Некоторое время назад мы анонсировали публичный релиз и открыли под лицензией MIT исходный код LuaVela – реализации Lua 5.1, основанной на LuaJIT 2.0. Мы начали работать над ним в 2015 году, и к началу 2017 года его использовали в более чем 95% проектов компании. Сейчас хочется оглянуться на пройденный путь. Какие обстоятельства подтолкнули нас к разработке собственной реализации языка программирования? С какими проблемами мы столкнулись и как их решали? Чем LuaVela отличается от остальных форков LuaJIT?
Данный раздел основан на нашем докладе на HighLoad++. Мы начали активно использовать Lua для написания бизнес-логики своих продуктов в 2008 году. Сначала это была ванильная Lua, а с 2009 года – LuaJIT. В протоколе RTB заложены жесткие рамки на время обработки запроса, так что переход на более быструю реализацию языка был логичным и с какого-то момента необходимым решением.
Со временем мы поняли, что в архитектуру LuaJIT заложены определенные ограничения. Самым принципиальным для нас стало то, что LuaJIT 2.0 использует строго 32-битные указатели. Это привело нас к ситуации, при которой запуск на 64-битном Linux ограничивал размер виртуального адресного пространства памяти процесса одним гигабайтом (в более поздних версиях ядра Linux этот лимит был поднят до двух гигабайт):
Это ограничение стало большой проблемой – к 2015 году многим проектам перестало хватать 1-2 гигабайт памяти для загрузки данных, с которыми работала логика. Стоит отметить, что каждый экземпляр виртуальной машины Lua является однопоточным и не умеет разделять данные с другими экземплярами – это означает, что на практике каждая виртуальная машина могла претендовать на объем памяти, не превышающий на 2Гб / n, где n – число рабочих потоков нашего сервера приложений.
Мы перебрали несколько вариантов решения проблемы: уменьшали количество потоков в нашем сервере приложений, пробовали организовать доступ к данным через LuaJIT FFI, тестировали переход на LuaJIT 2.1. К сожалению, все эти варианты были либо невыгодны с экономической точки зрения, либо плохо масштабировались в долгосрочной перспективе. Единственное, что нам оставалось – рискнуть и форкнуть LuaJIT. В этот момент мы приняли решения, которые во многом определили судьбу проекта.
Во-первых, мы сразу решили не вносить изменений в синтаксис и семантику языка, сосредоточившись на устранении архитектурных ограничений LuaJIT, которые оказались проблемой для компании. Конечно, по мере развития проекта мы стали добавлять расширения (речь об этом пойдет ниже) – но все новые API мы изолировали от стандартной библиотеки языка.
Кроме того, мы отказались от кроссплатформенности в пользу поддержки только Linux x86-64, нашей единственной production-платформы. К сожалению, у нас не было достаточно ресурсов, чтобы адекватно протестировать гигантский объем изменений, который мы собирались внести в платформу.
Давайте посмотрим, откуда берётся ограничение на размер указателей. Начнём с того, что тип number в Lua 5.1 – это (с некоторыми незначительными оговорками) тип double в языке C, который в свою очередь соответствует типу двойной точности, определяемому стандартом IEEE 754. В кодировке этого 64-битного типа диапазон значений выделен под представление NaN. В частности, как NaN интерпретируется любое значение в диапазоне [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Таким образом, в одно 64-битное значение мы можем упаковать либо «настоящее» число двойной точности, либо некую сущность, которая с точки зрения типа double будет интерпретироваться как NaN, а с точки зрения нашей платформы будет чем-то более осмысленным – например, типом объекта (старшие 32 бита) и указателем на его содержимое (младшие 32 бита):
Эта техника иногда называется NaN tagging (или NaN boxing), а TValue в общем-то и описывает то, каким образом LuaJIT представляет значения переменных в Lua. У TValue есть ещё и третья ипостась, используемая для хранения указателя на функцию и информации для отмотки Lua-стека, то есть в конечном счете структура данных выглядит так:
Поле frame.link в определении выше имеет тип uintptr_t, потому что в одних случаях оно хранит указатель, а в других – некое целое число. В результате получается очень компактное представление стека виртуальной машины – по сути, это массив TValue, причем каждый элемент массива ситуативно интерпретируется то как число, то как типизированный указатель на какой-либо объект, то как данные о кадре Lua-стека.
Давайте посмотрим на пример. Представим, что мы запустили с помощью LuaJIT вот такой Lua-код и поставили break point внутри функции print:
Lua-стек в этот момент будет выглядеть таким образом:

И всё бы хорошо, но эта техника начинает сбоить, как только мы пытаемся запуститься на x86-64. Если мы запускаемся в режиме совместимости для 32-битных приложений, то упираемся в уже упомянутое выше ограничение mmap. А 64-битные указатели и вовсе не заработают из коробки. Что делать? Для устранения проблемы пришлось:
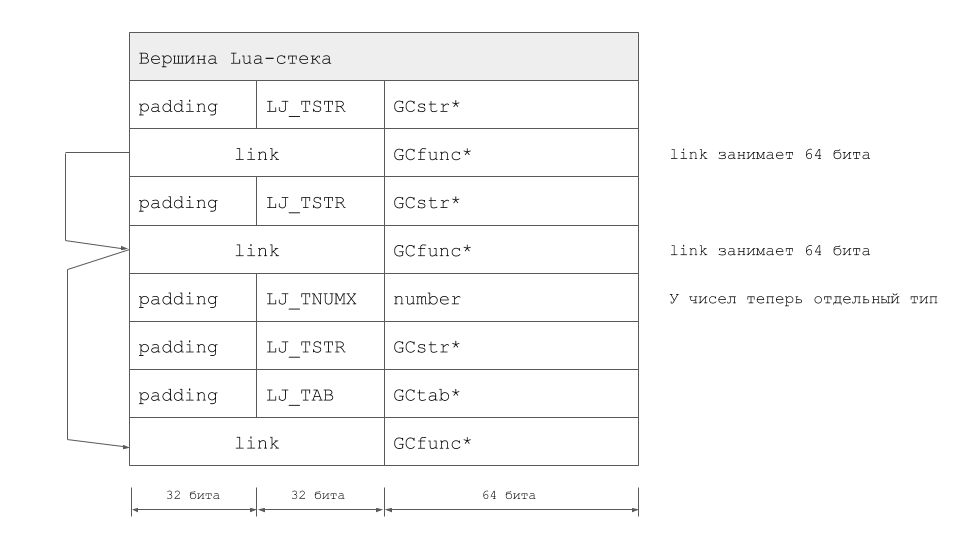
Итоговый объем изменений оказался весьма значителен и весьма отдалил нас от оригинального LuaJIT. При этом стоит заметить, что расширение TValue – это не единственный способ решения задачи. В LuaJIT 2.1 пошли другим путём, реализовав режим LJ_GC64. Питер Коули (Peter Cawley), внесший огромный вклад в разработку этого режима работы, прочитал об этом доклад на одном из митапов в Лондоне. Ну а в случае LuaVela стек для того же самого примера выглядит так:
После нескольких месяцев активной разработки настала пора опробовать LuaVela в бою. В качестве подопытных мы выбрали наиболее проблемные с точки зрения потребления памяти проекты: объем данных, с которыми им приходилось работать, заведомо превосходил 1 гигабайт, поэтому они были вынуждены применять различные обходные решения. Первые результаты внушили оптимизм: LuaVela была стабильна и показывала лучшую производительность по сравнению с конфигурацией LuaJIT, использовавшейся в этих же проектах.
Одновременно перед нами встал вопрос тестирования. К счастью, нам не пришлось начинать с чистого листа, поскольку с первого дня разработки в нашем распоряжении помимо staging-серверов были:
Как показала практика, этих ресурсов вполне хватило для отладки и доведения проекта до минимально стабильного состояния (сделали dev-сборку – выкатили на staging – работает и не падает). С другой стороны, такое тестирование через другие проекты совершенно не годилось в долгосрочной перспективе: проект такого уровня сложности, как реализация языка программирования, не может не иметь собственных тестов. Кроме того, отсутствие тестов непосредственно в проекте чисто технически усложняло поиск и исправление ошибок.
В идеальном мире нам хотелось тестировать не только нашу реализацию, но и иметь набор тестов, который позволял бы валидировать ее на соответствие семантике языка. К сожалению, в этом вопросе нас ждало некоторое разочарование. Несмотря на то, что Lua-сообщество охотно создаёт форки уже имеющихся реализаций, до недавнего времени подобный набор валидационных тестов отсутствовал. Ситуация изменилась к лучшему, когда в конце 2018 года Франсуа Перрa (François Perrad) анонсировал проект lua-Harness.
В конечном счёте проблему тестирования мы закрыли, интегрировав в наш репозиторий наиболее полные и репрезентативные наборы тестов в Lua-экосистеме:
Внедрение каждой порции тестов позволяло нам обнаружить и исправить 2-3 критические ошибки – так что очевидно, что наши усилия окупились. И хотя тема тестирования языковых рантаймов и компиляторов (как статических, так динамических) поистине безгранична, мы считаем, что заложили довольно солидный базис для стабильной разработки проекта. О проблемах тестирования собственной реализации Lua (включая такие темы, как работа с тестовыми стендами и postmortem-отладка) мы рассказывали дважды, на Lua in Moscow 2017 и на HighLoad++ 2018, – всех, кому интересны подробности, приглашаем посмотреть видео этих докладов. Ну и заглянуть в директорию tests в нашем репозитории, конечно.
Таким образом, в нашем распоряжении оказалась стабильная реализация Lua 5.1 для Linux x86-64, разрабатываемая силами небольшой команды, которая понемногу «осваивала» наследие LuaJIT и накапливала экспертизу. В таких условиях вполне естественным стало желание расширить платформу и добавить функции, которых нет ни в ванильной Lua, ни в LuaJIT, но которые помогли бы нам решить другие насущные проблемы.
Подробное описание всех расширений приводится в документации в формате RST (используйте cmake. && make docs для сборки локальной копии в формате HTML). Полное описание расширений Lua API можно найти по этой ссылке, а C API – по этой. К сожалению, в обзорной статье невозможно рассказать обо всем, поэтому вот список наиболее значимых функций:
Каждая из упомянутых возможностей заслуживает отдельной статьи – напишите в комментариях, о какой из них вы хотели бы почитать подробнее.
Здесь хочется чуть больше рассказать о том, как мы уменьшали нагрузку на сборщик мусора. Sealing («запечатывание») позволяет сделать объект недоступным для сборщика мусора. В нашем типичном проекте бо́льшая часть (вплоть до 80%) данных внутри виртуальной машины Lua – это уже бизнес-правила, которые представляют собой сложную Lua-таблицу. Время жизни этой таблицы (минуты) намного превосходит время жизни обрабатываемых запросов (десятки миллисекунд), причем данные в ней не изменяются во время обработки запросов. В такой ситуации нет смысла заставлять сборщик мусора снова и снова рекурсивно обходить эту огромную структуру данных. Для этого мы рекурсивно «запечатываем» объект и переупорядочиваем данные таким образом что сборщик мусора никогда не доходил ни до самого «запечатанного» объекта, ни до его содержимого. В ванильной Lua 5.4 эта проблема будет решена поддержкой поколений объектов в сборщике мусора (generational garbage collection).
Важно иметь в виду, что «запечатанные» объекты должны быть недоступны для записи. Несоблюдение этого инварианта приводит к появлению висячих указателей: например, «запечатанный» объект ссылается на обычный, а сборщик мусора, пропуская при обходе кучи «запечатанный» объект, пропускает и обычный – с той разницей, что «запечатанный» объект не может быть освобожден, а обычный – может. Реализовав поддержку данного инварианта, мы по сути бесплатно получаем поддержку иммутабельности объектов, на отсутствие которой часто сетуют в Lua. Подчеркну, что иммутабельные и «запечатанные» объекты – это не одно и то же. Из второго свойства следует первое, но не наоборот.
Замечу также, что в Lua 5.1 иммутабельность можно реализовать с помощью метатаблиц – решение вполне рабочее, но не самое выгодное с точки зрения производительности. Более подробную информацию о «запечатывании», иммутабельности и о том, как мы их применяем в повседневной жизни, можно найти в этом докладе.
На текущий момент мы удовлетворены стабильностью и набором возможностей нашей реализации. И хотя в силу изначальных ограничений наша реализация значительно уступает ванильной Lua и LuaJIT в плане переносимости, она решает многие наши проблемы – надеемся, эти решения пригодятся кому-то ещё.
Кроме того, даже если LuaVela не подойдет вам для production, мы приглашаем использовать его как точку входа для понимания того, как работает LuaJIT или его форк. Помимо решения проблем и расширения функциональности, за годы работы мы отрефакторили значительную часть кодовой базы и написали обучающие статьи по внутреннему устройству проекта – многие из них применимы не только к LuaVela, но и к LuaJIT.
Спасибо за внимание, ждём пулл-реквестов!
Предыстория
Данный раздел основан на нашем докладе на HighLoad++. Мы начали активно использовать Lua для написания бизнес-логики своих продуктов в 2008 году. Сначала это была ванильная Lua, а с 2009 года – LuaJIT. В протоколе RTB заложены жесткие рамки на время обработки запроса, так что переход на более быструю реализацию языка был логичным и с какого-то момента необходимым решением.
Со временем мы поняли, что в архитектуру LuaJIT заложены определенные ограничения. Самым принципиальным для нас стало то, что LuaJIT 2.0 использует строго 32-битные указатели. Это привело нас к ситуации, при которой запуск на 64-битном Linux ограничивал размер виртуального адресного пространства памяти процесса одним гигабайтом (в более поздних версиях ядра Linux этот лимит был поднят до двух гигабайт):
/* MAP_32BIT не позволит адресовать 4Гб на x86-64: */ void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
Это ограничение стало большой проблемой – к 2015 году многим проектам перестало хватать 1-2 гигабайт памяти для загрузки данных, с которыми работала логика. Стоит отметить, что каждый экземпляр виртуальной машины Lua является однопоточным и не умеет разделять данные с другими экземплярами – это означает, что на практике каждая виртуальная машина могла претендовать на объем памяти, не превышающий на 2Гб / n, где n – число рабочих потоков нашего сервера приложений.
Мы перебрали несколько вариантов решения проблемы: уменьшали количество потоков в нашем сервере приложений, пробовали организовать доступ к данным через LuaJIT FFI, тестировали переход на LuaJIT 2.1. К сожалению, все эти варианты были либо невыгодны с экономической точки зрения, либо плохо масштабировались в долгосрочной перспективе. Единственное, что нам оставалось – рискнуть и форкнуть LuaJIT. В этот момент мы приняли решения, которые во многом определили судьбу проекта.
Во-первых, мы сразу решили не вносить изменений в синтаксис и семантику языка, сосредоточившись на устранении архитектурных ограничений LuaJIT, которые оказались проблемой для компании. Конечно, по мере развития проекта мы стали добавлять расширения (речь об этом пойдет ниже) – но все новые API мы изолировали от стандартной библиотеки языка.
Кроме того, мы отказались от кроссплатформенности в пользу поддержки только Linux x86-64, нашей единственной production-платформы. К сожалению, у нас не было достаточно ресурсов, чтобы адекватно протестировать гигантский объем изменений, который мы собирались внести в платформу.
Быстрый взгляд под капот платформы
Давайте посмотрим, откуда берётся ограничение на размер указателей. Начнём с того, что тип number в Lua 5.1 – это (с некоторыми незначительными оговорками) тип double в языке C, который в свою очередь соответствует типу двойной точности, определяемому стандартом IEEE 754. В кодировке этого 64-битного типа диапазон значений выделен под представление NaN. В частности, как NaN интерпретируется любое значение в диапазоне [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Таким образом, в одно 64-битное значение мы можем упаковать либо «настоящее» число двойной точности, либо некую сущность, которая с точки зрения типа double будет интерпретироваться как NaN, а с точки зрения нашей платформы будет чем-то более осмысленным – например, типом объекта (старшие 32 бита) и указателем на его содержимое (младшие 32 бита):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
Эта техника иногда называется NaN tagging (или NaN boxing), а TValue в общем-то и описывает то, каким образом LuaJIT представляет значения переменных в Lua. У TValue есть ещё и третья ипостась, используемая для хранения указателя на функцию и информации для отмотки Lua-стека, то есть в конечном счете структура данных выглядит так:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
Поле frame.link в определении выше имеет тип uintptr_t, потому что в одних случаях оно хранит указатель, а в других – некое целое число. В результате получается очень компактное представление стека виртуальной машины – по сути, это массив TValue, причем каждый элемент массива ситуативно интерпретируется то как число, то как типизированный указатель на какой-либо объект, то как данные о кадре Lua-стека.
Давайте посмотрим на пример. Представим, что мы запустили с помощью LuaJIT вот такой Lua-код и поставили break point внутри функции print:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
Lua-стек в этот момент будет выглядеть таким образом:
И всё бы хорошо, но эта техника начинает сбоить, как только мы пытаемся запуститься на x86-64. Если мы запускаемся в режиме совместимости для 32-битных приложений, то упираемся в уже упомянутое выше ограничение mmap. А 64-битные указатели и вовсе не заработают из коробки. Что делать? Для устранения проблемы пришлось:
- Расширить TValue с 64 до 128 бит: таким образом мы получим «честный» void * на 64-битной платформе.
- Поправить соответствующим образом код виртуальной машины.
- Внести изменения в JIT-компилятор.
Итоговый объем изменений оказался весьма значителен и весьма отдалил нас от оригинального LuaJIT. При этом стоит заметить, что расширение TValue – это не единственный способ решения задачи. В LuaJIT 2.1 пошли другим путём, реализовав режим LJ_GC64. Питер Коули (Peter Cawley), внесший огромный вклад в разработку этого режима работы, прочитал об этом доклад на одном из митапов в Лондоне. Ну а в случае LuaVela стек для того же самого примера выглядит так:
Первые успехи и стабилизация проекта
После нескольких месяцев активной разработки настала пора опробовать LuaVela в бою. В качестве подопытных мы выбрали наиболее проблемные с точки зрения потребления памяти проекты: объем данных, с которыми им приходилось работать, заведомо превосходил 1 гигабайт, поэтому они были вынуждены применять различные обходные решения. Первые результаты внушили оптимизм: LuaVela была стабильна и показывала лучшую производительность по сравнению с конфигурацией LuaJIT, использовавшейся в этих же проектах.
Одновременно перед нами встал вопрос тестирования. К счастью, нам не пришлось начинать с чистого листа, поскольку с первого дня разработки в нашем распоряжении помимо staging-серверов были:
- Функциональные и интеграционные тесты сервера приложений, который исполняет бизнес-логику всех проектов компании.
- Тесты отдельных проектов.
Как показала практика, этих ресурсов вполне хватило для отладки и доведения проекта до минимально стабильного состояния (сделали dev-сборку – выкатили на staging – работает и не падает). С другой стороны, такое тестирование через другие проекты совершенно не годилось в долгосрочной перспективе: проект такого уровня сложности, как реализация языка программирования, не может не иметь собственных тестов. Кроме того, отсутствие тестов непосредственно в проекте чисто технически усложняло поиск и исправление ошибок.
В идеальном мире нам хотелось тестировать не только нашу реализацию, но и иметь набор тестов, который позволял бы валидировать ее на соответствие семантике языка. К сожалению, в этом вопросе нас ждало некоторое разочарование. Несмотря на то, что Lua-сообщество охотно создаёт форки уже имеющихся реализаций, до недавнего времени подобный набор валидационных тестов отсутствовал. Ситуация изменилась к лучшему, когда в конце 2018 года Франсуа Перрa (François Perrad) анонсировал проект lua-Harness.
В конечном счёте проблему тестирования мы закрыли, интегрировав в наш репозиторий наиболее полные и репрезентативные наборы тестов в Lua-экосистеме:
- Тесты, написанные создателями языка для их реализации Lua 5.1.
- Тесты, которые предоставил сообществу автор LuaJIT Майк Полл (Mike Pall).
- lua-Harness
- Подмножество тестов проекта MAD, разрабатываемого CERN.
- Два набора тестов, которые мы создали в IPONWEB и продолжаем пополнять до сих пор: один – для функционального тестирования платформы, другой, использующий фреймворк cmocka, – для тестирования C API и всего, для чего не хватает тестирования на уровне Lua-кода.
Внедрение каждой порции тестов позволяло нам обнаружить и исправить 2-3 критические ошибки – так что очевидно, что наши усилия окупились. И хотя тема тестирования языковых рантаймов и компиляторов (как статических, так динамических) поистине безгранична, мы считаем, что заложили довольно солидный базис для стабильной разработки проекта. О проблемах тестирования собственной реализации Lua (включая такие темы, как работа с тестовыми стендами и postmortem-отладка) мы рассказывали дважды, на Lua in Moscow 2017 и на HighLoad++ 2018, – всех, кому интересны подробности, приглашаем посмотреть видео этих докладов. Ну и заглянуть в директорию tests в нашем репозитории, конечно.
Новые функции
Таким образом, в нашем распоряжении оказалась стабильная реализация Lua 5.1 для Linux x86-64, разрабатываемая силами небольшой команды, которая понемногу «осваивала» наследие LuaJIT и накапливала экспертизу. В таких условиях вполне естественным стало желание расширить платформу и добавить функции, которых нет ни в ванильной Lua, ни в LuaJIT, но которые помогли бы нам решить другие насущные проблемы.
Подробное описание всех расширений приводится в документации в формате RST (используйте cmake. && make docs для сборки локальной копии в формате HTML). Полное описание расширений Lua API можно найти по этой ссылке, а C API – по этой. К сожалению, в обзорной статье невозможно рассказать обо всем, поэтому вот список наиболее значимых функций:
- DataState – возможность организовывать совместный доступ к объекту из нескольких независимых экземпляров виртуальных машин Lua.
- Возможность задавать тайм-аут для корутин и прерывать исполнение тех из них, которые исполняются дольше него.
- Комплекс оптимизаций JIT-компилятора, призванных бороться с экспоненциальным ростом числа трасс при копировании данных между объектами – об этом мы рассказывали на HighLoad++ 2017, но буквально пару месяцев назад у нас появились новые рабочие идеи, которые только предстоит задокументировать.
- Новый инструментарий: сэмплирующий профилировщик. анализатор отладочного вывода компилятора dumpanalyze и т. д.
Каждая из упомянутых возможностей заслуживает отдельной статьи – напишите в комментариях, о какой из них вы хотели бы почитать подробнее.
Здесь хочется чуть больше рассказать о том, как мы уменьшали нагрузку на сборщик мусора. Sealing («запечатывание») позволяет сделать объект недоступным для сборщика мусора. В нашем типичном проекте бо́льшая часть (вплоть до 80%) данных внутри виртуальной машины Lua – это уже бизнес-правила, которые представляют собой сложную Lua-таблицу. Время жизни этой таблицы (минуты) намного превосходит время жизни обрабатываемых запросов (десятки миллисекунд), причем данные в ней не изменяются во время обработки запросов. В такой ситуации нет смысла заставлять сборщик мусора снова и снова рекурсивно обходить эту огромную структуру данных. Для этого мы рекурсивно «запечатываем» объект и переупорядочиваем данные таким образом что сборщик мусора никогда не доходил ни до самого «запечатанного» объекта, ни до его содержимого. В ванильной Lua 5.4 эта проблема будет решена поддержкой поколений объектов в сборщике мусора (generational garbage collection).
Важно иметь в виду, что «запечатанные» объекты должны быть недоступны для записи. Несоблюдение этого инварианта приводит к появлению висячих указателей: например, «запечатанный» объект ссылается на обычный, а сборщик мусора, пропуская при обходе кучи «запечатанный» объект, пропускает и обычный – с той разницей, что «запечатанный» объект не может быть освобожден, а обычный – может. Реализовав поддержку данного инварианта, мы по сути бесплатно получаем поддержку иммутабельности объектов, на отсутствие которой часто сетуют в Lua. Подчеркну, что иммутабельные и «запечатанные» объекты – это не одно и то же. Из второго свойства следует первое, но не наоборот.
Замечу также, что в Lua 5.1 иммутабельность можно реализовать с помощью метатаблиц – решение вполне рабочее, но не самое выгодное с точки зрения производительности. Более подробную информацию о «запечатывании», иммутабельности и о том, как мы их применяем в повседневной жизни, можно найти в этом докладе.
Выводы
На текущий момент мы удовлетворены стабильностью и набором возможностей нашей реализации. И хотя в силу изначальных ограничений наша реализация значительно уступает ванильной Lua и LuaJIT в плане переносимости, она решает многие наши проблемы – надеемся, эти решения пригодятся кому-то ещё.
Кроме того, даже если LuaVela не подойдет вам для production, мы приглашаем использовать его как точку входа для понимания того, как работает LuaJIT или его форк. Помимо решения проблем и расширения функциональности, за годы работы мы отрефакторили значительную часть кодовой базы и написали обучающие статьи по внутреннему устройству проекта – многие из них применимы не только к LuaVela, но и к LuaJIT.
Спасибо за внимание, ждём пулл-реквестов!

