В данной статье я хочу рассмотреть подход к разбиению задач на подзадачи при использовании Clean Architecture.
С проблемой декомпозиции столкнулась команда мобильной разработки компании NullGravity и ниже то как мы ее решали и что в итоге получилось.

Была осень 2018-го, мы разрабатывали очередное приложение для телеком оператора. Но этот раз отличался. Сроки были достаточно сжатыми и привязанными к маркетинговой кампании клиента. Android команда выросла с 3 до 6-7 разработчиков. В спринт брали по несколько задач и стал вопрос о том, как их эффективно декомпозировать.
Что мы имеем в виду когда говорим эффективно:
Мы разделить все подзадачи на такие типы:
Data и Domain соответствуют слоям в Clean Architecture.
Empty, UI, Item и Custom относятся к presentation слою.
Integration относиться и к domain и к presentation слоям.
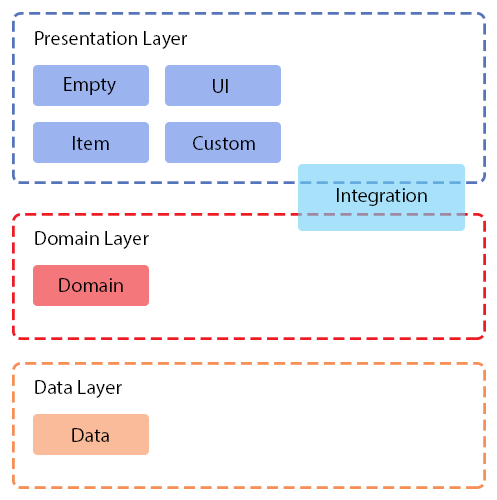
Рисунок 1. Расположение задач относительно слоев Clean Architecture
Давайте рассмотрим каждый тип в отдельности.
Описание DTO, интерфейс API, работа с базой данных, datasource и т.д.
Интерфейс репозитория, описание бизнес моделей, interactor-ы.
Так же реализуется интерфейс репозитория в data слое.
Такое несколько нелогичное, с первого взгляда, разделение позволило максимально изолировать задачи типа data и domain.
Создание основного макета экрана и дополнительных состояний, если таковые имеются.
Если экран – это список элементов, то под каждый тип нужно создать модель — Item. Для мапинга Item-а в макет нужен AdapterDelegate. Мы используем концепцию адаптер делегатов но с некоторыми доработками.
Дальше создание примера работы с элементом списка в PresentationModel.
Базовые классы необходимые для задач типа ui или item: PresentationModel, Framgent, layout, модуль DI, фабрика AdapterDelagate. Связывание интерфейсов и реализаций. Создание точки входа на экран.
Результат выполнения задачи – экран приложения. Он содержит Toolbar, RecyclerView, ProgressView и т.д. то есть общие элементы интерфейса, добавление которых могло бы дублироваться разными разработчиками и привело б к неизбежным merge конфликтам.
Реализация нестандартного UI компонента.
Дополнительный тип нужен чтоб отделить разработку нового компонента от задачи типа UI.
Интеграция domain и presentation слоев.
Как правило, это одна из самых затратных по времени задач. Нужно свести два слоя и доработать моменты, которые могли быть упущены на предыдущих этапах.
Задачи типа data, empty и custom можно начинать сразу после старта спринта. Они не зависят от других задач.
Задача domain выполняется после задачи data.
Задачи ui и item после задачи empty.
Задача integration выполняется в последнюю очередь так как требует завершения всех предидущих задач.
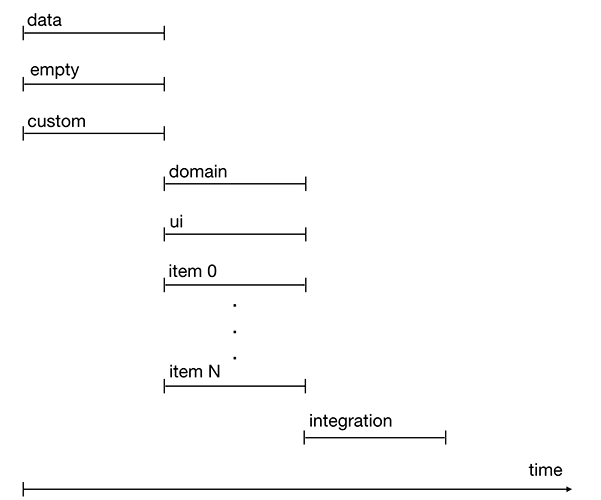
Рисунок 2. Timeline выполнения задач
Не смотря на то что часть задач заблокированы другими задачами их можно стартовать одновременно или с небольшой задержкой. К таким задачам относятся domain, ui и item. Таким образом процесс разработки ускориться.
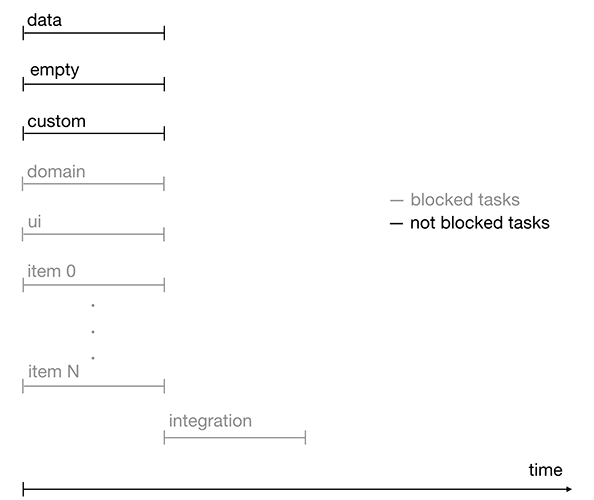
Рисунок 3. Timeline выполнения задач с блокировками
Под каждый конкретный функционал набор задач может варьироваться.
Может быть разное количество задач empty, ui, item и integration, а некоторые типы могут просто отсутствовать.
Для сбора статистики при создании задачи к ней приписываются label. Данный механизм в дальнейшем позволит анализировать время, затраченное на каждый тип, и формировать средние расходы. Собранную информацию можно применить при оценке нового проекта.
Для автоматизации также удалось найти решение. Так как задачи типичны, то почему их описание в Jira должно отличаться. Мы разработали шаблоны для summary и description. Сначала это был просто json файл, Python parser этого файла и подключено Jira REST API для генерации задач.
В таком виде скрипт просуществовал почти год. Сегодня он превратился в полноценное desktop приложение, написанное на Python с использованием PyQt и MVP архитектурой.
Возможно MVP была overhead, но когда первая версия на Tkinter крешила MacOS версии 10.14.6 и не все команды могли пользоваться приложением, мы с легкостью за пол дня переписали view на PyQt и все заработало. Мы в очередной раз убедились, что использование архитектурных подходов хоть и для таких простых задач имеет свои преимущества. Cкриншот JiraSubTaskCreator показано на рисунке 4.
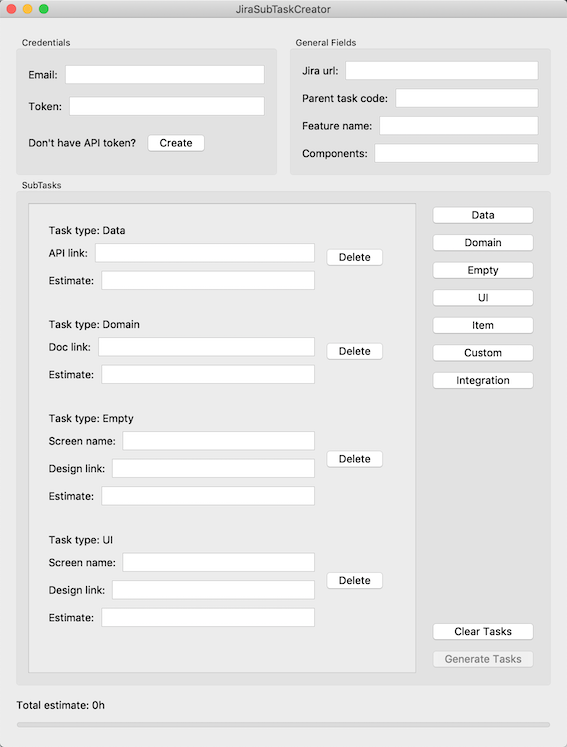
Рисунок 4. Главный экран JiraSubTaskCreator
С проблемой декомпозиции столкнулась команда мобильной разработки компании NullGravity и ниже то как мы ее решали и что в итоге получилось.
Предыстория
Была осень 2018-го, мы разрабатывали очередное приложение для телеком оператора. Но этот раз отличался. Сроки были достаточно сжатыми и привязанными к маркетинговой кампании клиента. Android команда выросла с 3 до 6-7 разработчиков. В спринт брали по несколько задач и стал вопрос о том, как их эффективно декомпозировать.
Что мы имеем в виду когда говорим эффективно:
- Максимально количество параллельных задач.
Это дает возможность занять все имеющиеся ресурсы. - Уменьшение размера merge request-ов.
Их будут смотреть не для галочки, и можно еще на этапе code review отловить потенциальные проблемы. - Уменьшение количества merge конфликтов.
Задачи будут вливаться быстрее и не нужно переключать разработчика на разрешение конфликтов. - Возможность собрать статистику затрат времени.
- Автоматизация создания задач в Jira.
Как мы решили задачу?
Мы разделить все подзадачи на такие типы:
- Data
- Domain
- Empty
- UI
- Item
- Custom
- Integration
Data и Domain соответствуют слоям в Clean Architecture.
Empty, UI, Item и Custom относятся к presentation слою.
Integration относиться и к domain и к presentation слоям.
Рисунок 1. Расположение задач относительно слоев Clean Architecture
Давайте рассмотрим каждый тип в отдельности.
Data
Описание DTO, интерфейс API, работа с базой данных, datasource и т.д.
Domain
Интерфейс репозитория, описание бизнес моделей, interactor-ы.
Так же реализуется интерфейс репозитория в data слое.
Такое несколько нелогичное, с первого взгляда, разделение позволило максимально изолировать задачи типа data и domain.
UI
Создание основного макета экрана и дополнительных состояний, если таковые имеются.
Item
Если экран – это список элементов, то под каждый тип нужно создать модель — Item. Для мапинга Item-а в макет нужен AdapterDelegate. Мы используем концепцию адаптер делегатов но с некоторыми доработками.
Дальше создание примера работы с элементом списка в PresentationModel.
Empty
Базовые классы необходимые для задач типа ui или item: PresentationModel, Framgent, layout, модуль DI, фабрика AdapterDelagate. Связывание интерфейсов и реализаций. Создание точки входа на экран.
Результат выполнения задачи – экран приложения. Он содержит Toolbar, RecyclerView, ProgressView и т.д. то есть общие элементы интерфейса, добавление которых могло бы дублироваться разными разработчиками и привело б к неизбежным merge конфликтам.
Custom
Реализация нестандартного UI компонента.
Дополнительный тип нужен чтоб отделить разработку нового компонента от задачи типа UI.
Integration
Интеграция domain и presentation слоев.
Как правило, это одна из самых затратных по времени задач. Нужно свести два слоя и доработать моменты, которые могли быть упущены на предыдущих этапах.
Порядок выполнения задач
Задачи типа data, empty и custom можно начинать сразу после старта спринта. Они не зависят от других задач.
Задача domain выполняется после задачи data.
Задачи ui и item после задачи empty.
Задача integration выполняется в последнюю очередь так как требует завершения всех предидущих задач.
Рисунок 2. Timeline выполнения задач
Не смотря на то что часть задач заблокированы другими задачами их можно стартовать одновременно или с небольшой задержкой. К таким задачам относятся domain, ui и item. Таким образом процесс разработки ускориться.
Рисунок 3. Timeline выполнения задач с блокировками
Под каждый конкретный функционал набор задач может варьироваться.
Может быть разное количество задач empty, ui, item и integration, а некоторые типы могут просто отсутствовать.
Автоматизация процесса и сбор статистики
Для сбора статистики при создании задачи к ней приписываются label. Данный механизм в дальнейшем позволит анализировать время, затраченное на каждый тип, и формировать средние расходы. Собранную информацию можно применить при оценке нового проекта.
Для автоматизации также удалось найти решение. Так как задачи типичны, то почему их описание в Jira должно отличаться. Мы разработали шаблоны для summary и description. Сначала это был просто json файл, Python parser этого файла и подключено Jira REST API для генерации задач.
В таком виде скрипт просуществовал почти год. Сегодня он превратился в полноценное desktop приложение, написанное на Python с использованием PyQt и MVP архитектурой.
Возможно MVP была overhead, но когда первая версия на Tkinter крешила MacOS версии 10.14.6 и не все команды могли пользоваться приложением, мы с легкостью за пол дня переписали view на PyQt и все заработало. Мы в очередной раз убедились, что использование архитектурных подходов хоть и для таких простых задач имеет свои преимущества. Cкриншот JiraSubTaskCreator показано на рисунке 4.
Рисунок 4. Главный экран JiraSubTaskCreator
Выводы
- Мы разработали подход к декомпозиции задач на минимально зависимы друг от друга подзадачи;
- Сформировали шаблоны для описания задач;
- Получили merge request-ы небольшого размера, который дает возможность внимательно провести review и менять код изолировано
- Уменьшили количество конфликтов при merge request-ах;
- Получили возможность более точно давать оценку и проводить анализ затрат времени на каждый тип задачи;
- Автоматизировали часть рутинной работы.

