

Привет, Хабр! Я руковожу разработкой платформы Vision — это наша публичная платформа, которая предоставляет доступ к моделям компьютерного зрения и позволяет вам решать такие задачи, как распознавание лиц, номеров, объектов и целых сцен. И сегодня хочу на примере Vision рассказать, как реализовать быстрый высоконагруженный сервис, использующий видеокарты, как его разворачивать и эксплуатировать.
Что такое Vision?
По сути, это REST API. Пользователь формирует HTTP-запрос c фотографией и отправляет на сервер.
Допустим, нужно на снимке распознать лицо. Система его находит, вырезает, извлекает из лица какие-то свойства, сохраняет в базе и присваивает некий условный номер. Например, person42. Затем пользователь загружает следующую фотографию, на которой есть тот же самый человек. Система извлекает из его лица свойства, ищет по базе и возвращает условный номер, который был присвоен персоне изначально, т.е. person42.
Сегодня основные пользователи Vision — это различные проекты Mail.ru Group. Больше всего запросов приходит от Почты и Облака.

В Облаке у пользователей есть папки, в которые загружаются фотографии. Облако прогоняет файлы через Vision и группирует их по категориям. После этого пользователь может удобно листать свои фотографии. Например, когда хочется показать фотографии друзьям или родным, можно быстро найти нужные.
И Почта, и Облако — это очень крупные сервисы с многомиллионными аудиториями, поэтому Vision обрабатывает сотни тысяч запросов в минуту. То есть это классический высоконагруженный сервис, но с изюминкой: в нём есть и nginx, и веб-сервер, и база данных, и очереди, но на самом нижнем уровне этого сервиса находится inference — прогон изображений через нейронные сети. Именно прогон нейронных сетей занимает большую часть времени и требует ресурсов. Вычисление сетей состоит из последовательности матричных операций, которые на CPU выполняются обычно долго, зато отлично распараллеливаются на GPU. Для эффективного прогона сетей у нас используется кластер серверов с видеокартами.
В этой статье я хочу поделиться набором советов, которые могут быть полезны при создании подобного сервиса.
Разработка сервиса
Время обработки одного запроса
Для системы с большой нагрузкой важное значение имеет время обработки одного запроса и пропускная способность системы. Высокая скорость обработки запросов обеспечивается, в первую очередь, правильным подбором архитектуры нейронной сети. В ML, как и в любых других задачах программирования, одни и те же задачи можно решать разными способами. Возьмём детектирование лиц: для решения этой задачи мы сначала взяли нейросети с архитектурой R-FCN. Они показывают достаточно высокое качество, но занимали порядка 40 мс на одном изображении, что нас не устраивало.Тогда мы обратились к архитектуре MTCNN и получили двукратный прирост скорости с незначительной потерей качества.
Иногда для оптимизации времени вычисления нейронных сетей бывает выгодно в проде осуществлять inference в другом фреймворке, не в том, котором проводилось обучение. Например, иногда имеет смысл конвертировать свою модель в NVIDIA TensorRT. Он применяет ряд оптимизаций и особенно хорош на достаточно сложных моделях. Например, он может каким-то образом переставить некоторые слои, объединить и даже выкинуть; результат при этом не изменится, а скорость вычисления inference возрастёт. Также TensorRT позволяет лучше управлять памятью и может после некоторых ухищрений сводить к вычислениям чисел с меньшей точностью, что тоже повышает скорость вычисления inference.
Загрузка видеокарты
Inference сети у нас осуществляется на GPU, видеокарта являются самой дорогой частью сервера, поэтому важно максимально эффективно ее использовать. Как понять, полностью мы загрузили GPU или можно увеличить нагрузку? На этот вопрос можно ответить, например, с помощью параметра GPU Utilization, в утилите nvidia-smi из стандартного пакета видеодрайвера. Данная цифра конечно не показывает сколько CUDA-ядер непосредственно загружено у видеокарты, а сколько простаивают, но она позволяет как-то оценить загрузку GPU. По опыту можно сказать, что хорошей является загрузка на 80-90 %. Если она загружена на 10-20 %, то это плохо, и потенциал ещё есть.
Важное следствие из этого наблюдения: нужно стараться организовать систему так, чтобы максимально загружать видеокарты. Кроме того, если у вас есть 10 видеокарт, каждая из которых загружена на 10-20 %, то, скорее всего, ту же самую задачу могут решить две видеокарты с высокой загрузкой.
Пропускная способность системы
Когда вы подаете картинку на вход нейросети, то обработка картинки сводится к разнообразным матричным операциям. Видеокарта — многоядерная система, а картинки на вход мы обычно подаем небольшого размера. Допустим, на нашей видеокарте 1 000 ядер, а картинки у нас 250 х 250 пикселей. По одиночке они не смогут загрузить все ядра из-за своего скромного размера. И если мы будем подавать такие картинки в модель по одной, то загрузка видеокарты не будет превышать 25 %.

Поэтому нужно загружать в inference сразу несколько картинок и формировать из них batch.

В этом случае загрузка видеокарты поднимается до 95 %, а вычисление inference займет время как для одной картинки.
А что делать, если в очереди нет 10 картинок, чтобы мы могли их объединить в батч? Можно немного подождать, например, 50-100 мс в надежде на то, что запросы придут. Эта стратегия носит название fix latency strategy (стратегия фиксированной задержки). Она позволяет объединять запросы от клиентов во внутреннем буфере. В итоге мы увеличиваем нашу задержку на некоторую фиксированную величину, но значительно увеличиваем пропускную способность системы.
Запуск inference
Модели мы обучаем на изображениях фиксированного формата и размера (например, 200 х 200 пикселей), но сервис должен поддерживать возможность загружать различные картинки. Поэтому все изображения прежде чем подавать на inference, нужно правильно подготовить (отресайзить, центрировать, нормировать, перевести во float и т.д.). Если все эти операции будут выполняться в процессе, который запускает inference, то его рабочий цикл будет выглядеть примерно так:
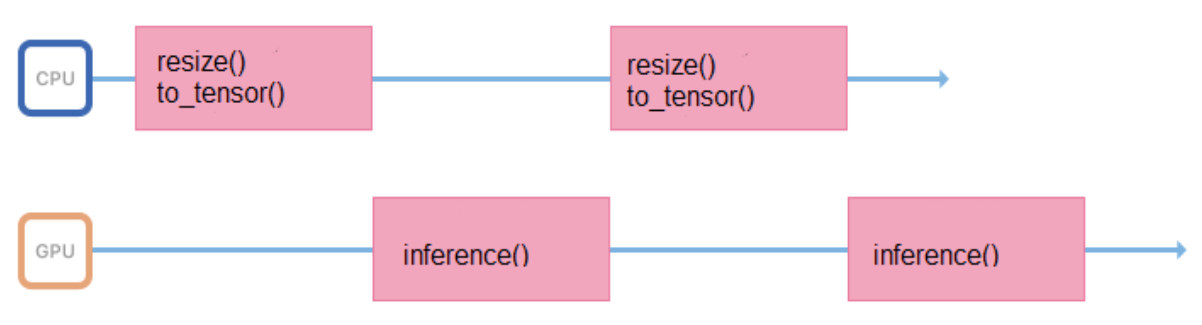
Какое-то время он тратит в процессоре, подготавливая входные данные, какое-то время ждет ответа от GPU. Лучше максимально уменьшить промежутки между inference, чтобы GPU меньше простаивала.

Для этого можно завести ещё один поток, или передать подготовку изображений другим серверам, без видеокарт, но с мощными процессорами.
Процесс, отвечающий за inference, по возможности должен заниматься только им: обращаться к общей памяти, забирать входные данные, сразу копировать их в память видеокарты и запускать inference.
Turbo Boost
Запуск нейросетей — операция, затратная по ресурсам не только GPU, но и процессора. Даже если у вас всё будет правильно организовано с точки зрения пропускной способности, и поток, который выполняет inference, уже ждет новых данных, на слабом процессоре вы просто не будете успевать насыщать этот поток новыми данными.
Многие процессоры поддерживают технологию Turbo Boost. Она позволяет увеличивать частоту работы процессора, однако не всегда включена по умолчанию. Стоит это проверить. Для этого в Linux есть утилита CPU Power:
$ cpupower frequency-info -m.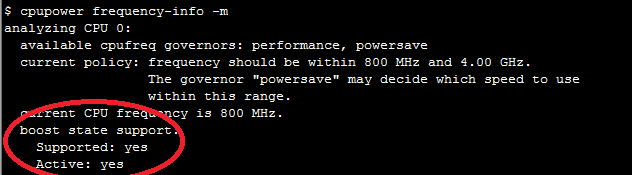
Также у процессоров настраивается режим энергопотребления, его можно узнать такой командой CPU Power:
performance.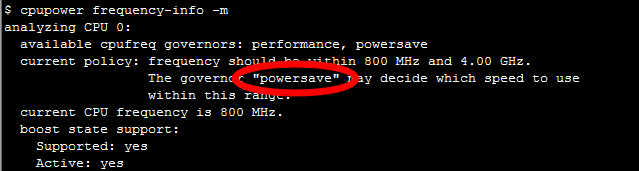
В режиме powersave процессор может тротлить свою частоту и работать медленнее. Стоит зайти в BIOS и выбрать режим performance. Тогда процессор будет всё время работать на максимальной частоте.
Развёртывание приложения
Для развертывания приложения отлично подходит Docker, он позволяет запускать приложения на GPU внутри контейнера. Чтобы получить доступ к видеокартам, для начала вам понадобится установить драйвера для видеокарты на хост-систему — физический сервер. Затем, чтобы запустить контейнер, нужно проделать много ручной работы: правильно прокинуть видеокарты внутрь контейнера с правильно подобранными параметрами. После запуска контейнера еще необходимо будет внутри него установить видеодрайверы. И только после этого вы сможете пользоваться вашим приложением.

У этого подхода есть один нюанс. Серверы могут пропадать из кластера и добавляться. Возможна ситуация, когда на разных серверах будут разные версии драйверов, и они будут отличаться от версии, которая ставится внутри контейнера. В этом случае простой Docker сломается: приложение при попытке доступа к видеокарте получит ошибку driver version mismatch.

Как с этим бороться? Существует версия Docker от NVIDIA, благодаря которой пользоваться контейнером становится проще и приятнее. По заверениям самой NVIDIA и по практическим наблюдениям, накладные расходы на использование nvidia-docker около 1 %.
В этом случае драйвера нужно ставить только на хост-машину. При запуске контейнера, ничего прокидывать во внутрь не надо, и у приложения сразу появится доступ к видеокартам.

«Независимость» nvidia-docker от драйверов позволяет запускать контейнер из одного и того же образа на разных машинах, на которых установлены разные версии драйверов. Как это реализовано? В Docker есть такое понятие, как docker-runtime: это набор стандартов, который описывает, как контейнер должен общаться с ядром хостовой машины, как он должен запускаться и останавливаться, как взаимодействовать с ядром и драйвером. Начиная с определенной версии Docker есть возможность подменять этот runtime. Это и сделали в NVIDIA: они подменяют рантайм, ловят внутри обращения к видеодрайверу и преобразуют в обращения к видеодрайверу правильной версии.
Оркестрация
В качестве оркестратора мы выбрали Kubernetes. Он поддерживает много очень хороших функций, которые полезны для любой высоконагруженной системы. Например, autodiscovering позволяет сервисам обращаться друг к другу внутри кластера без сложных правил роутинга. Или fault tolerance — когда Kubernetes всегда держит наготове несколько контейнеров, и если с вашим что-то случилось, то Kubernetes тут же запустит новый контейнер.
Если у вас есть уже настроенный Kubernetes-кластер, то вам нужно не так много, чтобы начать использовать видеокарты внутри кластера:
- относительно свежие драйверы
- установленный nvidia-docker версии 2
- docker runtime выставленный по умолчанию в `nvidia` в файле /etc/docker/daemon.json:
"default-runtime": "nvidia"
- Установленный плагин
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
После того, как вы сконфигурировали свой кластер и установили device плагин, можете в качестве ресурса указывать видеокарту.
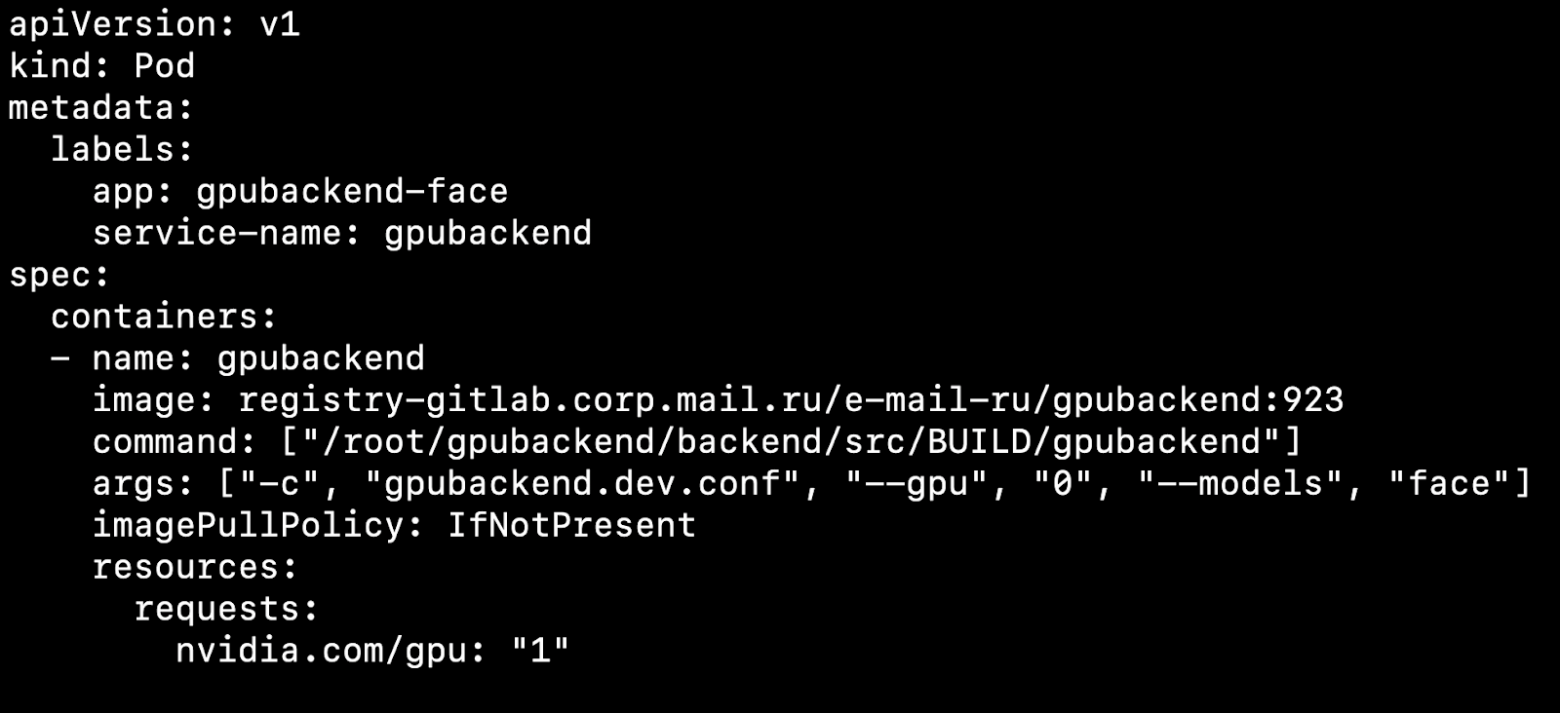
На что это влияет? Допустим, у нас есть две ноды, физические машины. На одной есть видеокарта, на другой нет. Kubernetes обнаружит машину с видеокартой и поднимет наш pod именно на ней.
Важно заметить, Kubernetes не умеет грамотно шарить видеокарту между подами. Если у вас имеется 4 видеокарты, и вам для запуска контейнера требуется 1 GPU, то вы сможете поднять не более 4 подов на вашем кластере.
Мы берем за правило 1 Pod = 1 Модель = 1 GPU.
Есть вариант запускать на 4 видеокартах больше инстансов, но мы не будем рассматривать его в этой статье, так как этот вариант не идет из коробки.
Если на проде должно крутиться сразу несколько моделей, удобно под каждую модель создать Deployment в Kubernetes. В его конфигурационном файле можно прописать количество подов под каждую модель, с учетом популярности модели. Если на модель приходит много запросов, то под нее соответственно нужно указать много подов, если мало запросов — мало подов. Суммарно количество подов должно равняться количеству видеокарт в кластере.
Рассмотрим интересный момент. Допустим у нас есть 4 видеокарты и 3 модели.

На двух первых видеокартах пусть поднимется inference модели распознавания лиц, еще на одной распознавание объектов и на другой распознавание автомобильных номеров.
Вы работаете, клиенты приходят и уходят, и однажды, например ночью, возникает ситуация, когда видеокарта с inference объектов просто не загружена, на неё приходит мизерное количество запросов, а видеокарты с распознаванием лиц перегружены. Хотелось бы потушить в этот момент модель с объектами и на ее месте запустить лица, чтобы разгрузить очереди.
Для автоматического масштабирования моделей по видеокартам существуют инструменты внутри Kubernetes — горизонтальное автомасштабирование подов (HPA, horizontal pod autoscaler).
Из коробки Kubernetes поддерживает автомасштабирование по загрузке процессора. Но в задаче с видеокартами будет гораздо разумнее для масштабирования использовать информацию о количестве задач к каждой модели.
Мы делаем так: складываем запросы к каждой модели в очередь. Когда запросы выполнены, мы их из этой очереди удаляем. Если мы успеваем быстро обрабатывать запросы к популярным моделям, то очередь не растет. Если же количество запросов к конкретной модели вдруг увеличивается, то очередь начинает расти. Становится понятно, что нужно добавлять видеокарты, которые будут помогать разгребать очередь.
Информацию об очередях мы прокидываем в HPA через Prometheus:

И затем делаем в кластере автомасштабирование моделей по видеокартам в зависимости от количества запросов к ним.
CI/CD
После того, как вы контейнировали приложение и завернули его в Kubernetes, вам остается буквально один шаг до вершины развития проекта. Можно добавить CI/CD, вот пример из нашего конвейера:

Здесь программист запушил новый код в мастер-ветку, после чего автоматически собирается Docker-образ с нашими демонами бэкендов, и прогоняются тесты. Если все галочки зеленые, то приложение заливается в тестовую среду. Если и в ней не будет никаких проблем, то далее можно без затруднений отправлять образ в эксплуатацию.
Заключение
В своей статье я затронул некоторые аспекты работы высоконагруженного сервиса, использующего GPU. Мы поговорили о способах уменьшения времени отклика сервиса, таких как:
- подбор оптимальной архитектуры нейросети для уменьшения latency;
- применения оптимизирующих фреймворков наподобие TensorRT.
Затронули вопросы увеличения пропускной способности:
- использование батчинга картинок;
- применение fix latency strategy, чтобы количество запусков inference уменьшалось, но каждый inference обрабатывал бы большее число картинок;
- оптимизация data input pipeline с целью минимизации простоев GPU;
- «борьба» с тротлингом процессора, вынос cpu-bound операций на другие серверы.
Взглянули на процесс развертывания приложения с GPU:
- использование nvidia-docker внутри Kubernetes;
- масштабирование на основе количества запросов и HPA (horizontal pod autoscaler).
