Приветствую коллеги! Пришло время продолжить наш спонтанный мини цикл статей, посвящённый основам машинного обучения и анализа данных.
В прошлый раз мы разбирали с Вами задачку применения линейной регрессии к открытым данным правительства Москвы, а в этот раз данные тоже открыты, но их уже пришлось собирать вручную.
Итак, сегодня мы с Вами поднимем животрепещущую тему – обращения граждан в органы исполнительной власти Москвы, нас с вами сегодня ждет: краткое описание набора данных, примитивный анализ данных, применение к ним модели линейной регрессии, а также краткая отсылка к учебным курсам для тех, кто совсем ничего не поймет из материала статьи. Ну и конечно же останется пространство для самостоятельного творчества.
Напомню, что наша статья рассчитана в первую очередь на начинающих любителей Python и его распространённых библиотек из области DataScience. Готовы? Тогда, милости прошу под кат.

UPD 07.01.17: Внимание в данные проекта на GitHub было добавлено два месяца, поэтому результаты немного изменились. Статья была написана для версии 1.0 доступной в истории проекта на GitHub
Для начала как обычно буквально два слова о необходимом уровне подготовки.
Данный материал будет вполне понятен людям, которые прочитали любой популярный самоучитель по машинному обучению и анализу данных с помощью Python, или прошли более-менее вменяемый on-line курс. Если совсем не знаете с чего начать можно сразу перейти в конец статьи или же почитать материалы из первой части цикла:
Наша статья будет состоять из следующих разделов:
В этот раз, пожалуй, обойдемся без стилизации заголовков.
Чтобы не тратить в пустую время сразу скажу, что как всегда набор данных, а также Jupyter Notebook notebook (Python 3) с примером выложены на GiTHub
Если чувствуете в себе силы можете сразу экспериментировать. Ну а мы продолжим.
Данные для набора взяты с Официального портала Мэра и Правительства Москвы, данные публичны и при указании ссылки вполне доступны к свободной обработке. Правда в отличии от данных которые есть на портале открытых данных правительства Москвы, эти сведения представлены в неудобном к машинной обработке формате. (Если кто-то напишет скрипт для автоматизированного сбора и похвастается нам – честь и хвала).
Данные пришлось собирать руками, причем насколько они правдоподобны мы оставим на совести разработчиков, отмечу только две вещи в одном из месяцев небыли проставлены цифры на диаграмме (пришлось на глазок), а в другом месяце один из столбцов диаграммы выглядит подозрительно, но даже если там есть какие-то недочеты, нам с вами это не помешает.
В исходном виде данные содержат следующие столбцы:
Период сбора данных начинается c 01.2016 и заканчивается 08.2017 (на текущий момент), таким образом столбцов всего получается 32, а строк всего 20. Данные представлены в виде .csv файла, разделитель – знак табуляции.
В принципе в исходных данных на портале Мэра есть некоторая аналитика данных (например, нарастающие итоги), те вещи, которые есть там мы – повторять не будем. Да и вообще поскольку статья рассчитана на начинающих, а сам я тоже из их числа, то в целях демонстрации мы намерено будем упрощать все решения, которые нам встретятся.
Поэтому сразу оговорюсь наша цель не идеально предсказать, что-либо, а просто потренироваться. Опытные читатели могут поделиться своей мудростью в комментариях, за что мы им будем благодарны.
Для анализа мы будем использовать Jupyter Notebook (Python 3) и как обычно, целиком код «записной книжки» выложен на GiTHub.
Пристегните ремни мы отправляемся в приключение по волнам бюрократии.
Загрузим необходимые библиотеки:
Затем прочитаем данные посмотрим на нашу таблицу
Вот такие данные получили за первый год.

К сожалению, целиком табличка не влезла, чтобы вы себе это представляли, после многоточия идут аналогичные столбцы по другим округам Москвы.
Давайте теперь посмотрим есть ли какая-либо линейная корреляция между первыми семью столбцами таблицы (без учета индекса).
Вы конечно можете проверить и больше, но нам хватит и этого, как раз умещается на экране.
В первой строке мы определили набор столбцов, которые будем извлекать из нашей таблицы (он нам еще пригодится в будущем).
Затем с помощью библиотеки seaborn построили диаграмму (если ваш ПК в процессе задумался, не переживайте это нормально).
Ну а последняя строка — это сохранение нашей картинки в файл, в той же папке, что и notebook, вы можете ее удалить, а мне она нужна чтобы было проще подготовить вам статью.
В результате получим вот такую красоту:
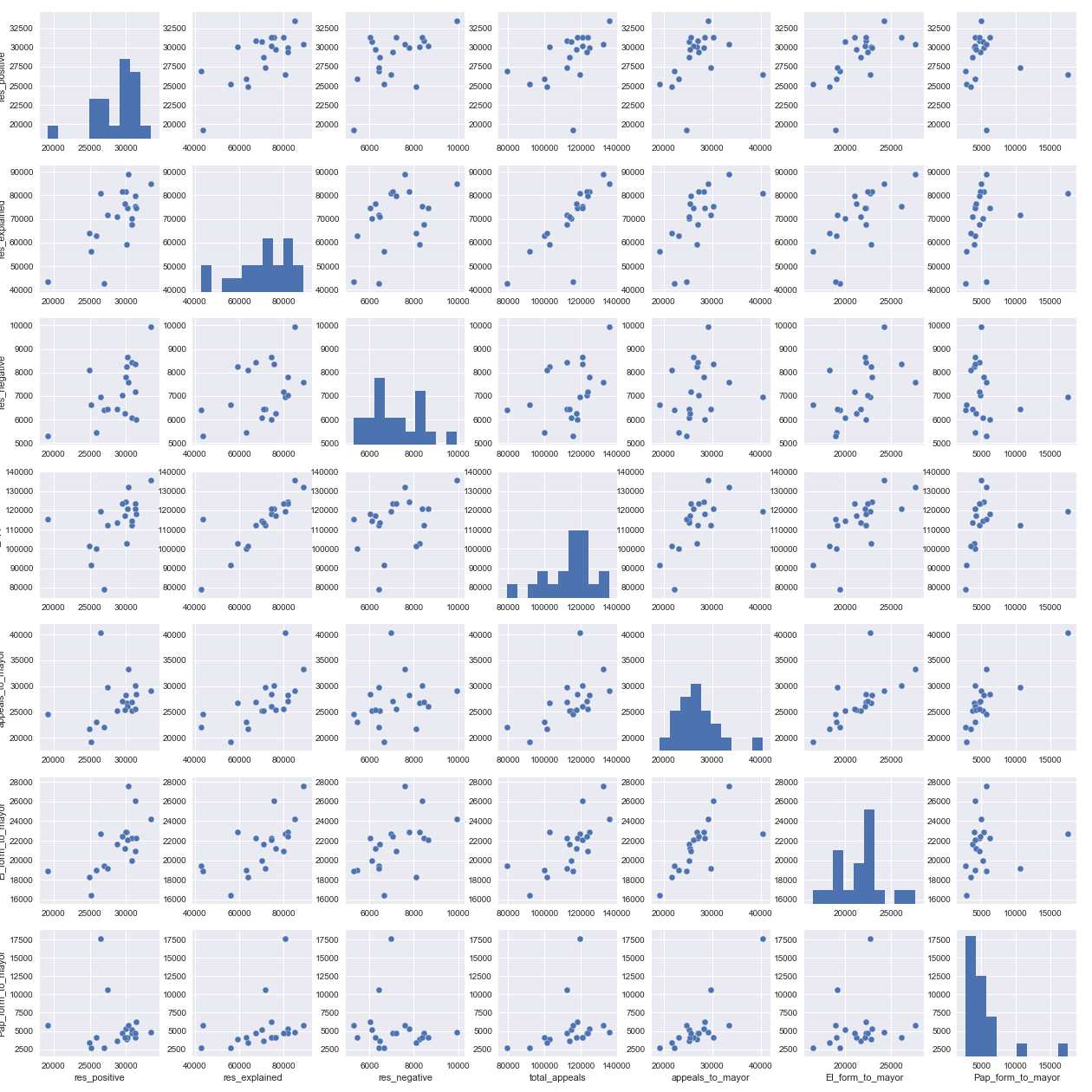
Что же мы видим, на диаграмме? Например, то что на пересечении количества «разъясненных» обращений и общего количества обращений, точки выстроились практически в ровную линию, давайте убедимся в этом, посмотрев численное значение коэффициента корреляции.
В первой строчке с помощью встроенного в Pandas Data Frame метода corr, мы как раз вычислили корреляцию между этими двумя столбцами. Корреляция оказалась достаточно высокая, но это очевидно, в большинстве случаев как говорится «находит коса на камень», так что с одной стороны обращения не всегда – грамотные, а с другой стороны любой бюрократический аппарат в большинстве случаев в первую очередь постарается вам «отписаться». Поэтому неудивительно, что разъяснённых обращений больше всего, ну и как следствие неудивительно, что чем больше обращений, тем больше разъяснительных ответов на них. Именно об этом нам и говорит коэффициент корреляции 0.83
Во второй строчке кода мы посмотрели вторую пару – общее обращений в адрес мэра и количество обращений, направленных ему в электронной форме. Тут также прослеживается зависимость и если бы не явные выбросы (которые вполне могут как ошибками в данных, так и нетипичным поведением горожан), то наверняка коэффициент корреляции мог бы быть еще ближе к единице.
В оригинальных данных есть диаграммы активности населения в разрезе округов Москвы отражающие количество обращений граждан на 10 тысяч жителей. Выглядит это примерно так:

Мы с вами посчитаем тоже самое, но суммарно за весь период.
Для начала выбреем нужные нам столбцы, мы оставим вам на самостоятельное изучение манипуляции с обращениями в адрес непосредственно мэра и сосредоточимся, на общем количестве обращений.
Затем сократим названия наших полей до названий округов и построим столбчатую диаграмму.

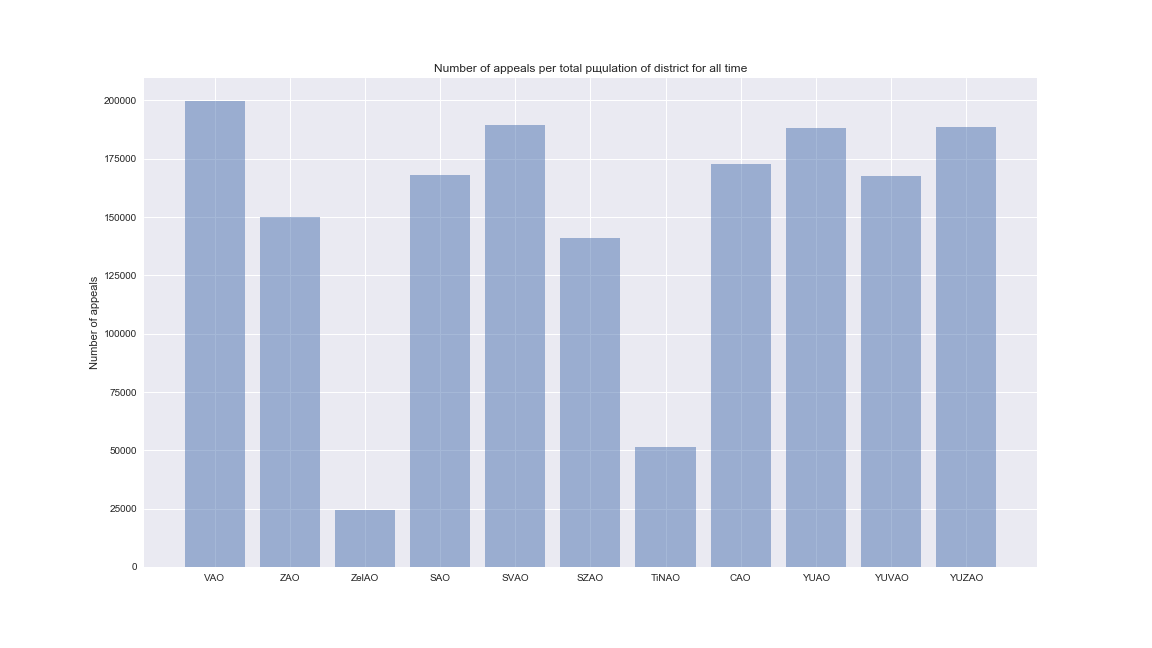
Что нам показывает диаграмма? То, что самый расстроенный округ это центральный. И вы знаете это скорей всего не потому, что люди там «с жиру бесятся». Есть у меня одна мыслишка…
Переходим на сайт программы «Моя улица» и чисто ради любопытства смотрим, где проводились работы в 2017 г.

Подавляющее большинство работ проводилось в ЦАО, я не думаю, что это единственная причина такого большого количества обращений на душу населения, но вполне возможно, что одна из.
Ну что же вот мы с вами и подошли к мысли, о том, что наш набор сам по себе «скучный» и мало, что объясняет. Давайте расширим его данными из глобальной сети.
Мы с вами рассмотрим только два простеньких случая, а дальше перед вами открыта полная свобода творчества.
Для начала переведем данные с прошлого графика из масштаба 1 обращение на 10000 тысяч человек, в полное количество обращений. Для того, чтобы выполнить обратный перевод, нам понадобится знать количество людей, проживающее во всех округах. В этом нам поможет Википедия из которой мы скопируем данные в ручную.
Число людей в district_population идет в том же порядке, что и наши столбцы в district_columns (см выше). Получим следующую диаграмму.
Где это применить? Сложно сказать, данных явно недостаточно, но можно копать в сторону более равномерного распределение трудовой нагрузки на специалистов районных управ отвечающих за обращения граждан.
Теперь давайте немного усложним задачу и попробуем забрать какие-нибудь данные автоматически. К счастью, на Python есть достойные библиотеки, которые нам могут в этом помочь. Мы выберем одну из весьма популярных Beautifulsoup.
Давайте разберемся, что все это значило. Если вы перейдете на страничку с исходными данными, то увидите, что в качестве источника данных для примера я выбрал очень простой случай. На странице есть таблица, у которой три колонки.
Третья колонка нас не интересует, но вы для себя можете реализовать и её обработку.
Взглянув на код таблицы мы поймем, что она имеет класс .item-description, получим весь код таблицы, затем просто в цикле обрабатываем каждую строчку таблицы, запихивая данные в словарь, где ключ это дата, а значение – цена на нефть. OrderedDict – мы выбрали для того, чтобы быть уверенными, что данные в словаре будут представлены именно в том порядке, в котором мы их считали.
Этот кусок кода, нам нужен в первую очередь, чтобы обеспечить работоспособность примера, в случае если страница исходных данных сильно изменится (или и вовсе пропадет). В таком случае будет достаточно разкомментировать строки, после чего код ниже позволит нам и дальше работать с примером, как ни в чем не бывало.
Осталось только создать в таблице столбец, в который мы добавим нашу цену на нефть и убедится, в том, что все вышло, как и планировали.
Как вы уже догадались мы не просто так добавляли цену на нефть, давайте посмотрим есть ли какая-нибудь корреляция между новым столбцом и парочкой старых.
Если честно не могу объяснить, как связана цена на нефть и общее количество обращений, думаю, что наличие хоть какой-то корреляции во многом случайность.
А вот отсутствие корреляции между числом положительных ответов и ценой на нефть объяснить можно. Бедные рядовые специалисты в управах, ГУПах (в которые наверняка часть обращений спускается), в департаментах правительства Москвы и других причастных подразделениях, наверняка в первую очередь думают, как бы дожить от аванса до получки и на себе ежемесячные колебания цен на нефть не сильно ощущают. А значит не становятся от роста цен на нефть добрее, и соответственно положительная динамика цен на нефть не вызывает у людей желания «разбиться в лепешку», чтобы у вас во дворе покрасили скамейку.
Я думаю вы сможете придумать еще кучу «безумных» комбинаций для анализа – дерзайте! А мы между тем перейдём к обещанной ранее линейной регрессии.
Еще раз повторюсь, что в сети в целом, да и на Хабре в частности полно достойных материалов про линейную регрессию, поэтому мы не будем усложнять и рассмотрим лишь пару простеньких примеров для демонстрации.
Начнем мы с подготовки данных и первое что сделаем это перекодируем нашу категориальную переменную «месяц» в ее числовой аналог, получим 12 новых признаков, код и таблица будут выглядеть будет вот так.
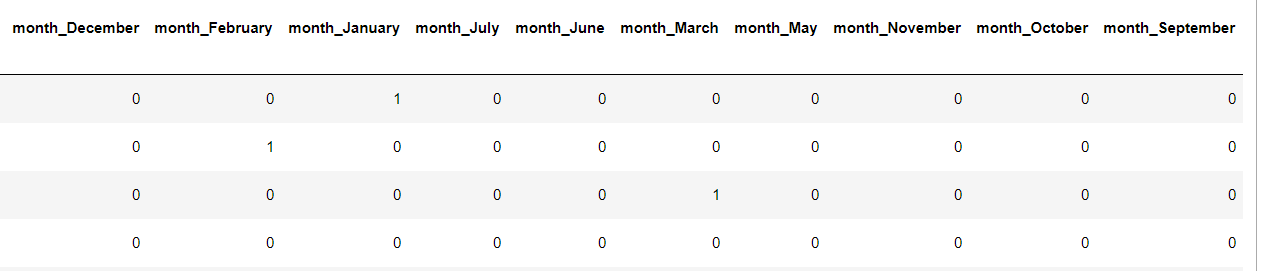
Так, например, 1 в столбце month_May значит, что раньше в этой строке как раз был месяц май
Идем дальше.
В первой части кода мы создаем соответствие названий месяцев и их порядковым номерам, затем поскольку pd.get_dummies удалил нашу исходную колонку «месяц», мы позаимствуем её из старой таблицы (df).
Во второй части кода мы склеиваем и помещаем в список строковые данные из столбца год, из переменной месяц и на всякий случай первое число каждого месяца (хотя думаю без этого можно было обойтись).
В третей части мы переименовываем столбец «год», и заменяем данные в нем на данные типа datetime, которые извлекаются из нашего списка в соответствии с шаблоном '%Y %m %d' (ГОД номер месяца день месяца).
Получим следующий результат:

Правда месяца нам сейчас не нужны, но потом пригодятся.
А пока, продолжим готовить данные для нашей модели линейной регрессии
В начале мы определили какие столбцы будем выбирать из таблицы в качестве признаков (х), а какой в качестве целевой функции (у) Также мы выкинули оттуда столбец ‘total_appeals', не то чтобы он нам сильно не нравился, но он избыточен, его можно получить комбинацией трех других столбцов.
После того как мы определились с данными, мы их на всякий случай масштабируем, в принципе это можно не делать, для данного случая будет не смертельно, гребневая регрессия могла бы нам в некотором роде помочь с их уравниванием, но так всяко удобней и лучше.
Для начала посмотрим, как почти все столбцы кроме месяцев и цен на нефть, помогают нам определить количество одобренных обращений
Обратите внимание в этот раз мы не только поделили нашу выборку на тренировочную и контрольную с помощью функции train_test_split, но еще и на базе тренировочной выборки провели оценку качества работы модели по кросс-валидации. Поскольку данных очень мало мы проводили кросс-валидацию по следующему принципу, в каждом разбиение берется 1 образец как контрольный, а на остальных производится обучение, результаты предсказания – усредняются. Эта оценка не является панацеей, но учитывая, то что у нас контрольная выборка состоит всего из четырех точек, то она является более надежной оценкой качества.
Вы можете ради любопытства побаловаться с коэффициентом регуляризации альфа и посмотреть, как будет скакать оценка по контрольной выборке и кросс-валидации или можете просто побаловаться параметром random-state в train_test_split и увидеть, как скачет качество предсказаний.
Рас уж речь зашла о коэффициенте регуляризации, в отличии от прошлой статьи где мы использовали L1 (lasso) регуляризацию, L2 (Ridge) регуляризация не может полностью удалить малополезные признаки, но сильно снижает их вес за счет коэффициентов. У нас мало данных и похоже, что в данном случае модель лучше работает с большим коэффициентом регуляризации, не так сильно в итоге переобучаясь.
Что значат эти цифры? Хорошо это или плохо? Это мы поймем, чуть позже, а пока давайте проделаем все тоже самое, но добавим в качестве исходного признака еще и нефть.
Как видим на контрольной выборке все изменилось в лучшую сторону, а вот на кросс-валидации не особо. В данном случае будем верить именно ей.
Так как трактовать эти данные. Напомню, что наш коэффициент среднеквадратичной ошибки (отклонения), получается на основании тех данных, что есть, если бы мы их не масштабировали его значение было бы больше. Лучше всего понять, как наша модель предсказывает контрольные данные это построить график.
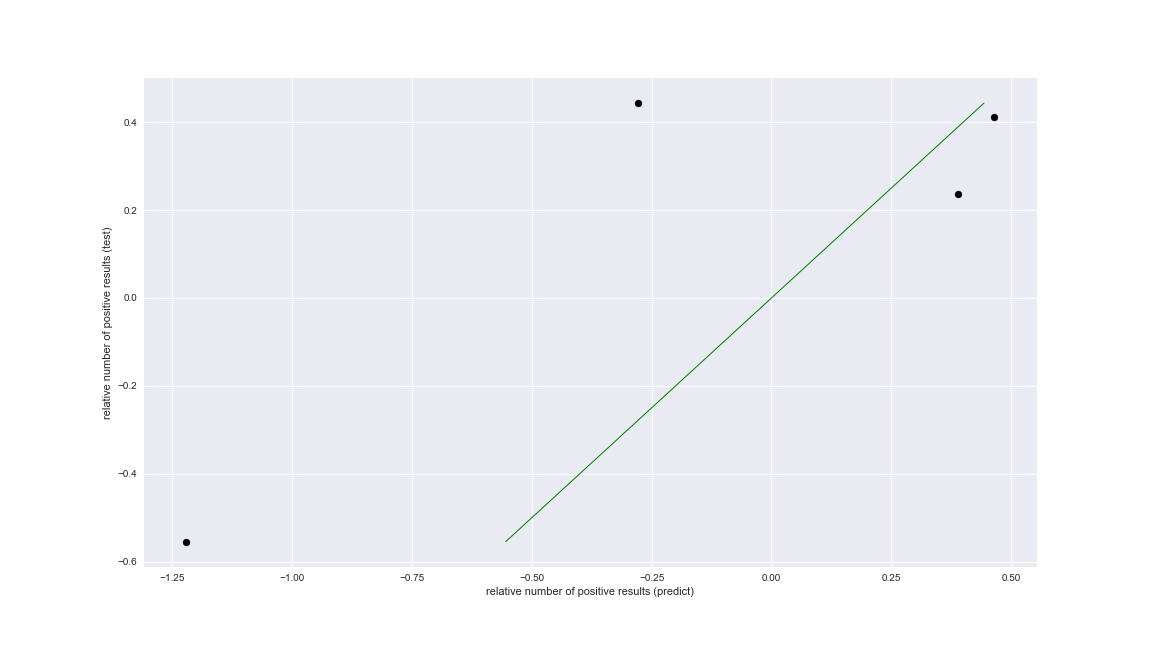
Ну вот теперь, мы явно видим насколько предсказанные значения отличаются, от тех, что должны быть. Для тех, кто не догадался, поясню, что в идеальном случае все точки (предсказанные значения), должны были бы оказаться на зеленой линии (это легко проверить заменив в scatter plot lr.predict(X_test) на y_test.
Как видите наша модель не идеальна, но чего еще ждать, коэффициент регуляризации мы подобрали на глазок, специально признаки не отбирали, а самих данных кот наплакал.
Но не буем грустить, а лучше соберемся с силами и сделаем последний рывок.
До этого момента, мы с вами брали для контроля случайные точки, куда как логичней было бы проверить, может ли наша модель по имеющимся данным в будущем предсказывать количество положительных результатов рассмотрения. Мы же ведь не просто так делали столбец с датой в таблице.
Я напомню, что мы пока в нашем анализе нигде не использовали данные по месяцам. Не использовали и сейчас не будем! Для начала посмотрим, как поведет себя в других условиях наша прошлая модель с ценами на нефть.

На рассмотренных в другом ключе данных модель себя показывает еще немного хуже, возможно дело в том числе и в коэффициенте регуляризации, чтобы было нагляднее я его взял таким же, как и для следующего примера (равным 7).
Ну что же все, что нам осталось это наконец-то отказаться от нефти и ввести наши закодированные признаки месяца.

Невооруженным глазом видно, что с учетом фактора месяца, модель лучше описывает наши данные. Хотя думаю, с точки зрения качества предсказания еще есть куда расти и расти.
Если есть знающие люди, то буду рад если кто-то разберет предсказание на этом наборе данных с помощью библиотеки Statsmodels, я ее понимаю плохо, но мне показалось, что для качественного анализа с её помощью, данных – «маловато будет!»

Не удержался все же я без картинок :)
Данный раздел посвящен – новичкам, остальные думаю могут его спокойно пролистать.
Не смотря, на то, что мы здесь разбирали простейшие вещи, все же кто-то мог в первый раз в жизни столкнутся с «Наукой о данных» (DataScience). Поэтому если вам понравилась эта «магия», но вы почти ничего не поняли из того как начать самому «колдовать» над данными. Мне остается вас только послать…к первым статьям цикла :)
Когда я писал эти статьи я ощущал себя также как и вы, ничего не понимал, но было интересно.
Если не хотите терять время, то резюмирую, наверное самым полезным вариантом из разобранных выше будет записаться на специализацию «Машинное обучение и анализ данных», на Coursera.
Не надо питать иллюзий что, пройдя эту специализацию вы сразу станете суперпрофессионалом с зарплатой over 150K «деревянных», это все же «торговля мечтой». Тем не менее специализация хорошая и как минимум, позволит вам писать вот такие статьи на Хабр как эта. Для начала и это хорошо, если вы конечно рассматриваете DataScience как хобби.
Если же вдруг с финансами или свободным временем – туго, и хочется просто познакомится поближе, то есть еще вариант.
Помню весь этот цикл начался со статьи о том, как я случайно наткнулся на бесплатные курсы от IBM, теперь они называются Cognitive Class, раньше Big Data University. Если ту статью кратко резюмировать, то в целом курсы – «не фонтан». Но они развиваются и вот в сентябре они выложили курс по Python в связке с наукой о данных.
Надо сказать, что у них появилась целая мини специализация («бейджик») Applied Data Science with Python, в которой аж три небольших курса.
Честно признаюсь руки недошли их пройти, когда пройду, наверное, напишу небольшой обзор, а пока могу смело сказать, что подглядел одним глазом один их трех Data Analysis with Python, он состоит из 5 модулей, в которых есть и видео, и интерактивные лабораторных. То есть ту же Anacond(у) ставить не придется.
Материал этого курса вроде бы охватывает почти все темы, что мы с вами могли видеть в данной статье, и курс строится по пути, который похоже становится стандартным для курсов и самоучителей на эту тему.
Как резюме — если вы хотя бы на базовом уровне владеете английским, у вас мало времени, и вы еще не решились начать учить предмет всерьез, можете попробовать начать с него.
В конце хотелось бы сказать, что неспроста почти все авторы учебных пособий призывают вас придумать себе задачу самостоятельно. Курсы или соревнования на Kagle, это очень хорошо, но там как правило данные уже подготовлены и рамки заданы, а это ограничивает немного вашу свободу творчества.
Если вам сходу тяжело придумать, что-то свое, попробуйте поэкспериментировать с этим набором данных, примените к нему другие модели регрессии, дополните данными, все в ваших руках. Ну или можете придумать, что-то свое. Например, посмотреть, как связаны выход плохих фильмов про Бэтмена и значение стрелок на «Часах Судного дня».
Всем хорошей трудовой недели!
UPD: Убрал неуместную шутку.
В прошлый раз мы разбирали с Вами задачку применения линейной регрессии к открытым данным правительства Москвы, а в этот раз данные тоже открыты, но их уже пришлось собирать вручную.
Итак, сегодня мы с Вами поднимем животрепещущую тему – обращения граждан в органы исполнительной власти Москвы, нас с вами сегодня ждет: краткое описание набора данных, примитивный анализ данных, применение к ним модели линейной регрессии, а также краткая отсылка к учебным курсам для тех, кто совсем ничего не поймет из материала статьи. Ну и конечно же останется пространство для самостоятельного творчества.
Напомню, что наша статья рассчитана в первую очередь на начинающих любителей Python и его распространённых библиотек из области DataScience. Готовы? Тогда, милости прошу под кат.
UPD 07.01.17: Внимание в данные проекта на GitHub было добавлено два месяца, поэтому результаты немного изменились. Статья была написана для версии 1.0 доступной в истории проекта на GitHub
Для начала как обычно буквально два слова о необходимом уровне подготовки.
Данный материал будет вполне понятен людям, которые прочитали любой популярный самоучитель по машинному обучению и анализу данных с помощью Python, или прошли более-менее вменяемый on-line курс. Если совсем не знаете с чего начать можно сразу перейти в конец статьи или же почитать материалы из первой части цикла:
Другие статьи цикла
1 Учим азы:
2. Практикуем первые навыки
- «Ловись Data большая и маленькая!» — (Краткий обзор курсов по Data Science от Cognitive Class)
- «Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch)
- «Айсберг вместо Оскара!» или как я пробовал освоить азы DataScience на kaggle
- ««Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science
2. Практикуем первые навыки
- “Восстание МашинLearning” или совмещаем хобби по Data Science и анализу спектров лампочек
- «Как по нотам!» или Машинное обучение (Data science) на C# с помощью Accord.NET Framework
- «Используй Силу машинного обучения, Люк!» или автоматическая классификация светильников по КСС
- «4 свадьбы и одни похороны» или линейная регрессия для анализа открытых данных правительства Москвы
Наша статья будет состоять из следующих разделов:
- Часть I: знакомимся с данными
- Часть II: Простейший анализ
- Часть III: добавим данные из сети
- Часть IV линейная регрессия — начало.
- Часть V: линейная регрессия- прогноз тренда
- Часть VI: если совсем ничего не понятно
- Часть VII: заключение
В этот раз, пожалуй, обойдемся без стилизации заголовков.
Часть I: знакомимся с данными
Чтобы не тратить в пустую время сразу скажу, что как всегда набор данных, а также Jupyter Notebook notebook (Python 3) с примером выложены на GiTHub
Если чувствуете в себе силы можете сразу экспериментировать. Ну а мы продолжим.
Данные для набора взяты с Официального портала Мэра и Правительства Москвы, данные публичны и при указании ссылки вполне доступны к свободной обработке. Правда в отличии от данных которые есть на портале открытых данных правительства Москвы, эти сведения представлены в неудобном к машинной обработке формате. (Если кто-то напишет скрипт для автоматизированного сбора и похвастается нам – честь и хвала).
Данные пришлось собирать руками, причем насколько они правдоподобны мы оставим на совести разработчиков, отмечу только две вещи в одном из месяцев небыли проставлены цифры на диаграмме (пришлось на глазок), а в другом месяце один из столбцов диаграммы выглядит подозрительно, но даже если там есть какие-то недочеты, нам с вами это не помешает.
В исходном виде данные содержат следующие столбцы:
- num — Индекс
- year – год записи
- month – месяц записи
- total_appeals – общее количество обращений за месяц
- appeals_to_mayor – общее количество обращений в адрес Мэра res_positive- количество положительных решений
- res_explained – количество обращений на которые дали разъяснения
- res_negative – количество обращений с отрицательным решением
- El_form_to_mayor – количество обращений к Мэру в электронной форме
- Pap_form_to_mayor — – количество обращений к Мэру на бумажных носителях
- to_10K_total_VAO…to_10K_total_YUZAO – количество обращений на 10000 населения в различных округах Москвы
- to_10K_mayor_VAO… to_10K_mayor_YUZAO– количество обращений в адрес Мэра и правительства Москвы на 10000 населения в различных округах города
Период сбора данных начинается c 01.2016 и заканчивается 08.2017 (на текущий момент), таким образом столбцов всего получается 32, а строк всего 20. Данные представлены в виде .csv файла, разделитель – знак табуляции.
Часть II: простейший анализ
В принципе в исходных данных на портале Мэра есть некоторая аналитика данных (например, нарастающие итоги), те вещи, которые есть там мы – повторять не будем. Да и вообще поскольку статья рассчитана на начинающих, а сам я тоже из их числа, то в целях демонстрации мы намерено будем упрощать все решения, которые нам встретятся.
Поэтому сразу оговорюсь наша цель не идеально предсказать, что-либо, а просто потренироваться. Опытные читатели могут поделиться своей мудростью в комментариях, за что мы им будем благодарны.
Для анализа мы будем использовать Jupyter Notebook (Python 3) и как обычно, целиком код «записной книжки» выложен на GiTHub.
Пристегните ремни мы отправляемся в приключение по волнам бюрократии.
Загрузим необходимые библиотеки:
#import libraries import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np import requests, bs4 import time from sklearn import model_selection from collections import OrderedDict from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn import linear_model import warnings warnings.filterwarnings('ignore') %matplotlib inline
Затем прочитаем данные посмотрим на нашу таблицу
#load and view data df = pd.read_csv('msc_appel_data.csv', sep='\t', index_col='num') df.head(12)
Вот такие данные получили за первый год.
К сожалению, целиком табличка не влезла, чтобы вы себе это представляли, после многоточия идут аналогичные столбцы по другим округам Москвы.
Давайте теперь посмотрим есть ли какая-либо линейная корреляция между первыми семью столбцами таблицы (без учета индекса).
Вы конечно можете проверить и больше, но нам хватит и этого, как раз умещается на экране.
columns_to_show = ['res_positive', 'res_explained', 'res_negative', 'total_appeals', 'appeals_to_mayor','El_form_to_mayor', 'Pap_form_to_mayor'] data=df[columns_to_show] grid = sns.pairplot(df[columns_to_show]) savefig('1.png')
В первой строке мы определили набор столбцов, которые будем извлекать из нашей таблицы (он нам еще пригодится в будущем).
Затем с помощью библиотеки seaborn построили диаграмму (если ваш ПК в процессе задумался, не переживайте это нормально).
Ну а последняя строка — это сохранение нашей картинки в файл, в той же папке, что и notebook, вы можете ее удалить, а мне она нужна чтобы было проще подготовить вам статью.
В результате получим вот такую красоту:
Что же мы видим, на диаграмме? Например, то что на пересечении количества «разъясненных» обращений и общего количества обращений, точки выстроились практически в ровную линию, давайте убедимся в этом, посмотрев численное значение коэффициента корреляции.
print("Correlation coefficient for a explained review result to the total number of appeals =", df.res_explained.corr(df.total_appeals) ) print("Corr.coeff. for a total number of appeals to mayor to the total number of appeals to mayor in electronic form =", df.appeals_to_mayor.corr(df.El_form_to_mayor) )
Correlation coefficient for a explained review result to the total number of appeals = 0.830749053715
Corr.coeff. for a total number of appeals to mayor to the total number of appeals to mayor in electronic form = 0.685450192201
В первой строчке с помощью встроенного в Pandas Data Frame метода corr, мы как раз вычислили корреляцию между этими двумя столбцами. Корреляция оказалась достаточно высокая, но это очевидно, в большинстве случаев как говорится «находит коса на камень», так что с одной стороны обращения не всегда – грамотные, а с другой стороны любой бюрократический аппарат в большинстве случаев в первую очередь постарается вам «отписаться». Поэтому неудивительно, что разъяснённых обращений больше всего, ну и как следствие неудивительно, что чем больше обращений, тем больше разъяснительных ответов на них. Именно об этом нам и говорит коэффициент корреляции 0.83
Во второй строчке кода мы посмотрели вторую пару – общее обращений в адрес мэра и количество обращений, направленных ему в электронной форме. Тут также прослеживается зависимость и если бы не явные выбросы (которые вполне могут как ошибками в данных, так и нетипичным поведением горожан), то наверняка коэффициент корреляции мог бы быть еще ближе к единице.
В оригинальных данных есть диаграммы активности населения в разрезе округов Москвы отражающие количество обращений граждан на 10 тысяч жителей. Выглядит это примерно так:
Мы с вами посчитаем тоже самое, но суммарно за весь период.
Для начала выбреем нужные нам столбцы, мы оставим вам на самостоятельное изучение манипуляции с обращениями в адрес непосредственно мэра и сосредоточимся, на общем количестве обращений.
district_columns = ['to_10K_total_VAO', 'to_10K_total_ZAO', 'to_10K_total_ZelAO', 'to_10K_total_SAO','to_10K_total_SVAO','to_10K_total_SZAO','to_10K_total_TiNAO','to_10K_total_CAO', 'to_10K_total_YUAO','to_10K_total_YUVAO','to_10K_total_YUZAO']
Затем сократим названия наших полей до названий округов и построим столбчатую диаграмму.
y_pos = np.arange(len(district_columns)) short_district_columns=district_columns.copy() for i in range(len(short_district_columns)): short_district_columns[i] = short_district_columns[i].replace('to_10K_total_','') distr_sum = df[district_columns].sum() plt.figure(figsize=(16,9)) plt.bar(y_pos, distr_sum, align='center', alpha=0.5) plt.xticks(y_pos, short_district_columns) plt.ylabel('Number of appeals') plt.title('Number of appeals per 10,000 people for all time') savefig('2.png')
Что нам показывает диаграмма? То, что самый расстроенный округ это центральный. И вы знаете это скорей всего не потому, что люди там «с жиру бесятся». Есть у меня одна мыслишка…
Переходим на сайт программы «Моя улица» и чисто ради любопытства смотрим, где проводились работы в 2017 г.
Подавляющее большинство работ проводилось в ЦАО, я не думаю, что это единственная причина такого большого количества обращений на душу населения, но вполне возможно, что одна из.
Часть III: добавим данные из сети
Ну что же вот мы с вами и подошли к мысли, о том, что наш набор сам по себе «скучный» и мало, что объясняет. Давайте расширим его данными из глобальной сети.
Мы с вами рассмотрим только два простеньких случая, а дальше перед вами открыта полная свобода творчества.
Для начала переведем данные с прошлого графика из масштаба 1 обращение на 10000 тысяч человек, в полное количество обращений. Для того, чтобы выполнить обратный перевод, нам понадобится знать количество людей, проживающее во всех округах. В этом нам поможет Википедия из которой мы скопируем данные в ручную.
# we will collect the data manually from #https://ru.wikipedia.org/wiki/%D0%90%D0%B4%D0%BC%D0%B8%D0%BD%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%BE-%D1%82%D0%B5%D1%80%D1%80%D0%B8%D1%82%D0%BE%D1%80%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%9C%D0%BE%D1%81%D0%BA%D0%B2%D1%8B #the data is filled in the same order as the district_columns district_population=[1507198,1368731,239861,1160576,1415283,990696,339231,769630,1776789,1385385,1427284] #transition from 1/10000 to citizens' appeal to the entire population of the district total_appel_dep=district_population*distr_sum/10000 plt.figure(figsize=(16,9)) plt.bar(y_pos, total_appel_dep, align='center', alpha=0.5) plt.xticks(y_pos, short_district_columns) plt.ylabel('Number of appeals') plt.title('Number of appeals per total pщulation of district for all time') savefig('3.png')
Число людей в district_population идет в том же порядке, что и наши столбцы в district_columns (см выше). Получим следующую диаграмму.
Где это применить? Сложно сказать, данных явно недостаточно, но можно копать в сторону более равномерного распределение трудовой нагрузки на специалистов районных управ отвечающих за обращения граждан.
Теперь давайте немного усложним задачу и попробуем забрать какие-нибудь данные автоматически. К счастью, на Python есть достойные библиотеки, которые нам могут в этом помочь. Мы выберем одну из весьма популярных Beautifulsoup.
#we use beautifulsoup oil_page=requests.get('https://worldtable.info/yekonomika/cena-na-neft-marki-brent-tablica-s-1986-po-20.html') b=bs4.BeautifulSoup(oil_page.text, "html.parser") table=b.select('.item-description') table = b.find('div', {'class': 'item-description'}) table_tr=table.find_all('tr') d_parse=OrderedDict() for tr in table_tr[1:len(table_tr)-1]: td=tr.find_all('td') d_parse[td[0].get_text()]=float(td[1].get_text())
Давайте разберемся, что все это значило. Если вы перейдете на страничку с исходными данными, то увидите, что в качестве источника данных для примера я выбрал очень простой случай. На странице есть таблица, у которой три колонки.
Третья колонка нас не интересует, но вы для себя можете реализовать и её обработку.
Взглянув на код таблицы мы поймем, что она имеет класс .item-description, получим весь код таблицы, затем просто в цикле обрабатываем каждую строчку таблицы, запихивая данные в словарь, где ключ это дата, а значение – цена на нефть. OrderedDict – мы выбрали для того, чтобы быть уверенными, что данные в словаре будут представлены именно в том порядке, в котором мы их считали.
# dictionary selection boundaries d_start=358 d_end=378 # Uncomment all if grabber doesn't work #d_parse=[("январь 2016", 30.8), ("февраль 2016", 33.2), ("март 2016", 39.25), ("апрель 2016", 42.78), ("май 2016", 47.09), # ("июнь 2016", 49.78), ("июль 2016", 46.63), ("август 2016", 46.37), ("сентябрь 2016", 47.68), ("октябрь 2016", 51.1), # ("ноябрь 2016", 47.97), ("декабрь 2016", 54.44), ("январь 2017", 55.98), ("февраль 2017", 55.95), ("март 2017", 53.38), # ("апрель 2017", 53.54), ("май 2017", 50.66), ("июнь 2017", 47.91), ("июль 2017", 49.51), ("август 2017", 51.82)] #d_parse=dict(d_parse) #d_start=0 #d_end=20
Этот кусок кода, нам нужен в первую очередь, чтобы обеспечить работоспособность примера, в случае если страница исходных данных сильно изменится (или и вовсе пропадет). В таком случае будет достаточно разкомментировать строки, после чего код ниже позволит нам и дальше работать с примером, как ни в чем не бывало.
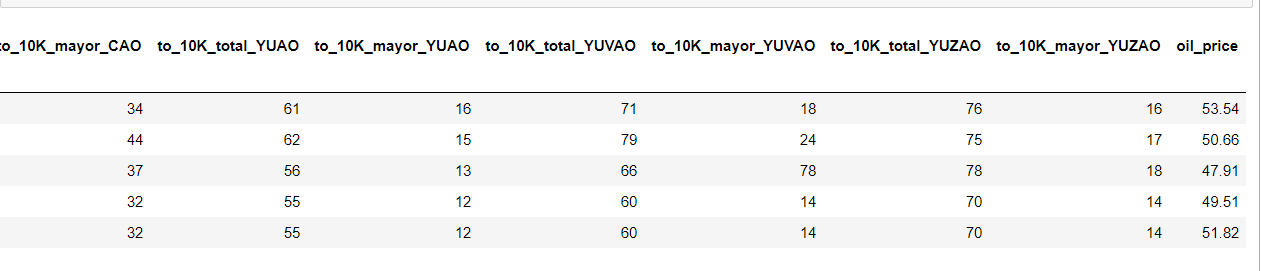
# values from January 2016 to August 2017 df['oil_price']=list(d_parse.values())[d_start:d_end] df.tail(5)
Осталось только создать в таблице столбец, в который мы добавим нашу цену на нефть и убедится, в том, что все вышло, как и планировали.
Как вы уже догадались мы не просто так добавляли цену на нефть, давайте посмотрим есть ли какая-нибудь корреляция между новым столбцом и парочкой старых.
print("Correlation coefficient for the total number of appeals result to the oil price (in US $) =", df.total_appeals.corr(df.oil_price) ) print("Correlation coefficient for a positive review result to the oil price (in US $) =", df.res_positive.corr(df.oil_price) )
Correlation coefficient for the total number of appeals result to the oil price (in US $) = 0.446035680201
Correlation coefficient for a positive review result to the oil price (in US $) = -0.0530061539779
Если честно не могу объяснить, как связана цена на нефть и общее количество обращений, думаю, что наличие хоть какой-то корреляции во многом случайность.
А вот отсутствие корреляции между числом положительных ответов и ценой на нефть объяснить можно. Бедные рядовые специалисты в управах, ГУПах (в которые наверняка часть обращений спускается), в департаментах правительства Москвы и других причастных подразделениях, наверняка в первую очередь думают, как бы дожить от аванса до получки и на себе ежемесячные колебания цен на нефть не сильно ощущают. А значит не становятся от роста цен на нефть добрее, и соответственно положительная динамика цен на нефть не вызывает у людей желания «разбиться в лепешку», чтобы у вас во дворе покрасили скамейку.
Я думаю вы сможете придумать еще кучу «безумных» комбинаций для анализа – дерзайте! А мы между тем перейдём к обещанной ранее линейной регрессии.
Часть IV: линейная регрессия — начало
Еще раз повторюсь, что в сети в целом, да и на Хабре в частности полно достойных материалов про линейную регрессию, поэтому мы не будем усложнять и рассмотрим лишь пару простеньких примеров для демонстрации.
Начнем мы с подготовки данных и первое что сделаем это перекодируем нашу категориальную переменную «месяц» в ее числовой аналог, получим 12 новых признаков, код и таблица будут выглядеть будет вот так.
df2=df.copy() #Let's make a separate column for each value of our categorical variable df2=pd.get_dummies(df2,prefix=['month'])
Так, например, 1 в столбце month_May значит, что раньше в этой строке как раз был месяц май
Идем дальше.
#Let's code the month with numbers d={'January':1, 'February':2, 'March':3, 'April':4, 'May':5, 'June':6, 'July':7, 'August':8, 'September':9, 'October':10, 'November':11, 'December':12} month=df.month.map(d) #We paste the information about the date from several columns dt=list() for year,mont in zip(df2.year.values, month.values): s=str(year)+' '+str(mont)+' 1' dt.append(s) #convert the received data into the DateTime type and replace them with a column year df2.rename(columns={'year': 'DateTime'}, inplace=True) df2['DateTime']=pd.to_datetime(dt, format='%Y %m %d') df2.head(5)
В первой части кода мы создаем соответствие названий месяцев и их порядковым номерам, затем поскольку pd.get_dummies удалил нашу исходную колонку «месяц», мы позаимствуем её из старой таблицы (df).
Во второй части кода мы склеиваем и помещаем в список строковые данные из столбца год, из переменной месяц и на всякий случай первое число каждого месяца (хотя думаю без этого можно было обойтись).
В третей части мы переименовываем столбец «год», и заменяем данные в нем на данные типа datetime, которые извлекаются из нашего списка в соответствии с шаблоном '%Y %m %d' (ГОД номер месяца день месяца).
Получим следующий результат:
Правда месяца нам сейчас не нужны, но потом пригодятся.
А пока, продолжим готовить данные для нашей модели линейной регрессии
#Prepare the data cols_for_regression=columns_to_show+district_columns cols_for_regression.remove('res_positive') cols_for_regression.remove('total_appeals') X=df2[cols_for_regression].values y=df2['res_positive'] #Scale the data scaler =StandardScaler() X_scal=scaler.fit_transform(X) y_scal=scaler.fit_transform(y)
В начале мы определили какие столбцы будем выбирать из таблицы в качестве признаков (х), а какой в качестве целевой функции (у) Также мы выкинули оттуда столбец ‘total_appeals', не то чтобы он нам сильно не нравился, но он избыточен, его можно получить комбинацией трех других столбцов.
После того как мы определились с данными, мы их на всякий случай масштабируем, в принципе это можно не делать, для данного случая будет не смертельно, гребневая регрессия могла бы нам в некотором роде помочь с их уравниванием, но так всяко удобней и лучше.
Для начала посмотрим, как почти все столбцы кроме месяцев и цен на нефть, помогают нам определить количество одобренных обращений
X_train, X_test, y_train, y_test = train_test_split(X_scal, y_scal, test_size=0.2, random_state=42) #y_train=np.reshape(y_train,[y_train.shape[0],1]) #y_test=np.reshape(y_test,[y_test.shape[0],1]) loo = model_selection.LeaveOneOut() #alpha coefficient is taken at a rough guess lr = linear_model.Ridge(alpha=55.0) scores = model_selection.cross_val_score(lr , X_train, y_train, scoring='mean_squared_error', cv=loo,) print('CV Score:', scores.mean()) lr .fit(X_train, y_train) print('Coefficients:', lr.coef_) print('Test Score:', lr.score(X_test,y_test))
CV Score: -0.862647707895
Coefficients: [ 0.10473057 0.08121859 0.00540471 0.06896755 -0.04812318 0.04166228
0.0572629 -0.01035959 0.09634643 0.07031471 -0.02657464 0.02800165
0.03528063 0.02458972 0.06148957 0.04026195]
Test Score: -0.814435440002
Обратите внимание в этот раз мы не только поделили нашу выборку на тренировочную и контрольную с помощью функции train_test_split, но еще и на базе тренировочной выборки провели оценку качества работы модели по кросс-валидации. Поскольку данных очень мало мы проводили кросс-валидацию по следующему принципу, в каждом разбиение берется 1 образец как контрольный, а на остальных производится обучение, результаты предсказания – усредняются. Эта оценка не является панацеей, но учитывая, то что у нас контрольная выборка состоит всего из четырех точек, то она является более надежной оценкой качества.
Вы можете ради любопытства побаловаться с коэффициентом регуляризации альфа и посмотреть, как будет скакать оценка по контрольной выборке и кросс-валидации или можете просто побаловаться параметром random-state в train_test_split и увидеть, как скачет качество предсказаний.
Рас уж речь зашла о коэффициенте регуляризации, в отличии от прошлой статьи где мы использовали L1 (lasso) регуляризацию, L2 (Ridge) регуляризация не может полностью удалить малополезные признаки, но сильно снижает их вес за счет коэффициентов. У нас мало данных и похоже, что в данном случае модель лучше работает с большим коэффициентом регуляризации, не так сильно в итоге переобучаясь.
Что значат эти цифры? Хорошо это или плохо? Это мы поймем, чуть позже, а пока давайте проделаем все тоже самое, но добавим в качестве исходного признака еще и нефть.
X_oil=df2[cols_for_regression+['oil_price']].values y_oil=df2['res_positive'] scaler =StandardScaler() X_scal_oil=scaler.fit_transform(X_oil) y_scal_oil=scaler.fit_transform(y_oil) X_train, X_test, y_train, y_test = train_test_split(X_scal_oil, y_scal_oil, test_size=0.2, random_state=42) #y_train=np.reshape(y_train,[y_train.shape[0],1]) #y_test=np.reshape(y_test,[y_test.shape[0],1]) lr = linear_model.Ridge() loo = model_selection.LeaveOneOut() lr = linear_model.Ridge(alpha=55.0) scores = model_selection.cross_val_score(lr , X_train, y_train, scoring='mean_squared_error', cv=loo,) print('CV Score:', scores.mean()) lr .fit(X_train, y_train) print('Coefficients:', lr.coef_) print('Test Score:', lr.score(X_test,y_test))
CV Score: -0.863699353968
Coefficients: [ 0.10502651 0.0819168 0.00415511 0.06749919 -0.04864709 0.04241101
0.05686368 -0.00928224 0.09569626 0.0708282 -0.02600053 0.02783746
0.0360866 0.02536353 0.06146142 0.04065484 -0.02887498]
Test Score: -0.506208294281
Как видим на контрольной выборке все изменилось в лучшую сторону, а вот на кросс-валидации не особо. В данном случае будем верить именно ей.
Так как трактовать эти данные. Напомню, что наш коэффициент среднеквадратичной ошибки (отклонения), получается на основании тех данных, что есть, если бы мы их не масштабировали его значение было бы больше. Лучше всего понять, как наша модель предсказывает контрольные данные это построить график.
# plot for test data plt.figure(figsize=(16,9)) plt.scatter(lr.predict(X_test), y_test, color='black') plt.plot(y_test, y_test, '-', color='green', linewidth=1) plt.xlabel('relative number of positive results (predict)') plt.ylabel('relative number of positive results (test)') plt.title="Regression on test data" print('predict: {0} '.format(lr.predict(X_test))) print('real: {0} '.format(y_test)) savefig('4.png')
predict: [-1.22036553 0.39006382 0.46499326 -0.27854243]
real: [-0.5543026 0.23746693 0.41263435 0.44332061]
Ну вот теперь, мы явно видим насколько предсказанные значения отличаются, от тех, что должны быть. Для тех, кто не догадался, поясню, что в идеальном случае все точки (предсказанные значения), должны были бы оказаться на зеленой линии (это легко проверить заменив в scatter plot lr.predict(X_test) на y_test.
Как видите наша модель не идеальна, но чего еще ждать, коэффициент регуляризации мы подобрали на глазок, специально признаки не отбирали, а самих данных кот наплакал.
Но не буем грустить, а лучше соберемся с силами и сделаем последний рывок.
Часть V : линейная регрессия — прогноз тренда
До этого момента, мы с вами брали для контроля случайные точки, куда как логичней было бы проверить, может ли наша модель по имеющимся данным в будущем предсказывать количество положительных результатов рассмотрения. Мы же ведь не просто так делали столбец с датой в таблице.
Я напомню, что мы пока в нашем анализе нигде не использовали данные по месяцам. Не использовали и сейчас не будем! Для начала посмотрим, как поведет себя в других условиях наша прошлая модель с ценами на нефть.
X_train=X_scal_oil[0:16] X_test=X_scal_oil[16:20] y_train=y_scal_oil[0:16] y_test=y_scal_oil[16:20] loo = model_selection.LeaveOneOut() lr = linear_model.Ridge(alpha=7.0) scores = model_selection.cross_val_score(lr , X_train, y_train, scoring='mean_squared_error', cv=loo,) print('CV Score:', scores.mean()) lr.fit(X_train, y_train) print('Coefficients:', lr.coef_) print('Test Score:', lr.score(X_test,y_test)) # plot for test data plt.figure(figsize=(19,10)) #trainline plt.scatter(df2.DateTime.values[0:16], lr.predict(X_train), color='black') plt.plot(df2.DateTime.values[0:16], y_train, '--', color='green', linewidth=3) #test line plt.scatter(df2.DateTime.values[16:20], lr.predict(X_test), color='black') plt.plot(df2.DateTime.values[16:20], y_test, '--', color='blue', linewidth=3) #connecting line plt.plot([df2.DateTime.values[15],df2.DateTime.values[16]], [y_train[15],y_test[0]] , color='magenta',linewidth=2, label='train to test') plt.xlabel('Date') plt.ylabel('Relative number of positive results') plt.title="Time series" print('predict: {0} '.format(lr.predict(X_test))) print('real: {0} '.format(y_test)) savefig('5.1.png')
CV Score: -0.989644199134
Coefficients: [ 0.29502827 0.18625818 -0.05782895 0.14304852 -0.19414197 0.00671457
0.00761346 -0.09589469 0.23355104 0.1795458 -0.08298576 -0.09204623
0.00742492 -0.03964034 0.13593245 -0.00747192 -0.18743228]
Test Score: -4.31744509658
predict: [ 1.40179872 0.5677182 0.1258284 0.38227278]
real: [ 0.53985448 0.23746693 0.35765479 0.84671711]
На рассмотренных в другом ключе данных модель себя показывает еще немного хуже, возможно дело в том числе и в коэффициенте регуляризации, чтобы было нагляднее я его взял таким же, как и для следующего примера (равным 7).
Ну что же все, что нам осталось это наконец-то отказаться от нефти и ввести наши закодированные признаки месяца.
cols_months=['month_December', 'month_February', 'month_January', 'month_July', 'month_June', 'month_March', 'month_May', 'month_November', 'month_October','month_September','month_April','month_August'] X_month=df2[cols_for_regression+cols_months].values y_month=df2['res_positive'] scaler =StandardScaler() X_scal_month=scaler.fit_transform(X_month) y_scal_month=scaler.fit_transform(y_month) X_train=X_scal_month[0:16] X_test=X_scal_month[16:20] y_train=y_scal_month[0:16] y_test=y_scal_month[16:20] loo = model_selection.LeaveOneOut() lr = linear_model.Ridge(alpha=7.0) scores = model_selection.cross_val_score(lr , X_train, y_train, scoring='mean_squared_error', cv=loo,) print('CV Score:', scores.mean()) lr.fit(X_train, y_train) print('Coefficients:', lr.coef_) print('Test Score:', lr.score(X_test,y_test)) # plot for test data plt.figure(figsize=(19,10)) #trainline plt.scatter(df2.DateTime.values[0:16], lr.predict(X_train), color='black') plt.plot(df2.DateTime.values[0:16], y_train, '--', color='green', linewidth=3) #test line plt.scatter(df2.DateTime.values[16:20], lr.predict(X_test), color='black') plt.plot(df2.DateTime.values[16:20], y_test, '--', color='blue', linewidth=3) #connecting line plt.plot([df2.DateTime.values[15],df2.DateTime.values[16]], [y_train[15],y_test[0]] , color='magenta',linewidth=2, label='train to test') plt.xlabel('Date') plt.ylabel('Relative number of positive results') plt.title="Time series" print('predict: {0} '.format(lr.predict(X_test))) print('real: {0} '.format(y_test)) savefig('5.2.png')
CV Score: -0.909527242059
Coefficients: [ 0.09886191 0.11920832 0.02519177 0.20624114 -0.13140361 -0.02511699
0.0580594 -0.12742719 0.13987627 0.07905998 -0.08918158 0.00626676
-0.00090422 -0.01557178 0.0838269 0.00827684 0.04305265 -0.05808898
0.01884837 -0.06313912 0.04531003 0.1165687 -0.13590156 -0.29777529
0.03542855 0.12639045 -0.00721213 0.15110762]
Test Score: -0.35070187517
predict: [ 0.71512724 0.37641552 -0.10881606 0.71539711]
real: [ 0.53985448 0.23746693 0.35765479 0.84671711]
Невооруженным глазом видно, что с учетом фактора месяца, модель лучше описывает наши данные. Хотя думаю, с точки зрения качества предсказания еще есть куда расти и расти.
Если есть знающие люди, то буду рад если кто-то разберет предсказание на этом наборе данных с помощью библиотеки Statsmodels, я ее понимаю плохо, но мне показалось, что для качественного анализа с её помощью, данных – «маловато будет!»
Не удержался все же я без картинок :)
Часть VI: если совсем ничего не понятно
Данный раздел посвящен – новичкам, остальные думаю могут его спокойно пролистать.
Не смотря, на то, что мы здесь разбирали простейшие вещи, все же кто-то мог в первый раз в жизни столкнутся с «Наукой о данных» (DataScience). Поэтому если вам понравилась эта «магия», но вы почти ничего не поняли из того как начать самому «колдовать» над данными. Мне остается вас только послать…к первым статьям цикла :)
- «Ловись Data большая и маленькая!» — (Краткий обзор курсов по Data Science от Cognitive Class)
- «Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch)
- «Айсберг вместо Оскара!» или как я пробовал освоить азы DataScience на kaggle
- «Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science
Когда я писал эти статьи я ощущал себя также как и вы, ничего не понимал, но было интересно.
Если не хотите терять время, то резюмирую, наверное самым полезным вариантом из разобранных выше будет записаться на специализацию «Машинное обучение и анализ данных», на Coursera.
Не надо питать иллюзий что, пройдя эту специализацию вы сразу станете суперпрофессионалом с зарплатой over 150K «деревянных», это все же «торговля мечтой». Тем не менее специализация хорошая и как минимум, позволит вам писать вот такие статьи на Хабр как эта. Для начала и это хорошо, если вы конечно рассматриваете DataScience как хобби.
Если же вдруг с финансами или свободным временем – туго, и хочется просто познакомится поближе, то есть еще вариант.
Помню весь этот цикл начался со статьи о том, как я случайно наткнулся на бесплатные курсы от IBM, теперь они называются Cognitive Class, раньше Big Data University. Если ту статью кратко резюмировать, то в целом курсы – «не фонтан». Но они развиваются и вот в сентябре они выложили курс по Python в связке с наукой о данных.
Надо сказать, что у них появилась целая мини специализация («бейджик») Applied Data Science with Python, в которой аж три небольших курса.
Честно признаюсь руки недошли их пройти, когда пройду, наверное, напишу небольшой обзор, а пока могу смело сказать, что подглядел одним глазом один их трех Data Analysis with Python, он состоит из 5 модулей, в которых есть и видео, и интерактивные лабораторных. То есть ту же Anacond(у) ставить не придется.
Материал этого курса вроде бы охватывает почти все темы, что мы с вами могли видеть в данной статье, и курс строится по пути, который похоже становится стандартным для курсов и самоучителей на эту тему.
Как резюме — если вы хотя бы на базовом уровне владеете английским, у вас мало времени, и вы еще не решились начать учить предмет всерьез, можете попробовать начать с него.
Часть VII: заключение
В конце хотелось бы сказать, что неспроста почти все авторы учебных пособий призывают вас придумать себе задачу самостоятельно. Курсы или соревнования на Kagle, это очень хорошо, но там как правило данные уже подготовлены и рамки заданы, а это ограничивает немного вашу свободу творчества.
Если вам сходу тяжело придумать, что-то свое, попробуйте поэкспериментировать с этим набором данных, примените к нему другие модели регрессии, дополните данными, все в ваших руках. Ну или можете придумать, что-то свое. Например, посмотреть, как связаны выход плохих фильмов про Бэтмена и значение стрелок на «Часах Судного дня».
Всем хорошей трудовой недели!
UPD: Убрал неуместную шутку.

