Привет! Меня зовут Соснин Илья. Я работаю в Lamoda Android разработчиком. Крашу кнопочки, прогаю списочки и, к сожалению, пишу аналитику…
Lamoda — это Data Driven Company, в которой все решения принимаются на основе поведения пользователей. Сначала мы наблюдаем и только потом делаем выводы. Поэтому несложно догадаться, что аналитика у нас есть, и она нам очень нужна.
В расшифровке моего доклада митапа Mosdroid #18 Argon я расскажу, как устроен наш SDK и почему рефлексия — это не всегда плохо. А также отвечу на главный вопрос этой темы: «Как внедрить аналитику и не сломать приложение?».

Для начала задам один простой вопрос: “Как вы думаете, сколько у нас установок в Google play?”.
10 миллионов инсталлов!
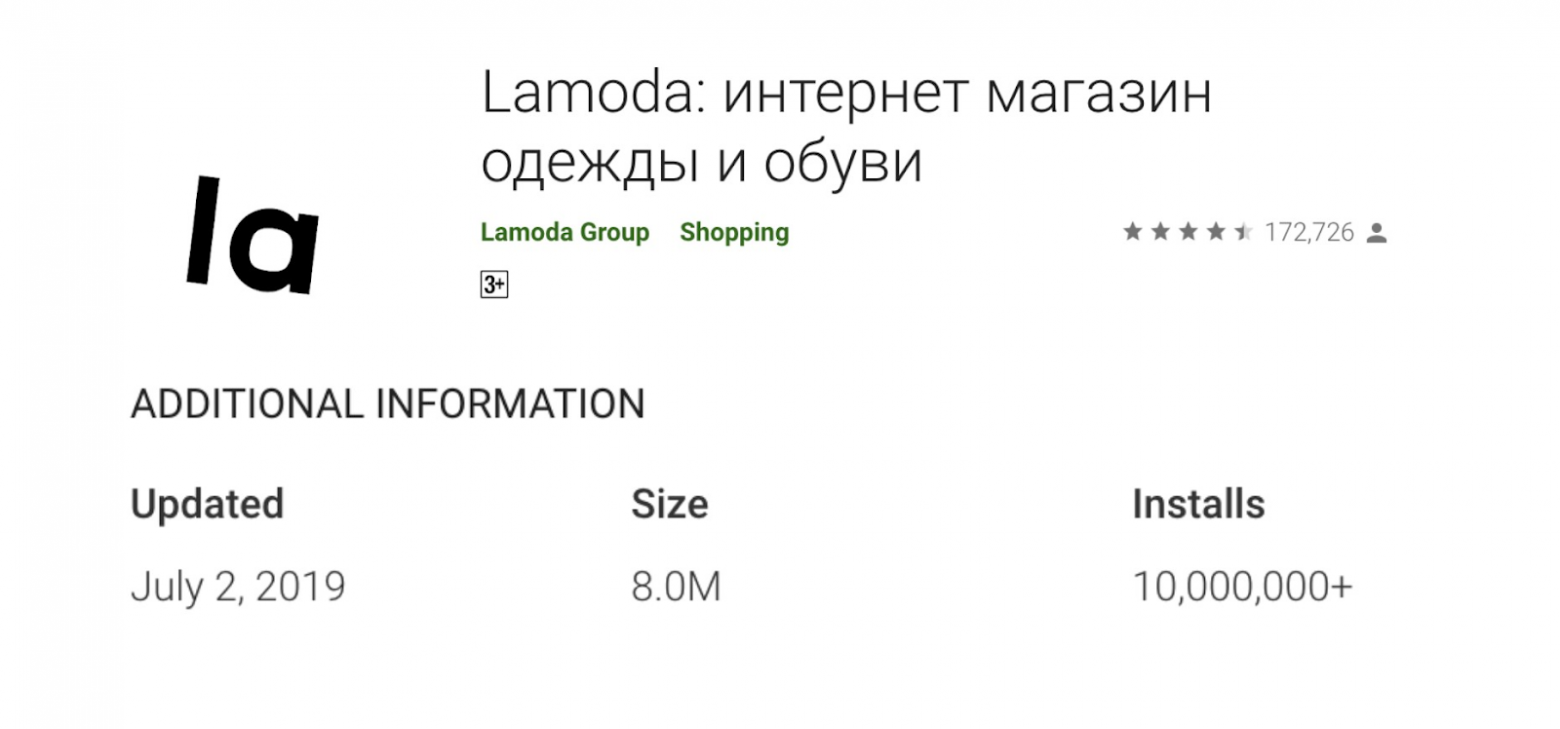
Показатель на начало июля 2019 года.
Кроме того, что мы делаем выводы, опираясь на пользователей, у нас есть и внутренние заказчики, которым также интересна аналитика.
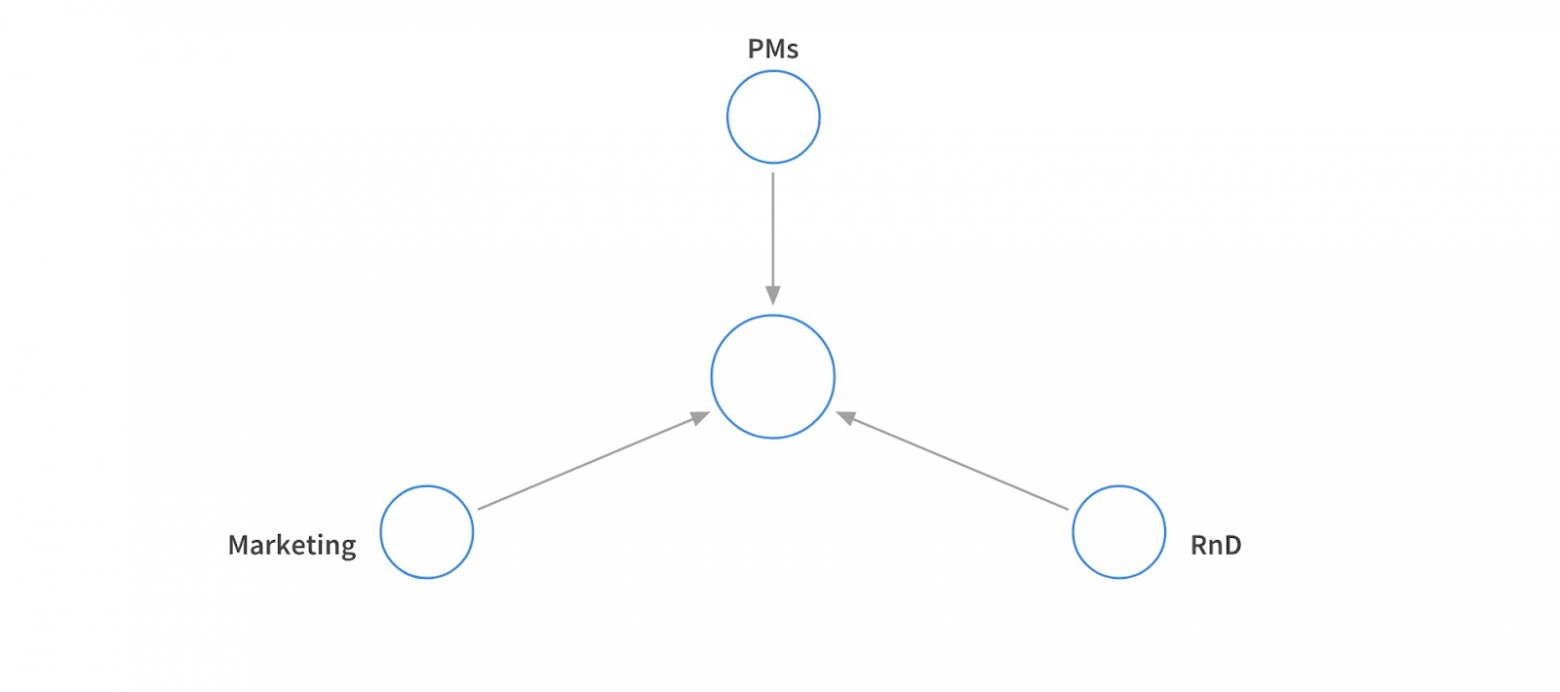
В первую очередь аналитика нужна маркетингу для собственных исследовательских целей. R&D за счет нее контролирует наши поисковые запросы, а продакты обкатывают новые фичи.
Например, была у нас фича, которая позволяла собрать весь образ целиком. То есть ты мог купить не только понравившуюся на модели рубашку, но и брюки из этого же образа. Мы решили, что для начала напишем ее для IOS, а потом подумаем, нужна ли она нам вообще. Написали, посмотрели и убедились, что пользователям она не понравилась.
А как вы думаете, что нужно делать с фичами, которые людям не нужны?
Правильно, выбрасывайте их! Особенно это стоит сделать, когда фича завязана на внешние сервисы, потому что они имеют свойство получать проблемы или могут быть платными. Так произошло и с этой фичей. Мы не стали реализовывать ни на Android, ни на Desktop, а вместо этого решили проэволюционировать ее. (возможно, когда-нибудь она поедет в прод в более совершенном виде).
Как бы смешно это ни звучало, но при внедрении аналитики может возникнуть сложность в работе с самими аналитиками. Чаще всего конфликты возникают из-за того, что они просят предоставить данные, которых у вас нет. А заканчивается это всегда тем, что тебе все равно приходится тащить пачку параметров через 10 экранов, чтобы отправить им один маленький ивент. И так происходит довольно часто.
Вторая сложность заключается в сборе аналитики. У нас этот процесс осуществляется в 7 систем.

Одни ивенты уходят в одну систему, другие — сразу в несколько… Причем есть такая особенность, что в разные системы у нас могут уходить ивенты с разными параметрами и в разных форматах. Безусловно, нам не очень хочется разруливать все эти зависимости.
Наш SDK выглядит следующим образом.
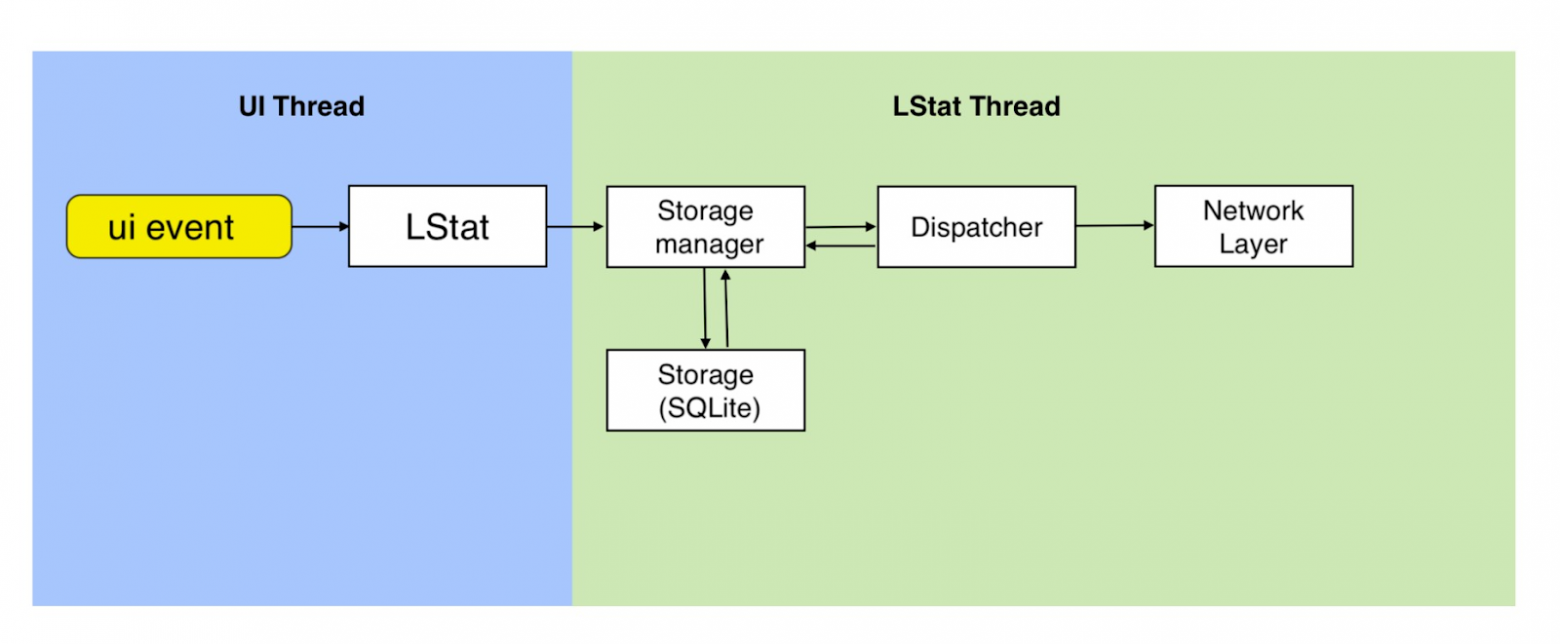
Наружу торчит чистый LStat, который внутри состоит из двух частей: хранение и отправка. Когда мы собираем ивент, то не отправляем его сиюминутно. Иначе было бы слишком много ивентов и запросов, что не очень удобно. Поэтому мы все складываем в нашу маленькую SQLite базу, где все и храним. Затем с некоторой периодичностью наш Network Layer выдергивает данные из базы и отправляет их.
После того, как мы получили от сервера подтверждение, что ивенты дошли, мы очищаем нашу базу. Такой процесс происходит регулярно. Благодаря этому наша база не разрастается, и мы гарантируем доставку всех ивентов. Если по какой-то причине ивент не пришел, то он будет храниться у нас в базе до тех пор, пока от сервера не поступит ответ.
Как я говорил ранее, у нас 7 коллекторов. Состоят они из таких методов: кастомная аннотация, EventHandler и AppStartEvent. Как вы думаете, что трекает этот ивент?

Конечно же, это холодный старт приложения. А главное тут — это то, что у нас есть класс AppStartEvent, который наследуется от некоторого интерфейса Event. А зачем нам это нужно, я расскажу чуть позже.
Как это собирается? Тут-то и начинается трэш, угар и рефлексия.

Сначала мы проходимся по всем нашим 7 коллекторам. Затем выдергиваем отсюда Java-класс и collectorName, который потребуется нам потом для хранения.
Далее из этого Java-класса мы вынимаем все наши методы, которые есть в этом коде. Теперь нам нужно проверить и убедиться, что наш метод является трек-ивент методом, который будет отвечать за хранение. Для этого у нас есть несколько параметров: первое – то, что у нас есть аннотация @EventHandler, у нас не пустой список параметров, и на вход нам приходит некоторый ивент.
Все условия выполнены, поэтому можем считать, что эта функция будет у нас ивентом. Я просто оборачиваю в некоторый враппер и отправляю в нашу коллекцию.
Да, многие из вас скажут, что рефлексия — это плохо, медленно, ужасно.
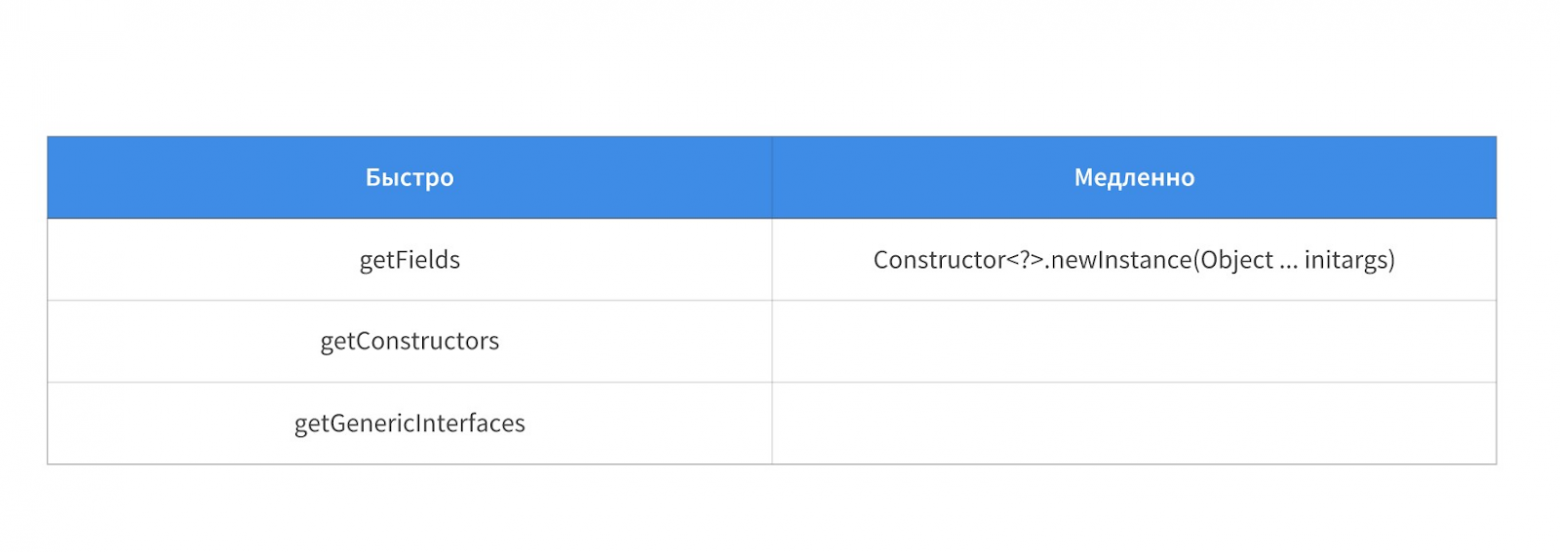
Начнем с того, что она может быть как медленная, так и быстрая. Есть методы типа getFields, getConstructors, которые работают очень быстро относительно остальной рефлексии. А есть, например, Constructor newInstance, который работает действительно медленно. Под словом “медленно” я подразумеваю разницу между левой и правой колонками в таблице выше на несколько порядков (примерно стократная разница). Поэтому, если вы понимаете, что делаете, и заранее знаете, к чему нужно быть готовым, то тут не все так страшно.
У нас выдергивается более, чем 500 методов из 7 классов. И выполняем мы это всего лишь один раз за сессию. Время, затраченное на полный проход, составляет 40 миллисекунд. Это меньше, чем 3 кадра (на этапе сплешскрина). Причем это был далеко не топовый девайс, а простой НТC на Android 6, которому уже много лет.
Безусловно, что на топовом девайсе все будет работать быстрее. А если мы будем говорить про старые китайские телефоны, то там затраченное время будет составлять условные 100 миллисекунд. Пользователи подобных телефонов уже привыкли к тому, что у них все работает медленно, поэтому им глубоко безразлично 40 там миллисекунд или 100. Какая разница? У них все равно все тормозит :)
А теперь главный вопрос: как внедрить аналитику так, чтобы не сломать архитектуру?
У нас в приложении используется MVP.
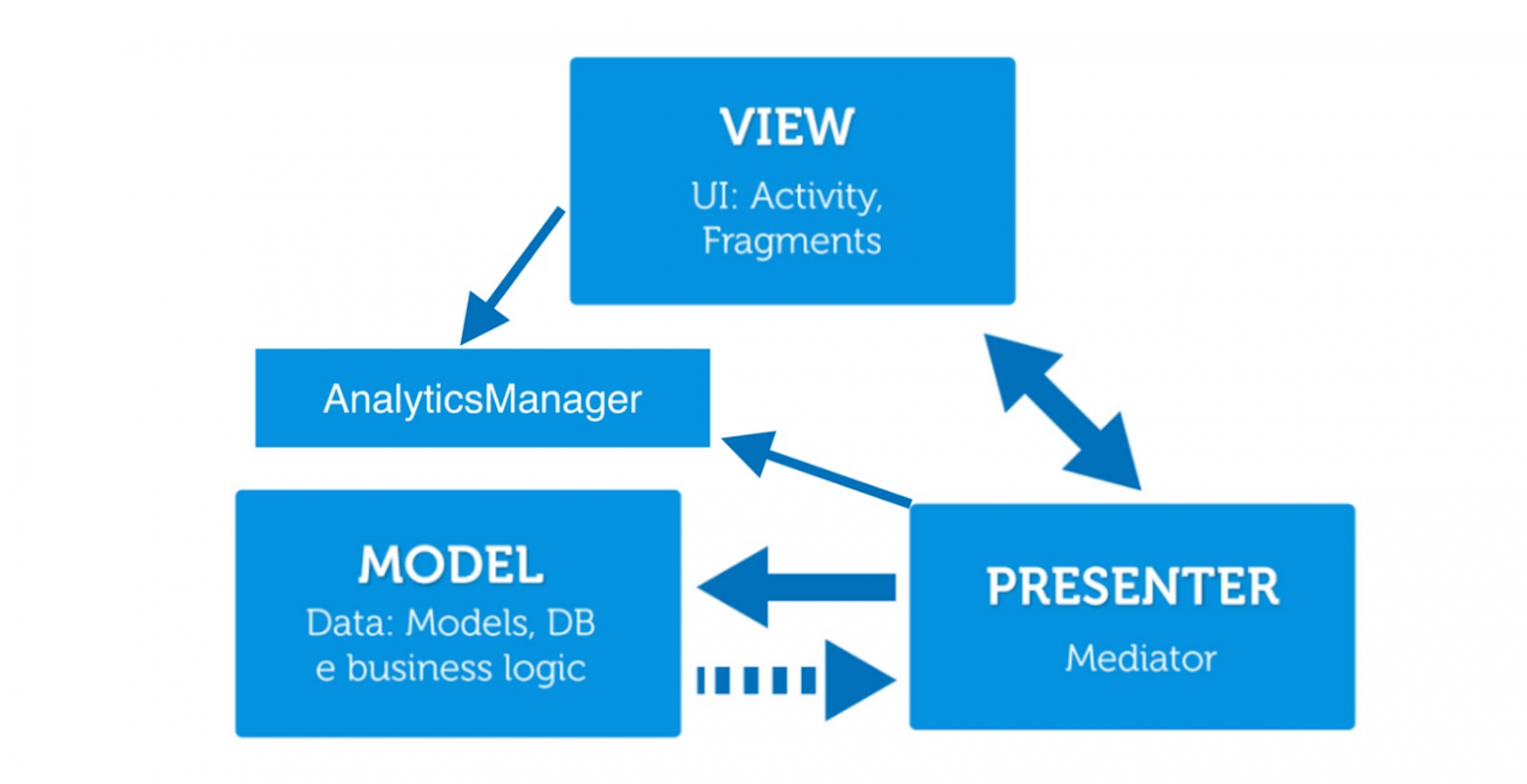
Это наша некая god-сущность, которая “живет” на ApplicationScope и инжектится ровно туда, где нам нужно. Например, нам нужно залогировать onClick(). Чтобы не ломать архитектуру, мы не будет пробрасывать ивент из View-слоя в Presenter, чтобы потом это куда-то ушло. Вместо этого мы напрямую делаем все из View и передаем трек в AnalyticsManager.
А теперь немного про отправку. У AnalyticsManager торчит наружу один метод — это метод трек, который и принимает на вход любой класс ивент. А дальше происходит черная магия.

Данный метод способен разрулить все наши проблемы.
Во-первых, он поможет залогировать в несколько разных систем. Handlers — это все наши ивенты, которые будут когда-либо собраны. Далее мы ищем здесь нужный метод. Соответственно, если у нас трек-эвент написан, например, в 4-х коллекторах, тогда и храниться он будет в 4-х экземплярах. То есть на 4-х проходах цикла мы его найдем и отправим во все 4 системы с соответствующими параметрами.
Во-вторых, это помогает решить проблему с одноразовыми ивентами. Это такие ивенты, которые должны быть залогированы строго 1 раз за весь цикл работы приложения. Ставим пометку e.once, обычная булевая переменная. Если мы говорим, что это одноразовый ивент, то просто удаляем его из коллекции. Что произойдет дальше, если мы попытаемся его заново залогировать? Очевидно, мы просто не найдем его в данной коллекции. Можно сколько угодно пытаться выстрелить себе в ногу, продолжая писать analyticsManager.track(AppStartEvent()), он все равно отправится один раз и больше не будет.
1. Мы не ломаем архитектуру нашего приложения, так как AnalyticsManager лежит и работает вне архитектуры. Это позволяет нам вставлять его в любую часть приложения.
2. Позволяет собирать любые ивенты одной строкой в любое количество систем аналитики. Для этого мы просто пишем: analyticsManager.track(Event()). Потому что дальше он сам разруливает куда, в каком количестве, с какими параметрами, когда и так далее.
3. Решает проблему “одноразовых ивентов”. Теперь нам не нужно делать различного рода проверки. Один раз отправили, удалили, и больше мы его не встретим.
4. Решает проблему сбора одного и того же элемента в разные системы. За счет того, что мы написали все в разных коллекторах, в разные коллекторы оно и ушло. Таким образом, вам не придется прибегать к лишним телодвижениям. На мой взгляд, это прекрасно.
Мы тестируем вручную. А почему бы не автоматизировать, спросите вы? И тут выясняется грустная вещь.
Во-первых, unit-тестом ты это, к сожалению, нормально не покроешь. Потому что большая часть проблем с ивентами в аналитике возникает не из-за того, что какой-то из параметров у тебя не собрался. На моем личном опыте 90% проблем возникают из-за того, что ты не отправил ивент там, где он должен был отправиться. Такие кейсы можно отлавливать только UI-тестами, которые мы пока не написали для всего этого.
И во-вторых, мы немножко пока упираемся в то, что аналитики описывают события в достаточно строгом формате (в confluence), но этот формат не является форматом строгой спецификации, как, например, Swagger. Соответственно, бывают небольшие расхождения, бывают дубликаты (хотя в этом случае чаще делается просто ссылка на другую страницу). Пока это ограничивает нас в возможностях автоматизации тестирования аналитики. Но мы работаем над этим.
Что же дальше можно сделать с этим решением?
1. Написать автотесты на аналитику. Это потребует большой подготовительной работы. Но нельзя сказать, что это невозможно.
2. Методы-треки плюс-минус достаточно похожи. В каждом мы генерируем некоторые “универсальные” параметры, которые нужны всем. И просто собираем мапу значений. В целом, можно было бы написать либо плагин, либо утилитку. Неважно. Главное, чтобы она генерила трек-ивент по соответствующим классам.
Но тут может возникнуть небольшая проблема, если ивенты начнут уходить чуть по-разному (например, для разных систем аналитики). Из-за этого не все удается решать адекватно. Да и к тому же не хочется плодить лишнюю кодогенерацию в проекте, которой и так много во многих проектах на андроиде (привет Даггер, Мокси и прочие либы работающие на кодгене).
3. Интеграция приложения со спеками аналитиков. Наверное, это слишком заоблачная мечта, но все же… Нам бы очень хотелось, чтобы наши аналитики писали в строгом формате, а мы могли бы парсить их произведения искусств и интегрировать. Тогда настал бы мир и гармония. Все были бы счастливы :)
Так что же я хочу всем этим сказать?
Во-первых, аналитика все-таки нужна. Потому что она позволяет экономить деньги, ресурсы и силы. Это спасает от написания лишнего кода или удаления кода, который вроде бы не старый, но все равно тут не нужен. Меньше legacy — это всегда хорошо.
Во-вторых, рефлексия – это не всегда плохо. Да, она бывает медленная. Но порой мы теряем совсем немного в производительности, зато много получаем, например, в области разработки, обработки ошибок.
И в-третьих, мы закладываем аналитику на этапе планирования фичи. За счет этого мы намного заранее можем договориться с аналитиками, достигнув компромисса. А также это дает нам возможность оценивать времязатраты на написание аналитики заранее.
Lamoda — это Data Driven Company, в которой все решения принимаются на основе поведения пользователей. Сначала мы наблюдаем и только потом делаем выводы. Поэтому несложно догадаться, что аналитика у нас есть, и она нам очень нужна.
В расшифровке моего доклада митапа Mosdroid #18 Argon я расскажу, как устроен наш SDK и почему рефлексия — это не всегда плохо. А также отвечу на главный вопрос этой темы: «Как внедрить аналитику и не сломать приложение?».
Для начала задам один простой вопрос: “Как вы думаете, сколько у нас установок в Google play?”.
10 миллионов инсталлов!
Показатель на начало июля 2019 года.
Кроме того, что мы делаем выводы, опираясь на пользователей, у нас есть и внутренние заказчики, которым также интересна аналитика.
В первую очередь аналитика нужна маркетингу для собственных исследовательских целей. R&D за счет нее контролирует наши поисковые запросы, а продакты обкатывают новые фичи.
Например, была у нас фича, которая позволяла собрать весь образ целиком. То есть ты мог купить не только понравившуюся на модели рубашку, но и брюки из этого же образа. Мы решили, что для начала напишем ее для IOS, а потом подумаем, нужна ли она нам вообще. Написали, посмотрели и убедились, что пользователям она не понравилась.
А как вы думаете, что нужно делать с фичами, которые людям не нужны?
Правильно, выбрасывайте их! Особенно это стоит сделать, когда фича завязана на внешние сервисы, потому что они имеют свойство получать проблемы или могут быть платными. Так произошло и с этой фичей. Мы не стали реализовывать ни на Android, ни на Desktop, а вместо этого решили проэволюционировать ее. (возможно, когда-нибудь она поедет в прод в более совершенном виде).
В чем сложность?
Как бы смешно это ни звучало, но при внедрении аналитики может возникнуть сложность в работе с самими аналитиками. Чаще всего конфликты возникают из-за того, что они просят предоставить данные, которых у вас нет. А заканчивается это всегда тем, что тебе все равно приходится тащить пачку параметров через 10 экранов, чтобы отправить им один маленький ивент. И так происходит довольно часто.
Вторая сложность заключается в сборе аналитики. У нас этот процесс осуществляется в 7 систем.
Одни ивенты уходят в одну систему, другие — сразу в несколько… Причем есть такая особенность, что в разные системы у нас могут уходить ивенты с разными параметрами и в разных форматах. Безусловно, нам не очень хочется разруливать все эти зависимости.
LStat — это наш собственный SDK (Lamoda statistics). Это массивная система, в которую уходит более 60% различных ивентов. Те ивенты, которые далее идут в Google, Adjust, зачастую изначально собирались только в LStat.
SDK
Наш SDK выглядит следующим образом.
Наружу торчит чистый LStat, который внутри состоит из двух частей: хранение и отправка. Когда мы собираем ивент, то не отправляем его сиюминутно. Иначе было бы слишком много ивентов и запросов, что не очень удобно. Поэтому мы все складываем в нашу маленькую SQLite базу, где все и храним. Затем с некоторой периодичностью наш Network Layer выдергивает данные из базы и отправляет их.
После того, как мы получили от сервера подтверждение, что ивенты дошли, мы очищаем нашу базу. Такой процесс происходит регулярно. Благодаря этому наша база не разрастается, и мы гарантируем доставку всех ивентов. Если по какой-то причине ивент не пришел, то он будет храниться у нас в базе до тех пор, пока от сервера не поступит ответ.
Collectors
Как я говорил ранее, у нас 7 коллекторов. Состоят они из таких методов: кастомная аннотация, EventHandler и AppStartEvent. Как вы думаете, что трекает этот ивент?
Конечно же, это холодный старт приложения. А главное тут — это то, что у нас есть класс AppStartEvent, который наследуется от некоторого интерфейса Event. А зачем нам это нужно, я расскажу чуть позже.
Как это собирается? Тут-то и начинается трэш, угар и рефлексия.
Сначала мы проходимся по всем нашим 7 коллекторам. Затем выдергиваем отсюда Java-класс и collectorName, который потребуется нам потом для хранения.
Далее из этого Java-класса мы вынимаем все наши методы, которые есть в этом коде. Теперь нам нужно проверить и убедиться, что наш метод является трек-ивент методом, который будет отвечать за хранение. Для этого у нас есть несколько параметров: первое – то, что у нас есть аннотация @EventHandler, у нас не пустой список параметров, и на вход нам приходит некоторый ивент.
Все условия выполнены, поэтому можем считать, что эта функция будет у нас ивентом. Я просто оборачиваю в некоторый враппер и отправляю в нашу коллекцию.
Рефлексия — это не всегда плохо
Да, многие из вас скажут, что рефлексия — это плохо, медленно, ужасно.
Начнем с того, что она может быть как медленная, так и быстрая. Есть методы типа getFields, getConstructors, которые работают очень быстро относительно остальной рефлексии. А есть, например, Constructor newInstance, который работает действительно медленно. Под словом “медленно” я подразумеваю разницу между левой и правой колонками в таблице выше на несколько порядков (примерно стократная разница). Поэтому, если вы понимаете, что делаете, и заранее знаете, к чему нужно быть готовым, то тут не все так страшно.
У нас выдергивается более, чем 500 методов из 7 классов. И выполняем мы это всего лишь один раз за сессию. Время, затраченное на полный проход, составляет 40 миллисекунд. Это меньше, чем 3 кадра (на этапе сплешскрина). Причем это был далеко не топовый девайс, а простой НТC на Android 6, которому уже много лет.
Безусловно, что на топовом девайсе все будет работать быстрее. А если мы будем говорить про старые китайские телефоны, то там затраченное время будет составлять условные 100 миллисекунд. Пользователи подобных телефонов уже привыкли к тому, что у них все работает медленно, поэтому им глубоко безразлично 40 там миллисекунд или 100. Какая разница? У них все равно все тормозит :)
А теперь главный вопрос: как внедрить аналитику так, чтобы не сломать архитектуру?
Архитектурка
У нас в приложении используется MVP.
Это наша некая god-сущность, которая “живет” на ApplicationScope и инжектится ровно туда, где нам нужно. Например, нам нужно залогировать onClick(). Чтобы не ломать архитектуру, мы не будет пробрасывать ивент из View-слоя в Presenter, чтобы потом это куда-то ушло. Вместо этого мы напрямую делаем все из View и передаем трек в AnalyticsManager.
А теперь немного про отправку. У AnalyticsManager торчит наружу один метод — это метод трек, который и принимает на вход любой класс ивент. А дальше происходит черная магия.
Данный метод способен разрулить все наши проблемы.
Во-первых, он поможет залогировать в несколько разных систем. Handlers — это все наши ивенты, которые будут когда-либо собраны. Далее мы ищем здесь нужный метод. Соответственно, если у нас трек-эвент написан, например, в 4-х коллекторах, тогда и храниться он будет в 4-х экземплярах. То есть на 4-х проходах цикла мы его найдем и отправим во все 4 системы с соответствующими параметрами.
Во-вторых, это помогает решить проблему с одноразовыми ивентами. Это такие ивенты, которые должны быть залогированы строго 1 раз за весь цикл работы приложения. Ставим пометку e.once, обычная булевая переменная. Если мы говорим, что это одноразовый ивент, то просто удаляем его из коллекции. Что произойдет дальше, если мы попытаемся его заново залогировать? Очевидно, мы просто не найдем его в данной коллекции. Можно сколько угодно пытаться выстрелить себе в ногу, продолжая писать analyticsManager.track(AppStartEvent()), он все равно отправится один раз и больше не будет.
В чем профит?
1. Мы не ломаем архитектуру нашего приложения, так как AnalyticsManager лежит и работает вне архитектуры. Это позволяет нам вставлять его в любую часть приложения.
2. Позволяет собирать любые ивенты одной строкой в любое количество систем аналитики. Для этого мы просто пишем: analyticsManager.track(Event()). Потому что дальше он сам разруливает куда, в каком количестве, с какими параметрами, когда и так далее.
3. Решает проблему “одноразовых ивентов”. Теперь нам не нужно делать различного рода проверки. Один раз отправили, удалили, и больше мы его не встретим.
4. Решает проблему сбора одного и того же элемента в разные системы. За счет того, что мы написали все в разных коллекторах, в разные коллекторы оно и ушло. Таким образом, вам не придется прибегать к лишним телодвижениям. На мой взгляд, это прекрасно.
Тестирование...
Мы тестируем вручную. А почему бы не автоматизировать, спросите вы? И тут выясняется грустная вещь.
Во-первых, unit-тестом ты это, к сожалению, нормально не покроешь. Потому что большая часть проблем с ивентами в аналитике возникает не из-за того, что какой-то из параметров у тебя не собрался. На моем личном опыте 90% проблем возникают из-за того, что ты не отправил ивент там, где он должен был отправиться. Такие кейсы можно отлавливать только UI-тестами, которые мы пока не написали для всего этого.
И во-вторых, мы немножко пока упираемся в то, что аналитики описывают события в достаточно строгом формате (в confluence), но этот формат не является форматом строгой спецификации, как, например, Swagger. Соответственно, бывают небольшие расхождения, бывают дубликаты (хотя в этом случае чаще делается просто ссылка на другую страницу). Пока это ограничивает нас в возможностях автоматизации тестирования аналитики. Но мы работаем над этим.
Выводы
Что же дальше можно сделать с этим решением?
1. Написать автотесты на аналитику. Это потребует большой подготовительной работы. Но нельзя сказать, что это невозможно.
2. Методы-треки плюс-минус достаточно похожи. В каждом мы генерируем некоторые “универсальные” параметры, которые нужны всем. И просто собираем мапу значений. В целом, можно было бы написать либо плагин, либо утилитку. Неважно. Главное, чтобы она генерила трек-ивент по соответствующим классам.
Но тут может возникнуть небольшая проблема, если ивенты начнут уходить чуть по-разному (например, для разных систем аналитики). Из-за этого не все удается решать адекватно. Да и к тому же не хочется плодить лишнюю кодогенерацию в проекте, которой и так много во многих проектах на андроиде (привет Даггер, Мокси и прочие либы работающие на кодгене).
3. Интеграция приложения со спеками аналитиков. Наверное, это слишком заоблачная мечта, но все же… Нам бы очень хотелось, чтобы наши аналитики писали в строгом формате, а мы могли бы парсить их произведения искусств и интегрировать. Тогда настал бы мир и гармония. Все были бы счастливы :)
Так что же я хочу всем этим сказать?
Во-первых, аналитика все-таки нужна. Потому что она позволяет экономить деньги, ресурсы и силы. Это спасает от написания лишнего кода или удаления кода, который вроде бы не старый, но все равно тут не нужен. Меньше legacy — это всегда хорошо.
Во-вторых, рефлексия – это не всегда плохо. Да, она бывает медленная. Но порой мы теряем совсем немного в производительности, зато много получаем, например, в области разработки, обработки ошибок.
И в-третьих, мы закладываем аналитику на этапе планирования фичи. За счет этого мы намного заранее можем договориться с аналитиками, достигнув компромисса. А также это дает нам возможность оценивать времязатраты на написание аналитики заранее.

