В этом руководстве я расскажу, как написать собственную виртуальную машину (VM), способную запускать программы на ассемблере, такие как 2048 (моего друга) или Roguelike (моя). Если вы умеете программировать, но хотите лучше понять, что происходит внутри компьютера и как работают языки программирования, то этот проект для вас. Написание собственной виртуальной машины может показаться немного страшным, но я обещаю, что тема удивительно простая и поучительная.
Окончательный код составляет около 250 строк на C. Достаточно знать лишь основы C или C++, такие как двоичная арифметика. Для сборки и запуска подходит любая Unix-система (включая macOS). Несколько API Unix используются для настройки ввода и отображения консоли, но они не являются существенными для основного кода. (Реализация поддержки Windows приветствуется).
Виртуальная машина — это программа, которая действует как компьютер. Она имитирует процессор с несколькими другими аппаратными компонентами, позволяя выполнять арифметику, считывать из памяти и записывать туда, а также взаимодействовать с устройствами ввода-вывода, словно настоящий физический компьютер. Самое главное, VM понимает машинный язык, который вы можете использовать для программирования.
Сколько аппаратного обеспечения имитирует конкретная VM — зависит от её предназначения. Некоторые VM воспроизводят поведение одного конкретного компьютера. У людей больше нет NES, но мы всё ещё можем играть в игры для NES, имитируя аппаратное обеспечение на программном уровне. Эти эмуляторы должны точно воссоздать каждую деталь и каждый основной аппаратный компонент оригинального устройства.
Другие VM не соответствуют никакому конкретному компьютеру, а частично соответствуют сразу нескольким! В первую очередь это делается для облегчения разработки ПО. Представьте, что вы хотите создать программу, работающую на нескольких компьютерных архитектурах. Виртуальная машина даёт стандартную платформу, которая обеспечивает переносимость. Не нужно переписывать программу на разных диалектах ассемблера для каждой архитектуры. Достаточно сделать только небольшую VM на каждом языке. После этого любую программу можно написать лишь единожды на языке ассемблера виртуальной машины.

Виртуальная машина Java (JVM) — очень успешный пример. Сама JVM относительно среднего размера, она достаточно мала для понимания программистом. Это позволяет писать код для тысяч разнообразных устройств, включая телефоны. После реализации JVM на новом устройстве любая написанная программа Java, Kotlin или Clojure может работать на нём без изменений. Единственными затратами будут только накладные расходы на саму VM и дальнейшее абстрагирование от машинного уровня. Обычно это довольно хороший компромисс.
VM не обязательно должна быть большой или вездесущной, чтобы обеспечить аналогичные преимущества. Старые видеоигры часто использовали небольшие VM для создания простых скриптовых систем.
VM также полезны для безопасной изоляции программ. Одно из применений — сборка мусора. Не существует тривиального способа реализовать автоматическую сборку мусора поверх C или C++, так как программа не может видеть собственный стек или переменные. Однако VM находится «вне» запущенной программы и может наблюдать все ссылки на ячейки памяти в стеке.
Ещё один пример такого поведения демонстрируют смарт-контракты Ethereum. Смарт-контракты — это небольшие программы, которые выполняются каждым узлом валидации в блокчейне. То есть операторы разрешают выполнение на своих машинах любых программ, написанных совершенно незнакомыми людьми, без какой-либо возможности изучить их заранее. Чтобы предотвратить вредоносные действия, они выполняются на VM, не имеющей доступа к файловой системе, сети, диску и т.д. Ethereum — также хороший пример переносимости. Благодаря VM можно писать смарт-контракты без учёта особенностей множества платформ.

Наша VM будет симулировать вымышленный компьютер под названием LC-3. Он популярен для обучения студентов ассемблеру. Здесь упрощённый набор команд по сравнению с x86, но сохраняются все основные концепции, которые используются в современных CPU.
Во-первых, нужно сымитировать необходимые аппаратные компоненты. Попытайтесь понять, что представляет собой каждый компонент, но не волнуйтесь, если не уверены, как он вписывается в общую картину. Начнём с создания файла на С. Каждый фрагмент кода из этого раздела следует поместить в глобальную область видимости этого файла.
В компьютере LC-3 есть 65 536 ячеек памяти (216), каждая из которых содержит 16-разрядное значение. Это означает, что он может хранить всего 128 Кб — намного меньше, чем вы привыкли! В нашей программе эта память хранится в простом массиве:
Регистр — это слот для хранения одного значения в CPU. Регистры подобны «верстаку» CPU. Чтобы он мог работать с каким-то фрагментом данных, тот должен находиться в одном из регистров. Но поскольку регистров всего несколько, в любой момент времени можно загрузить только минимальный объём данных. Программы обходят эту проблему, загружая значения из памяти в регистры, вычисляя значения в другие регистры, а затем сохраняя окончательные результаты обратно в память.
В компьютере LC-3 всего 10 регистров, каждый на 16 бит. Большинство из них —общего назначения, но некоторым назначены роли.
Регистры общего назначения могут использоваться для выполнения любых программных вычислений. Счётчик команд представляет собой целое число без знака, которое является адресом в памяти следующей инструкции для выполнения. Флаги условий сообщают нам информацию о предыдущем вычислении.
Как и память, будем хранить регистры в массиве:
Инструкция — это команда, которая говорит процессору выполнить какую-то фундаментальную задачу, например, сложить два числа. У инструкции есть опкод (код операции), указывающий тип выполняемой задачи, а также набор параметров, которые предоставляют входные данные для выполняемой задачи.
Каждый опкод представляет собой одну задачу, которую процессор «знает», как выполнить. В LC-3 всего 16 опкодов. Компьютер может вычислить только последовательность этих простых инструкций. Длина каждой инструкции 16 бит, а левые 4 бита хранят код операции. Остальные используются для хранения параметров.
Позже подробно обсудим, что делает каждая инструкция. На данный момент определите следующие опкоды. Удостоверьтесь, что сохраняют такой порядок, чтобы получать правильное значение enum:
Регистр
У каждого процессора множество флагов состояния для сигнализации о различных ситуациях. LC-3 использует только три флага условий, которые показывают знак предыдущего вычисления.
Мы закончили настройку аппаратных компонентов нашей виртуальной машины! После добавления стандартных включений (см. по ссылке выше) ваш файл должен выглядеть примерно так:
Теперь рассмотрим программу на ассемблере LC-3, чтобы получить представление, что фактически выполняет виртуальная машина. Вам не нужно знать, как программировать на ассемблере, или всё тут понимать. Просто постарайтесь получить общее представление, что происходит. Вот простой «Hello World»:
Как и в C, программа выполняет по одному оператору сверху вниз. Но в отличие от C, здесь нет вложенных областей
Обратите внимание, что имена некоторых операторов соответствуют опкодам, которые мы определили ранее. Мы знаем, что в инструкциях по 16 бит, но каждая строка выглядит как будто с разным количеством символов. Как возможно такое несоответствие?
Это происходит потому что код, который мы читаем, написан на ассемблере — в удобочитаемой и доступной для записи форме обычным текстом. Инструмент, называемый ассемблером, преобразует каждую строку текста в 16-разрядную двоичную инструкцию, понятную виртуальной машине. Эта двоичная форма, которая по сути представляет собой массив 16-разрядных инструкций, называется машинным кодом и фактически выполняется виртуальной машиной.

Команды
Циклы и условия выполняются с помощью goto-подобной инструкции. Вот еще один пример, который считает до 10.
Ещё раз, предыдущие примеры просто дают представление, что делает VM. Для написания VM вам не нужно полное понимание ассемблера. Пока вы следуете соответствующей процедуре чтения и исполнения инструкций, любая программа LC-3 будет корректно работать, независимо от её сложности. В теории, VM может запустить даже браузер или операционную систему, как Linux!
Если глубоко задуматься, то это философски замечательная идея. Сами программы могут производить сколь угодно сложные действия, которые мы никогда не ожидали и, возможно, не сможем понять. Но в то же время вся их функциональность ограничивается простым кодом, который мы напишем! Мы одновременно знаем всё и ничего о том, как работает каждая программа. Тьюринг упоминал эту чудесную идею:
Вот точное описание процедуры, которую нужно написать:
Вы можете задать вопрос: «Но если цикл продолжает увеличивать счётчик в отсутствие
Начнём изучение этого процесса на примере основного цикла:
Теперь ваша задача — сделать правильную реализацию для каждого опкода. Подробная спецификация каждой инструкции содержится в документации проекта. Из спецификации нужно узнать, как работает каждая инструкция, и написать реализацию. Это проще, чем кажется. Здесь я продемонстрирую, как реализовать две из них. Код для остальных можно найти в следующем разделе.
Инструкция
На схеме две строки, потому что для этой инструкции есть два различных «режима». Прежде чем я объясню режимы, давайте попробуем найти сходство между ними. Обе они начинаются с четырёх одинаковых битов
Таким образом, мы знаем, где сохранить результат, и знаем первое число для сложения. Осталось только узнать второе число для сложения. Здесь две строки начинают различаться. Обратите внимание, что вверху 5-й бит равен 0, а внизу — 1. Этот бит соответствует или непосредственному режиму, или регистровому режиму. В регистровом режиме второе число хранится в регистре, как и первое. Оно отмечено как
В непосредственном режиме вместо добавления содержимого регистра непосредственное значение внедряется в саму инструкцию. Это удобно, потому что программе не нужны дополнительные инструкции для загрузки этого числа в регистр из памяти. Вместо этого оно уже внутри инструкции, когда нам нужно. Компромисс в том, что там могут храниться только небольшие числа. Если быть точным, максимум 25=32. Это наиболее полезно для увеличения счётчиков или значений. На ассемблере можно написать так:
Вот выдержка из спецификации:
Это похоже на то, что мы обсуждали. Но что такое «расширение значения»? Хотя в непосредственном режиме у значения только 5 бит, его нужно сложить с 16-разрядным числом. Эти 5 бит следует расширить до 16, чтобы соответствовать другому числу. Для положительных чисел мы можем заполнить недостающие биты нулями и получить такое же значение. Однако для отрицательных чисел это не работает. Например, −1 в пяти битах равно
В спецификации есть последнее предложение:
Ранее мы определили условие flags enum, а теперь пришло время использовать этих флаги. Каждый раз, когда значение записывается в регистр, нам нужно обновить флаги, чтобы указать его знак. Напишем функцию для повторного использования:
Теперь мы готовы написать код для
В этом разделе много информации, поэтому подведём итоги.
Вы можете быть ошеломлены написанием ещё 15 инструкций. Однако полученную здесь информацию можно использовать повторно. В большинстве инструкций используется комбинация расширения значения, различных режимов и обновления флагов.
LDI означает «косвенную» или «непрямую» загрузку (load indirect). Эта инструкция используется для загрузки в регистр значения из места в памяти. Спецификация на стр. 532.
Вот как выглядит двоичная компоновка:

В отличие от
Как и раньше, нужно расширить это 9-битное значение, но на этот раз добавить его к текущему
Это может показаться окольным путём для чтения из памяти, но так нужно. Инструкция
Как и раньше, после записи значения в
Вот код для данного случая: (
Как я уже сказал, для этой инструкции мы использовали значительную часть кода и знаний, полученных ранее при написании
Теперь необходимо реализовать остальные инструкции. Следуйте спецификации и используйте уже написанный код. Код для всех инструкций приведён в конце статьи. Два из перечисленных ранее опкодов нам не понадобятся: это
В этом разделе — полные реализации оставшихся инструкций, если вы застряли.
(не используются)
LC-3 обеспечивает несколько предопределённых подпрограмм для выполнения общих задач и взаимодействия с устройствами ввода-вывода. Например, есть процедуры для получения ввода с клавиатуры и вывода строк на консоль. Они называются программами обработки системных прерываний (trap routines), которые вы можете представлять как операционную систему или API для LC-3. Каждой подпрограмме присваивается код прерывания (trap-код), который её идентифицирует (аналогично опкоду). Для её выполнения вызывается инструкция

Установим enum для каждого кода прерывания:
Вам может быть интересно, почему коды прерываний не включены в инструкции. Это потому что они фактически не добавляют LC-3 никакой новой функциональности, а только обеспечивают удобный способ выполнения задачи (подобно системным функциям в C). В официальном симуляторе LC-3 коды прерываний написаны на ассемблере. При вызове кода прерывания компьютер перемещается по адресу этого кода. CPU выполняет инструкции процедуры, а по завершении
Нет никакой спецификации, как реализовать подпрограммы обработки прерываний: только то, что они должны делать. В нашей VM мы поступим немного иначе, написав их на C. При вызове кода прерывания будет вызвана функция C. После её работы продолжится выполнение инструкции.
Хотя процедуры можно написать на ассемблере и в физическом компьютере LC-3 так и будет, это не лучший вариант для VM. Вместо написания собственных примитивных процедур ввода-вывода можно воспользоваться теми, которые доступны на нашей ОС. Это улучшит работу виртуальной машины на наших компьютерах, упростит код и обеспечит более высокий уровень абстракции для переносимости.
В оператор множественного выбора для опкода
Как и в случае с инструкциями, я покажу, как реализовать одну процедуру, а остальное сделаете сами.
Код прерывания
Чтобы отобразить строку, мы должны дать подпрограмме обработки прерываний строку для отображения. Это делается путём сохранения адреса первого символа в
Из спецификации:
Обратите внимание, что в отличие от строк C, здесь символы хранятся не в одном байте, а по одному расположению в памяти. Расположение в памяти LC-3 составляет 16 бит, поэтому у каждого символа в строке размер 16 бит. Чтобы отобразить это в функции C, нужно преобразовать каждое значение в символ и вывести их по отдельности.
Для данной процедуры больше ничего не требуется. Подпрограммы обработки прерываний довольно просты, если вы знаете C. Теперь вернитесь к спецификации и реализуйте остальные. Как и в случае с инструкциями, полный код можно найти в конце этого руководства.
Этот раздел содержит полные реализации остальных подпрограмм обработки прерываний.
Мы много говорили о загрузке и выполнении инструкций из памяти, но как вообще инструкции попадают в память? При преобразовании ассемблерной программы в машинный код результатом является файл, содержащий массив инструкций и данных. Его можно загрузить, просто скопировав содержимое прямо в адрес в памяти.
Первые 16 бит файла программы указывают адрес в памяти, где следует начать выполнение программы. Этот адрес называется origin. Он должен быть прочитан первым, после чего в память из файла считываются остальные данные.
Вот код для загрузки программы в память LC-3:
Обратите внимание, что для каждого загруженного значения вызывается
Добавим также удобную функцию для
Некоторые специальные регистры недоступны из обычной таблицы регистров. Вместо этого для них в памяти зарезервирован специальный адрес. Чтобы читать и писать в эти регистры, вы просто читаете и записываете в их память. Они называются отображаемыми в памяти регистрами. Обычно они используются для взаимодействия со специальными аппаратными устройствами.
Для нашей LC-3 нужно реализовать два отображаемых в памяти регистра. Это регистр состояния клавиатуры (
Хотя ввод с клавиатуры можно запросить с помощью
Отображаемые в памяти регистры немного усложняют доступ к памяти. Мы не можем читать и записывать в массив памяти напрямую, а вместо этого должны вызывать специальные функции — сеттер и геттер. После чтения памяти из регистра KBSR геттер проверит клавиатуру и обновляет оба местоположения в памяти.
Это последний компонент виртуальной машины! Если вы реализовали остальные процедуры обработки прерываний и инструкции, то почти готовы попробовать её!
Всё написанное следует добавить в файл C в следующем порядке:
Этот раздел содержит некоторые утомительные детали, необходимые для доступа к клавиатуре и корректной работы. Здесь ничего интересного или познавательного о работе виртуальных машин. Не стесняйтесь копипаста!
Если пытаетесь запустить VM в операционной системе, отличной от Unix, например Windows, эти функции нужно заменить на соответствующие функции Windows.
Код для извлечения пути из аргументов программы и вывода примера использования, если они отсутствуют.
Специфичный для Unix код настройки ввода с терминала.
Когда программа прерывается, мы хотим вернуть нормальные настройки консоли.
Теперь вы можете собрать и запустить виртуальную машину LC-3!
Если программа работает неправильно, скорее всего, вы неправильно закодировали какую-то инструкцию. Это может быть сложно отладить. Рекомендую одновременно читать ассемблерный код программы — и с помощью отладчика пошагово выполнять инструкции виртуальной машины по одной. При чтении кода убедитесь, что VM переходит к положенной инструкции. Если возникнет несоответствие, то вы узнаете, какая инструкция вызвала проблему. Перечитайте спецификацию и перепроверьте код.
Здесь показан продвинутый способ выполнения инструкций, который значительно уменьшает размер кода. Это совершенно необязательный раздел.
Поскольку C++ поддерживает мощные дженерики в процессе компиляции, мы можем создавать части инструкций с помощью компилятора. Этот метод уменьшает дублирование кода и на самом деле ближе к аппаратному уровню работы компьютера.
Идея в том, чтобы повторно использовать шаги, общие для каждой инструкции. Например, некоторые инструкции используют косвенную адресацию или расширение значения и добавление его к текущему значению
Рассматривая инструкцию как последовательность шагов, мы видим, что каждая инструкция — всего лишь перестановка нескольких меньших шагов. Будем использовать битовые флаги, чтобы отметить, какие шаги выполнять для каждой инструкции. Значение
Примечание: я узнал об этой технике из эмулятора NES, разработанного Bisqwit. Если вас интересует эмуляция или NES, настоятельно рекомендую его видеоролики.
Остальные версии C++ использует уже написанный код. Полная версия здесь.
Окончательный код составляет около 250 строк на C. Достаточно знать лишь основы C или C++, такие как двоичная арифметика. Для сборки и запуска подходит любая Unix-система (включая macOS). Несколько API Unix используются для настройки ввода и отображения консоли, но они не являются существенными для основного кода. (Реализация поддержки Windows приветствуется).
Примечание: эта VM — грамотная программа. То есть вы прямо сейчас уже читаете её исходный код! Каждый фрагмент кода будет показан и подробно объяснён, так что можете быть уверены: ничего не упущено. Окончательный код создан сплетением блоков кода. Репозиторий проекта тут.
1. Оглавление
- Оглавление
- Введение
- Архитектура LC-3
- Примеры на ассемблере
- Выполнение программ
- Реализация инструкций
- Шпаргалка по инструкциям
- Процедуры обработки прерываний
- Шпаргалка по процедурам обработки прерываний
- Загрузка программ
- Отображаемые в памяти регистры
- Особенности платформы
- Запуск виртуальной машины
- Альтернативный метод на C++
2. Введение
Что такое виртуальная машина?
Виртуальная машина — это программа, которая действует как компьютер. Она имитирует процессор с несколькими другими аппаратными компонентами, позволяя выполнять арифметику, считывать из памяти и записывать туда, а также взаимодействовать с устройствами ввода-вывода, словно настоящий физический компьютер. Самое главное, VM понимает машинный язык, который вы можете использовать для программирования.
Сколько аппаратного обеспечения имитирует конкретная VM — зависит от её предназначения. Некоторые VM воспроизводят поведение одного конкретного компьютера. У людей больше нет NES, но мы всё ещё можем играть в игры для NES, имитируя аппаратное обеспечение на программном уровне. Эти эмуляторы должны точно воссоздать каждую деталь и каждый основной аппаратный компонент оригинального устройства.
Другие VM не соответствуют никакому конкретному компьютеру, а частично соответствуют сразу нескольким! В первую очередь это делается для облегчения разработки ПО. Представьте, что вы хотите создать программу, работающую на нескольких компьютерных архитектурах. Виртуальная машина даёт стандартную платформу, которая обеспечивает переносимость. Не нужно переписывать программу на разных диалектах ассемблера для каждой архитектуры. Достаточно сделать только небольшую VM на каждом языке. После этого любую программу можно написать лишь единожды на языке ассемблера виртуальной машины.
Примечание: компилятор решает подобные проблемы, компилируя стандартный высокоуровневый язык для разных процессорных архитектур. VM создаёт одну стандартную архитектуру CPU, которая симулируется на различных аппаратных устройствах. Одно из преимуществ компилятора в том, что отсутствуют накладные расходы во время выполнения, как у VM. Хотя компиляторы хорошо работают, написание нового компилятора для нескольких платформ очень трудно, поэтому VM всё ещё полезны. В реальности на разных уровнях и VM, и компиляторы используются совместно.
Виртуальная машина Java (JVM) — очень успешный пример. Сама JVM относительно среднего размера, она достаточно мала для понимания программистом. Это позволяет писать код для тысяч разнообразных устройств, включая телефоны. После реализации JVM на новом устройстве любая написанная программа Java, Kotlin или Clojure может работать на нём без изменений. Единственными затратами будут только накладные расходы на саму VM и дальнейшее абстрагирование от машинного уровня. Обычно это довольно хороший компромисс.
VM не обязательно должна быть большой или вездесущной, чтобы обеспечить аналогичные преимущества. Старые видеоигры часто использовали небольшие VM для создания простых скриптовых систем.
VM также полезны для безопасной изоляции программ. Одно из применений — сборка мусора. Не существует тривиального способа реализовать автоматическую сборку мусора поверх C или C++, так как программа не может видеть собственный стек или переменные. Однако VM находится «вне» запущенной программы и может наблюдать все ссылки на ячейки памяти в стеке.
Ещё один пример такого поведения демонстрируют смарт-контракты Ethereum. Смарт-контракты — это небольшие программы, которые выполняются каждым узлом валидации в блокчейне. То есть операторы разрешают выполнение на своих машинах любых программ, написанных совершенно незнакомыми людьми, без какой-либо возможности изучить их заранее. Чтобы предотвратить вредоносные действия, они выполняются на VM, не имеющей доступа к файловой системе, сети, диску и т.д. Ethereum — также хороший пример переносимости. Благодаря VM можно писать смарт-контракты без учёта особенностей множества платформ.
3. Архитектура LC-3
Наша VM будет симулировать вымышленный компьютер под названием LC-3. Он популярен для обучения студентов ассемблеру. Здесь упрощённый набор команд по сравнению с x86, но сохраняются все основные концепции, которые используются в современных CPU.
Во-первых, нужно сымитировать необходимые аппаратные компоненты. Попытайтесь понять, что представляет собой каждый компонент, но не волнуйтесь, если не уверены, как он вписывается в общую картину. Начнём с создания файла на С. Каждый фрагмент кода из этого раздела следует поместить в глобальную область видимости этого файла.
Память
В компьютере LC-3 есть 65 536 ячеек памяти (216), каждая из которых содержит 16-разрядное значение. Это означает, что он может хранить всего 128 Кб — намного меньше, чем вы привыкли! В нашей программе эта память хранится в простом массиве:
/* 65536 locations */
uint16_t memory[UINT16_MAX];Регистры
Регистр — это слот для хранения одного значения в CPU. Регистры подобны «верстаку» CPU. Чтобы он мог работать с каким-то фрагментом данных, тот должен находиться в одном из регистров. Но поскольку регистров всего несколько, в любой момент времени можно загрузить только минимальный объём данных. Программы обходят эту проблему, загружая значения из памяти в регистры, вычисляя значения в другие регистры, а затем сохраняя окончательные результаты обратно в память.
В компьютере LC-3 всего 10 регистров, каждый на 16 бит. Большинство из них —общего назначения, но некоторым назначены роли.
- 8 регистров общего назначения (
R0-R7) - 1 регистр счётчика команд (
PC) - 1 регистр флагов условий (
COND)
Регистры общего назначения могут использоваться для выполнения любых программных вычислений. Счётчик команд представляет собой целое число без знака, которое является адресом в памяти следующей инструкции для выполнения. Флаги условий сообщают нам информацию о предыдущем вычислении.
enum
{
R_R0 = 0,
R_R1,
R_R2,
R_R3,
R_R4,
R_R5,
R_R6,
R_R7,
R_PC, /* program counter */
R_COND,
R_COUNT
};Как и память, будем хранить регистры в массиве:
uint16_t reg[R_COUNT];Набор инструкций
Инструкция — это команда, которая говорит процессору выполнить какую-то фундаментальную задачу, например, сложить два числа. У инструкции есть опкод (код операции), указывающий тип выполняемой задачи, а также набор параметров, которые предоставляют входные данные для выполняемой задачи.
Каждый опкод представляет собой одну задачу, которую процессор «знает», как выполнить. В LC-3 всего 16 опкодов. Компьютер может вычислить только последовательность этих простых инструкций. Длина каждой инструкции 16 бит, а левые 4 бита хранят код операции. Остальные используются для хранения параметров.
Позже подробно обсудим, что делает каждая инструкция. На данный момент определите следующие опкоды. Удостоверьтесь, что сохраняют такой порядок, чтобы получать правильное значение enum:
enum
{
OP_BR = 0, /* branch */
OP_ADD, /* add */
OP_LD, /* load */
OP_ST, /* store */
OP_JSR, /* jump register */
OP_AND, /* bitwise and */
OP_LDR, /* load register */
OP_STR, /* store register */
OP_RTI, /* unused */
OP_NOT, /* bitwise not */
OP_LDI, /* load indirect */
OP_STI, /* store indirect */
OP_JMP, /* jump */
OP_RES, /* reserved (unused) */
OP_LEA, /* load effective address */
OP_TRAP /* execute trap */
};Примечание: в архитектуре Intel x86 сотни инструкций, в то время как в других архитектурах, таких как ARM и LC-3, очень мало. Небольшие наборы инструкций называются RISC, а более крупные — CISC. Большие наборы инструкций, как правило, не предоставляют принципиально новых возможностей, но часто упрощают написание ассемблерного кода. Одна инструкция CISC может заменить несколько инструкций RISC. Однако процессоры CISC более сложны и дороги в проектировании и производстве. Это и другие компромиссы не позволяют назвать «оптимальный» дизайн.
Флаги условий
Регистр
R_COND хранит флаги условий, которые предоставляют информацию о последнем выполненном вычислении. Это позволяет программам проверять логические условия, такие как if (x > 0) { ... }.У каждого процессора множество флагов состояния для сигнализации о различных ситуациях. LC-3 использует только три флага условий, которые показывают знак предыдущего вычисления.
enum
{
FL_POS = 1 << 0, /* P */
FL_ZRO = 1 << 1, /* Z */
FL_NEG = 1 << 2, /* N */
};Примечание: (Символ<<называется оператором левого сдвига.(n << k)сдвигает битыnвлево наkмест. Таким образом,1 << 2равняется4. Почитайте здесь, если не знакомы с концепцией. Это будет очень важно).
Мы закончили настройку аппаратных компонентов нашей виртуальной машины! После добавления стандартных включений (см. по ссылке выше) ваш файл должен выглядеть примерно так:
{Includes, 12}
{Registers, 3}
{Opcodes, 3}
{Condition Flags, 3}4. Примеры на ассемблере
Теперь рассмотрим программу на ассемблере LC-3, чтобы получить представление, что фактически выполняет виртуальная машина. Вам не нужно знать, как программировать на ассемблере, или всё тут понимать. Просто постарайтесь получить общее представление, что происходит. Вот простой «Hello World»:
.ORIG x3000 ; this is the address in memory where the program will be loaded
LEA R0, HELLO_STR ; load the address of the HELLO_STR string into R0
PUTs ; output the string pointed to by R0 to the console
HALT ; halt the program
HELLO_STR .STRINGZ "Hello World!" ; store this string here in the program
.END ; mark the end of the fileКак и в C, программа выполняет по одному оператору сверху вниз. Но в отличие от C, здесь нет вложенных областей
{} или управляющих структур, таких как if или while; только простой список операторов. Поэтому его гораздо легче выполнить.Обратите внимание, что имена некоторых операторов соответствуют опкодам, которые мы определили ранее. Мы знаем, что в инструкциях по 16 бит, но каждая строка выглядит как будто с разным количеством символов. Как возможно такое несоответствие?
Это происходит потому что код, который мы читаем, написан на ассемблере — в удобочитаемой и доступной для записи форме обычным текстом. Инструмент, называемый ассемблером, преобразует каждую строку текста в 16-разрядную двоичную инструкцию, понятную виртуальной машине. Эта двоичная форма, которая по сути представляет собой массив 16-разрядных инструкций, называется машинным кодом и фактически выполняется виртуальной машиной.
Примечание: хотя компилятор и ассемблер играют схожую роль в разработке, они не одинаковы. Ассемблер просто кодирует то, что программист написал в тексте, заменяя символы их двоичным представлением и упаковывая их в инструкции.
Команды
.ORIG и .STRINGZ выглядят как инструкции, но нет. Это директивы ассемблера, которые генерируют часть кода или данных. Например, .STRINGZ вставляет строку символов в указанном месте двоичной программы.Циклы и условия выполняются с помощью goto-подобной инструкции. Вот еще один пример, который считает до 10.
AND R0, R0, 0 ; clear R0
LOOP ; label at the top of our loop
ADD R0, R0, 1 ; add 1 to R0 and store back in R0
ADD R1, R0, -10 ; subtract 10 from R0 and store back in R1
BRn LOOP ; go back to LOOP if the result was negative
... ; R0 is now 10!Примечание: для этого руководства необязательно учиться ассемблеру. Но если вам интересно, можете написать и собрать собственные программы LC-3 с помощью LC-3 Tools.
5. Выполнение программ
Ещё раз, предыдущие примеры просто дают представление, что делает VM. Для написания VM вам не нужно полное понимание ассемблера. Пока вы следуете соответствующей процедуре чтения и исполнения инструкций, любая программа LC-3 будет корректно работать, независимо от её сложности. В теории, VM может запустить даже браузер или операционную систему, как Linux!
Если глубоко задуматься, то это философски замечательная идея. Сами программы могут производить сколь угодно сложные действия, которые мы никогда не ожидали и, возможно, не сможем понять. Но в то же время вся их функциональность ограничивается простым кодом, который мы напишем! Мы одновременно знаем всё и ничего о том, как работает каждая программа. Тьюринг упоминал эту чудесную идею:
«Мнение о том, что машины не могут чем-либо удивить человека, основывается, как я полагаю, на одном заблуждении, которому в особенности подвержены математики и философы. Я имею в виду предположение о том, что коль скоро какой-то факт стал достоянием разума, тотчас же достоянием разума становятся все следствия из этого факта». — Алан М. Тьюринг
Процедура
Вот точное описание процедуры, которую нужно написать:
- Загрузить одну инструкцию из памяти по адресу регистра
PC. - Увеличить регистр
PC. - Посмотреть опкод, чтобы определить, какой тип инструкции выполнять.
- Выполнить инструкцию, используя её параметры.
- Вернуться к шагу 1.
Вы можете задать вопрос: «Но если цикл продолжает увеличивать счётчик в отсутствие
if или while, инструкции разве не закончатся?» Ответ отрицательный. Как мы уже упоминали, некоторые goto-подобные инструкции изменяют поток выполнения, прыгая вокруг PC.Начнём изучение этого процесса на примере основного цикла:
int main(int argc, const char* argv[])
{
{Load Arguments, 12}
{Setup, 12}
/* set the PC to starting position */
/* 0x3000 is the default */
enum { PC_START = 0x3000 };
reg[R_PC] = PC_START;
int running = 1;
while (running)
{
/* FETCH */
uint16_t instr = mem_read(reg[R_PC]++);
uint16_t op = instr >> 12;
switch (op)
{
case OP_ADD:
{ADD, 6}
break;
case OP_AND:
{AND, 7}
break;
case OP_NOT:
{NOT, 7}
break;
case OP_BR:
{BR, 7}
break;
case OP_JMP:
{JMP, 7}
break;
case OP_JSR:
{JSR, 7}
break;
case OP_LD:
{LD, 7}
break;
case OP_LDI:
{LDI, 6}
break;
case OP_LDR:
{LDR, 7}
break;
case OP_LEA:
{LEA, 7}
break;
case OP_ST:
{ST, 7}
break;
case OP_STI:
{STI, 7}
break;
case OP_STR:
{STR, 7}
break;
case OP_TRAP:
{TRAP, 8}
break;
case OP_RES:
case OP_RTI:
default:
{BAD OPCODE, 7}
break;
}
}
{Shutdown, 12}
}6. Реализация инструкций
Теперь ваша задача — сделать правильную реализацию для каждого опкода. Подробная спецификация каждой инструкции содержится в документации проекта. Из спецификации нужно узнать, как работает каждая инструкция, и написать реализацию. Это проще, чем кажется. Здесь я продемонстрирую, как реализовать две из них. Код для остальных можно найти в следующем разделе.
ADD
Инструкция
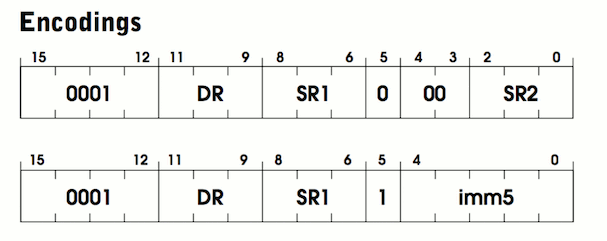
ADD берёт два числа, складывает их и сохраняет результат в регистре. Спецификация в документации на стр. 526. Каждая инструкция ADD выглядит следующим образом:На схеме две строки, потому что для этой инструкции есть два различных «режима». Прежде чем я объясню режимы, давайте попробуем найти сходство между ними. Обе они начинаются с четырёх одинаковых битов
0001. Это значение опкода для OP_ADD. Следующие три бита помечены DR для выходного регистра. Выходной регистр — это место хранения суммы. Следующие три бита: SR1. Это регистр, содержащий первое добавляемое число.Таким образом, мы знаем, где сохранить результат, и знаем первое число для сложения. Осталось только узнать второе число для сложения. Здесь две строки начинают различаться. Обратите внимание, что вверху 5-й бит равен 0, а внизу — 1. Этот бит соответствует или непосредственному режиму, или регистровому режиму. В регистровом режиме второе число хранится в регистре, как и первое. Оно отмечено как
SR2 и содержится в битах со второго по нулевой. Биты 3 и 4 не используются. На ассемблере это будет написано так:ADD R2 R0 R1 ; add the contents of R0 to R1 and store in R2.В непосредственном режиме вместо добавления содержимого регистра непосредственное значение внедряется в саму инструкцию. Это удобно, потому что программе не нужны дополнительные инструкции для загрузки этого числа в регистр из памяти. Вместо этого оно уже внутри инструкции, когда нам нужно. Компромисс в том, что там могут храниться только небольшие числа. Если быть точным, максимум 25=32. Это наиболее полезно для увеличения счётчиков или значений. На ассемблере можно написать так:
ADD R0 R0 1 ; add 1 to R0 and store back in R0Вот выдержка из спецификации:
Если бит [5] равен 0, то второй исходный операнд получают из SR2. Если бит [5] равен 1, то второй исходный операнд получают путём расширения значения imm5 до 16 бит. В обоих случаях второй исходный операнд добавляется к содержимому SR1, а результат сохраняется в DR. (стр. 526)
Это похоже на то, что мы обсуждали. Но что такое «расширение значения»? Хотя в непосредственном режиме у значения только 5 бит, его нужно сложить с 16-разрядным числом. Эти 5 бит следует расширить до 16, чтобы соответствовать другому числу. Для положительных чисел мы можем заполнить недостающие биты нулями и получить такое же значение. Однако для отрицательных чисел это не работает. Например, −1 в пяти битах равно
1 1111. Если просто заполнить нулями, получим 0000 0000 0001 1111, что равно 32! Расширение значения предотвращает эту проблему, заполняя биты нулями для положительных чисел и единицами для отрицательных чисел.uint16_t sign_extend(uint16_t x, int bit_count)
{
if ((x >> (bit_count - 1)) & 1) {
x |= (0xFFFF << bit_count);
}
return x;
}Примечание: если вас интересуют двоичные отрицательные числа, можете прочитать о дополнительном коде. Но это не существенно. Достаточно просто скопировать код выше и использовать его, когда спецификация говорит расширить значение.
В спецификации есть последнее предложение:
Коды условий задаются в зависимости от того, является ли результат отрицательным, нулевым или положительным. (стр. 526)
Ранее мы определили условие flags enum, а теперь пришло время использовать этих флаги. Каждый раз, когда значение записывается в регистр, нам нужно обновить флаги, чтобы указать его знак. Напишем функцию для повторного использования:
void update_flags(uint16_t r)
{
if (reg[r] == 0)
{
reg[R_COND] = FL_ZRO;
}
else if (reg[r] >> 15) /* a 1 in the left-most bit indicates negative */
{
reg[R_COND] = FL_NEG;
}
else
{
reg[R_COND] = FL_POS;
}
}Теперь мы готовы написать код для
ADD:{
/* destination register (DR) */
uint16_t r0 = (instr >> 9) & 0x7;
/* first operand (SR1) */
uint16_t r1 = (instr >> 6) & 0x7;
/* whether we are in immediate mode */
uint16_t imm_flag = (instr >> 5) & 0x1;
if (imm_flag)
{
uint16_t imm5 = sign_extend(instr & 0x1F, 5);
reg[r0] = reg[r1] + imm5;
}
else
{
uint16_t r2 = instr & 0x7;
reg[r0] = reg[r1] + reg[r2];
}
update_flags(r0);
}В этом разделе много информации, поэтому подведём итоги.
ADDберёт два значения и сохраняет их в регистре.- В регистровом режиме второе добавляемое значение находится в регистре.
- В непосредственном режиме второе значение внедряется в правые 5 бит инструкции.
- Значения короче 16 бит следует расширить.
- Каждый раз, когда инструкция изменяет регистр, следует обновить флаги условий.
Вы можете быть ошеломлены написанием ещё 15 инструкций. Однако полученную здесь информацию можно использовать повторно. В большинстве инструкций используется комбинация расширения значения, различных режимов и обновления флагов.
LDI
LDI означает «косвенную» или «непрямую» загрузку (load indirect). Эта инструкция используется для загрузки в регистр значения из места в памяти. Спецификация на стр. 532.
Вот как выглядит двоичная компоновка:
В отличие от
ADD, здесь нет режимов и меньше параметров. На этот раз код операции 1010, что соответствует значению enum OP_LDI. Опять же мы видим трёхбитный DR (выходной регистр) для хранения загруженного значения. Остальные биты помечены как PCoffset9. Это непосредственное значение, встроенное в инструкцию (аналогично imm5). Поскольку инструкция загружается из памяти, мы можем догадаться, что это число является своего рода адресом, который говорит, откуда загружать значение. Спецификация объясняет подробнее:Адрес вычисляется с помощью расширения битов значения[8:0]до 16 бит и добавления этого значения к увеличенномуPC. Что хранится в памяти по этому адресу — это адрес данных, которые будут загружены вDR. (стр. 532)
Как и раньше, нужно расширить это 9-битное значение, но на этот раз добавить его к текущему
PC. (Если вы посмотрите на цикл выполнения, PC увеличился сразу после загрузки этой инструкции). Результирующая сумма — это адрес местоположения в памяти, и этот адрес содержит ещё одно значение, которое является адресом загружаемого значения.Это может показаться окольным путём для чтения из памяти, но так нужно. Инструкция
LD ограничена адресным смещением 9 бит, тогда как память требует для адреса 16 бит. LDI полезна для загрузки значений, которые хранятся где-то за пределами текущего компьютера, но для их использования адрес конечного местоположения должен храниться рядом. Вы можете думать о ней как о локальной переменной в C, которая является указателем на некоторые данные:// the value of far_data is an address
// of course far_data itself (the location in memory containing the address) has an address
char* far_data = "apple";
// In memory it may be layed out like this:
// Address Label Value
// 0x123: far_data = 0x456
// ...
// 0x456: string = 'a'
// if PC was at 0x100
// LDI R0 0x023
// would load 'a' into R0Как и раньше, после записи значения в
DR следует обновить флаги:Коды условий задаются в зависимости от того, является ли результат отрицательным, нулевым или положительным. (стр. 532)
Вот код для данного случая: (
mem_read обсудим в следующем разделе):{
/* destination register (DR) */
uint16_t r0 = (instr >> 9) & 0x7;
/* PCoffset 9*/
uint16_t pc_offset = sign_extend(instr & 0x1ff, 9);
/* add pc_offset to the current PC, look at that memory location to get the final address */
reg[r0] = mem_read(mem_read(reg[R_PC] + pc_offset));
update_flags(r0);
}Как я уже сказал, для этой инструкции мы использовали значительную часть кода и знаний, полученных ранее при написании
ADD. То же самое с остальными инструкциями.Теперь необходимо реализовать остальные инструкции. Следуйте спецификации и используйте уже написанный код. Код для всех инструкций приведён в конце статьи. Два из перечисленных ранее опкодов нам не понадобятся: это
OP_RTI и OP_RES. Можно их проигнорировать или выдать ошибку, если они вызываются. Когда закончите, основную часть вашей VM можно считать завершённой!7. Шпаргалка по инструкциям
В этом разделе — полные реализации оставшихся инструкций, если вы застряли.
RTI & RES
(не используются)
abort();Битовое «И»
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t r1 = (instr >> 6) & 0x7;
uint16_t imm_flag = (instr >> 5) & 0x1;
if (imm_flag)
{
uint16_t imm5 = sign_extend(instr & 0x1F, 5);
reg[r0] = reg[r1] & imm5;
}
else
{
uint16_t r2 = instr & 0x7;
reg[r0] = reg[r1] & reg[r2];
}
update_flags(r0);
}Битовое «НЕ»
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t r1 = (instr >> 6) & 0x7;
reg[r0] = ~reg[r1];
update_flags(r0);
}Branch
{
uint16_t pc_offset = sign_extend((instr) & 0x1ff, 9);
uint16_t cond_flag = (instr >> 9) & 0x7;
if (cond_flag & reg[R_COND])
{
reg[R_PC] += pc_offset;
}
}Jump
RET указана как отдельная инструкция в спецификации, так как это другая команда в ассемблере. На самом деле это особый случай JMP. RET происходит всякий раз, когда R1 равно 7.{
/* Also handles RET */
uint16_t r1 = (instr >> 6) & 0x7;
reg[R_PC] = reg[r1];
}Jump Register
{
uint16_t r1 = (instr >> 6) & 0x7;
uint16_t long_pc_offset = sign_extend(instr & 0x7ff, 11);
uint16_t long_flag = (instr >> 11) & 1;
reg[R_R7] = reg[R_PC];
if (long_flag)
{
reg[R_PC] += long_pc_offset; /* JSR */
}
else
{
reg[R_PC] = reg[r1]; /* JSRR */
}
break;
}Load
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t pc_offset = sign_extend(instr & 0x1ff, 9);
reg[r0] = mem_read(reg[R_PC] + pc_offset);
update_flags(r0);
}Load Register
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t r1 = (instr >> 6) & 0x7;
uint16_t offset = sign_extend(instr & 0x3F, 6);
reg[r0] = mem_read(reg[r1] + offset);
update_flags(r0);
}Эффективный адрес Load
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t pc_offset = sign_extend(instr & 0x1ff, 9);
reg[r0] = reg[R_PC] + pc_offset;
update_flags(r0);
}Store
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t pc_offset = sign_extend(instr & 0x1ff, 9);
mem_write(reg[R_PC] + pc_offset, reg[r0]);
}Store Indirect
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t pc_offset = sign_extend(instr & 0x1ff, 9);
mem_write(mem_read(reg[R_PC] + pc_offset), reg[r0]);
}Store Register
{
uint16_t r0 = (instr >> 9) & 0x7;
uint16_t r1 = (instr >> 6) & 0x7;
uint16_t offset = sign_extend(instr & 0x3F, 6);
mem_write(reg[r1] + offset, reg[r0]);
}8. Процедуры обработки прерываний
LC-3 обеспечивает несколько предопределённых подпрограмм для выполнения общих задач и взаимодействия с устройствами ввода-вывода. Например, есть процедуры для получения ввода с клавиатуры и вывода строк на консоль. Они называются программами обработки системных прерываний (trap routines), которые вы можете представлять как операционную систему или API для LC-3. Каждой подпрограмме присваивается код прерывания (trap-код), который её идентифицирует (аналогично опкоду). Для её выполнения вызывается инструкция
TRAP с кодом нужной подпрограммы.Установим enum для каждого кода прерывания:
enum
{
TRAP_GETC = 0x20, /* get character from keyboard */
TRAP_OUT = 0x21, /* output a character */
TRAP_PUTS = 0x22, /* output a word string */
TRAP_IN = 0x23, /* input a string */
TRAP_PUTSP = 0x24, /* output a byte string */
TRAP_HALT = 0x25 /* halt the program */
};Вам может быть интересно, почему коды прерываний не включены в инструкции. Это потому что они фактически не добавляют LC-3 никакой новой функциональности, а только обеспечивают удобный способ выполнения задачи (подобно системным функциям в C). В официальном симуляторе LC-3 коды прерываний написаны на ассемблере. При вызове кода прерывания компьютер перемещается по адресу этого кода. CPU выполняет инструкции процедуры, а по завершении
PC сбрасывается в местоположение, откуда было вызвано прерывание.Примечание: вот почему программы начинаются с адреса0x3000вместо0x0. Нижние адреса остаются пустыми, чтобы оставить место для кода подпрограммы обработки прерываний.
Нет никакой спецификации, как реализовать подпрограммы обработки прерываний: только то, что они должны делать. В нашей VM мы поступим немного иначе, написав их на C. При вызове кода прерывания будет вызвана функция C. После её работы продолжится выполнение инструкции.
Хотя процедуры можно написать на ассемблере и в физическом компьютере LC-3 так и будет, это не лучший вариант для VM. Вместо написания собственных примитивных процедур ввода-вывода можно воспользоваться теми, которые доступны на нашей ОС. Это улучшит работу виртуальной машины на наших компьютерах, упростит код и обеспечит более высокий уровень абстракции для переносимости.
Примечание: одним из конкретных примеров является ввод с клавиатуры. В ассемблерной версии используется цикл для непрерывной проверки ввода клавиатуры. Но ведь так впустую тратится много процессорного времени! При использовании надлежащей функции ОС программа может спокойно спать до входного сигнала.
В оператор множественного выбора для опкода
TRAP добавим ещё один switch:switch (instr & 0xFF)
{
case TRAP_GETC:
{TRAP GETC, 9}
break;
case TRAP_OUT:
{TRAP OUT, 9}
break;
case TRAP_PUTS:
{TRAP PUTS, 8}
break;
case TRAP_IN:
{TRAP IN, 9}
break;
case TRAP_PUTSP:
{TRAP PUTSP, 9}
break;
case TRAP_HALT:
{TRAP HALT, 9}
break;
}Как и в случае с инструкциями, я покажу, как реализовать одну процедуру, а остальное сделаете сами.
PUTS
Код прерывания
PUTS используется для выдачи строки с завершающим нулём (аналогично printf в C). Спецификация на стр. 543.Чтобы отобразить строку, мы должны дать подпрограмме обработки прерываний строку для отображения. Это делается путём сохранения адреса первого символа в
R0 перед началом обработки.Из спецификации:
Выведите строку символов ASCII на дисплей консоли. Символы содержатся в последовательных ячейках памяти, по одному символу на ячейку, начиная с адреса, указанного вR0. Вывод завершается, когда в памяти встречается значениеx0000. (стр. 543)
Обратите внимание, что в отличие от строк C, здесь символы хранятся не в одном байте, а по одному расположению в памяти. Расположение в памяти LC-3 составляет 16 бит, поэтому у каждого символа в строке размер 16 бит. Чтобы отобразить это в функции C, нужно преобразовать каждое значение в символ и вывести их по отдельности.
{
/* one char per word */
uint16_t* c = memory + reg[R_R0];
while (*c)
{
putc((char)*c, stdout);
++c;
}
fflush(stdout);
}Для данной процедуры больше ничего не требуется. Подпрограммы обработки прерываний довольно просты, если вы знаете C. Теперь вернитесь к спецификации и реализуйте остальные. Как и в случае с инструкциями, полный код можно найти в конце этого руководства.
9. Шпаргалка по процедурам обработки прерываний
Этот раздел содержит полные реализации остальных подпрограмм обработки прерываний.
Ввод символа
/* read a single ASCII char */
reg[R_R0] = (uint16_t)getchar();Вывод символа
putc((char)reg[R_R0], stdout);
fflush(stdout);Запрос ввода символа
printf("Enter a character: ");
reg[R_R0] = (uint16_t)getchar();Вывод строки
{
/* one char per byte (two bytes per word)
here we need to swap back to
big endian format */
uint16_t* c = memory + reg[R_R0];
while (*c)
{
char char1 = (*c) & 0xFF;
putc(char1, stdout);
char char2 = (*c) >> 8;
if (char2) putc(char2, stdout);
++c;
}
fflush(stdout);
}Прекращение выполнения программы
puts("HALT");
fflush(stdout);
running = 0;10. Загрузка программ
Мы много говорили о загрузке и выполнении инструкций из памяти, но как вообще инструкции попадают в память? При преобразовании ассемблерной программы в машинный код результатом является файл, содержащий массив инструкций и данных. Его можно загрузить, просто скопировав содержимое прямо в адрес в памяти.
Первые 16 бит файла программы указывают адрес в памяти, где следует начать выполнение программы. Этот адрес называется origin. Он должен быть прочитан первым, после чего в память из файла считываются остальные данные.
Вот код для загрузки программы в память LC-3:
void read_image_file(FILE* file)
{
/* the origin tells us where in memory to place the image */
uint16_t origin;
fread(&origin, sizeof(origin), 1, file);
origin = swap16(origin);
/* we know the maximum file size so we only need one fread */
uint16_t max_read = UINT16_MAX - origin;
uint16_t* p = memory + origin;
size_t read = fread(p, sizeof(uint16_t), max_read, file);
/* swap to little endian */
while (read-- > 0)
{
*p = swap16(*p);
++p;
}
}Обратите внимание, что для каждого загруженного значения вызывается
swap16. Программы LC-3 записаны в прямом порядке байтов, но большинство современных компьютеров используют обратный порядок. В результате нам нужно перевернуть каждый загруженный uint16. (Если вы случайно используете странный компьютер вроде PPC, то ничего менять не надо).uint16_t swap16(uint16_t x)
{
return (x << 8) | (x >> 8);
}Примечание: Порядок байтов относится к тому, как интерпретируются байты целого числа. В обратном порядке первый байт является наименьшей значащей цифрой, а в прямом порядке — наоборот. Насколько мне известно, решение в основном произвольное. Разные компании принимали разные решения, так что теперь у нас различные реализации. Для этого проекта больше ничего не нужно знать о порядке байтов.
Добавим также удобную функцию для
read_image_file, которая принимает путь для строки:int read_image(const char* image_path)
{
FILE* file = fopen(image_path, "rb");
if (!file) { return 0; };
read_image_file(file);
fclose(file);
return 1;
}11. Отображаемые в памяти регистры
Некоторые специальные регистры недоступны из обычной таблицы регистров. Вместо этого для них в памяти зарезервирован специальный адрес. Чтобы читать и писать в эти регистры, вы просто читаете и записываете в их память. Они называются отображаемыми в памяти регистрами. Обычно они используются для взаимодействия со специальными аппаратными устройствами.
Для нашей LC-3 нужно реализовать два отображаемых в памяти регистра. Это регистр состояния клавиатуры (
KBSR) и регистр данных клавиатуры (KBDR). Первый указывает, была ли нажата клавиша, а второй определяет, какая именно клавиша нажата.Хотя ввод с клавиатуры можно запросить с помощью
GETC, это блокирует выполнение до получения ввода. KBSR и KBDR позволяют опрашивать состояние устройства, продолжая выполнение программы, так что она остаётся отзывчивой во время ожидания ввода.enum
{
MR_KBSR = 0xFE00, /* keyboard status */
MR_KBDR = 0xFE02 /* keyboard data */
};Отображаемые в памяти регистры немного усложняют доступ к памяти. Мы не можем читать и записывать в массив памяти напрямую, а вместо этого должны вызывать специальные функции — сеттер и геттер. После чтения памяти из регистра KBSR геттер проверит клавиатуру и обновляет оба местоположения в памяти.
void mem_write(uint16_t address, uint16_t val)
{
memory[address] = val;
}
uint16_t mem_read(uint16_t address)
{
if (address == MR_KBSR)
{
if (check_key())
{
memory[MR_KBSR] = (1 << 15);
memory[MR_KBDR] = getchar();
}
else
{
memory[MR_KBSR] = 0;
}
}
return memory[address];
}Это последний компонент виртуальной машины! Если вы реализовали остальные процедуры обработки прерываний и инструкции, то почти готовы попробовать её!
Всё написанное следует добавить в файл C в следующем порядке:
{Memory Mapped Registers, 11}
{TRAP Codes, 8}
{Memory Storage, 3}
{Register Storage, 3}
{Functions, 12}
{Main Loop, 5}12. Особенности платформы
Этот раздел содержит некоторые утомительные детали, необходимые для доступа к клавиатуре и корректной работы. Здесь ничего интересного или познавательного о работе виртуальных машин. Не стесняйтесь копипаста!
Если пытаетесь запустить VM в операционной системе, отличной от Unix, например Windows, эти функции нужно заменить на соответствующие функции Windows.
uint16_t check_key()
{
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(STDIN_FILENO, &readfds);
struct timeval timeout;
timeout.tv_sec = 0;
timeout.tv_usec = 0;
return select(1, &readfds, NULL, NULL, &timeout) != 0;
}Код для извлечения пути из аргументов программы и вывода примера использования, если они отсутствуют.
if (argc < 2)
{
/* show usage string */
printf("lc3 [image-file1] ...\n");
exit(2);
}
for (int j = 1; j < argc; ++j)
{
if (!read_image(argv[j]))
{
printf("failed to load image: %s\n", argv[j]);
exit(1);
}
}Специфичный для Unix код настройки ввода с терминала.
struct termios original_tio;
void disable_input_buffering()
{
tcgetattr(STDIN_FILENO, &original_tio);
struct termios new_tio = original_tio;
new_tio.c_lflag &= ~ICANON & ~ECHO;
tcsetattr(STDIN_FILENO, TCSANOW, &new_tio);
}
void restore_input_buffering()
{
tcsetattr(STDIN_FILENO, TCSANOW, &original_tio);
}Когда программа прерывается, мы хотим вернуть нормальные настройки консоли.
void handle_interrupt(int signal)
{
restore_input_buffering();
printf("\n");
exit(-2);
}signal(SIGINT, handle_interrupt);
disable_input_buffering();restore_input_buffering();{Sign Extend, 6}
{Swap, 10}
{Update Flags, 6}
{Read Image File, 10}
{Read Image, 10}
{Check Key, 12}
{Memory Access, 11}
{Input Buffering, 12}
{Handle Interrupt, 12}#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <signal.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/time.h>
#include <sys/types.h>
#include <sys/termios.h>
#include <sys/mman.h>Запуск виртуальной машины
Теперь вы можете собрать и запустить виртуальную машину LC-3!
- Скомпилируйте программу любимым компилятором.
- Загрузите собранную версию 2048 или Rogue.
- Запустите программу с obj-файлом в качестве аргумента:
lc3-vm path/to/2048.obj - Играйте в 2048!
Control the game using WASD keys.
Are you on an ANSI terminal (y/n)? y
+--------------------------+
| |
| |
| |
| 2 |
| |
| 2 |
| |
| |
| |
+--------------------------+Отладка
Если программа работает неправильно, скорее всего, вы неправильно закодировали какую-то инструкцию. Это может быть сложно отладить. Рекомендую одновременно читать ассемблерный код программы — и с помощью отладчика пошагово выполнять инструкции виртуальной машины по одной. При чтении кода убедитесь, что VM переходит к положенной инструкции. Если возникнет несоответствие, то вы узнаете, какая инструкция вызвала проблему. Перечитайте спецификацию и перепроверьте код.
14. Альтернативный метод на C++
Здесь показан продвинутый способ выполнения инструкций, который значительно уменьшает размер кода. Это совершенно необязательный раздел.
Поскольку C++ поддерживает мощные дженерики в процессе компиляции, мы можем создавать части инструкций с помощью компилятора. Этот метод уменьшает дублирование кода и на самом деле ближе к аппаратному уровню работы компьютера.
Идея в том, чтобы повторно использовать шаги, общие для каждой инструкции. Например, некоторые инструкции используют косвенную адресацию или расширение значения и добавление его к текущему значению
PC. Согласитесь, неплохо было бы написать этот код один раз для всех инструкций?Рассматривая инструкцию как последовательность шагов, мы видим, что каждая инструкция — всего лишь перестановка нескольких меньших шагов. Будем использовать битовые флаги, чтобы отметить, какие шаги выполнять для каждой инструкции. Значение
1 в бите номера инструкции указывает, что для этой инструкции компилятор должен включить данный раздел кода.template <unsigned op>
void ins(uint16_t instr)
{
uint16_t r0, r1, r2, imm5, imm_flag;
uint16_t pc_plus_off, base_plus_off;
uint16_t opbit = (1 << op);
if (0x4EEE & opbit) { r0 = (instr >> 9) & 0x7; }
if (0x12E3 & opbit) { r1 = (instr >> 6) & 0x7; }
if (0x0022 & opbit)
{
r2 = instr & 0x7;
imm_flag = (instr >> 5) & 0x1;
imm5 = sign_extend((instr) & 0x1F, 5);
}
if (0x00C0 & opbit)
{ // Base + offset
base_plus_off = reg[r1] + sign_extend(instr & 0x3f, 6);
}
if (0x4C0D & opbit)
{
// Indirect address
pc_plus_off = reg[R_PC] + sign_extend(instr & 0x1ff, 9);
}
if (0x0001 & opbit)
{
// BR
uint16_t cond = (instr >> 9) & 0x7;
if (cond & reg[R_COND]) { reg[R_PC] = pc_plus_off; }
}
if (0x0002 & opbit) // ADD
{
if (imm_flag)
{
reg[r0] = reg[r1] + imm5;
}
else
{
reg[r0] = reg[r1] + reg[r2];
}
}
if (0x0020 & opbit) // AND
{
if (imm_flag)
{
reg[r0] = reg[r1] & imm5;
}
else
{
reg[r0] = reg[r1] & reg[r2];
}
}
if (0x0200 & opbit) { reg[r0] = ~reg[r1]; } // NOT
if (0x1000 & opbit) { reg[R_PC] = reg[r1]; } // JMP
if (0x0010 & opbit) // JSR
{
uint16_t long_flag = (instr >> 11) & 1;
pc_plus_off = reg[R_PC] + sign_extend(instr & 0x7ff, 11);
reg[R_R7] = reg[R_PC];
if (long_flag)
{
reg[R_PC] = pc_plus_off;
}
else
{
reg[R_PC] = reg[r1];
}
}
if (0x0004 & opbit) { reg[r0] = mem_read(pc_plus_off); } // LD
if (0x0400 & opbit) { reg[r0] = mem_read(mem_read(pc_plus_off)); } // LDI
if (0x0040 & opbit) { reg[r0] = mem_read(base_plus_off); } // LDR
if (0x4000 & opbit) { reg[r0] = pc_plus_off; } // LEA
if (0x0008 & opbit) { mem_write(pc_plus_off, reg[r0]); } // ST
if (0x0800 & opbit) { mem_write(mem_read(pc_plus_off), reg[r0]); } // STI
if (0x0080 & opbit) { mem_write(base_plus_off, reg[r0]); } // STR
if (0x8000 & opbit) // TRAP
{
{TRAP, 8}
}
//if (0x0100 & opbit) { } // RTI
if (0x4666 & opbit) { update_flags(r0); }
}static void (*op_table[16])(uint16_t) = {
ins<0>, ins<1>, ins<2>, ins<3>,
ins<4>, ins<5>, ins<6>, ins<7>,
NULL, ins<9>, ins<10>, ins<11>,
ins<12>, NULL, ins<14>, ins<15>
};Примечание: я узнал об этой технике из эмулятора NES, разработанного Bisqwit. Если вас интересует эмуляция или NES, настоятельно рекомендую его видеоролики.
Остальные версии C++ использует уже написанный код. Полная версия здесь.
{Includes, 12}
{Registers, 3}
{Condition Flags, 3}
{Opcodes, 3}
{Memory Mapped Registers, 11}
{TRAP Codes, 8}
{Memory Storage, 3}
{Register Storage, 3}
{Functions, 12}
int running = 1;
{Instruction C++, 14}
{Op Table, 14}
int main(int argc, const char* argv[])
{
{Load Arguments, 12}
{Setup, 12}
enum { PC_START = 0x3000 };
reg[R_PC] = PC_START;
while (running)
{
uint16_t instr = mem_read(reg[R_PC]++);
uint16_t op = instr >> 12;
op_table[op](instr);
}
{Shutdown, 12}
}






