найти для двух заданных точек
и целое число , удовлетворяющее уравнению  . Точки принадлежат подгруппе эллиптической кривой с базовой точкой и порядком .
. Точки принадлежат подгруппе эллиптической кривой с базовой точкой и порядком .Baby-step, giant-step
Для начала приведу простое рассуждение: мы всегда можем записать любое целое
как  , где , и — три произвольных целых. Например, можно записать
, где , и — три произвольных целых. Например, можно записать  .
.С учётом этого можно переписать уравнение задачи дискретного логарифмирования следующим образом:

Baby-step giant-step — это алгоритм «встречи посередине». В отличие от атаки перебором (при которой придётся вычислять все точки
 для каждого , пока мы не найдём ), можно вычислять «несколько» значений для и «несколько» значений для
для каждого , пока мы не найдём ), можно вычислять «несколько» значений для и «несколько» значений для  , пока мы не найдём соответствие. Алгоритм работает следующим образом:
, пока мы не найдём соответствие. Алгоритм работает следующим образом:- Вычисляем

- Для каждого из
 вычисляем и сохраняем результаты в хеш-таблицу.
вычисляем и сохраняем результаты в хеш-таблицу. - Для каждого из :
- вычисляем
 ;
; - вычисляем ;
- проверяем хеш-таблицу и ищем точку , такую, что
 ;
; - если такая точка существует, то мы нашли .
- вычисляем
Как видите, изначально мы вычисляем точки
с небольшим инкрементом («детскими шагами» «baby step») для коэффициента ( , , , ...). Во второй части алгоритма мы вычисляем точки с большим инкрементом («великанскими шагами» «giant step») для
, , , ...). Во второй части алгоритма мы вычисляем точки с большим инкрементом («великанскими шагами» «giant step») для  (
( ,
,  ,
,  , ..., где — большое число).
, ..., где — большое число).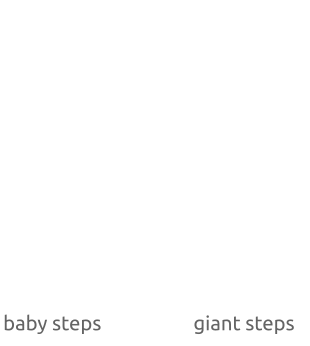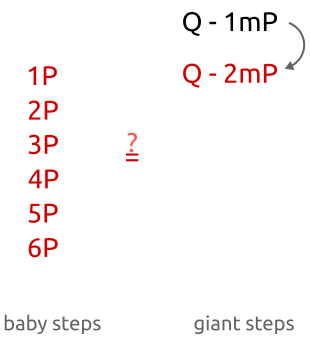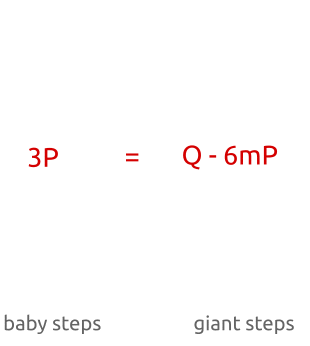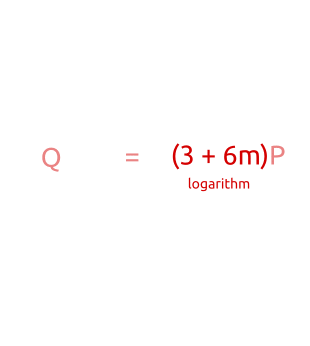
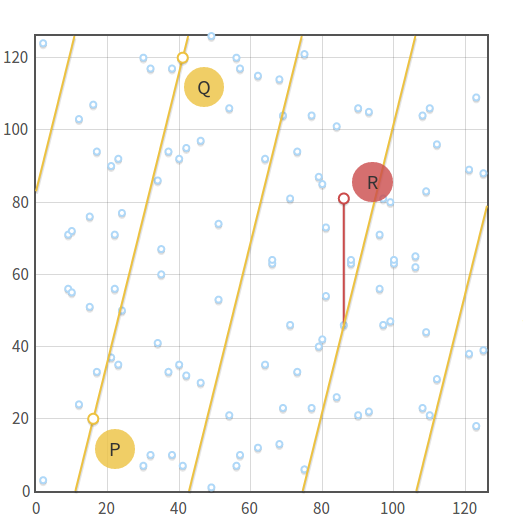
Алгоритм baby-step, giant-step: сначала мы вычисляем несколько точек с небольшим шагом и сохраняем их в хеш-таблице. Затем делаем великанские шаги и сравниваем новые точки с точками в хеш-таблице. Найдя соответствие, мы можем вычислить дискретный алгоритм простой перестановкой членов.
Чтобы понять, как работает алгоритм, забудем на минуту о том, что
кешируются, и возьмём уравнение  . Рассмотрим, что из этого следует:
. Рассмотрим, что из этого следует:- При
 мы проверяем, равно ли числу , где — одно из целых от 0 до . Таким образом, мы сравниваем со всеми точками от
мы проверяем, равно ли числу , где — одно из целых от 0 до . Таким образом, мы сравниваем со всеми точками от  до
до  .
. - При
 мы проверяем равно ли числу
мы проверяем равно ли числу  . Мы сравниваем со всеми точками от до .
. Мы сравниваем со всеми точками от до . - При
 мы сравниваем со всеми точками от до .
мы сравниваем со всеми точками от до . - ...
- При
 мы сравниваем со всеми точками от
мы сравниваем со всеми точками от  до
до  .
.
В итоге мы проверили все точки от
до (то есть все возможные точки), выполнив не более  сложений и умножений (ровно для «детских шагов», не более для «великанских шагов»).
сложений и умножений (ровно для «детских шагов», не более для «великанских шагов»).Если считать, что поиск в хеш-таблице занимает время
то легко увидеть, что этот алгоритм имеет временную и пространственную сложность  (или
(или  , если учесть битовую длину). Это всё ещё экспоненциальное время, но оно намного лучше, чем при атаке перебором.
, если учесть битовую длину). Это всё ещё экспоненциальное время, но оно намного лучше, чем при атаке перебором.Baby-step giant-step на практике
Имеет смысл разобраться, что же значит сложность
на практике. Возьмём стандартизированную кривую: prime192v1 (она же secp192r1, ansiX9p192r1). Эта кривая имеет порядок = 0xffffffff ffffffff ffffffff 99def836 146bc9b1 b4d22831. Квадратный корень из — это примерно 7,922816251426434 · 1028 (почти восемьдесят октиллионов [прим. пер.: по короткой шкале]).Представим, что мы храним
 точек в хеш-таблице. Предположим, что каждая точка занимает ровно 32 байта: для хеш-таблицы потребуется примерно 2,5 · 1030 байт памяти. Поискав в Интернете, можно узнать, что современная общая ёмкость накопителей всего мира имеет порядок зеттабайта (1021 байт). Это почти на десять порядков меньше, чем объём памяти, необходимый нашей хеш-таблице! Даже если бы точки занимали по 1 байт каждая, мы всё равно не смогли бы хранить их все.
точек в хеш-таблице. Предположим, что каждая точка занимает ровно 32 байта: для хеш-таблицы потребуется примерно 2,5 · 1030 байт памяти. Поискав в Интернете, можно узнать, что современная общая ёмкость накопителей всего мира имеет порядок зеттабайта (1021 байт). Это почти на десять порядков меньше, чем объём памяти, необходимый нашей хеш-таблице! Даже если бы точки занимали по 1 байт каждая, мы всё равно не смогли бы хранить их все.Это впечатляет, и впечатляет ещё сильнее, если вспомнить, что
prime192v1 — это одна из кривых с наименьшим порядком. Порядок secp521r1 (ещё одной стандартной кривой NIST) равен примерно 6,9 · 10156!Эксперименты с baby-step giant-step
Я написал скрипт на Python, вычисляющий дискретные логарифмы с помощью алгоритма baby-step giant-step. Очевидно, что он работает только с кривыми малого порядка: не пытайтесь использовать
secp521r1, если только не хотите получить MemoryError.Скрипт выдаёт примерно такие выходные данные:
Curve: y^2 = (x^3 + 1x - 1) mod 10177 Curve order: 10331 p = (0x1, 0x1) q = (0x1a28, 0x8fb) 325 * p = q log(p, q) = 325 Took 105 steps
ρ Полларда
ρ Полларда — это ещё один алгоритм вычисления дискретных логарифмов. Он имеет ту же асимптотическую временную сложность
, что и baby-step giant-step, но его пространственная сложность равна всего . Если baby-step giant-step не мог решить дискретные логарифмы из-за огромных требований к памяти, может быть, ρ Полларда справится? Давайте проверим…Для начала ещё раз напомню задачу дискретного логарифмирования: найти для заданных
и целое , такое, что . В ρ-алгоритме Полларда мы будем решать немного другую задачу: найти для заданных и целые , ,  и
и  , такие, что
, такие, что  .
.Найдя четыре целых числа, мы сможем использовать уравнение
для вычисления :
Теперь мы можем избавиться от
. Но прежде чем сделать это, вспомним, что наша подгруппа циклическая и имеет порядок , то есть коэффициенты, используемые при умножении точек, берутся по модулю :
Принцип работы ρ Полларда прост: мы определяем псевдослучайную последовательность пар
 . Эту последовательность пар можно использовать для генерирования последовательности точек
. Эту последовательность пар можно использовать для генерирования последовательности точек  . Поскольку и являются элементами одной циклической подгруппы, последовательность точек тоже циклическая.
. Поскольку и являются элементами одной циклической подгруппы, последовательность точек тоже циклическая.Это значит, что если мы обойдём нашу псевдослучайную последовательность пар
, то рано или поздно обнаружим цикл. То есть: мы найдём пару и другую отдельную пару  , такие, что . Те же точки, отдельные пары: мы сможем применить приведённое выше уравнение для нахождения логарифма.
, такие, что . Те же точки, отдельные пары: мы сможем применить приведённое выше уравнение для нахождения логарифма.Задача заключается в следующем: как обнаружить цикл эффективным способом?
Черепаха и заяц
Для обнаружения цикла мы можем проверить все возможные значения
и с помощью функции пересчёта пар, но при условии, что существует  таких пар, алгоритм будет иметь сложность
таких пар, алгоритм будет иметь сложность  , что намного хуже атаки простым перебором.
, что намного хуже атаки простым перебором.Но существует и более быстрый способ: алгоритм черепахи и зайца (также известный как алгоритм нахождения цикла Флойда). На рисунке ниже показан принцип работы метода черепахи и зайца, на котором основан ρ-алгоритм Полларда.

У нас есть кривая
и точки и  . Точки принадлежат циклической подгруппе с порядком 5. Мы обходим последовательность пар с разными скоростями, пока не находим две разные пары и , дающих одну точку. В этом случае мы нашли пары
. Точки принадлежат циклической подгруппе с порядком 5. Мы обходим последовательность пар с разными скоростями, пока не находим две разные пары и , дающих одну точку. В этом случае мы нашли пары  и
и  , что позволяет нам вычислить логарифм как
, что позволяет нам вычислить логарифм как  . И на самом деле, у нас получилось
. И на самом деле, у нас получилось  .
.В сущности, мы берём псевдослучайную последовательность пар
вместе с соответствующей последовательностью точек . Последовательность пар может быть или не быть циклической, но последовательность точек точно циклическая, потому что и сгенерированы из одной базовой точки, а из свойство подгрупп мы знаем, что не можем «сбежать» из подгруппы только скалярным умножением и сложением.Теперь мы берём двух животных, черепаху и зайца, и заставляем обходить последовательность слева направо. Черепаха (зелёная точка на изображении) медленная и считывает каждую точку, одну за другой; заяц (красная точка) быстр и пропускает точку на каждом шаге.
Через какое-то время черепаха и заяц найдут одну точку, но с разными парами коэффициентов. Или, если выразить это уравнениями, черепаха найдёт пару
, а заяц — пару , такие, что .Если случайная последовательность определяется через алгоритм (а не хранится статически), легко увидеть, что принцип работы требует всего
пространства. Вычисление сложности асимптотического времени не так просто, но мы можем построить вероятностное доказательство, показывающее, что временная сложность равна  ), как мы уже говорили.
), как мы уже говорили.Экспериментируем с ρ Полларда
Я создал скрипт на Python, вычисляющий дискретные логарифмы с помощью ρ-алгоритма Полларда. Это не реализация исходного ρ Полларда, а небольшая его вариация (я использовал более эффективный способ генерирования псевдослучайной последовательности пар). В скрипте есть полезные комментарии, так что прочитайте его, если вам интересны подробности алгоритма.
Этот скрипт, как и baby-step giant-step, работает для маленьких кривых и создаёт те же выходные данные.
Ро Полларда на практике
Мы говорили, что baby-step giant-step невозможно использовать на практике из-за огромных требований к памяти. С другой стороны, ро-алгоритм Полларда требует очень мало памяти. Насколько же он практичен?
В 1998 году Certicom начала соревнование по вычислению дискретных логарифмов на эллиптических кривых с битовой длиной от 109 до 369. На сегодняшний день успешно взломаны только кривые длиной 109 бит. Последняя успешная попытка была совершена в 2004 году. Процитируем Википедию:
Награда была вручена 8 апреля 2004 года примерно 2600 людям, которых представлял Крис Монико. Они тоже использовали разновидность распараллеленного ро-алгоритма Полларда, вычисления по которому заняли 17 месяцев календарного времени.
Как мы уже сказали,
prime192v1 — это одна из «наименьших» эллиптических кривых. Мы также сказали, что ρ Полларда имеет временную сложность . Если бы мы использовали ту же технику, что и Крис Монико (тот же алгоритм, то же оборудование и количество машин), сколько бы заняло вычисление логарифма для prime192v1?
Полученный результат говорит сам за себя и даёт чётко понять, насколько сложно взломать дискретный логарифм с помощью таких техник.
Сравниние ρ Полларда и Baby-step giant-step
Я решил объединить скрипт baby-step giant-step, скрипт ро Полларда и скрипт перебора в четвёртый скрипт для сравнения их производительности.
Этот четвёртый скрипт вычисляет все логарифмы для всех точек на «маленькой» кривой с помощью разных алгоритмов и сообщает, сколько времени это заняло:
Curve order: 10331 Using bruteforce Computing all logarithms: 100.00% done Took 2m 31s (5193 steps on average) Using babygiantstep Computing all logarithms: 100.00% done Took 0m 6s (152 steps on average) Using pollardsrho Computing all logarithms: 100.00% done Took 0m 21s (138 steps on average)
Как и можно ожидать, метод перебора чудовищно медленный по сравнению с двумя другими. Baby-step giant-step быстрее, а ро-алгоритм Полларда больше чем в три раза медленнее baby-step giant-step (хоть он и использует гораздо меньше памяти и меньшее количество шагов в среднем).
Посмотрите ещё и на количество шагов: для вычисления каждого логарифма способом перебора в среднем потребовалось 5193 шагов. 5193 очень близко к 10331 / 2 (половина порядка кривой). Baby-step giant-steps и ро Полларда использовали 152 шага и 138 шагов соответственно. Эти два числа очень близки к квадратному корню 10331 (101,64).
Дальнейшие рассуждения
В обсуждении этих алгоритмов я использовал много чисел. При их чтении важно быть внимательным: алгоритмы во многих аспектах можно сильно оптимизировать. Оборудование может улучшаться. Можно создать специализированное оборудование.
Если сегодня подход кажется непрактичным, это не значит, что его нельзя улучшить. Это также не значит, что нет других, более хороших подходов (не забывайте, что у нас нет доказательств сложности задачи дискретного логарифмирования).
Алгоритм Шора
Если современные техники неприменимы, то как насчёт техник ближайшего будущего? Ситуация вызывает всё больше беспокойства: уже существует квантовый алгоритм, способный вычислять дискретные логарифмы за полиномиальное время: алгоритм Шора со временной сложностью
 и пространственной сложностью .
и пространственной сложностью .Эффективность квантовых алгоритмов заключается в суперпозиции состояния. У классических компьютеров ячейки памяти (т.е. биты) могут иметь значение 1 или 0. Между ними нет промежуточных состояний. С другой стороны, ячейки памяти квантовых компьютеров (кубиты) подвержены принципу неопределённости: пока их не измерят, у них нет полностью определённого состояния. Суперпозиция состояния не значит, что каждый кубит может одновременно иметь значение 0 и 1 (как часто пишут в Интернете). Она значит, что при измерении кубита у нас есть определённая вероятность наблюдать 0 и другая вероятность наблюдать 1. Работа квантовых алгоритмов заключается в изменении вероятности каждого кубита.
Эта странность означает, что с ограниченным количеством кубитов мы можем одновременно иметь дело со множеством возможных входных данных одновременно. Например, мы можем сказать квантовому компьютеру, что существует число
, равномерно распределённое между 0 и  . При этом требуется всего
. При этом требуется всего  кубитов вместо
кубитов вместо  бит. Затем мы можем приказать квантовому компьютеру выполнить скалярное умножение . В результате мы получим суперпозицию состояний, заданную всеми точками от до
бит. Затем мы можем приказать квантовому компьютеру выполнить скалярное умножение . В результате мы получим суперпозицию состояний, заданную всеми точками от до  , то есть если мы теперь измерим все кубиты, то получим одну из точек от до с вероятностью
, то есть если мы теперь измерим все кубиты, то получим одну из точек от до с вероятностью  .
.Я рассказал об этом, чтобы вы поняли всю мощь суперпозиции состояний. Алгоритм Шора работает не совсем так, на самом деле он более сложен. Его усложняет то, что хотя мы и можем «симулировать»
состояний одновременно, на каком-то этапе нам придётся снизить это количество состояний до нескольких, потому что на выходе нам нужно одно число, а не несколько (т.е., нам нужно знать один логарифм, а не множество вероятно ошибочных логарифмов).ECC и RSA
Теперь давайте забудем о квантовых вычислениях, которые пока ещё не стали серьёзной проблемой. Я хочу ответить на следующий вопрос: зачем возиться с эллиптическими кривыми, если RSA и так работает хорошо?
Простой ответ дал NIST, представив таблицу сравнения размеров ключей RSA и ECC, необходимых для получения одинакового уровня защиты.
| Размер ключа RSA (биты) | Размер ключа ECC (биты) |
|---|---|
| 1024 | 160 |
| 2048 | 224 |
| 3072 | 256 |
| 7680 | 384 |
| 15360 | 521 |
Заметьте, что линейной связи между размерами ключей RSA и ECC нет (другими словами: если мы удваиваем размер ключа RSA, нам не нужно удваивать размер ключа ECC). Таблица говорит нам, что ECC не только использует меньше памяти, но и генерирование ключей с подписыванием в ней гораздо быстрее.
Но почему это так? Ответ заключается в том, что самые быстрые алгоритмы для вычисления дискретных алгоритмов над эллиптическими кривыми — это ρ-алгоритм Полларда и baby-step giant-step, а в случае RSA есть более быстрые алгоритмы. В частности, один из них — это общий метод решета числового поля: алгоритм для факторизации целых чисел, который можно использовать для вычисления дискретных логарифмов. Общий метод решета числового поля — это на сегодняшний день самый быстрый алгоритм для факторизации целых чисел.
Всё это относится и к другим криптосистемам, основанным на модулярной арифметике, в том числе к DSA, Диффи-Хеллману и Эль-Гамалю.
Скрытые угрозы АНБ
А теперь перейдём к сложной части. До этого момента мы обсуждали алгоритмы и математику. Настало время обсудить людей, и всё становится сложнее.
Если вы помните, в третьей части мы говорили, что некоторые классы эллиптических кривых являются слабыми, поэтому для решения проблемы получения надёжных кривых от сомнительных источников мы добавляем случайное порождающее значение (seed) к параметрам области определения. И если посмотреть на стандартные кривые NIST, можно увидеть, что они проверяемо случайны.
Если прочитать страницу Википедии о принципе "в рукавах ничего нет", можно заметить, что:
- Случайные числа для MD5 получаются из синуса целых чисел.
- Случайные числа для Blowfish получаются из первых чисел
 .
. - Случайные числа для RC5 получаются из
 и золотого сечения.
и золотого сечения.
Эти числа случайны, потому что их цифры распределены равномерно. И они не вызывают подозрений, потому что имеют обоснование.
Теперь возникает следующий вопрос: откуда берутся случайные порождающие значения для кривых NIST? Ответ: к сожалению, мы не знаем. Эти значения не имеют никакого обоснования.
Возможно ли, что NIST обнаружил «значительно большой» класс слабых эллиптических кривых, попробовал различные возможные варианты порождающих значений и нашёл уязвимую кривую? Я не могу ответить на этот вопрос, но это закономерный и важный вопрос. Мы знаем, что NIST как минимум успешно стандартизировал уязвимый генератор случайных чисел (генератор, который, как ни странно, основан на эллиптических кривых). Возможно, он успешно стандартизировал и множество слабых эллиптических кривых? Как это проверить? Да никак.
Важно понимать, что «проверяемо случайный» и «защищённый» не являются синонимами. И неважно, насколько сложна задача логарифмирования или насколько длинны ключи — если алгоритмы взломаны, то мы ничего не можем поделать.
В этом отношении RSA побеждает, потому что ей не требуются специальные параметры области определения, которые можно эксплуатировать. RSA (как и другие системы модулярной арифметики) может быть хорошей альтернативой, если мы не можем доверять властям и если мы не можем создать собственные параметры области определения. И если вам любопытно: да, TLS может использовать кривые NIST. Если вы проверите в google, то увидите, что при подключении используются ECDHE и ECDSA с сертификатом, основанным на
prime256v1 (она же secp256p1).Вот и всё!
Надеюсь, вам понравилась эта статья. Я стремился познакомить вас с основной информацией, терминологией и допущениями, необходимыми для понимания текущего состояния криптографии на эллиптических кривых. Если мне это удалось, то теперь вы сможете разобраться с существующими криптосистемами на базе ECC и расширить свои знания чтением более глубокой документации. При написании статьи я пропустил очень многие подробности и использовал упрощённую терминологию, но я чувствовал, что в противном случае вы бы не поняли информацию, изложенную в Интернете. Я считаю, что мне удалось найти хороший компромисс между простотой и полнотой информации.
Стоит однако заметить, что прочитав только эту статью, вы не сможете реализовать защищённые криптосистемы на основе ECC: обеспечение безопасности требует знания многих тонких, но важных подробностей. Вспомните требования к атаке Смарта и ошибку Sony — это два примера того, как можно создать небезопасные алгоритмы и как легко их можно эксплуатировать.
Итак, если вам интересно глубже погрузиться в мир ECC, то с чего же начать?
Во-первых, пока мы видели кривые Вейерштрасса над простыми полями, но вы должны знать, что существуют и другие виды кривых и полей, а именно:
- Кривые Коблица над двоичными полями. Это эллиптические кривые в форме
 (где — 0 или 1) над конечными полями, содержащими
(где — 0 или 1) над конечными полями, содержащими  элементов (где — простое число). Они обеспечивают особо эффективное сложение точек и скалярное умножение.
элементов (где — простое число). Они обеспечивают особо эффективное сложение точек и скалярное умножение.
Примерами стандартизированных кривых Коблица являютсяnistk163,nistk283иnistk571(три кривые, определённые над полем из 163, 283 и 571 бит). - Двоичные кривые. Они очень похожи на кривые Коблица и имеют форму
 (где — целое число, часто генерируемое из случайного порождающего значения). Как подсказывает название, двоичные кривые ограничены только двоичными полями. Примерами стандартизированных кривых являются
(где — целое число, часто генерируемое из случайного порождающего значения). Как подсказывает название, двоичные кривые ограничены только двоичными полями. Примерами стандартизированных кривых являются nistb163,nistb283иnistb571.
Надо сказать, что возникает всё больше подозрений в том, что кривые Коблица и двоичные кривые могут быть не так безопасны, как простые кривые. - Кривые Эдвардса имеют вид
 (где — это 0 или 1). Они особенно интересны не только потому, что для них быстро выполняются сложение точек и скалярное умножение, но и потому, что формула сложения точек всегда одинакова, в любом случае (, , , ...). Эта особенность снижает возможность атак по сторонним каналам (side-channel attack), при которых атакующий измеряет время, использованное для скалярного умножения, и пытается подобрать скалярный коэффициент на основании времени для его вычисления.
(где — это 0 или 1). Они особенно интересны не только потому, что для них быстро выполняются сложение точек и скалярное умножение, но и потому, что формула сложения точек всегда одинакова, в любом случае (, , , ...). Эта особенность снижает возможность атак по сторонним каналам (side-channel attack), при которых атакующий измеряет время, использованное для скалярного умножения, и пытается подобрать скалярный коэффициент на основании времени для его вычисления.
Кривые Эдвардса относительно новы (впервые они были представлены в 2007 году), поэтому ни один орган, такой как Certicom или NIST, пока не стандартизировал ни одну из них. - Curve25519 и Ed25519 — это две специальные эллиптические кривые, созданные для ECDH и варианта ECDSA соответственно. Как и кривые Эдвардса, эти две кривые быстры и помогают защищаться от атак по сторонним каналам. Как и кривые Эдвардса, эти две кривые не были пока стандартизированы и не используются в популярном ПО (за исключением OpenSSH, который поддерживает пары ключей Ed25519 с 2014 года).
Если вам интересны подробности реализации ECC, предлагаю вам почитать исходники OpenSSL и GnuTLS.
И наконец, если вам интересны математические подробности, а не безопасность и эффективность алгоритмов, то нужно знать следующее:
- Эллиптические кривые — это алгебраические многообразия рода 1.
- Бесконечно удалённые точки изучаются в проективной геометрии. Они могут быть представлены с помощью однородных координат (хотя большинство из свойств проективной геометрии не нужны для криптографии на эллиптических кривых).
И не забудьте изучить конечные поля вместе с теорией полей.
Если вас интересует эта тема, то стоит искать по таким ключевым словам.
На этом статья официально заканчивается. Благодарю за все дружественные комментарии, твиты и письма. Многие спрашивали, буду ли я писать другие статьи о близких темах. Мой ответ: возможно. Можете присылать свои предложения, но ничего не обещаю.

