
Привет! Я Дима, и я довольно давно и плотно сижу на Python. Сегодня хочу показать вам отличия двух асинхронных фреймворков — Tornado и Aiohttp. Расскажу историю выбора между фреймворками в нашем проекте, чем отличаются корутины в Tornado и в AsyncIO, покажу бенчмарки и дам немного полезных советов, как забраться в дебри фреймворков и успешно оттуда выбраться.

Как вы знаете, Авито — довольно большой сервис объявлений. У нас много данных и нагрузки, 35 миллионов пользователей каждый месяц и 45 миллионов активных объявлений ежедневно. Я работаю техлидом группы разработки рекомендаций. Моя команда пишет микросервисы, сейчас у нас работает их примерно двадцать. На все это сверху наливается нагрузка — вроде 5к RPS.
Сначала расскажу, как мы оказались там, где находимся сейчас. В 2015 году нам нужно было выбрать асинхронный фреймворк, потому что знали:
Таким образом, у нас очень много сетевых задач, и приложение в основном занято вводом/выводом. Актуальная версия питона на тот момент — 3.4, async и await тогда ещё не появились. Aiohttp тоже был — в версии 0.x. Асинхронный Tornado от Facebook появился в 2010 году. Для него написано много драйверов к базам данных, которые нам нужны. На бенчмарках Tornado показал стабильные результаты. Свой выбор тогда мы остановили именно на этом фреймворке.
Спустя три года мы поняли многое.
Во-первых, вышел Python 3.5 с механикой async/await. Мы разобрались, в чём же разница между yield и yield from и как Tornado согласуется с await (спойлер: не очень хорошо).
Во-вторых, мы столкнулись со странными проблемами с производительностью при наличии большого количества корутин в планировщике, даже когда CPU занят не полностью.
В-третьих, мы обнаружили, что при выполнении большого количества http-запросов к другим сервисам Tornado нужно специально дружить с асинхронным dns-резолвером, он не уважает таймауты на установление соединения и отправку запроса, которые мы указываем. И в целом оптимальный метод делать http-запросы в Tornado — это — curl, что довольно странно само по себе.
В своём докладе на PyCon Russia 2018 Андрей Светлов говорил: «Если вы хотите написать какое-то асинхронное веб-приложение, пожалуйста, просто пишите async, await. Event loop, наверное, вам вообще скоро будет не нужен. Не залезайте в дебри фреймворков, чтобы не запутаться. Не используйте низкоуровневые примитивы, и всё у вас будет нормально...». За последние три года нам, к сожалению, пришлось достаточно часто залезать во внутренности Tornado, узнавать оттуда очень много всего интересного и видеть гигантские трейсбеки на 30-40 вызовов.
Одной из самых больших проблем для понимания в асинхронном питоне является различие между yield from и yield.
Подробнее об этом написал Гвидо Ван Россум. Прилагаю перевод с небольшими сокращениями.
У двух корутин старой и новой школы есть только одно незначительное отличие — get yield from iter vs get awaitable.
К чему это всё? В Tornado используется простой yield. До версии 5 он соединяет всю эту цепочку вызовов через yield, что плохо совместимо с новой крутой yield from/await парадигмой.
Сложно найти действительно хороший фреймворк, выбирая его только лишь по данным синтетических тестов. В реальной жизни много чего может пойти не так.
Я взял Aiohttp версии 3.4.4, Tornado 5.1.1, uvloop 0.11, взял серверный процессор Intel Xeon, CPU E5 v4, 3.6 GHz, и на нём с Python 3.6.5 начал проверять веб-серверы на конкурентность.
Типовая задача, которую мы решаем при помощи микросервисов, и которая работает на асинхронщине, выглядит так. Нам будут приходить запросы. На каждый из них будем сами делать один запрос в какой-то микросервис, получать оттуда данные, потом ходить ещё в два-три микросервиса, тоже асинхронно, потом записывать данные куда-то в базу и возвращать результат. Получается много моментов, где мы будем ждать.
Проведём более простую операцию. Включаем сервер, заставляем его поспать 50 мс. Создаём корутину и завершаем её. У нас будет не очень большой RPS (может на порядок не совпадать с тем, что видно в полностью синтетических бенчмарках) c приемлемой задержкой за счёт того, что много корутин будет одновременно крутиться в конкурентном сервере.
Нагрузка — GET http запросы. Duration — 300s, 1s — warmup, 5 повторений нагрузки.
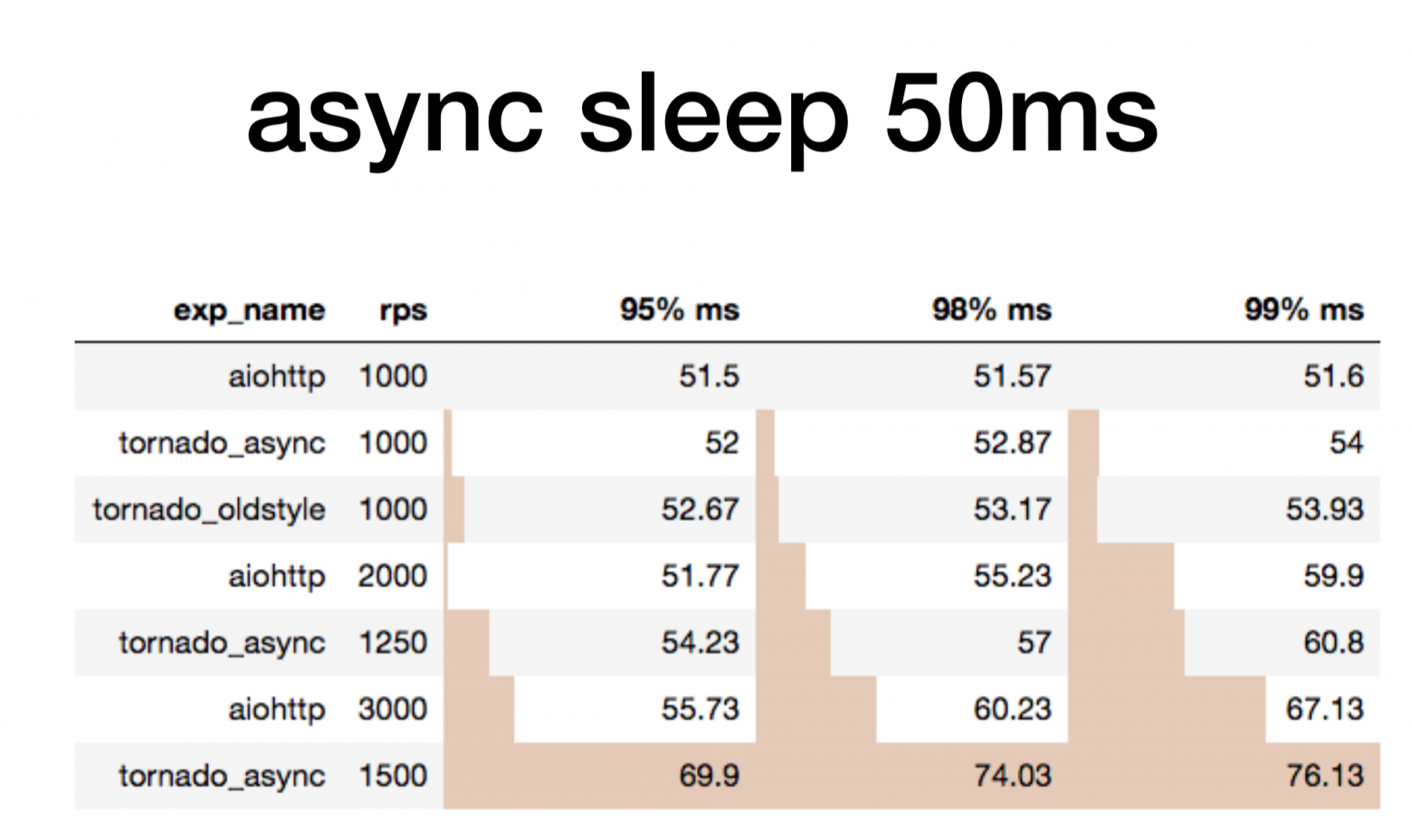
Результаты по персентилям времени ответа сервиса.
Мы видим, что Aiohttp на таком простом тесте отлично справился на 1000 RPS. Всё пока без uvloop.
Сравним Tornado с корутинами старой (yield) и новой (async) школы. Авторы настоятельно советуют использовать async. Мы можем убедиться, что они действительно значительно быстрее.
На 1200 RPS Tornado, даже c корутинами новой школы, уже начинает сдаваться, а Tornado с корутинами старой школы совсем сдулся. Если мы 50 мс спим, а микросервис отвечает за 80 мс — это совсем ни в какие ворота не лезет.
Tornado новой школы на 1500 RPS совсем сдался, а Aiohttp еще далеко до лимита на 3000 RPS. Самое интересное ещё впереди.
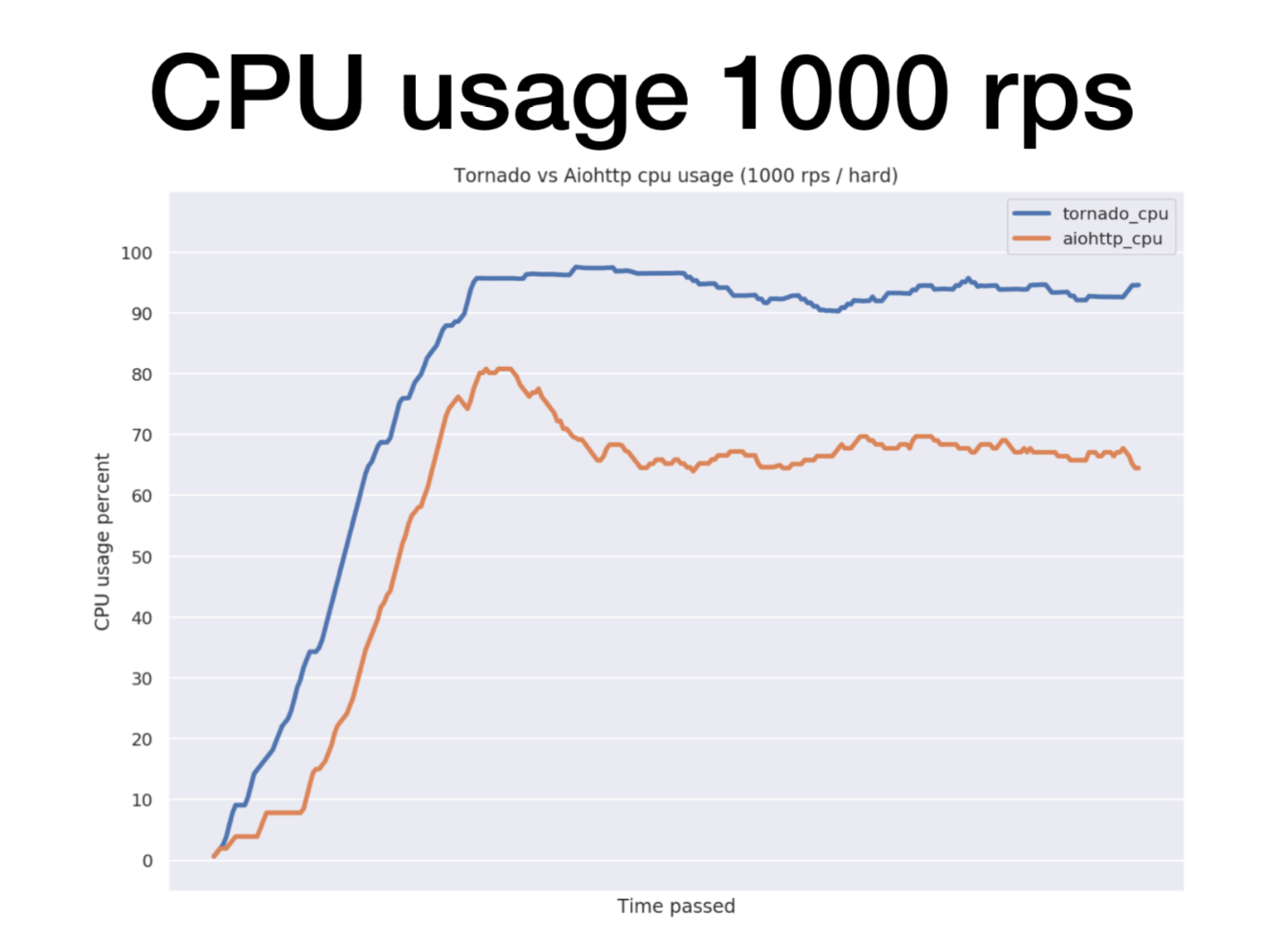
Давайте посмотрим, что творится в этот момент с процессором.
Когда мы разбирались с тем, как асинхронные микросервисы на Python работают в продакшене, то пытались понять, во что всё упиралось. В большинстве случаев проблема была с CPU или с дескрипторами. Есть замечательный инструмент для профилирования, созданный в Uber, — это профилировщик Pyflame, который основан на системном вызове ptrace.
Мы запускаем в контейнере какой-нибудь сервис и начинаем кидать на него боевую нагрузку. Зачастую это не очень тривиальная задача — создать именно такую нагрузку, которая на бою, потому что часто бывает, что запускаешь синтетические тесты на нагрузочном тестировании, смотришь, и всё отлично работает. Толкаешь на него боевую нагрузку, и вот микросервис начинает тупить.
Во время работы этот профайлер за нас делает снапшоты стека вызовов. Можно вообще сервис не менять, просто рядом запустить pyflame. Он будет собирать stack trace раз в какой-то промежуток времени, и потом делает прикольную визуализацию. Этот профилировщик даёт очень мало оверхэда, особенно если сравнивать с cProfile. Также Pyflame поддерживает многопоточные программы. Мы запускали эту штуку прямо в проде, и сильно performance не деградировал.
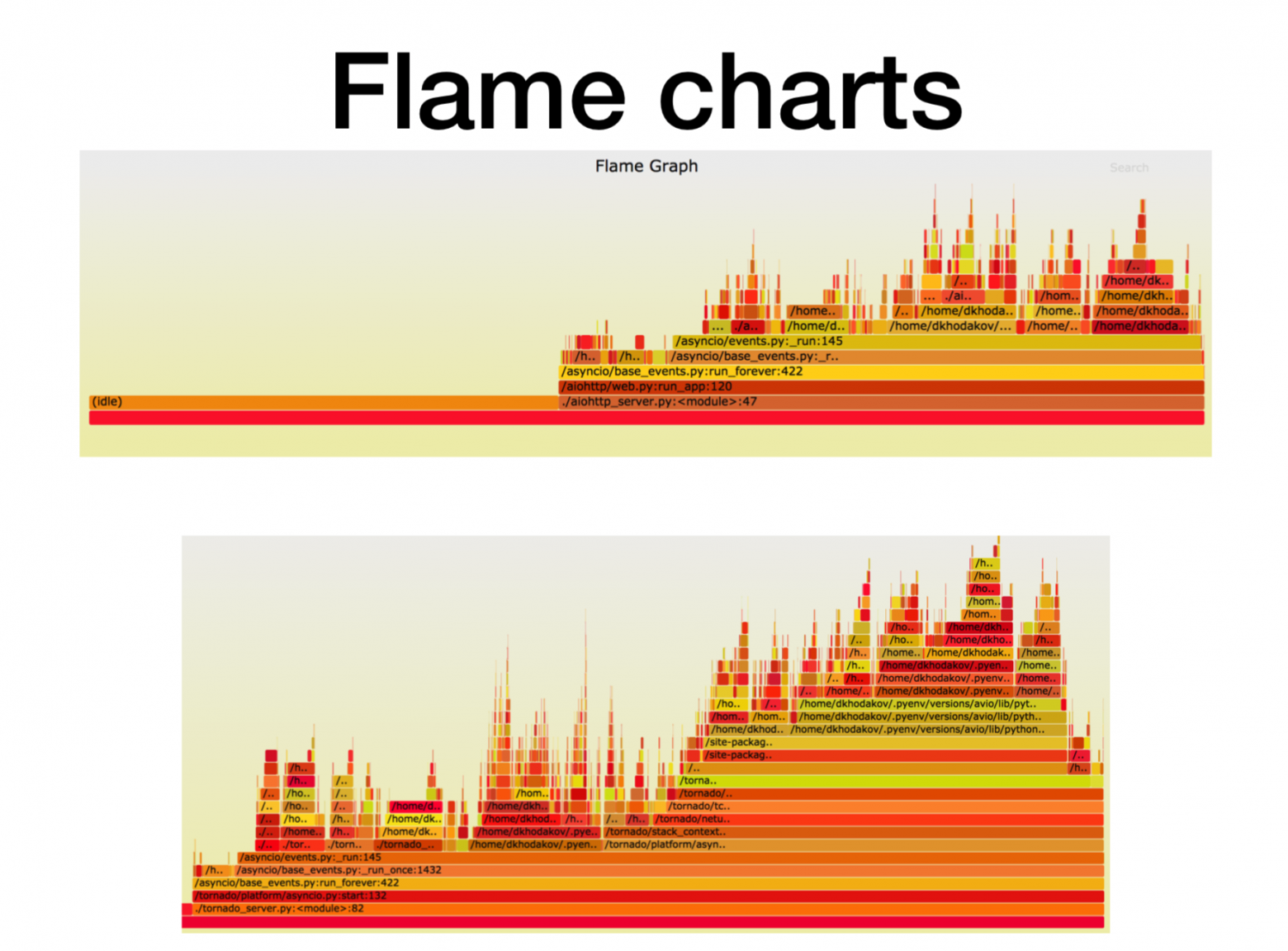
Здесь по оси X — количество времени, количество вызовов, когда фрейм стека был в списке всех стек фреймов Python. Это примерное количество процессорного времени, которое мы провели именно в этом фрейме стека.
Как видите, здесь бо́льшую часть времени в aiohttp уходит на idle. Прекрасно: это то, чего мы хотим от асинхронного сервиса, чтобы он бо́льшую часть времени занимался сетевыми вызовами. Глубина стека в данном случае порядка 15 фреймов.
В Tornado (вторая картинка) при той же нагрузке значительно меньше времени уходит на idle и глубина стека в данном случае порядка 30 фреймов.
Вот ссылка на svg, можете покрутить сами.
Cледует ожидать времени работы 125 мс.
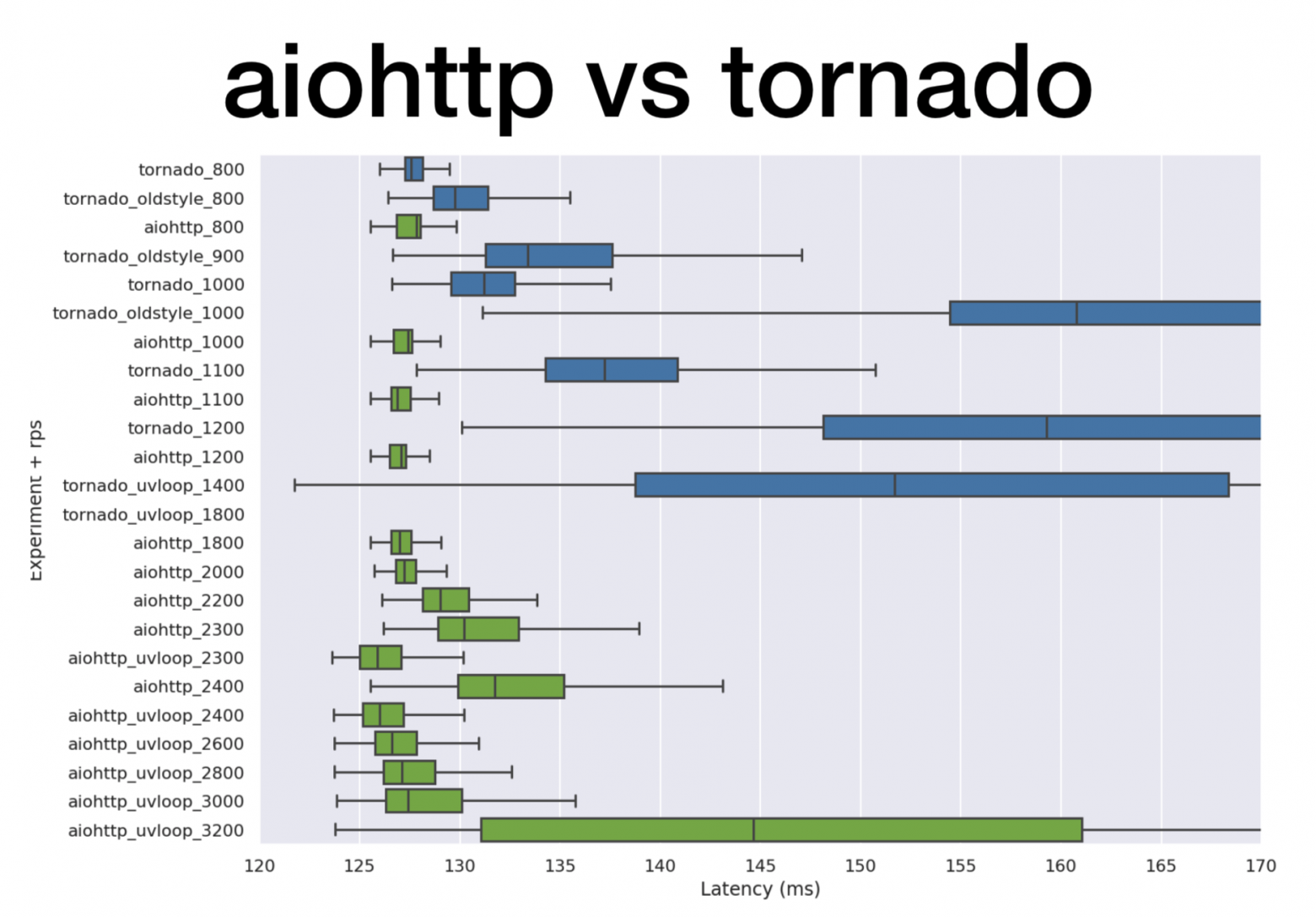
Tornado с uvloop держится лучше. Но Aiohttp uvloop помогает гораздо сильнее. Aiohttp начинает плохо себя вести на 2300-2400 RPS, а с uvloop значительно расширяет диапазон нагрузки. Одна строчка импорта, и вот у вас уже намного более производительный сервис.
Подведу итоги по тому, что хотел до вас сегодня донести.
В результате этих бенчмарков наша команда рекомендаций (и некоторые другие) практически полностью переехала на Aiohttp c Tornado для микросервисов на Python в продакшене.
Вот ссылка на бенчмарк. Если интересно, можете повторить. Спасибо всем за внимание. Задавайте вопросы, постараюсь на них ответить.
Как вы знаете, Авито — довольно большой сервис объявлений. У нас много данных и нагрузки, 35 миллионов пользователей каждый месяц и 45 миллионов активных объявлений ежедневно. Я работаю техлидом группы разработки рекомендаций. Моя команда пишет микросервисы, сейчас у нас работает их примерно двадцать. На все это сверху наливается нагрузка — вроде 5к RPS.
Выбор асинхронного фреймворка
Сначала расскажу, как мы оказались там, где находимся сейчас. В 2015 году нам нужно было выбрать асинхронный фреймворк, потому что знали:
- что придётся делать много запросов к другим микросервисам: http, json, rpc;
- что нужно будет всё время собирать данные из разных источников: Redis, Postgres, MongoDB.
Таким образом, у нас очень много сетевых задач, и приложение в основном занято вводом/выводом. Актуальная версия питона на тот момент — 3.4, async и await тогда ещё не появились. Aiohttp тоже был — в версии 0.x. Асинхронный Tornado от Facebook появился в 2010 году. Для него написано много драйверов к базам данных, которые нам нужны. На бенчмарках Tornado показал стабильные результаты. Свой выбор тогда мы остановили именно на этом фреймворке.
Спустя три года мы поняли многое.
Во-первых, вышел Python 3.5 с механикой async/await. Мы разобрались, в чём же разница между yield и yield from и как Tornado согласуется с await (спойлер: не очень хорошо).
Во-вторых, мы столкнулись со странными проблемами с производительностью при наличии большого количества корутин в планировщике, даже когда CPU занят не полностью.
В-третьих, мы обнаружили, что при выполнении большого количества http-запросов к другим сервисам Tornado нужно специально дружить с асинхронным dns-резолвером, он не уважает таймауты на установление соединения и отправку запроса, которые мы указываем. И в целом оптимальный метод делать http-запросы в Tornado — это — curl, что довольно странно само по себе.
В своём докладе на PyCon Russia 2018 Андрей Светлов говорил: «Если вы хотите написать какое-то асинхронное веб-приложение, пожалуйста, просто пишите async, await. Event loop, наверное, вам вообще скоро будет не нужен. Не залезайте в дебри фреймворков, чтобы не запутаться. Не используйте низкоуровневые примитивы, и всё у вас будет нормально...». За последние три года нам, к сожалению, пришлось достаточно часто залезать во внутренности Tornado, узнавать оттуда очень много всего интересного и видеть гигантские трейсбеки на 30-40 вызовов.
Yield vs yield from
Одной из самых больших проблем для понимания в асинхронном питоне является различие между yield from и yield.
Подробнее об этом написал Гвидо Ван Россум. Прилагаю перевод с небольшими сокращениями.
Меня спрашивали несколько раз, почему PEP 3156 настаивает на использовании yield-from вместо yield, что исключает возможность бэкпорта в Python 3.2 или даже 2.7.Оказывается, yield from — это практически то же самое, что и await.
(...)
всякий раз, когда вы хотите получить результат future, вы используете yield.
Это реализовано следующим образом. Функция, содержащая yield, является (очевидно) генератором, поэтому должен быть какой-то итерирующий код. Назовём его планировщиком. На самом деле планировщик не «итерирует» в классическом смысле (с for-loop); вместо этого он поддерживает две коллекции future.
Я назову первую коллекцию «исполняемой» последовательностью. Это future, результаты которых доступны. Пока этот список не пуст, планировщик выбирает один элемент и делает один шаг итерации. Этот шаг вызывает метод генератора .send() с результатом из future (которым могут быть данные, которые только что были прочитаны из сокета); в генераторе этот результат появляется как возвращаемое значение выражения yield. Когда send() возвращает результат или завершается, планировщик анализирует результат (который может быть StopIteration, другим исключением или каким-либо объектом).
(Если вы запутались, вам, наверное, следует почитать о том, как работают генераторы, в частности, метод .send(). Возможно, PEP 342 является хорошей отправной точкой).
(...)
вторая коллекция future, поддерживаемая планировщиком, состоит из future, которые всё ещё ожидают ввода-вывода. Они каким-то образом передаются на оболочку select/poll/и т.д. которая дает обратный вызов, когда дескриптор файла готов для ввода-вывода. Обратный вызов фактически выполняет операцию ввода-вывода, запрошенную future, задает результирующее значение future результату операции ввода-вывода и перемещает future в очередь выполнения.
(...)
Теперь мы дошли до самого интересного. Предположим, вы пишете сложный протокол. Внутри вашего протокола вы читаете байты из сокета с помощью метода recv(). Эти байты попадают в буфер. Метод recv() завернут в оболочку async, которая устанавливает ввод-вывод и возвращает future, который выполняется при завершении ввода-вывода, как я объяснял выше. Теперь предположим, что какая-то другая часть вашего кода хочет читать данные из буфера по одной строке за раз. Предположим, вы использовали метод readline(). Если размер буфера больше средней длины строки, ваш метод readline() может просто получать следующую строку из буфера без блокировки; но иногда буфер не содержит целой строки, и readline() в свою очередь вызывает recv () в сокете.
Вопрос: должен ли readline() возвращать future или нет? Было бы не очень хорошо, если бы он иногда возвращал байтовую строку, а иногда future, заставляя вызывающего выполнять проверку типа и условный yield. Поэтому ответ заключается в том, что readline() всегда должен возвращать future. Когда вызывается readline (), он проверяет буфер, и если он находит там, по крайней мере, целую строку, он создает future, задает результат future строки, взятой из буфера, и возвращает future. Если в буфере нет целой строки, он инициирует ввод-вывод и ожидает его, а когда ввод-вывод завершен, начинает заново.
(...)
Но теперь мы создаём множество future, которые не требуют блокировки ввода-вывода, но всё равно вынуждают обращение к планировщику, — поскольку readline() возвращает future, от вызывающего требуется yield, и что означает обращение к планировщику.
Планировщик может передать контроль прямо в корутину, если видит, что выведен future, который уже завершен, или может вернуть future в очередь выполнения. Последнее сильно замедлит работу (при условии, что существует более одной исполняемой корутины), так как не только требуется ожидание в конце очереди, но и локальность памяти (если она вообще существует), вероятно, также потеряна.
(...)
Чистый эффект всего этого заключается в том, что авторы корутины должны знать о yield future, и, следовательно, существует больший психологический барьер для реорганизации сложного кода в более читаемые корутины — намного сильнее существующего сопротивления, потому что вызовы функций в Python довольно медленны. И я помню из разговора с Glyph, что в типичной асинхронной структуре ввода-вывода важна скорость.
Теперь давайте сравним это с yield-from.
(...)
Возможно, вы слышали, что «yield from S» примерно эквивалентно «for i in S: yield i». В простейшем случае это так, но для понимания корутин этого недостаточно. Рассмотрим следующее (пока не думайте о async I/O):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
Этот код напечатает две строки, содержащие «okay» и «42» (а затем выдаст необработанную StopIteration, которую вы можете подавить, добавив yield в конце gen1). Вы можете увидеть этот код в действии на pythontutor.com по ссылке.
Теперь рассмотрим следующее:
def gen2(): yield from gen1() driver(gen2())
Это работает точно так же. Теперь подумайте. Как это работает? Здесь не может использоваться простое расширение yield-from в for-loop, поскольку в этом случае код выдавал бы None. (Попробуйте). Yield-from действует как «прозрачный канал» между driver и gen1. То есть, когда gen1 дает значение «okay», оно выходит из gen2, через yield-from, в драйвер, и когда драйвер посылает значение 42 обратно в gen2, это значение возвращается обратно через yield-from в gen1 снова (где становится результатом yield).
То же самое произошло бы, если бы driver выдал ошибку в генератор: ошибка проходит через yield-from во внутренний генератор, который обрабатывает её. Например:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
Код выдаст «okay» и «bah», как и следующий код:
def gen2(): yield from gen1() # unchanged throwing_driver(gen2())
(См. здесь: goo.gl/8tnjk)
Теперь я хотел бы ввести простую (ASCII) графику, чтобы иметь возможность говорить об этом виде кода. Я использую [f1 -> f2 ->… -> fN) для представления стека с f1 внизу (старейший кадр вызова) и fN вверху (новейший кадр вызова), где каждый элемент в списке является генератором, а -> представляют собой yield-from. Первый пример, driver(gen1()), не имеет yield-from, но имеет генератор gen1, поэтому он выглядит так:
[ gen1 )
Во второй примере gen2 вызывает gen1 с использованием yield-from, поэтому он выглядит следующим образом:
[ gen2 -> gen1 )
Я использую математическое обозначение полуоткрытого интервала [...), чтобы показать, что другой фрейм можно добавить справа, когда самый правый генератор использует yield-from для вызова другого генератора, в то время как левое окончание более или менее фиксированное. Левое окончание — это то, что видит драйвер (т.е. планировщик).
Теперь я готов вернуться к примеру readline(). Мы можем переписать readline() как генератор, который вызывает read(), другой генератор, используя yield-from; последний, в свою очередь, вызывает recv(), что выполняет фактический ввод-вывод из сокета. Слева у нас приложение, которое мы рассматриваем также как генератор, вызывающий readline(), снова используя yield-from. Схема такова:
[ app -> readline -> read -> recv )
Теперь генератор recv() задаёт I/O, связывает его с future и передает его планировщику, используя *yield* (не yield-from!). future проходит налево по обеим стрелкам yield-from в планировщик (расположен слева от «[»). Обратите внимание, что планировщик не знает, что он содержит стек генераторов; все, что он знает, это то, что он содержит самый левый генератор и что он только что выдал future. Когда ввод-вывод завершен, планировщик задает результат future и отправляет его обратно в генератор; результат перемещается вправо по обеим стрелкам yiled-from в генератор recv, который получает байты, которые он хотел прочитать из сокета в качестве результата yield.
Другими словами, планировщик фреймворка, основанного на yield-from, обрабатывает операции ввода-вывода точно так же, как планировщик фреймворка на основе yield, который я описал ранее. *Но:* ему не нужно беспокоиться об оптимизации, когда future уже выполнен, поскольку планировщик вообще не участвует в передаче контроля между readline() и read() или между read() и recv(), и обратно. Поэтому планировщик вообще не участвует, когда app() вызывает readline(), а readline() может удовлетворить запрос из буфера (не вызывая read()) — взаимодействие между app() и readline() в этом случае полностью обрабатывается интерпретатором байт-кода Python. Планировщик может быть проще, а количество future, создаваемых и управляемых планировщиком, меньше, потому что отсутствуют future, которые создаются и уничтожаются при каждом вызове корутины. Единственными future, которые по-прежнему необходимы, являются те, которые представляют собой фактический ввод-вывод, например, созданный recv().
Если дочитали до этого момента, вы заслуживаете награды. Я опустил много деталей реализации, но приведенная выше иллюстрация по сути верно отражает картину.
Еще одна вещь, которую я хотел бы отметить. *Можно* сделать так, чтобы часть кода использовала yield-from, а другая часть — yield. Но yield требует, чтобы в каждом звене цепи присутствовал future, а не просто корутина. Поскольку есть несколько преимуществ использования yield-from, я хочу, чтобы пользователю не нужно было помнить, когда использовать yield, а когда yield-from, — проще всегда использовать yield-from. Простое решение позволяет даже recv() использовать yield-from для передачи future ввода-вывода планировщику: метод __iter__ является фактически генератором, который выдает future.
(...)
И ещё кое-что. Какое значение возвращает yield-from? Оказывается, это возвращаемое значение *внешнего* генератора.
(...)
Таким образом, хотя стрелки связывают крайние левые и правые фреймы с целью *yielding*, они также передают обычные возвращаемые значения обычным образом, по одному фрейму стека за раз. Исключения перемещаются таким же способом; конечно, на каждом уровне требуется try/except, чтобы поймать их.
yield from vs async
def coro()^ y = yield from a |
async def async_coro(): y = await a |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 yield_from | 6 yield_from |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const |
| 12 return_value | 12 return_value |
У двух корутин старой и новой школы есть только одно незначительное отличие — get yield from iter vs get awaitable.
К чему это всё? В Tornado используется простой yield. До версии 5 он соединяет всю эту цепочку вызовов через yield, что плохо совместимо с новой крутой yield from/await парадигмой.
Простейший асинхронный бенчмарк
Сложно найти действительно хороший фреймворк, выбирая его только лишь по данным синтетических тестов. В реальной жизни много чего может пойти не так.
Я взял Aiohttp версии 3.4.4, Tornado 5.1.1, uvloop 0.11, взял серверный процессор Intel Xeon, CPU E5 v4, 3.6 GHz, и на нём с Python 3.6.5 начал проверять веб-серверы на конкурентность.
Типовая задача, которую мы решаем при помощи микросервисов, и которая работает на асинхронщине, выглядит так. Нам будут приходить запросы. На каждый из них будем сами делать один запрос в какой-то микросервис, получать оттуда данные, потом ходить ещё в два-три микросервиса, тоже асинхронно, потом записывать данные куда-то в базу и возвращать результат. Получается много моментов, где мы будем ждать.
Проведём более простую операцию. Включаем сервер, заставляем его поспать 50 мс. Создаём корутину и завершаем её. У нас будет не очень большой RPS (может на порядок не совпадать с тем, что видно в полностью синтетических бенчмарках) c приемлемой задержкой за счёт того, что много корутин будет одновременно крутиться в конкурентном сервере.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
Нагрузка — GET http запросы. Duration — 300s, 1s — warmup, 5 повторений нагрузки.
Результаты по персентилям времени ответа сервиса.
Что такое персентили?
У вас есть какое-то большое множество чисел. 95-я персентиль X значит, что 95% значений в этой выборке меньше X. С вероятностью 5% ваше число будет больше X.
Мы видим, что Aiohttp на таком простом тесте отлично справился на 1000 RPS. Всё пока без uvloop.
Сравним Tornado с корутинами старой (yield) и новой (async) школы. Авторы настоятельно советуют использовать async. Мы можем убедиться, что они действительно значительно быстрее.
На 1200 RPS Tornado, даже c корутинами новой школы, уже начинает сдаваться, а Tornado с корутинами старой школы совсем сдулся. Если мы 50 мс спим, а микросервис отвечает за 80 мс — это совсем ни в какие ворота не лезет.
Tornado новой школы на 1500 RPS совсем сдался, а Aiohttp еще далеко до лимита на 3000 RPS. Самое интересное ещё впереди.
Pyflame, профилирование работающего микросервиса
Давайте посмотрим, что творится в этот момент с процессором.
Когда мы разбирались с тем, как асинхронные микросервисы на Python работают в продакшене, то пытались понять, во что всё упиралось. В большинстве случаев проблема была с CPU или с дескрипторами. Есть замечательный инструмент для профилирования, созданный в Uber, — это профилировщик Pyflame, который основан на системном вызове ptrace.
Мы запускаем в контейнере какой-нибудь сервис и начинаем кидать на него боевую нагрузку. Зачастую это не очень тривиальная задача — создать именно такую нагрузку, которая на бою, потому что часто бывает, что запускаешь синтетические тесты на нагрузочном тестировании, смотришь, и всё отлично работает. Толкаешь на него боевую нагрузку, и вот микросервис начинает тупить.
Во время работы этот профайлер за нас делает снапшоты стека вызовов. Можно вообще сервис не менять, просто рядом запустить pyflame. Он будет собирать stack trace раз в какой-то промежуток времени, и потом делает прикольную визуализацию. Этот профилировщик даёт очень мало оверхэда, особенно если сравнивать с cProfile. Также Pyflame поддерживает многопоточные программы. Мы запускали эту штуку прямо в проде, и сильно performance не деградировал.
Здесь по оси X — количество времени, количество вызовов, когда фрейм стека был в списке всех стек фреймов Python. Это примерное количество процессорного времени, которое мы провели именно в этом фрейме стека.
Как видите, здесь бо́льшую часть времени в aiohttp уходит на idle. Прекрасно: это то, чего мы хотим от асинхронного сервиса, чтобы он бо́льшую часть времени занимался сетевыми вызовами. Глубина стека в данном случае порядка 15 фреймов.
В Tornado (вторая картинка) при той же нагрузке значительно меньше времени уходит на idle и глубина стека в данном случае порядка 30 фреймов.
Вот ссылка на svg, можете покрутить сами.
Более сложный асинхронный бенчмарк
async def work(): # Эмуляция асинхронного сетевого вызова await asyncio.sleep(SLEEP_TIME) class HardWorkHandler(tornado.web.RequestHandler): timeout_time = datetime.timedelta(seconds=SLEEP_TIME / 2) async def get(self): await work() # Эмуляция асинхронного сетевого вызова await tornado.gen.multi([work(), work()]) # Два одновременных асинхронных вызова try: await tornado.gen.with_timeout(self.timeout_time, work()) except tornado.util.TimeoutError: # Асинхронный вызов с таймаутом pass
Cледует ожидать времени работы 125 мс.
Tornado с uvloop держится лучше. Но Aiohttp uvloop помогает гораздо сильнее. Aiohttp начинает плохо себя вести на 2300-2400 RPS, а с uvloop значительно расширяет диапазон нагрузки. Одна строчка импорта, и вот у вас уже намного более производительный сервис.
Итоги
Подведу итоги по тому, что хотел до вас сегодня донести.
- Во-первых, я запускал некий искусственный бенчмарк, где было приличное количество долгих корутин. В нашем тесте Aiohttp показал себя лучше в 2,5 раза, чем Tornado.
- Второй факт. Uvloop очень хорошо помогает улучшить производительность Aiohttp (получше, чем Tornado).
- Рассказал вам про Pyflame, которым мы частенько профилируем приложение прямо в продакшене.
- И еще мы с вами поговорили про yield from (await) против yield.
В результате этих бенчмарков наша команда рекомендаций (и некоторые другие) практически полностью переехала на Aiohttp c Tornado для микросервисов на Python в продакшене.
- Для боевых сервисов потребление CPU упало более чем в 2 раза.
- Начали уважать таймауты на http-запросы.
- Латенси сервисов упало от 2 до 5 раз.
Вот ссылка на бенчмарк. Если интересно, можете повторить. Спасибо всем за внимание. Задавайте вопросы, постараюсь на них ответить.
