
Один из главных источников данных для сервиса Яндекс.Карты — спутниковые снимки. Чтобы с картой было удобно работать, на снимках многоугольниками размечаются объекты: леса, водоёмы, улицы, дома и т. п. Обычно разметкой занимаются специалисты-картографы. Мы решили помочь им и научить компьютер добавлять многоугольники домов без участия людей.
За операции с изображениями отвечает область ИТ, которая называется компьютерным зрением. Последние несколько лет большую часть задач из этой области очень удачно решают, применяя нейронные сети. О нашем опыте применения нейронных сетей в картографировании мы и расскажем сегодня читателям Хабра.

Первым делом натренируем нейронную сетку, которая займётся семантической сегментацией, т. е. определит, относится ли каждая точка на спутниковом снимке к дому. Почему семантическая сегментация, а не просто детектирование объектов? Когда задача обнаружения будет решена, мы получим на выходе набор прямоугольников, причём специфических: две стороны вертикальные, две горизонтальные. А дома обычно повёрнуты относительно осей изображения, а у некоторых зданий ещё и сложная форма.
Задачу семантической сегментации сейчас решают различные сети (FCN, SegNet, UNet и т. п.). Надо только выбрать, какая из них лучше нам подходит.
Получив маску по спутниковому снимку, мы выделим достаточно большие скопления точек, принадлежащих домам, соберём их в связные области и представим границы областей в векторной форме в виде многоугольников.
Понятно, что маска не будет абсолютно точной, а значит, близко стоящие дома могут склеиться в одну связную область. Чтобы справиться с этой проблемой, мы решили дополнительно натренировать сеть. Она отыщет на изображении рёбра (границы домов) и разделит здания, которые склеились.
Итак, вырисовывалась такая схема:

Мы не стали полностью отбрасывать детектирующие сети и попробовали Mask R-CNN. Её плюс в сравнении с обычной сегментацией в том, что Mask R-CNN и обнаруживает объекты, и генерирует маску, поэтому не надо возиться с разделением общей маски на связные области. Ну а минус (как без него) в фиксированном разрешении маски каждого объекта, т. е. для больших домов со сложной границей эта граница заведомо получится упрощённой.
Затем следовало определиться с инструментами. Здесь всё было достаточно очевидно: для задач компьютерного зрения лучше всего подходит OpenCV. Выбор нейронных сетей несколько шире. Мы остановились на Tensorflow. Её плюсы:
Для тренировок и прочих тяжёлых вычислений планировали применять Нирвану — чудесную платформу Яндекса, о которой мы уже рассказывали.
Успех в работе с нейронной сетью процентов на восемьдесят состоит из хорошего датасета. А значит, для начала нам следовало собрать такой датасет. В Яндексе имеется огромное количество спутниковых снимков с уже размеченными объектами. Кажется, всё просто: достаточно выгрузить эти данные и собрать в датасет. Однако есть один нюанс.
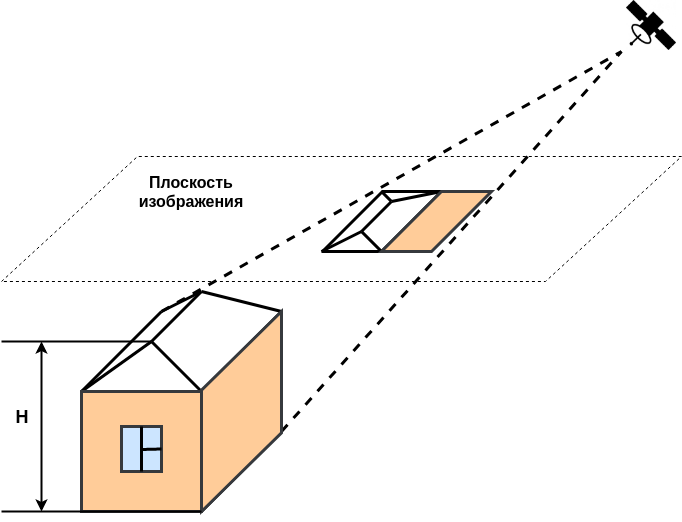
Когда человек ищет дома на спутниковом снимке, то первым делом он замечает крыши. Но высота домов различается, спутник может снять одну и ту же местность с разных углов — и если мы поместим на векторную карту многоугольник, соответствующий крыше, то нет гарантий, что при обновлении снимка крыша не уедет. А вот фундамент врыт в землю и, с какого угла его ни снимай, всё время остаётся на одном месте. Именно поэтому дома на векторной Яндекс.Карте размечены «по фундаментам». Это правильно, но для задачи сегментирования снимков лучше научить сеть искать крыши: надежда, что сетка натренируется распознавать фундаменты, очень невелика. Поэтому в датасете всё должно быть размечено по крышам. Значит, чтобы создать хороший датасет, нам надо научиться сдвигать векторную разметку домиков от фундаментов к крышам.
Мы пробовали и не сдвигать, но качество получалось очень не очень, и это понятно: углы съёмки спутника разные, высоты домов разные, в итоге на фотографиях фундамент смещался в разные стороны и на разное расстояние от крыши. Сеть теряется от такого разнообразия и в лучшем случае тренируется на что-то среднее, в худшем — на что-то непонятное. Причём сеть для семантической сегментации выдаёт результат, похожий на что-то приемлемое, но при поиске рёбер качество падает драматически.
Раз уж мы залезли в область компьютерного зрения, то первым делом опробовали подход, релевантный этому самому компьютерному зрению. Cначала векторная карта растеризуется (многоугольники домиков отрисовываются белыми линиями на чёрном фоне), фильтр Собеля выделяет рёбра на спутниковом снимке. А затем находится смещение двух изображений относительно друг друга, которое максимизирует корреляцию между ними. Рёбра после фильтра Собеля довольно шумные, поэтому, если применять данный подход к одному зданию, не всегда получается приемлемый результат. Однако метод хорошо работает на территориях со зданиями одинаковой высоты: если искать смещение сразу по большому участку изображения, результат будет более стабильный.

Если территория застроена не однотипными, а разнообразными домами, предыдущий метод не подойдёт. К счастью, иногда мы знаем высоту зданий на векторной карте Яндекса и положение спутника во время съёмки. Таким образом, мы можем воспользоваться школьными знаниями геометрии и сосчитать, куда и на какое расстояние сдвинется крыша относительно фундамента. Этот способ позволил улучшить датасет на территориях с высотными зданиями.

Самый трудоёмкий способ: засучить рукава, расчехлить мышку, уставиться в монитор и вручную сдвинуть векторную разметку домиков от фундаментов к крышам. Методика приносит просто потрясающий по качеству результат, но применять её в больших количествах не рекомендуется: разработчики, занятые такими задачами, быстро впадают в апатию и теряют интерес к жизни.
В итоге мы получили достаточно спутниковых снимков, хорошо размеченных по крышам. А значит, появился шанс натренировать нейронную сеть (пока, правда, не для сегментации, а для улучшения разметки других спутниковых снимков). И мы это сделали.
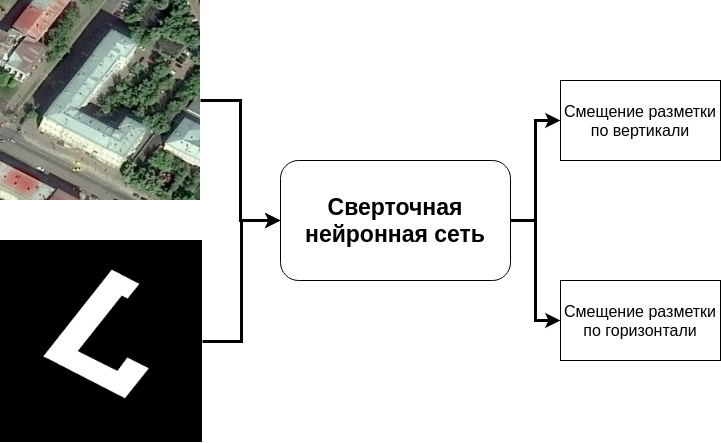
Входными данными свёрточной нейронной сети были спутниковый снимок и смещённая растеризованная разметка. На выходе мы получали двухмерный вектор: смещения по вертикали и горизонтали.
С помощью нейронной сети мы нашли необходимое смещение, что позволило добиться хороших результатов на зданиях, у которых не указана высота. В итоге мы значительно сократили исправление разметки вручную.

На Яндекс.Картах есть множество интересных территорий и государств. Но даже в России дома крайне разнообразны, что сказывается на том, как они выглядят на спутниковых снимках. Значит, надо отразить разнообразие в датасете. Причём изначально мы не очень понимали, как правильно справляться со всем этим великолепием. Собирать огромный датасет и потом тренировать на нём одну сеть? Делать свой датасет для каждого (условного) типа застройки и обучать отдельную сеть? Тренировать некую базовую сеть и потом дотренировывать её под конкретный тип застройки?

Опытным путём мы выяснили, что:

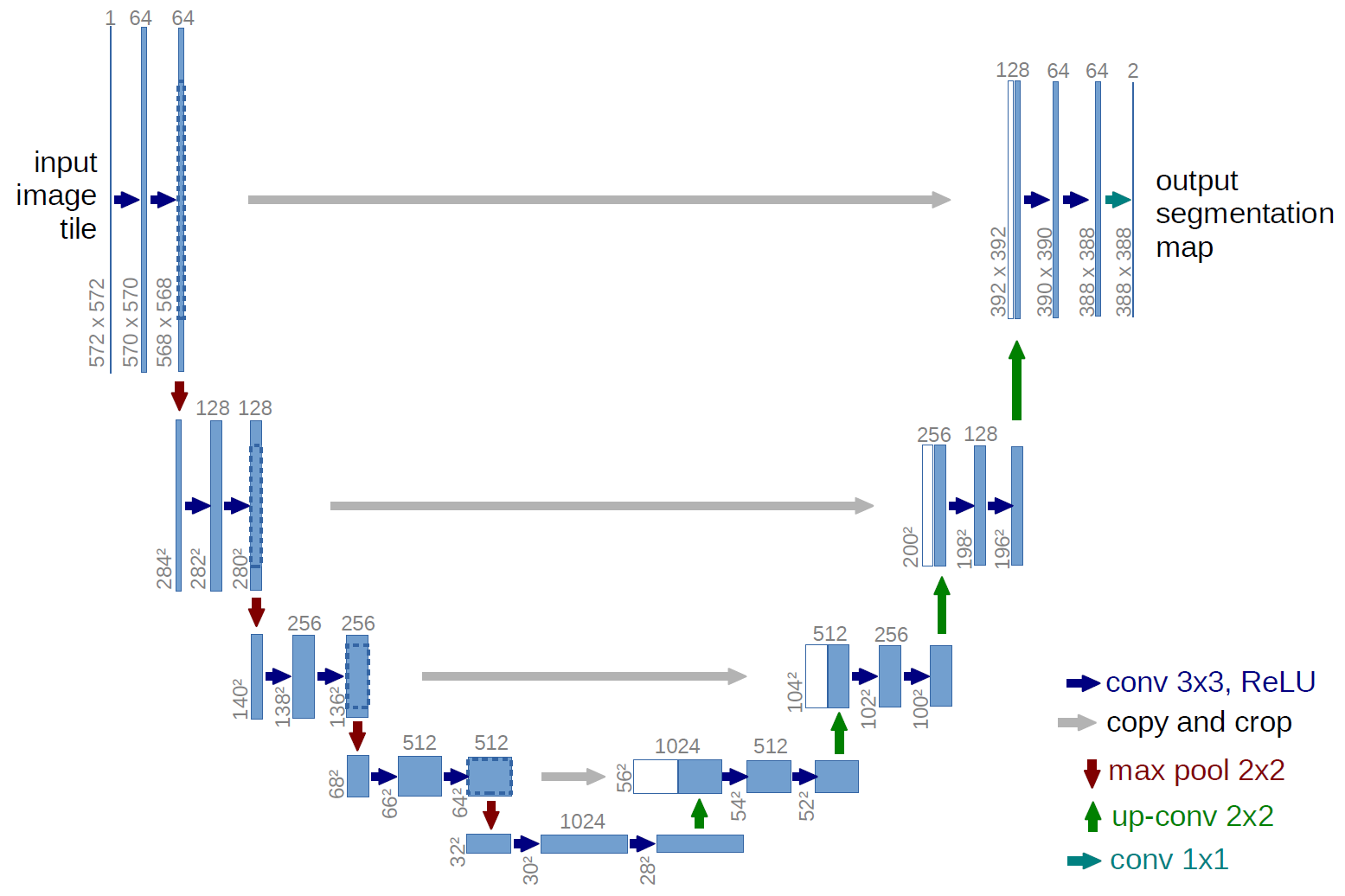
Семантическая сегментация — достаточно хорошо исследованная задача. После появления статьи Fully Convolutional Networks она в основном решается при помощи нейронных сетей. Остаётся только выбрать сеть (мы рассматривали FCN, SegNet и UNet), подумать, нужны ли нам дополнительные ухищрения типа CRF на выходе, и определиться, как и с какой функцией ошибки будет проходить обучение.
В итоге остановились на U-Net-подобной архитектуре с обобщенной функцией Intersection Over Union в качестве функции ошибки. Для тренировки нарезали спутниковые снимки и соответствующую им разметку (естественно, растеризованную) на квадраты и собрали в датасеты. Получилось вполне миленько, а иногда так и просто отлично.

На территориях с одиночными зданиями семантической сегментации оказалось достаточно для перехода к следующему этапу — векторизации. Там, где застройка плотная, дома иногда склеивались в связную область. Потребовалось разделить их.
Чтобы справиться с этой задачей, можно найти рёбра на изображении. Для детектирования рёбер мы решили тоже обучить сеть (алгоритмы поиска рёбер, не использующие нейронные сети, явно уходят в прошлое). Тренировали сеть типа HED, которая описана в работе Holistically-Nested Edge Detection. В оригинальной статье сеть обучалась на наборе данных BSDS-500, в котором на изображениях размечены все рёбра. Обученная сеть находит все явно выраженные рёбра: границы домов, дорог, озёр и т. д. Этого уже хватало, чтобы разделить близко стоящие здания. Но мы решили пойти дальше и использовать для обучения тот же датасет, что и для семантической сегментации, только при растеризации не закрашивать многоугольники зданий целиком, а отрисовывать лишь их границы.
Результат оказался настолько ошеломляюще прекрасен, что мы решили векторизовать здания непосредственно по рёбрам, полученным от сети. И это вполне получилось.

Поскольку сеть типа HED дала отличный результат на рёбрах, мы решили натренировать её же для обнаружения вершин. Фактически у нас получилась сеть с общими весами на свёрточных слоях. У неё было два выхода одновременно: для рёбер и для вершин. В итоге мы сделали ещё один вариант векторизации зданий, и в некоторых случаях он показывал вполне вменяемые результаты.

Mask R-CNN — это относительно новое расширение сетей типа Faster R-CNN. Mask R-CNN ищет объекты и выделяет для каждого из них маску. В результате для домов мы получим не только ограничивающие прямоугольники, но и уточнённую структуру. Этот подход выгодно отличается от простого детектирования (мы не знаем, как здание расположено внутри прямоугольника) и от обычной сегментации (несколько домов могут склеиться в один, и непонятно, как их разделять). С Mask R-CNN уже не надо думать о дополнительных ухищрениях: достаточно векторизовать границу маски для каждого объекта и сразу получить результат. Есть и минус: размер маски для объекта всегда фиксированный, т. е. для больших зданий точность разметки пикселей будет низкой. Результат работы Mask R-CNN выглядит так:

Мы попробовали Mask R-CNN последним и убедились, что для некоторых типов застройки этот подход выигрывает у других.
При всём современном архитектурном разнообразии дома на спутниковых снимках до сих пор чаще всего выглядят как прямоугольники. Более того, для массы территорий не нужна разметка сложными многоугольниками. Но всё же хочется, чтобы дома на карте были размечены. (Ну, например, садоводческое товарищество: домов там обычно много, вручную размечать — не настолько актуально, но обозначить прямоугольниками на карте очень неплохо.) Поэтому первый подход к векторизации был крайне простой.
Понятно, что качество такого подхода далеко от идеального. Однако алгоритм достаточно простой и при этом во многих случаях рабочий.
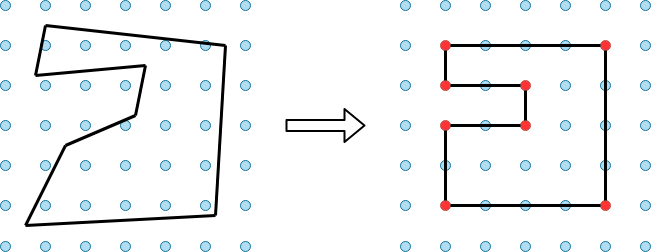
Если качество сегментации достаточно хорошее, можно более точно воссоздать контур дома. У большинства зданий сложной формы углы в основном прямые, поэтому мы решили свести задачу к задаче построения многоугольника с ортогональными сторонами. Решая её, мы хотим добиться сразу двух целей: найти наиболее простой многоугольник и как можно точнее повторить форму зданий. Эти цели конфликтуют между собой, поэтому приходится вводить дополнительные условия: ограничивать минимальную длину стен, максимальное отклонение от растровой области и т. д.
Алгоритм, который первым пришёл нам в голову, был основан на построении проекции точек на прямые:
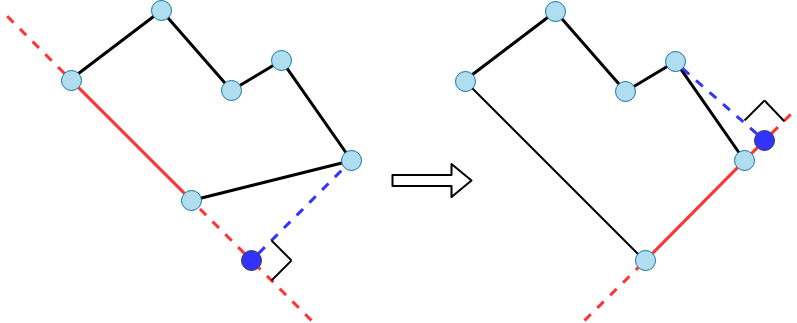
Данный алгоритм крайне прост и быстро приносит результат, но всё же контур здания иногда получается довольно зашумленным. Пытаясь справиться с этой проблемой, мы наткнулись на довольно интересный вариант решения задачи, который использует квадратную сетку в пространстве для приближения многоугольника. Если описывать кратко, то алгоритм состоит из трёх действий:
Так как необходимый угол поворота сетки заранее неизвестен, приходится перебирать несколько значений, что плохо сказывается на производительности. Однако алгоритм позволяет добиться более визуально красивых результатов.

Пока мы фактически работали с каждым домом отдельно. Когда первый этап пройден, можно поработать уже с картиной в целом и улучшить результат. Для этого был добавлен алгоритм постобработки набора многоугольников. Мы воспользовались следующими эвристиками:
В результате появился такой алгоритм:
В результате мы получили инструмент, способный распознавать здания различных типов застройки. Он помогает картографам в их нелёгкой работе: значительно ускоряет поиск пропущенных домов и заполнение новых, ещё не обработанных территорий. На данный момент с помощью этого инструмента в Народную карту добавлено уже более 800 тысяч новых объектов.
Ниже вы увидите несколько примеров распознавания.







За операции с изображениями отвечает область ИТ, которая называется компьютерным зрением. Последние несколько лет большую часть задач из этой области очень удачно решают, применяя нейронные сети. О нашем опыте применения нейронных сетей в картографировании мы и расскажем сегодня читателям Хабра.
Первым делом натренируем нейронную сетку, которая займётся семантической сегментацией, т. е. определит, относится ли каждая точка на спутниковом снимке к дому. Почему семантическая сегментация, а не просто детектирование объектов? Когда задача обнаружения будет решена, мы получим на выходе набор прямоугольников, причём специфических: две стороны вертикальные, две горизонтальные. А дома обычно повёрнуты относительно осей изображения, а у некоторых зданий ещё и сложная форма.
Задачу семантической сегментации сейчас решают различные сети (FCN, SegNet, UNet и т. п.). Надо только выбрать, какая из них лучше нам подходит.
Получив маску по спутниковому снимку, мы выделим достаточно большие скопления точек, принадлежащих домам, соберём их в связные области и представим границы областей в векторной форме в виде многоугольников.
Понятно, что маска не будет абсолютно точной, а значит, близко стоящие дома могут склеиться в одну связную область. Чтобы справиться с этой проблемой, мы решили дополнительно натренировать сеть. Она отыщет на изображении рёбра (границы домов) и разделит здания, которые склеились.
Итак, вырисовывалась такая схема:
Мы не стали полностью отбрасывать детектирующие сети и попробовали Mask R-CNN. Её плюс в сравнении с обычной сегментацией в том, что Mask R-CNN и обнаруживает объекты, и генерирует маску, поэтому не надо возиться с разделением общей маски на связные области. Ну а минус (как без него) в фиксированном разрешении маски каждого объекта, т. е. для больших домов со сложной границей эта граница заведомо получится упрощённой.
Инструменты
Затем следовало определиться с инструментами. Здесь всё было достаточно очевидно: для задач компьютерного зрения лучше всего подходит OpenCV. Выбор нейронных сетей несколько шире. Мы остановились на Tensorflow. Её плюсы:
- достаточно развитый набор готовых «кубиков», из которых можно собирать свои сети;
- Python API, удобный для быстрого создания структуры сети и для тренировки;
- натренированную сеть можно использовать в своей программе через C++ интерфейс (сильно небогатый по сравнению с Python-частью, но вполне достаточный для запуска готовых сетей).
Для тренировок и прочих тяжёлых вычислений планировали применять Нирвану — чудесную платформу Яндекса, о которой мы уже рассказывали.
Датасет
Успех в работе с нейронной сетью процентов на восемьдесят состоит из хорошего датасета. А значит, для начала нам следовало собрать такой датасет. В Яндексе имеется огромное количество спутниковых снимков с уже размеченными объектами. Кажется, всё просто: достаточно выгрузить эти данные и собрать в датасет. Однако есть один нюанс.
Уточнение датасета
Когда человек ищет дома на спутниковом снимке, то первым делом он замечает крыши. Но высота домов различается, спутник может снять одну и ту же местность с разных углов — и если мы поместим на векторную карту многоугольник, соответствующий крыше, то нет гарантий, что при обновлении снимка крыша не уедет. А вот фундамент врыт в землю и, с какого угла его ни снимай, всё время остаётся на одном месте. Именно поэтому дома на векторной Яндекс.Карте размечены «по фундаментам». Это правильно, но для задачи сегментирования снимков лучше научить сеть искать крыши: надежда, что сетка натренируется распознавать фундаменты, очень невелика. Поэтому в датасете всё должно быть размечено по крышам. Значит, чтобы создать хороший датасет, нам надо научиться сдвигать векторную разметку домиков от фундаментов к крышам.
Мы пробовали и не сдвигать, но качество получалось очень не очень, и это понятно: углы съёмки спутника разные, высоты домов разные, в итоге на фотографиях фундамент смещался в разные стороны и на разное расстояние от крыши. Сеть теряется от такого разнообразия и в лучшем случае тренируется на что-то среднее, в худшем — на что-то непонятное. Причём сеть для семантической сегментации выдаёт результат, похожий на что-то приемлемое, но при поиске рёбер качество падает драматически.
«Растровый» подход
Раз уж мы залезли в область компьютерного зрения, то первым делом опробовали подход, релевантный этому самому компьютерному зрению. Cначала векторная карта растеризуется (многоугольники домиков отрисовываются белыми линиями на чёрном фоне), фильтр Собеля выделяет рёбра на спутниковом снимке. А затем находится смещение двух изображений относительно друг друга, которое максимизирует корреляцию между ними. Рёбра после фильтра Собеля довольно шумные, поэтому, если применять данный подход к одному зданию, не всегда получается приемлемый результат. Однако метод хорошо работает на территориях со зданиями одинаковой высоты: если искать смещение сразу по большому участку изображения, результат будет более стабильный.
«Геометрический» подход
Если территория застроена не однотипными, а разнообразными домами, предыдущий метод не подойдёт. К счастью, иногда мы знаем высоту зданий на векторной карте Яндекса и положение спутника во время съёмки. Таким образом, мы можем воспользоваться школьными знаниями геометрии и сосчитать, куда и на какое расстояние сдвинется крыша относительно фундамента. Этот способ позволил улучшить датасет на территориях с высотными зданиями.
«Ручной» подход
Самый трудоёмкий способ: засучить рукава, расчехлить мышку, уставиться в монитор и вручную сдвинуть векторную разметку домиков от фундаментов к крышам. Методика приносит просто потрясающий по качеству результат, но применять её в больших количествах не рекомендуется: разработчики, занятые такими задачами, быстро впадают в апатию и теряют интерес к жизни.
Нейронная сеть
В итоге мы получили достаточно спутниковых снимков, хорошо размеченных по крышам. А значит, появился шанс натренировать нейронную сеть (пока, правда, не для сегментации, а для улучшения разметки других спутниковых снимков). И мы это сделали.
Входными данными свёрточной нейронной сети были спутниковый снимок и смещённая растеризованная разметка. На выходе мы получали двухмерный вектор: смещения по вертикали и горизонтали.
С помощью нейронной сети мы нашли необходимое смещение, что позволило добиться хороших результатов на зданиях, у которых не указана высота. В итоге мы значительно сократили исправление разметки вручную.
Разные территории — разные дома
На Яндекс.Картах есть множество интересных территорий и государств. Но даже в России дома крайне разнообразны, что сказывается на том, как они выглядят на спутниковых снимках. Значит, надо отразить разнообразие в датасете. Причём изначально мы не очень понимали, как правильно справляться со всем этим великолепием. Собирать огромный датасет и потом тренировать на нём одну сеть? Делать свой датасет для каждого (условного) типа застройки и обучать отдельную сеть? Тренировать некую базовую сеть и потом дотренировывать её под конкретный тип застройки?
Опытным путём мы выяснили, что:
- Несомненно, надо расширять датасет под разные типы застройки, на которых планируется применять инструмент. Сеть, обученная на одном типе, способна выделять здания другого типа, хотя очень некачественно.
- Лучше тренировать одну большую сеть на всём наборе данных. Она довольно хорошо обобщается на различные территории. Если обучать отдельные сети для каждого типа застройки, качество либо останется прежним, либо едва-едва повысится. Так что внедрять разные сети для разных территорий бессмысленно. К тому же это требует большего количества данных и дополнительного классификатора типа застройки.
- Если использовать старые сети при добавлении новых территорий в данные, сети обучаются значительно быстрее. Дообучение старых сетей на расширенных данных приводит примерно к тому же результату, что и обучение сети с нуля, однако требует намного меньше времени.
Варианты решения
Семантическая сегментация
Семантическая сегментация — достаточно хорошо исследованная задача. После появления статьи Fully Convolutional Networks она в основном решается при помощи нейронных сетей. Остаётся только выбрать сеть (мы рассматривали FCN, SegNet и UNet), подумать, нужны ли нам дополнительные ухищрения типа CRF на выходе, и определиться, как и с какой функцией ошибки будет проходить обучение.
В итоге остановились на U-Net-подобной архитектуре с обобщенной функцией Intersection Over Union в качестве функции ошибки. Для тренировки нарезали спутниковые снимки и соответствующую им разметку (естественно, растеризованную) на квадраты и собрали в датасеты. Получилось вполне миленько, а иногда так и просто отлично.
На территориях с одиночными зданиями семантической сегментации оказалось достаточно для перехода к следующему этапу — векторизации. Там, где застройка плотная, дома иногда склеивались в связную область. Потребовалось разделить их.
Детектирование рёбер
Чтобы справиться с этой задачей, можно найти рёбра на изображении. Для детектирования рёбер мы решили тоже обучить сеть (алгоритмы поиска рёбер, не использующие нейронные сети, явно уходят в прошлое). Тренировали сеть типа HED, которая описана в работе Holistically-Nested Edge Detection. В оригинальной статье сеть обучалась на наборе данных BSDS-500, в котором на изображениях размечены все рёбра. Обученная сеть находит все явно выраженные рёбра: границы домов, дорог, озёр и т. д. Этого уже хватало, чтобы разделить близко стоящие здания. Но мы решили пойти дальше и использовать для обучения тот же датасет, что и для семантической сегментации, только при растеризации не закрашивать многоугольники зданий целиком, а отрисовывать лишь их границы.
Результат оказался настолько ошеломляюще прекрасен, что мы решили векторизовать здания непосредственно по рёбрам, полученным от сети. И это вполне получилось.
Детектирование вершин
Поскольку сеть типа HED дала отличный результат на рёбрах, мы решили натренировать её же для обнаружения вершин. Фактически у нас получилась сеть с общими весами на свёрточных слоях. У неё было два выхода одновременно: для рёбер и для вершин. В итоге мы сделали ещё один вариант векторизации зданий, и в некоторых случаях он показывал вполне вменяемые результаты.
Mask R-CNN
Mask R-CNN — это относительно новое расширение сетей типа Faster R-CNN. Mask R-CNN ищет объекты и выделяет для каждого из них маску. В результате для домов мы получим не только ограничивающие прямоугольники, но и уточнённую структуру. Этот подход выгодно отличается от простого детектирования (мы не знаем, как здание расположено внутри прямоугольника) и от обычной сегментации (несколько домов могут склеиться в один, и непонятно, как их разделять). С Mask R-CNN уже не надо думать о дополнительных ухищрениях: достаточно векторизовать границу маски для каждого объекта и сразу получить результат. Есть и минус: размер маски для объекта всегда фиксированный, т. е. для больших зданий точность разметки пикселей будет низкой. Результат работы Mask R-CNN выглядит так:
Мы попробовали Mask R-CNN последним и убедились, что для некоторых типов застройки этот подход выигрывает у других.
Векторизация
Векторизация прямоугольниками
При всём современном архитектурном разнообразии дома на спутниковых снимках до сих пор чаще всего выглядят как прямоугольники. Более того, для массы территорий не нужна разметка сложными многоугольниками. Но всё же хочется, чтобы дома на карте были размечены. (Ну, например, садоводческое товарищество: домов там обычно много, вручную размечать — не настолько актуально, но обозначить прямоугольниками на карте очень неплохо.) Поэтому первый подход к векторизации был крайне простой.
- Берём растровую область, соответствующую «дому».
- Находим прямоугольник минимальной площади, который содержит эту область (например, вот так: OpenCV::minAreaRect). Задача решена.
Понятно, что качество такого подхода далеко от идеального. Однако алгоритм достаточно простой и при этом во многих случаях рабочий.
Векторизация многоугольниками
Если качество сегментации достаточно хорошее, можно более точно воссоздать контур дома. У большинства зданий сложной формы углы в основном прямые, поэтому мы решили свести задачу к задаче построения многоугольника с ортогональными сторонами. Решая её, мы хотим добиться сразу двух целей: найти наиболее простой многоугольник и как можно точнее повторить форму зданий. Эти цели конфликтуют между собой, поэтому приходится вводить дополнительные условия: ограничивать минимальную длину стен, максимальное отклонение от растровой области и т. д.
Алгоритм, который первым пришёл нам в голову, был основан на построении проекции точек на прямые:
- Найти контур растровой области, соответствующий одному дому.
- Сократить количество точек в контуре, упростив его, например алгоритмом Дугласа-Пекера.
- Найти самую длинную сторону в контуре. Именно её угол наклона определит угол всего будущего ортогонального многоугольника.
- Построить проекцию из следующей точки контура на предыдущую сторону.
- Продлить сторону до точки проекции. Если расстояние от точки до её проекции больше самой короткой стены здания, добавить получившийся отрезок в контур здания.
- Повторять пункты 4 и 5, пока контур не замкнётся.
Данный алгоритм крайне прост и быстро приносит результат, но всё же контур здания иногда получается довольно зашумленным. Пытаясь справиться с этой проблемой, мы наткнулись на довольно интересный вариант решения задачи, который использует квадратную сетку в пространстве для приближения многоугольника. Если описывать кратко, то алгоритм состоит из трёх действий:
- Построить квадратную сетку в пространстве с центром в нуле.
- На точках сетки, которые расположены не дальше некоторого расстояния от исходного контура, построить различные многоугольники.
- Выбрать многоугольник с минимальным количеством вершин.
Так как необходимый угол поворота сетки заранее неизвестен, приходится перебирать несколько значений, что плохо сказывается на производительности. Однако алгоритм позволяет добиться более визуально красивых результатов.
Улучшение векторизации
Пока мы фактически работали с каждым домом отдельно. Когда первый этап пройден, можно поработать уже с картиной в целом и улучшить результат. Для этого был добавлен алгоритм постобработки набора многоугольников. Мы воспользовались следующими эвристиками:
- Обычно стены рядом стоящих домов параллельны. Более того: чаще всего дома можно объединить в наборы, внутри которых все элементы выравнены.
- Если на снимке уже размечены улицы, то весьма вероятно, что стороны многоугольников будут параллельны улицам.
- Если многоугольники пересеклись, то, скорее всего, есть смысл подвигать стены, чтобы пересечение исчезло.
В результате появился такой алгоритм:
- Кластеризуем найденные дома по расстоянию между ними и углу поворота. Усредняем повороты зданий в каждом кластере. Повторяем, пока положение зданий не перестанет меняться или пока дома не начнут слишком сильно отклоняться от начального положения.
- Выбираем дома рядом с дорогами, находим самую протяжённую и близкую к дороге сторону. Поворачиваем дом до параллельности выбранной стороны и дороги.
- Убираем пересечения между многоугольниками, сдвигая стороны двух пересекающихся зданий пропорционально величине сторон.
Результат
В результате мы получили инструмент, способный распознавать здания различных типов застройки. Он помогает картографам в их нелёгкой работе: значительно ускоряет поиск пропущенных домов и заполнение новых, ещё не обработанных территорий. На данный момент с помощью этого инструмента в Народную карту добавлено уже более 800 тысяч новых объектов.
Ниже вы увидите несколько примеров распознавания.
