 AV1 — это новый универсальный видеокодек, разработанный Альянсом за открытые медиа (Alliance for Open Media). Альянс взял за основу кодек VPX от Google, Thor от Cisco и Daala от Mozilla/Xiph.Org. Кодек AV1 превосходит по производительности VP9 и HEVC, что делает его кодеком не завтрашнего, а послезавтрашнего дня. Формат AV1 свободен от любых роялти и всегда останется таковым с разрешительной лицензией свободного и открытого ПО.
AV1 — это новый универсальный видеокодек, разработанный Альянсом за открытые медиа (Alliance for Open Media). Альянс взял за основу кодек VPX от Google, Thor от Cisco и Daala от Mozilla/Xiph.Org. Кодек AV1 превосходит по производительности VP9 и HEVC, что делает его кодеком не завтрашнего, а послезавтрашнего дня. Формат AV1 свободен от любых роялти и всегда останется таковым с разрешительной лицензией свободного и открытого ПО.Тройственная платформа
Кто следил за развитием Daala, тот знает, что после формирования Альянса за открытые медиа (AOM) Xiph и Mozilla предложили наш кодек Daala как один из базисов для нового стандарта. Кроме него, компания Google представила свой кодек VP9, а Cisco представила Thor. Идея заключалась в том, чтобы создать новый кодек в том числе на основе этих трёх решений. С того момента я не публиковал никаких демо о новых технологиях в Daala или AV1; в течение долгого времени мы мало что знали об окончательном кодеке.
Около двух лет назад AOM проголосовал за то, чтобы основать фундаментальную структуру нового кодека на базе VP9, а не Daala или Thor. Компании-члены альянса хотели в кратчайший срок получить полезный кодек без роялти и лицензирования, поэтому выбрали VP9 как наименее рискованный вариант. Я согласен с таким выбором. Хотя Daala выдвинули кандидатом, но я всё-таки думаю, что и устранение блочных артефактов трансформацией внахлёст (lapping arrpoach), и техники частотной области в Daala тогда (да и сейчас) ещё недостаточно созрели для реального развёртывания. В Daala по-прежнему оставались нерешённые технические вопросы, а выбор в качестве отправной точки VP9 решал большинство этих проблем.
Благодаря тому, что VP9 взят за основу, кодек AV1 (AOM Video Codec 1) будет в основном понятным и знакомым кодеком, построенным на традиционном коде блочного преобразования. Конечно, он также включает в себя и новые очень интересные вещи, причём некоторые из них взяты из Daala! Теперь, когда мы быстро приближаемся к утверждению окончательных спецификаций, пришло время представить долгожданные технологические демонстрации кодека в контексте AV1.
Новый взгляд на прогнозирование цветности по яркости (CfL)
Прогнозирование цветности по яркости (Chroma from Luma, сокращённо CfL) — один из новых методов прогнозирования, принятых для AV1. Как следует из названия, он прогнозирует цвета в изображении (chroma) на основе значений яркости (luma). Сначала кодируются и декодируются значения яркости, а затем CfL выполняет обоснованное прогнозирование цветов. Если предположение хорошее, то это уменьшает количество цветовой информации для кодирования и экономит место.
На самом деле CfL в AV1 — это не абсолютно новая техника. Основополагающая научная статья по CfL вышла в 2009 году, а LG и Samsung совместно предложили первую реализацию CfL под названием LM Mode, которую отклонили на этапе проектирования HEVC. Вы помните, что я писал об особо продвинутой версии CfL, которая используется в кодеке Daala. В кодеке Thor от Cisco тоже применяется техника CfL, похожая на LM Mode, а HEVC в итоге добавил улучшенную версию, названную Cross-Channel Prediction (CCP), как расширение HEVC Range Extension (RExt).
| LM Mode | Thor CfL | Daala CfL | HEVC CCP | AV1 CfL | |
|---|---|---|---|---|---|
| Область прогнозирования | простран- ственная |
простран- ственная |
частотная | простран- ственная |
простран- ственная |
| Кодирование | нет | нет | бит знака | индекс + знаки | совместный знак + индекс |
| Механизм активации | LM_MODE | порог | сигнал | двоичный флаг | CFL_PRED (только в режиме uv) |
| Требует PVQ | нет | нет | да | нет | нет |
| Моделирование декодера? | да | да | нет | нет | нет |
LM Mode и Thor похожи тем, что кодер и декодер параллельно запускают идентичную модель прогнозирования и не требуют кодирования каких-либо параметров. К сожалению, эта параллельная/неявная модель снижает точность аппроксимации и усложняет декодер.
В отличие от других, CfL в Daala работает в частотной области. Это передаёт только бит активации и бит знака, а другая информация о параметрах уже неявно закодирована через PVQ.
Окончательная реализация AV1 CfL основана на реализации Daala, заимствует идеи модели у Thor и улучшает оба варианта за счёт внедрения результатов дополнительных научных исследований. Это позволяет избежать увеличения сложности в декодере, реализовать поиск модели, которая также уменьшает сложность кодера по сравнению с предшественниками и особенно улучшает точность и аппроксимацию кодированной модели.
Необходимость лучшего внутрикадрового прогнозирования
На фундаментальном уровне сжатие — это искусство прогнозирования. До кодеков последнего поколения сжатие видео полагалось в основном на межкадровое прогнозирование кодирования, то есть кодирование кадра как набора изменений по сравнению с другими кадрами. Те кадры, на которых основано межкадровое кодирование, называются опорными кадрами. Прогнозирование межкадрового кодирования за последние несколько десятилетий стало невероятно мощным инструментом.
Несмотря на мощь межкадрового прогнозирования, нам по-прежнему нужны отдельные опорные кадры. Они по определению не полагаются на информацию из каких-либо других кадров — в результате могут использовать только внутрикадровое прогнозирование, которое работает полностью внутри кадра. Поскольку в опорных кадрах используется только внутрикадровое прогнозирование, их также часто называют I-кадрами (intra-frames). Опорные или I-кадры позволяют осуществлять поиск в видео, иначе нам всегда приходилось бы воспроизводить видео только с самого начала*.
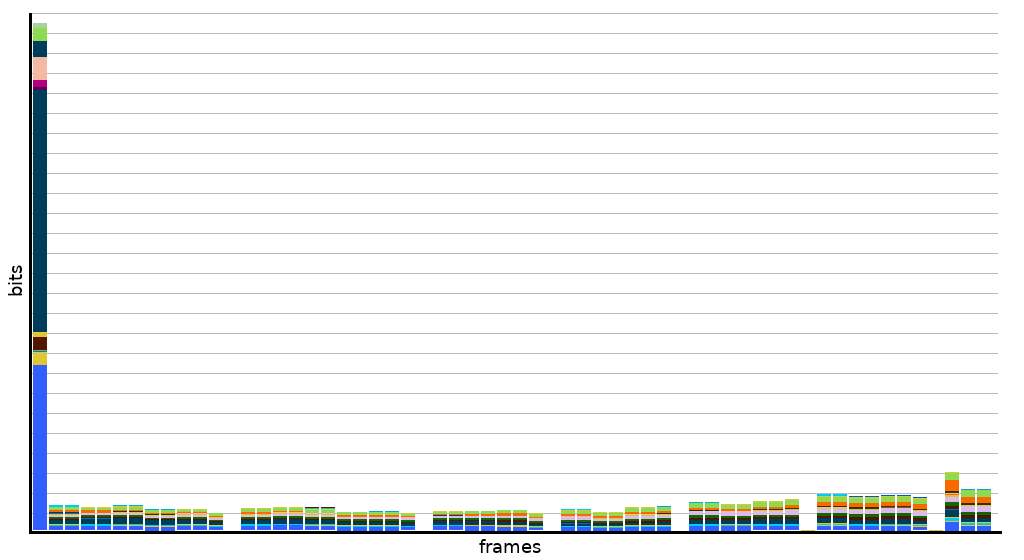
Гистограмма размера в битах первых шестидесяти кадров тестового видео, начиная с опорного кадра. В этом клипе опорный кадр в 20-30 больше по размеру последующих промежуточных кадров. В замедленной съёмке или сильно статичном видеоряде опорный кадр может быть в сотни раз больше промежуточных.
Опорные кадры чрезвычайно велики по сравнению с промежуточными, поэтому их обычно используют как можно реже и широко разносят друг от друга. Несмотря на это, промежуточные кадры становятся всё меньше и меньше, а опорные кадры занимают всё большую часть битового потока. В результате исследования видеокодеков сосредоточились на поиске новых, более мощных форм внутрикадрового прогнозирования, чтобы уменьшить размер опорных кадров. И несмотря на своё название, промежуточные кадры тоже могут извлечь пользу из внутрикадрового прогнозирования.
Улучшение внутрикадрового прогнозирования — это двойная победа!
Прогнозирование цветности по яркости работает исключительно на основе блоков яркости в пределах кадра. Таким образом, это техника внутрикадрового прогнозирования.
Энергия — это сила †
Корреляция энергии — это информация
Почему мы думаем, что можно предсказать цвет по яркости?
В большинстве реализаций видео корреляция каналов уменьшена из-за использования цветового пространства типа YUV. Y — это канал яркости, версия оригинального видеосигнала в оттенках серого, сгенерированная путём сложения взвешенных версий исходных красного, зелёного и синего сигналов. Каналы цветности U и V вычитают сигнал яркости из синего и красного, соответственно. Модель YUV простая и существенно уменьшает дублирование кодирования на каналах.

Разложение изображения (крайнее левое) в модели YUV или, точнее, в цветовом пространстве bt.601 Y'CbCr. Второе слева изображение показывает канал яркости, а два правых — каналы цветности. В YUV меньше межканальной избыточности, чем в изображении RGB, но черты оригинального изображения по-прежнему ясно видны во всех трёх каналах после декомпозиции YUV; во всех трёх каналах очертания объектов находятся в одинаковых местах.
И всё же, если посмотреть на декомпозицию кадра по каналам YUV, становится очевидно, что очертания границ цветности и яркости по-прежнему находятся в одинаковых местах кадра. Осталась некая корреляция, которую можно использовать для уменьшения битрейта. Давайте попробуем использовать некоторые данные яркости для прогнозирования цветности.
Достаём цветные мелки
Прогнозирование цветности по яркости — это, по сути, процесс раскрашивания монохромного изображения исходя из обоснованных догадок. Примерно как взять старую чёрно-белую фотографию, цветные карандаши — и приступить к раскраске. Конечно, прогнозы CfL должны быть точными, а не чистыми догадками.
Работа облегчается тем, что современные видеокодеки разбивают изображение на иерархию блоков меньшего размера, выполняя основную часть кодирования независимо на каждом блоке.

Кодер AV1 разбивает кадр на отдельные блоки прогнозирования для максимальной точности кодирования, а также, что не менее важно, для упрощения анализа и внесения корректив в прогнозирование по мере обработки изображения.
Модель, которая прогнозирует цвет сразу для всего изображения, была бы слишком громоздкой, сложной и подверженной ошибкам — но нам и не нужно прогнозировать всё изображение. Поскольку кодер работает по очереди с небольшими фрагментами, нужно только сравнить корреляции на небольших областях — и по ним мы можем прогнозировать цветность по яркости с высокой степенью точности, используя довольно простую модель. Рассмотрим небольшую часть изображения ниже, в красном контуре:

Единственный блок на одном кадре видео иллюстрирует, что локализация прогнозирования цветности в небольших блоках — эффективное средство для упрощения прогнозирования.
В небольшом диапазоне из этого примера хорошее «правило» для раскрашивания изображения будет простым: более яркие области — зелёные, а насыщенность уменьшается вместе с яркостью вплоть до чёрного. У большинства блоков — такие же простые правила расцвечивания. Мы можем усложнить их на свой вкус, но самый простой метод тоже проявляет себя очень хорошо, так что начнём с простого и аппроксимируем данные к простой линии ax+β:

Значения Cb и Cr (U и V) относительно яркости (Y) для пикселей в выделенном блоке из предыдущего изображения. Квантованная и кодированная линейная модель аппроксимирована и наложена в виде линии на диаграмму рассеяния. Обратите внимание, что аппроксимация состоит из двух линий; в этом примере они накладываются друг на друга.
Ну, хорошо, у нас две линии — одна для канала U (разница с синим, Cb) и одна для канала V (разница с красным, Cr). Другими словами, если
 — это восстановленные значения яркости, то мы вычисляем значения цветности следующим образом:
— это восстановленные значения яркости, то мы вычисляем значения цветности следующим образом:

Как выглядят эти параметры? Каждая
 соответствует определённому тону (и антитону) из двухмерной палитры, которые масштабируются и применяются в соответствии с показателем яркости:
соответствует определённому тону (и антитону) из двухмерной палитры, которые масштабируются и применяются в соответствии с показателем яркости:
Параметры
в CfL выбирают тон для раскрашивания блока из двухмерной палитры.Значения
 изменяют точку пересечения нуля для цветовой шкалы, то есть это кнопки для переключения минимального и максимального уровня насыщенности при раскрашивании. Обратите внимание, что позволяет применить отрицательный цвет. Это противоположное значение тону, выбранному параметром .
изменяют точку пересечения нуля для цветовой шкалы, то есть это кнопки для переключения минимального и максимального уровня насыщенности при раскрашивании. Обратите внимание, что позволяет применить отрицательный цвет. Это противоположное значение тону, выбранному параметром .Теперь наша задача сводится к выбору правильных
и , а затем их кодированию. Вот один пример прямолинейного неявного подхода для прогнозирования цветности по яркости в AV1:
Выглядит страшнее, чем есть на самом деле. Если перевести на нормальный язык: выполните аппроксимацию наименьших квадратов значений цветности по восстановленным значениями яркости, чтобы найти
, затем используйте для решения смещения цветности . По крайней мере, это один из возможных способов аппроксимации. Он часто используется в реализациях CfL (таких как LM Mode и Thor), которые не передают сигнал ни , ни . В этом случае аппроксимация выполняется с использованием значений цветности соседних пикселей, которые уже были полностью декодированы.CfL в Daala
Daala выполняет всё прогнозирование в частотной области, включая CfL, предоставляя вектор прогнозирования как одно из входных значений для кодирования PVQ. PVQ — это кодирование усиления/контуров (gain/shape encoding). Вектор яркости PVQ кодирует расположение контуров и границ в яркости, и мы просто повторно используем его в качестве предиктора для контуров и границ цветности.
Кодеку Daala не нужно кодировать значение
, так как оно попадает в коэффициент усиления PVQ (за исключением знака). Daala также не нужно кодировать значение : поскольку Daala применяет CfL только к коэффициентам цветности AC, всегда равно нулю. Это даёт нам инсайт: концептуально является просто DC-смещением значений цветности.Фактически, поскольку кодек Daala использует PVQ для кодирования блоков преобразования, он получает CfL практически без затрат, как с точки зрения битов, так и с точки зрения дополнительных вычислений в кодере и декодере.
CfL в AV1
AV1 не принял PVQ, поэтому стоимость CfL примерно одинакова при вычислении в пиксельной или частотной области; больше нет особого бонуса за работу в частотной области. Кроме того, частотновременное переключение разрешения TF (Time-Frequency resolution switching), которое использует Daala для склеивания наименьших блоков яркости и создания достаточно больших субдискретизированных блоков цветности, в настоящее время работает только с преобразованиями DCT и Уолша-Адамара. Поскольку AV1 использует ещё дискретное синусное преобразование и преобразование пиксельной области (pixel domain identity transform), мы не можем легко выполнить AV1 CfL в частотной области, по крайней мере при использовании субдискретизированной цветности.
Но, в отличие от Daala, AV1 не нуждается в выполнении CfL в частотной области. Так что для AV1 мы перемещаем CfL из частотной области обратно в пиксельную область. Это одна из замечательных особенностей CfL — основные уравнения одинаково работают в обеих областях.
CfL в AV1 должен свести сложность реконструкции к минимуму. По этой причине мы явно кодируем
, чтобы в декодере не происходило затратной аппроксимации наименьших квадратов. Затраты битов на явное кодирование более чем окупаются дополнительной точностью, полученной при вычислении с использованием пикселей цветности текущего блока вместо соседних реконструированных пикселей цветности.Затем мы оптимизируем сложность аппроксимации на стороне кодера. Daala работает в частотной области, поэтому мы выполняем CfL только с AC-коэффициентами яркости. AV1 выполняет аппроксимацию CfL в пиксельной области, но мы можем вычесть среднее (то есть уже вычисленное значение DC) из каждого пикселя, что приводит значения пикселей к нулевому среднему, эквиваленту вклада коэффициента AC в Daala. Нулевые средние значения яркости сокращают значительную часть уравнения наименьших квадратов, значительно уменьшая издержки на вычисление:

Мы можем оптимизировать ещё больше. Ведь
— это просто DC-смещение цветности, так что кодер и декодер уже выполняют DC-прогнозирование для плоскостей цветности, поскольку это необходимо для других режимов прогнозирования. Конечно, прогнозное значение DC не будет таким точным, как явно закодированное значение DC/, но тесты показали, что оно всё равно неплохо выглядит: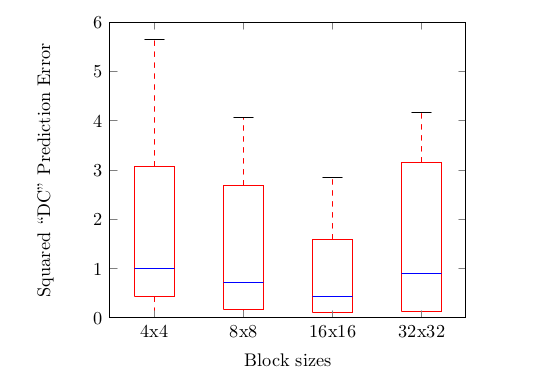
Анализ ошибок дефолтного DC-предиктора по соседним пикселям и кодирования явного значения
по пикселям в текущем блоке.В результате мы просто используем уже существующий прогноз цветности DC вместо
. Теперь не только пропадает необходимость кодировать , но вообще не нужно явно вычислять из ни в кодере, ни в декодере. Таким образом, наше окончательное уравнение прогнозирования CfL сводится к следующему: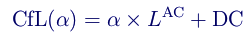
В тех случаях, когда одного лишь предсказания недостаточно для точного результата, мы кодируем остаточную область преобразований. И конечно, когда прогнозирование не даёт вообще никакой выгоды в битах, мы его просто не используем.
Результаты
Как и в любом методе прогнозирования, эффективность CfL зависит от выбора теста. AOM использует ряд стандартизированных наборов тестов, размещённых на Xiph.Org и доступных через автоматизированный инструмент тестирования «Мы уже сжаты?» (“Are We Compressed Yet?”, AWCY).
CfL — это техника внутрикадрового прогнозирования. Чтобы лучше оценить её эффективность на опорных кадрах, возьмём тестовый набор изображений subset-1:
| BD-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Среднее | -0.53 | -0.31 | -0.34 | -4.87 | -12.87 | -10.75 | -0.34 |
Большинство этих метрик не чувствительны к цвету. Они просто всегда включены, и приятно видеть, что техника CfL не вредит им. Конечно, она и не должна, ведь более эффективное кодирование цвета одновременно освобождает биты, которые можно использовать для лучшего представления яркости.
Тем не менее, есть смысл посмотреть на показатель CIE delta-E 2000; он показывает метрику перцептивно-равномерной ошибки цвета. Мы видим, что CfL экономит почти 5% в битрейта с учётом и яркости, и цветности! Это ошеломляющей результат для единственного метода прогнозирования.
CfL также доступен для внутрикадровых блоков внутри промежуточных кадров. Во время разработки AV1 набор objective-1-fast был стандартным тестовым набором для оценки показателей последовательностей движения:
| BD-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Среднее | -0.43 | -0.42 | -0.38 | -2.41 | -5.85 | -5.51 | -0.40 |
| 1080p | -0.32 | -0.37 | -0.28 | -2.52 | -6.80 | -5.31 | -0.31 |
| 1080p-screen | -1.82 | -1.72 | -1.71 | -8.22 | -17.76 | -12.00 | -1.75 |
| 720p | -0.12 | -0.11 | -0.07 | -0.52 | -1.08 | -1.23 | -0.12 |
| 360p | -0.15 | -0.05 | -0.10 | -0.80 | -2.17 | -6.45 | -0.04 |
Как и ожидалось, мы по-прежнему видим солидный прирост, хотя вклад CfL несколько ослаблен из-за преобладания интерполяции. Внутрикадровые блоки используются в основном в опорных кадрах, каждая из этих тестовых последовательностей кодирует только один опорный кадр и внутрикадровое кодирование не часто используется в промежуточных кадрах.
Явное исключение — контент “1080p-screen”, где мы видим колоссальное снижение битрейта на 8%. Это логично, ведь значительная часть скринкастов довольно статичны, а если область меняется, то почти всегда это крупное обновление, подходящее для внутрикадрового кодирования, а не плавное движение, подходящее для межкадрового кодирования. В этих скринкастах активнее кодируются внутрикадровые блоки — и поэтому сильнее заметна выгода от CfL.
Это относится и к синтетическому контенту, и к рендерингу:
| BD-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Twitch | -1.01 | -0.93 | -0.90 | -5.74 | -15.58 | -9.96 | -0.81 |
Тестовый набор Twitch полностью состоит из трансляций видеоигр, и здесь мы тоже видим солидное сокращение битрейта.
Конечно, предсказание цветности по яркости — не единственная техника, которую впервые откроет для массового использования кодек AV1. В следующей статье мы рассмотрим действительно совершенно новую технику из AV1: фильтр с фиксированным направленным усилением (Constrained Directional Enhancement Filter).
Автор: Monty (monty@xiph.org, cmontgomery@mozilla.com). Опубликовано 9 апреля 2018 года.
* Есть возможность «размазать» опорный кадр по другим кадрам, используя прокат I-кадра (rolling intra). В случае проката отдельные опорные кадры делятся на отдельные блоки, которые рассеиваются среди предшествующих опорных кадров. Вместо поиска опорного кадра и начала воспроизведения с этой точки кодек с поддержкой проката I-кадров ищет первый предыдущий блок, считывает все остальные необходимые фрагменты опорного кадра и начинает воспроизведение после сбора достаточного количества информации для восстановления полного опорного кадра. Прокат I-кадра не улучшает сжатие; он просто размазывает всплески битрейта, вызванные большими опорными кадрами. Его также можно использовать для повышения устойчивости к ошибкам. [вернуться]
† Технически, энергия — это произведение мощности на время. При сравнении яблок и апельсинов важно выражать оба фрукта в ватт-часах. [вернуться]
Дополнительные ресурсы
- Проектный документ Альянса за открытые медиа: CfL в AV1, Люк Трюдо, Дэвид Майкл Барр
- Основополагающая научная статья по прогнозированию цветности по яркости в пространственной области: «Метод внутрикадрового прогнозирования, основанный на линейной связи между каналами во внутрикадровом кодировании YUV 4:2:0», Сан Хен Ли, 16-я международная конференция IEEE по обработке изображений (ICIP), 2009
- Предложение LG включить пространственное прогнозирование CfL в HEVC: «Новая техника внутрикадрового прогнозирования цветности с использованием межканальной корреляции», Ким и др., 2010
- Совместное предложение Samsung и LG по LM Mode в HEVC: «Внутрикадровое прогнозирование цветности по реконструированным образцам яркости», Ким и др., 2011
- Реализация CfL в Daala: «Прогнозирование цветности по яркости во внутрикадровой частотной области», Натан Эгги, Жан-Марк Валин, 10 марта 2016 г.
- «Прогнозирование цветности по яркости в AV1», Люк Трюдо, Натан Эгги, Дэвид Барр, 17 января 2018 г.
- Демо-страница частотновременного переключения разрешения в Daala
- Демо-страница CfL в Daala
- Презентация CfL с конференции VideoLan Dev Days 2017: «CfL в AV1», Люк Трюдо, Дэвид Барр, сентябрь 2017 г.
- Презентация с Конференции по сжатию данных: «Внутрикадровое прогнозирование CfL для AV1», Люк Трюдо, Натан Эгги, Дэвид Барр, март 2018 г.
- Стандартные наборы тестов 'derf' от Xiph.Org на media.xiph.org
- Система автоматизированного тестирования и метрик, используемых при разработке Daala и AV1: «Мы уже сжаты?»

